데이터 랭글링
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
데이터 랭글링은 데이터를 분석에 적합하도록 변환하는 과정을 의미한다. 이는 미국 의회 도서관의 국가 디지털 정보 인프라 및 보존 프로그램에서 유래되었으며, 데이터 마이닝과 밀접한 관련이 있다. 데이터 랭글링은 데이터 발견, 구조화, 정리, 강화, 유효성 검사, 게시 등의 단계를 거치며, 데이터 분석 시간을 단축하고 정확한 결과를 도출하여 의사 결정을 돕는 이점이 있다. 데이터 랭글링은 스프레드시트, 스크립트, 시각적 데이터 랭글링 시스템 등을 통해 수행될 수 있으며, 데이터 프랜차이징, 데이터 준비, 데이터 멍깅 등과 같은 다른 용어로도 불린다.
더 읽어볼만한 페이지
- 데이터 매핑 - 객체 관계 매핑
객체 관계 매핑(ORM)은 객체 지향 프로그래밍에서 객체와 관계형 데이터베이스 간의 데이터 매핑을 위한 프로그래밍 기법이며, 개발 생산성 향상에 기여하지만 성능 저하 및 데이터베이스 설계 문제의 원인이 되기도 한다. - 데이터 매핑 - 데이터 접근 계층
- 컴퓨터 관련 직업 - 웹마스터
웹마스터는 웹사이트 관련 업무를 총괄하는 사람으로, 초기에는 시스템 관리자를 의미했으나 웹 기술 발전과 함께 웹사이트 관리, 개발, 콘텐츠 관리, 마케팅 등 광범위한 업무를 수행하는 사람 또는 회사를 포괄하며, 웹사이트 관리자를 위한 공식 연락 창구로도 활용된다. - 컴퓨터 관련 직업 - 소프트웨어 개발자
| 데이터 랭글링 | |
|---|---|
| 데이터 랭글링 | |
 | |
| 개요 | |
| 정의 | 데이터 랭글링(때로는 데이터 먼징이라고도 함)은 한 형식에서 다른 형식으로 데이터를 변환하여 더 가치 있게 만들고 분석하기 쉽게 만드는 프로세스임 |
| 목적 | 데이터 랭글링의 목표는 데이터를 개선하고 품질을 높이는 것임 데이터 랭글링은 데이터 과학에서 초기 단계로, 분석을 위해 데이터를 조직하는 데 중요한 역할 수행 |
| 특징 | |
| 프로세스 | 데이터 랭글링은 일반적으로 데이터를 추출, 정렬, 정리, 보강, 유효성 검사, 통계 분석 및 제시하는 과정을 포함 데이터 랭글링은 데이터 과학, 데이터 분석, 비즈니스 인텔리전스 분야에서 널리 사용됨 |
| 기술 | 데이터 랭글링에는 병합, 시각화, 필터링, 데이터 모델링, 데이터 통합 등 다양한 기술이 포함됨 데이터 랭글링은 수동으로 수행할 수도 있지만, 자동화 도구를 사용하여 더 효율적으로 수행할 수도 있음 |
| 기법 | |
| 데이터 검색 | 다양한 소스에서 데이터를 식별하고 검색하는 단계임 |
| 데이터 구조화 | 데이터가 구조화되지 않았거나 잘못 구조화된 경우, 행과 열로 구성된 테이블 형식으로 변환하는 단계임 |
| 데이터 정리 | 불완전하거나 부정확하거나 관련 없는 데이터를 수정하거나 제거하는 단계임. 여기에는 누락된 값 처리, 중복 제거, 오류 수정 등이 포함될 수 있음 |
| 데이터 보강 | 데이터 세트를 더욱 풍부하고 유용하게 만들기 위해 추가 데이터를 통합하는 단계임 |
| 데이터 유효성 검사 | 데이터 품질과 일관성을 보장하기 위해 유효성 검사 규칙과 제약 조건을 적용하는 단계임 |
| 데이터 게시 | 랭글링된 데이터를 사용자가 액세스하고 사용할 수 있도록 적절한 형식으로 게시하는 단계임 |
| 도구 | |
| 일반 프로그래밍 언어 | 파이썬 (pandas 라이브러리) R Perl |
| SQL 쿼리 언어 | SQL |
| 스프레드시트 | 마이크로소프트 엑셀 |
| 상업 소프트웨어 | Trifacta Wrangler Paxata OpenRefine Dataiku Data Science Studio Alteryx |
| 관련 주제 | |
| 관련 주제 | 데이터 품질 데이터 마이닝 ETL 데이터 통합 데이터 거버넌스 |
2. 배경
'랭글러(wrangler)'라는 용어는 미국 의회 도서관의 국가 디지털 정보 인프라 및 보존 프로그램(NDIIPP)과 에모리 대학교 도서관의 MetaArchive 파트너십에서 유래되었다고 한다.[2] '멍(mung)'은 Jargon File에 설명된 멍잉에서 비롯되었다.[2]
데이터 랭글링은 데이터 마이닝의 상위 집합이며, 데이터 마이닝에서 사용하는 프로세스를 필요로 하지만 항상 그런 것은 아니다. 데이터 마이닝은 대규모 데이터 세트 내에서 패턴을 찾는 과정이며, 데이터 랭글링은 해당 데이터에 대한 통찰력을 제공하기 위해 데이터를 변환한다. 데이터 랭글링이 데이터 마이닝의 상위 집합이라고 해서 데이터 마이닝이 이를 사용하지 않는다는 의미는 아니며, 데이터 마이닝에서 데이터 랭글링을 사용하는 사례는 많다. 데이터 랭글링은 전체 세트에 도움이 되지 않거나, 제대로 형식화되지 않은 데이터를 제거함으로써 데이터 마이닝에 도움이 될 수 있으며, 이는 전체 데이터 마이닝 프로세스에 더 나은 결과를 제공한다.
데이터 랭글링은 데이터 분석 시간을 단축하고, 더 정확한 결과를 도출하여 더 나은 의사 결정을 가능하게 한다. 메타데이터의 일관성을 보장하여 데이터 분석의 신뢰성을 높인다.[1]
데이터 랭글링이 과학적 맥락에서 처음 언급된 사례 중 하나는 NASA/NOAA Cold Lands Processes Experiment에서 도널드 클라인에 의해서였다.[4] 클라인은 데이터 랭글러의 역할을 "실험 데이터 전체 수집의 획득을 조정"하는 것으로 정의했다.
3. 데이터 마이닝과의 관계
데이터 랭글링과 밀접하게 관련된 데이터 마이닝의 예로는 목표와 관련이 없는 세트의 데이터를 무시하는 것이 있다. 예를 들어, 텍사스 주와 관련된 데이터 세트가 있고, 휴스턴 거주자에 대한 통계를 얻는 것이 목표라면, 댈러스 거주자와 관련된 데이터는 전체 세트에 유용하지 않으므로, 데이터 마이닝 프로세스의 효율성을 높이기 위해 처리 전에 제거할 수 있다.
4. 이점
5. 핵심 단계
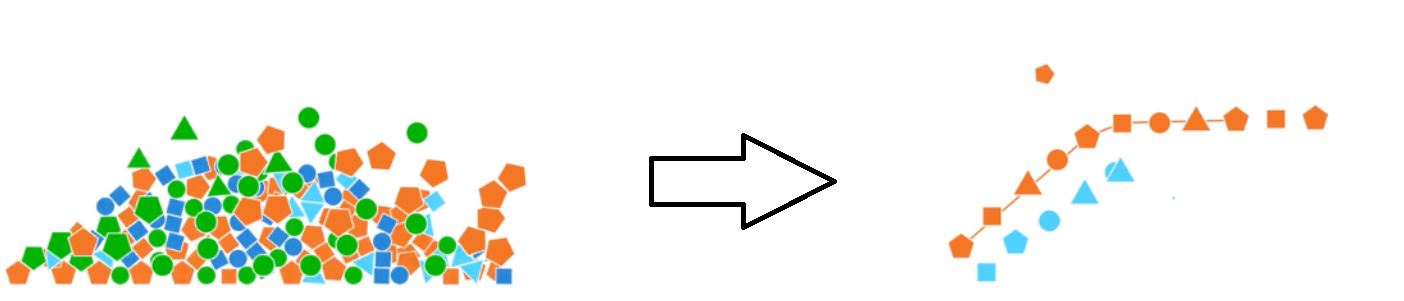
데이터 랭글링은 다음과 같은 주요 단계로 구성된다.
# '''데이터 발견:''' 데이터를 이해하고 익숙해지는 첫 번째 단계이다.
# '''구조화:''' 원시 데이터를 정리하여 이후 단계에서 계산과 분석이 용이하도록 하는 단계이다.
# '''정리:''' 날짜 형식 통일, 이상치 제거, 결측값 처리 등을 통해 데이터의 품질을 높이는 단계이다.
# '''강화:''' 추가 데이터가 데이터 세트에 도움이 되는지 판단하는 단계이다.
# '''유효성 검사:''' 유효성 검사 규칙을 반복 적용하여 데이터 일관성, 품질, 보안을 확보하는 단계이다.
# '''게시:''' 사용자나 소프트웨어가 사용할 수 있도록 데이터 세트를 준비하고, 랭글링 과정과 논리를 문서화하는 단계이다.
이러한 단계는 분석에 사용할 수 있는 깨끗하고 사용 가능한 데이터 세트를 만들기 위한 반복적인 과정이다. 이 과정은 지루할 수 있지만, 분석가가 읽을 수 없는 대량의 데이터 세트에서 필요한 정보를 얻을 수 있도록 해주기 때문에 중요하다.
데이터 랭글링의 예시는 다음과 같다.이름 전화 생년월일 주 John, Smith 445-881-4478 1989년 8월 12일 Maine Jennifer Tal +1-189-456-4513 1965년 11월 12일 Tx Gates, Bill (876)546-8165 1972년 6월 15일 Kansas Alan Fitch 5493156648 1985년 2월 6일 Oh Jacob Alan 156-4896 1월 3일 Alabama 데이터 랭글링 후 John Smith 445-881-4478 1989-08-12 Maine Jennifer Tal 189-456-4513 1965-11-12 Texas Bill Gates 876-546-8165 1972-06-15 Kansas Alan Fitch 549-315-6648 1985-02-06 Ohio
5. 1. 데이터 발견
"랭글러"(wrangler)라는 비기술적 용어는 미국 의회 도서관의 국가 디지털 정보 인프라 및 보존 프로그램(NDIIPP)과 에모리 대학교 도서관 기반 MetaArchive 파트너십의 작업에서 유래되었다고 한다. "멍"(mung)이라는 용어는 Jargon File에 설명된 멍잉에서 유래되었다.[2] "데이터 랭글러"라는 용어는 데이터를 다루는 사람을 설명하는 가장 적절한 비유로 제시되기도 했다.[3]
데이터 랭글링이 과학적 맥락에서 처음 언급된 사례 중 하나는 NASA/NOAA Cold Lands Processes Experiment 동안 도널드 클라인에 의해서였다.[4]
데이터 랭글링의 주요 단계 중 데이터 발견은 데이터를 이해하는 방법을 설명하며, 데이터에 익숙해지기 위한 첫 번째 단계이다.
아래의 표는 데이터 랭글링의 과정을 보여주는 예시이다.
| 이름 | 전화 | 생년월일 | 주 |
|---|---|---|---|
| John, Smith | 445-881-4478 | 1989년 8월 12일 | Maine |
| Jennifer Tal | 1965년 11월 12일 | Tx | |
| Gates, Bill | (876)546-8165 | 1972년 6월 15일 | Kansas |
| Alan Fitch | 5493156648 | 1985년 2월 6일 | Oh |
| Jacob Alan | 156-4896 | 1월 3일 | Alabama |
| 데이터 랭글링 후 | |||
| John Smith | 445-881-4478 | 1989-08-12 | Maine |
| Jennifer Tal | 189-456-4513 | 1965-11-12 | Texas |
| Bill Gates | 876-546-8165 | 1972-06-15 | Kansas |
| Alan Fitch | 549-315-6648 | 1985-02-06 | Ohio |
5. 2. 구조화
데이터 랭글링의 구조화 단계는 원시 데이터를 정돈하여 이후 단계에서 더 쉬운 계산과 분석을 할 수 있도록 하는 중요한 단계이다.데이터 랭글링 전후의 데이터 세트 비교는 아래 표와 같다.
| 이름 | 전화 | 생년월일 | 주 |
|---|---|---|---|
| John, Smith | 445-881-4478 | 1989년 8월 12일 | Maine |
| Jennifer Tal | +1-189-456-4513 | 1965년 11월 12일 | Tx |
| Gates, Bill | (876)546-8165 | 1972년 6월 15일 | Kansas |
| Alan Fitch | 5493156648 | 1985년 2월 6일 | Oh |
| Jacob Alan | 156-4896 | 1월 3일 | Alabama |
| 이름 | 전화 | 생년월일 | 주 |
| John Smith | 445-881-4478 | 1989-08-12 | Maine |
| Jennifer Tal | 189-456-4513 | 1965-11-12 | Texas |
| Bill Gates | 876-546-8165 | 1972-06-15 | Kansas |
| Alan Fitch | 549-315-6648 | 1985-02-06 | Ohio |
위 표에서 이름은 '이름 성' 형식으로, 전화번호는 '지역 번호-XXX-XXXX' 형식으로, 생년월일은 'YYYY-mm-dd' 숫자 형식으로, 주는 약어 없이 전체 이름으로 통일되었다. Jacob Alan의 경우, 전화번호 지역 번호와 생년월일의 연도가 없어 데이터 세트에서 삭제되었다. 이처럼 정리된 데이터 세트는 배포 및 평가에 용이하다.
5. 3. 정제
데이터 정제는 여러 가지 형태로 이루어진다. 예를 들어, 서로 다른 방식으로 표현된 날짜 형식을 통일하고, 결과값을 왜곡하는 이상치(Outlier)를 제거하며, 빈 값(Null)을 적절하게 처리하는 것이 데이터 정제의 한 형태이다. 이 단계는 데이터의 전반적인 품질을 보장하는 데 중요하다.데이터 랭글링 과정을 거치면 데이터 세트를 훨씬 더 읽기 쉽게 만들 수 있다. 다음의 표는 데이터 랭글링의 예시를 보여준다.
| 시작 데이터 | 결과 | |
|---|---|---|
| 이름 | ||
| 전화 | ||
| 생년월일 | ||
| 주 |
위 표에서 모든 이름은 '이름 성' 형식으로, 전화 번호는 '지역 번호-XXX-XXXX' 형식으로, 날짜는 'YYYY-mm-dd' 숫자 형식으로 통일되었다. 주는 약어 대신 전체 이름으로 표시되었다. Jacob Alan의 항목은 전화 번호의 지역 번호와 생년월일의 연도가 없어 데이터 세트에서 삭제되었다.
5. 4. 강화
이 단계에서는 데이터 세트에 쉽게 추가할 수 있는 추가 데이터가 데이터 세트에 도움이 되는지 여부를 결정한다.5. 5. 유효성 검사
이 단계는 구조화 및 정리와 유사하다. 유효성 검사 규칙을 반복적으로 적용하여 데이터 일관성뿐만 아니라 품질과 보안을 보장한다. 유효성 검사 규칙의 예로는 데이터를 상호 검사하여 필드의 정확성을 확인하는 것이 있다.5. 6. 게시
사용자 또는 소프트웨어가 다운스트림에서 사용할 수 있도록 데이터 세트를 준비하는 단계이다. 랭글링 과정의 모든 단계와 논리는 문서화되어야 한다.데이터 랭글링 프로세스를 거친 결과, 데이터 세트는 훨씬 더 읽기 쉬워진다. 모든 이름은 {이름 성} 형식으로, 전화번호는 {지역 번호-XXX-XXXX} 형식으로, 날짜는 {YYYY-mm-dd} 숫자 형식으로 통일되었고, 주는 더 이상 약어로 표시되지 않는다. Jacob Alan의 항목은 불완전한 데이터(전화번호 지역 번호 누락, 생년월일에 연도 없음)를 가지고 있었기 때문에 데이터 세트에서 삭제되었다. 결과 데이터 세트는 정리되어 배포 또는 평가할 준비가 되었다.
6. 일반적인 사용 예시
데이터 변환은 일반적으로 필드, 행, 열, 데이터 값 등과 같은 개별 엔터티에 적용되며, 추출, 구문 분석, 조인, 표준화, 증강, 정리, 통합 및 필터링과 같은 작업을 포함한다.[1] 이러한 데이터는 데이터 아키텍트, 데이터 과학자, 비즈니스 사용자 또는 시스템(데이터 웨어하우스, 데이터 레이크 등)에 의해 활용될 수 있다.[2]
의료 데이터에서 질병과의 상관 관계를 찾는 예시를 통해 데이터 랭글링 과정을 살펴볼 수 있다.[3]
1. 질병 진단에 영향을 미치는 요인을 파악하기 위해, 먼저 결과의 구조를 결정한다.[4]
2. 도움이 되지 않거나 잘못된 형식의 데이터(예: 질병 진단이 없는 환자)를 제거한다.[5]
3. 이미 알고 있는 내용을 데이터 세트에 추가하여 데이터의 유용성을 높인다. (예: 해당 지역에서 가장 흔한 질병)[6]
4. 유효성 검사 규칙을 결정하여 데이터의 유효성을 검사한다. (예: 생년월일, 특정 질병 검사)[7]
5. 마지막으로, 데이터를 배포 또는 평가할 수 있도록 구성한다.[8]
이러한 과정을 통해 방대한 양의 의료 데이터를 분석하여 질병 진단의 상관 관계를 파악하는 데 도움을 줄 수 있다.[9]
7. 작동 방식
데이터 랭글링은 전통적으로 수동(예: 엑셀과 같은 스프레드시트를 통해)으로나, KNIME과 같은 도구나 파이썬 또는 SQL과 같은 언어의 스크립트를 통해 수행되어 왔다. R 언어도 데이터 마이닝 및 통계적 데이터 분석에 자주 사용되며 데이터 랭글링에 사용되기도 한다.[6] 데이터 랭글러는 일반적으로 R, Python, SQL, PHP, Scala 및 데이터를 분석하는 데 일반적으로 사용되는 언어에 대한 기술을 갖추고 있다.
시각적 데이터 랭글링 시스템은 비 프로그래머가 데이터 랭글링에 접근할 수 있도록 하고 프로그래머에게 더 간단하게 만들기 위해 개발되었다. 이 중 일부는 사용자 지원을 제공하기 위해 내장된 AI 추천 시스템 및 예시 프로그래밍 기능과 확장 가능한 데이터 흐름 코드를 자동 생성하는 프로그램 합성 기술을 포함한다. 시각적 데이터 랭글링 도구의 초기 프로토타입에는 OpenRefine과 스탠포드/버클리 [http://vis.stanford.edu/wrangler/ Wrangler] 연구 시스템이 포함되었으며,[7] 후자는 Trifacta로 발전했다.
참조
[1]
웹사이트
What Is Data Munging?
http://eduunix.ccut.[...]
2022-01-21
[2]
웹사이트
Mung
http://catb.org/jarg[...]
2012-10-10
[3]
Webarchive
As coder is for code, X is for data
https://blog.okfn.or[...]
2021-04-15
[4]
간행물
Data management for the Cold Land Processes Experiment: improving hydrological science
[5]
웹사이트
What Is Data Wrangling? What are the steps in data wrangling?
https://expressanaly[...]
2020-04-22
[6]
서적
R for data science : import, tidy, transform, visualize, and model data
https://r4ds.had.co.[...]
O'Reilly
2016
[7]
서적
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems
2011-05
[8]
Webarchive
What is Data Franchising?
https://www.iri.com/[...]
Innovative Routines International
2021-04-15
[9]
웹사이트
What is data wrangling and what are the steps?
https://www.altair.c[...]
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com