고가용성
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
고가용성은 시스템이 지정된 기간 동안 중단 없이 작동할 수 있는 정도를 의미하며, 시스템 설계의 중요한 목표 중 하나이다. 신뢰성 공학의 원칙에 따라 단일 실패 지점 제거, 신뢰할 수 있는 전환, 오류 발생 시 감지를 통해 달성할 수 있다. 고가용성은 가동 중단 시간을 최소화하여 측정되며, 가용성 백분율로 표시된다. 중복성, 부하 분산, 재해 복구 등의 다양한 구성 방식을 통해 고가용성을 확보할 수 있으며, 군사 제어 시스템과 같은 특정 분야에서 특히 중요하다.
더 읽어볼만한 페이지
- 응용확률론 - 자급자족
자급자족은 개인이 스스로 생산한 것만 소비하며 자립적 건축, 지속 가능한 농업, 재생 에너지 등을 통해 실현되는 지속 가능한 삶의 방식이다. - 응용확률론 - 진폭 편이 방식
진폭 편이 방식(ASK)은 반송파의 진폭을 변화시켜 데이터를 표현하는 변조 방식이며, 온오프 변조와 다치 ASK가 있으며, 오류 확률은 다양한 요인에 의해 영향을 받는다. - 품질 관리 - OpenVMS
OpenVMS는 DEC에서 개발한 멀티유저, 멀티프로세싱 가상 메모리 기반 운영 체제로, 고도의 안정성, 보안성, 확장성을 특징으로 하며 다양한 아키텍처, 클러스터링, 네트워킹, 프로그래밍 언어 및 개발 도구를 지원한다. - 품질 관리 - 산점도
산점도는 두 변수 간의 관계를 좌표평면 위에 점으로 시각화하여 상관관계, 패턴, 이상점 등을 파악하는 데 사용되는 그래프이다. - 정보 시스템 - 추천 시스템
추천 시스템은 사용자의 선호도와 행동 패턴을 분석하여 개인 맞춤형 정보나 상품을 추천하는 시스템으로, 다양한 알고리즘과 새로운 기술이 도입되어 정확도와 개인화 수준을 높이고 있으며, 여러 서비스에서 활용되면서 정확도 외 다양성, 개인정보 보호 등 다양한 요소를 고려한 평가가 중요해지고 있다. - 정보 시스템 - 정보 관리
정보 관리는 조직의 목표 달성을 위해 데이터, 정보, 지식을 효과적으로 활용하는 전략적 과정으로, 정보 기술 발전과 함께 전략적으로 진화했으며, 의사결정, 정보 시스템 구축, 프레임워크 활용, 조직 설계 등을 통해 경쟁력 확보에 필수적인 복합적인 관리 활동이다.
| 고가용성 |
|---|
2. 역사
2. 1. 고가용성 개념의 등장
2. 2. 인터넷과 분산 시스템의 발전
3. 원칙
신뢰성 공학에는 시스템 설계를 통해 고가용성을 달성하는 데 도움이 되는 세 가지 원칙이 있다.
# 단일 실패 지점 제거. 이는 구성 요소의 실패가 전체 시스템의 실패를 의미하지 않도록 시스템에 중복성을 추가하거나 구축하는 것을 의미한다.
# 신뢰할 수 있는 전환. 중복성 (공학) 시스템에서 전환 지점 자체가 단일 실패 지점이 되는 경향이 있다. 신뢰할 수 있는 시스템은 신뢰할 수 있는 전환을 제공해야 한다.
# 오류 발생 시 감지. 위의 두 가지 원칙을 준수하면 사용자는 오류를 전혀 보지 못할 수 있지만, 유지 관리 활동은 오류를 감지해야 한다.
3. 1. 단일 실패 지점 제거
신뢰성 공학에서 시스템 설계를 통해 고가용성을 달성하는 데 도움이 되는 세 가지 원칙이 있다.# 단일 실패 지점 제거. 이는 구성 요소의 실패가 전체 시스템의 실패를 의미하지 않도록 시스템에 중복성을 추가하거나 구축하는 것을 의미한다.
# 신뢰할 수 있는 전환. 중복성 시스템에서 전환 지점 자체가 단일 실패 지점이 되는 경향이 있다. 신뢰할 수 있는 시스템은 신뢰할 수 있는 전환을 제공해야 한다.
# 오류 발생 시 감지. 위의 두 가지 원칙을 준수하면 사용자는 오류를 전혀 보지 못할 수 있지만, 유지 관리 활동은 오류를 감지해야 한다.
3. 2. 신뢰할 수 있는 전환
신뢰성 공학에는 고가용성을 달성하는 데 도움이 되는 시스템 설계의 세 가지 원칙이 있다. 그 중 하나는 신뢰할 수 있는 전환이다. 중복성 (공학) 시스템에서 전환 지점 자체가 단일 실패 지점이 되는 경향이 있다. 신뢰할 수 있는 시스템은 신뢰할 수 있는 전환을 제공해야 한다.3. 3. 오류 감지
신뢰성 공학에는 고가용성을 달성하는 데 도움이 되는 시스템 설계의 세 가지 원칙이 있다.# 단일 실패 지점 제거. 이는 구성 요소의 실패가 전체 시스템의 실패를 의미하지 않도록 시스템에 중복성을 추가하거나 구축하는 것을 의미한다.
# 신뢰할 수 있는 전환. 중복성 (공학) 시스템에서 전환 지점 자체가 단일 실패 지점이 되는 경향이 있다. 신뢰할 수 있는 시스템은 신뢰할 수 있는 전환을 제공해야 한다.
# 오류 발생 시 감지. 위의 두 가지 원칙을 준수하면 사용자는 오류를 전혀 보지 못할 수 있지만, 유지 관리 활동은 오류를 감지해야 한다.
4. 가동 중단
예정된 가동 중단과 예정되지 않은 가동 중단을 구분할 수 있다. 일반적으로, 예정된 가동 중단은 시스템 운영에 지장을 주는 유지 보수의 결과이며, 현재 설치된 시스템 설계로는 피할 수 없다. 예정된 가동 중단에는 시스템 소프트웨어에 대한 재부팅이 필요한 패치 또는 재부팅 시에만 적용되는 시스템 구성 변경 등이 포함될 수 있다. 일반적으로 예정된 가동 중단은 논리적인 관리자가 시작한 이벤트의 결과이다. 예정되지 않은 가동 중단은 일반적으로 하드웨어나 소프트웨어 고장, 또는 환경 이상과 같은 물리적 이벤트로 인해 발생한다. 예정되지 않은 가동 중단의 예로는 정전, CPU 또는 RAM 구성 요소 고장 (또는 다른 하드웨어 구성 요소 고장 가능성), 과열 관련 종료, 논리적 또는 물리적으로 끊어진 네트워크 연결, 보안 침해, 또는 다양한 응용 프로그램, 미들웨어, 운영 체제 실패 등이 있다.
사용자가 예정된 가동 중단에 대해 경고를 받을 수 있다면 이러한 구분이 유용하다. 그러나 진정한 고가용성이 요구되는 경우, 가동 중단은 예정되었는지 여부에 관계없이 가동 중단이다.
많은 컴퓨팅 사이트는 가동 중단이 컴퓨팅 사용자 커뮤니티에 거의 또는 전혀 영향을 미치지 않는다고 가정하여 가용성 계산에서 예정된 가동 중단을 제외한다. 이렇게 함으로써 엄청나게 높은 가용성을 주장할 수 있으며, 이는 지속적인 가용성의 환상을 줄 수 있다. 진정으로 지속적인 가용성을 보이는 시스템은 비교적 드물고 가격이 더 비싸며, 대부분 단일 실패 지점을 제거하고 온라인 하드웨어, 네트워크, 운영 체제, 미들웨어 및 응용 프로그램 업그레이드, 패치 및 교체를 허용하는 특별한 설계를 신중하게 구현했다. 특정 시스템의 경우, 모든 사람이 밤에 퇴근한 후 사무실 건물에서의 시스템 가동 중단과 같이 예정된 가동 중단은 중요하지 않다.
4. 1. 예정된 가동 중단
유지 보수로 인해 시스템 운영에 지장을 주는 예정된 가동 중단은 현재 설치된 시스템 설계로는 피할 수 없는 경우가 일반적이다. 시스템 소프트웨어에 대한 재부팅이 필요한 패치, 재부팅 시에만 적용되는 시스템 구성 변경 등이 예정된 가동 중단에 해당한다. 예정된 가동 중단은 논리적인 관리자에 의해 시작되는 경우가 많다.많은 컴퓨팅 사이트에서는 가동 중단이 사용자에게 거의 영향을 미치지 않는다고 가정하여 가용성 계산에서 예정된 가동 중단을 제외하기도 한다. 이를 통해 지속적인 가용성의 환상을 줄 수 있는 높은 가용성을 주장할 수 있다. 진정으로 지속적인 가용성을 보이는 시스템은 드물고 가격이 비싸며, 단일 실패 지점을 제거하고 온라인 업그레이드, 패치, 교체를 허용하는 설계를 구현한다.
4. 2. 예정되지 않은 가동 중단
예정된 가동 중단과 예정되지 않은 가동 중단을 구분할 수 있다. 일반적으로, 예정된 가동 중단은 시스템 운영에 지장을 주는 유지 보수의 결과이며, 일반적으로 현재 설치된 시스템 설계로는 피할 수 없다. 예정된 가동 중단 이벤트에는 시스템 소프트웨어에 대한 재부팅이 필요한 패치 또는 재부팅 시에만 적용되는 시스템 구성 변경 등이 포함될 수 있다. 일반적으로 예정된 가동 중단은 일반적으로 논리적인 관리자가 시작한 이벤트의 결과이다. 예정되지 않은 가동 중단 이벤트는 일반적으로 하드웨어 또는 소프트웨어 고장 또는 환경 이상과 같은 물리적 이벤트로 인해 발생한다. 예정되지 않은 가동 중단 이벤트의 예로는 정전, CPU 또는 RAM 구성 요소 고장 (또는 다른 하드웨어 구성 요소 고장 가능성), 과열 관련 종료, 논리적 또는 물리적으로 끊어진 네트워크 연결, 보안 침해 또는 다양한 응용 프로그램, 미들웨어, 운영 체제 실패 등이 있다.사용자가 예정된 가동 중단에 대해 경고를 받을 수 있다면 이러한 구분이 유용하다. 그러나 진정한 고가용성이 요구되는 경우, 가동 중단은 예정되었는지 여부에 관계없이 가동 중단이다.
많은 컴퓨팅 사이트는 가동 중단이 컴퓨팅 사용자 커뮤니티에 거의 또는 전혀 영향을 미치지 않는다고 가정하여 가용성 계산에서 예정된 가동 중단을 제외한다. 이렇게 함으로써 엄청나게 높은 가용성을 주장할 수 있으며, 이는 지속적인 가용성의 환상을 줄 수 있다. 진정으로 지속적인 가용성을 보이는 시스템은 비교적 드물고 가격이 더 비싸며, 대부분 단일 실패 지점을 제거하고 온라인 하드웨어, 네트워크, 운영 체제, 미들웨어 및 응용 프로그램 업그레이드, 패치 및 교체를 허용하는 특별한 설계를 신중하게 구현했다. 특정 시스템의 경우, 모든 사람이 밤에 퇴근한 후 사무실 건물에서의 시스템 가동 중단과 같이 예정된 가동 중단은 중요하지 않다.
5. 가용성 측정
가용성은 일반적으로 특정 연도의 가동 시간의 백분율로 표시된다. 다음 표는 시스템이 지속적으로 작동해야 한다고 가정할 때 특정 가용성 백분율에 대해 허용되는 중단 시간을 보여준다. 서비스 수준 협약은 월별 청구 주기에 맞춰 서비스 크레딧을 계산하기 위해 월별 중단 시간 또는 가용성을 참조하는 경우가 많다. 다음 표는 주어진 가용성 백분율을 시스템을 사용할 수 없는 해당 시간으로 변환한 것이다.
| 가용성 % | 한 해 중 다운타임 | 분기 중 다운타임 | 1개월 중 다운타임 | 1주 중 다운타임 | 1일(24시간) 중 다운타임 |
|---|---|---|---|---|---|
| 90% ("1-9") | 36.53 일 | 9.13 일 | 73.05 시간 | 16.80 시간 | 2.40 시간 |
| 95% ("1-9-5") | 18.26 일 | 4.56 일 | 36.53 시간 | 8.40 시간 | 1.20 시간 |
| 97% ("1-9-7") | 10.96 일 | 2.74 일 | 21.92 시간 | 5.04 시간 | 43.20 분 |
| 98% ("1-9-8") | 7.31 일 | 43.86 시간 | 14.61 시간 | 3.36 시간 | 28.80 분 |
| 99% ("2-9") | 3.65 일 | 21.9 시간 | 7.31 시간 | 1.68 시간 | 14.40 분 |
| 99.5% ("2-9-5") | 1.83 일 | 10.98 시간 | 3.65 시간 | 50.40 분 | 7.20 분 |
| 99.8% ("2-9-8") | 17.53 시간 | 4.38 시간 | 87.66 분 | 20.16 분 | 2.88 분 |
| 99.9% ("3-9") | 8.77 시간 | 2.19 시간 | 43.83 분 | 10.08 분 | 1.44 분 |
| 99.95% ("3-9-5") | 4.38 시간 | 65.7 분 | 21.92 분 | 5.04 분 | 43.20 초 |
| 99.99% ("4-9") | 52.60 분 | 13.15 분 | 4.38 분 | 1.01 분 | 8.64 초 |
| 99.995% ("4-9-5") | 26.30 분 | 6.57 분 | 2.19 분 | 30.24 초 | 4.32 초 |
| 99.999% ("5-9") | 5.26 분 | 1.31 분 | 26.30 초 | 6.05 초 | 864.00 밀리초 |
| 99.9999% ("6-9") | 31.56 초 | 7.89 초 | 2.63 초 | 604.80 밀리초 | 86.40 밀리초 |
| 99.99999% ("7-9") | 3.16 초 | 0.79 초 | 262.98 밀리초 | 60.48 밀리초 | 8.64 밀리초 |
| 99.999999% ("8-9") | 315.58 밀리초 | 78.89 밀리초 | 26.30 밀리초 | 6.05 밀리초 | 864.00 마이크로초 |
| 99.9999999% ("9-9") | 31.56 밀리초 | 7.89 밀리초 | 2.63 밀리초 | 604.80 마이크로초 | 86.40 마이크로초 |
가동 시간과 가용성이라는 용어는 종종 같은 의미로 사용되지만 항상 동일한 것을 의미하지는 않는다. 예를 들어, 네트워크 중단의 경우 시스템이 서비스가 "가용"하지 않은 상태에서 "가동"될 수 있다. 또는 소프트웨어 유지 관리를 받고 있는 시스템은 시스템 관리자가 작업할 수 있도록 "가용"할 수 있지만 해당 서비스는 최종 사용자 또는 고객에게 "가동"되지 않은 것처럼 보일수 있다. 따라서 용어의 대상이 여기에서 중요하며, 논의의 초점이 서버 하드웨어, 서버 OS, 기능 서비스, 소프트웨어 서비스/프로세스 또는 이와 유사한 것이라면, 가동 시간과 가용성이라는 단어를 동의어로 사용할 수 있는 것은 논의의 대상이 단일하고 일관된 경우뿐이다.
가용성 측정은 어느 정도 해석의 여지가 있다. 윤년이 아닌 해에 365일 동안 가동된 시스템이 최고 사용량 기간 동안 9시간 동안 지속된 네트워크 오류로 인해 중단되었을 수 있다. 사용자 커뮤니티는 시스템을 사용할 수 없다고 생각할 것이지만, 시스템 관리자는 100% 가동 시간을 주장할 것이다. 그러나 가용성의 진정한 정의를 감안할 때, 시스템은 약 99.9%의 가용성을 가지며, 즉 "쓰리 나인"(윤년이 아닌 해에 8760시간 중 8751시간 가용)을 나타낸다. 또한, 시스템이 계속 작동하더라도 성능 문제가 발생하는 시스템은 사용자에 의해 부분적으로 또는 완전히 사용할 수 없는 것으로 간주되는 경우가 많다. 마찬가지로, 특정 애플리케이션 기능의 사용 불가 상태는 관리자가 알아차리지 못할 수 있지만 사용자에게는 치명적일 수 있다. 진정한 가용성 측정은 총체적이다.
가용성은 이를 결정하기 위해 측정되어야 하며, 이상적으로는 자체적으로 고가용성을 갖춘 포괄적인 모니터링 도구("계측")를 사용하여 측정해야 한다. 계측이 부족한 경우, 신용 카드 처리 시스템이나 전화 교환기와 같이 주야간 대량의 트랜잭션 처리를 지원하는 시스템은 최소한 사용자 스스로에 의해 주기적인 수요 감소를 경험하는 시스템보다 더 잘 모니터링되는 경향이 있다.
대안적인 지표는 고장 간 평균 시간(MTBF)이다.
5. 1. 백분율 계산
가용성은 일반적으로 특정 연도의 가동 시간 백분율로 표시된다. 다음 표는 시스템이 지속적으로 작동해야 한다고 가정할 때 특정 가용성 백분율에 대해 허용되는 중단 시간을 보여준다. 서비스 수준 협약은 월별 청구 주기에 맞춰 서비스 크레딧을 계산하기 위해 월별 중단 시간 또는 가용성을 참조하는 경우가 많다. 다음 표는 주어진 가용성 백분율을 시스템을 사용할 수 없는 해당 시간으로 변환한 것이다.| 가용성 % | 한 해 중 다운타임 | 분기 중 다운타임 | 1개월 중 다운타임 | 1주 중 다운타임 | 1일(24시간) 중 다운타임 |
|---|---|---|---|---|---|
| 90% ("one nine") | 36.53 일 | 9.13 일 | 73.05 시간 | 16.80 시간 | 2.40 시간 |
| 95% ("one and a half nines") | 18.26 일 | 4.56 일 | 36.53 시간 | 8.40 시간 | 1.20 시간 |
| 97% | 10.96 일 | 2.74 일 | 21.92 시간 | 5.04 시간 | 43.20 분 |
| 98% | 7.31 일 | 43.86 시간 | 14.61 시간 | 3.36 시간 | 28.80 분 |
| 99% ("two nines") | 3.65 일 | 21.9 시간 | 7.31 시간 | 1.68 시간 | 14.40 분 |
| 99.5% ("two and a half nines") | 1.83 일 | 10.98 시간 | 3.65 시간 | 50.40 분 | 7.20 분 |
| 99.8% | 17.53 시간 | 4.38 시간 | 87.66 분 | 20.16 분 | 2.88 분 |
| 99.9% ("three nines") | 8.77 시간 | 2.19 시간 | 43.83 분 | 10.08 분 | 1.44 분 |
| 99.95% ("three and a half nines") | 4.38 시간 | 65.7 분 | 21.92 분 | 5.04 분 | 43.20 초 |
| 99.99% ("four nines") | 52.60 분 | 13.15 분 | 4.38 분 | 1.01 분 | 8.64 초 |
| 99.995% ("four and a half nines") | 26.30 분 | 6.57 분 | 2.19 분 | 30.24 초 | 4.32 초 |
| 99.999% ("five nines") | 5.26 분 | 1.31 분 | 26.30 초 | 6.05 초 | 864.00 밀리초 |
| 99.9999% ("six nines") | 31.56 초 | 7.89 초 | 2.63 초 | 604.80 밀리초 | 86.40 밀리초 |
| 99.99999% ("seven nines") | 3.16 초 | 0.79 초 | 262.98 밀리초 | 60.48 밀리초 | 8.64 밀리초 |
| 99.999999% ("eight nines") | 315.58 밀리초 | 78.89 밀리초 | 26.30 밀리초 | 6.05 밀리초 | 864.00 마이크로초 |
| 99.9999999% ("nine nines") | 31.56 밀리초 | 7.89 밀리초 | 2.63 밀리초 | 604.80 마이크로초 | 86.40 마이크로초 |
"n-나인" 가용성 백분율에 대한 허용된 가동 중단 시간 기간을 계산하는 또 다른 기억술은 하루에 초 공식을 사용하는 것이다.
예를 들어 90% ("1 나인")은 지수 을 생성하므로 허용되는 가동 중단 시간은 하루에 초이다.
또한 99.999% ("5 나인")은 지수 을 제공하므로 허용되는 가동 중단 시간은 하루에 초이다.
5. 2. 나인(9) 표기법
간단한 기억 보조 규칙에 따르면 ''5 나인''은 연간 약 5분의 다운타임을 허용한다. 10을 곱하거나 나누어 변형을 도출할 수 있는데, 예를 들어 4 나인은 50분이고 3 나인은 500분이다. 반대로 6 나인은 0.5분 (30초)이고 7 나인은 3초이다.[10]특정 규모의 백분율은 때때로 자릿수의 나인의 수 또는 "나인 클래스"로 지칭된다. 예를 들어, 중단 없이 제공되는 전기(정전 또는 전압 강하 또는 서지 전압)가 99.999%의 시간 동안 작동한다면 5 나인 신뢰성, 즉 5 클래스를 갖게 된다.[10] 이 용어는 메인프레임[11][12] 또는 엔터프라이즈 컴퓨팅과 관련하여 사용되며, 종종 서비스 수준 계약의 일부로 사용된다.
마찬가지로, 5로 끝나는 백분율은 전통적으로 나인의 수와 "다섯"으로 구성된 고유한 이름이 있으며, 99.95%는 "세 나인 다섯"으로 3N5로 줄여서 표기한다.[13][14] 이는 비공식적으로 "세 개 반 나인"이라고도 부르지만,[15] 이는 정확하지 않다. 99.95% 가용성은 3.3 나인이지 3.5 나인이 아니다.[16]
시스템의 사용 불가 를 기반으로 한 ''9s 클래스'' 의 공식은 다음과 같다.
:
(바닥 함수와 천장 함수 참조).
유사한 측정은 때때로 물질의 순도를 설명하는 데 사용된다.
일반적으로, 나인의 수는 공식에 적용하기 어려우므로 네트워크 엔지니어가 가용성을 모델링하고 측정할 때 자주 사용되지 않는다. 더 자주, 확률로 표현된 사용 불가 또는 연간 다운 타임이 인용된다. 나인의 수로 지정된 가용성은 종종 마케팅 문서에서 볼 수 있다. "나인"의 사용은 사용 불가의 영향이 발생하는 시간에 따라 다르다는 것을 적절하게 반영하지 못하므로 의문이 제기되었다.[17]
때로는 유머러스한 용어 "나인 파이브"(55.5555555%)가 "파이브 나인"(99.999%)과 대조하여 사용되기도 하지만,[18][19][20] 이는 실제 목표가 아니라 합리적인 목표를 전혀 달성하지 못하는 것에 대한 풍자적인 언급이다.
5. 3. 가용성과 다운타임
가용성은 일반적으로 특정 연도의 가동 시간의 백분율로 표시된다. 다음 표는 시스템이 지속적으로 작동해야 한다고 가정할 때 특정 가용성 백분율에 대해 허용되는 중단 시간을 보여준다. 서비스 수준 협약은 월별 청구 주기에 맞춰 서비스 크레딧을 계산하기 위해 월별 중단 시간 또는 가용성을 참조하는 경우가 많다. 다음 표는 주어진 가용성 백분율을 시스템을 사용할 수 없는 해당 시간으로 변환한 것이다.| 가용성 % | 1년당 중단 시간 | 분기당 중단 시간 | 월별 중단 시간 | 주당 중단 시간 | 일일 중단 시간(24시간) |
|---|---|---|---|---|---|
| 90% ("1-9") | 36.53일 | 9.13일 | 73.05시간 | 16.80시간 | 2.40시간 |
| 95% ("1-9-5") | 18.26일 | 4.56일 | 36.53시간 | 8.40시간 | 1.20시간 |
| 97% ("1-9-7") | 10.96일 | 2.74일 | 21.92시간 | 5.04시간 | 43.20분 |
| 98% ("1-9-8") | 7.31일 | 43.86시간 | 14.61시간 | 3.36시간 | 28.80분 |
| 99% ("2-9") | 3.65일 | 21.9시간 | 7.31시간 | 1.68시간 | 14.40분 |
| 99.5% ("2-9-5") | 1.83일 | 10.98시간 | 3.65시간 | 50.40분 | 7.20분 |
| 99.8% ("2-9-8") | 17.53시간 | 4.38시간 | 87.66분 | 20.16분 | 2.88분 |
| 99.9% ("3-9") | 8.77시간 | 2.19시간 | 43.83분 | 10.08분 | 1.44분 |
| 99.95% ("3-9-5") | 4.38시간 | 65.7분 | 21.92분 | 5.04분 | 43.20초 |
| 99.99% ("4-9") | 52.60분 | 13.15분 | 4.38분 | 1.01분 | 8.64초 |
| 99.995% ("4-9-5") | 26.30분 | 6.57분 | 2.19분 | 30.24초 | 4.32초 |
| 99.999% ("5-9") | 5.26분 | 1.31분 | 26.30초 | 6.05초 | 864.00 밀리초 |
| 99.9999% ("6-9") | 31.56초 | 7.89초 | 2.63초 | 604.80밀리초 | 86.40밀리초 |
| 99.99999% ("7-9") | 3.16초 | 0.79초 | 262.98밀리초 | 60.48밀리초 | 8.64밀리초 |
| 99.999999% ("8-9") | 315.58밀리초 | 78.89밀리초 | 26.30밀리초 | 6.05밀리초 | 864.00 마이크로초 |
| 99.9999999% ("9-9") | 31.56밀리초 | 7.89밀리초 | 2.63밀리초 | 604.80마이크로초 | 86.40마이크로초 |
| 99.99999999% ("10-9") | 3.16밀리초 | 788.40마이크로초 | 262.80마이크로초 | 60.48마이크로초 | 8.64마이크로초 |
| 99.999999999% ("11-9") | 315.58마이크로초 | 78.84마이크로초 | 26.28마이크로초 | 6.05마이크로초 | 864.00 나노초 |
| 99.9999999999% ("12-9") | 31.56마이크로초 | 7.88마이크로초 | 2.63마이크로초 | 604.81나노초 | 86.40나노초 |
가동 시간과 가용성이라는 용어는 종종 같은 의미로 사용되지만 항상 동일한 것을 의미하지는 않는다. 예를 들어, 네트워크 중단의 경우 시스템이 서비스가 "가용"하지 않은 상태에서 "가동"될 수 있다. 또는 소프트웨어 유지 관리를 받고 있는 시스템은 시스템 관리자가 작업할 수 있도록 "가용"할 수 있지만 해당 서비스는 최종 사용자 또는 고객에게 "가동"되지 않은 것처럼 보일수 있다. 따라서 용어의 대상이 여기에서 중요하며, 논의의 초점이 서버 하드웨어, 서버 OS, 기능 서비스, 소프트웨어 서비스/프로세스 또는 이와 유사한 것이라면, 가동 시간과 가용성이라는 단어를 동의어로 사용할 수 있는 것은 논의의 대상이 단일하고 일관된 경우뿐이다.
간단한 기억 보조 규칙에 따르면 ''5 나인''은 연간 약 5분의 다운타임을 허용한다. 10을 곱하거나 나누어 변형을 도출할 수 있다. 4 나인은 50분이고 3 나인은 500분이다. 반대 방향으로 6 나인은 0.5분 (30초)이고 7 나인은 3초이다.
"n-나인" 가용성 백분율에 대한 허용된 가동 중단 시간 기간을 계산하는 또 다른 기억술은 하루에 초 공식을 사용하는 것이다.
예를 들어 90% ("1 나인")은 지수 을 생성하므로 허용되는 가동 중단 시간은 하루에 초이다.
또한 99.999% ("5 나인")은 지수 을 제공하므로 허용되는 가동 중단 시간은 하루에 초이다.
6. 관련 개념
복구 시간 (또는 예상 수리 시간 (ETR), 복구 시간 목표(RTO)라고도 함)은 가용성과 밀접하게 관련되어 있으며, 계획된 중단에 필요한 총 시간 또는 계획되지 않은 중단으로부터 완전히 복구하는 데 필요한 시간이다. 또 다른 지표는 평균 복구 시간(MTTR)이다. 특정 시스템 설계 및 장애의 경우 복구 시간은 무한대가 될 수 있다. 즉, 완전한 복구가 불가능하다. 이러한 예로는 보조 재해 복구 데이터 센터가 없을 때 데이터 센터와 시스템을 파괴하는 화재 또는 홍수가 있다.
또 다른 관련 개념은 데이터 가용성으로, 데이터베이스 및 기타 정보 저장 시스템이 시스템 트랜잭션을 충실하게 기록하고 보고하는 정도이다. 정보 관리는 종종 다양한 장애 이벤트에서 허용 가능한 (또는 실제) 데이터 손실을 결정하기 위해 데이터 가용성 또는 복구 시점 목표에 별도로 초점을 맞춘다. 일부 사용자는 애플리케이션 서비스 중단을 견딜 수 있지만 데이터 손실은 견딜 수 없다.
서비스 수준 계약(SLA)은 조직의 가용성 목표 및 요구 사항을 공식화한다.
HA의 개념은 앞서 언급한 "높은 가용성을 자랑하는 것"이며, 이를 실현한 시스템을 HA 구성 또는 HA 서버, HA 클러스터 등으로 칭한다. HA를 실현하기 위한 수단으로는 몇 가지 방식이 있지만, 기본적으로 시스템적인 이중화가 이루어진 구성을 HA 구성이라고 부르는 것이 일반적이다.
6. 1. 복원력 (Resilience)
네트워크 '''복원력'''은 "고장과 정상적인 작동에 대한 문제에 직면하여 허용 가능한 수준의 서비스를 제공하고 유지하는" 능력을 의미한다.[3] 서비스에 대한 위협과 문제는 단순한 구성 오류에서 대규모 자연 재해, 표적 공격에 이르기까지 다양할 수 있다.[4] 따라서 네트워크 복원력은 매우 광범위한 주제와 관련이 있다. 주어진 통신 네트워크의 복원력을 높이기 위해서는 발생 가능한 문제와 위험을 파악하고 보호할 서비스에 적합한 복원력 지표를 정의해야 한다.[5]통신 네트워크가 중요 인프라의 운영에 기본적인 요소가 되면서 네트워크 복원력의 중요성은 지속적으로 증가하고 있다.[6] 최근의 노력은 중요 인프라에 적용하여 네트워크 및 컴퓨팅 복원력을 해석하고 개선하는 데 중점을 두고 있다.[7] 예를 들어, 네트워크 자체의 서비스가 아닌 네트워크를 통한 서비스 프로비저닝을 복원력 목표로 고려할 수 있으며, 이는 네트워크와 네트워크 상에서 실행되는 서비스 모두의 조율된 응답을 필요로 할 수 있다.[8]
이러한 서비스에는 분산 처리, 네트워크 스토리지 지원, 화상 회의, 인스턴트 메시징, 온라인 협업과 같은 통신 서비스 유지, 필요에 따라 응용 프로그램 및 데이터에 대한 접근 등이 포함된다.
복원력과 생존성은 특정 연구의 맥락에 따라 상호 교환적으로 사용된다.[9] 복구 시간 (또는 예상 수리 시간 (ETR), 복구 시간 목표 (RTO)라고도 함)은 가용성과 밀접하게 관련되어 있으며, 계획된 중단 또는 계획되지 않은 중단으로부터 완전히 복구하는 데 필요한 총 시간이다. 또 다른 지표는 평균 복구 시간 (MTTR)이다. 보조 재해 복구 데이터 센터가 없을 때 데이터 센터와 시스템을 파괴하는 화재 또는 홍수와 같이, 특정 시스템 설계 및 장애의 경우 복구 시간은 무한대가 될 수 있으며 완전한 복구가 불가능하다.
데이터 가용성은 데이터베이스 및 기타 정보 저장 시스템이 시스템 트랜잭션을 충실하게 기록하고 보고하는 정도이다. 정보 관리는 종종 다양한 장애 이벤트에서 허용 가능한 (또는 실제) 데이터 손실을 결정하기 위해 데이터 가용성 또는 복구 시점 목표에 별도로 초점을 맞춘다. 일부 사용자는 애플리케이션 서비스 중단을 견딜 수 있지만 데이터 손실은 견딜 수 없다.
서비스 수준 계약("SLA")은 조직의 가용성 목표 및 요구 사항을 공식화한다.
6. 2. 복구 시간 목표 (RTO)
복구 시간 (또는 예상 수리 시간 (ETR), 복구 시간 목표(RTO)라고도 함)은 가용성과 밀접하게 관련되어 있으며, 계획된 중단에 필요한 총 시간 또는 계획되지 않은 중단으로부터 완전히 복구하는 데 필요한 시간이다. 또 다른 지표는 평균 복구 시간(MTTR)이다. 특정 시스템 설계 및 장애의 경우 복구 시간은 무한대가 될 수 있다. 즉, 완전한 복구가 불가능하다. 이러한 예로는 보조 재해 복구 데이터 센터가 없을 때 데이터 센터와 시스템을 파괴하는 화재 또는 홍수가 있다.또 다른 관련 개념은 데이터 가용성으로, 데이터베이스 및 기타 정보 저장 시스템이 시스템 트랜잭션을 충실하게 기록하고 보고하는 정도이다. 정보 관리는 종종 다양한 장애 이벤트에서 허용 가능한 (또는 실제) 데이터 손실을 결정하기 위해 데이터 가용성 또는 복구 시점 목표에 별도로 초점을 맞춘다. 일부 사용자는 애플리케이션 서비스 중단을 견딜 수 있지만 데이터 손실은 견딜 수 없다.
서비스 수준 계약(SLA)은 조직의 가용성 목표 및 요구 사항을 공식화한다.
6. 3. 평균 복구 시간 (MTTR)
복구 시간(예상 수리 시간(ETR), 복구 시간 목표(RTO)라고도 함)은 가용성과 밀접하게 관련되어 있으며, 계획되거나 계획되지 않은 중단으로부터 완전히 복구하는 데 필요한 시간이다. 또 다른 지표는 평균 복구 시간(MTTR)이다. 특정 시스템 설계 및 장애의 경우 복구 시간은 무한대가 될 수 있다. 즉, 완전한 복구가 불가능하다. 예를 들어 보조 재해 복구 데이터 센터가 없을 때 데이터 센터와 시스템을 파괴하는 화재 또는 홍수가 이에 해당한다.데이터 가용성은 데이터베이스 및 기타 정보 저장 시스템이 시스템 트랜잭션을 충실하게 기록하고 보고하는 정도를 나타내는 관련 개념이다. 정보 관리는 종종 다양한 장애 이벤트에서 허용 가능한 (또는 실제) 데이터 손실을 결정하기 위해 데이터 가용성 또는 복구 시점 목표에 별도로 초점을 맞춘다. 일부 사용자는 애플리케이션 서비스 중단을 견딜 수 있지만 데이터 손실은 견딜 수 없다.
서비스 수준 계약(SLA)은 조직의 가용성 목표 및 요구 사항을 공식화한다.
6. 4. 데이터 가용성
복구 시간 목표(RTO) 또는 예상 수리 시간(ETR)은 가용성과 밀접하게 관련되어 있으며, 계획된 중단 또는 계획되지 않은 중단으로부터 완전히 복구하는 데 필요한 총 시간이다. 또 다른 관련 지표는 평균 복구 시간(MTTR)이다. 특정 시스템 설계 및 장애의 경우, 보조 재해 복구 데이터 센터가 없을 때 데이터 센터와 시스템을 파괴하는 화재나 홍수와 같이 복구 시간이 무한대가 될 수 있다.데이터 가용성은 데이터베이스 및 기타 정보 저장 시스템이 시스템 트랜잭션을 충실하게 기록하고 보고하는 정도를 나타내는 개념이다. 정보 관리는 종종 다양한 장애 이벤트에서 허용 가능한(또는 실제) 데이터 손실을 결정하기 위해 데이터 가용성 또는 복구 시점 목표에 별도로 초점을 맞춘다. 일부 사용자는 애플리케이션 서비스 중단을 견딜 수 있지만 데이터 손실은 견딜 수 없다.
서비스 수준 계약(SLA)은 조직의 가용성 목표 및 요구 사항을 공식화한다.
7. 고가용성 구성 방식
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용될 수 있다. (예: 인기 있는 전자 상거래 웹사이트). 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.[22][23]
만약 중복 부품이 병렬로 사용되고 독립적으로 고장나는 경우(예: 동일한 데이터 센터 내에 있지 않음으로써), 가용성을 기하급수적으로 증가시키고 전체 시스템을 고가용성으로 만들 수 있다. N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우 다음 공식을 사용할 수 있다.
:병렬 구성 요소의 가용성 = 1 - (1 - X)^ N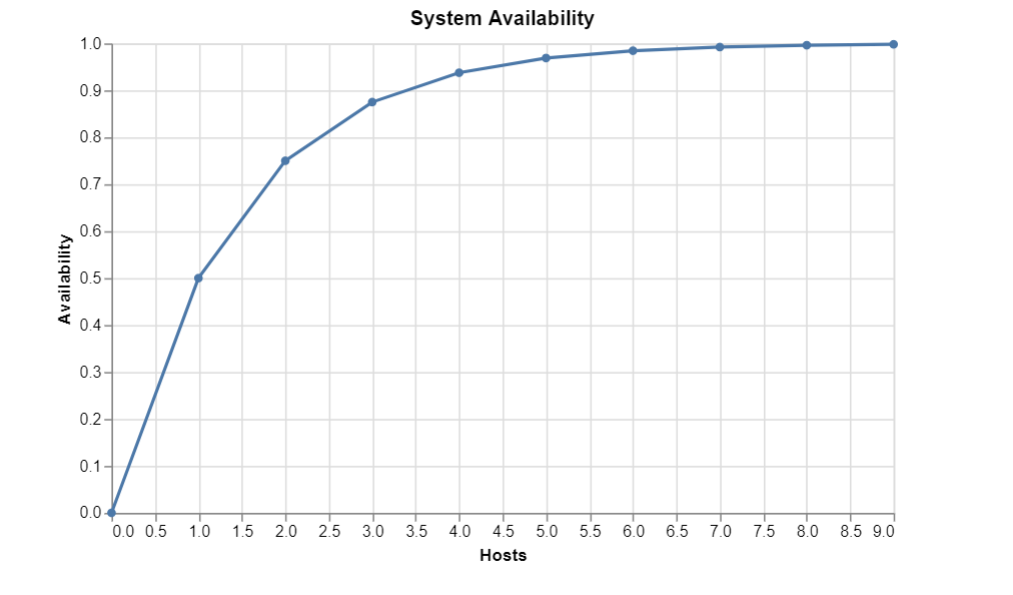
예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
중복성의 두 가지 종류는 수동 중복성과 능동 중복성이다.
수동 중복성은 성능 저하를 수용할 수 있도록 설계에 충분한 초과 용량을 포함시켜 고가용성을 달성하는 데 사용된다. 가장 간단한 예는 두 개의 별도 엔진이 두 개의 별도 프로펠러를 구동하는 보트이다. 보트는 하나의 엔진 또는 프로펠러가 고장나도 목적지를 향해 계속 나아간다. 더 복잡한 예는 전력 전송을 포함하는 대규모 시스템 내의 여러 중복 발전 시설이다. 단일 구성 요소의 오작동은 전체 시스템의 사양 제한을 초과하는 성능 저하가 발생하지 않는 한 고장으로 간주되지 않는다.
능동 중복성은 성능 저하 없이 고가용성을 달성하기 위해 복잡한 시스템에서 사용된다. 동일한 종류의 여러 항목이 고장을 감지하고 투표 방식을 사용하여 고장난 항목을 자동으로 우회하도록 시스템을 재구성하는 방법을 포함하는 설계에 통합된다. 이것은 연결된 복잡한 컴퓨팅 시스템과 함께 사용된다. 인터넷 라우팅은 이 분야에서 Birman과 Joseph의 초기 작업에서 파생되었다.[24] 능동 중복성은 잘못된 투표 로직으로 인한 지속적인 시스템 재구성과 같은 더 복잡한 고장 모드를 시스템에 도입할 수 있다.
무중단 시스템 설계는 모델링 및 시뮬레이션을 통해 평균 고장 간격 시간이 계획된 유지 관리, 업그레이드 이벤트 또는 시스템 수명보다 훨씬 길다는 것을 의미한다. 무중단은 일부 유형의 항공기 및 대부분의 통신 위성에 필요한 대규모 중복성을 포함한다. GPS는 무중단 시스템의 한 예이다.
고장 계측은 제한된 중복성을 가진 시스템에서 고가용성을 달성하는 데 사용할 수 있다. 유지 관리 작업은 고장 표시기가 활성화된 후에만 짧은 기간의 가동 중지 시간 동안 발생한다. 고장은 미션 크리티컬 기간 동안 발생하는 경우에만 중요하다.
모델링 및 시뮬레이션은 대규모 시스템의 이론적 신뢰성을 평가하는 데 사용된다. 이러한 종류의 모델의 결과는 다양한 설계 옵션을 평가하는 데 사용된다. 전체 시스템의 모델이 생성되고 구성 요소를 제거하여 모델에 부하를 준다. 중복 시뮬레이션에는 N-x 기준이 포함된다. N은 시스템의 총 구성 요소 수를 나타낸다. x는 시스템에 부하를 주기 위해 사용되는 구성 요소의 수이다. N-1은 하나의 구성 요소가 고장난 모든 가능한 조합으로 성능을 평가하여 모델에 부하를 가한다는 것을 의미한다. N-2는 두 개의 구성 요소가 동시에 고장난 모든 가능한 조합으로 성능을 평가하여 모델에 부하를 가한다는 것을 의미한다.
==== 콜드 스탠바이 (Cold Standby) 구성 ====
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용될 수 있다. 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.[22][23]
N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우, 병렬 구성 요소의 가용성은 '1 - (1 - X)^ N' 공식을 통해 계산할 수 있다. 예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
콜드 스탠바이(Cold Standby)는 본격적으로 가동 중인 서버와 동일한 구성을 갖춘 예비기를 준비해두고, 장애 발생 시 예비기로 업무를 지속하는 방식이다. 1대만 운용할 때보다 가용성은 높아지지만, 전원을 켜고, 차분 데이터를 가져오는 등의 시스템 엔지니어(SE) 작업이 발생하므로 서비스 제공 중단 시간이 발생한다.
==== 핫 스탠바이 (Hot Standby) 구성 ====
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용된다.[22][23] 예를 들어, 인기 있는 전자 상거래 웹사이트와 같은 경우가 이에 해당한다. 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.
만약 중복 부품이 병렬로 사용되고 독립적으로 고장나는 경우 (예: 동일한 데이터 센터 내에 있지 않음으로써), 가용성을 기하급수적으로 증가시키고 전체 시스템을 고가용성으로 만들 수 있다. N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우 다음 공식을 사용할 수 있다:[22][23]
:병렬 구성 요소의 가용성 = 1 - (1 - X)^ N
예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
중복성의 두 가지 종류는 수동 중복성과 능동 중복성이다.
수동 중복성은 성능 저하를 수용할 수 있도록 설계에 충분한 초과 용량을 포함시켜 고가용성을 달성하는 데 사용된다. 가장 간단한 예는 두 개의 별도 엔진이 두 개의 별도 프로펠러를 구동하는 보트이다. 보트는 하나의 엔진 또는 프로펠러가 고장나도 목적지를 향해 계속 나아간다. 더 복잡한 예는 전력 전송을 포함하는 대규모 시스템 내의 여러 중복 발전 시설이다.
능동 중복성은 성능 저하 없이 고가용성을 달성하기 위해 복잡한 시스템에서 사용된다. 동일한 종류의 여러 항목이 고장을 감지하고 투표 방식을 사용하여 고장난 항목을 자동으로 우회하도록 시스템을 재구성하는 방법을 포함하는 설계에 통합된다. 인터넷 라우팅은 이 분야에서 Birman과 Joseph의 초기 작업에서 파생되었다.[24]
유사한 구성을 가진 서버를 2대 이상 준비하여 1대가 사용 불가능하게 되었을 경우 자동으로 시스템 전환을 실시하여 서비스 제공을 지속하는 구성이 핫 스탠바이 구성이다. 콜드 스탠바이 구성보다 서비스 제공 불가 시간대가 짧기 때문에 가용성은 더욱 높아지지만, 대기 서버에 대한 운영·유지보수도 필요하게 되어 운영 비용은 2배 이상이 되며, 정상 시스템이 정지했을 경우의 전환 검증 등도 발생하기 때문에 설계 또한 복잡해진다.
==== 부하 분산 (Load Balancing) 구성 ====
복잡한 시스템은 더 많은 오류 지점을 가질 수 있고 구현이 어렵기 때문에, 고가용성 달성이 어려울 수 있다.[21] 하지만, 고급 시스템 설계에서는 로드 밸런싱 및 장애 조치를 통해 서비스 중단 없이 시스템을 패치하고 업그레이드할 수 있다.[21] 고가용성은 복잡한 시스템에서 작동 복구를 위한 인적 개입을 줄여주는데, 이는 인적 오류가 중단의 가장 흔한 원인이기 때문이다.[21]
중복성은 고가용성 시스템을 구축하는 데 사용될 수 있다.[22][23] 예를 들어, 각 구성 요소의 가용성이 50%일 때, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 얻을 수 있다.[22][23]
중복성에는 수동적 중복성과 능동적 중복성이 있다. 수동적 중복성은 성능 저하를 수용할 수 있는 충분한 초과 용량을 포함시켜 고가용성을 달성한다. 능동적 중복성은 복잡한 시스템에서 성능 저하 없이 고가용성을 달성하기 위해 사용되며, 고장 감지 및 자동 우회 기능을 포함한다. 인터넷 라우팅은 이러한 능동적 중복성의 초기 연구에서 파생되었다.[24]
항상 동일한 기능을 제공하는 둘 이상의 서버를 가동하고 트래픽 분산 및 부하 경감 등을 실시하여 장애 발생 시 정상 서버만으로 축퇴 운용을 하여 서비스 중단을 최소화 할 수 있다. 이중 장애를 고려하더라도 서버 수를 늘릴수록 신뢰도는 높아진다. 데이터베이스 서버와 같이 데이터 쓰기가 발생하는 시스템에서는 여러 서버에 동시에 기록했을 때 불일치가 발생할 수 있으므로, 읽기는 여러 서버에서, 쓰기는 하나의 마스터 서버로 하는 등의 구성이 필요할 수 있다.
==== 재해 복구 (Disaster Recovery) 구성 ====
본격적인 운영을 수행하는 서버군과는 별개의 지역에 데이터 센터를 배치하여, 천재지변 등으로 본 운영 데이터 센터에서의 운영이 지속 불가능하게 된 경우에도 서비스를 제공할 수 있도록 하는 방식이다.
7. 1. 콜드 스탠바이 (Cold Standby) 구성
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용될 수 있다. 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.[22][23]N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우, 병렬 구성 요소의 가용성은 '1 - (1 - X)^ N' 공식을 통해 계산할 수 있다. 예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
콜드 스탠바이(Cold Standby)는 본격적으로 가동 중인 서버와 동일한 구성을 갖춘 예비기를 준비해두고, 장애 발생 시 예비기로 업무를 지속하는 방식이다. 1대만 운용할 때보다 가용성은 높아지지만, 전원을 켜고, 차분 데이터를 가져오는 등의 시스템 엔지니어(SE) 작업이 발생하므로 서비스 제공 중단 시간이 발생한다.
7. 2. 핫 스탠바이 (Hot Standby) 구성
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용된다.[22][23] 예를 들어, 인기 있는 전자 상거래 웹사이트와 같은 경우가 이에 해당한다. 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.만약 중복 부품이 병렬로 사용되고 독립적으로 고장나는 경우 (예: 동일한 데이터 센터 내에 있지 않음으로써), 가용성을 기하급수적으로 증가시키고 전체 시스템을 고가용성으로 만들 수 있다. N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우 다음 공식을 사용할 수 있다:[22][23]
:병렬 구성 요소의 가용성 = 1 - (1 - X)^ N
예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
중복성의 두 가지 종류는 수동 중복성과 능동 중복성이다.
수동 중복성은 성능 저하를 수용할 수 있도록 설계에 충분한 초과 용량을 포함시켜 고가용성을 달성하는 데 사용된다. 가장 간단한 예는 두 개의 별도 엔진이 두 개의 별도 프로펠러를 구동하는 보트이다. 보트는 하나의 엔진 또는 프로펠러가 고장나도 목적지를 향해 계속 나아간다. 더 복잡한 예는 전력 전송을 포함하는 대규모 시스템 내의 여러 중복 발전 시설이다.
능동 중복성은 성능 저하 없이 고가용성을 달성하기 위해 복잡한 시스템에서 사용된다. 동일한 종류의 여러 항목이 고장을 감지하고 투표 방식을 사용하여 고장난 항목을 자동으로 우회하도록 시스템을 재구성하는 방법을 포함하는 설계에 통합된다. 인터넷 라우팅은 이 분야에서 Birman과 Joseph의 초기 작업에서 파생되었다.[24]
유사한 구성을 가진 서버를 2대 이상 준비하여 1대가 사용 불가능하게 되었을 경우 자동으로 시스템 전환을 실시하여 서비스 제공을 지속하는 구성이 핫 스탠바이 구성이다. 콜드 스탠바이 구성보다 서비스 제공 불가 시간대가 짧기 때문에 가용성은 더욱 높아지지만, 대기 서버에 대한 운영·유지보수도 필요하게 되어 운영 비용은 2배 이상이 되며, 정상 시스템이 정지했을 경우의 전환 검증 등도 발생하기 때문에 설계 또한 복잡해진다.
7. 3. 부하 분산 (Load Balancing) 구성
복잡한 시스템은 더 많은 오류 지점을 가질 수 있고 구현이 어렵기 때문에, 고가용성 달성이 어려울 수 있다.[21] 하지만, 고급 시스템 설계에서는 로드 밸런싱 및 장애 조치를 통해 서비스 중단 없이 시스템을 패치하고 업그레이드할 수 있다.[21] 고가용성은 복잡한 시스템에서 작동 복구를 위한 인적 개입을 줄여주는데, 이는 인적 오류가 중단의 가장 흔한 원인이기 때문이다.[21]중복성은 고가용성 시스템을 구축하는 데 사용될 수 있다.[22][23] 예를 들어, 각 구성 요소의 가용성이 50%일 때, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 얻을 수 있다.[22][23]
중복성에는 수동적 중복성과 능동적 중복성이 있다. 수동적 중복성은 성능 저하를 수용할 수 있는 충분한 초과 용량을 포함시켜 고가용성을 달성한다. 능동적 중복성은 복잡한 시스템에서 성능 저하 없이 고가용성을 달성하기 위해 사용되며, 고장 감지 및 자동 우회 기능을 포함한다. 인터넷 라우팅은 이러한 능동적 중복성의 초기 연구에서 파생되었다.[24]
항상 동일한 기능을 제공하는 둘 이상의 서버를 가동하고 트래픽 분산 및 부하 경감 등을 실시하여 장애 발생 시 정상 서버만으로 축퇴 운용을 하여 서비스 중단을 최소화 할 수 있다. 이중 장애를 고려하더라도 서버 수를 늘릴수록 신뢰도는 높아진다. 데이터베이스 서버와 같이 데이터 쓰기가 발생하는 시스템에서는 여러 서버에 동시에 기록했을 때 불일치가 발생할 수 있으므로, 읽기는 여러 서버에서, 쓰기는 하나의 마스터 서버로 하는 등의 구성이 필요할 수 있다.
7. 4. 재해 복구 (Disaster Recovery) 구성
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용될수 있다. (예: 인기 있는 전자 상거래 웹사이트). 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.[22][23]만약 중복 부품이 병렬로 사용되고 독립적으로 고장나는 경우(예: 동일한 데이터 센터 내에 있지 않음으로써), 가용성을 기하급수적으로 증가시키고 전체 시스템을 고가용성으로 만들 수 있다. N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우 다음 공식을 사용할 수 있다.
병렬 구성 요소의 가용성 = 1 - (1 - X)^ N
예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
중복성의 두 가지 종류는 수동 중복성과 능동 중복성이다.
수동 중복성은 성능 저하를 수용할 수 있도록 설계에 충분한 초과 용량을 포함시켜 고가용성을 달성하는 데 사용된다. 가장 간단한 예는 두 개의 별도 엔진이 두 개의 별도 프로펠러를 구동하는 보트이다. 보트는 하나의 엔진 또는 프로펠러가 고장나도 목적지를 향해 계속 나아갑니다. 더 복잡한 예는 전력 전송을 포함하는 대규모 시스템 내의 여러 중복 발전 시설이다. 단일 구성 요소의 오작동은 전체 시스템의 사양 제한을 초과하는 성능 저하가 발생하지 않는 한 고장으로 간주되지 않는다.
능동 중복성은 성능 저하 없이 고가용성을 달성하기 위해 복잡한 시스템에서 사용된다. 동일한 종류의 여러 항목이 고장을 감지하고 투표 방식을 사용하여 고장난 항목을 자동으로 우회하도록 시스템을 재구성하는 방법을 포함하는 설계에 통합된다. 이것은 연결된 복잡한 컴퓨팅 시스템과 함께 사용된다. 인터넷 라우팅은 이 분야에서 Birman과 Joseph의 초기 작업에서 파생되었다.[24] 능동 중복성은 잘못된 투표 로직으로 인한 지속적인 시스템 재구성과 같은 더 복잡한 고장 모드를 시스템에 도입할 수 있다.
무중단 시스템 설계는 모델링 및 시뮬레이션을 통해 평균 고장 간격 시간이 계획된 유지 관리, 업그레이드 이벤트 또는 시스템 수명보다 훨씬 길다는 것을 의미한다. 무중단은 일부 유형의 항공기 및 대부분의 통신 위성에 필요한 대규모 중복성을 포함한다. GPS는 무중단 시스템의 한 예이다.
고장 계측은 제한된 중복성을 가진 시스템에서 고가용성을 달성하는 데 사용할 수 있다. 유지 관리 작업은 고장 표시기가 활성화된 후에만 짧은 기간의 가동 중지 시간 동안 발생한다. 고장은 미션 크리티컬 기간 동안 발생하는 경우에만 중요하다.
모델링 및 시뮬레이션은 대규모 시스템의 이론적 신뢰성을 평가하는 데 사용된다. 이러한 종류의 모델의 결과는 다양한 설계 옵션을 평가하는 데 사용된다. 전체 시스템의 모델이 생성되고 구성 요소를 제거하여 모델에 부하를 준다. 중복 시뮬레이션에는 N-x 기준이 포함된다. N은 시스템의 총 구성 요소 수를 나타낸다. x는 시스템에 부하를 주기 위해 사용되는 구성 요소의 수이다. N-1은 하나의 구성 요소가 고장난 모든 가능한 조합으로 성능을 평가하여 모델에 부하를 가한다는 것을 의미한다. N-2는 두 개의 구성 요소가 동시에 고장난 모든 가능한 조합으로 성능을 평가하여 모델에 부하를 가한다는 것을 의미한다.
본격적인 운영을 수행하는 서버군과는 별개의 지역에 데이터 센터를 배치하여, 천재지변 등으로 본 운영 데이터 센터에서의 운영이 지속 불가능하게 된 경우에도 서비스를 제공할 수 있도록 하는 방식이다.
8. 가용성 저해 요인
2010년 학계의 가용성 전문가들을 대상으로 한 설문 조사에서 기업 IT 시스템의 가용성 저하 요인들이 순위가 매겨졌다. 모든 요인은 각 분야에서 '''최적의 관행을 따르지 않음'''을 의미한다(중요도 순).[25]
# 관련 구성 요소의 모니터링
# 요구 사항 및 조달
# 운영
# 네트워크 장애 회피
# 내부 애플리케이션 장애 회피
# 실패하는 외부 서비스 회피
# 물리적 환경
# 네트워크 중복성
# 백업의 기술적 솔루션
# 백업의 프로세스 솔루션
# 물리적 위치
# 인프라 중복성
# 스토리지 아키텍처 중복성
요인 자체에 관한 책이 2003년에 출판되었다.[26]
9. 군사 제어 시스템
고가용성은 무인 차량 및 자율 해상 선박의 제어 시스템에 대한 주요 요구 사항 중 하나이다. 제어 시스템을 사용할 수 없게 되면 지상 전투 차량(GCV) 또는 대잠 지속 추적 무인 선박(ACTUV)을 잃게 된다.
10. 시스템 설계
복잡한 시스템은 본질적으로 더 많은 잠재적 오류 지점을 가지며 올바르게 구현하기가 더 어렵기 때문에, 전체 시스템 설계에 더 많은 구성 요소를 추가하는 것은 고가용성 달성을 위한 노력을 약화시킬 수 있다. 일부 분석가들은 가장 높은 가용성을 가진 시스템이 단순한 아키텍처(포괄적인 내부 하드웨어 중복성을 갖춘 단일의 고품질, 다목적 물리 시스템)를 따른다는 이론을 제시하지만, 이 아키텍처는 패치 및 운영 체제 업그레이드를 위해 전체 시스템을 중단해야 한다는 요구 사항의 영향을 받는다.[21] 보다 진보된 시스템 설계는 서비스 가용성을 저해하지 않으면서 시스템을 패치하고 업그레이드할 수 있도록 한다( 로드 밸런싱 및 장애 조치 참조). 고가용성은 복잡한 시스템에서 작동을 복원하기 위해 인간의 개입을 덜 필요로 하는데, 그 이유는 중단의 가장 흔한 원인이 인적 오류이기 때문이다.[21]
==== 중복성을 통한 고가용성 확보 ====
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용될 수 있다. 예를 들어 인기 있는 전자 상거래 웹사이트와 같은 경우가 이에 해당한다. 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.[22][23]
만약 중복 부품이 병렬로 사용되고 독립적으로 고장나는 경우(예: 동일한 데이터 센터 내에 있지 않음으로써), 가용성을 기하급수적으로 증가시키고 전체 시스템을 고가용성으로 만들 수 있다. N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우 다음 공식을 사용할 수 있다.[22][23]
: 병렬 구성 요소의 가용성 = 1 - (1 - X)^ N
예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
중복성의 두 가지 종류는 수동 중복성과 능동 중복성이다. 수동 중복성은 성능 저하를 수용할 수 있도록 설계에 충분한 초과 용량을 포함시켜 고가용성을 달성하는 데 사용된다. 가장 간단한 예는 두 개의 별도 엔진이 두 개의 별도 프로펠러를 구동하는 보트이다. 보트는 하나의 엔진 또는 프로펠러가 고장나도 목적지를 향해 계속 나아간다. 더 복잡한 예는 전력 전송을 포함하는 대규모 시스템 내의 여러 중복 발전 시설이다.
능동 중복성은 성능 저하 없이 고가용성을 달성하기 위해 복잡한 시스템에서 사용된다. 동일한 종류의 여러 항목이 고장을 감지하고 투표 방식을 사용하여 고장난 항목을 자동으로 우회하도록 시스템을 재구성하는 방법을 포함하는 설계에 통합된다. 인터넷 라우팅은 이 분야에서 Birman과 Joseph의 초기 작업에서 파생되었다.[24]
무중단 시스템 설계는 모델링 및 시뮬레이션을 통해 평균 고장 간격 시간이 계획된 유지 관리, 업그레이드 이벤트 또는 시스템 수명보다 훨씬 길다는 것을 의미한다. GPS는 무중단 시스템의 한 예이다.
고장 계측은 제한된 중복성을 가진 시스템에서 고가용성을 달성하는 데 사용할 수 있다. 유지 관리 작업은 고장 표시기가 활성화된 후에만 짧은 기간의 가동 중지 시간 동안 발생한다.
모델링 및 시뮬레이션은 대규모 시스템의 이론적 신뢰성을 평가하는 데 사용된다. 이러한 종류의 모델의 결과는 다양한 설계 옵션을 평가하는 데 사용된다. 중복 시뮬레이션에는 N-x 기준이 포함된다. N은 시스템의 총 구성 요소 수를 나타내고 x는 시스템에 부하를 주기 위해 사용되는 구성 요소의 수이다.
10. 1. 중복성을 통한 고가용성 확보
중복성은 높은 수준의 가용성을 가진 시스템을 만드는 데 사용될 수 있다. 예를 들어 인기 있는 전자 상거래 웹사이트와 같은 경우가 이에 해당한다. 이 경우 높은 수준의 고장 감지 능력과 공통 원인 고장 회피가 필요하다.[22][23]만약 중복 부품이 병렬로 사용되고 독립적으로 고장나는 경우(예: 동일한 데이터 센터 내에 있지 않음으로써), 가용성을 기하급수적으로 증가시키고 전체 시스템을 고가용성으로 만들 수 있다. N개의 병렬 구성 요소가 각각 X의 가용성을 갖는 경우 다음 공식을 사용할 수 있다.[22][23]
: 병렬 구성 요소의 가용성 = 1 - (1 - X)^ N
예를 들어, 각 구성 요소가 50%의 가용성만 갖는 경우, 10개의 구성 요소를 병렬로 사용하면 99.9023%의 가용성을 달성할 수 있다.
중복성의 두 가지 종류는 수동 중복성과 능동 중복성이다. 수동 중복성은 성능 저하를 수용할 수 있도록 설계에 충분한 초과 용량을 포함시켜 고가용성을 달성하는 데 사용된다. 가장 간단한 예는 두 개의 별도 엔진이 두 개의 별도 프로펠러를 구동하는 보트이다. 보트는 하나의 엔진 또는 프로펠러가 고장나도 목적지를 향해 계속 나아간다. 더 복잡한 예는 전력 전송을 포함하는 대규모 시스템 내의 여러 중복 발전 시설이다.
능동 중복성은 성능 저하 없이 고가용성을 달성하기 위해 복잡한 시스템에서 사용된다. 동일한 종류의 여러 항목이 고장을 감지하고 투표 방식을 사용하여 고장난 항목을 자동으로 우회하도록 시스템을 재구성하는 방법을 포함하는 설계에 통합된다. 인터넷 라우팅은 이 분야에서 Birman과 Joseph의 초기 작업에서 파생되었다.[24]
무중단 시스템 설계는 모델링 및 시뮬레이션을 통해 평균 고장 간격 시간이 계획된 유지 관리, 업그레이드 이벤트 또는 시스템 수명보다 훨씬 길다는 것을 의미한다. GPS는 무중단 시스템의 한 예이다.
고장 계측은 제한된 중복성을 가진 시스템에서 고가용성을 달성하는 데 사용할 수 있다. 유지 관리 작업은 고장 표시기가 활성화된 후에만 짧은 기간의 가동 중지 시간 동안 발생한다.
모델링 및 시뮬레이션은 대규모 시스템의 이론적 신뢰성을 평가하는 데 사용된다. 이러한 종류의 모델의 결과는 다양한 설계 옵션을 평가하는 데 사용된다. 중복 시뮬레이션에는 N-x 기준이 포함된다. N은 시스템의 총 구성 요소 수를 나타내고 x는 시스템에 부하를 주기 위해 사용되는 구성 요소의 수이다.
참조
[1]
웹사이트
high availability (HA)
https://www.techtarg[...]
2024-04-01
[2]
서적
High Availability: Design, Techniques, and Processes
https://books.google[...]
Prentice Hall
[3]
웹사이트
Definitions - ResiliNetsWiki
https://resilinets.o[...]
[4]
웹사이트
Webarchiv ETHZ / Webarchive ETH
https://webarchiv.et[...]
[5]
간행물
Network resilience: a systematic approach
https://ieeexplore.i[...]
2011-07-03
[6]
웹사이트
operational resilience {{!}} telcos {{!}} accesstel {{!}} risk {{!}} crisis
https://accesstel.co[...]
2023-05-08
[7]
웹사이트
The CERCES project - Center for Resilient Critical Infrastructures at KTH Royal Institute of Technology.
https://www.kth.se/a[...]
2023-08-26
[8]
간행물
A Benders Decomposition Approach for Resilient Placement of Virtual Process Control Functions in Mobile Edge Clouds
https://ieeexplore.i[...]
2018-12-03
[9]
보고서
Castet J., Saleh J. Survivability and Resiliency of Spacecraft and Space-Based Networks: a Framework for Characterization and Analysis
https://smartech.gat[...]
American Institute of Aeronautics and Astronautics, AIAA Technical Report 2008-7707. Conference on Network Protocols (ICNP 2006)
2006-11-01
[10]
문서
Lecture Notes
http://www.cs.kent.e[...]
M. Nesterenko, Kent State University
[11]
문서
Introduction to the new mainframe: Large scale commercial computing Chapter 5 Availability
http://comet.lehman.[...]
2006-01-01
[12]
Youtube
IBM zEnterprise EC12 Business Value Video
https://www.youtube.[...]
[13]
서적
Precious metals, Volume 4
Pergamon Press
[14]
서적
PVD for Microelectronics: Sputter Desposition to Semiconductor Manufacturing
[15]
서적
Site Reliability Engineering: How Google Runs Production Systems
[16]
웹사이트
Nines of Nines
http://www.joshdepre[...]
2016-05-31
[17]
문서
The myth of the nines
http://searchstorage[...]
[18]
간행물
Crying Wolf: False alarms hide attacks
https://books.google[...]
2019-03-15
[19]
웹사이트
After 35 years of technology crusades, Bob Metcalfe rides off into the sunset
https://www.itworld.[...]
2019-03-15
[20]
웹사이트
Goodbye Five 9s
https://www.seeclear[...]
Clearfield, Inc.
2019-03-15
[21]
웹사이트
What is network downtime?
https://www.techtarg[...]
2023-12-27
[22]
서적
Reliability and Availability Engineering: Modeling, Analysis, and Applications
Cambridge University Press
[23]
서적
System Sustainment: Acquisition And Engineering Processes For The Sustainment Of Critical And Legacy Systems (World Scientific Series On Emerging Technologies: Avram Bar-cohen Memorial Series)
World Scientific
[24]
IETF RFC
"992"
[25]
문서
Availability of enterprise IT systems – an expert-based Bayesian model
http://www.kth.se/ee[...]
Proc. Fourth International Workshop on Software Quality and Maintainability (WSQM 2010), Madrid
[26]
서적
Blueprints for high availability
John Wiley & Sons
[27]
문서
Improving systems availability
http://www.dis.uniro[...]
IBM Global Services
[28]
문서
HACMP는 High Availability Clustering Multiprocessing의 약자로서 고가용성 솔루션이라는 뜻이다.
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com