베르누이 분포
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
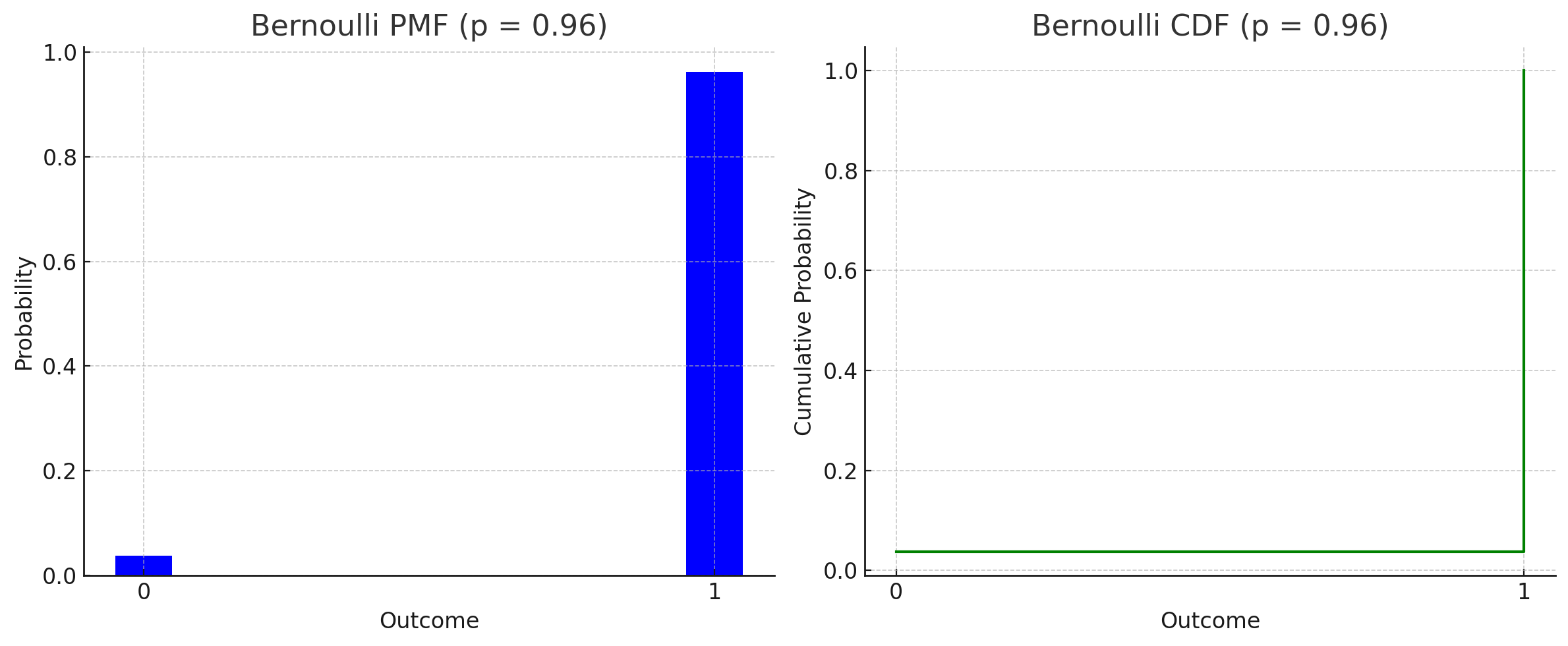
베르누이 분포는 성공 확률 p와 실패 확률 q = 1-p로 결정되는 이산 확률 분포이다. 확률 변수 X가 베르누이 분포를 따를 때, X=1일 확률은 p, X=0일 확률은 q이며, 확률 질량 함수는 k=1일 때 p, k=0일 때 q이다. 베르누이 분포는 이항 분포의 특수한 경우이며, 기댓값은 p, 분산은 p(1-p)이다. 또한 왜도, 첨도, 고차 적률, 엔트로피, 피셔 정보량 등의 성질을 가지며, 이항 분포, 기하 분포, 범주형 분포, 베타 분포, 라데마허 분포와 관련이 있다.
베르누이 분포는 성공 확률 와 실패 확률 로 완전히 결정된다.[3] 이 분포는 인 이항 분포의 특수한 경우이다.[4]
2. 성질
범위에서 베르누이 분포는 지수족을 형성한다. 임의 표본을 기반으로 한 의 최대우도추정량은 표본 평균이다.
2. 1. 확률 질량 함수
만약 X가 베르누이 분포를 따르는 확률변수라면 다음이 성립한다.[3]
:
이 분포의 확률 질량 함수 는 가능한 결과값 ''k''에 대해 다음과 같다.[3]
:
이는 다음과 같이 표현될 수도 있다.[3]
:
또는
:
베르누이 분포는 인 이항 분포의 특수한 경우이다.[4]
2. 2. 기댓값
베르누이 확률 변수 X의 기댓값은 다음과 같다.
:
이는 와 인 베르누이 분포를 따르는 확률 변수 X에 대해 다음과 같이 구할 수 있기 때문이다.
:[3]
2. 3. 분산
베르누이 분포를 따르는 확률 변수 의 분산은 다음과 같다.
:
먼저 다음을 구한다.
:
:
따라서 다음이 성립한다.
:
:[3]
이 결과를 이용하면, 임의의 베르누이 분포에 대해 그 분산의 값이 범위 내에 있음을 쉽게 증명할 수 있다.
2. 4. 왜도
왜도는 이다. 표준화된 베르누이 분포를 따르는 확률변수 를 생각해보면, 이 확률변수는 확률 로 의 값을 가지고, 확률 로 의 값을 가짐을 알 수 있다. 따라서 다음을 얻는다.
:
2. 5. 첨도
베르누이 분포의 첨도는 이다.[3] 가 0 또는 1에 가까워질수록 첨도는 무한대에 가까워지고, 일 때 -2로 가장 작은 값을 가진다. 이는 베르누이 분포를 포함한 이점 분포가 다른 어떤 확률 분포보다 낮은 초과 첨도를 갖는다는 것을 의미한다.[3]
2. 6. 고차 적률과 누율
원시 적률은 E영어[Xk] = p이다.
''k''차 중심 적률은 다음과 같이 주어진다.
:μk = (1-p)(-p)k + p(1-p)k
처음 여섯 개의 중심 적률은 다음과 같다.
:μ1 = 0
:μ2 = p(1-p)
:μ3 = p(1-p)(1-2p)
:μ4 = p(1-p)(1-3p(1-p))
:μ5 = p(1-p)(1-2p)(1-2p(1-p))
:μ6 = p(1-p)(1-5p(1-p)(1-p(1-p)))
더 높은 차수의 중심 적률은 μ2와 μ3로 더 간결하게 표현할 수 있다.
:μ4 = μ2 (1-3μ2)
:μ5 = μ3 (1-2μ2)
:μ6 = μ2 (1-5μ2 (1-μ2))
처음 여섯 개의 누율은 다음과 같다.
:κ1 = p
:κ2 = μ2
:κ3 = μ3
:κ4 = μ2 (1-6μ2)
:κ5 = μ3 (1-12μ2)
:κ6 = μ2 (1-30μ2 (1-4μ2))
2. 7. 엔트로피
성공 확률이 이고 실패 확률이 인 베르누이 확률 변수 의 경우, 엔트로피 는 다음과 같이 정의된다.
:
일 때 엔트로피가 최대가 되는데, 이는 두 결과가 동일한 확률을 가질 때 불확실성이 가장 높음을 나타낸다. 또는 일 때, 즉 한 가지 결과가 확실할 때 엔트로피는 0이 된다.
2. 8. 피셔 정보량
베르누이 분포에서 모수 ''p''에 대한 피셔 정보량은 다음과 같이 정의된다.[1]
:
여기서 ''q''는 1 - ''p''이다.
이는 ''p''가 0.5일 때 최대값을 가지는데, 이는 최대 불확실성과 따라서 모수 ''p''에 대한 최대 정보를 반영한다.[1]
3. 관련 분포
3. 1. 이항 분포
베르누이 시행을 n번 독립적으로 반복했을 때 성공 횟수는 이항 분포를 따른다.[3] 베르누이 분포는 이항 분포 B(n,p)에서 n=1인 특수한 경우이다.[4] 즉, 베르누이 분포는 로 표기할 수 있다.
만약 이 모두 성공 확률이 ''p''인 베르누이 시행이고, 독립적으로 동일하게 분포된(i.i.d.) 확률 변수이면, 그들의 합은 매개변수 ''n''과 ''p''를 갖는 이항 분포를 따른다.[3]
: (이항 분포).
3. 2. 기하 분포
첫 번째 성공을 얻기 위해 필요한, 독립적이고 동일한 베르누이 시행의 수는 기하 분포를 따른다.[3]
3. 3. 범주형 분포
범주형 분포는 2개 이상의 결과를 가지는 경우로 베르누이 분포를 일반화한 것이다.
3. 4. 베타 분포
베타 분포는 베르누이 분포의 켤레 사전 분포이다.[5]
3. 5. 라데마허 분포
이면, 은 라데마허 분포를 따른다.
참조
[1]
서적
Introduction to Mathematical Probability
McGraw-Hill
[2]
서적
A Modern Introduction to Probability and Statistics
Springer London
2010-10-09
[3]
서적
Introduction to Probability
Athena Scientific
2002
[4]
서적
Generalized Linear Models, Second Edition
Boca Raton: Chapman and Hall/CRC
[5]
웹사이트
Conjugate priors: Beta and normal
https://math.mit.edu[...]
2023-10-20
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com