자기조직화 지도(SOM)는 인공 신경망의 한 종류로, 고차원 데이터를 저차원 공간으로 매핑하여 시각화하고 데이터의 특징을 추출하는 데 사용된다. SOM은 뇌의 시각 피질의 자기 조직화 방식을 모방하여, 입력 데이터에 가장 가까운 뉴런을 찾아 해당 뉴런과 이웃 뉴런의 가중치를 조정하는 경쟁 학습 방식을 사용한다. 온라인 학습과 배치 학습 방식이 있으며, U-Matrix, 히트맵 등을 통해 SOM의 결과를 해석하고 시각화할 수 있다. SOM은 차원 축소, 군집화, 위상 보존 등의 특징을 가지며, 프로젝트 우선순위 결정, 지진 분석, 고장 모드 분석 등 다양한 분야에 활용된다. GTM, GSOM, 탄성 지도 등 다양한 확장 및 변형이 이루어졌다.
2. 역사적 배경
자기조직화 지도는 입력층과 경쟁층(출력층)으로 구성된 2층 구조의 비지도 학습 신경망이다. 입력은 수치 데이터이며, 출력은 경쟁층에 배치된 노드가 된다. 경쟁층의 노드 배치 차원은 자유롭게 설정할 수 있는데, 가장 기본적인 활용법은 2차원 위에 노드를 배치하고, 고차원 데이터를 학습시켜 고차원 데이터의 관계성을 시각화하는 것이다. 이처럼 자기조직화 지도는 고차원 데이터 간에 존재하는 비선형 관계를 간단하게 기하학적 관계를 갖는 이미지로 변환할 수 있다.[1]
현재 자기조직화 지도에는 다양한 변형이 있으며, 기존의 자기조직화 지도를 기본 SOM (Basic SOM, BSOM)이라고 부르기도 한다. 하지만 BSOM이라는 약칭은 배치 학습 SOM (Batch Learning SOM, BL-SOM)과 혼동될 수 있으므로 바람직하지 않다.[1]
2. 1. 초기 모델
자기조직화 지도는 대뇌 피질의 시각야가 기둥 구조를 가지며, 이 구조가 학습에 의해 얻어진다는 점을 모델화한 것이다. 1976년 Willshaw와 Von Der Malsburg에 의해 제안되었다.
2. 2. 코호넨의 공헌
1976년 Willshaw와 Von Der Malsburg는 대뇌 피질 시각야에서의 기둥 구조 자기 조직화를 모델화한 자기조직화 지도를 제안했다. 이 기둥 구조는 생득적인 것이 아니라 학습에 의해 얻어지는 것이다.
3. 알고리즘
자기 조직화 지도(SOM)는 훈련과 매핑이라는 두 가지 모드로 작동한다. 훈련은 입력 데이터 집합을 사용하여 입력 데이터의 저차원 표현(지도 공간)을 생성하고, 매핑은 생성된 지도를 사용하여 추가 입력 데이터를 분류한다.[5]
훈련의 목표는 ''p'' 차원의 입력 공간을 2차원의 지도 공간으로 표현하는 것이다. 지도 공간은 2차원의 육각형 또는 직사각형 그리드로 배열된 "노드" 또는 "뉴런"으로 구성된다.[5] 각 노드는 입력 공간에서 해당 노드의 위치를 나타내는 "가중치" 벡터와 연관되어 있다. 지도 공간의 노드는 고정되어 있지만, 훈련은 가중치 벡터를 입력 데이터 쪽으로 이동(예: 유클리드 거리 감소)시키는 방식으로 이루어진다.
훈련 후에는 가중치 벡터가 입력 공간 벡터에 가장 가까운 노드를 찾아 추가적인 입력 데이터를 분류할 수 있다.
SOM 알고리즘에는 온라인 학습 모델과 배치 학습 모델이 있다. 온라인 학습 모델은 데이터가 입력될 때마다 학습이 이루어지며, 최근에 입력된 데이터에 더 큰 가중치를 부여한다. 각 뉴런의 초기값은 무작위로 설정된다. 반면, 배치 학습 모델은 모든 데이터를 분류한 후 한 번에 학습을 진행한다.
자기조직화 지도(SOM)는 훈련과 매핑이라는 두 가지 모드로 작동한다. 훈련은 입력 데이터를 사용하여 저차원 표현(지도 공간)을 생성하고, 매핑은 생성된 지도를 사용하여 추가 입력 데이터를 분류한다.[5]
학습 목표는 네트워크의 서로 다른 부분이 특정 입력 패턴에 유사하게 반응하도록 하는 것이다. 이는 대뇌 피질에서 시각, 청각 등의 감각 정보가 별도 부분에서 처리되는 방식에서 부분적으로 영감을 받았다.[6]
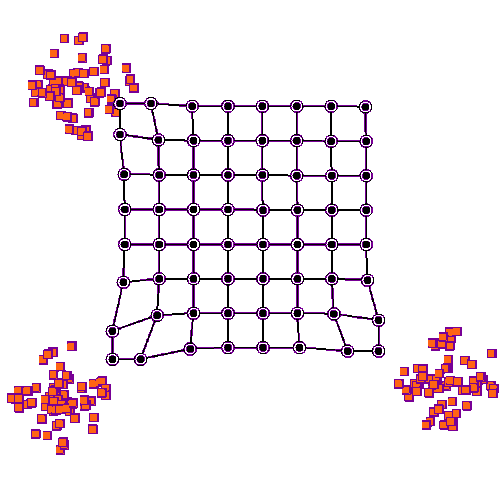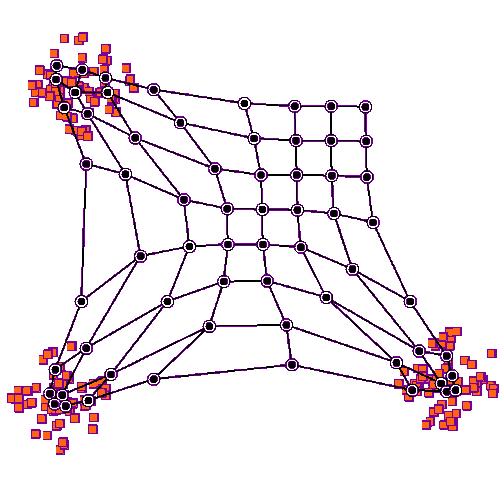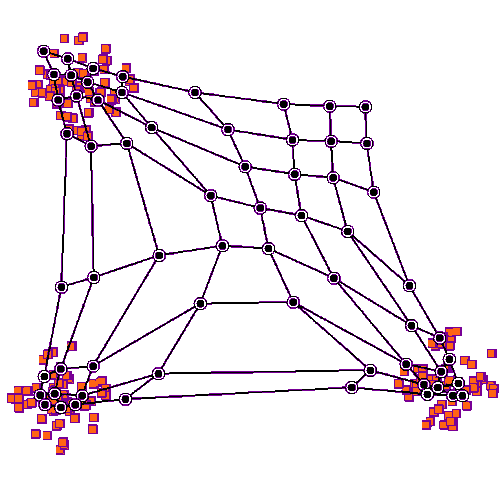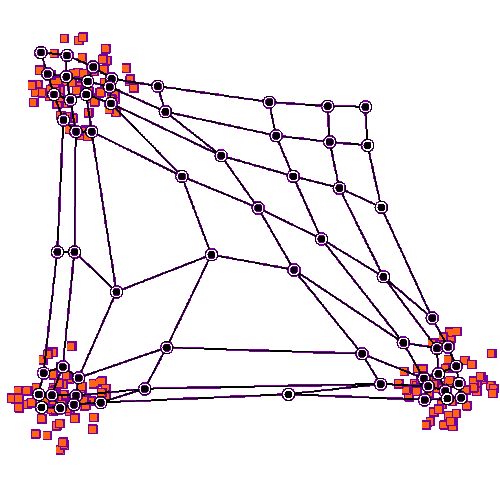
자기 조직화 맵의 학습 그림. 파란색 덩어리는 학습 데이터의 분포이며, 작은 흰색 원반은 해당 분포에서 추출된 현재 학습 데이터이다. 처음에는 (왼쪽) SOM 노드가 데이터 공간에 임의로 배치된다. 학습 데이터에 가장 가까운 노드 (노란색으로 강조 표시됨)가 선택된다. 그리드의 이웃과 마찬가지로 학습 데이터를 향해 이동한다. 여러 반복 후에 그리드는 데이터 분포를 근사하는 경향이 있다 (오른쪽).
2차원 데이터 집합에 대한 SOM의 학습 과정
뉴런의 가중치는 작은 임의 값으로 초기화되거나, 두 개의 가장 큰 주성분 고유 벡터로 구성된 하위 공간에서 균등하게 샘플링된다. 후자의 경우 초기 가중치가 이미 SOM 가중치를 잘 근사하기 때문에 학습이 훨씬 빠르다.[7]
학습은 경쟁 학습을 활용한다. 학습 예제가 네트워크에 제공되면, 모든 가중치 벡터에 대한 유클리드 거리가 계산된다. 입력과 가중치 벡터가 가장 유사한 뉴런을 '''최적 적합 유닛'''(BMU)이라고 한다. SOM 그리드에서 BMU와 그 근처 뉴런의 가중치는 입력 벡터를 향해 조정된다. 변경 크기는 시간과 BMU로부터의 그리드 거리에 따라 감소한다.
가중치 벡터 '''Wv'''(s)를 가진 뉴런 v의 업데이트 공식은 다음과 같다.
:
여기서,
''s''는 단계 인덱스
''t''는 학습 샘플의 인덱스
''u''는 입력 벡터 '''D'''(''t'')에 대한 BMU의 인덱스
''α''(''s'')는 단조 감소 학습 계수
''θ''(''u'', ''v'', ''s'')는 뉴런 u와 단계 ''s''의 뉴런 ''v'' 사이의 거리를 제공하는 근방 함수이다.[8]
구현에 따라 학습 데이터 집합을 체계적으로 스캔하거나, 무작위로 추출하거나, 다른 샘플링 방법을 사용할 수 있다.
근방 함수 ''θ''(''u'', ''v'', ''s'')는 BMU (뉴런 ''u'')와 뉴런 ''v'' 사이의 그리드 거리에 따라 달라진다. 가장 간단한 형태는 BMU에 충분히 가까운 모든 뉴런에 대해 1이고 나머지는 0이지만, 가우스 함수 및 멕시코 모자 웨이블릿[9] 함수도 일반적인 선택이다. 근방 함수는 시간이 지남에 따라 축소된다.[6] 근방이 넓은 초기에 자기 조직화는 전역적인 규모로 발생하고, 근방이 몇 개의 뉴런으로 축소되면 가중치가 로컬 추정치로 수렴된다.
이 과정은 각 입력 벡터에 대해 반복된다. 네트워크는 결국 출력 노드를 입력 데이터 집합의 그룹 또는 패턴과 연결하며, 이러한 패턴의 이름을 지정할 수 있으면 훈련된 네트워크의 관련 노드에 이름을 첨부할 수 있다.
매핑하는 동안 입력 벡터에 가중치 벡터가 가장 가까운 단일 ''승리'' 뉴런이 존재하며, 이는 유클리드 거리 계산으로 결정된다.
SOM의 주요 설계 선택은 형태, 이웃 함수 및 학습률 스케줄이다. 이웃 함수의 아이디어는 BMU가 가장 많이 업데이트되도록 하고, 바로 옆의 이웃은 조금 덜 업데이트되도록 하는 것이다. 학습률 스케줄의 아이디어는 맵 업데이트가 처음에는 크고 점차 업데이트를 중지하도록 하는 것이다.
업데이트율은 유클리드 공간에서 점의 위치가 아닌 SOM 자체 내에서의 위치에 의존한다.
SOM의 알고리즘에는 온라인 학습 모델과 배치 학습 모델이 있다.
3. 1. 1. 온라인 학습 (Online Learning)
자기 조직화 지도(SOM)의 학습 목표는 네트워크의 서로 다른 부분이 특정 입력 패턴에 유사하게 반응하도록 만드는 것이다. 이는 대뇌 피질에서 시각, 청각 등의 감각 정보가 별도 부분에서 처리되는 방식에서 부분적으로 영감을 받았다.[6]
뉴런의 가중치는 작은 임의 값으로 초기화되거나, 두 개의 가장 큰 주성분 고유 벡터로 구성된 하위 공간에서 균등하게 샘플링된다. 후자의 경우 초기 가중치가 이미 SOM 가중치를 잘 근사하기 때문에 학습이 훨씬 빠르다.[7]
온라인 학습은 경쟁 학습을 활용한다. 학습 예제가 네트워크에 제공되면, 모든 가중치 벡터에 대한 유클리드 거리가 계산된다. 입력과 가중치 벡터가 가장 유사한 뉴런을 '''최적 적합 유닛'''(BMU)이라고 한다. SOM 그리드에서 BMU와 그 근처 뉴런의 가중치는 입력 벡터를 향해 조정된다. 변경 크기는 시간과 BMU로부터의 그리드 거리에 따라 감소한다. 가중치 벡터 '''Wv'''(s)를 가진 뉴런 v의 업데이트 공식은 다음과 같다.
:
여기서,
''s''는 단계 인덱스
''t''는 학습 샘플의 인덱스
''u''는 입력 벡터 '''D'''(''t'')에 대한 BMU의 인덱스
''α''(''s'')는 단조 감소 학습 계수
''θ''(''u'', ''v'', ''s'')는 뉴런 u와 단계 ''s''의 뉴런 ''v'' 사이의 거리를 제공하는 근방 함수[8]
구현에 따라 학습 데이터 집합을 체계적으로 스캔하거나, 무작위로 추출하거나, 다른 샘플링 방법을 사용할 수 있다.
근방 함수 ''θ''(''u'', ''v'', ''s'')는 BMU (뉴런 ''u'')와 뉴런 ''v'' 사이의 그리드 거리에 따라 달라진다. 가장 간단한 형태는 BMU에 충분히 가까운 모든 뉴런에 대해 1이고 나머지는 0이지만, 가우스 함수 및 멕시코 모자 웨이블릿[9] 함수도 일반적인 선택이다. 근방 함수는 시간이 지남에 따라 축소된다.[6] 근방이 넓은 초기에 자기 조직화는 전역적인 규모로 발생하고, 근방이 몇 개의 뉴런으로 축소되면 가중치가 로컬 추정치로 수렴된다.
이 과정은 각 입력 벡터에 대해 반복된다. 네트워크는 결국 출력 노드를 입력 데이터 집합의 그룹 또는 패턴과 연결하며, 이러한 패턴의 이름을 지정할 수 있으면 훈련된 네트워크의 관련 노드에 이름을 첨부할 수 있다.
매핑하는 동안 입력 벡터에 가중치 벡터가 가장 가까운 단일 ''승리'' 뉴런이 존재하며, 이는 유클리드 거리 계산으로 결정된다.
SOM의 알고리즘은 다음과 같이 요약할 수 있다.
1. 맵에서 노드 가중치 벡터를 무작위로 초기화한다.
2. 입력 벡터 를 무작위로 선택한다.
3. 맵에서 입력 벡터에 가장 가까운 노드(BMU)를 찾는다.
4. 각 노드 에 대해, 입력 벡터에 가깝게 벡터를 업데이트한다:
5. 를 증가시키면서 2-4단계를 반복한다.
SOM의 주요 설계 선택은 형태, 이웃 함수 및 학습률 스케줄이다. 이웃 함수의 아이디어는 BMU가 가장 많이 업데이트되도록 하고, 바로 옆의 이웃은 조금 덜 업데이트되도록 하는 것이다. 학습률 스케줄의 아이디어는 맵 업데이트가 처음에는 크고 점차 업데이트를 중지하도록 하는 것이다.
예를 들어, 사각형 그리드를 사용하고, 를 사용하여 인덱싱할 수 있으며 (), 이웃 함수는 다음과 같이 만들 수 있다.
} = \begin{cases}
1 & \text{if }i=i', j = j' \\
1/2 & \text{if }|i-i'| + |j-j'| = 1 \\
1/4 & \text{if }|i-i'| + |j-j'| = 2 \\
\cdots & \cdots
\end{cases}
그리고 간단한 선형 학습률 스케줄 를 사용할 수 있다.
업데이트율은 유클리드 공간에서 점의 위치가 아닌 SOM 자체 내에서의 위치에 의존한다.
SOM의 알고리즘은 크게 두 가지가 있는데, 온라인 학습 모델은 데이터가 입력될 때마다 학습이 이루어지고, 나중에 입력된 데이터의 가중치가 높아지는 경향이 있다. 또한 각 뉴런의 초기값은 임의로 설정된다.
3. 1. 2. 배치 학습 (Batch Learning)
자기조직화 지도(SOM)의 학습 목표는 네트워크의 서로 다른 부분이 특정 입력 패턴에 유사하게 반응하도록 하는 것이다. 이는 대뇌 피질에서 시각, 청각 등의 감각 정보가 별도 부분에서 처리되는 방식과 유사하다.[6]
뉴런의 가중치는 초기에는 작은 임의의 값으로 설정되거나, 두 개의 가장 큰 주성분 고유벡터로 구성된 하위 공간에서 균등하게 샘플링된다. 후자의 경우 초기 가중치가 이미 SOM 가중치를 잘 근사하므로 학습이 더 빠르다.[7]
학습에는 경쟁 학습이 사용된다. 학습 예제가 네트워크에 주어지면, 모든 가중치 벡터에 대한 유클리드 거리가 계산된다. 입력과 가중치 벡터가 가장 유사한 뉴런을 '''최적 적합 유닛'''(BMU, Best Matching Unit)이라고 한다. SOM 그리드에서 BMU와 그 근처 뉴런의 가중치는 입력 벡터를 향해 조정된다. 변경 크기는 시간이 지남에 따라, 그리고 BMU로부터의 그리드 거리에 따라 감소한다. 뉴런 v의 가중치 벡터 '''Wv'''(s) 업데이트 공식은 다음과 같다.
:
여기서,
''s''는 단계 인덱스
''t''는 학습 샘플의 인덱스
''u''는 입력 벡터 '''D'''(''t'')에 대한 BMU의 인덱스
''α''(''s'')는 단조 감소 학습 계수
''θ''(''u'', ''v'', ''s'')는 뉴런 u와 단계 ''s''의 뉴런 ''v'' 사이의 거리를 나타내는 근방 함수이다.[8]
근방 함수 ''θ''(''u'', ''v'', ''s'')는 BMU (뉴런 ''u'')와 뉴런 ''v'' 사이의 그리드 거리에 따라 달라진다. 가장 간단한 형태는 BMU에 충분히 가까운 모든 뉴런에 대해 1, 나머지는 0이다. 가우스 함수 및 멕시코 모자 웨이블릿[9] 함수도 일반적으로 사용된다. 어떤 형식이든, 근방 함수는 시간이 지남에 따라 축소된다.[6] 초기에는 넓은 근방에서 전역적인 자기조직화가 발생하고, 근방이 몇 개의 뉴런으로 좁혀지면 가중치는 로컬 추정치로 수렴한다.
이 과정은 각 입력 벡터에 대해 여러 사이클(λ) 동안 반복된다. 네트워크는 결국 출력 노드를 입력 데이터 집합의 그룹 또는 패턴과 연결하며, 이러한 패턴의 이름을 지정하여 훈련된 네트워크의 관련 노드에 붙일 수 있다.
매핑 과정에서 입력 벡터에 가장 가까운 가중치 벡터를 가진 단일 ''승리'' 뉴런이 존재하며, 이는 유클리드 거리 계산으로 결정된다.
SOM의 알고리즘은 다음과 같다.
1. 지도에서 노드 가중치 벡터를 무작위로 초기화한다.
2. 에 대해 반복한다.
입력 벡터 를 무작위로 선택한다.
지도에서 입력 벡터에 가장 가까운 노드(BMU)를 찾는다.
각 노드 에 대해, 입력 벡터에 가깝게 벡터를 업데이트한다:
변수의 의미는 다음과 같다.
: 현재 반복 횟수
: 반복 제한
: 입력 데이터 집합 에서 대상 입력 데이터 벡터의 인덱스
: 대상 입력 데이터 벡터
: 지도 노드 인덱스
: 노드 의 현재 가중치 벡터
: 지도에서 최적 매칭 유닛(BMU)의 인덱스
: 이웃 함수
: 학습률 스케줄
SOM 설계 시 형태, 이웃 함수, 학습률 스케줄이 중요하며, 업데이트율은 유클리드 공간이 아닌 SOM 내 위치에 의존한다.
SOM의 알고리즘에는 데이터 입력 시마다 학습하는 온라인 학습 모델과, 모든 데이터를 분류 후 동시에 학습하는 BL-SOM이 있다.
3. 2. 매핑 단계
자기조직화 지도(SOM)는 대부분의 인공 신경망과 마찬가지로 훈련과 매핑이라는 두 가지 모드로 작동한다. 먼저, 훈련은 입력 데이터 집합("입력 공간")을 사용하여 입력 데이터의 더 낮은 차원 표현("지도 공간")을 생성한다. 둘째, 매핑은 생성된 지도를 사용하여 추가 입력 데이터를 분류한다.
대부분의 경우 훈련의 목표는 ''p'' 차원의 입력 공간을 2차원의 지도 공간으로 표현하는 것이다. 구체적으로, ''p''개의 변수를 가진 입력 공간은 ''p''차원을 갖는다고 말한다. 지도 공간은 2차원의 육각형 또는 직사각형 그리드로 배열된 "노드" 또는 "뉴런"이라고 하는 구성 요소로 구성된다.[5]
지도 공간의 각 노드는 "가중치" 벡터와 연관되어 있으며, 이는 입력 공간에서 노드의 위치이다. 훈련 후, 지도는 입력 공간 벡터에 가장 가까운 가중치 벡터(최소 거리 메트릭)를 가진 노드를 찾아 입력 공간에 대한 추가 관측치를 분류하는 데 사용할 수 있다.
3. 3. 알고리즘 상세
자기 조직화 지도(SOM) 학습의 목표는 네트워크의 서로 다른 부분이 특정 입력 패턴에 유사하게 반응하도록 만드는 것이다. 이는 대뇌 피질에서 시각, 청각 등의 감각 정보가 별도 부분에서 처리되는 방식에서 부분적으로 영감을 받았다.[6]
뉴런의 가중치는 초기화 시 작은 임의 값으로 설정되거나, 두 개의 가장 큰 주성분 고유 벡터로 구성된 하위 공간에서 균등하게 샘플링된다. 후자의 경우 초기 가중치가 이미 SOM 가중치를 잘 근사하므로 학습이 더 빨라진다.[7]
학습 과정은 경쟁 학습을 기반으로 한다. 학습 예제가 네트워크에 주어지면, 모든 가중치 벡터와 유클리드 거리를 계산한다. 입력과 가장 유사한 가중치 벡터를 가진 뉴런을 '''최적 적합 유닛'''(BMU)이라고 한다. BMU와 그 근처 뉴런의 가중치는 입력 벡터 방향으로 조정된다. 변화량은 시간과 BMU로부터의 그리드 거리에 따라 감소한다. 뉴런 v의 가중치 벡터 '''Wv'''(s)의 업데이트 공식은 다음과 같다.
:
여기서,
s는 단계 인덱스
t는 학습 샘플 인덱스
u는 입력 벡터 '''D'''(''t'')에 대한 BMU 인덱스
α(s)는 단조 감소하는 학습 계수
θ(''u'', ''v'', ''s'')는 뉴런 u와 뉴런 v 사이의 거리를 나타내는 근방 함수이다.[8]
근방 함수 θ(''u'', ''v'', ''s'')는 BMU(뉴런 ''u'')와 뉴런 ''v'' 사이의 그리드 거리에 따라 달라진다. 가장 간단한 형태는 BMU에 충분히 가까운 모든 뉴런에 대해 1, 나머지는 0이다. 가우스 함수나 멕시코 모자 웨이블릿[9] 함수도 사용된다. 어떤 형식이든, 근방 함수는 시간이 지남에 따라 축소된다.[6] 초기에는 넓은 근방에서 전역적인 자기 조직화가 일어나고, 근방이 축소되면 가중치는 로컬 추정치로 수렴한다.
이 과정은 각 입력 벡터에 대해 여러 번(λ) 반복된다. 네트워크는 결국 출력 노드를 입력 데이터 집합의 그룹 또는 패턴과 연결하며, 이러한 패턴에 이름을 붙일 수 있다.
매핑 과정에서 입력 벡터에 가장 가까운 가중치 벡터를 가진 단일 '승리' 뉴런이 존재하며, 이는 유클리드 거리 계산으로 결정된다.
자기조직화 지도는 벡터뿐만 아니라 디지털 표현, 적절한 거리 척도, 학습에 필요한 연산이 가능한 모든 종류의 개체에도 적용 가능하다. 알고리즘 요약:1. 맵에서 노드 가중치 벡터를 무작위로 초기화한다.
2. 에 대해 반복:
입력 벡터 를 무작위로 선택한다.
입력 벡터에 가장 가까운 노드(BMU, )를 찾는다.
각 노드 에 대해, 를 통해 가중치를 업데이트한다.
s를 증가시킨다.
주요 설계 선택: SOM의 형태, 이웃 함수, 학습률 스케줄 예시: 사각형 그리드, 이웃 함수