양자화 (정보 이론)
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
양자화는 연속적인 값을 유한한 개수의 값으로 변환하는 과정으로, 정보 이론, 신호 처리, 데이터 압축 등 다양한 분야에서 활용된다. 균일 양자화, 비균일 양자화, 데드존 양자화기 등이 있으며, 양자화 과정에서 발생하는 오차는 양자화 잡음으로 표현된다. 율-왜곡 최적화는 데이터 압축을 위한 양자화 설계에 사용되며, 아날로그-디지털 변환기(ADC)와 같은 장치에서 샘플링과 함께 사용된다. 양자화는 전자 공학, 광학, 생물학, 물리학, 화학 등 다양한 과학 분야에서 활용된다.
양자화는 연속적인 값을 이산적인 값으로 변환하는 과정이다. 예를 들어, 실수 값을 반올림하여 가장 가까운 정수로 만드는 것은 기본적인 양자화의 한 예시이다.
실수 를 가장 가까운 정수 값으로 반올림하는 것은 매우 기본적인 양자화기 유형 중 하나인 ''균일'' 양자화기를 형성한다. 전형적인 (''중앙 트레드'') 균일 양자화기는 양자화 ''단계 크기''가 어떤 값 와 같을 때, 다음과 같이 표현할 수 있다.
양자화는 적용 분야 및 방법에 따라 다양한 종류로 나뉜다.
2. 양자화의 기본 원리
일반적인 (중앙 트레드) 균일 양자화기는 다음과 같이 표현할 수 있다.
:
여기서 는 바닥 함수를 나타내며, 는 양자화 단계의 크기를 의미한다.
천장 함수를 사용하면 다음과 같이 표현할 수도 있다.
:
(는 천장 함수)
이때 출력 값은 입력 값보다 더 적은 가산 집합을 가지며, 정수, 유리수, 실수 값을 가질 수 있다. 이면 실수 입력을 정수 출력으로 변환한다.
양자화 단계 크기(Δ)가 작을수록 평균 제곱 오차(양자화 잡음 전력)는 대략 가 된다.[1][2][3][4][5][6] 1비트를 추가하면 Δ는 절반이 되고, 잡음 전력은 1/4배, 즉 데시벨로 약 -6 dB 감소한다.
양자화는 ''순방향 양자화''(분류)와 ''역 양자화''(재구성) 단계로 나눌 수 있다. 순방향 양자화는 입력 값을 정수 양자화 인덱스 로, 역 양자화는 를 재구성 값 로 매핑한다.
순방향 양자화 단계는 다음과 같다.
:
재구성 단계는 다음과 같다.
:
이러한 2단계 분해는 벡터 양자화와 스칼라 양자화기에 동일하게 적용되며, 통신 채널을 통해 양자화된 데이터를 주고받는 과정에 응용된다.
2. 1. 균일 양자화
균일 양자화는 입력 값의 범위를 동일한 간격으로 나누어 양자화하는 방식이다. 반올림이 대표적인 예시이며, 단계 크기(Δ)에 따라 양자화 오차가 결정된다.
양자화기의 출력 값 집합은 가능한 입력 값 집합보다 작은 가산 집합이다. 출력 값은 정수, 유리수, 실수 값을 가질 수 있다. 가장 가까운 정수로 반올림하는 경우, 단계 크기 는 1이며, 이 경우 실수 입력과 정수 출력을 갖는 양자화기가 된다.
양자화 단계 크기(Δ)가 신호 변동에 비해 작을 때, 평균 제곱 오차(양자화 잡음 전력)는 대략 가 된다.[1][2][3][4][5][6] 양자화기에 1비트를 추가하면 Δ 값이 절반으로 줄어들어 잡음 전력이 1/4배 감소한다. 데시벨로 표현하면, 잡음 전력 변화는 약 -6 dB이다.
모든 양자화기는 ''분류'' 단계(''순방향 양자화'')와 ''재구성'' 단계(''역 양자화'')로 나눌 수 있다. 순방향 양자화는 입력 값을 정수 ''양자화 인덱스'' 로 매핑하고, 역 양자화는 인덱스 를 ''재구성 값'' 로 매핑한다. 이는 통신 채널을 통한 데이터 전송에 유용하게 사용될 수 있다.
대칭 소스 X가 (, 그 외에는 0)로 모델링될 때, 단계 크기 이고 양자화기의 신호 대 양자화 잡음비(SQNR)는 다음과 같다.
:.
비트 사용시 이므로,
:,
즉, 대략 비트당 6 dB이다. (=8 비트: SQNR = 48 dB, =16 비트: SQNR = 96 dB) 양자화에 사용되는 비트가 추가될 때마다 SQNR이 6 dB 향상되는 것은 잘 알려진 성능 지표이다.
많은 소스에서 높은 비트 전송률일 때 양자화기 SQNR 기울기를 6 dB/비트로 근사할 수 있다. 단계 크기를 절반으로 줄이면 비트 전송률이 샘플당 약 1 비트 증가하고, 평균 제곱 오차는 4배(6 dB) 감소한다.
2. 1. 1. 중앙 트레드 균일 양자화기
실수 를 가장 가까운 정수 값으로 만드는 반올림은 매우 기본적인 유형의 양자화기, 즉 균일 양자화기를 형성한다. 양자화 단계 크기가 어떤 값 와 같은 전형적인 (''중앙 트레드'') 균일 양자화기는 다음과 같이 표현될 수 있다.
:,
여기서 표기법 는 바닥 함수를 나타낸다.
같은 양자화기는 천장 함수를 사용하여 다음과 같이 표현할 수도 있다.
:.
(표기법 는 천장 함수를 나타낸다).
부호가 있는 입력 데이터에 대한 대부분의 균일 양자화기는 ''미드-라이저''와 ''미드-트레드'' 두 가지 유형으로 분류할 수 있다. 이는 0 주변 영역에서 발생하는 상황을 기반으로 하며, 양자화기의 입출력 함수를 계단으로 보는 비유를 사용한다. 미드-트레드 양자화기는 0 값을 갖는 재구성 레벨(계단의 ''트레드'')을 가지는 반면, 미드-라이저 양자화기는 0 값을 갖는 분류 임계값(계단의 ''라이저'')을 갖는다.[9] 미드-트레드 양자화는 반올림을 포함하며, 미드-트레드 균일 양자화에 대한 공식은 위에 제공되어 있다.
일반적으로 미드-라이저 또는 미드-트레드 양자화기가 실제로 ''균일'' 양자화기가 아닐 수도 있다. 즉, 양자화기의 분류 구간의 크기가 모두 동일하지 않거나, 가능한 출력 값 사이의 간격이 모두 동일하지 않을 수 있다. 미드-라이저 양자화기의 특징은 분류 임계 값의 정확한 값이 0이고, 미드-트레드 양자화기의 특징은 재구성 값의 정확한 값이 0이라는 것이다.[9]
2. 1. 2. 중앙 라이저 균일 양자화기
실수를 가장 가까운 정수 값으로 만드는 반올림은 균일 양자화기의 기본적인 예시이다. 일반적인 중앙 라이저(mid-riser) 균일 양자화기는 다음과 같이 표현할 수 있다.
:
여기서 는 양자화 단계의 크기를 나타내며, 는 바닥 함수이다.
이때, 분류 규칙은 다음과 같다.
:
그리고 재구성 규칙은 다음과 같다.
:
중앙 라이저 균일 양자화기는 0 출력 값을 가지지 않으며, 최소 출력 크기는 단계 크기의 절반이다. 일부 응용 분야에서는 0 출력 신호 표현이 필요할 수 있기 때문에, 이런 경우에는 중앙 트레드(mid-tread) 양자화기를 사용한다.[9]
2. 2. 비균일 양자화
비균일 양자화는 입력 값의 분포에 따라 양자화 구간을 다르게 설정하는 방식이다. 신호의 특성에 맞게 양자화 레벨을 조절하여 효율성을 높인다.
2. 2. 1. 데드존 양자화기
'''데드존 양자화기'''는 0을 중심으로 대칭적인 동작을 하는 미드-트레드 양자화기의 한 유형이다. 0 출력 값 주변 영역은 ''데드존'' 또는 ''데드밴드''라고 불린다.[9] 데드존은 때때로 노이즈 게이트 또는 스퀄치와 같은 역할을 하여, 작은 신호 값을 0으로 만들어 노이즈를 제거하거나 데이터를 압축하는 데 효과적이다.
특히 압축 응용 분야에서 데드존은 다른 단계와 다른 너비를 가질 수 있다. 균일 양자화기의 경우, 데드존 너비 를 설정하기 위한 순방향 양자화 규칙은 다음과 같다.[10][11][18]
:
여기서 는 부호 함수이다.
데드존 양자화기의 일반적인 재구성 규칙은 다음과 같다.
:
여기서 는 0과 1 사이의 값을 가지는 재구성 오프셋 값이다. 입력 데이터가 가우시안 분포, 라플라스 분포 등과 같이 0을 중심으로 대칭적인 확률 밀도 함수를 따를 때, 값은 보통 0과 사이에서 결정된다. 는 에 따라 달라질 수 있지만, 와 같은 상수로 설정되기도 한다.
일반적인 경우(예: 재무 회계, 초등 수학)에는 및 로 설정하여 데드존 양자화기를 균일 양자화기로 사용한다.
2. 3. 양자화 오차 및 잡음
아날로그-디지털 변환기(ADC)에서 양자화 과정은 원본 신호와 양자화된 신호 사이에 오차를 발생시키는데, 이를 양자화 오차라고 한다. 이 오차는 확률론적 동작으로 인해 '''양자화 잡음'''이라고 불리는 부가적인 랜덤 신호로 모델링되기도 한다.[2][6][12][13] 양자화기는 더 많은 레벨을 사용할수록 양자화 잡음 전력이 낮아진다.
일반적으로 양자화 오차는 백색 잡음처럼 신호 처리 시스템에 영향을 미친다고 가정한다. 즉, 신호와 상관관계가 거의 없고, 전력 스펙트럼 밀도가 거의 평탄하다는 것이다.[2][6][12][13]
하지만 양자화 오차는 실제로 신호와 결정론적으로 관련되어 있어서 완전히 독립적이지 않다. 주기적인 신호는 주기적인 양자화 잡음을 생성할 수 있으며, 심지어 리미트 사이클을 발생시킬 수도 있다. 이러한 문제를 해결하기 위해 디더링 기법을 사용하는데, 이는 양자화 전에 신호에 임의의 잡음을 추가하는 방식이다.[6][13]
원래 신호가 1 최하위 비트(LSB)보다 훨씬 큰 경우, 양자화 오차는 신호와 크게 상관관계가 없으며, 대략 균일 분포를 가진다. 반올림을 사용하면 평균이 0이고 제곱 평균 제곱근(RMS) 값은 인 표준 편차를 가진다. 잘라내기를 사용하면 평균은 이고 RMS 값은 이다. 양자화 비트 수가 1비트 증가할 때마다 신호 대 양자화 잡음 전력비는 약 6dB씩 증가한다.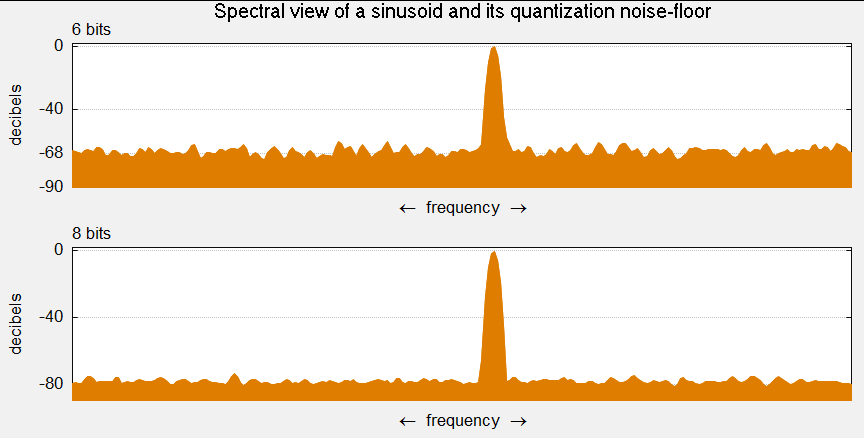
낮은 진폭의 신호에서는 양자화 오차가 입력 신호에 종속되어 왜곡이 발생한다. 디더링은 이러한 왜곡을 제거하는 데 효과적이다.
이상적인 ADC에서 양자화 오차가 -1/2 LSB와 +1/2 LSB 사이에 균일하게 분포하고 신호가 균일한 분포를 갖는 경우, 신호 대 양자화 잡음비(SQNR)는 다음과 같이 계산된다.
:
여기서 Q는 양자화 비트의 수이다. 예를 들어, 16비트 ADC의 최대 신호 대 양자화 잡음비는 96.3dB이다.
입력 신호가 전체 진폭 사인파인 경우, SQNR은 다음과 같이 계산된다.
:
이 경우 16비트 ADC의 최대 신호 대 잡음비는 98.09dB이다.
하지만, 저해상도 ADC, 고해상도 ADC의 저레벨 신호, 간단한 파형의 경우에는 양자화 잡음이 균일하게 분포되지 않아 위의 모델이 부정확할 수 있다.[16]
3. 양자화의 수학적 특성
:
여기서 는 바닥 함수를 나타낸다.
같은 양자화기는 천장 함수를 사용하여 다음과 같이 표현할 수도 있다.
:
(는 천장 함수를 나타낸다).
양자화기의 필수적인 속성은 가능한 출력 값의 집합이 가능한 입력 값의 집합보다 작은 가산 집합을 갖는다는 것이다. 출력 값 집합의 구성원은 정수, 유리수 또는 실수 값을 가질 수 있다. 가장 가까운 정수로 단순하게 반올림할 경우, 단계 크기 는 1과 같다. 이거나 가 다른 정수 값과 같으면 이 양자화기는 실수 입력과 정수 출력을 갖는다.
양자화 단계 크기(Δ)가 양자화되는 신호의 변동에 비해 작을 때, 이러한 반올림 연산으로 생성되는 평균 제곱 오차는 대략 가 된다.[1][2][3][4][5][6] 평균 제곱 오차는 양자화 ''잡음 전력''이라고도 한다. 양자화기에 1비트를 추가하면 Δ 값이 절반으로 줄어들어 잡음 전력이 1/4배 감소한다. 데시벨로 표현하면, 잡음 전력 변화는 이다.
모든 양자화기는 가능한 출력 값 집합이 가산 가능하므로, ''분류'' 단계 (''순방향 양자화'' 단계)와 ''재구성'' 단계 (''역 양자화'' 단계)의 두 가지 뚜렷한 단계로 분해될 수 있다. 분류 단계는 입력 값을 정수 ''양자화 인덱스'' 로 매핑하고, 재구성 단계는 인덱스 를 입력 값의 출력 근사값인 ''재구성 값'' 로 매핑한다. 위에 설명된 균일 양자화기 예제의 경우, 순방향 양자화 단계는 다음과 같이 표현될 수 있다.
:
그리고 이 예제 양자화기의 재구성 단계는 다음과 같다.
:
이러한 2단계 분해는 양자화 동작의 설계 및 분석에 유용하며, 양자화된 데이터가 통신 채널을 통해 통신될 수 있는 방식을 보여준다. ''소스 인코더''는 순방향 양자화 단계를 수행하고 통신 채널을 통해 인덱스 정보를 보내며, ''디코더''는 재구성 단계를 수행하여 원래 입력 데이터의 출력 근사값을 생성한다. 일반적으로 순방향 양자화 단계는 입력 데이터를 양자화 인덱스 데이터의 정수 공간으로 매핑하는 어떠한 함수든 사용할 수 있으며, 역 양자화 단계는 개념적으로 (또는 문자 그대로) 각 양자화 인덱스를 해당 재구성 값에 매핑하는 테이블 조회 연산일 수 있다. 이 2단계 분해는 벡터 양자화와 스칼라 양자화기에 동일하게 적용된다.
양자화는 다대일 매핑이므로 본질적으로 비선형적이고 되돌릴 수 없는 과정이다. 즉, 동일한 출력 값을 여러 입력 값이 공유하기 때문에 일반적으로 출력 값만 주어졌을 때 정확한 입력 값을 복구하는 것은 불가능하다.
가능한 입력 값의 집합은 무한히 클 수 있으며, 연속적이고 따라서 비가산적일 수 있다 (예: 모든 실수 집합 또는 제한된 범위 내의 모든 실수). 가능한 출력 값의 집합은 유한 집합 또는 가산 무한일 수 있다.[6] 예를 들어, 벡터 양자화는 다차원(벡터 값) 입력 데이터에 양자화를 적용한 것이다.[7]
4. 양자화의 종류
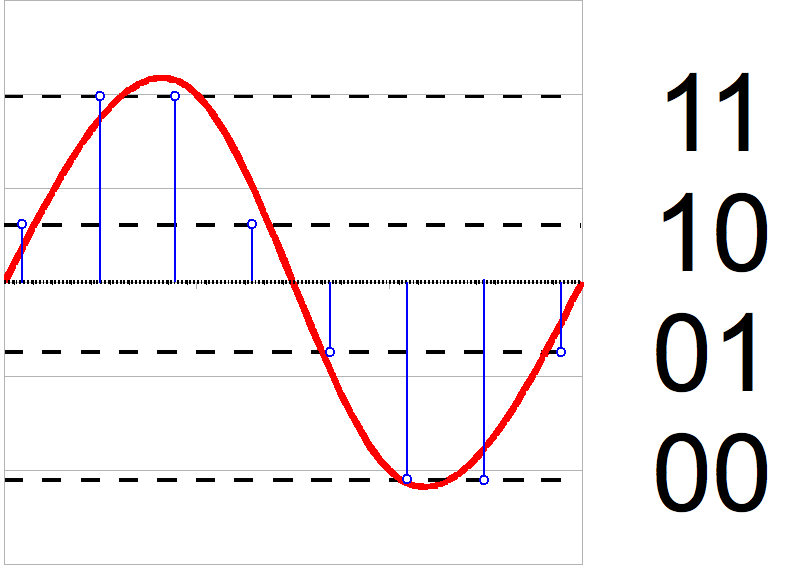
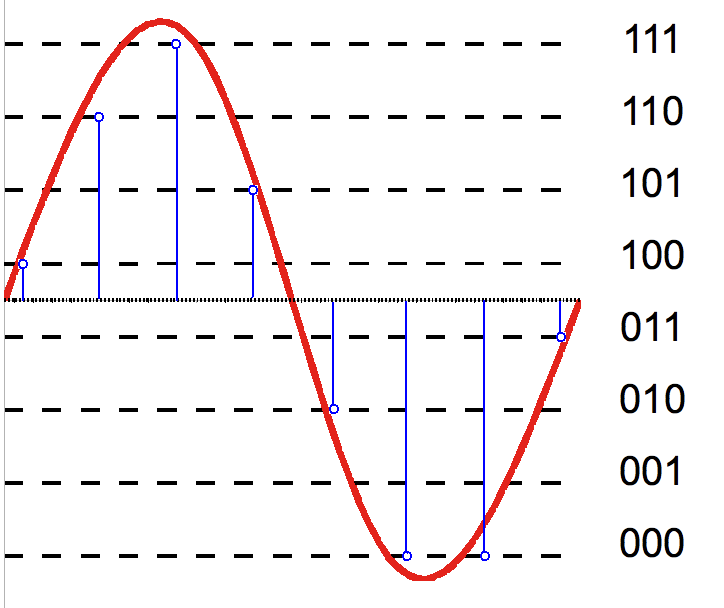
4. 1. 아날로그-디지털 변환기 (ADC)
아날로그-디지털 변환기(ADC)는 샘플링과 양자화라는 두 가지 과정을 통해 아날로그 신호를 디지털 신호로 변환한다. 샘플링은 시간에 따라 변하는 전압 신호를 실수 값의 연속인 이산 시간 신호로 만든다. 양자화는 각 실수 값을 정해진 유한한 개수의 이산 값으로 근사화한다. 이산 값은 주로 고정 소수점 워드로 표현된다. 가능한 양자화 레벨에는 제한이 없지만, 일반적으로 사용되는 워드 길이는 8비트(256 레벨), 16비트(65,536 레벨), 24비트(1680만 레벨)이다.
숫자 시퀀스를 양자화하면 양자화 오류가 발생하는데, 이는 확률론적인 동작으로 인해 '''양자화 잡음'''이라고 불리는 추가적인 랜덤 신호로 모델링되기도 한다. 양자화기가 더 많은 레벨을 사용할수록 양자화 잡음의 세기는 낮아진다.
양자화 잡음은 ADC에서 양자화로 인해 발생하는 양자화 오차를 나타내는 모델이다. 이는 ADC의 아날로그 입력 전압과 출력되는 디지털 값 사이의 반올림 오차이다. 이 잡음은 비선형적이며 신호에 따라 달라진다.
이상적인 ADC에서 양자화 오차가 -1/2 LSB와 +1/2 LSB 사이에 균일하게 분포하고, 신호가 모든 양자화 레벨을 포함하는 균일한 분포를 갖는 경우, 신호 대 양자화 잡음비(SQNR)는 다음과 같이 계산할 수 있다.
:
여기서 Q는 양자화 비트의 수이다. 이를 만족하는 가장 일반적인 테스트 신호는 최대 진폭의 삼각파와 톱니파이다. 예를 들어, 16비트 ADC는 최대 신호 대 양자화 잡음비가 6.02 × 16 = 96.3 dB이다.
입력 신호가 최대 진폭의 사인파인 경우, 신호의 분포는 더 이상 균일하지 않으며 해당 방정식은 다음과 같다.
:
여기서 양자화 잡음은 다시 한번 균일하게 분포되어 있다고 가정한다. 입력 신호의 진폭이 크고 주파수 스펙트럼이 넓은 경우에 이 가정이 성립한다.[15] 이 경우 16비트 ADC는 최대 신호 대 잡음비가 98.09 dB이다. 신호 대 잡음비에서 1.761 차이는 신호가 삼각파나 톱니파 대신 전체 스케일 사인파이기 때문에 발생한다.
고해상도 ADC에서 복잡한 신호의 경우, 이것은 정확한 모델이다. 그러나 저해상도 ADC, 고해상도 ADC의 낮은 레벨 신호, 간단한 파형의 경우에는 양자화 잡음이 균일하게 분포되지 않아 이 모델은 부정확하다.[16] 이러한 경우 양자화 잡음 분포는 신호의 정확한 진폭에 의해 크게 영향을 받는다.
계산은 전체 스케일 입력을 기준으로 한다. 작은 신호의 경우 상대적인 양자화 왜곡이 매우 클 수 있다. 이 문제를 해결하기 위해 아날로그 컴팬딩을 사용할 수 있지만, 이는 왜곡을 유발할 수 있다.
4. 2. 율-왜곡 최적화
율-왜곡 최적화는 데이터 압축 과정에서 정보 손실(왜곡)을 최소화하면서 데이터 크기(비트율)를 줄이는 것을 목표로 한다. 이는 통신 채널이나 저장 매체의 제한된 비트율 내에서 왜곡을 관리하는 문제를 다룬다.
양자화는 일반적으로 다음 두 단계로 나뉜다.
엔트로피 부호화는 양자화 인덱스를 효율적으로 전달하는 데 사용될 수 있다. 각 인덱스에 이진 코드워드를 할당하고, 코드워드의 길이에 따라 비트율이 결정된다. 율-왜곡 최적화의 목표는 비트율과 왜곡의 균형을 최적으로 맞추는 것이다.
정보 소스 가 확률 밀도 함수(PDF) 를 갖는 랜덤 변수 를 생성한다고 가정하면, 특정 구간에 속할 확률, 비트 전송률 , 왜곡 는 다음과 같이 계산된다.
:.
:.
:.
율-왜곡 최적화 문제는 다음과 같이 두 가지 방식으로 표현될 수 있다.
1. 주어진 최대 왜곡 제약 조건에서 비트 전송률 최소화.
2. 주어진 최대 비트 전송률 제약 조건에서 왜곡 최소화.
이 문제들은 라그랑주 승수를 사용하여 제약 없는 문제로 변환하여 해결할 수 있다.
최적의 재구성 값은 각 구간 내의 조건부 기대값(중심점)으로 설정하여 얻을 수 있다.
:.
산술 부호화와 같은 효율적인 엔트로피 부호화 기술을 사용하면 실제 엔트로피에 매우 가까운 비트 전송률을 달성할 수 있다.
5. 양자화 설계
양자화기 설계는 왜곡과 비트율 간의 균형을 고려하여 이루어진다. 부호가 있는 입력 데이터에 대한 대부분의 균일 양자화기는 미드-라이저(mid-riser)와 미드-트레드(mid-tread) 두 가지 유형으로 분류할 수 있다. 미드-트레드 양자화기는 0 값을 갖는 재구성 레벨(계단의 '트레드')을 가지는 반면, 미드-라이저 양자화기는 0 값을 갖는 분류 임계값(계단의 '라이저')을 갖는다.[9]
미드-트레드 양자화는 반올림을 포함하며, 관련 공식은 다음과 같다.
:
미드-라이저 양자화는 절단을 포함하며, 입출력 공식은 다음과 같다.
:
분류 규칙은
:
이고, 재구성 규칙은
:
이다.
미드-라이저 균일 양자화기는 0 출력 값을 갖지 않는 반면, 미드-트레드 양자화기는 0 출력 레벨을 갖는다. 일부 응용 분야에서는 0 출력 신호 표현이 필요할 수 있다.
일반적으로 미드-라이저 또는 미드-트레드 양자화기는 실제로 ''균일'' 양자화기가 아닐 수 있다. 즉, 양자화기의 분류 구간의 크기가 모두 동일하지 않거나, 가능한 출력 값 사이의 간격이 모두 동일하지 않을 수 있다. 미드-라이저 양자화기의 특징은 분류 임계 값의 정확한 값이 0이고, 미드-트레드 양자화기의 특징은 재구성 값의 정확한 값이 0이라는 것이다.[9]
5. 1. 입자 왜곡과 과부하 왜곡
부호가 있는 입력 데이터에 대한 대부분의 균일 양자화기는 미드-라이저(mid-riser)와 미드-트레드(mid-tread) 두 가지 유형으로 분류할 수 있다. 미드-트레드 양자화기는 0 값을 갖는 재구성 레벨(계단의 '트레드')을 가지는 반면, 미드-라이저 양자화기는 0 값을 갖는 분류 임계값(계단의 '라이저')을 갖는다.[9]양자화기 설계는 종종 제한된 범위의 가능한 출력 값만 지원하고, 입력이 지원 범위를 초과할 때마다 클리핑을 수행한다. 이 클리핑으로 인해 발생하는 오류를 과부하 왜곡이라고 한다. 지원되는 범위 내에서 양자화기의 출력 값 사이 간격의 양을 입자성이라 하며, 이 간격으로 인해 발생하는 오류를 입자 왜곡이라고 한다. 양자화기 설계는 입자 왜곡과 과부하 왜곡 사이의 적절한 균형을 결정하는 것을 포함한다. 주어진 출력 값 개수에 대해 평균 입자 왜곡을 줄이면 평균 과부하 왜곡이 증가할 수 있으며, 그 반대도 마찬가지다. 신호 진폭(또는 양자화 단계 크기 )을 제어하는 기술은 자동 이득 제어(AGC)를 사용하는 것이다.[6]
5. 2. 율-왜곡 양자화기 설계
율-왜곡 이론에서 최적의 양자화는 주어진 비트율 제약 조건 하에서 왜곡을 최소화하거나, 주어진 왜곡 제약 조건 하에서 비트율을 최소화하는 방식으로 이루어진다.일반적인 율-왜곡 문제는 다음 두 가지 방식으로 표현할 수 있다.
- 최대 왜곡 제약 조건 이 주어지면 비트 전송률 을 최소화한다.
- 최대 비트 전송률 제약 조건 이 주어지면 왜곡 를 최소화한다.
이러한 문제는 라그랑주 승수 를 사용하여 와 같은 비제약 문제로 변환하여 해결할 수 있다. 여기서 는 전송률과 왜곡 간의 균형을 설정하는 음수가 아닌 상수이다.
고정 길이 코드를 사용하는 경우(예: 로이드-맥스 양자화기), 율-왜곡 최소화 문제는 왜곡 최소화 문제로 단순화된다. 로이드-맥스 양자화기는 다음 두 방정식을 반복적으로 풀어 최적의 결정 경계 와 재구성 레벨 을 찾는다.[6][21][22]
- : 각 임계값을 각 재구성 값 쌍의 중간점에 배치한다.
- : 각 재구성 값을 관련된 분류 간격의 중심에 배치한다.
6. 양자화의 응용
양자화는 다양한 분야에서 활용된다. 많은 물리량은 실제로 물리적 실체에 의해 양자화된다.
6. 1. 기타 분야
많은 물리량은 실제로 물리적 실체에 의해 양자화된다. 이러한 제한이 적용되는 분야의 예로는 전자공학(전자 때문에), 광학(광자 때문에), 생물학(DNA 때문에), 물리학(플랑크 한계 때문에) 및 화학(분자 때문에) 등이 있다.참조
[1]
논문
On the Calculation of the most Probable Values of Frequency-Constants, for Data arranged according to Equidistant Division of a Scale
https://zenodo.org/r[...]
Wiley
[2]
간행물
Spectra of Quantized Signals
http://www.alcatel-l[...]
Bell System Technical Journal
1948-07
[3]
논문
The Philosophy of PCM
Institute of Electrical and Electronics Engineers (IEEE)
[4]
서적
Modern Communication Principles
https://books.google[...]
McGraw–Hill
[5]
논문
Asymptotically efficient quantizing
Institute of Electrical and Electronics Engineers (IEEE)
[6]
논문
Quantization
Institute of Electrical and Electronics Engineers (IEEE)
[7]
서적
Vector Quantization and Signal Compression
https://books.google[...]
Springer Science+Business Media
1991
[8]
서적
Understanding Records
Berklee Press
2010
[9]
논문
Quantization
Institute of Electrical and Electronics Engineers (IEEE)
[10]
서적
The JPEG 2000 Suite
https://archive.org/[...]
John Wiley & Sons
2009
[11]
서적
JPEG2000: Image Compression Fundamentals, Standards and Practice
https://archive.org/[...]
Kluwer Academic Publishers
2002
[12]
논문
A Study of Rough Amplitude Quantization by Means of Nyquist Sampling Theory
Institute of Electrical and Electronics Engineers (IEEE)
[13]
간행물
Statistical analysis of amplitude quantized sampled data systems
http://www-isl.stanf[...]
Trans. AIEE Pt. II: Appl. Ind.
1961-01
[14]
논문
The Validity of the Additive Noise Model for Uniform Scalar Quantizers
Institute of Electrical and Electronics Engineers (IEEE)
[15]
서적
Principles of Digital Audio 2nd Edition
https://books.google[...]
SAMS
1989
[16]
서적
The Art of Digital Audio 3rd Edition
Focal Press
2001
[17]
논문
Optimum quantizer performance for a class of non-Gaussian memoryless sources
Institute of Electrical and Electronics Engineers (IEEE)
[18]
논문
Efficient scalar quantization of exponential and Laplacian random variables
Institute of Electrical and Electronics Engineers (IEEE)
[19]
논문
Optimum quantizers and permutation codes
Institute of Electrical and Electronics Engineers (IEEE)
[20]
논문
Minimum entropy quantizers and permutation codes
Institute of Electrical and Electronics Engineers (IEEE)
[21]
논문
Least squares quantization in PCM
Institute of Electrical and Electronics Engineers (IEEE)
[22]
논문
Quantizing for minimum distortion
Institute of Electrical and Electronics Engineers (IEEE)
[23]
논문
Entropy-constrained vector quantization
Institute of Electrical and Electronics Engineers (IEEE)
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com