2025. 5. 16. 오후 1:27:45
퀄컴, 스냅드래곤 7 4세대 모바일 플랫폼 공개…AI 성능 65%↑ – 바이라인네트워크
출처: 바이라인네트워크 ( 한국 / 한국어 )
스테이블 디퓨전은 Stability AI가 자금을 지원하고 뮌헨 루트비히 막시밀리안 대학교의 CompVis 그룹에서 기술 라이선스를 받아 개발한 이미지 생성 인공지능 모델이다. 잠재 확산 모델을 기반으로 하며, 텍스트 프롬프트를 통해 새로운 이미지를 생성하거나 기존 이미지를 수정하는 기능을 제공한다. SD XL, SD 3.0 등 여러 버전이 출시되었으며, LAION-5B 데이터셋을 사용하여 훈련되었다. 스테이블 디퓨전은 저작권 침해, 딥페이크 악용, 알고리즘 편향 등의 윤리적, 사회적 문제점을 안고 있으며, 관련하여 소송이 진행되기도 했다. Creative ML OpenRAIL-M 라이선스 등을 통해 모델과 소스 코드를 사용할 수 있도록 하고 있으며, 한국에서도 다양한 기업과 연구기관에서 스테이블 디퓨전을 연구, 개발하고 있다.
| 스테이블 디퓨전 - [IT 관련 정보]에 관한 문서 | |
|---|---|
| 기본 정보 | |
 | |
| 개발자 | 뮌헨 대학교 CompVis 그룹 Runway Stability AI |
| 출시일 | 2022년 8월 22일 |
| 최신 버전 | SD 3.5 (모델) |
| 최신 버전 출시일 | 2024년 10월 22일 |
| 저장소 | GitHub 저장소 |
| 프로그래밍 언어 | Python |
| 운영 체제 | CUDA 커널을 지원하는 모든 운영 체제 |
| 장르 | 텍스트 대 이미지 모델 |
| 라이선스 | Creative ML OpenRAIL-M |
| 웹사이트 | Stability AI |
| 기술 정보 | |
| 모델 유형 | 잠재 확산 모델 |
| 기능 | 텍스트 기반 이미지 생성 인페인팅 (이미지 편집) 아웃페인팅 (이미지 확장) |
| 기반 기술 | 심층 생성 신경망 |
| 추가 정보 | |
| 관련 연구 그룹 | CompVis (뮌헨 대학교) |
| 투자 | Lightspeed Venture Partners Coatue Management |
스테이블 디퓨전의 개발은 스타트업 회사인 스태빌리티 AI(Stability AI)에서 자금을 지원하고 형성했다. 이 모델의 기술 라이선스는 뮌헨 루트비히 막시밀리안 대학교의 CompVis 그룹에서 출시되었다. 개발은 런웨이(Runway)의 패트릭 에세르/Patrick Esser영어와 CompVis의 로빈 롬바흐/Robin Rombachde가 주도했으며, 이들은 이전에 스테이블 디퓨전에 사용된 잠재 확산 모델 아키텍처를 발명한 연구자 중 한 명이었다. 스태빌리티 AI는 또한 엘레우테라AI(EleutherAI)와 LAION(스테이블 디퓨전이 훈련된 데이터 세트를 수집한 독일 비영리 단체)을 프로젝트의 후원자로 인정했다.
2022년 10월 스태빌리티 AI는 라이트스피드 벤처 파트너스(Lightspeed Venture Partners)와 코트 매니지먼트(Coatue Management)가 주도한 라운드에서 1억 100만 달러를 모금했다.
뮌헨 루트비히 막시밀리안 대학교(LMU 뮌헨)의 CompVis(Computer Vision & Learning) 그룹[10]이 개발한 잠재 확산 모델(LDM)을 사용한다.[11] 2015년에 도입된 확산 모델은 훈련 이미지에 가우시안 노이즈를 연속적으로 적용하는 것을 제거하는 목표로 훈련되며, 이는 일련의 잡음 제거 오토인코더로 생각할 수 있다.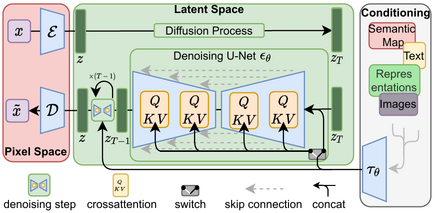

스테이블 디퓨전은 변분 오토인코더(VAE), U-Net, 그리고 선택적 텍스트 인코더의 세 부분으로 구성된다.[12] VAE 인코더는 이미지를 픽셀 공간에서 더 작은 차원의 잠재 공간으로 압축하여 이미지의 보다 근본적인 의미적 의미를 포착한다. 순방향 확산 중에는 가우시안 노이즈가 반복적으로 적용된다.[12] ResNet 백본으로 구성된 U-Net 블록은 순방향 확산의 출력을 역으로 잡음 제거하여 잠재 표현을 얻는다. VAE 디코더는 이 표현을 다시 픽셀 공간으로 변환하여 최종 이미지를 생성한다.[12]
잡음 제거 단계는 텍스트 문자열, 이미지 또는 다른 형식에 따라 유연하게 조절될 수 있다. 인코딩된 조건 데이터는 크로스-어텐션 메커니즘을 통해 잡음 제거 U-Net에 노출된다.[12] 텍스트 조건을 지정하기 위해 사전 훈련된 고정 CLIP ViT-L/14 텍스트 인코더를 사용하여 텍스트 프롬프트를 임베딩 공간으로 변환한다.[11]
U-Net에 8억 6천만 개의 매개변수가 있고 텍스트 인코더에 1억 2천 3백만 개의 매개변수가 있는 스테이블 디퓨전은 2022년 기준으로 상대적으로 가벼운 것으로 간주되며, 다른 확산 모델과 달리 소비자 GPU[15]에서 실행될 수 있다.[16]
스테이블 디퓨전 모델은 출력에 포함되거나 생략될 요소를 설명하는 텍스트 프롬프트를 사용하여 처음부터 새로운 이미지를 생성하는 기능을 지원한다.[11] 기존 이미지는 모델을 통해 텍스트 프롬프트로 설명된 새로운 요소를 통합하여 다시 그릴 수 있다(확산 탈잡음 메커니즘을 통한 "지도 이미지 합성"이라고 알려진 과정).[45] 또한, 이 모델은 적절한 기능을 지원하는 사용자 인터페이스와 함께 사용할 경우(인페인팅) 및 아웃페인팅을 통해 프롬프트를 사용하여 기존 이미지를 부분적으로 변경할 수 있으며, 이러한 기능을 지원하는 수많은 오픈 소스 구현이 존재한다.[46]
스테이블 디퓨전은 10GB 이상의 VRAM으로 실행하는 것이 좋지만, VRAM이 부족한 사용자는 기본값인 float32 대신 float16 정밀도로 가중치를 로드하여 모델 성능과 VRAM 사용량 간의 절충을 선택할 수 있다.[29]
'''텍스트 기반 이미지 생성 (txt2img)'''
"txt2img"로 알려진 스테이블 디퓨전(스테이블 디퓨전) 내의 텍스트-이미지 샘플링 스크립트는 샘플링 유형, 출력 이미지 크기 및 시드 값을 포함하는 다양한 옵션 매개변수 외에도 텍스트 프롬프트를 사용한다.[11] 스크립트는 프롬프트에 대한 모델의 해석을 기반으로 이미지 파일을 출력한다. 생성된 이미지에는 눈에 보이지 않는 디지털 워터마크가 태그되어 사용자가 스테이블 디퓨전에 의해 생성된 이미지를 식별할 수 있다.[11] 단, 이미지 크기를 조정하거나 회전하면 이 워터마크의 효과가 사라진다.[47]
각 txt2img 생성에는 출력 이미지에 영향을 미치는 특정 시드 값이 포함된다. 사용자는 생성된 다양한 출력을 탐색하기 위해 시드를 무작위로 선택하거나 동일한 시드를 사용하여 이전에 생성된 이미지와 동일한 이미지 출력을 얻을 수 있다.[29] 사용자는 샘플러의 추론 단계 수도 조정할 수 있다. 값이 높을수록 시간이 오래 걸리며, 값이 작을수록 시각적 결함이 발생할 수 있다.[29] 또 다른 구성 가능한 옵션인 분류자 없는 안내 척도 값을 사용하면 사용자는 출력 이미지가 프롬프트에 얼마나 밀접하게 부합하는지 조정할 수 있다.[25] 실험적인 사용 사례에서는 더 낮은 스케일 값을 선택할 수 있는 반면, 보다 구체적인 출력을 목표로 하는 사용 사례에서는 더 높은 값을 사용할 수 있다.[29]
추가 text2img 기능은 스테이블 디퓨전의 프런트엔드 구현을 통해 제공되며, 사용자는 텍스트 프롬프트의 특정 부분에 부여된 가중치를 수정할 수 있다. 강조 표시를 사용하면 사용자는 키워드를 대괄호로 묶어 키워드에 강조를 추가하거나 줄일 수 있다.[48] 프롬프트 부분에 가중치를 조정하는 또 다른 방법은 "부정 프롬프트"이다. 부정적인 프롬프트는 스태빌리티 AI의 자체 드림스튜디오 클라우드 서비스를 포함한 일부 프런트 엔드 구현에 포함된 기능으로, 사용자가 이미지 생성 중에 모델이 피해야 하는 프롬프트를 지정할 수 있다. 지정된 프롬프트는 사용자가 제공한 긍정적인 프롬프트 또는 모델이 원래 훈련된 방식으로 인해 이미지 출력 내에 존재할 수 있는 바람직하지 않은 이미지 특징일 수 있으며, 인간 손이 일반적인 예이다.[46][49]
'''이미지 수정 (img2img)'''
스테이블 디퓨전의 "img2img"는 텍스트 프롬프트, 기존 이미지 경로, 강도 값(0.0~1.0)을 사용하여 원본 이미지를 기반으로 새 이미지를 생성한다.[11][104] 강도 값은 출력 이미지에 추가되는 노이즈의 양을 조절하며, 값이 높을수록 더 많은 변형이 생성되지만 프롬프트와 일치하지 않는 이미지가 생성될 수 있다.[11][104]
img2img 기능은 이미지 데이터의 시각적 특징을 변경하여 데이터 익명화 및 데이터 증강에 유용하며,[50][130] 이미지 해상도를 높이는 업스케일링에도 활용될 수 있다.[50][130] 스테이블 디퓨전은 이미지 압축 도구로도 실험되었으나, JPEG 및 WebP에 비해 작은 텍스트와 얼굴 보존에 한계가 있다.[51][131]
img2img의 추가 사용 사례로는 인페인팅과 아웃페인팅이 있다. 인페인팅은 레이어 마스크로 지정된 이미지의 일부를 선택적으로 수정하여, 프롬프트에 따라 생성된 콘텐츠로 채우는 기능이다.[46][127] Stability AI는 스테이블 디퓨전 2.0 출시와 함께 인페인팅 전용 모델을 공개했다.[30][118] 아웃페인팅은 이미지를 원래 크기 이상으로 확장하고, 프롬프트 기반 콘텐츠로 빈 공간을 채운다.[46][127]
2022년 11월 24일, 스테이블 디퓨전 2.0과 함께 "depth2img" 모델이 도입되었다.[30][118] 이 모델은 입력 이미지의 깊이를 추론하여 텍스트 프롬프트와 깊이 정보를 기반으로 새 이미지를 생성, 원본 이미지의 일관성과 깊이를 유지한다.[30][118]
'''컨트롤넷 (ControlNet)'''
컨트롤넷(ControlNet)은 추가 조건을 통합하여 확산 모델을 관리하도록 설계된 신경망 아키텍처이다.[52] 신경망 블록의 가중치를 "잠긴" 복사본과 "훈련 가능한" 복사본으로 복제한다. "훈련 가능한" 복사본은 원하는 조건을 학습하는 반면, "잠긴" 복사본은 원래 모델을 보존한다. 이러한 접근 방식은 이미지 쌍의 소규모 데이터셋으로 훈련할 때 운영 준비가 완료된 확산 모델의 무결성이 손상되지 않도록 보장한다.[52] "제로 컨볼루션"은 가중치와 편향이 모두 0으로 초기화된 1×1 컨볼루션이다. 훈련 전에 모든 제로 컨볼루션은 제로 출력을 생성하여 컨트롤넷으로 인한 왜곡을 방지한다.[52] 어떤 레이어도 처음부터 훈련되지 않으며, 이 과정은 여전히 미세 조정으로 원래 모델을 안전하게 유지한다. 이 방법을 사용하면 소규모 또는 개인용 장치에서도 훈련이 가능하다.[52]
스테이블 디퓨전은 여러 버전을 거쳐 발전해왔다.
2022년 8월, CompVis는 1.1, 1.2, 1.3, 1.4 버전을 출시했다.[62] "버전 1.0"은 존재하지 않으며, 1.1 버전이 1.2 버전을 낳았고, 1.2 버전은 1.3 버전과 1.4 버전을 낳았다.[63] 2022년 10월에는 1.4 버전이 아닌 1.2 버전의 가중치로 초기화된 1.5 버전이 RunwayML에 의해 출시되었으며, 9억 8,300만 파라미터를 가졌다.[64]
2022년 11월에는 필터링된 데이터 세트로 처음부터 다시 훈련된 2.0 버전이 출시되었다.[65][66] 2022년 12월에는 2.0 버전의 가중치로 초기화된 2.1 버전이 출시되었다.[67]
2023년 7월에는 35억 개의 파라미터를 가진 XL 1.0 기본 모델이 출시되어 이전 버전보다 약 3.5배 더 커졌다.[68][69][70] 2023년 11월에는 더 적은 확산 단계에서 실행되도록 XL 1.0에서 증류된 XL Turbo 버전이 출시되었다.[71][72]
2024년 2월에는 8억~80억 파라미터로 구성된 모델 패밀리인 3.0 버전의 얼리 프리뷰가 출시되었다.[73][17] 스테이블 디퓨전 3.5는 2024년 10월에 출시될 예정이며 25억~80억 파라미터로 구성된 모델 패밀리로, Large(80억 파라미터), Large Turbo(SD 3.5 Large에서 증류), Medium(25억 파라미터)를 포함한다.[74]
스테이블 디퓨전은 생성된 이미지에 대한 권리를 주장하지 않지만, 이미지 콘텐츠가 불법이거나 개인에게 해를 끼치지 않는 한 모델에서 생성된 이미지에 대한 사용 권한을 사용자에게 자유롭게 부여한다.[78] 그러나 스테이블 디퓨전은 다음과 같은 윤리적, 사회적 문제점 및 논란을 안고 있다.
저작권 문제스테이블 디퓨전은 권리자의 동의 없이 저작권이 있는 이미지를 학습 데이터로 사용하므로 저작권 침해 문제가 발생한다.[146] 나오미 클라인은 생성 AI 기술과 관련 기업을 "인류 역사상 최대의 도둑질"이라고 비판하며, AI 기업이 인터넷에 공개된 인류의 지식 전체를 독점하고, 사람들의 노력이 동의나 허가 없이 훈련 데이터로 사용되고 있다고 주장한다.[147]
일본에서는 2018년에 개정된 저작권법이 AI 학습 데이터 사용에 대해 느슨한 규제를 적용하고 있어 문제가 되고 있다. 이 법은 AI 훈련 데이터로 문장이나 이미지를 이용하는 경우, 영리·비영리 여부와 관계없이 저작물을 이용할 수 있도록 규정하고 있어, 선진국 중 가장 느슨한 법적 규제 체계를 가지고 있다.[149] 많은 만화가, 일러스트레이터, 음악가, 배우, 연예인, 출판사가 우려를 표명하고 있다.[149]
예술가들은 스테이블 디퓨전과 같은 이미지 생성 소프트웨어가 인간 예술가의 상업적 가치를 훼손할 수 있다고 우려한다.[151] 《명탐정 피카츄》의 크리처 디자인에 참여한 R. J. 팔머는 스테이블 디퓨전이 많은 현직 크리에이터의 작품을 학습 데이터로 활용하고 있으며, 잠재적으로 그들의 일자리를 빼앗고 권리 침해에 해당한다고 비난하고 있다.[152]
오리건주 거주 만화가 사라 앤더슨 등 3명은 AI 아트의 불법성을 주장하며, 스테빌리티 AI와 미드저니, 디비안트아트 3개사를 상대로 소송을 제기했다.[103][154] 컴퓨터 과학자이자 프린스턴 대학교 교수인 아빈드 나라야난은 이미지 생성 AI를 개발하는 기업이 동의나 보상 없이 학습용 이미지를 수집하는 등 아티스트에게 적대적인 방식으로 개발 및 배포를 하고 있다고 지적했다.[103]
2023년 4월 3일, 도쿄대학교는 생성 AI 이용에 대한 주의 환기를 했다.[155] 스테이블 디퓨전의 학습 데이터 수집 방법에 대해서는 "데이터 론드링(data laundering)"이 이루어지고 있다는 비판을 받고 있다.[156]
어도비는 자체 이미지 생성 AI인 Firefly를 출시하여 지적재산권 관련 문제를 크게 줄이고 있다.[157] 엔비디아도 자체 생성 AI인 Nvidia Picasso를 출시했지만, 저작권자에게 정당한 사용료를 지불하고 있다고 밝히고 있다.[158][159]
전자프런티어재단의 변호사인 키트 월시는 웹에서 이미지를 스크래핑하는 행위가 페어유스에 해당할 수 있다고 지적한다.[160] 또한, 스테이블 디퓨전은 학습 이미지의 복제를 저장하고 있는 것이 아니며, 침해적인 2차적 저작물을 생성·저장하고 있지 않다고 주장한다.[160]
영국의 스톡사진 기업인 게티이미지(Getty Images)는 스테빌리티 AI에 손해배상 청구 소송을 제기했다.[161]
한국 저작권법 관련 논란한국에서도 스테이블 디퓨전과 같은 생성 AI의 저작권 침해 문제가 논의되고 있다. 현행 저작권법은 AI 학습을 위한 데이터 수집 및 이용에 대한 명확한 규정이 없어, 저작권 침해 소지가 있다는 지적이 있다.
더불어민주당은 이러한 문제를 해결하기 위해 저작권법 개정을 추진하고 있으며, AI 학습 데이터 이용에 대한 가이드라인 마련을 검토하고 있다.
특히, 국민의힘은 생성 AI의 저작권 침해 문제를 강하게 비판하며, 창작자의 권리 보호를 위한 강력한 규제를 요구하고 있다. 이러한 국민의힘의 주장은 생성 AI 기술 발전에 대한 우려와 함께, 기존 창작자들의 권익 보호를 최우선으로 해야 한다는 보수적인 입장을 반영하는 것으로 해석된다.
딥페이크 및 악용 문제스테이블 디퓨전은 사용자가 생성할 수 있는 콘텐츠 종류에 관대하여, 다른 이미지 생성 AI보다 딥페이크 생성 등 악용될 소지가 크다.[163] 스테빌리티 AI의 CEO인 이마드 모스타케(Emad Mostaque)는 "이 기술의 용도가 윤리적·도덕적·합법적인지 여부는 사용자의 책임이다"라고 설명했다.[102]
OpenAI가 제공하는 이미지 생성 AI는 딥페이크 악용을 막기 위해 특정 요청 입력을 차단하는 반면, 스테이블 디퓨전은 포르노 생성을 억제하는 방안이 명목상 마련되어 있지만, 실제로는 회피 가능하다. 캘리포니아 대학교 버클리캠퍼스 교수 Honey Farid는 인터넷에 공개된 수억 개의 이미지 데이터를 학습하는 과정에서 여성을 성적으로 대상화하는 편향이 반영되어 모델 출력을 완전히 제어하는 것은 어렵다고 지적한다.[165][166]
생성 AI는 사기, 여론 조작, 명예훼손 등 가짜 미디어 유통에 악용될 수 있다.[168] 한국에서도 스테이블 디퓨전을 이용해 조작된 재난 이미지가 확산되는 사례가 발생하여, 이에 대한 대책 마련이 요구되고 있다.[168]
알고리즘 편향스테이블 디퓨전 제작자들은 모델이 주로 영어 설명이 있는 이미지로 학습되었기 때문에 알고리즘 편향의 가능성을 인정한다.[40] 결과적으로 생성된 이미지는 사회적 편견을 강화하고 서구적 관점에서 생성된다.[40] 제작자는 모델에 다른 지역 사회와 문화의 데이터가 부족하다고 언급한다.[40] 이 모델은 다른 언어로 작성된 프롬프트보다 영어로 작성된 프롬프트에 대해 더 정확한 결과를 제공하며, 서구 또는 백인 문화가 종종 기본 표현으로 사용된다.[40]
스테이블 디퓨전이 학습에 사용한 이미지는 인간의 개입 없이 필터링되었기 때문에, 일부 유해한 이미지와 많은 양의 개인 정보 및 민감한 정보가 학습 데이터에 나타났다.[22]
보다 전통적인 시각 예술가들은 스테이블 디퓨전과 같은 이미지 합성 소프트웨어의 광범위한 사용이 결국 인간 예술가와 사진작가, 모델, 촬영감독, 배우 등이 AI 기반 경쟁자에 비해 점차 상업적 생존 가능성을 잃을 수 있다는 우려를 표명했다.
미성년자를 성적으로 묘사한 사진과 같은 사실적인 이미지에 대한 논란이 제기되었는데, 이는 스테이블 디퓨전으로 생성된 이러한 이미지가 픽시브(Pixiv)와 같은 웹사이트에서 공유되기 때문이다.[81]
2024년 6월, 스테이블 디퓨전의 사용자 인터페이스인 ComfyUI의 확장 프로그램에 대한 해킹이 발생했으며, 해커들은 "우리의 죄 중 하나"를 저지른 사용자를 표적으로 삼았다고 주장했는데, 여기에는 AI 아트 생성, 아트 도용, 암호화폐 홍보가 포함된다.[82]
2023년 1월, 사라 안데르센을 비롯한 세 명의 아티스트는 스테빌리티 AI, 미드저니, 데비안트아트를 상대로 저작권 침해 소송을 제기했다.[83] 이들은 이 회사들이 원작 아티스트들의 동의 없이 웹에서 수집한 50억 개의 이미지를 이용하여 AI 도구를 훈련시킴으로써 수백만 명의 아티스트의 권리를 침해했다고 주장했다.[83] 2023년 7월, 미국 지방 법원 판사 윌리엄 오릭 3세는 이 소송 대부분을 기각하는 쪽으로 기울었지만, 새로운 소장을 제출할 수 있도록 허용했다.[84]
같은 해 1월, 게티 이미지는 스테빌리티 AI를 상대로 지적재산권 침해 소송을 제기했다.[85][86] 게티 이미지는 스테빌리티 AI가 동의 없이 자사 웹사이트에서 수백만 장의 이미지를 스크래핑하여 스테이블 디퓨전 모델을 훈련 및 개발했다고 주장한다.[85][86]
게티 이미지와의 소송에서 주요 쟁점은 스테이블 디퓨전의 훈련 및 개발에 영국에 있을 가능성이 있는 서버와 컴퓨터에서 다운로드한 자사 이미지의 무단 사용이 포함되었는지 여부였다.[87] 스테빌리티 AI는 모든 훈련 및 개발이 영국 외부, 구체적으로는 아마존 웹 서비스가 운영하는 미국 데이터 센터에서 이루어졌다고 주장한다.[87] 스테빌리티 AI는 훈련 및 개발 관련 주장과 저작권의 2차적 침해 주장 두 가지에 대해 요약판결 및/또는 기각을 신청했지만, 고등법원은 이러한 주장을 기각하지 않고 재판으로 진행하도록 허용했다.[88]
2차적 침해 주장은 GitHub, HuggingFace, DreamStudio와 같은 플랫폼을 통해 영국에서 제공되는 사전 훈련된 스테이블 디퓨전 소프트웨어가 영국의 저작권, 디자인 및 특허법(CDPA) 22조와 23조에 따른 "저작물"에 해당하는지 여부를 중심으로 한다.[88] 재판은 2025년 여름에 열릴 것으로 예상된다.[88]
전자프런티어재단의 변호사 키트 월시는 “확산 모델이 훈련 데이터 중 이미지를 재현할 수 있는 정보를 저장할 가능성은, 해당 이미지가 훈련 중에 여러 번 복제된 경우에는 약간 있지만”, “훈련 데이터 중 이미지가 출력될 확률은, 비록 그 출력을 이끌어내기 위해 특별히 고안된 프롬프트를 사용하더라도, 말 그대로 100만 분의 1 이하의 확률이다”라고 말하고 있다.[160]
DALL-E와 같은 모델과 달리 스테이블 디퓨전은 모델(사전 훈련된 가중치)과 함께 소스 코드를 사용할 수 있도록 한다.[89][11] 스테이블 디퓨전 3 이전 버전은 책임있는 AI 라이선스(RAIL)의 일종인 Creative ML OpenRAIL-M 라이선스를 모델(M)에 적용했다.[90] 이 라이선스는 범죄, 명예훼손, 괴롭힘, 신상털이, "아동 포르노 제작 ... 미성년자 유린", 의학적 조언 제공, 법적 의무 자동 생성, 법적 증거 생성, 그리고 "...사회적 행동 또는 ... 개인적 특성 ... [또는] 법적으로 보호되는 특성이나 범주를 기반으로 개인이나 집단을 차별하거나 해치는 행위"를 포함한 특정 용도를 금지한다.[91][92] 사용자는 자신이 생성한 출력 이미지에 대한 권리를 소유하며, 이를 상업적으로 사용할 수 있다.[93]
스테이블 디퓨전 3.5는 허가적 Stability AI 커뮤니티 라이선스를 적용하며, 연 매출이 100만 달러를 초과하는 상업 기업은 Stability AI 엔터프라이즈 라이선스가 필요하다.[94] OpenRAIL-M 라이선스와 마찬가지로, 사용자는 자신이 생성한 출력 이미지에 대한 권리를 유지하고 상업적으로 사용할 수 있다.[74]
[1]
웹사이트
Stable Diffusion 3.5
https://stability.ai[...]
2024-10-23
[2]
웹사이트
How to Run Stable Diffusion Locally to Generate Images
https://www.assembly[...]
2022-08-23
[3]
웹사이트
Diffuse The Rest - a Hugging Face Space by huggingface
https://huggingface.[...]
2022-09-05
[4]
웹사이트
Leaked deck raises questions over Stability AI's Series A pitch to investors
https://sifted.eu/ar[...]
2023-06-20
[5]
웹사이트
Revolutionizing image generation by AI: Turning text into images
https://www.lmu.de/e[...]
2023-06-21
[6]
웹사이트
Stable Diffusion came from the Machine Vision & Learning research group (CompVis) @LMU_Muenchen
https://twitter.com/[...]
2022-11-02
[7]
웹사이트
The new killer app: Creating AI art will absolutely crush your PC
https://www.pcworld.[...]
2022-08-31
[8]
웹사이트
CompVis/Latent-diffusion
https://github.com/C[...]
[9]
웹사이트
Stable Diffusion 3: Research Paper
https://stability.ai[...]
[10]
웹사이트
Home
https://ommer-lab.co[...]
2024-09-05
[11]
웹사이트
Stable Diffusion Repository on GitHub
https://github.com/C[...]
CompVis - Machine Vision and Learning Research Group, LMU Munich
2022-09-17
[12]
웹사이트
The Illustrated Stable Diffusion
https://jalammar.git[...]
2022-10-31
[13]
서적
Generative Deep Learning
O'Reilly
[14]
논문
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
2015-03-12
[15]
웹사이트
Stable diffusion pipelines
https://huggingface.[...]
2023-06-22
[16]
웹사이트
Text-to-Image Generation with Stable Diffusion and OpenVINO™
https://docs.openvin[...]
Intel
2024-02-10
[17]
논문
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
2024-03-05
[18]
논문
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
2022-09-07
[19]
웹사이트
Rectified Flow — Rectified Flow
https://www.cs.utexa[...]
2024-03-06
[20]
웹사이트
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion's Image Generator
https://waxy.org/202[...]
2022-08-30
[21]
웹사이트
This artist is dominating AI-generated art. And he's not happy about it.
https://www.technolo[...]
2022-11-02
[22]
웹사이트
We Are All Raw Material for AI
https://interaktiv.b[...]
2023-07-07
[23]
웹사이트
CLIP+MLP Aesthetic Score Predictor
https://github.com/c[...]
2022-11-02
[24]
웹사이트
LAION-Aesthetics {{!}} LAION
https://laion.ai/blo[...]
2022-09-02
[25]
논문
Classifier-Free Diffusion Guidance
2022-07-25
[26]
웹사이트
Cost of construction
https://twitter.com/[...]
2022-08-28
[27]
웹사이트
A startup wants to democratize the tech behind DALL-E 2, consequences be damned
https://techcrunch.c[...]
2022-08-12
[28]
웹사이트
10m is about right
http://www.reddit.co[...]
2024-04-19
[29]
웹사이트
Stable Diffusion with 🧨 Diffusers
https://huggingface.[...]
2022-10-31
[30]
웹사이트
Stable Diffusion 2.0 Release
https://stability.ai[...]
[31]
웹사이트
LAION
https://laion.ai/
2022-10-31
[32]
웹사이트
Generating images with Stable Diffusion
https://blog.papersp[...]
2022-08-24
[33]
웹사이트
Announcing SDXL 1.0
https://stability.ai[...]
2023-08-21
[34]
웹사이트
Stability AI releases Stable Diffusion XL, its next-gen image synthesis model
https://arstechnica.[...]
2023-07-27
[35]
웹사이트
hakurei/waifu-diffusion · Hugging Face
https://huggingface.[...]
2022-10-31
[36]
arXiv
Adapting Pretrained Vision-Language Foundational Models to Medical Imaging Domains
2022-10-09
[37]
웹사이트
Riffusion - Stable diffusion for real-time music generation
https://www.riffusio[...]
[38]
Citation
Waifu Diffusion
https://github.com/h[...]
2022-10-31
[39]
웹사이트
NVIDIA Quietly Launches GeForce RTX 3080 12GB: More VRAM, More Power, More Money
https://www.anandtec[...]
[40]
웹사이트
CompVis/stable-diffusion-v1-4 · Hugging Face
https://huggingface.[...]
[41]
웹사이트
I thrashed the RTX 4090 for 8 hours straight training Stable Diffusion to paint like my uncle Hermann
https://www.pcgamer.[...]
2022-10-28
[42]
arXiv
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
2022-08-02
[43]
웹사이트
NovelAI Improvements on Stable Diffusion
https://blog.novelai[...]
2022-10-11
[44]
웹사이트
愛犬の合成画像を生成できるAI 文章で指示するだけでコスプレ 米Googleが開発
https://www.itmedia.[...]
2022-09-01
[45]
arXiv
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
2021-08-02
[46]
웹사이트
Stable Diffusion web UI
https://github.com/A[...]
2022-11-10
[47]
Citation
invisible-watermark
https://github.com/S[...]
Shield Mountain
2022-11-02
[48]
웹사이트
stable-diffusion-tools/emphasis at master · JohannesGaessler/stable-diffusion-tools
https://github.com/J[...]
[49]
웹사이트
Stable Diffusion v2.1 and DreamStudio Updates 7-Dec 22
https://stability.ai[...]
[50]
arXiv
Boomerang: Local sampling on image manifolds using diffusion models
2022-10-21
[51]
웹사이트
Stable Diffusion Based Image Compression
https://pub.towardsa[...]
2022-09-28
[52]
arXiv
Adding Conditional Control to Text-to-Image Diffusion Models
2023-02-10
[53]
웹사이트
Stable Diffusion in your pocket? "Draw Things" brings AI images to iPhone
https://arstechnica.[...]
2022-11-10
[54]
웹사이트
AI can be easily used to make fake election photos - report
https://www.bbc.com/[...]
2024-03-06
[55]
웹사이트
Stability AI open sources its AI-powered design studio
https://techcrunch.c[...]
2023-05-18
[56]
웹사이트
Stability AI is open-sourcing its DreamStudio web app
https://www.theverge[...]
2023-05-17
[57]
웹사이트
A friendly guide to local AI image gen with Stable Diffusion and Automatic1111
https://www.theregis[...]
2024-06-29
[58]
웹사이트
Fooocus is the easiest way to create AI art on your PC
https://www.pcworld.[...]
[59]
웹사이트
ComfyUI Workflows and what you need to know
https://learn.thinkd[...]
2023-12-01
[60]
웹사이트
ComfyUI
https://github.com/c[...]
[61]
논문
Latent Auto-recursive Composition Engine
https://digitalcommo[...]
Dartmouth College
2024-05-10
[62]
웹사이트
CompVis/stable-diffusion-v1-4 · Hugging Face
https://huggingface.[...]
[63]
웹사이트
CompVis (CompVis)
https://huggingface.[...]
2023-08-23
[64]
웹사이트
runwayml/stable-diffusion-v1-5 · Hugging Face
https://huggingface.[...]
[65]
웹사이트
stabilityai/stable-diffusion-2 · Hugging Face
https://huggingface.[...]
[66]
웹사이트
stabilityai/stable-diffusion-2-base · Hugging Face
https://huggingface.[...]
[67]
웹사이트
stabilityai/stable-diffusion-2-1 · Hugging Face
https://huggingface.[...]
[68]
웹사이트
stabilityai/stable-diffusion-xl-base-1.0 · Hugging Face
https://huggingface.[...]
[69]
arXiv
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
2023-07-04
[70]
웹사이트
Announcing SDXL 1.0
https://stability.ai[...]
[71]
웹사이트
stabilityai/sdxl-turbo · Hugging Face
https://huggingface.[...]
2024-01-01
[72]
웹사이트
Adversarial Diffusion Distillation
https://stability.ai[...]
2024-01-01
[73]
웹사이트
Stable Diffusion 3
https://stability.ai[...]
2024-03-05
[74]
웹사이트
Stable Diffusion 3.5
https://stability.ai[...]
2024-10-23
[75]
논문
Learning Transferable Visual Models From Natural Language Supervision
2021-02-26
[76]
논문
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
2022-01-04
[77]
서적
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2022
[78]
웹사이트
LICENSE.md · stabilityai/stable-diffusion-xl-base-1.0 at main
https://huggingface.[...]
2024-01-01
[79]
뉴스
Midjourneyを超えた? 無料の作画AI「 #StableDiffusion 」が「AIを民主化した」と断言できる理由
https://www.business[...]
2022-08-26
[80]
뉴스
Startup Behind AI Image Generator Stable Diffusion Is In Talks To Raise At A Valuation Up To $1 Billion
https://www.forbes.c[...]
2022-09-07
[81]
뉴스
Illegal trade in AI child sex abuse images exposed
https://www.bbc.com/[...]
2023-07-26
[82]
뉴스
Hackers Target AI Users With Malicious Stable Diffusion Tool on GitHub to Protest 'Art Theft'
https://www.404media[...]
2024-06-11
[83]
뉴스
AI art tools Stable Diffusion and Midjourney targeted with copyright lawsuit
https://www.theverge[...]
2023-01-16
[84]
뉴스
US judge finds flaws in artists' lawsuit against AI companies
https://www.reuters.[...]
2023-07-19
[85]
뉴스
Getty Images v Stability AI: the implications for UK copyright law and licensing
https://www.pinsentm[...]
2024-02-28
[86]
뉴스
Getty Images v Stability AI: copyright claims can proceed to trial
https://www.pinsentm[...]
2023-12-11
[87]
뉴스
Getty v. Stability AI case goes to trial in the UK – what we learned
https://www.reedsmit[...]
2024-02-28
[88]
뉴스
Generative AI in the courts: Getty Images v Stability AI
https://www.penningt[...]
2024-02-16
[89]
웹사이트
Stable Diffusion Public Release
https://stability.ai[...]
[90]
웹사이트
From RAIL to Open RAIL: Topologies of RAIL Licenses
https://www.licenses[...]
2022-08-18
[91]
뉴스
Ready or not, mass video deepfakes are coming
https://www.washingt[...]
2022-08-30
[92]
웹사이트
License - a Hugging Face Space by CompVis
https://huggingface.[...]
[93]
뉴스
言葉で指示した画像を凄いAIが描き出す「Stable Diffusion」 ~画像は商用利用も可能
https://forest.watch[...]
2022-08-26
[94]
웹사이트
Community License
https://stability.ai[...]
2024-07-05
[95]
웹사이트
Stable Diffusion 3.5
https://stability.ai[...]
[96]
웹사이트
Diffuse The Rest - a Hugging Face Space by huggingface
https://huggingface.[...]
[97]
학회발표
High-Resolution Image Synthesis with Latent Diffusion Models
https://openaccess.t[...]
2022-06
[98]
웹사이트
Stable Diffusion Launch Announcement
https://stability.ai[...]
[99]
웹사이트
Revolutionizing image generation by AI: Turning text into images
https://www.lmu.de/e[...]
[100]
뉴스
Stability AI, the startup behind Stable Diffusion, raises $101M
https://techcrunch.c[...]
2022-10-17
[101]
웹사이트
The new killer app: Creating AI art will absolutely crush your PC
https://www.pcworld.[...]
[102]
뉴스
Anyone can use this AI art generator — that's the risk
https://www.theverge[...]
2022-09-15
[103]
웹사이트
Artists are alarmed by AI — and they’re fighting back
https://www.washingt[...]
[104]
웹사이트
Stable Diffusion Repository on GitHub
https://github.com/C[...]
CompVis - Machine Vision and Learning Research Group, LMU Munich
2022-09-17
[105]
웹사이트
The Illustrated Stable Diffusion
https://jalammar.git[...]
[106]
웹사이트
High-Resolution Image Synthesis with Latent Diffusion Models
https://ommer-lab.co[...]
2022-11-04
[107]
웹사이트
Stable Diffusion launch announcement
https://stability.ai[...]
2022-11-02
[108]
논문
High-Resolution Image Synthesis with Latent Diffusion Models
International Conference on Computer Vision and Pattern Recognition (CVPR)
2022-06
[109]
웹사이트
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion's Image Generator
https://waxy.org/202[...]
2022-11-02
[110]
웹사이트
This artist is dominating AI-generated art. And he's not happy about it.
https://www.technolo[...]
2022-11-02
[111]
웹사이트
Stable Diffusion: Tutorials, Resources, and Tools
https://stackdiary.c[...]
2022-11-02
[112]
기타
CLIP+MLP Aesthetic Score Predictor
https://github.com/c[...]
2022-11-02
[113]
웹사이트
LAION-Aesthetics
https://laion.ai/blo[...]
2022-09-02
[114]
논문
Classifier-Free Diffusion Guidance
2022-07-25
[115]
웹사이트
Cost of construction
https://twitter.com/[...]
2022-09-06
[116]
웹사이트
A startup wants to democratize the tech behind DALL-E 2, consequences be damned
https://techcrunch.c[...]
2022-11-02
[117]
웹사이트
Stable Diffusion with 🧨 Diffusers
https://huggingface.[...]
2022-10-31
[118]
웹사이트
Stable Diffusion 2.0 Release
https://stability.ai[...]
2022-11-24
[119]
웹사이트
LAION
https://laion.ai/
2022-10-31
[120]
웹사이트
Generating images with Stable Diffusion
https://blog.papersp[...]
2022-10-31
[121]
웹사이트
(If you were wondering how often Stable Diffusion will give you a horse with more than 4 legs (or sometimes less) when you ask it for a photo of a horse: in my experience it's about 20-25% of the time.)
https://twitter.com/[...]
2022-10-31
[122]
웹사이트
hakurei/waifu-diffusion · Hugging Face
https://huggingface.[...]
2022-10-31
[123]
기타
Waifu Diffusion
https://github.com/h[...]
2022-10-31
[124]
웹사이트
NVIDIA Quietly Launches GeForce RTX 3080 12GB: More VRAM, More Power, More Money
https://www.anandtec[...]
2022-10-31
[125]
웹사이트
CompVis/stable-diffusion-v1-4 · Hugging Face
https://huggingface.[...]
2022-11-02
[126]
논문
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
2021-08-02
[127]
웹사이트
Stable Diffusion web UI
https://github.com/A[...]
2022-11-30
[128]
기타
invisible-watermark
https://github.com/S[...]
Shield Mountain
2022-11-02
[129]
웹사이트
stable-diffusion-tools/emphasis at master · JohannesGaessler/stable-diffusion-tools
https://github.com/J[...]
2022-11-02
[130]
논문
Boomerang: Local sampling on image manifolds using diffusion models
2022-10-21
[131]
웹사이트
Stable Diffusion Based Image Compression
https://pub.towardsa[...]
2022-11-02
[132]
웹사이트
CompVis (CompVis)
https://huggingface.[...]
2024-03-06
[133]
웹사이트
runwayml/stable-diffusion-v1-5 · Hugging Face
https://huggingface.[...]
2023-08-17
[134]
웹사이트
stabilityai/stable-diffusion-2 · Hugging Face
https://huggingface.[...]
2023-08-17
[135]
웹사이트
stabilityai/stable-diffusion-2-base · Hugging Face
https://huggingface.[...]
2024-01-01
[136]
웹사이트
stabilityai/stable-diffusion-2-1 · Hugging Face
https://huggingface.[...]
2023-08-17
[137]
웹사이트
stabilityai/stable-diffusion-xl-base-1.0 · Hugging Face
https://huggingface.[...]
2023-08-17
[138]
논문
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
2023-07-04
[139]
웹사이트
Announcing SDXL 1.0
https://stability.ai[...]
2024-01-01
[140]
웹사이트
stabilityai/sdxl-turbo · Hugging Face
https://huggingface.[...]
2024-01-01
[141]
웹사이트
Adversarial Diffusion Distillation
https://stability.ai[...]
2024-01-01
[142]
웹사이트
AIがリアルタイムでテキストから画像を生成する「SDXL Turbo」が発表/画質を犠牲にすることなく、最先端のマルチステップモデルを凌駕する性能を発揮
https://forest.watch[...]
2023-11-29
[143]
웹사이트
Stable Diffusion 3
https://stability.ai[...]
2024-03-05
[144]
논문
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
2024-03-05
[145]
웹사이트
画像生成AI「Stable Diffusion 3」API利用可能に 文字の正確さが強み
https://ascii.jp/ele[...]
2024-07-28
[146]
웹사이트
Startup Behind AI Image Generator Stable Diffusion Is In Talks To Raise At A Valuation Up To $1 Billion
https://www.forbes.c[...]
2022-10-31
[147]
간행물
「「幻覚を見ている」のはAIの機械ではなく、その製作者たちだ」
岩波書店
2023-07
[148]
간행물
「「幻覚を見ている」のはAIの機械ではなく、その製作者たちだ」
岩波書店
2023-07
[149]
뉴스
null
読売新聞
2023-05-16
[150]
웹사이트
Generative AI Has an Intellectual Property Problem
https://hbr.org/2023[...]
2023-04-12
[151]
웹사이트
This artist is dominating AI-generated art. And he's not happy about it.
https://www.technolo[...]
2022-09-16
[152]
웹사이트
まさに人間のアーティストが描いたような画像を生成するAIが「アーティストの権利を侵害している」と批判される
https://gigazine.net[...]
OSA
2022-08-15
[153]
웹사이트
風景写真家がAI画像ジェネレーター「Stable Diffusion」で非実在美景を生成
https://gigazine.net[...]
OSA
2022-08-19
[154]
웹사이트
米画家ら、画像生成AI「Stable Diffusion」と「Midjourney」を提訴
https://pc.watch.imp[...]
株式会社インプレス
2023-01-17
[155]
웹사이트
生成系AI(ChatGPT, BingAI, Bard, Midjourney, Stable Diffusion等)について
https://utelecon.adm[...]
2023-04-05
[156]
웹사이트
生成AI(Generative AI)の倫理的・法的・社会的課題(ELSI)論点の概観:2023年3月版
https://elsi.osaka-u[...]
2023-04-17
[157]
웹사이트
Nvidia launches new cloud services and partnerships to train generative AI
https://techcrunch.c[...]
2023-06-26
[158]
웹사이트
Adobe aims to sell businesses on its Firefly generative AI tools
https://www.axios.co[...]
2023-06-19
[159]
웹사이트
アドビ、生成AI「Firefly」でクリエーティブツールを強化--「Illustrator」などに搭載
https://japan.zdnet.[...]
2023-06-26
[160]
웹사이트
How We Think About Copyright and AI Art
https://www.eff.org/[...]
2023-04-03
[161]
웹사이트
null
https://www.gizmodo.[...]
[162]
논문
Extracting Training Data from Diffusion Models
https://arxiv.org/ab[...]
2023-01-30
[163]
웹사이트
Midjourneyを超えた? 無料の作画AI「 #StableDiffusion 」が「AIを民主化した」と断言できる理由
https://www.business[...]
2022-08-26
[164]
웹사이트
Stable Diffusion Public Release
https://stability.ai[...]
2022-08-31
[165]
웹사이트
AI porn is easy to make now. For women, that’s a nightmare.
https://www.washingt[...]
2023-02-20
[166]
뉴스
Ready or not, mass video deepfakes are coming
https://www.washingt[...]
2022-08-30
[167]
웹사이트
AIでポルノ画像を作成するプロジェクト「Unstable Diffusion」がKickstarterでの出資募集をブロックされる
https://gigazine.net[...]
2023-02-08
[168]
간행물
インフォデミック時代におけるフェイクメディア克服の最前線
人工知能学界
2023-03
[169]
웹사이트
インチキAIに騙されないために
https://wirelesswire[...]
2023-03-24
[170]
웹인용
Announcing SDXL 1.0
https://stability.ai[...]
[171]
웹인용
How to Run Stable Diffusion Locally to Generate Images
https://www.assembly[...]
2022-08-23
[172]
웹인용
Diffuse The Rest - a Hugging Face Space by huggingface
https://huggingface.[...]
[173]
웹인용
Stable Diffusion Launch Announcement
https://stability.ai[...]
[174]
웹인용
The new killer app: Creating AI art will absolutely crush your PC
https://www.pcworld.[...]
[175]
웹인용
Anyone can use this AI art generator — that's the risk
https://www.theverge[...]
2022-09-15
[176]
웹사이트
SDXL 설치 및 사용법
https://allwayhelp.c[...]
[177]
웹인용
CompVis/stable-diffusion-v1-4 · Hugging Face
https://huggingface.[...]
2023-08-17
[178]
웹인용
runwayml/stable-diffusion-v1-5 · Hugging Face
https://huggingface.[...]
2023-08-17
[179]
웹인용
stabilityai/stable-diffusion-2 · Hugging Face
https://huggingface.[...]
2023-08-17
[180]
웹인용
stabilityai/stable-diffusion-2-1 · Hugging Face
https://huggingface.[...]
2023-08-17
[181]
웹인용
stabilityai/stable-diffusion-xl-base-1.0 · Hugging Face
https://huggingface.[...]
2023-08-17
( 최근 20개의 뉴스만 표기 됩니다. )
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com