키-값 데이터베이스
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
키-값 데이터베이스는 각 레코드를 고유하게 식별하는 키를 사용하여 데이터를 저장하고 검색하는 데이터베이스 유형이다. 관계형 데이터베이스와 달리 데이터를 단일의 비공개 집합으로 취급하며, 레코드마다 다른 필드를 가질 수 있어 유연성이 높다. 1979년 유닉스 시스템에서 처음 등장한 DBM과 같은 초기 형태를 거쳐, 클라우드 컴퓨팅의 발전과 함께 NoSQL의 한 유형으로 널리 사용되고 있다. 키-값 데이터베이스는 일관성 모델, 데이터 저장 방식, 키의 순서 지원 등 다양한 특징을 가지며, 빅데이터, 데이터 분석, 분산 데이터 저장소 등 다양한 분야에서 활용된다.
2. 기본 개념
키-값 데이터베이스에서 사전은 객체 또는 레코드의 집합을 포함하며, 각 레코드 안에는 데이터를 포함하는 다양한 필드가 있다. 이러한 레코드는 고유하게 식별하는 키를 사용하여 저장 및 검색되며, 데이터베이스 내의 데이터를 찾는 데 사용된다.
2. 1. 관계형 데이터베이스와의 비교
관계형 데이터베이스(RDB)는 잘 알려진 데이터베이스 유형으로, 키-값 데이터베이스와는 작동 방식이 매우 다르다. RDB는 데이터 구조를 명확하게 정의된 데이터 형식의 필드를 포함하는 일련의 테이블로 미리 정의한다. 이 데이터 형식을 데이터베이스 프로그램에 공개함으로써 다양한 최적화를 적용할 수 있다.
반면, 키-값 시스템은 데이터를 단일의 비공개 집합으로 취급하며, 레코드마다 다른 필드를 가질 수 있다. 이는 상당한 유연성을 제공하며, 객체 지향 프로그래밍과 같은 현대적인 개념을 더 잘 따른다. 대부분의 RDB와 달리, 선택적 값은 자리 표시자나 입력 매개변수로 표현되지 않으므로, 키-값 데이터베이스는 동일한 데이터를 저장하는 데 사용되는 메모리가 훨씬 적어 특정 작업에서 성능이 크게 향상될 수 있다.
성능, 표준화 부족 등의 문제로 인해 키-값 시스템은 오랫동안 틈새 용도로만 사용되었다. 그러나 2010년 이후 클라우드 컴퓨팅으로 빠르게 전환되면서 더 광범위한 NoSQL 운동의 일환으로 다시 주목받고 있다. ArangoDB[3]와 같은 그래프 데이터베이스도 내부적으로 키-값 데이터베이스이며, 레코드 간의 관계(포인터) 개념을 일급 데이터 유형으로 추가한다.
2. 2. JSON 및 XML 표현
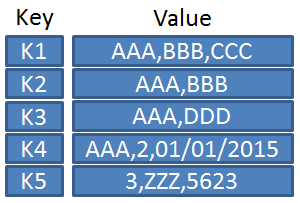
키-값 쌍의 JSON 그리고 XML 표현의 예는 다음과 같다.
| 데이터베이스 테이블 | |
|---|---|
| 제이슨(JSON) stringify | {"k1":"AAA,BBB,CCC","k2":"AAA,BBB","k3":"AAA,DDD","k4":"AAA,2,01/01/2015","k5":"3,ZZZ,5623"} |
| XML 스키마 표현 |
키-값 데이터베이스는 결합성 모델을 사용하여 결과적 일관성에서 직렬 가능성에 이르기까지 다양하게 사용할 수 있으며, 일부는 키의 순서를 지원한다. 데이터를 메모리(RAM)에 유지하거나, 솔리드 스테이트 드라이브 또는 회전 디스크를 사용하는 등 다양한 저장 방식을 사용한다.
3. 종류 및 특징
모든 엔티티(레코드)는 키-값 쌍의 집합으로 구성된다. 키는 정렬된 목록으로 지정된 여러 구성 요소를 가지며, 주요 키는 레코드를 식별하고 키의 선행 구성 요소로 구성된다. 후속 구성 요소는 부 키라고 불리며, 이는 파일 시스템의 디렉토리 경로와 유사한 구조를 가진다(예: /Major/minor1/minor2/). 키-값 쌍의 "값" 부분은 임의의 길이의 해석되지 않은 바이트 문자열이다.[2]
유닉스 시스템은 1979년 켄 톰슨이 처음 작성한 dbm (데이터베이스 관리자) 라이브러리를 제공한다. dbm은 단일 키(기본 키)를 사용하여 임의의 데이터의 연관 배열을 관리하며, Perl for Win32와 같은 프로그래밍 언어를 통해 마이크로소프트 윈도우로도 이식되었다. 최신 구현에는 sdbm, GNU dbm 및 Berkeley DB가 있다. ''dbm''은 NoSQL 개념보다 앞서며 현대적인 담론에서는 거의 언급되지 않지만, 많은 소프트웨어에서 사용된다.
최신 키-값 데이터베이스의 예로는 ArangoDB와 같은 다른 데이터베이스 관리 시스템의 스토리지 엔진으로 사용되는 RocksDB가 있다. 다른 예로는 Aerospike (데이터베이스), 아마존 다이나모DB(Amazon DynamoDB), Memcached, Redis, ScyllaDB 등이 있다.
키-값 데이터베이스는 관계형 데이터베이스(RDB)와는 매우 다른 방식으로 작동한다. RDB는 데이터베이스 내의 데이터 구조를 명확하게 정의된 데이터 형식의 필드를 포함하는 일련의 테이블로 미리 정의하여 데이터베이스 프로그램에 공개함으로써 많은 최적화를 적용할 수 있다. 반면, 키-값 시스템에서는 데이터를 단일의 비공개 집합으로 취급하며, 레코드마다 다른 필드를 가질 수 있다. 이는 상당한 유연성을 제공하며, 객체 지향 프로그래밍과 같은 현대적인 개념을 더 잘 추구한다. 대부분의 RDB처럼, 선택적 값은 자리 표시자나 입력 매개변수로 표현되지 않으므로, 키-값 데이터베이스에서는 동일한 데이터를 저장하는 데 사용되는 메모리가 훨씬 적으며, 특정 작업 부하에서 성능이 크게 향상될 수 있다.
성능, 표준화 부족 등의 문제로 인해 키-값 시스템은 오랫동안 틈새 용도로 제한되었으나, 2010년 이후 클라우드 컴퓨팅으로의 전환과 함께 더 광범위한 NoSQL 전환의 일부로 다시 유행하고 있다.
3. 1. 일관성 모델
키-값 데이터베이스는 결합성 모델을 사용하여 결과적 일관성에서 직렬 가능성에 이르기까지 다양하게 사용할 수 있다. 일부는 키의 순서를 지원한다.[2]
일부는 데이터를 메모리(RAM)에 유지하고, 다른 일부는 솔리드 스테이트 드라이브 또는 회전 디스크를 사용한다.[2]
3. 2. 데이터 저장 방식
키-값 데이터베이스는 결합성 모델을 사용하여 결과적 일관성에서 직렬 가능성에 이르기까지 다양하게 사용할 수 있다. 일부는 키의 순서를 지원한다.[2]
일부 키-값 데이터베이스는 데이터를 메모리(RAM)에 유지하는 반면, 다른 일부는 솔리드 스테이트 드라이브 또는 회전 디스크를 사용한다.[2]
모든 엔티티(레코드)는 키-값 쌍의 집합이다. 키는 정렬된 목록으로 지정된 여러 구성 요소를 갖는다. 주요 키는 레코드를 식별하며 키의 선행 구성 요소로 구성된다. 후속 구성 요소는 부 키라고 한다. 이 구성은 파일 시스템의 디렉토리 경로 사양과 유사하다(예: /Major/minor1/minor2/). 키-값 쌍의 "값" 부분은 임의의 길이의 해석되지 않은 바이트 문자열이다.[2]
키-값 데이터베이스는 결과적 일관성에서 직렬 가능성까지, 일관성 모델을 사용할 수 있으며, 키의 순서를 지원하는 것도 있다.[4] 데이터를 메모리 (RAM)에 보관하는 것도 있고, 솔리드 스테이트 드라이브나 회전 디스크를 사용하는 것도 있다.[4]
모든 실체(레코드)는 키와 값의 쌍으로 이루어진 집합이다. 하나의 키는 여러 요소를 가지며, 정렬된 리스트로 지정된다. 주 분류 키(메이저 키)는 레코드를 식별하는 것으로, 키의 첫 번째 구성 요소로 구성된다. 후속 구성 요소는 소분류 키(마이너 키)라고 한다. 이 구성은 파일 시스템의 디렉토리 경로 지정과 유사하다(예: /Major/minor1/minor2/). 키-값 쌍의 "값" 부분은 단순히 임의의 길이를 가진 해석되지 않은 바이트 문자열이다.[4]
3. 3. 키의 순서 지원
키-값 데이터베이스는 결합성 모델을 사용하여 결과적 일관성에서 직렬 가능성에 이르기까지 다양하게 사용할 수 있다. 일부는 키의 순서를 지원한다.[2]
4. 주요 사용 사례
키-값 데이터베이스는 관계형 데이터베이스(RDB)와 다른 방식으로 작동한다. RDB는 데이터 구조를 미리 정의된 데이터 형식의 필드를 포함하는 테이블로 정의한다. 반면, 키-값 시스템은 데이터를 단일 비공개 집합으로 취급하여 각 레코드가 다른 필드를 가질 수 있게 한다. 이는 유연성을 제공하며 객체 지향 프로그래밍과 같은 현대적 개념에 더 적합하다. 선택적 값은 자리 표시자나 입력 매개변수로 표현되지 않으므로, 키-값 데이터베이스는 동일한 데이터 저장에 필요한 메모리가 적고, 특정 작업에서 성능이 향상될 수 있다.
성능, 표준화 부족 등의 문제로 키-값 시스템은 오랫동안 틈새 용도로 제한되었다. 그러나 2010년 이후 클라우드 컴퓨팅으로 전환되면서 NoSQL 운동의 일부로 다시 유행하고 있다. ArangoDB영어[3] 같은 Graph database영어도 내부적으로 키-값 데이터베이스이며, 레코드 간 관계(포인터)를 일급 데이터 유형으로 추가한다.
5. 주요 제품
결합성 모델을 사용하는 키-값 데이터베이스는 결과적 일관성에서 직렬 가능성에 이르기까지 다양하게 사용할 수 있으며, 일부는 키 순서를 지원한다. 데이터를 메모리(RAM)에 유지하는 경우도 있고, 솔리드 스테이트 드라이브나 회전 디스크를 사용하는 경우도 있다.[2]
켄 톰슨이 1979년에 처음 작성한 dbm은 유닉스 시스템에서 제공하는 라이브러리이다. dbm은 단일 키(기본 키)를 사용하여 임의의 데이터 연관 배열을 관리하며, Perl for Win32와 같은 프로그래밍 언어를 통해 마이크로소프트 윈도우로도 이식되었다. 최신 구현에는 sdbm, GNU dbm 및 Berkeley DB가 있다.
현대적인 키-값 데이터베이스의 예로는 ArangoDB 등 다른 데이터베이스 관리 시스템의 스토리지 엔진으로 사용되는 RocksDB가 있다. 이 외에도 Aerospike (데이터베이스), 아마존 다이나모DB(Amazon DynamoDB), Memcached, Redis, ScyllaDB 등이 있다.
6. 한계점
키-값 데이터베이스는 잘 알려진 관계형 데이터베이스(RDB)와는 매우 다른 방식으로 작동한다. RDB는 데이터베이스 내의 데이터 구조를 명확하게 정의된 데이터 형식의 필드를 포함하는 일련의 테이블로 미리 정의한다. 이 데이터 형식을 데이터베이스 프로그램에 공개함으로써 많은 최적화를 적용할 수 있다. 이에 반해 키-값 시스템에서는 데이터를 단일의 비공개 집합으로 취급하며, 레코드마다 다른 필드를 가질 수 있다. 이는 상당한 유연성을 제공하며, 객체 지향 프로그래밍과 같은 현대적인 개념을 더 잘 추구한다. 대부분의 RDB처럼, 선택적 값은 자리 표시자나 입력 매개변수로 표현되지 않으므로, 키-값 데이터베이스에서는 동일한 데이터를 저장하는 데 사용되는 메모리가 훨씬 적으며, 특정 작업 부하에서 성능이 크게 향상될 수 있다.
성능, 표준화의 부족, 기타 문제로 인해 키-값 시스템은 오랫동안 틈새 용도로 제한되었다. 그러나 2010년 이후, 클라우드 컴퓨팅으로의 급속한 전환이 진행되면서 더 광범위한 NoSQL 전환의 일부로 다시 유행하고 있다.[3]
참조
[1]
웹사이트
Storage Engines
https://www.arangodb[...]
2020-11-16
[2]
문서
Oracle NoSQL Database
http://www.thinkmind[...]
[3]
웹사이트
Storage Engines
https://www.arangodb[...]
2020-11-16
[4]
문서
Oracle NoSQL Database
https://www.thinkmin[...]
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com