B 트리
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
B 트리는 1970년 보잉 연구소에서 개발된 자기 균형 이진 탐색 트리로, 대용량 임의 접근 파일의 인덱스 페이지를 효율적으로 관리하기 위해 고안되었다. 각 노드는 최대 m개의 자식을 가지며, 루트와 리프 노드를 제외한 모든 노드는 최소 ⌈m/2⌉개의 자식을 갖는 구조를 가진다. B-트리는 데이터베이스의 인덱스 구현, 파일 시스템 등에서 활용되며, 검색, 삽입, 삭제 연산에 효과적이다. B+ 트리, B* 트리 등 다양한 변형이 존재하며, 데이터 접근 시간이 처리 시간보다 오래 걸리는 환경에서 다른 균형 탐색 트리보다 유리하다.
더 읽어볼만한 페이지
- B 트리 - B+ 트리
B+ 트리는 데이터베이스와 파일 시스템에서 널리 쓰이는 트리 자료 구조로, 모든 데이터는 리프 노드에 저장되고 내부 노드는 키와 포인터로 구성되어 효율적인 검색을 지원하며, 리프 노드들이 연결 리스트로 연결되어 있어 범위 검색에 특히 효율적이다. - 트리 구조 - 덴드로그램
덴드로그램은 데이터 분석에서 데이터 포인트 간 계층적 관계를 시각적으로 표현하는 나무 형태의 다이어그램으로, 군집 분석에서 클러스터 간 유사성을 나타내기 위해 활용되며 다양한 분야에 응용된다. - 트리 구조 - 프림 알고리즘
프림 알고리즘은 그래프의 최소 비용 신장 트리를 찾는 탐욕 알고리즘으로, 최소 가중치를 가진 간선을 선택하여 트리를 확장하며, 시간 복잡도는 사용되는 자료 구조에 따라 달라진다.
| B 트리 | |
|---|---|
| 개요 | |
| 유형 | 트리 |
| 고안자 | 루돌프 바이어, 에드워드 M. 맥크레이트 |
| 고안 연도 | 1970년 |
| 평균 공간 복잡도 | O(n) |
| 최악 공간 복잡도 | O(n) |
| 평균 탐색 복잡도 | O(log n) |
| 최악 탐색 복잡도 | O(log n) |
| 평균 삽입 복잡도 | O(log n) |
| 최악 삽입 복잡도 | O(log n) |
| 평균 삭제 복잡도 | O(log n) |
| 최악 삭제 복잡도 | O(log n) |
2. 역사
1970년 보잉 연구소의 루돌프 바이어와 에드워드 M. 맥크라이트가 B-트리를 처음 고안했다.[1] 이들은 대용량 인덱스를 효율적으로 관리하기 위해 B-트리를 개발했으며, 당시에는 인덱스 크기가 매우 커서 트리의 일부만 주 메모리에 저장할 수 있었다. 바이어와 맥크라이트의 논문은 1970년 7월에 처음 배포되었고, 나중에 ''Acta Informatica''에 게재되었다.
B-트리의 "B"가 무엇을 의미하는지는 명확하게 밝혀지지 않았다. 보잉(Boeing), 균형(balanced), 바이어(Bayer) 등 여러 추측이 있지만, 맥크라이트는 "B-트리의 B가 무엇을 의미하는지에 대해 더 많이 생각할수록 B-트리를 더 잘 이해하게 된다"고 말했다.[3][2]
2. 1. 한국에서의 B-트리 연구 및 활용
B-트리에 관한 한국어 자료는 용어 면에서 통일성을 보이지 않는다. 예를 들어, B-트리의 '차수'는 루트 노드를 제외한 노드에 들어갈 수 있는 최소 키의 개수로 정의되기도 하고,[4] 최대 자식 노드의 개수(최대 키 개수보다 1 많음)로 정의되기도 한다.[4]'리프'라는 용어 또한 자료마다 다르게 정의된다. 어떤 자료에서는 리프 레벨을 키의 최하위 레벨로 간주하지만, 다른 자료에서는 리프 레벨을 최하위 키보다 한 레벨 아래로 간주하기도 한다.[4]
이러한 용어 정의의 차이는 B-트리의 구현 방식에 따라 달라질 수 있는데, 어떤 구현에서는 리프가 전체 데이터 레코드를 포함하지만, 다른 구현에서는 리프가 데이터 레코드에 대한 포인터만 포함할 수도 있다.[4]
3. 정의
B-트리는 보잉 연구소에서 일하던 루돌프 바이어와 에드워드 M. 맥크라이트가 대용량 파일의 인덱스 관리를 위해 발명하였다.[1] 이들은 "B"가 무엇을 의미하는지 명확히 밝히지 않았으나, ''보잉'', ''균형(balanced)'', ''넓은(broad)'', ''무성한(bushy)'', ''바이어(Bayer)''등의 추측이 있다.[3][2]
커누스는 차수 ''m''의 B-트리가 다음 속성을 만족한다고 정의하였다.[3]
# 모든 노드는 최대 ''m''개의 자식을 갖는다.
# 루트와 리프 노드를 제외한 모든 노드는 최소 ⌈''m''/2⌉개의 자식을 갖는다.
# 루트 노드는 리프 노드가 아닌 이상 최소 두 개의 자식을 갖는다.
# 모든 리프 노드는 동일한 레벨에 나타난다.
# ''k''개의 자식을 가진 비-리프 노드는 ''k''−1개의 키를 포함한다.
B-트리는 다중 분기 균형 트리(밸런스 트리)이며, 1개의 노드에서 최대 ''m''개의 분기가 나올 때 차수 ''m''의 B-트리라고 한다. 루트와 잎을 제외한 "내부 노드"는 최소 ''m''/2개의 분기를 갖도록 구성된다.[27]
각 노드는 분기 수 - 1개의 키를 가지며, 분기1 ~ 분기''m'' 과 키1 ~ 키''m'' -1을 가질 때, 분기''i''에는 키''i'' -1보다 크고 키''i''보다 작은 키만을 보관한다.
B-트리 중 차수가 3인 것을 2-3 트리, 차수가 4인 것을 2-3-4 트리라고 부른다.
3. 1. 내부 노드
내부 노드(내부 노드라고도 함)는 리프 노드와 루트 노드를 제외한 모든 노드이다. 일반적으로 정렬된 요소 집합과 자식 포인터로 표현된다. 모든 내부 노드는 '''최대''' ''U''개의 자식과 '''최소''' ''L''개의 자식을 포함한다. 따라서 요소의 수는 자식 포인터 수보다 항상 1개 적다(요소 수는 ''L''−1과 ''U''−1 사이). ''U''는 2''L'' 또는 2''L''−1이어야 하므로 각 내부 노드는 최소 절반 이상 채워진다. ''U''와 ''L''의 관계는 두 개의 반쯤 채워진 노드를 결합하여 유효한 노드를 만들 수 있으며 하나의 가득 찬 노드를 두 개의 유효한 노드로 분할할 수 있음을 의미한다(부모 노드로 하나의 요소를 올릴 공간이 있는 경우). 이러한 속성을 통해 B-트리에 새 값을 삭제하고 삽입하고 B-트리 속성을 유지하도록 트리를 조정할 수 있다.[5]각 내부 노드의 키는 하위 트리를 나누는 분리 값으로 작용한다. 예를 들어, 내부 노드가 3개의 자식 노드(또는 하위 트리)를 갖는 경우, ''a''1과 ''a''2의 2개의 키를 가져야 한다. 가장 왼쪽 하위 트리의 모든 값은 ''a''1보다 작고, 가운데 하위 트리의 모든 값은 ''a''1과 ''a''2 사이에 있으며, 가장 오른쪽 하위 트리의 모든 값은 ''a''2보다 크다.
B-트리의 각 내부 노드는 다음과 같은 형식을 갖는다.
| pt0 | k0 | pt1 | pr0 | k1 | pt2 | pr1 | ... | kK-1 | ptK | prK-1 |
|---|
| &math> pt _0 when &math>k_0 존재 | &math>pt_i when &math>k_{i-1} and &math>k_i 존재 | &math>pt_i when &math>k_{i-1} 존재, and &math>k_i 존재하지 않음 | &math>pt_i when &math>k_{i-1} and &math>k_i 존재하지 않음 | &math>pr_i when &math>k_i 존재 | &math>pr_i when &math>k_i 존재하지 않음 |
|---|---|---|---|---|---|
| 모든 검색 키가 &math>k_0보다 작은 하위 트리를 가리킨다. | 모든 검색 키가 &math>k_{i-1}보다 크고 &math>k_i보다 작은 하위 트리를 가리킨다. | 모든 검색 키가 &math>k_{i-1}보다 큰 하위 트리를 가리킨다. | 여기서 &math>pt_i는 비어 있다. | 값이 &math>k_i와 같은 레코드를 가리킨다. | 여기서 &math>pr_i는 비어 있다. |
3. 2. 루트 노드
루트 노드는 트리의 최상위 노드이다. 자식 수의 상한은 내부 노드와 동일하지만 하한은 없다. 예를 들어, 전체 트리에 ''L''−1개 미만의 요소가 있는 경우 루트는 트리에 자식이 없는 유일한 노드가 된다.[27]3. 3. 리프 노드
커누스의 용어에서 "리프" 노드는 실제 데이터 객체/청크이다. 다른 저자들은 이러한 리프 노드보다 한 레벨 위에 있는 내부 노드를 "리프"라고 부르기도 한다.[4] 이 노드들은 키(최대 ''m''-1개, 루트가 아닌 경우 최소 ''m''/2-1개)와 데이터 객체/청크를 가리키는 포인터(키당 하나)만 저장한다.트리의 종단을 널 포인터와 같은 특수한 값으로 나타내는 경우, 모든 분기가 종단 기호로 되어 있는 노드를 잎으로 한다.[28] 반면, 일부 문헌에서는 종단을 나타내기 위해 키가 0개인 노드를 연결하고 이 노드를 잎으로 정의하기도 한다. 즉, 후자의 정의에서 잎 노드의 부모가 전자의 정의에서 잎 노드가 된다. 후자의 정의를 따르는 문헌에서는 "잎 노드는 키를 갖지 않는다"고 한다.
4. 노드 구조
B-트리의 노드는 일반적으로 키와 자식 노드를 가리키는 포인터의 정렬된 집합으로 표현된다. 각 내부 노드의 키는 하위 트리를 나누는 구분 값 역할을 한다.
;내부 노드
: 내부 노드(내부 노드라고도 함)는 리프 노드와 루트 노드를 제외한 모든 노드이다. 일반적으로 정렬된 요소 집합과 자식 포인터로 표현된다. 모든 내부 노드는 '''최대''' ''U''개의 자식과 '''최소''' ''L''개의 자식을 포함한다. 따라서 요소의 수는 자식 포인터 수보다 항상 1개 적다(요소 수는 ''L''−1과 ''U''−1 사이). ''U''는 2''L'' 또는 2''L''−1이어야 하므로 각 내부 노드는 최소 절반 이상 채워진다.
;루트 노드
: 루트 노드의 자식 수는 내부 노드와 동일한 상한을 갖지만 하한은 없다. 예를 들어, 전체 트리에 ''L''−1개 미만의 요소가 있는 경우 루트는 트리에 자식이 없는 유일한 노드가 된다.
;리프 노드
: 커누스의 용어에서 "리프" 노드는 실제 데이터 객체/청크이다. 이러한 리프 노드보다 한 레벨 위에 있는 내부 노드는 다른 저자가 "리프"라고 부르는 것이다.
다음은 노드 구조를 나타내는 표이다.
- '''K''': B-트리의 각 노드에 대한 잠재적 검색 키의 최대 수 (이 값은 전체 트리에서 상수)
- : 하위 트리를 시작하는 자식 노드에 대한 포인터
- : 데이터를 저장하는 레코드에 대한 포인터
- : 0부터 시작하는 노드 인덱스 의 검색 키
B-트리의 각 내부 노드는 다음과 같은 형식을 갖는다.
| pt0 | k0 | pt1 | pr0 | k1 | pt2 | pr1 | ... | kK-1 | ptK | prK-1 |
|---|
| when 존재 | when and 존재 | when 존재, and 존재하지 않음 | when and 존재하지 않음 | when 존재 | when 존재하지 않음 |
|---|---|---|---|---|---|
| 모든 검색 키가 보다 작은 하위 트리를 가리킨다. | 모든 검색 키가 보다 크고 보다 작은 하위 트리를 가리킨다. | 모든 검색 키가 보다 큰 하위 트리를 가리킵니다. | 여기서 는 비어 있다. | 값이 와 같은 레코드를 가리킵니다. | 여기서 는 비어 있습니다. |
B-트리의 각 리프 노드는 다음과 같은 형식을 갖는다.
| pr0 | k0 | pr1 | k1 | ... | prK-1 | kK-1 |
|---|
| when 존재 | when 존재하지 않음 |
|---|---|
| 값이 와 같은 레코드를 가리킵니다. | 여기서 는 비어 있습니다. |
노드 경계는 아래 표에 요약되어 있다.
5. 알고리즘
B-트리 알고리즘에 대한 문헌들은 용어 사용에 통일성이 부족하다.[4]
Bayer와 McCreight, Comer 등은 B-트리의 '''차수'''를 루트 노드를 제외한 노드가 가질 수 있는 최소 키 개수로 정의한다.[4] 그러나 Folk와 Zoellick은 최대 키 개수가 명확하지 않아 이 용어가 모호하다고 지적한다.[4] 예를 들어 차수가 3인 B-트리는 최대 6개 또는 7개의 키를 가질 수 있다. Knuth는 이 문제를 해결하기 위해 '''차수'''를 최대 자식 노드 개수(최대 키 개수보다 1 많음)로 정의한다.[4]
'''리프'''라는 용어 또한 일관성이 없다. Bayer와 McCreight는 리프 레벨을 키의 최하위 레벨로 보았지만, Knuth는 최하위 키보다 한 레벨 아래로 간주했다.[4] 어떤 설계에서는 리프가 전체 데이터 레코드를 포함할 수도 있고, 다른 설계에서는 데이터 레코드에 대한 포인터만 포함할 수도 있다.[4]
대부분의 저자는 노드에 들어갈 수 있는 키 개수가 고정되어 있다고 가정하지만, 실제로는 가변 길이 키가 사용될 수 있다.[4]
5. 1. 탐색
탐색은 일반적인 방식, 즉 이진 탐색 트리와 동일한 방식으로 수행된다. 루트에서 시작하여, 하향식으로 탐색 대상의 값을 구분 값과 비교하며 자식 포인터를 찾아나가는 과정으로 진행한다.[5]탐색은 이진 탐색 트리에서의 탐색과 유사하다. 루트에서 시작하여 트리는 상단에서 하단으로 재귀적으로 탐색된다. 각 레벨에서 탐색은 탐색 값을 포함하는 범위를 가진 자식 포인터(서브트리)로 시야를 좁힌다. 서브트리의 범위는 부모 노드에 포함된 값, 즉 키 값으로 정의된다. 이러한 제한 값은 분리 값이라고도 한다.
이진 탐색은 일반적으로 (하지만 반드시 그렇지는 않음) 노드 내에서 관심 있는 분리 값과 자식 트리를 찾기 위해 사용된다.
다음은 구현 예시이다. 여기서는 편의상 노드 내부를 탐색하는 데 선형 탐색을 사용했지만, 노드에 포함된 키의 수가 많은 경우에는 이진 탐색을 사용하여 속도를 높일 수 있다.
# 루트를 대상 노드로 하여 검색을 시작한다.
# 대상 노드가 존재하지 않는 경우, 검색값이 트리에 등록되어 있지 않은 것으로 간주하고 종료한다.
# i = 1
# 키i 가 존재하지 않거나, 검색값 < 키i 인 경우, 가지i 가 가리키는 노드를 대상으로 2로 이동한다.
# 검색값 = 키i 인 경우, 검색 성공으로 종료한다.
# i = i + 1 로 하고 4로 이동한다.
5. 2. 삽입
모든 삽입은 리프 노드에서 시작한다. 새로운 요소를 삽입하려면, 트리를 검색하여 새로운 요소가 추가되어야 하는 리프 노드를 찾는다. 삽입 처리는 항상 리프 노드를 대상으로 시작된다.[28]다음 단계를 통해 새 요소를 해당 노드에 삽입한다.
1. 노드가 허용된 최대 요소 수보다 적은 요소를 포함하는 경우, 새 요소를 위한 공간이 있다. 노드의 요소를 정렬된 상태로 유지하면서 새 요소를 노드에 삽입한다.
2. 그렇지 않으면 노드가 가득 찼으므로 다음과 같이 두 개의 노드로 균등하게 분할한다.
- 리프의 요소와 삽입하려는 새 요소 중에서 단일 중앙값을 선택한다.
- 중앙값보다 작은 값은 새 왼쪽 노드에 넣고 중앙값보다 큰 값은 새 오른쪽 노드에 넣으며, 중앙값은 분리 값 역할을 한다.
- 분리 값은 노드의 부모에 삽입되며, 부모 노드를 분할할 수 있다. 이러한 분할은 계속 진행된다. 노드에 부모가 없는 경우 (즉, 노드가 루트였던 경우) 이 노드 위에 새 루트를 생성한다 (트리의 높이를 증가시킨다).
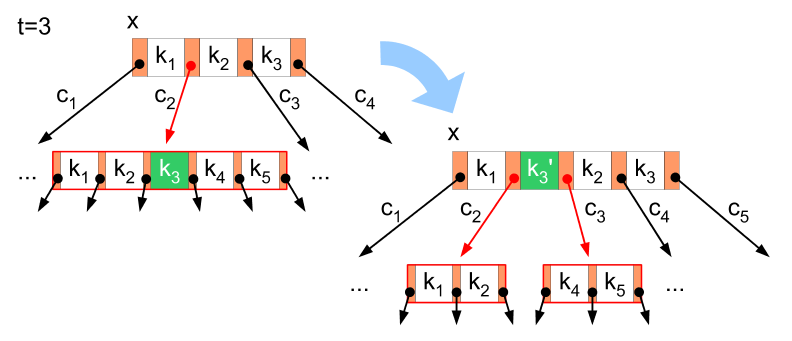
대상 노드가 이미 허용 가능한 최대 수의 키를 가지고 있는 경우, 노드의 '''분할''' 처리를 수행한다. 분할이 필요한 노드에서 키를 하나 선택하고 (일반적으로, 크기 순으로 중앙의 값을 선택한다), 이 키보다 작은 키만 포함하는 노드와, 더 큰 키만 포함하는 노드로 분할한다. 분할의 기준이 된 키는, 부모 노드로 이동한다.[28]
부모 노드에 대해 키를 추가할 때,[28] 부모 노드에서 키의 최대 수를 초과한 경우에는, 루트를 향해 순서대로 분할 처리를 적용해 나간다.[28] 루트까지 도달하여 루트가 분할된 경우에는, 트리의 높이가 한 단계 증가하게 된다. 분할 직후의 새로운 루트는, 키를 1개와 가지를 2개만 가지고 있다.
분할이 루트까지 모두 진행되면 단일 분리 값과 두 개의 자식 노드를 가진 새 루트가 생성된다. 이것이 내부 노드 크기에 대한 하한이 루트에 적용되지 않는 이유이다. 노드당 최대 요소 수는 ''U''−1이다. 노드가 분할될 때 하나의 요소가 부모로 이동하지만 하나의 요소가 추가된다. 따라서 최대 요소 수 ''U''−1을 두 개의 유효한 노드로 나눌 수 있어야 한다. 이 숫자가 홀수인 경우 ''U''=2''L''이고 새 노드 중 하나는 (''U''−2)/2 = ''L''−1개의 요소를 포함하므로 유효한 노드이며, 다른 노드는 요소 하나를 더 포함하므로 유효하다. ''U''−1이 짝수인 경우, ''U''=2''L''−1이므로 노드에는 2''L''−2개의 요소가 있다. 이 숫자의 절반은 ''L''−1이며, 이는 노드당 허용되는 최소 요소 수이다.
5. 3. 삭제
B-트리에서 삭제 연산은 삭제할 키를 찾는 것에서 시작한다. 키가 리프 노드에 있으면 해당 키를 노드에서 바로 삭제한다. 만약 키가 내부 노드에 있으면, 해당 키를 대체할 적절한 키를 찾아 교체해야 한다. 이때 대체 키는 삭제될 키의 왼쪽 하위 트리에서 가장 큰 값이거나, 오른쪽 하위 트리에서 가장 작은 값이며, 이들은 항상 리프 노드에 존재한다.[13]삭제 후에는 노드의 키 개수를 확인해야 한다. 만약 노드의 키 개수가 최소값보다 작아지면, 트리의 균형을 맞추기 위한 재균형 과정이 필요하다. 재균형은 리프 노드에서 시작하여 루트 노드 방향으로 진행되며, 회전(rotation) 또는 병합(merge) 연산을 통해 이루어진다.[13]
- 회전: 부족한 노드의 형제 노드가 최소 키 개수보다 많은 키를 가지고 있을 때 수행된다. 키를 형제 노드에서 부족한 노드로 이동시켜 균형을 맞춘다.[13]
- 병합: 부족한 노드의 형제 노드도 최소 키 개수만 가지고 있을 때 수행된다. 부족한 노드와 형제 노드를 합치고, 부모 노드에서 구분자 키를 가져와 하나의 노드로 만든다. 이로 인해 부모 노드의 키 개수가 줄어들 수 있으며, 부모 노드에 대해서도 재균형 과정이 필요할 수 있다.[13]
재균형 과정은 루트 노드까지 반복될 수 있다. 루트 노드는 최소 키 개수에 대한 제약이 없으므로, 루트 노드가 유일하게 부족한 노드가 되어도 문제가 되지 않는다. 루트 노드와 그 자식 노드들이 병합되면 트리의 높이가 줄어들 수 있다.[13]
6. B-트리의 활용
B-트리는 관계형 데이터베이스에서 표준 인덱스로 사용되며,[10] 디스크 캐시를 통해 검색 성능을 향상시킨다. B-트리는 삽입, 삭제 시 재귀 알고리즘으로 균형을 유지하고,[10] 키를 정렬된 순서로 유지하며,[10] 계층적 인덱스로 디스크 읽기를 최소화한다.[10] 레코드 삭제는 인덱스 변경 없이 표시로 관리되지만, 지연 삭제가 많으면 효율성이 저하될 수 있다.[11] 블록 내 여유 공간으로 삽입/삭제 문제를 해결하고, 근처 블록에서 공간을 찾아 인덱스를 조정한다.[10]
B-트리(또는 그 변형)는 파일 시스템에서 빠른 블록 접근을 지원한다. MS-DOS는 파일 할당 테이블(FAT)을 사용했지만 디스크가 커지면서 성능이 저하되었다. TOPS-20 (및 TENEX)는 B-트리와 유사한 트리를 사용했다. HFS+ 및 APFS, NTFS,[17] AIX(jfs2) 및 일부 리눅스 파일 시스템(예: Bcachefs, Btrfs 및 ext4)은 B-트리를 사용한다. B*-트리는 HFS 및 Reiser4에서, DragonFly BSD의 HAMMER은 수정된 B+-트리를 사용한다.[18]
6. 1. 데이터베이스
B-트리는 대부분의 관계형 데이터베이스에서 표준 인덱스 구현으로 사용된다.[10] 비관계형 데이터베이스에서도 B-트리를 활용하는 경우가 많다.[10]B-트리는 디스크 캐시에 자주 사용되는 데이터가 상주할 가능성이 높아, 실제 디스크 읽기 횟수를 줄여준다. 이를 통해 검색 성능을 크게 향상시킨다.
B-트리는 다음과 같은 특징을 통해 데이터베이스 성능을 향상시킨다.
- 효율적인 검색, 삽입, 삭제: B-트리는 데이터베이스에 삽입, 삭제가 발생할 때, 인덱스의 균형을 유지하기 위해 재귀 알고리즘을 사용한다.[10]
- 순차 접근 및 범위 검색: B-트리는 키를 정렬된 순서로 유지하여 순차 탐색을 지원한다.[10]
- 다양한 질의 처리: B-트리는 계층적 인덱스를 사용하여 디스크 읽기 횟수를 최소화한다.[10]
B-트리는 데이터베이스에서 레코드를 효율적으로 관리한다. 특히, 레코드 삭제 시 인덱스를 변경하지 않고 해당 레코드를 삭제된 것으로 표시하여 관리할 수 있다.[11] 정렬된 순서를 유지하며, 지연 삭제가 많아지면 검색 및 저장 효율성이 저하될 수 있다.[11]
정렬된 순차 파일에서는 삽입할 레코드를 위한 공간을 확보해야 하므로 삽입 속도가 느릴 수 있지만, B-트리는 블록 내에 여유 공간을 두어 이러한 문제를 해결한다.[10] 블록에 공간이 있으면 삽입과 삭제가 빠르며, 삽입이 블록에 맞지 않으면 근처 블록에서 여유 공간을 찾아 보조 인덱스를 조정한다.[10] 최상의 경우는 근처에 충분한 공간이 있어 블록 재구성을 최소화하는 것이며, 순서가 맞지 않는 디스크 블록을 사용할 수도 있다.[10]
6. 2. 파일 시스템
B-트리(또는 그 변형)는 특정 파일의 임의 블록에 대한 빠른 접근을 지원하기 위해 파일 시스템에서도 사용된다. 파일 블록 주소를 디스크 블록 주소로 변환하는 것이 핵심 과제이다.일부 운영 체제는 파일 생성 시 최대 크기를 할당하고 연속적인 디스크 블록을 할당하는 방식을 사용한다. 이 방식은 간단하지만 파일 크기가 제한된다. 다른 운영 체제는 파일 확장을 허용하지만, 논리 블록과 물리 블록 매핑이 복잡해진다.
MS-DOS는 파일 할당 테이블(FAT)을 사용하여 파일 할당을 관리했다. FAT는 각 디스크 블록에 대한 항목을 가지며, 파일 블록의 연결 리스트로 표현된다. 그러나 디스크가 커짐에 따라 FAT 방식은 성능 저하를 겪었다.
TOPS-20 (및 TENEX)는 B-트리와 유사한 0~2 레벨 트리를 사용했다. 이를 통해 두 번의 디스크 읽기로 파일 블록 위치를 찾고, 세 번째 읽기에서 데이터를 읽을 수 있었다.
HFS+ 및 APFS, NTFS,[17] AIX(jfs2) 및 일부 리눅스 파일 시스템(예: Bcachefs, Btrfs 및 ext4)은 B-트리를 사용한다.
B*-트리는 HFS 및 Reiser4 파일 시스템에서 사용된다.
DragonFly BSD의 HAMMER 파일 시스템은 수정된 B+-트리를 사용한다.[18]
7. B-트리의 변형
B-트리는 다양한 변형이 존재하며, B-트리라는 용어는 특정 디자인을 지칭하거나 일반적인 디자인 클래스를 지칭할 수 있다. 좁은 의미의 B-트리는 내부 노드에 키를 저장하지만, 잎 노드의 레코드에는 해당 키를 저장할 필요가 없다. 일반적인 클래스에는 B+ 트리, B* 트리 및 B*+ 트리와 같은 변형이 포함된다.
- B+ 트리: 내부 노드는 키만 저장하고 레코드에 대한 포인터는 잎 노드에 저장한다. 잎 노드는 순차적 접근을 빠르게 하기 위해 다음 잎 노드를 가리키는 포인터를 포함한다.
- B* 트리: 루트가 아닌 노드가 최소 2/3 이상 채워지도록 인접 내부 노드와 균형을 맞춘다.
- B*+ 트리: B+ 트리와 B* 트리의 기능을 결합한다.[7]
- 순서 통계 트리: B-트리는 키 순서로 N번째 레코드를 빠르게 검색하거나 두 레코드 사이의 레코드 수를 계산하고 기타 다양한 관련 작업을 수행할 수 있도록 한다.[8]
B-트리의 변형에 대한 주요 연구는 다음과 같다.
- Maintenance and Access of Large Ordered Indexes|대규모 정렬된 인덱스의 구성 및 유지보수영어:
- Binary B-Trees for Virtual Memory|가상 메모리를 위한 이진 B-트리영어:
7. 1. B+ 트리
B+ 트리에서 내부 노드는 레코드에 대한 포인터를 저장하지 않으므로 레코드에 대한 모든 포인터는 잎 노드에 저장된다. 또한 잎 노드는 순차적 접근을 가속화하기 위해 다음 잎 노드에 대한 포인터를 포함할 수 있다.[6] B+ 트리 내부 노드는 포인터가 적기 때문에 각 노드는 더 많은 키를 저장할 수 있어 트리가 얕아지고 검색 속도가 빨라진다.7. 2. B* 트리
B+ 트리와 유사하게 B* 트리는 루트 노드를 제외한 모든 노드가 최소 2/3 이상 채워지도록 하는 B-트리의 변형이다.[6] B* 트리는 내부 노드를 더 조밀하게 유지하기 위해 더 많은 인접 내부 노드의 균형을 맞춘다. B-트리에서 노드를 삽입하는 작업 중 가장 비용이 많이 드는 부분은 노드 분할이므로, B* 트리는 분할 작업을 가능한 한 늦추기 위해 만들어졌다.[6]이를 위해 노드가 가득 찼을 때 즉시 노드를 분할하는 대신, 키를 인접한 노드와 공유한다. 이 넘침 작업은 분할하는 것보다 덜 비용이 드는데, 새 노드에 대한 메모리를 할당하는 것이 아니라 기존 노드 간에 키를 이동하기만 하면 되기 때문이다. 삽입 시 먼저 노드에 여유 공간이 있는지 확인하고, 있다면 새 키를 노드에 삽입한다.
만약 노드가 가득 찬 경우(한 노드에서 하위 트리에 대한 최대 포인터 수인을 트리 차수로 할 때 개의 키가 있는 경우), 오른쪽 형제가 존재하고 여유 공간이 있는지 확인해야 한다. 오른쪽 형제에 개의 키가 있다면, 두 형제 노드 간에 가능한 한 균등하게 키를 재분배한다. 이를 위해 현재 노드의 개의 키, 삽입된 새 키, 부모 노드의 키 1개, 형제 노드의 개의 키를 개의 키의 정렬된 배열로 간주한다. 이 배열은 절반으로 분할되어 개의 가장 낮은 키는 현재 노드에 유지되고, 다음(가운데) 키는 부모에 삽입되고, 나머지는 오른쪽 형제로 이동한다. (새로 삽입된 키는 세 위치 중 하나에 배치될 수 있다.) 오른쪽 형제가 가득 차고 왼쪽은 그렇지 않은 상황은 유사하다. 두 형제 노드가 모두 가득 찬 경우 두 노드(현재 노드와 형제 노드)는 셋으로 분할되고 키가 하나 더 트리 상단인 부모 노드로 이동한다. 부모가 가득 찬 경우 넘침/분할 작업은 루트 노드 방향으로 전파된다. 노드 삭제는 삽입보다 다소 복잡하다.
8. 성능
B-트리는 데이터 양이 증가함에 따라 연결 리스트의 선형 성장보다 느리게 성장한다. 스킵 리스트와 비교하면 두 구조 모두 동일한 성능을 보이지만, B-트리는 ''n''의 증가에 더 잘 대응한다. T-트리는 주 메모리 데이터베이스 시스템용으로 유사하지만 더 콤팩트하다.[12]
참조
[1]
간행물
Organization and maintenance of large ordered indices
https://infolab.usc.[...]
Boeing Scientific Research Laboratories
1970-07
[2]
웹사이트
Stanford Center for Professional Development
http://scpd.stanford[...]
2011-01-16
[3]
웹사이트
4- Edward M McCreight
https://vimeo.com/73[...]
2013-08-30
[4]
문서
avoided the issue by saying an index element is a (physically adjacent) pair of (''x'', ''a'') where ''x'' is the key, and ''a'' is some associated information. The associated information might be a pointer to a record or records in a random access, but what it was didn't really matter. states, "For this paper the associated information is of no further interest."
[5]
서적
Fundamentals of database systems
Pearson Education
[6]
서적
Algorithms and Data Structures
Akademska misao
[7]
논문
SQLite RDBMS Extension for Data Indexing Using B-tree Modifications
https://ispranprocee[...]
Institute for System Programming of the RAS (ISP RAS)
2019-09-10
[8]
웹사이트
Counted B-Trees
http://www.chiark.gr[...]
2010-01-25
[9]
서적
Product Manual: Barracuda ES.2 Serial ATA, Rev. F., publication 100468393
http://www.seagate.c[...]
Seagate Technology LLC
2008
[10]
서적
Designing Data-Intensive Applications
https://www.academia[...]
"[[O'Reilly Media]]"
2017
[11]
문서
Jan Jannink.
[12]
문서
Comer}};
[13]
웹사이트
Deletion in a B-tree
https://www.cs.rhode[...]
2022-05-24
[14]
웹사이트
Cache Oblivious B-trees
http://www.cs.sunysb[...]
State University of New York (SUNY) at Stony Brook
2011-01-17
[15]
문서
For FAT, what is called a "disk block" here is what the FAT documentation calls a "cluster", which is a fixed-size group of one or more contiguous whole physical disk
[16]
문서
Two of these were reserved for special purposes, so only 4078 could actually represent disk blocks (clusters).
[17]
웹사이트
Inside Win2K NTFS, Part 1
http://msdn2.microso[...]
"[[MSDN|Microsoft Developer Network]]"
2008-04-18
[18]
웹사이트
The HAMMER Filesystem
https://www.dragonfl[...]
2008-06-21
[19]
논문
Efficient locking for concurrent operations on B-trees
[20]
웹사이트
An In-Depth Analysis of Concurrent B-tree Algorithms
http://www.dtic.mil/[...]
2022-10-21
[21]
웹사이트
Downloads - high-concurrency-btree - High Concurrency B-Tree code in C - GitHub Project Hosting
https://github.com/m[...]
2014-01-27
[22]
웹사이트
Lockless concurrent B-tree index meta access method for cached nodes
http://www.freepaten[...]
[23]
웹사이트
Introducing maple trees (LWN.net)
https://lwn.net/Arti[...]
[24]
웹사이트
Maple Tree (The Linux Kernel documentation)
https://docs.kernel.[...]
[25]
웹사이트
Introducing the Maple Tree (LWN.net / github)
https://lwn.net/Arti[...]
[26]
서적
Proceedings of the 1970 ACM SIGFIDET (Now SIGMOD) Workshop on Data Description, Access and Control - SIGFIDET '70
Boeing Scientific Research Laboratories
1970-07
[27]
문서
奥村
[28]
문서
奥村
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com