변분 오토인코더
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
변분 오토인코더(VAE)는 딥러닝 모델의 한 종류로, 데이터를 저차원 잠재 공간으로 압축하고 다시 복원하는 방식으로 작동한다. AEVB 알고리즘을 기반으로 하며, 인코더와 디코더 두 개의 신경망을 사용한다. 인코더는 데이터를 잠재 공간에 매핑하는 데 사용되며, 디코더는 잠재 공간에서 데이터를 복원하는 데 사용된다. VAE는 재매개변수화 기법을 사용하여 학습하며, 증거 하한(ELBO)을 최대화하여 모델을 훈련시킨다. VAE는 β-VAE, 조건부 VAE(CVAE) 등의 변형 모델과 생성적 적대 신경망(GAN)과의 결합을 통해 성능을 향상시키고 있으며, 통계적 거리를 활용한 다양한 변종도 존재한다.

더 읽어볼만한 페이지
- 비지도 학습 - 챗GPT
챗GPT는 오픈AI가 개발한 GPT-3.5 기반의 대화형 인공지능 서비스로, 인간과 유사한 텍스트 생성, 코드 생성, 보고서 작성, 번역 등의 다양한 기능을 제공하지만, 편향된 정보 생성, 데이터 유출, 윤리 및 저작권 문제 등의 논란도 있으며, 유료 서비스를 포함한 다양한 형태로 제공되고, 지속적인 모델 개발을 통해 성능을 향상시키고 있다. - 비지도 학습 - 환각 (인공지능)
인공지능 환각은 인공지능이 사실이 아닌 정보를 사실처럼 생성하는 현상으로, 대규모 언어 모델의 부정확한 정보 생성 문제를 설명하기 위해 사용되며, 데이터 불일치, 모델 오류, 훈련 데이터 부족 등이 원인으로 발생하여 다양한 완화 기술이 연구되고 있다. - 토막글 틀에 과도한 변수를 사용한 문서 - 전향
전향은 종교적 개종이나 노선 변경을 의미하며, 근대 이후 정치적 이념 변화를 지칭하는 용어로 확장되어 개인의 신념 변화, 정치적 압력 등 다양한 요인으로 발생하며, 사회주의·공산주의로부터의 전향, 전향 문학, 냉전 시대 이후의 전향 현상 등을 폭넓게 논의한다. - 토막글 틀에 과도한 변수를 사용한 문서 - 포토마스크
포토마스크는 반도체, 디스플레이, 인쇄 회로 기판 제조 시 웨이퍼에 회로 패턴을 전사하는 마스크로, 기술 발전을 거듭하며 융용 실리카 기판과 금속 흡수막을 사용하고 위상 천이 마스크, EUV 마스크 등의 고급 기술이 개발되어 반도체 미세화에 기여하고 있지만, 높은 제작 비용과 기술적 어려움은 해결해야 할 과제이다. - 토론 이름공간 토막글 - 전향
전향은 종교적 개종이나 노선 변경을 의미하며, 근대 이후 정치적 이념 변화를 지칭하는 용어로 확장되어 개인의 신념 변화, 정치적 압력 등 다양한 요인으로 발생하며, 사회주의·공산주의로부터의 전향, 전향 문학, 냉전 시대 이후의 전향 현상 등을 폭넓게 논의한다. - 토론 이름공간 토막글 - 포토마스크
포토마스크는 반도체, 디스플레이, 인쇄 회로 기판 제조 시 웨이퍼에 회로 패턴을 전사하는 마스크로, 기술 발전을 거듭하며 융용 실리카 기판과 금속 흡수막을 사용하고 위상 천이 마스크, EUV 마스크 등의 고급 기술이 개발되어 반도체 미세화에 기여하고 있지만, 높은 제작 비용과 기술적 어려움은 해결해야 할 과제이다.
2. 역사
'''오토인코딩 변분 베이즈 알고리즘'''(Auto-Encoding Variational Bayes algorithm|오토인코딩 변분 베이즈 알고리즘영어; AEVB)은 기울기 추정치를 이용해 잠재 변수 모델과 추론 모델을 동시에 최적화하는 알고리즘이다.[1]
기존 방법들은 AEVB 알고리즘의 가정하에서는 유용성이 제한적이다.[1]
- 최대우도법은 를 쉽게 계산할 수 없는 경우 사용할 수 없다.
- EM 알고리즘은 계산이 용이하지 않으면 사용할 수 없다.
- 변분 베이즈 방법은 가 평균장 근사될 수 있는 경우에만 사용할 수 있다.
- 몬테카를로 EM 알고리즘은 실행 속도가 느려 대규모 데이터 집합에는 사용할 수 없다.
가 신경망으로 정의된 경우, 위에서 언급한 기존 방법들은 사용할 수 없지만 AEVB 알고리즘은 적용할 수 있다.[1]
2. 1. AEVB 알고리즘
'''오토인코딩 변분 베이즈 알고리즘'''(Auto-Encoding Variational Bayes algorithm|오토인코딩 변분 베이즈 알고리즘영어; '''AEVB''')은 기울기 추정치를 이용한 유향 잠재 변수 모델과 추론 모델의 동시 최적화 알고리즘이다.AEVB에서는 유향 잠재 변수 모델 을 추론 모델 의 도입에 의한 변분 하한 최대화에 의해 최적화한다. 일반적으로 변분 하한의 기울기 는 intractable 하지만, AEVB에서는 이것을 몬테카를로 방법 ()을 이용한 기울기의 불편 추정량 로 대체하고, 확률적 경사 하강법에 의해 파라미터를 최적화한다. 이때 의 기울기 추정·전파에 관한 문제는 reparameterization trick으로 해결한다.
표본 이 각 i에 대해 다음과 같이 생성된다고 가정한다.
- 먼저 잠재 변수 가 어떤 확률 밀도 함수 를 따르도록 선택되고,
- 가 에 의존하는 어떤 확률 밀도 함수 를 따르도록 선택된다.
여기서 는 어떤 매개변수이며, 의 참값 는 알 수 없다. 또한 , 를 따르는 값을 선택하는 것은 계산량 측면에서 용이하다고 가정한다.
한편, 잠재 변수의 사후 분포 는 쉽게 계산할 수 없으므로, (쉽게 계산할 수 있는) 확률 밀도 함수 로 근사하는 것을 고려한다 ('''근사 사후 분포'''). 여기서 는 매개변수이다.
근사 사후 분포를 사용하면 주변 로그 우도 는 다음과 같이 변형할 수 있다.
:
우변의 첫 번째 항은 '''변분 하한''' 또는 '''ELBO'''라고 하며, 두 번째 항은 사후 분포-근사 사후 분포 간의 쿨백-라이블러 발산에 해당한다. 즉, 다음 식이 성립한다.
:
여기서 (깁스 부등식)이므로, 변분 하한 최대화는 다음 두 가지 의미를 갖는다.
- 근사 사후 분포의 근사 정확도 최대화 ()
- 생성 모델의 우도 최대화 ()
따라서 변분 하한 최대화는 최대 우도 추정의 대안으로 사용할 수 있다.
변분 하한은 일반적으로 계산이 간단하지 않다. 따라서 가 적절한 가정을 만족한다는 조건 하에 변분 하한의 추정량을 도입한다. 표본 에 대해 확률적 경사 하강법을 사용하여 SGVB 추정량을 최대화하여 모델을 최적화한다.
본 장에서 가정하는 설정에서는 기존의 방법들의 유용성은 제한적이다.
- 최대우도법은 본 장의 설정에서는 를 쉽게 계산할 수 없는 경우에는 사용할 수 없다.
- EM 알고리즘은 의 계산이 용이한 경우가 아니면 사용할 수 없다.
- 변분 베이즈 방법은 가 평균장 근사될 수 있는 경우에만 사용할 수 있다.
- 몬테카를로 EM 알고리즘은 실행 속도가 느리기 때문에 대규모 데이터 집합에는 사용할 수 없다.
예를 들어 가 신경망으로 정의되어 있는 경우에는 위에서 언급한 기존 방법들은 사용할 수 없지만, 본 방법이라면 적용할 수 있다. 후술하는 변분 오토인코더는 바로 이러한 경우이며, 를 신경망으로 정의하고 있다.
2. 2. VAE의 등장
'''오토인코딩 변분 베이즈 알고리즘'''(Auto-Encoding Variational Bayes algorithm|오토인코딩 변분 베이즈 알고리즘영어; '''AEVB''')은 기울기 추정치를 이용한 유향 잠재 변수 모델과 추론 모델의 동시 최적화 알고리즘이다.본 장에서 가정하는 설정에서는 기존 방법들의 유용성은 제한적이다.[1]
- 최대우도법은 본 장의 설정에서는 를 쉽게 계산할 수 없는 경우에는 사용할 수 없다.
- EM 알고리즘은 의 계산이 용이한 경우가 아니면 사용할 수 없다.
- 변분 베이즈 방법은 가 평균장 근사될 수 있는 경우에만 사용할 수 있다.
- 몬테카를로 EM 알고리즘은 실행 속도가 느리기 때문에 대규모 데이터 집합에는 사용할 수 없다.
예를 들어 가 신경망으로 정의되어 있는 경우에는 위에서 언급한 기존 방법들은 사용할 수 없지만, AEVB 알고리즘은 적용할 수 있다. 후술하는 변분 오토인코더는 바로 이러한 경우이며, 를 신경망으로 정의하고 있다.
3. 작동 원리
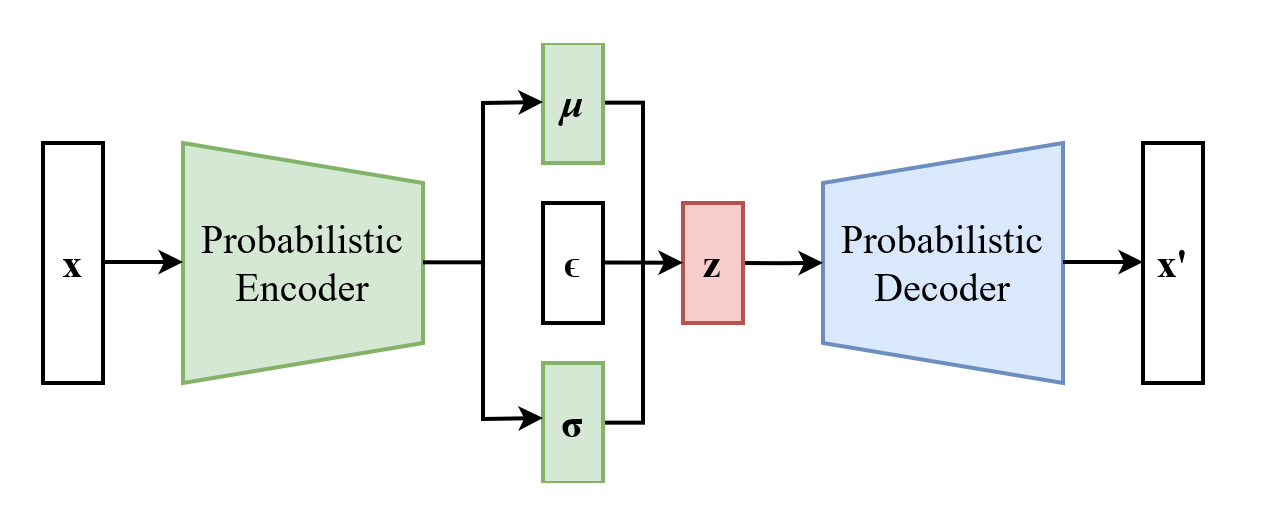
변분 오토인코더(Variational Autoencoder, VAE)는 생성 모델의 일종으로, 인코더와 디코더라는 두 개의 신경망으로 구성된다. 작동 원리는 다음과 같다.
1. 인코더 (Encoder):인코더는 입력 데이터 x를 저차원 잠재 공간으로 매핑하는 신경망이다. 데이터 포인트 자체를 입력으로 받아 변분 분포의 매개변수를 출력하며, 잠재 변수 z는 일반적으로 유한 차원의 실수 벡터로 표현된다. 인코더는 근사 사후 분포 를 계산하여, 입력 데이터 x가 주어졌을 때 잠재 변수 z의 확률 분포를 추정한다.
2. 디코더 (Decoder):디코더는 잠재 공간의 변수 z를 입력받아 다시 원래의 데이터 공간으로 매핑하는 신경망이다. 디코더는 조건부 우도 분포 를 계산하여, 잠재 변수 z가 주어졌을 때 원래 데이터 x가 나타날 확률 분포를 추정한다.
3. 재매개변수화 기법 (Reparameterization Trick):VAE의 학습 과정에서는 경사 하강법을 사용하는데, 잠재 변수 z가 확률 분포를 따르기 때문에 역전파가 어렵다. 이 문제를 해결하기 위해 재매개변수화 기법을 사용한다. 이 기법은 잠재 변수 z를 표준 정규 분포를 따르는 새로운 변수 ε와 인코더의 출력 (, )을 이용하여 결정론적인 함수로 표현하는 방법이다. 이를 통해 역전파가 가능하게 된다.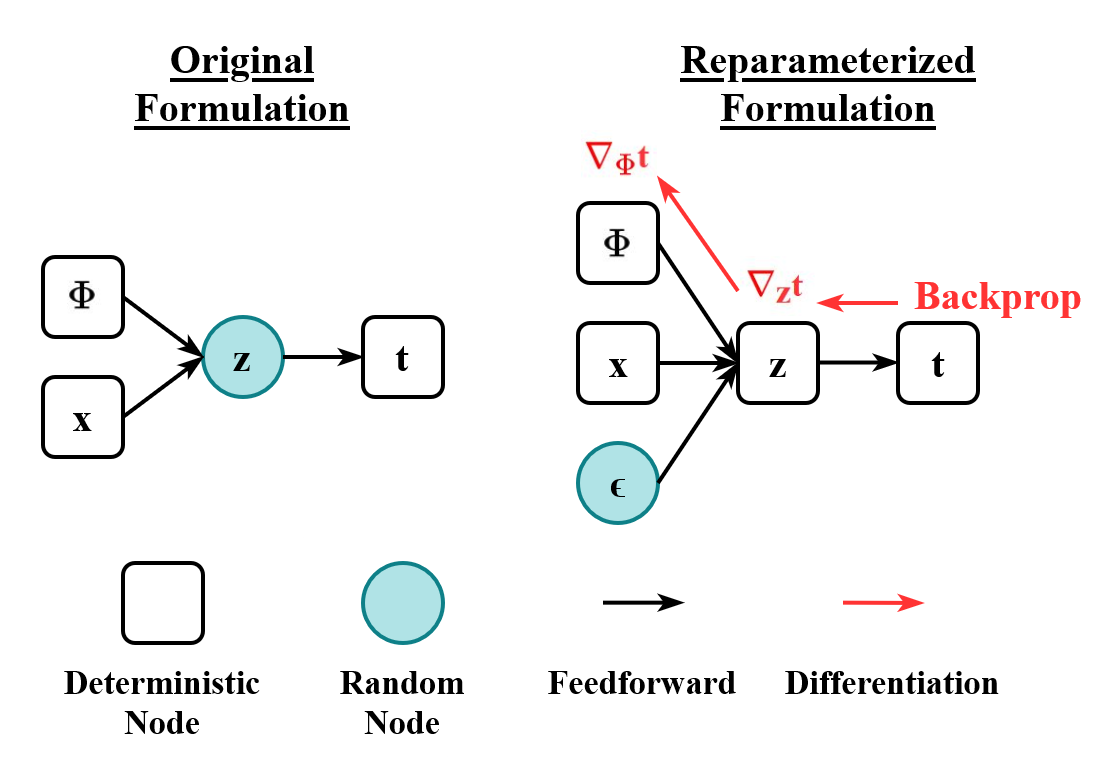
4. 증거 하한 (Evidence Lower Bound, ELBO):VAE는 ELBO라는 목적 함수를 최대화하는 방식으로 학습된다. ELBO는 재구성 오류(reconstruction error)와 쿨백-라이블러 발산(KL-Divergence)의 두 가지 항으로 구성된다.
- 재구성 오류: 입력 데이터 x와 디코더를 통해 복원된 데이터 간의 차이를 나타낸다.
- 쿨백-라이블러 발산: 근사 사후 분포 와 잠재 변수의 사전 분포 간의 차이를 나타낸다.
ELBO를 최대화하는 것은 근사 사후 분포의 정확도를 높이는 동시에 생성 모델의 우도를 최대화하는 것과 같다.
5. 학습:VAE의 학습은 주어진 데이터 집합에 대해 오토인코딩 변분 베이즈 알고리즘을 사용하여 인코더와 디코더 신경망의 매개변수를 결정하는 과정이다. 이 과정에서 ELBO를 최대화하는 방향으로 경사 상승법을 사용하여 매개변수를 업데이트한다.
6. 생성:VAE의 생성 과정에서는 먼저 표준 정규 분포를 따르는 잠재 변수 z를 생성하고, 생성된 z와 학습된 디코더를 사용하여 새로운 데이터 x를 생성한다.[8]
3. 1. 인코더 (Encoder)
변분 오토인코더(Variational Autoencoder)에서 인코더는 입력 데이터 x를 저차원의 잠재 공간으로 매핑하는 신경망이다. 이 신경망은 데이터 포인트 자체를 입력으로 받아 변분 분포의 매개변수를 출력한다.일반적인 변분 자동 인코더에서 잠재 변수 z는 유한 차원의 실수 벡터이고, 인코더는 근사된 사후 분포 를 계산한다. 이는 다음과 같은 형태를 가진다.
:, 여기서
여기서 는 매개변수 를 갖는 신경망이며, 부호 이론과의 유추에서 '''인코더'''라고 불린다.[8]
z의 차원은 x의 차원보다 작게 설정되는데, 이는 을 사용하여 데이터 x를 더 짧은 데이터 z로 "압축"하는 역할을 한다.[8]
인코더는 "감가상각 추론(amortized inference)"이라고 불리는 방식을 사용하는데, 이는 좋은 를 찾는 데 "투자"함으로써, 나중에 적분을 수행하지 않고도 x에서 z를 빠르게 추론할 수 있게 해준다.[8]
3. 2. 디코더 (Decoder)
디코더는 변분 오토인코더 모델의 두 번째 신경망이다. 잠재 공간을 입력 공간으로 매핑하는 함수, 예를 들어 잡음 분포의 평균으로 매핑하는 함수이다. 분산을 매핑하는 또 다른 신경망을 사용할 수 있지만, 단순화를 위해 생략할 수 있다. 이 경우 분산은 경사 하강법으로 최적화할 수 있다.[8]확률적 모델링의 관점에서, 선택된 매개변수화된 확률 분포 에 의한 데이터 의 우도를 최대화하는 것이 목표이다. 이 분포는 일반적으로 와 로 매개변수화된 가우시안 으로 선택되며, 지수족 분포의 구성원으로서 잡음 분포로 사용하기에 용이하다.
에 대한 주변화를 통해 를 구하면 다음과 같다.
:
여기서 는 관측 가능한 데이터 와 그 잠재 표현 또는 인코딩 에 대한 하의 결합 분포를 나타낸다. 연쇄 법칙에 따라, 위 식은 다음과 같이 다시 쓸 수 있다.
:
일반적인 변분 자동 인코더에서, 는 일반적으로 유한 차원의 실수 벡터로, 는 가우스 분포로 간주된다. 그러면 는 가우스 분포의 혼합물이 된다.
입력 데이터와 그 잠재 표현 간의 관계는 다음과 같이 정의할 수 있다.
- 사전 분포
- 우도
- 사후 분포
의 계산은 비용이 많이 들고 대부분의 경우 다루기 어렵기 때문에, 사후 분포를 근사하는 추가 함수를 도입하여 계산 속도를 높인다.
:
는 를 매개변수화하는 실수 값의 집합으로 정의된다.
이러한 방식으로, 문제는 좋은 확률적 자동 인코더를 찾는 것이 되는데, 여기서 조건부 우도 분포 는 "확률적 디코더"에 의해 계산되고, 근사된 사후 분포 는 "확률적 인코더"에 의해 계산된다.
인코더는 로, 디코더는 로 매개변수화한다.
'''변분 오토인코더'''는 오토인코딩 변분 베이즈 알고리즘을 사용하여 학습하는 신경망 기반의 생성 모델이다. 변분 오토인코더에서는 잠재 변수가 따르는 확률 밀도 함수 가 표준 정규 분포: 를 따르며, 가 따르는 조건부 확률 밀도 함수 가 , 여기서 와 같은 형태라고 가정한다. 여기서 는 매개변수 를 갖는 신경망이다.
의 차원은 의 차원보다 작게 설정한다. 이는 를 사용하여 에서 를 "복원"할 수 있음을 의미한다 (실제로는 이후에 정규 난수를 생성하는 과정이 있으므로, "복원"해도 원래대로 돌아가지는 않는다). 부호 이론과의 유추에서 를 '''디코더'''라고 부른다.
변분 오토인코더의 학습 알고리즘은 주어진 데이터 집합 에 대해, 오토인코딩 변분 베이즈 알고리즘을 사용하여 두 개의 신경망 과 의 매개변수 와 를 결정하는 것이다.
변분 오토인코더의 생성 알고리즘에서는 먼저 표준 정규 분포를 따르는 를 생성하고, 생성된 와 학습된 를 사용하여 를 생성한다.
3. 3. 재매개변수화 기법 (Reparameterization Trick)
를 효율적으로 찾는 일반적인 방법은 경사 상승법이다.
를 찾는 것은 간단하다. 그러나 에서는 ϕ가 확률 분포 자체에 나타나기 때문에 기대값 안에 를 넣을 수 없다. '''재매개변수화 기법'''(확률적 역전파라고도 함)[10]은 이러한 어려움을 우회한다.[8][11][12]
가장 중요한 예는 가 와 같이 정규 분포를 따르는 경우이다.
를 "표준 난수 생성기"로 하고, 로 를 구성함으로써 이를 재매개변수화할 수 있다. 여기서 는 콜레스키 분해를 통해 얻는다. 이다. 그러면 다음을 얻는다.
따라서 기울기의 불편 추정량을 얻어 확률적 경사 하강법을 허용한다.
z를 재매개변수화했으므로 를 찾아야 한다. 에 대한 확률 밀도 함수를 라고 하면, 이다. 여기서 는 에 대한 의 야코비 행렬이다. 이므로, 이다.
3. 4. 증거 하한 (Evidence Lower Bound, ELBO)
이 모델을 최적화하려면 "재구성 오류(reconstruction error)"와 쿨백-라이블러 발산(KL-D)의 두 가지 항을 알아야 한다. 두 항 모두 확률 모델의 자유 에너지 표현식에서 유도되므로 잡음 분포와 가정된 데이터의 사전 분포에 따라 다르다. 예를 들어, ImageNet과 같은 표준 VAE 작업은 일반적으로 가우스 분포 잡음을 갖는다고 가정하지만, 이진화된 MNIST와 같은 작업에는 베르누이 잡음이 필요하다. 자유 에너지 표현식에서 KL-D는 p-분포와 겹치는 q-분포의 확률 질량을 최대화하며, 안타깝게도 모드 추구(mode-seeking) 동작을 초래할 수 있다. "재구성" 항은 자유 에너지 표현식의 나머지 부분이며, 기대값을 계산하기 위해 샘플링 근사가 필요하다.[8]최근에는 쿨백-라이블러 발산(KL-D)을 다양한 통계적 거리로 대체하는 접근 방식이 사용되고 있다(아래 "통계적 거리 VAE 변형" 섹션 참조).
확률적 모델링의 관점에서, 선택된 매개변수화된 확률 분포 에 의한 데이터 의 우도를 최대화하는 것이 목표이다. 이 분포는 일반적으로 와 로 매개변수화된 가우시안 으로 선택되며, 지수족 분포의 구성원으로서 잡음 분포로 사용하기에 용이하다. 단순한 분포는 최대화하기 쉽지만, 잠재 변수 에 대한 사전 분포를 가정하는 분포의 경우에는 다루기 어려운 적분이 발생한다. 에 대한 주변화를 통해 를 구해보자.
:
여기서 는 관측 가능한 데이터 와 그 잠재 표현 또는 인코딩 에 대한 하의 결합 분포를 나타낸다. 연쇄 법칙에 따라, 위 식은 다음과 같이 다시 쓸 수 있다.
:
일반적인 변분 자동 인코더에서, 는 일반적으로 유한 차원의 실수 벡터로, 는 가우스 분포로 간주된다. 그러면 는 가우스 분포의 혼합물이 된다.
이제 입력 데이터와 그 잠재 표현 간의 관계 집합을 다음과 같이 정의할 수 있다.
- 사전 분포
- 우도
- 사후 분포
하지만, 의 계산은 비용이 많이 들고 대부분의 경우 다루기 어렵다. 계산 속도를 높여 실행 가능하게 하려면, 사후 분포를 근사하는 추가 함수를 도입해야 한다.
:
는 를 매개변수화하는 실수 값의 집합으로 정의된다. 이것은 때때로 "감가상각 추론(amortized inference)"이라고 불리는데, 좋은 를 찾는 데 "투자"함으로써, 나중에 적분을 수행하지 않고도 에서 를 빠르게 추론할 수 있기 때문이다.
이러한 방식으로, 문제는 좋은 확률적 자동 인코더를 찾는 것이 되는데, 여기서 조건부 우도 분포 는 "확률적 디코더"에 의해 계산되고, 근사된 사후 분포 는 "확률적 인코더"에 의해 계산된다.
인코더는 로, 디코더는 로 매개변수화한다.
많은 심층 학습 구현과 마찬가지로, 훈련은 일반적으로 미분 가능한 손실 함수와 역전파를 사용한다.
변분 오토인코더의 경우, 입력과 출력 간의 재구성 오류를 줄이기 위해 생성 모델 매개변수 θ를 공동으로 최적화하고, qϕ(z|x)를 pθ(z|x)에 최대한 가깝게 만들기 위해 ϕ를 최적화하는 것이 목표이다. 재구성 손실로는 평균 제곱 오차와 교차 엔트로피가 종종 사용된다.
두 분포 간의 거리 손실로는 쿨백-라이블러 발산 DKL(qϕ(z|x) || pθ(z|x))이 qϕ(z|x)를 pθ(z|x) 아래로 압축하는 좋은 선택이다.[8][9]
방금 정의한 거리 손실은 다음과 같이 확장된다.
:
이제 증거 하한(ELBO)을 정의한다.
:
ELBO를 최대화하는 것
:
은 ln pθ(x)를 동시에 최대화하고 DKL(qϕ(z|x) || pθ(z|x))를 최소화하는 것과 같다. 즉, 관찰된 데이터의 로그 우도를 최대화하고, 근사 사후 분포 qϕ(·|x)와 정확한 사후 분포 pθ(·|x)의 발산을 최소화하는 것이다.
제시된 형태는 최대화에 적합하지 않지만, 다음과 같은 동등한 형태가 있다.
:
여기서 ln pθ(x|z)는 로 구현된다. 왜냐하면 이것은 덧셈 상수를 제외하고 가 생성하는 값이기 때문이다. 즉, z를 조건으로 한 x의 분포를 Dθ(z)를 중심으로 하는 가우스 분포로 모델링한다. qϕ(z|x)와 pθ(z)의 분포는 종종 z|x ~ N(Eϕ(x), σϕ(x)²I) 와 z ~ N(0, I) 와 같은 가우스 분포로 선택되며, 가우스 분포의 KL 발산 공식을 사용하여 다음을 얻는다.
:
여기서 N은 z의 차원이다. ELBO 및 그 최대화에 대한 자세한 유도 및 해석은 주요 페이지를 참조하십시오.
표본 이 각 에 대해 다음과 같이 생성된다고 가정한다.
- 먼저 잠재 변수 가 어떤 확률 밀도 함수 를 따르도록 선택되고,
- 가 에 의존하는 어떤 확률 밀도 함수 를 따르도록 선택된다.
여기서 는 어떤 매개변수이며, 의 참값 는 알 수 없다. 또한 , 를 따르는 값을 선택하는 것은 계산량 측면에서 용이하다고 가정한다.
한편, 잠재 변수의 사후 분포 는 쉽게 계산할 수 없으므로, (쉽게 계산할 수 있는) 확률 밀도 함수 로 근사하는 것을 고려한다 ('''근사 사후 분포'''). 여기서 는 매개변수이다.
근사 사후 분포를 사용하면 주변 로그 우도 는 다음과 같이 변형할 수 있다.
:
우변의 첫 번째 항은 '''변분 하한''' 또는 '''ELBO'''라고 하며, 두 번째 항은 사후 분포-근사 사후 분포 간의 쿨백-라이블러 발산에 해당한다. 즉, 다음 식이 성립한다.
:
여기서 (깁스 부등식)이므로, 변분 하한 최대화는 다음 두 가지 의미를 갖는다.
- 근사 사후 분포의 근사 정확도 최대화 ()
- 생성 모델의 우도 최대화 ()
따라서 변분 하한 최대화는 최대 우도 추정의 대안으로 사용할 수 있다.
통계학에서의 표본 에 대한 변분 하한을 최대화하는 를 목표로 한다. 즉, 다음 식으로 표현된다.
:
4. 변형 모델
다양한 변분 오토인코더(VAE) 응용 프로그램과 확장 프로그램이 아키텍처를 다른 도메인에 적용하고 성능을 향상시키는 데 사용되었다.
일부 구조는 생성된 샘플의 품질을 직접 다루거나,[16][17] 표현 학습을 더욱 향상시키기 위해 둘 이상의 잠재 공간을 구현하기도 한다.
4. 1. β-VAE
β-VAE는 가중된 쿨백-라이블러 발산 항을 사용하여 자동으로 인수 분해된 잠재 표현을 발견하고 해석하는 구현체이다. 이 구현을 통해 β 값이 1보다 큰 경우 다양체 분리를 강제할 수 있다. 이 아키텍처는 감독 없이 얽히지 않은 잠재 요인을 발견할 수 있다.[13][14]4. 2. 조건부 VAE (Conditional VAE, CVAE)
조건부 VAE(CVAE)는 잠재 공간에 레이블 정보를 삽입하여 학습된 데이터의 결정론적 제약 표현을 강제한다.[15]4. 3. 생성적 적대 신경망 (GAN)과의 결합
일부 아키텍처는 하이브리드 모델을 얻기 위해 변분 오토인코더와 생성적 적대 신경망을 혼합한다.[18][19][20]4. 4. 통계적 거리 기반 VAE
β-VAE는 가중된 쿨백-라이블러 발산 항을 사용하여 자동으로 인수 분해된 잠재 표현을 발견하고 해석하는 구현이다. 이 구현을 통해 β 값이 1보다 큰 경우 다양체 분리를 강제할 수 있다. 이 아키텍처는 감독 없이 얽히지 않은 잠재 요인을 발견할 수 있다.[13][14]조건부 VAE(CVAE)는 잠재 공간에 레이블 정보를 삽입하여 학습된 데이터의 결정론적 제약 표현을 강제한다.[15]
일부 구조는 생성된 샘플의 품질을 직접 다루거나,[16][17] 표현 학습을 더욱 향상시키기 위해 둘 이상의 잠재 공간을 구현한다.
일부 아키텍처는 하이브리드 모델을 얻기 위해 VAE와 생성적 적대 신경망을 혼합하기도 한다.[18][19][20]
디데릭 P. 킹마(Diederik P. Kingma)와 맥스 웰링(Max Welling)의 초기 연구 이후,[21] VAE의 작동 방식을 보다 추상적인 방식으로 공식화하는 여러 절차가 제안되었다. 이러한 접근 방식에서 손실 함수는 다음 두 부분으로 구성된다.
- 일반적인 재구성 오류 부분: 인코더-디코더 매핑 이 항등 매핑에 가능한 한 가깝도록 한다.
- 변분 부분: 경험적 분포 가 인코더 를 통과할 때, 일반적으로 다변량 정규 분포로 간주되는 목표 분포를 복구한다.
손실에 대한 최종 공식은 다음과 같다.
통계적 거리 에는 특별한 속성이 필요하다. 예를 들어, 손실 함수를 확률적 최적화 알고리즘으로 최적화해야 하기 때문에 기댓값으로서 공식을 가져야 한다. 여러 거리를 선택할 수 있으며, 이는 여러 종류의 VAE를 만들어냈다.
통계적 거리에 따른 VAE의 종류는 다음과 같다.
참조
[1]
arXiv
Auto-Encoding Variational Bayes
2022-12-10
[2]
book
Variational Methods for Machine Learning with Applications to Deep Networks
Springer
[3]
arXiv
Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders
2017-01-13
[4]
book
2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)
2017-12-00
[5]
book
Infinite Variational Autoencoder for Semi-Supervised Learning
https://openaccess.t[...]
2017-00-00
[6]
journal
Variational Autoencoder for Semi-Supervised Text Classification
https://ojs.aaai.org[...]
2017-02-12
[7]
journal
Supervised Determined Source Separation with Multichannel Variational Autoencoder
https://direct.mit.e[...]
2019-09-01
[8]
arXiv
Auto-Encoding Variational Bayes
2013-12-20
[9]
news
From Autoencoder to Beta-VAE
https://lilianweng.g[...]
2018-08-12
[10]
journal
Stochastic Backpropagation and Approximate Inference in Deep Generative Models
https://proceedings.[...]
PMLR
2014-06-18
[11]
journal
Representation Learning: A Review and New Perspectives
https://ieeexplore.i[...]
[12]
arXiv
Semi-Supervised Learning with Deep Generative Models
2014-10-31
[13]
conference
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework
https://openreview.n[...]
2016-11-04
[14]
arXiv
Understanding disentangling in β-VAE
2018-04-10
[15]
conference
Learning Structured Output Representation using Deep Conditional Generative Models
https://proceedings.[...]
2015-01-01
[16]
arXiv
Diagnosing and Enhancing VAE Models
2019-10-30
[17]
arXiv
Training VAEs Under Structured Residuals
2018-07-31
[18]
journal
Autoencoding beyond pixels using a learned similarity metric
http://proceedings.m[...]
PMLR
2016-06-11
[19]
arXiv
CVAE-GAN: Fine-Grained Image Generation Through Asymmetric Training
2017-00-00
[20]
journal
Zero-VAE-GAN: Generating Unseen Features for Generalized and Transductive Zero-Shot Learning
https://ieeexplore.i[...]
2020-00-00
[21]
arXiv
Auto-Encoding Variational Bayes
2022-12-10
[22]
conference
Sliced Wasserstein Auto-Encoders
https://openreview.n[...]
ICPR
2019-00-00
[23]
journal
Radon-Sobolev Variational Auto-Encoders
https://www.scienced[...]
[24]
journal
A Polya Contagion Model for Networks
2017-00-00
[25]
arXiv
Wasserstein Auto-Encoders
2018-00-00
[26]
arXiv
Kernelized Variational Autoencoders
2019-00-00
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com