퇴각검색
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
퇴각검색은 해를 찾기 위해 가능한 모든 후보를 탐색하는 알고리즘으로, 후보는 트리 구조로 표현된다. 이 알고리즘은 깊이 우선 탐색 방식을 사용하며, 유효하지 않은 후보는 가지치기하여 탐색 시간을 단축한다. 퇴각검색은 조합 탐색과 관련이 있으며, 주어진 문제에 대한 모든 가능한 해를 제공하기 위해 부분 후보 집합을 열거한다. 이 알고리즘은 재귀 함수로 구현되며, 각 노드에서 유효한 해로 완성될 수 있는지 확인하고, 그렇지 않으면 해당 노드를 루트로 하는 하위 트리를 건너뛴다. 퇴각검색은 제약 충족 문제, 조합 최적화 문제, 퍼즐, 구문 분석 등 다양한 분야에 적용된다.
백트래킹은 해를 찾기 위해 모든 가능한 후보군을 탐색하며, 후보군은 트리 구조로 표현된다. 각 후보군은 점진적으로 확장되며, 유효하지 않은 후보군은 가지치기하여 탐색 시간을 단축한다. 이러한 탐색은 일반적으로 깊이 우선 탐색(DFS) 방식으로 이루어진다.
퇴각검색은 주로 재귀 함수를 사용하여 구현한다. 재귀 함수는 현재 시점에서 적용 가능한 변수값들을 파악하고, 이를 통해 문제를 해결해 나간다. 퇴각검색은 깊이 우선 탐색과 유사하지만, 현재 상태를 유지하고 갱신하는 데 필요한 공간만 차지하므로 메모리 사용량이 적다는 장점이 있다.
처리 속도를 높이기 위해 몇 가지 휴리스틱이 사용된다. 변수는 어떤 순서로도 처리할 수 있으므로, 가장 한정된 조건을 먼저 시도하는 것(예를 들어 선택 사항이 적은 것)이 효율적이다. 이런 가지치기는 탐색 트리를 작게 한다 (최소의 비용으로 최대의 결과를 얻는다).
퇴각검색은 플래너나 프롤로그 같은 프로그래밍 언어를 구현하는 데 쓰인다. 혹은 구문 분석 분야에도 적용된다. 행위자 모델 개발에 주로 쓰이는 인공지능에 퇴각검색을 적용하려는 토론이 있었다.
Constraint Satisfaction Problem영어(제약 충족 문제)는 주어진 제약 조건을 만족하는 변수 값의 목록을 찾는 문제이다. 각 변수는 특정 범위 내의 값을 가져야 하며, 이러한 값들이 주어진 모든 제약 조건을 만족해야 한다.
2. 설명
주요 개념은 해를 얻을 때까지 모든 가능성을 시도한다는 점이다. 모든 가능성은 트리처럼 구성할 수 있으며, 가지 중에 해결책이 있다. 트리를 검사하기 위해 깊이 우선 탐색을 사용한다. 탐색 중에 오답을 만나면 이전 분기점으로 돌아간다. 시도해보지 않은 다른 해결 방법이 있으면 시도한다. 해결 방법이 더 없으면 더 이전의 분기점으로 돌아간다. 모든 트리의 노드를 검사해도 답을 못 찾을 경우, 이 문제의 해결책은 없는 것이다.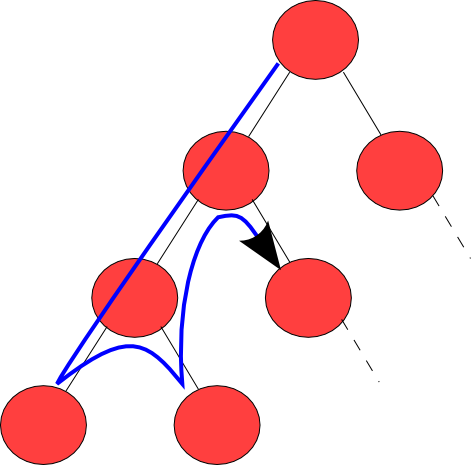
개념적으로, 부분 후보는 트리 구조의 노드로 표현되며, 이를 '잠재적 검색 트리'라고 한다. 각 부분 후보는 단일 확장 단계로 부분 후보와 다른 후보의 부모 노드이며, 트리의 잎은 더 이상 확장할 수 없는 부분 후보이다.
퇴각검색 알고리즘은 이 검색 트리를 재귀적으로, 루트에서 아래로, 깊이 우선 순서로 순회한다. 각 노드 ''c''에서 알고리즘은 ''c''가 유효한 해로 완성될 수 있는지 확인한다. 만약 그렇지 않다면, ''c''를 루트로 하는 전체 하위 트리는 건너뛴다(''가지치기''). 그렇지 않으면, 알고리즘은 (1) ''c'' 자체가 유효한 해인지 확인하고, 그렇다면 사용자에게 보고하고, (2) ''c''의 모든 하위 트리를 재귀적으로 열거한다. 각 노드의 두 가지 테스트와 자식은 사용자가 제공한 절차에 의해 정의된다.
따라서 알고리즘이 순회하는 '실제 검색 트리'는 잠재적 트리의 일부일 뿐이다. 알고리즘의 총 비용은 실제 트리의 노드 수에 각 노드를 얻고 처리하는 비용을 곱한 것이다. 잠재적 검색 트리를 선택하고 가지치기 테스트를 구현할 때 이 사실을 고려해야 한다.
퇴각검색은 보통 재귀 함수로 구현된다. 재귀로 파생된 해결 방법은 하나 이상의 변수가 필요한데, 이것은 현재 시점에서 적용할 수 있는 변수값들을 알고 있다. 퇴각검색은 깊이 우선 탐색과 대략 같으나 기억 공간은 덜 차지한다. 현재의 상태를 보관하고 바꾸는 동안만 차지한다.
탐색 속도를 높이기 위해, 재귀 호출을 하기 전에 시도할 값을 정하고 조건(전진 탐색의 경우)을 벗어난 값을 지우는 알고리즘을 적용할 수 있다. 아니면 그 값을 제외한 다른 값들을 탐색할 수도 있다.
3. 구현
탐색 속도를 높이기 위해, 재귀 호출 전에 시도할 값을 정하고 조건을 벗어난 값을 제거하는 알고리즘(전진 탐색)을 적용할 수 있다. 또는 그 값을 제외한 다른 값들을 탐색하는 방법을 사용할 수도 있다. 이러한 기법은 0/1 배낭 문제나 N 퀸 문제와 같이 복잡한 문제를 해결하는 데 매우 효율적이며, 동적 계획법보다 더 나은 결과를 얻을 수 있다.
3. 1. 의사 코드
'''절차''' backtrack(P, c) '''는'''
'''만약''' reject(P, c) '''이면''' return
'''만약''' accept(P, c) '''이면''' output(P, c)
s ← first(P, c)
'''동안''' s ≠ NULL '''을''' '''do'''
backtrack(P, s)
s ← next(P, s)
3. 2. 고려 사항
`reject` 절차는 `c`의 확장이 유효한 해결책이 아님이 확실한 경우에만 `true`를 반환해야 한다. 만약 확실하지 않다면 `false`를 반환해야 하는데, 잘못된 `true` 반환은 일부 유효한 해결책을 놓치게 할 수 있기 때문이다.[1] 이 절차는 검색 트리에서 `c`의 모든 조상 `t`에 대해 `reject`(`P`,`t`)가 `false`를 반환했다고 가정할 수 있다.[1]
`accept` 절차는 `c`가 완전하고 유효한 해결책인 경우 `true`를 반환하고, 그렇지 않으면 `false`를 반환해야 한다. 부분 후보 `c`와 트리의 모든 조상이 `reject` 테스트를 통과했다고 가정할 수 있다.[1]
`first` 및 `next` 절차는 부분 후보 집합과 잠재적 검색 트리를 정의한다. 이 함수들은 모든 해결책이 트리에 나타나고 중복되지 않도록 선택해야 하며, 효율적인 `reject` 술어를 허용해야 한다.[1]
알고리즘은 첫 번째 해를 찾거나, 지정된 수의 해를 찾거나, 지정된 CPU 시간을 사용한 후에 중단하도록 수정할 수 있다.[1]
4. 휴리스틱
값을 설정할 때, 많은 구현에서는 다른 값을 최대한 제한하지 않는 값을 선택한다. 이러한 선택은 a) 해를 발견할 가능성이 높고, b) 미해결 제약이 없어졌을 때 해가 발견된다는 점에서 유리하다.[1]
복잡한 퇴각검색 구현에서는 종종 경계값 검사 함수를 사용한다. 이 함수는 현재의 부분 해답으로 답을 얻을 수 있는지 확인한다. 그러나 부분적인 해답이 있는지 확인하는 경계값 검사는 때때로 모든 조건에 대한 연산 비용을 최소화해야 하는데, 그렇지 못하면 알고리즘의 효율성이 향상되지 않으므로, 더 나은 탐색 방법이 아닐 수 있다. 효율적인 경계 검사 함수는 다른 휴리스틱 함수를 만드는 것과 같이 문제의 규칙(제약) 일부를 완화하여 만든다.[1]
5. 적용
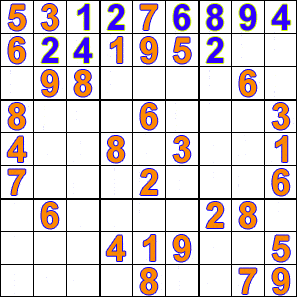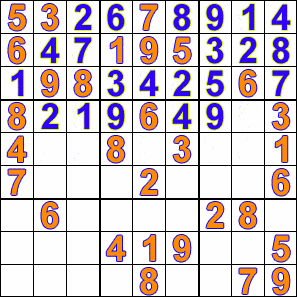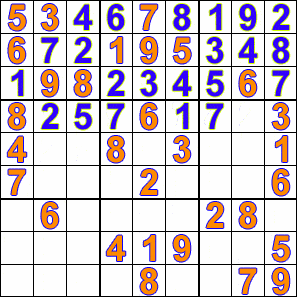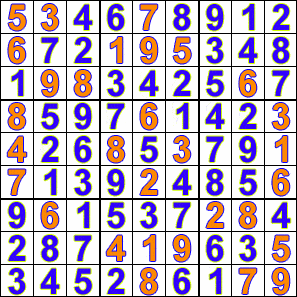
백트래킹을 사용하여 퍼즐 또는 문제를 해결할 수 있는 예시는 다음과 같다.종류 예시 퍼즐 8 퀸 문제, 십자말 풀이, 문자 산술, 스도쿠, 페그 솔리테어 등 조합 최적화 문제 구문 분석 및 배낭 문제 등 목표 지향 프로그래밍 언어 아이콘, 플래너 및 프롤로그와 같은 목표 지향 프로그래밍 언어는 답을 생성하기 위해 내부적으로 백트래킹을 사용 부울 만족 문제 DPLL 알고리즘
다음은 백트래킹이 제약 충족 문제에 사용되는 예시이다.
제약 충족 문제는 완전한 해가 존재하는 문제이며, 요소의 순서는 문제가 되지 않는다. 일련의 변수가 주어지면 지정된 제약을 만족하도록 그 값들을 설정해야 한다. 백트래킹에서는 변수 값의 조합을 시행착오를 통해 해를 찾는다. 백트래킹의 효과는 부분적 조합을 배제하는 구현에 있으며, 이를 통해 실행 시간을 단축한다.
백트래킹은 조합 최적화와 밀접하게 관련되어 있다.
백트래킹의 가장 광범위한 이용법으로는, 정규 표현식의 실행이 있다. 예를 들어, "a*a" 라는 단순한 패턴은 백트래킹을 하지 않을 경우 "a"에 매치되지 않는다 (첫 번째 패스에서 "a"가 "a*"에 흡수되어 버리고, 후속의 "a"에는 매치시킬 문자열이 남지 않기 때문이다).
백트래킹은 프로그래밍 언어의 구현에도 사용되고 있으며 (Planner 나 Prolog), 구문 분석 등에도 이용된다. 이러한 이용은 인공 지능 분야에서 논의되었고, 액터 모델의 개발로 이어졌다.
6. 제약 충족 문제 (Constraint Satisfaction Problem)
이러한 문제 해결에는 퇴각검색이 사용될 수 있다. 퇴각검색은 가능한 모든 조합을 시도하여 해를 찾는데, 이 과정에서 많은 부분 조합을 배제하여 풀이 시간을 단축시킨다.
일반적인 제약 충족 문제는 다음과 같이 구성된다.
이 문제에서 인스턴스 데이터 ''P''는 정수 ''m''과 ''n'', 그리고 술어 ''F''로 구성된다. 부분 후보는 처음 ''k''개의 변수 $x[1], x[2], \dots, x[k]$에 할당될 정수 목록 $c = (c[1], c[2], \dots, c[k])$로 정의할 수 있다. 루트 후보는 빈 목록()이다.
''first''와 ''next'' 함수는 다음과 같이 정의된다.
'''function''' first(P, c) '''is'''
:k ← length(c)
:'''if''' k = n '''then'''
::'''return''' NULL
:'''else'''
::'''return''' (c[1], c[2], ..., c[k], 1)
'''function''' next(P, s) '''is'''
:k ← length(s)
:'''if''' s[k] = m '''then'''
::'''return''' NULL
:'''else'''
::'''return''' (s[1], s[2], ..., s[k − 1], 1 + s[k])
여기서 ''length''(''c'')는 목록 ''c''의 요소 수이다.
''reject''(''P'', ''c'') 함수는 ''F'' 제약 조건이 ''c''의 ''k''개 요소로 시작하는 ''n''개의 정수 목록에 의해 만족될 수 없는 경우 ''true''를 반환한다. ''accept''(''P'', ''c'') 함수는 ''c''가 완료되었는지, 즉 ''n''개의 요소를 가지고 있는지 확인한다.
퇴각검색의 효율성을 높이기 위해 다음과 같은 방법을 사용할 수 있다.
퇴각검색은 제약 프로그래밍 언어에서 유용하게 사용될 수 있으며, Planner나 Prolog와 같은 언어에서 간단한 깊이 우선 탐색을 통해 구현될 수 있다.
참조
[1]
웹사이트
CIS 680: DATA STRUCTURES: Chapter 19: Backtracking Algorithms
http://www.cse.ohio-[...]
[2]
서적
Handbook of Satisfiability
https://books.google[...]
IOS Press
2009-01-29
[3]
서적
A Practical Approach to Compiler Construction
https://books.google[...]
Springer
2017-03-22
[4]
서적
Handbook of Constraint Programming
https://books.google[...]
Elsevier
2008-12-30
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com