임의 슬라이스 정렬
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
임의 슬라이스 정렬(ASO)은 제한된 컴퓨팅 자원을 가진 저가형 애플리케이션에서 사용되는 기술로, 모든 매크로블록이 디코딩 순서대로 배열되어야 하는 제약을 완화하여 낮은 지연 시간을 향상시킨다. AVC에서 ASO를 사용할 경우 슬라이스 인터리빙 문제가 발생할 수 있으며, 그림 내로 제한하여 해결할 수 있지만 디코더 복잡성이 증가한다. ASO 디코딩은 매크로블록과 슬라이스, 슬라이스와 슬라이스 그룹 연결 방식에 따라 디코더 복잡성에 영향을 미치며, 디코딩 순서에 따라 대기 시간 증가, 메모리 소비, 대역폭 증가 등의 문제점이 발생할 수 있다.
ASO는 모든 매크로블록이 디코딩 순서대로 배열되어야 한다는 제약을 완화하여 화상 회의 및 대화형 인터넷 애플리케이션에서 중요한 저지연 성능을 향상시킨다.
AVC에서 여러 그림에 걸쳐 임의 슬라이스 정렬(ASO)을 지원하면 심각한 문제가 발생한다. 서로 다른 그림의 '슬라이스'가 인터리빙되기 때문이다. 이 문제를 해결하는 한 가지 방법은 ASO를 그림 내로 제한하는 것이다. 즉, 서로 다른 그림의 슬라이스가 인터리빙되지 않도록 하는 것이다.
ASO 디코딩에는 크게 두 가지 유형이 있다.
2. 응용 분야
3. 문제점
그러나 ASO를 그림 내로 제한하더라도 디코더의 복잡성은 상당히 증가한다. FMO는 연속적이지 않은 매크로블록이 동일한 '슬라이스'에 속하도록 허용하여 슬라이스의 개념을 확장하므로, FMO에 의해 발생하는 디코더 복잡성 문제도 있다.
4. ASO 디코딩의 유형
첫 번째 방법은 대기 시간이 길어지지만, 디코딩과 디블로킹을 병렬로 수행할 수 있다. 그러나 많은 수의 포인터를 관리하고 DRAM 액세스 유닛의 복잡성을 증가시켜 디코더 복잡성이 증가한다.
두 번째 방법은 디코더 성능을 크게 저하시키며, 디블로킹을 별도 단계에서 수행하면 DRAM과 프로세서 메모리 간 대역폭이 증가한다.
슬라이스를 수신 순서대로 디코딩하면 추가적인 메모리 소비가 발생하거나, 디코더 및 로컬 메모리에 더 높은 처리량 요구 사항이 발생하여 클록 속도가 높아질 수 있다. 디스플레이 작업 시 디코더가 그림을 저장한 메모리 섹션에서 바로 표시될 그림을 읽는 경우를 고려해 볼 수 있다.
4. 1. 매크로블록과 슬라이스 연결
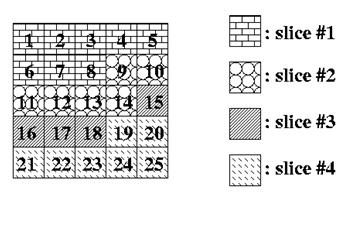
임의 슬라이스 정렬(ASO)이 지원될 때, 위 그림 예제의 네 개 슬라이스는 디코더에서 임의 순서로 수신될 수 있다.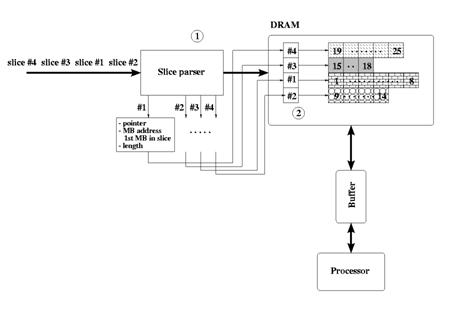
위 그림은 ASO 디코딩을 지원하는 데 필요한 AVC 디코더 블록을 나타낸다. 각 슬라이스에 대해, 슬라이스 길이와 슬라이스의 첫 번째 매크로블록(MB)의 매크로블록 주소(래스터 스캔 순서에 대한 인덱스)는 슬라이스 파서에 의해 추출된다. 이 정보는 슬라이스 자체와 함께 메모리(DRAM)에 저장된다. 또한 포인터 목록(각 슬라이스에 대한 포인터, 각 슬라이스가 저장된 메모리 위치)이 생성되어야 한다. 포인터 목록은 슬라이스의 첫 번째 매크로블록 주소와 함께 순서가 아닌 슬라이스를 탐색하는 데 사용된다. 슬라이스 길이는 슬라이스 데이터를 DRAM에서 디코더 내부 메모리로 전송하는 데 사용된다.
순서가 아닌 슬라이스를 디코딩해야 할 경우 디코더는 다음 방법을 사용할 수 있다.
첫 번째 방법은 대기 시간을 늘리지만, 디코딩과 디블로킹을 병렬 수행할 수 있다. 그러나 많은 수의 포인터(최악의 경우 각 MB에 대해 하나의 포인터)를 관리하고 DRAM 액세스 유닛의 인텔리전스를 증가시키면 디코더 복잡성이 증가한다.
두 번째 방법은 디코더 성능을 크게 저하시킨다. 또한, 두 번째 패스에서 디블로킹을 수행하면 DRAM에서 프로세서 메모리로의 대역폭이 증가한다.
슬라이스를 수신 순서대로 디코딩하면 추가적인 메모리 소비가 발생하거나, 디코더 및 로컬 메모리에 더 높은 처리량 요구 사항이 부과되어 더 높은 클록 속도로 실행될 수 있다. 디스플레이 작업이 디코더가 그림을 저장한 메모리 섹션에서 바로 표시될 그림을 읽는 응용 프로그램을 생각해 보라.
4. 2. 매크로블록과 슬라이스, 슬라이스와 슬라이스 그룹 연결
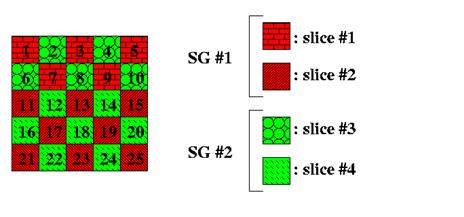
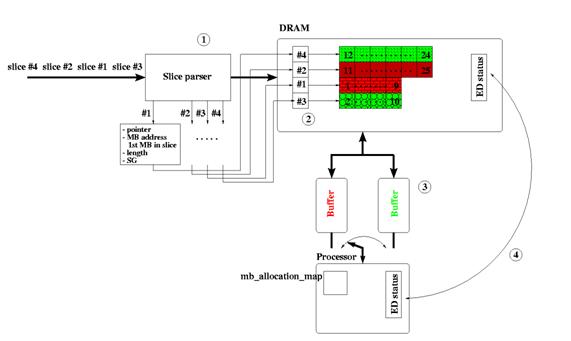
''슬라이스'' 길이와 ''슬라이스''의 첫 번째 매크로블록(MB)의 매크로블록 주소 외에도, ''슬라이스'' 파서(그림 4)는 각 ''슬라이스''의 ''슬라이스'' 그룹(SG)을 추출해야 한다. 이 정보는 ''슬라이스'' 자체와 함께 DRAM에 저장된다. ASO와 마찬가지로, 포인터 목록(그림 4)이 생성되어야 한다.
포인터 목록은 ''슬라이스''의 첫 번째 MB 주소, SG, 그리고 mb_allocation_map (프로세서의 로컬 메모리에 저장됨)과 함께 ''슬라이스''를 탐색하는 데 사용된다. ''슬라이스'' 길이는 DRAM에서 프로세서 로컬 메모리로 ''슬라이스'' 데이터를 전송하는 데 사용된다.
ASO와 FMO가 결합된 경우, 디코더는 다음 두 가지 방법 중 하나를 사용할 수 있다.
일반적으로 첫 번째 접근 방식이 선호된다. FMO로 인해 래스터 스캔 순서로 매크로블록을 디코딩하려면 서로 다른 ''슬라이스'' 및/또는 ''슬라이스'' 그룹 간의 전환이 필요할 수 있다. DRAM 액세스를 가속화하기 위해 각 ''슬라이스'' 그룹에 대해 하나의 버퍼를 사용해야 한다(그림 4). DRAM 액세스 유닛의 이러한 추가적인 기능은 디코더 복잡성을 더욱 증가시킨다. 또한, 서로 다른 ''슬라이스'' 및/또는 ''슬라이스'' 그룹 간 전환 시 엔트로피 디코더(ED) 상태 정보를 스와핑해야 한다. 최악의 경우, 각 매크로블록을 디코딩한 후에 스와핑이 발생한다. 전체 엔트로피 디코더 상태 정보를 프로세서 로컬 메모리에 저장하기에는 너무 크면, 각 ED 상태를 DRAM에서 로드하고 DRAM에 저장해야 하므로 DRAM에서 프로세서의 메모리 대역폭(그림 4)이 더욱 증가한다.
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com