참조 횟수 계산 방식
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
참조 횟수 계산 방식은 객체에 대한 참조(포인터) 개수를 세어 메모리 관리 효율을 높이는 기법이다. 강한 참조와 약한 참조가 있으며, 객체마다 참조 카운트 값을 두어 참조가 변경될 때마다 갱신한다. 참조 카운트가 0이 되면 객체 파기가 허용된다.
이 방식은 메모리 즉시 회수, 구현 간편성, 비메모리 리소스 관리에 장점이 있지만, 순환 참조 시 메모리 누수, 오버헤드 발생 등의 단점도 존재한다. 이러한 단점을 보완하기 위해 컴파일러 최적화, 약한 참조, 추적 가비지 수집 등의 기술이 사용된다. 가중 참조 횟수 계산 방식은 분산 시스템에 적합하며, 간접 참조 횟수 계산 방식은 객체의 조기 폐기를 방지한다.
참조 횟수 계산 방식은 C++, Objective-C, Python, PHP, Perl 등 다양한 프로그래밍 언어에서 사용되며, 파일 시스템의 하드 링크, COM 객체 등에서도 활용된다.
더 읽어볼만한 페이지
- 자동 메모리 관리 - 쓰레기 수집 (컴퓨터 과학)
쓰레기 수집은 프로그램이 사용하지 않는 메모리 공간을 자동으로 회수하는 기술로, 수동 메모리 관리의 어려움을 줄여주며 다양한 알고리즘을 통해 성능을 최적화하고 자바, 닷넷 등 현대 언어에서 널리 쓰인다. - 자동 메모리 관리 - 통합과 집약
통합과 집약은 메모리 공간에서 사용 중인 영역과 빈 영역을 정리하여 시스템 효율성을 높이는 과정이지만, 단일 실패 지점, 확장성 문제, 보안 위험 등 여러 잠재적인 문제점을 야기할 수 있다. - 메모리 관리 - 동적 메모리 할당
동적 메모리 할당은 프로그램 실행 중 힙 영역에서 메모리 공간을 확보 및 해제하여 효율적인 메모리 관리와 유연성을 제공하는 기술로, 메모리 누수 방지 및 가비지 컬렉션 등의 고려 사항이 중요하며 C, C++, C++/CLI, C# 등에서 사용된다. - 메모리 관리 - 정적 변수
정적 변수는 프로그램 실행 시간 동안 값을 유지하며, C 언어에서 `static` 키워드로 정의되어 함수 호출 간에 값을 유지하고, 객체 지향 프로그래밍에서 클래스의 모든 인스턴스에서 공유되는 클래스 변수로 사용된다.
| 참조 횟수 계산 방식 | |
|---|---|
| 일반 정보 | |
 | |
| 유형 | 자동 메모리 관리 |
| 발명 시기 | 1960년 |
| 발명가 | 조지 이반스 |
| 작동 방식 | |
| 주요 원리 | 각 객체가 참조되는 횟수를 추적 횟수가 0이 되면 객체를 회수 |
| 장점 | 구현이 간단함 객체가 더 이상 필요하지 않게 되면 즉시 회수됨 |
| 단점 | 순환 참조 문제를 해결할 수 없음 객체에 대한 각 할당 및 할당 해제 작업 시 참조 횟수를 업데이트해야 하므로 성능 오버헤드가 발생함 스레드 환경에서는 참조 횟수를 안전하게 업데이트하기 위한 동기화가 필요함 |
| 구현 | |
| 구현 방법 | C++의 스마트 포인터 델파이 파이썬 PHP 스위프트 펄 러스트의 `Rc` 스마트 포인터 |
2. 방식
참조 횟수 계산 방식에는 강한 참조(strong reference)와 약한 참조가 있는데, 보통 참조 횟수 계산 방식을 이야기할 때는 강한 참조를 말하며, 약점으로 지적된 순환 참조 오류를 해소하기 위해 약한 참조를 사용하기도 한다. 모든 객체(메모리에 있는 데이터 단위)에 대해, 참조 카운트라고 불리는 정수값을 붙여 둔다. 이것은 이 객체에 대한 참조(또는 포인터)가 시스템 전체에 몇 개나 존재하는지를 세는 것이다. 객체에 대한 참조가 변할 때마다 이 값은 수시로 갱신된다. 참조 카운트가 0이 된 것은 파기가 허용된다. 단, 파일 캐시처럼 참조 카운트가 0이 되어도 즉시 객체를 파기하지 않고, 재이용에 대비하여 리소스 용량이 허락하는 한 보존해도 상관없다. 이 경우, 객체를 파기하기 위한 판단에는 다른 기준이 필요하다.
공유된 단일 객체에 대한 참조가 아닌, 독립적인 데이터를 의사적으로 표현하는 경우에는, 아래의 처리를 추가한다.
- 객체의 복사가 요구되어도, 실제로는 복사를 하지 않고 원래 객체에 대한 참조를 반환하고, 참조 카운트에 1을 더한다.
- 객체의 변경이 이루어지는 경우에는, 다음 순서로 수행한다.
- * 참조 카운트가 1이면 그대로 갱신한다.
- * 참조 카운트가 2 이상이면, 원래 객체를 복사하여 참조 카운트가 1인 새 객체를 생성하고, 그것을 갱신한다. 원래 객체의 참조 카운트는 1 감소시킨다.
2. 1. 구현 (C 코드 예시)
cstruct object
{
int ref;
};
struct object* object_new(void)
{
struct object* p=malloc(sizeof(struct object));
p->ref=1;
return p;
}
int object_ref(struct object* p)
{
return (p->ref++);
}
int object_unref(struct object* p)
{
if ((p->ref--)!=0)
return p->ref;
else
{
free(p);
return 0;
}
}
```
C 언어를 사용한 참조 횟수 계산 구현 예시이다.
3. 장점 및 단점
참조 횟수 계산 방식은 객체가 더 이상 필요하지 않게 되는 즉시 메모리를 회수할 수 있다는 장점이 있다. 이는 실시간 시스템이나 메모리가 제한된 환경에서 특히 유용하다. 또한, 추적 가비지 컬렉션보다 구현이 간단하고, 비메모리 리소스 관리에도 효과적이다. 가중 참조 횟수는 분산 시스템의 가비지 컬렉션에 좋은 솔루션이다.[2]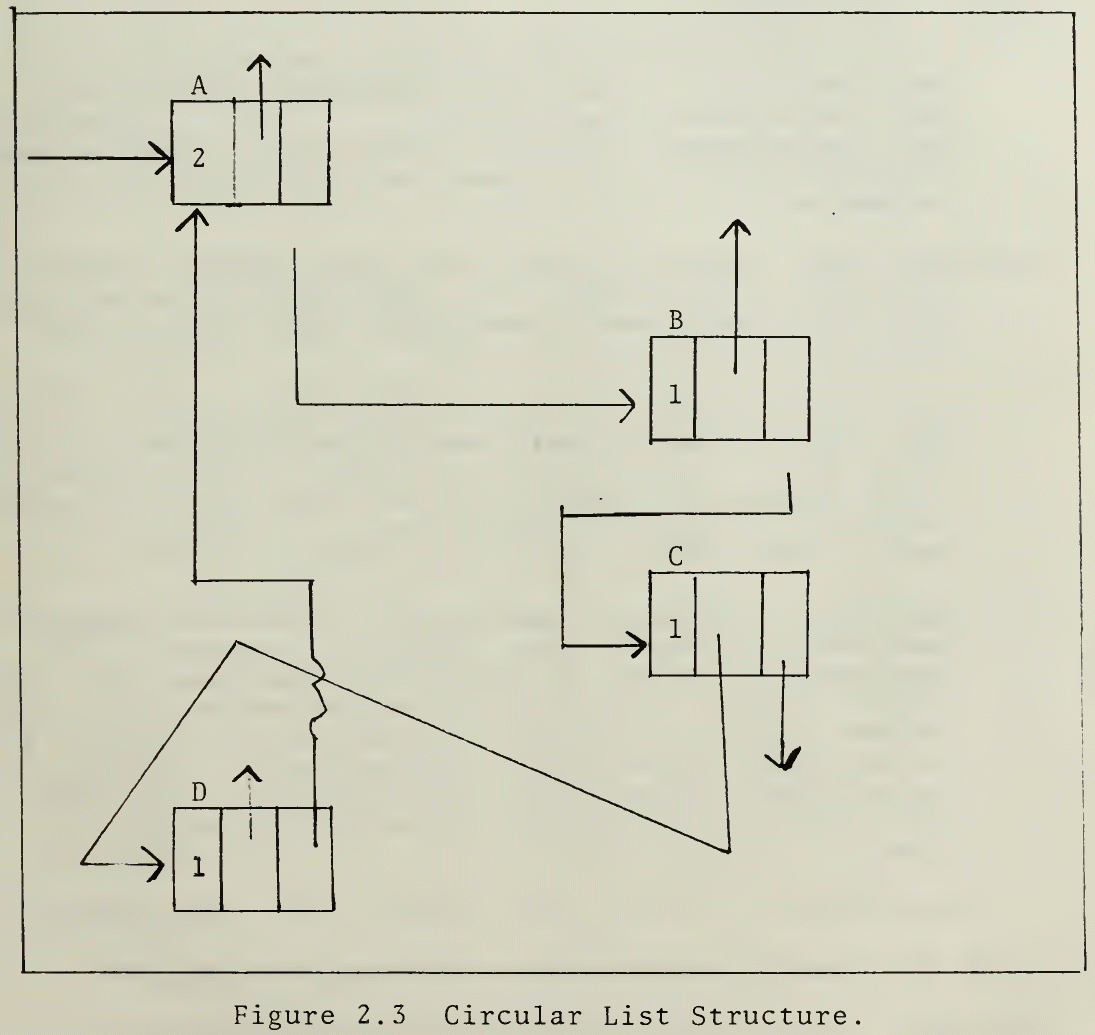
하지만, 참조 횟수 계산 방식에는 몇 가지 단점이 있다.
- 매번 참조할 때마다 참조 횟수를 검사해야 하므로, 많은 수의 단위 객체를 사용하는 경우 부하가 커진다.
- 객체들이 서로를 참조하는 순환 참조가 발생하면 메모리 누수가 발생할 수 있다. (순환 참조 오류 참조)
- 참조 횟수 관리 자체에 따른 오버헤드가 발생할 수 있다.
- 단순한 구현에서는 대량의 객체가 일제히 해제될 때 CPU 처리 속도가 느려질 수 있다. 특히 컨테이너 객체처럼 해제되는 객체가 많은 객체를 참조하고 있는 경우에 발생하기 쉽다.
- 대상 객체가 작고 복사가 빈번하게 이루어지는 경우, 참조 횟수의 공간적, 시간적 오버헤드가 문제가 될 수 있다.
- 멀티스레드 환경에서는 참조 횟수 증감이 스레드 세이프해야 하므로, 배타적 제어나 원자적 연산 등의 락 기구를 사용해야 하는데, 이는 상당한 오버헤드를 유발할 수 있다.[25]
이러한 단점을 극복하기 위해 다양한 기법들이 개발되었다.
- 컴파일러가 인접한 여러 참조 업데이트를 하나로 결합하여 오버헤드를 줄일 수 있다.
- Deutsch-Bobrow 방법은 지역 변수에 저장된 참조를 무시하고 데이터 구조의 참조만 계산하여 오버헤드를 줄인다.
- 헨리 베이커가 고안한 지연 증가는 지역 변수에 저장된 참조의 횟수 증가를 지연시켜 오버헤드를 줄인다.[4]
- 레바노니와 페트랭크의 업데이트 병합 방법은 중복된 참조 횟수 업데이트를 제거하여 오버헤드를 줄인다.[5][6]
- Blackburn과 McKinley의 이전 참조 횟수 계산 방법은 지연된 참조 횟수 계산과 복사 보육을 결합하여 오버헤드를 줄인다.[8]
- 약한 참조(위크 레퍼런스)를 사용하여 순환 참조 문제를 해결할 수 있다.[9]
- 주기적으로 추적 가비지 수집기를 사용하여 순환 참조를 회수할 수 있다.[10][11]
참조횟수는 또한 다른 런타임 최적화의 입력으로 사용할 유용한 정보 이기도 하다. 예를 들면, 많은 함수형 프로그래밍 언어와 같이 불변 객체에 크게 의존하는 시스템은 빈번한 복사로 인해 효율성 저하를 겪을 수있다. 그러나 컴파일러(또는 런타임 시스템)가 특정 객체가 하나의 참조만 가지고 있고(대부분의 시스템에서 그렇듯이) 해당 참조가 유사한 새 객체가 생성되는 동시에 손실된다는 것을 알고 있다면(문자열 추가 문 `str ← str + "a"`와 같이) 작업을 원본 객체에 대한 변형으로 바꿀 수 있다.
추적 가비지 컬렉션 주기는 사용 가능한 메모리의 대부분을 라이브 객체 세트가 채우는 경우 너무 자주 트리거됩니다; 효율성을 위해서는 추가 공간이 필요합니다. 참조 횟수 계산 성능은 총 여유 공간의 양이 감소해도 저하되지 않습니다.
단순한 형태의 참조 횟수 계산은 추적 가비지 컬렉션보다 세가지 주요 단점이 있으며, 둘다 완화하기 위해 추가 메커니즘이 필요하다.
- 관련 빈번한 업데이트는 비효율성의 원인입니다. 추적 가비지 컬렉터는 컨텍스트 전환 및 캐시 라인 오류를 통해 효율성에 심각한 영향을 미칠 수 있지만 비교적 드물게 수집하는 반면, 객체 액세스는 지속적으로 수행됩니다. 또한 덜 중요하지만 참조 횟수 계산은 메모리 관리 객체마다 참조 횟수를 위해 공간을 예약해야 합니다. 추적 가비지 컬렉터에서 이 정보는 해당 객체를 참조하는 참조에 암시적으로 저장되어 공간을 절약하지만, 특히 증분 가비지 컬렉터는 다른 목적으로 추가 공간이 필요할 수 있습니다.
- 위에서 설명한 단순 알고리즘은 직접 또는 간접적으로 자체를 참조하는 객체인 참조 순환을 처리할 수 없습니다. 순전히 참조 횟수에 의존하는 메커니즘은 참조 횟수가 0이 아닌 상태로 유지되도록 보장되므로 객체의 순환 체인을 삭제하는 것을 절대 고려하지 않습니다(그림 참조). 이 문제를 해결하는 방법이 있지만 참조 횟수 계산의 오버헤드와 복잡성을 증가시킬 수도 있습니다. 반면에 이러한 방법은 순환을 형성할 수 있는 데이터, 즉 모든 데이터의 작은 하위 집합에만 적용해야 합니다. 이러한 방법 중 하나는 약한 참조를 사용하는 것이고, 다른 방법은 드물게 호출되어 정리하는 마크-스윕 알고리즘을 사용하는 것입니다.
- 동시 설정에서 참조 횟수와 모든 포인터 수정의 모든 업데이트는 추가 비용이 발생하는 원자적 연산이어야 합니다. 원자성 요구 사항에는 세 가지 이유가 있습니다. 첫째, 참조 횟수 필드는 여러 스레드에서 업데이트될 수 있으므로 (비용이 많이 드는) 비교 및 교환과 같은 적절한 원자적 명령을 사용하여 횟수를 업데이트해야 합니다. 둘째, 참조 횟수를 적절하게 감소시키기 위해 참조를 잃는 객체를 명확히 해야 합니다. 그러나 여러 스레드가 동일한 참조를 수정하려고 시도하는 설정에서는 이 객체를 결정하는 것이 쉽지 않습니다(즉, 데이터 경합이 가능할 때). 마지막으로, 한 스레드가 객체에 대한 포인터를 얻었지만 객체의 참조 횟수를 증가시키기 전에 이 객체에 대한 다른 모든 참조가 다른 스레드에서 동시에 삭제되고 객체가 회수되어 해당 스레드가 회수된 객체의 참조 횟수를 증가시키는 미묘한 경합이 존재합니다.
이 외에도 메모리가 자유 목록에서 할당된 경우 참조 횟수 계산은 열악한 지역성을 겪습니다. 참조 횟수 계산만으로는 캐시 성능을 개선하기 위해 객체를 이동할 수 없으므로 고성능 컬렉터는 추적 가비지 컬렉터도 구현합니다. 대부분의 구현(PHP 및 Objective-C의 구현과 같은)은 객체를 복사하지 않으므로 열악한 캐시 성능을 겪습니다.
참조 횟수를 생성하거나 제거할 때마다 참조 횟수를 증가시키거나 감소시키는 것은 성능을 상당히 저하시킬 수 있습니다. 이러한 연산은 시간이 걸릴 뿐만 아니라 캐시 성능을 저하시키고 파이프라인 버블을 유발할 수 있습니다. 단순한 참조 횟수 계산으로는 목록의 길이를 계산하는 것과 같은 읽기 전용 연산조차도 참조 업데이트를 위해 많은 수의 읽기 및 쓰기를 필요로 합니다.
한가지 간단한 기술은 컴파일러가 인접한 여러 참조 업데이트를 하나로 결합하는 것입니다. 이것은 생성되어 빠르게 제거되는 참조에 특히 효과적입니다. 그러나 조기 해제를 방지하기 위해 결합된 업데이트를 적절한 위치에 배치하는 데 주의를 기울여야 합니다.
참조 횟수 계산의 Deutsch-Bobrow 방법은 대부분의 참조 횟수 업데이트가 실제로 지역 변수에 저장된 참조에 의해 생성된다는 사실을 이용합니다. 이러한 참조는 무시하고 데이터 구조의 참조만 계산하지만, 참조 횟수가 0인 객체를 삭제하기 전에 시스템은 스택과 레지스터를 스캔하여 다른 참조가 여전히 존재하지 않는지 확인해야 합니다.
Levanoni와 Petrank는 2001년에 이러한 업데이트 병합을 참조 횟수 계산 수집기에서 사용하는 방법을 보여주었습니다. 새로운 객체에 대한 적절한 처리를 통해 업데이트 병합을 사용하면 일반적인 Java 벤치마크의 경우 카운터 업데이트의 99% 이상이 제거됩니다.
흥미롭게도 업데이트 병합은 또한 동시 환경에서 포인터 업데이트 중에 원자 연산을 사용할 필요성을 제거하여 동시 환경에서 참조 횟수 계산 문제를 해결합니다. 따라서 업데이트 병합은 단순한 참조 횟수 계산의 세 번째 문제(즉, 동시 환경에서 비용이 많이 드는 오버헤드)를 해결합니다. Levanoni와 Petrank는 미세한 동기화만 사용하여 멀티 스레드 응용 프로그램과 동시에 실행될 수 있는 향상된 알고리즘을 제시했습니다.
Blackburn과 McKinley의 ''이전 참조 횟수 계산'' 방법은 지연된 참조 횟수 계산과 복사 보육을 결합하여 대부분의 포인터 변형이 젊은 객체에서 발생한다는 점을 관찰했습니다. 이 알고리즘은 참조 횟수 계산의 낮은 경계 지연 시간으로 가장 빠른 세대별 복사 수집기와 유사한 처리량을 달성합니다.
요약하자면, 참조 횟수 계산 방식은 장점과 단점을 모두 가지고 있으며, 특정 상황에 따라 적합한 가비지 컬렉션 방식을 선택하는 것이 중요하다. 특히, 실시간 시스템이나 메모리가 제한된 환경에서는 참조 횟수 계산 방식이 유용할 수 있지만, 순환 참조 문제와 오버헤드 문제를 고려해야 한다.
3. 1. 순환 참조 문제점
순환 참조는 두 개 이상의 객체가 서로를 참조하여 참조 횟수가 0이 되지 않아 메모리에서 해제되지 않는 현상이다.[26][27][28][29] 예를 들어 C++의 `std::shared_ptr`을 사용하여 자기 참조 또는 상호 참조를 하는 클래스를 정의하면, 참조 횟수가 줄어들지 않아 인스턴스가 해제되지 않는다.```cpp
#include
#include
class A {
public:
std::shared_ptr
A() {}
~A() {
std::cout << "Destructor of A is called." << std::endl;
}
};
class B {
public:
std::shared_ptr
B() {}
~B() {
std::cout << "Destructor of B is called." << std::endl;
}
};
void doTest() {
std::shared_ptr refA(new A());
std::shared_ptr refB(new B());
refA->m_refB = refB;
refB->m_refA = refA;
} // 여기서 A 및 B의 소멸자가 호출되지 않아 메모리 누수가 발생한다.
int main() {
doTest();
return 0;
}
```
자바(Java)에서는 참조 횟수 기반이 아닌 가비지 컬렉션 방식을 채택하고 있어 순환 참조에 의한 메모리 누수는 발생하지 않는다.[26][27] 다음 자바(Java) 코드는 합법이며, 순환 참조가 있더라도 가비지 컬렉션의 회수 대상이 된다.
```java
class A {
public B b;
}
class B {
public A a;
}
public class Test {
public static void doTest() {
A a = new A();
B b = new B();
a.b = b;
b.a = a;
} // 충분한 시간이 지나면, 언젠가 GC에 의해 회수된다.
public static void main(String[] args) {
doTest();
}
}
```
이러한 순환 참조 문제는 약한 참조(위크 레퍼런스, weak reference영어)를 사용하여 해결할 수 있다.[9] 약한 참조는 참조 횟수를 증가시키지 않는다. 코코아 프레임워크는 부모-자식 관계에는 "강한" 참조를, 자식-부모 관계에는 "약한" 참조를 사용하는 것을 권장한다.[9] C++에서는 `boost::weak_ptr` 또는 `std::weak_ptr` 등이 해당한다.
또한, 순환을 감지하고 해결하는 알고리즘을 통해 해결할수 있다. 주기적으로 추적 가비지 수집기를 사용하여 순환을 회수하는 방법이 있다.[10][11][5][6]
4. 다양한 해결 방법
순환 참조를 피하는 가장 확실한 방법은 시스템 설계 단계에서 순환이 발생하지 않도록 하는 것이다. 하드 링크를 사용하는 파일 시스템은 이러한 방식을 사용하며, 순환 참조를 명시적으로 금지한다. "약한"(계산되지 않는) 참조를 신중하게 사용하면 유지 순환을 피할 수 있다. 코코아 프레임워크는 부모-자식 관계에는 "강한" 참조를, 자식-부모 관계에는 "약한" 참조를 사용하는 것을 권장한다.[9]
시스템은 생성된 순환을 허용하거나 수정하도록 설계될 수도 있다. 개발자는 데이터 구조의 수명을 수동으로 추적하여 더 이상 필요하지 않은 참조를 명시적으로 "해체"하는 코드를 작성할 수 있다. 또는 "소유자" 객체를 생성하여 파괴될 때 해체를 자동화할 수 있다. 예를 들어, 그래프 객체의 소멸자는 GraphNode의 가장자리를 삭제하여 그래프의 참조 순환을 끊을 수 있다. 순환 데이터 구조를 최대한 피하는 방법론을 사용하여 시스템을 개발한 경우, 일반적으로 효율성을 희생하면서 수명이 짧고 순환 가비지가 적은 시스템에서는 순환을 무시할 수도 있다.
컴퓨터 과학자들은 데이터 구조 설계를 변경하지 않고도 참조 순환을 자동으로 감지하고 수집하는 방법을 개발했다. 한 가지 간단한 해결책은 주기적으로 추적 가비지 수집기를 사용하여 순환을 회수하는 것이다. 순환은 일반적으로 회수되는 공간의 비교적 적은 부분을 차지하므로, 수집기는 일반적인 추적 가비지 수집기보다 훨씬 덜 자주 실행할 수 있다.
Bacon은 추적 수집기와 유사한 이론적 시간 제한을 포함하는 참조 계수를 위한 순환 수집 알고리즘을 설명한다. 이 알고리즘은 순환이 참조 횟수가 0이 아닌 값으로 감소될 때만 격리될 수 있다는 점에 착안한다. 이러한 상황이 발생하면 해당 객체를 ''루트'' 목록에 추가하고, 주기적으로 프로그램은 루트에서 도달 가능한 객체를 검색하여 순환을 찾는다. 참조 순환의 모든 참조 횟수를 감소시켜 모두 0으로 만들면 수집할 수 있는 순환을 찾았음을 알 수 있다.[10] Paz 등이 개발한 이 알고리즘의 개선된 버전은[11] 다른 작업과 동시에 실행될 수 있으며, Levanoni와 Petrank의 업데이트 결합 방식을 사용하여 효율성을 향상시킨다.[5][6]
C++의 경우 Boost C++ 라이브러리나 C++11 이후 표준 C++ 라이브러리에서 제공하는 `boost::shared_ptr` 또는 `std::shared_ptr`와 같은 스마트 포인터를 사용하여 자기 참조 또는 상호 참조를 가지는 클래스를 정의하면, 참조 횟수가 적절하게 줄어들지 않아 서로의 인스턴스가 해제되지 않는 문제가 발생할 수 있다. 이러한 메모리 누수를 방지하기 위해 약한 참조(위크 레퍼런스, )를 사용한다. 예를 들어 C++에서는 boost::weak_ptr 또는 std::weak_ptr 등이 해당한다.
마크 앤 스위프나 복사 GC에 의한 가비지 컬렉션에서는 순환 참조에 의한 메모리 누수 문제가 발생하지 않는다. 자바(Java)나 .NET Framework에서는 모두 참조 횟수 기반이 아닌 가비지 컬렉션 방식을 채택하고 있어[26][27][28][29] 순환 참조에 의한 메모리 누수는 발생하지 않는다. 다만, 비의도적 객체 보존(unintentional object retention)으로 인한 메모리 누수를 방지하기 위해 와 같은 약한 참조 클래스의 인스턴스를 사용하기도 한다.[30]
4. 1. 가중 참조 횟수 계산 (Weighted Reference Counting)
가중 참조 횟수 계산 방식에서는 각 참조에 '가중치'가 할당되며, 각 객체는 자신을 참조하는 참조의 수를 추적하는 것이 아니라, 자신을 참조하는 참조의 총 가중치를 추적한다. 새로 생성된 객체에 대한 초기 참조는 216과 같이 큰 가중치를 갖는다. 이 참조가 복사될 때마다 가중치의 절반은 새 참조로 이동하고, 가중치의 절반은 이전 참조에 남아 있다. 총 가중치는 변경되지 않으므로 객체의 참조 횟수를 업데이트할 필요가 없다.참조를 삭제하면 해당 참조의 가중치만큼 총 가중치가 감소한다. 총 가중치가 0이 되면 모든 참조가 삭제된 것이다. 가중치가 1인 참조를 복사하려고 하면, 참조는 총 가중치에 더하고 이 새로운 가중치를 참조에 추가한 다음 분할하여 "더 많은 가중치를 얻어야" 한다. 이 경우 대안은 초기 참조가 분할될 수 있는 큰 가중치로 생성되는 ''간접 참조'' 객체를 만드는 것이다.
참조를 복사할 때 참조 횟수에 접근할 필요가 없는 속성은 객체의 참조 횟수에 접근하는 데 비용이 많이 드는 경우, 예를 들어 다른 프로세스, 디스크 또는 네트워크를 통해 접근해야 하는 경우에 특히 유용하다. 또한 참조 횟수를 증가시키기 위해 여러 스레드가 잠그는 것을 피함으로써 동시성을 높이는 데 도움이 될 수 있다. 따라서 가중 참조 횟수 계산 방식은 병렬, 다중 프로세스, 데이터베이스 또는 분산 응용 프로그램에서 가장 유용하다.
단순 가중 참조 횟수 계산 방식의 주요 문제는 참조를 삭제하는 데 여전히 참조 횟수에 접근해야 하며, 많은 참조가 삭제되면 피하려는 것과 동일한 병목 현상을 일으킬 수 있다는 것이다. 가중 참조 횟수 계산 방식의 일부 적응은 죽어가는 참조에서 활성 참조로 가중치를 전송하여 이를 방지하려고 한다.
가중 참조 횟수 계산 방식은 데이비드 비반과 Watson & Watson에 의해 1987년에 독립적으로 개발되었다.
4. 2. 간접 참조 횟수 계산 (Indirect Reference Counting)
간접 참조 횟수 계산 방식에서는 참조의 출처를 추적해야 한다. 이는 객체에 대한 두 개의 참조가 유지됨을 의미한다. 하나는 호출에 사용되는 직접 참조이고, 다른 하나는 다익스트라-숄튼 알고리즘과 같은 확산 트리의 일부를 형성하여 가비지 수집기가 죽은 객체를 식별할 수 있도록 하는 간접 참조이다. 이러한 접근 방식은 객체가 조기에 폐기되는 것을 방지한다.5. 대표적으로 사용하는 곳
- 구성요소 개체 방식(Component Object Model(COM))[14]
- 마이크로소프트의 IUnknown, ATL
- 스크립트 언어: 펄, 파이썬, 스퀴럴[14]
- C++ TR1, 부스트 라이브러리의 shared_ptr[14]
- GLib의 GObject, 아파치의 APR 라이브러리[14]
- 문자열 객체의 구현 수단
- 단순한 비트열 등의 데이터
- 마이크로소프트의 Component Object Model (COM)에서 COM 객체
- 프로그래밍 언어 Objective-C 및 Swift의 객체
- 프로그래밍 언어 Perl의 가비지 컬렉터
- 프로그래밍 언어 Python의 가비지 컬렉터[31][32]
- C++의 규격 C++11 이후의 `std::shared_ptr`
- Boost C++ 라이브러리의 `boost::shared_ptr` 및 `boost::shared_array`
- POCO C++ Libraries의 SharedPtr.
- GLib에 포함된 객체 시스템 ''GObject''
- 파일 시스템에서의 하드 링크
5. 1. 프로그래밍 언어
C++는 기본적으로 참조 횟수 계산을 하지 않지만, C++11부터 `std::shared_ptr`를 통해 참조 횟수 기반 스마트 포인터를 제공하여 동적으로 할당된 객체의 자동 공유 메모리 관리를 지원한다. 프로그래머는 약한 포인터 (`std::weak_ptr`)를 사용하여 순환 종속성을 끊을 수 있다. 또한, C++11의 이동 의미론은 객체 포인터 복사만으로 딥 복사를 줄여 참조 횟수 수정 범위를 줄여준다. Boost C++ 라이브러리의 `boost::shared_ptr` 및 `boost::shared_array`도 참조 횟수 관리 기능을 제공한다.[33][34]Objective-C와 Swift는 자동 참조 카운팅(ARC) 기능을 통해 참조 횟수 계산을 사용한다.[15][16] Objective-C는 전통적으로 프로그래머가 `retain` 및 `release` 메시지를 통해 수동으로 참조 횟수를 관리했지만, ARC를 통해 컴파일러가 자동으로 메시지를 삽입한다. 애플의 코코아 및 코코아 터치 프레임워크에서 널리 사용된다.
Python은 기본적인 메모리 관리 방식으로 참조 횟수 계산을 사용하며, 순환 참조 탐지 기능도 제공한다.[21] PHP는 내부 변수 관리에 참조 횟수 계산 방식을 사용하며, PHP 5.3부터는 순환 참조 해결 알고리즘도 구현했다.[20] Perl 역시 참조 횟수 계산 방식을 사용하며, 약한 참조를 통해 순환 참조 생성을 방지한다.
델파이는 문자열, 동적 배열 등 내장 형식에 대해 참조 횟수를 사용한다. GObject 객체 지향 프로그래밍 프레임워크는 약한 참조를 포함하여 기본 유형에 대한 참조 횟수를 구현한다. Vala 프로그래밍 언어는 GObject 참조 횟수를 기본 가비지 수집 시스템으로 사용한다.[19] Rust는 `Rc` 및 `Arc` 타입을 통해 참조 횟수 계산 기능을 제공한다.[22] 스쿼럴은 순환 참조 감지 기능을 갖춘 참조 횟수 계산 방식을 사용한다. Tcl 8은 값의 메모리 관리를 위해 참조 횟수를 사용하며, 값은 변경 불가능하여 순환 참조가 발생하지 않는다. Xojo 역시 참조 횟수를 사용하며, 약한 참조를 통해 순환 참조를 방지한다.
5. 2. 파일 시스템
파일 시스템은 파일 또는 디스크 블록의 참조 횟수를 관리하는 데 참조 횟수 계산 방식을 사용한다. 예를 들어, 유닉스 파일 시스템의 inode ''링크 수''는 하드 링크로 알려져 있으며, 이 횟수가 0이 되면 해당 파일을 안전하게 해제할 수 있다. 일부 유닉스 계열 운영체제에서는 디렉터리뿐만 아니라 실행 중인 프로세스도 파일에 대한 참조 횟수를 가질 수 있다. 파일 시스템에서 파일이 삭제되었더라도 프로세스가 해당 파일을 열고 있으면 참조 횟수가 0이 아니므로 파일은 해제되지 않으며, 해당 파일을 열고 있는 모든 프로세스가 파일을 닫으면 디스크에서 해제된다.5. 3. 기타
마이크로소프트의 컴포넌트 오브젝트 모델(COM) 객체는 참조 횟수 계산 방식으로 관리된다. COM은 서로 다른 프로그래밍 언어 및 런타임 시스템 간의 상호 운용성을 가능하게 하기 위해 참조 횟수 계산 방식을 사용한다. 윈도우 셸의 상당 부분과 마이크로소프트 인터넷 익스플로러, 마이크로소프트 오피스와 같은 많은 윈도우 응용 프로그램들이 COM을 기반으로 구축되어 있다.펄, 파이썬, 스퀴럴과 같은 스크립팅 언어와 C++ TR1, 부스트 라이브러리의 shared_ptr, GLib의 GObject, 아파치 웹 서버의 APR 라이브러리 등 다양한 환경에서 참조 횟수 계산 방식이 사용된다.
6. 한국의 관점
참조
[1]
학위논문
The Feasibility of Automatic Storage Reclamation with Concurrent Program Execution in a LISP Environment
https://commons.wiki[...]
1985-12
[2]
학회자료
Uniprocessor Garbage Collection Techniques
ftp://ftp.cs.utexas.[...]
Springer-Verlag
[3]
학회자료
Taking Off the Gloves with Reference Counting Immix
http://research.micr[...]
[4]
학술지
Minimizing Reference Count Updating with Deferred and Anchored Pointers for Functional Data Structures
1994-09
[5]
학회자료
An on-the-fly reference-counting garbage collector for java
https://www.cs.techn[...]
[6]
학술지
An on-the-fly reference-counting garbage collector for java
https://www.cs.techn[...]
[7]
웹사이트
An On-the-Fly Reference-Counting Garbage Collector for Java
https://www.cs.techn[...]
2017-06-24
[8]
학회자료
Ulterior Reference Counting: Fast Garbage Collection without a Long Wait
http://www.cs.utexas[...]
[9]
웹사이트
Mac Developer Library
https://developer.ap[...]
Developer.apple.com
2015-12-17
[10]
서적
ECOOP 2001 — Object-Oriented Programming
[11]
학술지
An efficient on-the-fly cycle collection
[12]
학회자료
Distributed garbage collection using reference counting
Springer-Verlag
[13]
학회자료
An efficient garbage collection scheme for parallel computer architectures
Springer-Verlag
[14]
학술지
A Study on Garbage Collection Algorithms for Big Data Environments
[15]
웹사이트
https://web.archive.[...]
2011-06-09
[16]
웹사이트
Mac Developer Library
https://developer.ap[...]
Developer.apple.com
2015-12-17
[17]
웹사이트
OS X 10.8 Mountain Lion: the Ars Technica review
https://arstechnica.[...]
2012-07-25
[18]
웹사이트
Xcode 8 Release Notes
https://developer.ap[...]
2016-10-27
[19]
웹사이트
Projects/Vala/ReferenceHandling - GNOME Wiki!
https://wiki.gnome.o[...]
GNOME
2015-05-25
[20]
웹사이트
PHP: Reference Counting Basics - Manual
https://www.php.net/[...]
[21]
웹사이트
1. Extending Python with C or C++ — Python 2.7.11 documentation
https://docs.python.[...]
Docs.python.org
2015-12-05
[22]
웹사이트
std::rc - Rust
https://doc.rust-lan[...]
[23]
웹사이트
The Rust Reference
https://doc.rust-lan[...]
2022-07-21
[24]
웹사이트
Documentation
https://docs.swift.o[...]
[25]
뉴스
Improving .NET Performance by Reducing Memory Usage - InfoQ
https://www.infoq.co[...]
[26]
웹사이트
Javaの理論と実践: ガベージコレクションとパフォーマンス | IBM
https://web.archive.[...]
[27]
웹사이트
Javaの理論と実践: ガーベッジ・コレクション小史 | IBM
https://web.archive.[...]
[28]
웹사이트
Resource management | Microsoft Docs | Blog Archive | Brad Abrams
https://docs.microso[...]
[29]
웹사이트
.NETアプリを軽快にするためのガベージ・コレクション講座(2/4) - @IT
https://www.atmarkit[...]
[30]
웹사이트
Javaの理論と実践: 弱参照でメモリー・リークを塞ぐ | IBM
https://web.archive.[...]
[31]
웹사이트
29.11. gc — ガベージコレクタインターフェース — Python 3.6.5 ドキュメント
https://docs.python.[...]
[32]
웹사이트
Garbage Collection for Python
http://arctrix.com/n[...]
[33]
웹사이트
Version 1.53.0
https://www.boost.or[...]
[34]
웹사이트
Boost.SmartPtr: The Smart Pointer Library
https://www.boost.or[...]
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com