피보나치 힙
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
피보나치 힙은 최소 우선순위 큐를 구현하기 위한 자료구조이다. 트리의 집합으로 구성되며, 각 트리는 최소 힙 속성을 만족한다. 피보나치 힙은 잠재 비용을 사용하여 연산의 분할 상환 시간을 분석하며, 잠재 비용은 트리의 수와 표시된 노드의 수를 기반으로 계산된다. 주요 연산으로는 최소값 찾기, 병합, 삽입, 최소값 추출, 키 감소, 삭제 등이 있으며, 이러한 연산들은 특정 시간 복잡도를 가진다. 특히, 최소값 찾기, 병합, 삽입, 키 감소 연산은 상수 시간에 수행되지만, 최소값 추출과 삭제 연산은 O(log n)의 분할 상환 시간을 갖는다. 피보나치 힙은 이론적으로 효율적인 성능을 보이지만, 최악의 경우 선형 시간이 소요될 수 있으며, 실시간 시스템에는 적합하지 않을 수 있다.
더 읽어볼만한 페이지
- 힙 - 힙 (자료 구조)
힙은 이진 트리 기반의 자료구조로, 부모 노드의 키 값이 자식 노드보다 크거나 작도록 구성되며, 최대 힙과 최소 힙이 존재하고, 배열로 구현되어 삽입, 삭제 연산의 시간 복잡도는 O(log n)이며, 다양한 분야에 활용된다. - 힙 - 이진 힙
이진 힙은 완전 이진 트리 기반 자료 구조로 우선순위 큐 구현에 사용되며, 힙 속성을 유지하기 위해 삽입/제거 시 상향 또는 하향 힙 연산을 수행하고 배열로 효율적인 구현이 가능하다. - 분할 상환 자료 구조 - 스플레이 트리
스플레이 트리는 스플레이 연산을 통해 자가 균형을 유지하며 최근 접근 노드의 빠른 접근을 가능하게 하는 이진 탐색 트리로, 분할 상환 분석 시 평균적으로 O(log n)의 시간 복잡도를 가진다. - 분할 상환 자료 구조 - AVL 트리
AVL 트리는 높이 균형 속성을 가진 스스로 균형을 잡는 이진 탐색 트리로서, 높이를 log n으로 유지하여 탐색, 삽입, 삭제 연산의 시간 복잡도를 O(log n)으로 보장하고, 각 노드는 균형 계수를 사용하여 트리의 재구성을 돕는다. - 피보나치 수 - 레오나르도 피보나치
레오나르도 피보나치는 힌두-아라비아 숫자 체계를 유럽에 소개하고 피보나치 수열을 제시하여 중세 수학 발전에 기여했으며, 상업 발달을 돕는 《산반서》를 저술하고 황금비와 관련된 피보나치 수열이 다양한 분야에서 활용되도록 했다. - 피보나치 수 - 에두아르 뤼카
프랑스 수학자 에두아르 뤼카는 수론, 특히 뤼카 수열을 이용한 소수 판별법 개발과 "대포알 문제" 제시, 하노이 탑 퍼즐 발명 등 레크리에이션 수학 분야에 기여했다.
| 피보나치 힙 |
|---|
2. 구조
피보나치 힙은 최소 힙 속성을 만족하는 트리들의 집합이다. 즉, 자식 노드의 키는 항상 부모 노드의 키보다 크거나 같다. 이는 최소 키가 항상 트리들 중 한 트리의 루트에 있다는 것을 의미한다. 이항 힙에 비해, 피보나치 힙의 구조는 좀더 유연하다. 트리는 규정된 모양을 가지지 않는다. 극단적인 경우, 힙의 모든 구성요소가 서로 떨어진 별개의 트리에 존재할 수도 있다. 이러한 유연성으로 인해, 일부 연산은 “게으른” 방식으로 수행할 수 있다. 즉 나중 연산으로 작업을 연기(뒤로 미룸)하는 방식이다. 예를 들어, 힙의 병합은 두개의 리스트로 구성된 트리를 단순히 결합함으로써 가능하다.
그러나, 요구되는 실행시간을 달성하기 위해 어느 시점에 어떤 순서가 힙에 도입될 필요가 있다. 특히, 노드의 차수(여기서 차수는 자식의 수를 의미한다)는 상당히 낮게 유지된다. 즉 모든 노드는 차수가 많아야 O(log n)이 되며, 차수가 k인 노드를 루트로 하는 하위트리의 크기는 적어도 Fk+2이다. 여기서 Fk 은 k번째 피보나치 수이다. 이것은 루트가 아닌 노드에서는 최대 하나의 자식만 절단할 수 있다는 규칙에 의해 달성된다.
두번째 자식이 절단될 때, 이 노드 자체는 이것의 부모로부터 절단될 필요가 있으며, 이것이 새로운 트리의 루트가 된다. 최소값 삭제 연산을 수행하면 트리의 수가 감소되는데, 이 최소값 삭제 연산에서 트리가 함께 연결되기 때문이다.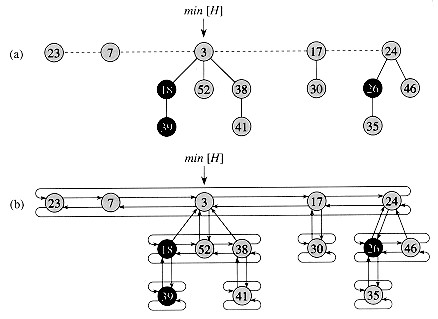
2. 1. 잠재 비용
피보나치 힙의 잠재 비용은 다음과 같이 계산된다.:Potential = t + 2m
여기서 t는 피보나치 힙 내의 트리 수이며, m은 표시(mark)된 노드의 수이다.
어떤 노드의 자식 중 적어도 하나가 절단되었다면 이 노드는 표시된다. 왜냐하면 이 노드는 다른 노드 (모든 루트는 표시되지 않는다)의 자식으로 만들어졌기 때문이다. 어떤 연산에 대한 분할상환된 시간은 실제 시간과 잠재비용의 차이에 c를 곱한 값을 더하여 구한다. 이때 c는 상수이다 (실제 시간에 대한 빅 오 표기법에서 매치되는 상수 요소를 찾아 선택한다).
그러므로, 힙 내에서 각 트리의 루트는 한 단위의 시간을 보유하게 된다. 이렇게 보유한 한 단위의 시간은 나중에 이 트리를 다른 트리에 연결할 때 사용할 수 있다. 그렇게 되면 결국 0 분할상환된 시간 안에 트리를 연결하게 된다. 표시된 각 노드 또한 두 단위의 시간을 보유한다. 한 단위 시간은 이 노드를 자신의 부모에서 절단할 때 사용할 수 있다. 만일 이 일이 발생하면, 이 노드는 부모가 되고, 나머지 두 번째 시간 단위는 이 노드 안에 여전히 보유한다. 다른 루트 노드가 하나의 시간 단위를 보유한 것처럼 말이다.
3. 연산
모든 트리의 루트는 순환 이중 연결 리스트를 사용하여 연결되어 있어 빠른 삭제와 결합을 허용한다. 각 노드의 자식 노드도 이러한 리스트를 사용하여 연결된다. 각 노드에 대해 자식 수와 노드의 마킹 여부를 유지한다. 피보나치 힙은 1984년에 마이클 L. 프레드먼(Michael L. Fredman)과 로버트 타잔에 의해 개발되었으며, 1987년에 과학 잡지에 처음 게재되었다.
피보나치 힙은 트리들의 집합으로, 최소 힙 속성을 만족한다. 즉, 자식 노드의 키는 항상 부모 노드의 키보다 크거나 같다. 이는 최소 키가 항상 트리 중 하나의 루트에 있음을 의미한다. 이항 힙에 비해 피보나치 힙의 구조는 더 유연하다. 트리는 정해진 형태를 갖지 않으며, 극단적인 경우 힙은 모든 요소를 개별 트리로 가질 수 있다. 이러한 유연성으로 인해 일부 연산을 지연 평가 방식으로 수행하여 작업을 나중 연산으로 연기할 수 있다. 예를 들어, 힙 병합은 두 개의 트리 목록을 연결하여 간단하게 수행되며, ''키 감소'' 연산은 때때로 노드를 부모로부터 잘라내어 새로운 트리를 형성한다.
하지만 원하는 실행 시간을 달성하려면 어느 시점에서 힙에 순서를 도입해야 한다. 특히 노드의 차수(여기서 차수는 직접적인 자식의 수를 의미함)는 매우 낮게 유지된다. 즉, 모든 노드는 최대 의 차수를 가지며 차수 인 노드를 루트로 하는 하위 트리의 크기는 최소 이다. 여기서 는 번째 피보나치 수이다. 이는 규칙에 의해 달성된다. 즉, 각 비 루트 노드에서 최대 하나의 자식만 잘라낼 수 있다. 두 번째 자식이 잘려나가면 노드 자체가 부모로부터 잘려나가 새로운 트리의 루트가 되어야 한다. 트리의 수는 ''delete-min'' 연산에서 감소하며, 여기서 트리는 서로 연결된다.
느슨한 구조의 결과로 일부 연산은 시간이 오래 걸릴 수 있고, 다른 연산은 매우 빠르게 수행될 수 있다. 상환 분석을 위해 잠재적 방법을 사용하는데, 이는 매우 빠른 연산이 실제보다 약간 더 오래 걸린다고 가정하는 방식이다. 이 추가 시간은 나중에 결합되어 느린 연산의 실제 실행 시간에서 빼진다. 나중에 사용할 수 있도록 절약된 시간의 양은 주어진 시점에서 잠재적 함수에 의해 측정된다. 피보나치 힙의 잠재성 는 다음과 같다.
:,
여기서 는 피보나치 힙의 트리 수이고, 은 표시된 노드의 수이다. 노드는 자식 중 적어도 하나가 잘린 경우 표시된다. 왜냐하면 이 노드는 다른 노드의 자식이 되었기 때문이다(모든 루트는 표시되지 않음). 연산의 상환 시간은 실제 시간과 곱하기 잠재성의 차이의 합으로 주어진다. 여기서 ''c''는 상수이다([빅 오 표기법|빅 오 표기법]]의 상수 인자와 일치하도록 선택됨).
따라서 힙의 각 트리의 루트는 1단위의 시간을 저장한다. 이 시간 단위는 나중에 이 트리를 다른 트리와 연결하는 데 상환 시간 0으로 사용할 수 있다. 또한 각 표시된 노드는 2단위의 시간을 저장한다. 하나는 노드를 부모로부터 잘라내는 데 사용할 수 있다. 이 경우 노드는 루트가 되고 두 번째 시간 단위는 다른 루트와 마찬가지로 노드에 저장된 상태로 유지된다.
피보나치 힙의 기본 연산은 다음과 같다:
- 삽입: 새로운 노드를 루트 리스트에 추가한다. (상세 내용)
- 최소값 찾기: 최소 키 값을 가진 노드를 가리키는 포인터를 유지한다. (상세 내용)
- 병합: 두 힙의 루트 리스트를 연결하고, 최소값 포인터를 업데이트한다. (상세 내용)
- 최소값 추출: 최소값 노드를 제거하고, 자식 노드들을 새로운 트리로 만든 후, 루트 노드들을 연결하여 차수를 줄인다. (상세 내용)
- 키 감소: 노드의 키 값을 감소시키고, 필요한 경우 부모 노드로부터 분리하여 새로운 루트로 만든다. (상세 내용)
- 삭제: 삭제할 노드의 키 값을 음의 무한대로 감소시킨 후, 최소값 추출 연산을 수행한다. (상세 내용)
피보나치 힙은 이항 힙과 매우 유사한 자료 구조이지만, 더 짧은 상환 실행 시간을 갖는다. 피보나치 힙은 그래프 내에서 최단 경로를 계산하기 위한 다익스트라 알고리즘과, 그래프의 최소 신장 트리를 계산하는 프림 알고리즘의 점근적인 처리 시간을 개선하는 데 사용된다.
특히, 삽입, 최소값 검색, 키 값 감소, 병합 연산은 상환 O(1) 시간 내에 완료된다. 삭제와 최소값 삭제 연산은 상환 O(log n) 시간 내에 완료된다. 즉, 빈 데이터 구조에서 시작하는 경우, 첫 번째 그룹의 "a"개 연산, 그리고 두 번째 그룹의 "b"개 연산으로 구성된 임의의 시퀀스는 O(a + b log a) 시간에 완료된다.
이항 힙에서는 이러한 일련의 연산에 O((a + b)log(n)) 시간이 걸린다. 따라서 a보다 b가 점근적으로 작은 경우, 피보나치 힙은 이항 힙보다 더 좋다.
빈 구조에서 일련의 연산에 걸리는 시간은 위에서 언급한 범위 내에 있지만, (매우 드물지만) 몇몇 연산에서는 매우 긴 시간이 걸릴 수 있다 (특히 키 값 감소, 요소의 삭제, 최소값의 삭제에 걸리는 시간은 최악의 경우 요소 수에 비례한다). 이러한 이유로 피보나치 힙 및 이를 사용하는 데이터 구조는 실시간 시스템에는 적합하지 않을 수 있다.
3. 1. 최소값 찾기 (Find-min)
최소값 찾기 연산은 최소 키를 가진 루트 노드에 대한 포인터를 유지하기 때문에 간단하다. 이 방식은 힙의 잠재 비용을 변경하지 않으므로, 실제 비용과 분할 상환된 비용 모두 상수(일정한 값)이다. 최소 키를 포함하는 루트 노드에 대한 포인터를 유지하면 시간에 최소값에 접근할 수 있으며, 이 포인터는 다른 연산 중에 업데이트되고 상수 시간 오버헤드만 추가된다.[2]3. 2. 병합 (Merge)
두 힙의 루트 리스트를 단순히 연결하고, 두 힙 중 작은 값을 최소값으로 설정한다. 이 연산은 상수 시간에 수행되며, 잠재 비용은 변하지 않는다.[1] 이 연산은 두 힙의 루트 노드 리스트를 결합하여 쉽게 구현 가능하다.[2] 따라서 분할상환 시간은 상수로 유지된다.[3][4]삽입 연산은 하나의 요소를 가진 새로운 힙을 만들어 결합하는 방식으로 동작한다. 이 또한 상수 시간이 소요되며, 잠재 비용은 트리 수 증가에 따라 1 증가하지만, 상환 시간은 여전히 일정하다.
3. 3. 삽입 (Insert)
삽입 연산은 하나의 구성요소를 가지고 새로운 힙을 생성한 후, 병합하는 방식으로 수행된다. 삽입에는 상수 시간이 걸리며, 잠재 비용은 1만큼 증가하는데, 이는 트리의 수가 늘어나기 때문이다. 따라서 분할 상환된 비용은 여전히 상수이다.
삽입 연산은 단일 노드를 가진 병합 연산의 특수한 경우로 볼 수 있다. 노드는 단순히 루트 리스트에 추가되어 잠재력을 1 증가시킨다. 따라서 상환 비용은 여전히 상수이다.
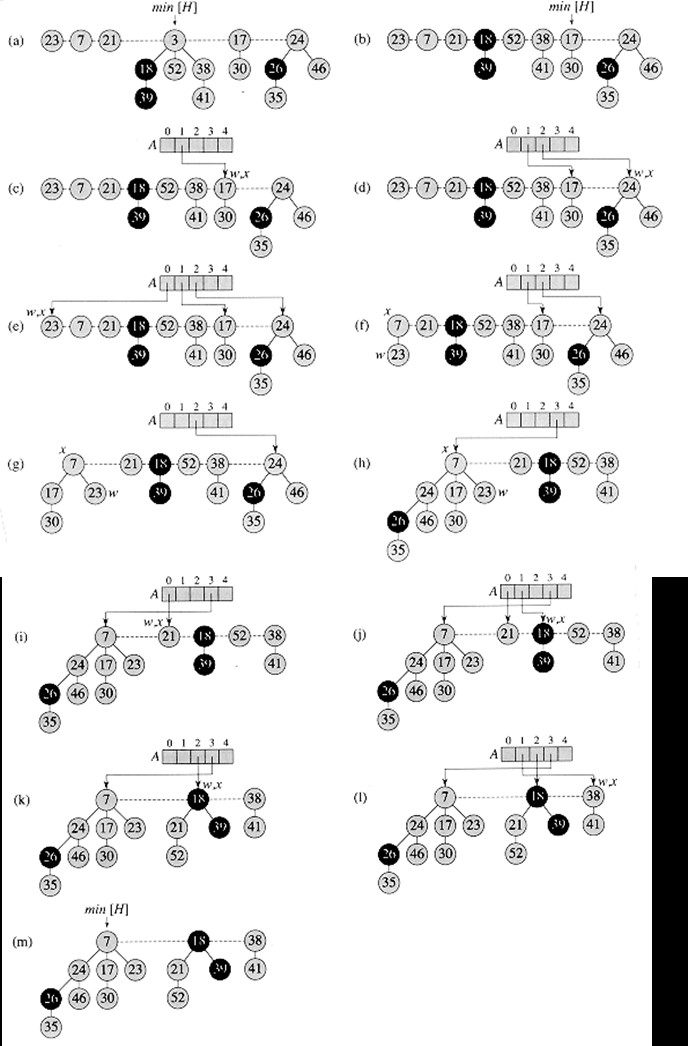
3. 4. 최소값 추출 (Delete-min)
최소값 추출(Delete-min) 연산은 세 단계로 수행된다.1. 최소값을 가진 루트를 제거한다. 이 루트의 자식 노드들은 각각 새로운 트리의 루트가 된다. 만약 자식의 수가 d개라면, 모든 새로운 루트를 처리하는 데 O(d) 시간이 소요되며, 잠재 비용은 d-1만큼 증가한다. 따라서 이 단계의 상환 실행 시간은 O(d) = O(log n)이다.
- -
2. 같은 차수를 가진 루트들을 반복적으로 연결하여 루트의 수를 줄인다. 두 루트 u와 v가 같은 차수를 가지면, 더 작은 키 값을 가진 노드를 루트로 만들고, 다른 노드를 그 자식으로 만든다. 이 작업은 모든 루트의 차수가 서로 다를 때까지 반복한다. 동일한 차수를 가지는 트리를 효율적으로 찾기 위해, 각 차수별로 루트를 가리키는 포인터를 저장하는 O(log n) 길이의 배열을 사용한다. 두 번째 루트가 동일한 차수를 가지는 것을 발견하면, 두 트리를 연결하고 배열을 업데이트한다. 실제 실행 시간은 O(log n + m)이다. (m은 두 번째 단계 시작 시점의 루트의 수) 마지막에는 최대 O(log n)개의 루트를 가지게 된다. (각각 서로 다른 차수를 가지기 때문) 그러므로 이 단계 전후의 잠재 비용 차이는 O(log n) - m이며, 충분히 큰 c값을 선택하면 상환 실행 시간은 O(log n)으로 단순화된다.
3. 남은 루트들을 확인하여 최소값을 찾고, 최소값 포인터를 업데이트한다. 이 작업에는 O(log n) 시간이 소요되며, 잠재 비용은 변하지 않는다.
결론적으로, 최소값 추출 연산의 전체 상환 실행 시간은 O(log n)이다.
아래의 그림은 최소값 추출의 상세한 동작을 보여준다.
3. 5. 키 감소 (Decrease-key)
키 감소 연산은 특정 노드의 키 값을 감소시킨다. 이 과정에서 힙의 속성이 위반될 수 있는데, 새 키 값이 부모 노드의 키 값보다 작아지는 경우가 해당된다. 이 경우, 해당 노드를 부모 노드로부터 분리한다. 만약 부모 노드가 루트가 아니라면, 분리된 노드는 '표시(marked)'된다. 이미 표시된 노드였다면, 해당 노드를 분리하고 부모 노드를 표시한다. 이 과정을 루트 노드나 표시되지 않은 노드를 만날 때까지 반복한다.이 과정에서 새로운 트리들이 생성될 수 있다. (이때 생성되는 신규 트리의 수를 k라고 하자). 첫 번째 트리를 제외한 나머지 새로 생성된 트리들은 원래 표시된 상태였지만, 루트가 되면서 표시되지 않은 상태(unmarked)가 된다. 이 과정에서 한 노드는 표시될 수 있다. 결과적으로, 표시된 노드의 수는 −(k − 1) + 1 = − k + 2 만큼 변경된다. 이러한 변화를 종합하면, 잠재 비용은 2(−k + 2) + k = −k + 4만큼 변경된다. 실제 절단 작업에는 O(k) 시간이 소요되므로, 충분히 큰 c 값을 선택하면 분할 상환된 실행 시간은 상수가 된다.
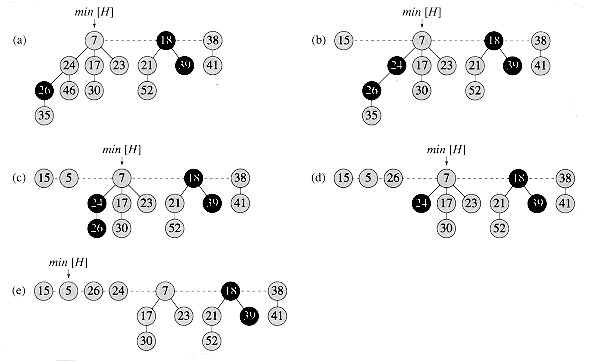
좀 더 구체적으로, 노드 의 키 값을 감소시켜 부모 노드보다 작아지면, 해당 노드는 부모 노드로부터 분리되어 표시되지 않은 새로운 루트가 된다. 또한, 최소 키 값보다 작아지면 최소 포인터가 업데이트된다.
이후, 의 부모 노드부터 시작하여 ''계단식 잘라내기''가 진행된다. 현재 노드가 표시되어 있으면 부모 노드로부터 분리되어 표시되지 않은 루트가 되고, 다음으로 원래 부모 노드를 확인한다. 이 과정은 표시되지 않은 노드 에 도달하면 중단된다. 가 루트가 아니라면, 표시된다. 이 과정에서 개의 새로운 트리가 생성된다고 가정하면, 를 제외한 나머지 새로운 트리들은 원래 표시를 잃게 된다. 종료 노드 는 표시될 수 있다. 따라서 표시된 노드의 수 변화는 에서 사이가 된다. 잠재력 변화는 이다. 잘라내기를 수행하는데 실제 시간이 소요되므로, 상각 시간은 가 되며, 가 충분히 크면 상수가 된다.
3. 6. 삭제 (Delete)
삭제 연산은 삭제하고자 하는 노드의 키 값을 무한히 작게 만들어 해당 노드가 전체 힙의 최소값이 되도록 한다. 그 후, 최소값 추출 함수를 호출하여 최소값이 된 노드를 제거한다. 이 과정의 상환 실행 시간은 O(log n)이다.그런 다음 의 부모 노드부터 시작하여 일련의 ''계단식 잘라내기''를 시작한다. 현재 노드가 표시되어 있으면 부모 노드에서 잘려나가 표시되지 않은 루트가 된다. 그런 다음 원래 부모 노드를 고려한다. 이 과정은 표시되지 않은 노드 에 도달하면 중단된다. 만약 가 루트가 아니라면, 표시된다. 이 과정에서 새로운 트리 개가 생성된다고 가정하자. 를 제외하고, 이 새로운 트리는 원래 표시를 잃는다. 종료 노드 는 표시될 수 있다. 따라서 표시된 노드의 수의 변화는 에서 사이이다. 잠재력의 변화는 이다. 잘라내기를 수행하는 데 필요한 실제 시간은 였다. 따라서, 상각 시간은 이며, 가 충분히 크면 상수가 된다.
4. Degree 경계의 증명
피보나치 힙의 분할 상환 성능은 힙 크기 n에 대해 임의의 트리 루트가 가지는 차수(자식 노드의 수)가 O(log n)이라는 사실에 기반한다. 여기서 차수가 d인 임의의 노드 x를 루트로 하는 (하위) 트리의 크기는 최소 Fd+2가 되어야 함을 보인다. (Fk는 k번째 피보나치 수이다.)
이러한 차수 경계는 모든 정수 d ≥ 0 에 대해 Fd+2 ≥ φd 라는 사실로부터 도출된다. (이는 귀납법으로 쉽게 증명 가능). 여기서 φ = ((1+√5))⁄2 ≈ 1.618 이며 황금비이다. 결과적으로 n ≥ Fd+2 ≥ φd 를 얻고, 양변에 밑이 φ인 로그를 취하면 d ≤ 〖log〗φ n 을 얻는다.
힙 내부의 임의의 노드 x를 고려한다 (x는 루트 노드일 필요는 없다). size(x)를 x를 루트로 하는 트리의 크기 (x 자신을 포함한 x의 자손 수)로 정의한다. 이제 x의 높이 (x에서 자손 리프(leaf) 노드까지의 가장 긴 단순 경로의 길이)에 대한 귀납법을 사용하여 size(x) ≥ Fd+2임을 증명한다. 여기서 d는 x의 차수이다.
기초 사례: x의 높이가 0이면, d = 0 이고 size(x) = 1 = F2이다.
귀납적 사례: x가 양의 높이를 가지고 차수 d > 0 이라고 가정한다. y1, y2, ..., yd를 x의 자식 노드라고 하고, x의 자식이 된 순서대로 인덱스를 붙인다 (y1이 가장 먼저, yd가 가장 나중에 x의 자식이 됨). c1, c2, ..., cd를 각각의 차수라고 하자.
2 ≤ i ≤ d인 각 i에 대해 ci ≥ i-2라고 주장한다. yi가 x의 자식이 되기 직전에, y1, ..., yi-1은 이미 x의 자식이었으므로, x는 그 시점에 적어도 i-1의 차수를 가졌다. 트리는 루트의 차수가 같을 때만 결합되므로, yi가 x의 자식이 될 당시 yi는 적어도 i-1의 차수를 가졌을 것이다. 이 시점부터 현재까지, yi는 최대 하나의 자식을 잃을 수 있다(마킹 과정에 의해 보장됨). 따라서 현재 차수 ci는 적어도 i-2이다.
모든 yi의 높이는 x의 높이보다 작으므로, 귀납 가설을 적용하면
size(x) ≥ 2 + Σ(i=2~d) size(yi) ≥ 2 + Σ(i=2~d) Fi = 1 + Σ(i=0~d) Fi. 를 얻을 수 있다.
노드 x와 y1은 각각 최소 1을 size(x)에 기여한다. 따라서 다음을 얻는다.
size(x) ≥ 2 + Σ(i=2~d) size(yi)
≥ 2 + Σ(i=2~d) Fi
= 1 + Σ(i=0~d) Fi
= Fd+2
마지막 단계는 피보나치 수에 대한 항등식을 이용한 것이다.
5. 최악의 경우
피보나치 힙은 몇몇 연산(삭제, 최소값 삭제)에서 최악의 경우 선형 시간(linear time)이 소요될 수 있다는 단점이 있다.[2] 이러한 이유 때문에 피보나치 힙은 실시간 시스템에는 적합하지 않을 수 있다.[2]
피보나치 힙과 동일한 최악의 경우의 분할상환 성능을 가지는 자료 구조를 만드는 것이 가능하다. 그러한 구조 중 하나가 브로달 큐인데,[4] 창안자는 "매우 복잡"하며 "[실제로] 적용할 수 없다."고 언급했다. 2012년에 개발된 엄격한 피보나치 힙은[5] 브로달 큐에 비해 더 단순한 구조를 가지면서도 동일한 최악의 경우 경계값을 가진다. 그러나 실험 결과에 따르면, 엄격한 피보나치 힙은 더 복잡한 브로달 큐보다 느리고, 기본적인 피보나치 힙보다도 느리게 수행된다는 것이 밝혀졌다.[6][7]
6. 수행시간
다음은 다양한 힙 자료 구조의 시간 복잡도를 나타낸 표이다. "''O''(''f'')" 및 "''Θ''(''f'')"의 의미는 빅 오 표기법을 참조한다. 연산 이름은 최소 힙을 가정한다.
| 연산 | find-최소 | delete-최소 | 감소-키 | 삽입 | 병합 | make-heap |
|---|---|---|---|---|---|---|
| 이진[9] | Θ(1) | Θ(log n) | Θ(log n) | Θ(log n) | Θ(n) | Θ(n) |
| 기울어진[11] | Θ(1) | O(log n) | O(log n) | O(log n) | O(log n) | Θ(n) |
| 왼쪽으로 치우친[12] | Θ(1) | Θ(log n) | Θ(log n) | Θ(log n) | Θ(log n) | Θ(n) |
| 이항[9][13] | Θ(1) | Θ(log n) | Θ(log n) | Θ(1) | Θ(log n) | Θ(n) |
| 기울어진 이항[14] | Θ(1) | Θ(log n) | Θ(log n) | Θ(1) | Θ(log n) | Θ(n) |
| 2–3 힙[16] | Θ(1) | O(log n) | Θ(1) | Θ(1) | O(log n) | Θ(n) |
| Bottom-up 기울어진[11] | Θ(1) | O(log n) | O(log n) | Θ(1) | Θ(1) | Θ(n) |
| 페어링[17] | Θ(1) | O(log n) | o(log n) | Θ(1) | Θ(1) | Θ(n) |
| 랭크-페어링[20] | Θ(1) | O(log n) | Θ(1) | Θ(1) | Θ(1) | Θ(n) |
| 피보나치 힙[9][21] | Θ(1) | O(log n) | Θ(1) | Θ(1) | Θ(1) | Θ(n) |
| 엄격한 피보나치[22] | Θ(1) | Θ(log n) | Θ(1) | Θ(1) | Θ(1) | Θ(n) |
| Brodal[23] | Θ(1) | Θ(log n) | Θ(1) | Θ(1) | Θ(1) | Θ(n)[24] |
피보나치 힙은 1984년에 마이클 L. 프레드먼(Michael L. Fredman)과 로버트 타잔에 의해 개발되었으며, 1987년에 과학 잡지에 처음 게재되었다.[2] 피보나치 힙은 다익스트라 알고리즘과 프림 알고리즘을 포함한 그래프 알고리즘의 실행 시간을 개선한 것으로 가장 잘 알려져 있다.
이항 힙과 유사하지만, 더 짧은 상환 실행 시간을 갖는다. 삽입, 최소값 검색, 키 값 감소, 병합 연산은 상환 O(1) 시간 내에 완료된다. 삭제와 최소값 삭제 연산은 상환 O(log n) 시간 내에 완료된다. 즉, 빈 데이터 구조에서 시작하는 경우, 첫 번째 그룹의 "a"개 연산, 그리고 두 번째 그룹의 "b"개 연산으로 구성된 임의의 시퀀스는 O(a + b log a) 시간에 완료된다.
이항 힙에서는 이러한 일련의 연산에 O((a + b)log(n)) 시간이 걸린다. 따라서 a보다 b가 점근적으로 작은 경우, 피보나치 힙은 이항 힙보다 더 좋다.
비어있는 구조에서 시작하는 일련의 연산의 총 실행 시간은 위에서 언급한 범위 내에 있지만, 일련의 일부 (극히 적은) 연산은 완료하는 데 매우 오래 걸릴 수 있다 (특히 delete-min은 최악의 경우 선형 실행 시간을 가진다).[3] 이러한 이유로 피보나치 힙 및 기타 분할 상환 데이터 구조는 실시간 시스템에는 적합하지 않을 수 있다.
피보나치 힙이 분할 상환 성능을 가지는 것과 동일한 최악의 경우 성능을 가진 데이터 구조를 만들 수 있다. 그러한 구조 중 하나인 브로달 큐는[4] 창시자의 말에 따르면 "매우 복잡"하며 "[실제로] 적용할 수 없다." 2012년에 발명된 엄격한 피보나치 힙은 (브로달 큐에 비해) 더 간단한 구조이며 동일한 최악의 경우 경계를 가진다.[5] 더 간단함에도 불구하고, 실험 결과 엄격한 피보나치 힙은 더 복잡한 브로달 큐보다 느리게, 그리고 기본적인 피보나치 힙보다 느리게 수행된다는 것을 보여준다.[6][7] Driscoll 등의 런-릴렉스드 힙은 병합을 제외한 모든 피보나치 힙 연산에 대해 좋은 최악의 경우 성능을 제공한다.[8] 최근의 실험 결과에 따르면 피보나치 힙은 퀘이크 힙, 위반 힙, 엄격한 피보나치 힙 및 랭크 페어링 힙을 포함한 대부분의 후기 파생물보다 실제로는 더 효율적이지만 페어링 힙 또는 배열 기반 힙보다 효율적이지 않다.[7]
참조
[1]
서적
Introduction to Algorithms
[2]
논문
The pairing heap: a new form of self-adjusting heap
https://www.cs.cmu.e[...]
[3]
웹사이트
http://www.cs.prince[...]
[4]
간행물
Worst-Case Efficient Priority Queues
https://archive.org/[...]
Society for Industrial and Applied Mathematics
[5]
학회자료
Strict Fibonacci heaps
http://www.cs.au.dk/[...]
[6]
서적
2019 International Conference on Information and Digital Technologies (IDT)
IEEE
2019-06
[7]
논문
A Back-to-Basics Empirical Study of Priority Queues
2014
[8]
논문
Relaxed heaps: An alternative to Fibonacci heaps with applications to parallel computation
1988-11
[9]
서적
Introduction to Algorithms
[10]
논문
Average Case Analysis of Heap Building by Repeated Insertion
http://www.stats.ox.[...]
2016-01-28
[11]
논문
Self-Adjusting Heaps
https://www.cs.cmu.e[...]
1986-02
[12]
서적
Data Structures and Network Algorithms
[13]
웹사이트
Binomial Heap {{!}} Brilliant Math & Science Wiki
https://brilliant.or[...]
2019-09-30
[14]
간행물
Optimal purely functional priority queues
1996-11
[15]
서적
Purely Functional Data Structures
[16]
간행물
Theory of 2–3 Heaps
https://ir.canterbur[...]
[17]
간행물
Proc. 7th Scandinavian Workshop on Algorithm Theory
http://john2.poly.ed[...]
Springer-Verlag
[18]
논문
On the Efficiency of Pairing Heaps and Related Data Structures
http://www.uqac.ca/a[...]
1999-07
[19]
학회자료
Towards a Final Analysis of Pairing Heaps
http://web.eecs.umic[...]
[20]
논문
Rank-pairing heaps
http://sidsen.org/pa[...]
2011-11
[21]
논문
Fibonacci heaps and their uses in improved network optimization algorithms
http://bioinfo.ict.a[...]
1987-07
[22]
학회자료
Strict Fibonacci heaps
http://www.cs.au.dk/[...]
[23]
간행물
Proc. 7th Annual ACM-SIAM Symposium on Discrete Algorithms
[24]
서적
Data Structures and Algorithms in Java
[25]
논문
Relaxed heaps: an alternative to Fibonacci heaps with applications to parallel computation
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com