관계형 모델
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
관계형 모델은 1970년 에드거 F. 코드가 제안한 데이터 모델로, 데이터를 2차원 테이블 형태의 관계(relation)로 표현한다. 관계형 모델은 튜플(행)과 속성(열)으로 구성되며, 관계 대수 또는 관계 논리를 사용하여 데이터 연산을 수행한다. 데이터베이스 설계 시 데이터 중복을 최소화하고 데이터 무결성을 유지하기 위해 정규화를 수행한다. 관계형 모델은 술어 논리를 기반으로 하며, SQL과 같은 데이터베이스 언어의 기반이 된다. SQL은 관계형 모델과 용어 및 기능에서 차이를 보이며, 다른 데이터 모델과의 비교를 통해 관계형 모델의 장단점을 파악할 수 있다. 데이터의 유연성 부족과 NULL 개념의 문제점 등 비판도 존재하지만, 여전히 널리 사용되고 있다.
더 읽어볼만한 페이지
- 1969년 컴퓨팅 - 커리-하워드 대응
커리-하워드 대응은 증명 시스템과 계산 모델 간의 동형성을 나타내며, 증명은 프로그램이고 증명하는 공식은 프로그램의 타입이라는 일반화를 통해 논리 프로그래밍의 기초가 되어 현대 타입 이론 연구에 큰 영향을 미쳤다. - 1969년 컴퓨팅 - 호어 논리
호어 논리는 프로그램의 실행 전후 조건을 명시하고 코드 조각이 조건을 어떻게 변화시키는지 추론하는 규칙을 제공하여 프로그램의 정확성을 형식적으로 검증하는 논리 시스템이다. - 관계형 모델 - 관계 논리
관계 논리는 관계 모델 기반 데이터베이스 언어로서 관계 대수와 논리적으로 동일하며, 튜플 관계 논리와 도메인 관계 논리로 나뉘어 쿼리 최적화에 사용된다. - 관계형 모델 - 관계형 데이터베이스
관계형 데이터베이스는 데이터를 테이블 형태로 구성하여 관리하며, 1970년 E.F. 코드에 의해 정의되었고, RDBMS를 통해 ACID 트랜잭션, 저장 프로시저, 정규화, 인덱스 등의 기술을 활용하여 다양한 분야에서 사용된다. - 데이터베이스 모델 - 플랫 파일 데이터베이스
플랫 파일 데이터베이스는 각 줄에 레코드를 기록하고 구분자로 필드를 구분하는 단순한 형태이지만, 데이터 중복, 대용량 처리의 어려움, 보안 취약성 등의 한계로 특정 용도로만 활용된다. - 데이터베이스 모델 - 네트워크 모델
네트워크 모델은 찰스 바크만이 발명하고 CODASYL 컨소시엄에 의해 표준 사양으로 개발된 데이터베이스 모델이며, 바흐만 다이어그램으로 표현되고 IDS, IDMS, IMAGE 등 다양한 시스템에서 구현되었다.
| 관계형 모델 | |
|---|---|
| 관계형 모델 | |
| 기본 정보 | |
| 종류 | 데이터베이스 모델 |
| 고안자 | 에드거 F. 커드 |
| 고안 시기 | 1969년 |
| 발표 시기 | 1970년 |
| 특징 | |
| 핵심 개념 | 관계, 튜플, 속성 |
| 데이터 표현 | 테이블 (관계) |
| 데이터 조작 | 관계 대수, 관계 해석 |
| 제약 조건 | 개체 무결성 제약 조건, 참조 무결성 제약 조건 |
| 장단점 | |
| 장점 | 단순하고 이해하기 쉬운 구조 데이터의 독립성 보장 다양한 질의어 지원 데이터의 무결성 유지 |
| 단점 | 성능 문제 (조인 연산) 객체 지향 데이터베이스와의 통합 어려움 복잡한 데이터 모델링의 어려움 |
| 관련 기술 | |
| 질의어 | SQL |
| 데이터베이스 관리 시스템 | MySQL, PostgreSQL, Oracle Database, SQL Server |
| 정규화 | 데이터베이스 정규화 |
| 기타 | |
| 영향 | 현재 대부분의 데이터베이스 시스템의 기반이 됨 |
2. 역사
에드거 F. 코드는 1970년 집합론에 기반한 관계형 모델을 고안했다. 19세기 독일 수학자 게오르크 칸토어는 집합론을 고안했고, 1968년 미국 수학자 D. L. 차일즈는 데이터와 데이터 검색을 집합과 집합 연산으로 표현하는 집합론적 데이터 구조를 고안하여 물리적 데이터 구조로부터의 독립성을 실현하는 선구적인 업적을 이루었다.
관계형 모델은 이후 크리스 데이트와 휴 다윈 등에 의해 널리 알려졌다. 데이트와 다윈은 1995년 저서 《제3 선언》에서 관계형 모델이 특정 "원하는" 객체 지향 기능을 어떻게 수용할 수 있는지 설명했다.[4]
2. 1. 관계형 모델의 등장
에드거 F. 코드는 1970년 논문 ''"[http://www.acm.org/classics/nov95/toc.html A Relational Model of Data for Large Shared Data Banks"]''에서 관계형 모델을 데이터의 일반 모델로 처음 제안했다.[4] 이 논문에서는 D. L. 차일즈가 1968년에 발표한 집합론적 데이터 구조에 대한 논문도 인용되었다.관계형 모델은 이후 크리스 데이트와 휴 다윈 등에 의해 널리 알려지고 발전되었다. 이들은 1995년 저서 《제3 선언》에서 관계형 모델이 그 기본 원리를 훼손하지 않고 바람직한 형태로 객체 지향 기능에 대응하는 기법을 제시했다.[4]
2. 2. 확장 및 발전
에드거 F. 코드가 관계형 모델을 개발한 후, 크리스 데이트와 휴 다윈 등이 이를 널리 알렸다. 데이트와 다윈은 1995년 저서 《The Third Manifesto》(제3 선언)에서 관계형 모델이 특정 "원하는" 객체 지향 기능을 어떻게 수용할 수 있는지 설명했다.[4]1970년 모델 발표 후, 코드는 누락된 정보를 처리하기 위해 3값 논리 (참, 거짓, 누락/NULL) 버전을 제안했고, 1990년 저서 ''데이터베이스 관리를 위한 관계형 모델 버전 2''에서 4값 논리(참, 거짓, 누락되었지만 적용 가능, 누락되었지만 적용 불가능) 버전으로 확장했다.[5]
3. 개념
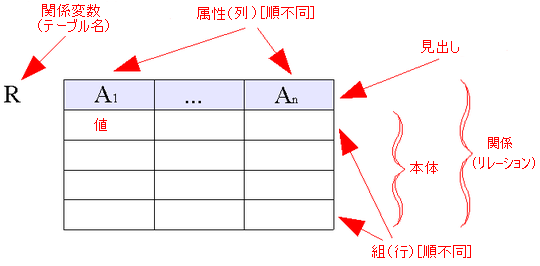
관계형 모델의 기본 요소는 '''정의역'''(도메인)이다. 정의역은 '''데이터 형식'''과 같은 의미로, 현재는 '''형'''(타입)으로 줄여 부르기도 한다.
'''속성'''은 속성명과 타입명(정의역명)의 쌍으로 구성된다. 속성의 이름과 값의 정렬되지 않은 집합을 '''튜플'''이라 한다. 속성 값은 속성의 정의역에 적합한 구체적인 값으로, 스칼라 값 또는 더 복잡한 구조를 갖는 값이다.
'''관계'''는 '''머리글'''과 '''본문'''으로 구성된다. 머리글은 정렬되지 않은 속성의 집합이며, 본문은 정렬되지 않은 튜플의 집합이다. ''n''항 관계의 본문은 ''n''튜플의 집합으로 구성된다. 어떤 관계의 머리글은 그 관계에 포함된 튜플의 머리글이기도 하다.
관계는 ''n''튜플의 집합으로 정의된다. 수학과 관계형 모델 모두에서 집합은 정렬되지 않은 요소들의 모임이다. 이러한 정의를 따르지 않는 시스템은 관계형 모델에 준거하지 않는다고 비판받기도 한다. 수학에서는 튜플 내 요소 간 순서가 존재하고 중복이 허용되지만, 에드거 F. 코드는 처음에 수학적 정의로 튜플을 정의했다가[12] 나중에 개념을 변경했다. 튜플 개념 변경으로 관계 대수의 데카르트 곱 연산에서 교환 법칙이 성립하게 되었다.
현재 표(테이블)는 관계의 시각적 표현으로 널리 사용되며, 튜플은 표의 행과 유사하다. 데이터베이스 언어 SQL에서 표의 열(컬럼)은 정렬되어 있어, SQL이 관계형 모델에 준거하지 않는다는 비판의 근거가 되기도 한다.
'''관계 변수'''(relvar)는 특정 관계형의 이름 있는 변수다. 관계 변수에는 해당 형식에 대응하는 관계(관계 값)가 할당되며, 튜플 수는 0일 수도 있다.
관계형 모델의 기본 원리는 정보의 원리다. 모든 정보는 관계에 포함된 데이터로 표현된다. 따라서 관계형 데이터베이스는 관계 변수의 집합이며, 모든 검색 결과는 관계로 표현된다.
관계형 데이터베이스에는 정합성이 강제 적용된다. 논리 스키마의 일부로 정합성 제약이 선언되며, RDBMS에 의해 모든 애플리케이션 소프트웨어에 강제 적용된다. 따라서 애플리케이션 소프트웨어에 정합성 규칙을 구현할 필요가 없다. 제약은 관계 비교 연산자로 표현되며, 이론적으로 "—는—의 부분 집합이다"(⊆) 연산자만으로 충분하지만, 실제로는 후보 키(슈퍼 키), 외래 키 등 단축 표기가 사용된다.
관계형 데이터베이스의 전형적인 '''정의역'''은 정수, 문자열, 논리형 등이며, "int", "char", "boolean" 등의 이름이 규정된다.
'''속성'''은 관계의 데이터 구조 일부로 선언되며, 속성명과 정의역 이름을 지정한다. SQL을 사용하는 데이터베이스에서 '''튜플'''은 행과 유사하다.
'''속성명'''의 예로는 "name", "age" 등이 있다. '''속성값'''은 특정 튜플의 특정 속성에 포함되는 구체적인 값(엔트리)으로, "John Doe", "35" 등이다.
'''관계'''는 테이블과 유사한 데이터 구조 사양 및 데이터(본체)를 포함한다. '''머리글'''은 관계의 데이터 구조 선언이며, '''본체'''는 데이터 구조에 포함되는 데이터다.
19세기 독일 수학자 게오르크 칸토어는 집합론을 고안했다.
미국 수학자 D. L. 차일즈는 1968년 논문 ''"Description of a Set-Theoretic Data Structure"''에서 데이터와 데이터 검색을 집합과 집합 연산으로 표현하는 집합론적 데이터 구조를 고안했다. 이는 물리적 데이터 구조로부터 독립성을 실현한 선구적 업적이었다.
에드거 F. 코드는 1970년 논문 ''[http://www.acm.org/classics/nov95/toc.html "A Relational Model of Data for Large Shared Data Banks"]''에서 관계형 모델을 데이터의 일반 모델로 고안하며 차일즈의 논문을 인용했다.
이후 관계형 모델은 많은 사람들에 의해 수정, 개량되었다. 크리스 데이트와 휴 다윈은 ''The Third Manifesto''(1995년 초판)에서 관계형 모델이 기본 원리를 훼손하지 않고 객체 지향 기능에 대응하는 기법을 제시했다.
3. 1. 기본 개념

'''관계'''는 '''머리'''와 '''몸통'''으로 구성된다. 머리는 '''속성'''의 집합을 정의하며, 각 속성은 '''이름'''과 '''데이터 유형'''(때로는 '''도메인'''이라고 함)을 갖는다. 이 집합에 있는 속성의 수는 관계의 '''차수''' 또는 '''아리티'''이다. 몸통은 '''튜플'''의 집합이다. 튜플은 ''n''개의 '''값'''의 모음이며, 여기서 ''n''은 관계의 차수이고, 튜플의 각 값은 고유한 속성에 해당한다.[6] 이 집합에 있는 튜플의 수는 관계의 '''기수'''이다.[8]
관계는 재할당될 수 있는 '''관계형 변수'''(릴변수)로 표현된다.[8] '''데이터베이스'''는 릴변수의 모음이다.[8]
이 모델에서 데이터베이스는 '''정보 원칙'''을 따른다. 즉, 주어진 시점에서 데이터베이스의 모든 정보는 릴변수로 식별되는 관계의 속성에 해당하는 튜플 내의 값으로만 표현된다.[8]
관계변수(관계)와 그 속성에 대한 묘사의 이상적이고 매우 단순한 예시는 다음과 같다.
- 고객 ('''고객 ID''', 이름)
- 주문 ('''주문 ID''', 고객 ID, 송장 ID, 날짜)
- 송장 ('''송장 ID''', 고객 ID, 주문 ID, 상태)
이 설계에는 고객, 주문, 송장의 세 가지 관계변수가 있다. 굵고 밑줄이 그어진 속성은 후보 키이다. 굵지 않고 밑줄이 그어진 속성은 외래 키이다.
일반적으로 하나의 후보 키가 기본 키로 선택되어 다른 후보 키보다 선호되어 사용되며, 이 경우 다른 후보 키는 대체 키라고 한다.
후보 키는 튜플이 중복되지 않도록 하는 고유한 식별자이다. 후보키는 관계가 백이 되는것을 막고, 집합의 기본 정의를 준수하도록 한다. 외래 키와 수퍼키(후보 키 포함)는 복합 키가 될 수 있으며, 여러 속성으로 구성될 수 있다. 아래는 예시인 고객 관계변수의 관계를 표로 나타낸 것이다. 관계는 관계변수에 할당될 수 있는 값이라고 생각할 수 있다.
| 고객 ID | 이름 |
|---|---|
| 123 | 앨리스 |
| 456 | 밥 |
| 789 | 캐롤 |
만약 ID가 ''123''인 새로운 고객을 ''삽입''하려고 시도한다면, 이는 관계형 변수의 설계를 위반하게 된다. 왜냐하면 '''고객 ID'''는 ''기본 키''이고, 이미 고객 ''123''이 있기 때문이다. DBMS는 이러한 유형의 트랜잭션을 거부해야 한다. 이는 데이터베이스를 무결성 제약 조건 위반으로 일관성이 없게 만들기 때문이다. 하지만, 새로운 고객이 고유한 ID를 가지고 있다면, 이름 필드는 기본 키의 일부가 아니므로, ''앨리스''라는 다른 고객을 삽입하는 것은 가능하다.
외래 키는 다른 관계에서 후보 키로부터 속성 집합의 값을 가져오도록 강제하는 무결성 제약 조건이다. 예를 들어, Order 관계에서 속성 '''고객 ID'''는 외래 키이다. 조인은 여러 관계의 정보를 한 번에 활용하는 연산이다. 위 예시에서 관계형 변수를 조인함으로써 우리는 모든 고객, 주문 및 송장에 대한 데이터베이스를 쿼리할 수 있다. 만약 특정 고객에 대한 튜플만 원한다면, 제한 조건을 사용하여 이를 지정할 것이다. 만약 고객 ''123''에 대한 모든 주문을 검색하고 싶다면, '''고객 ID'''가 ''123''인 Order 테이블의 모든 행을 반환하도록 데이터베이스를 쿼리할 수 있다.
관계형 데이터베이스에서 데이터 유형은 정수 집합, 문자열 집합, 날짜 집합 등이 될 수 있다. 관계형 모델은 어떤 유형을 지원해야 하는지 규정하지 않는다.
속성은 일반적으로 열, 튜플은 행, 관계는 테이블로 표현된다. 테이블은 열 정의 목록으로 지정되며, 각 열 정의는 고유한 열 이름과 해당 열에 허용되는 값의 유형을 지정한다. 속성 ''값''은 특정 열과 행의 항목이다.
데이터베이스 릴레이션 변수(relation variable)는 일반적으로 기본 테이블로 알려져 있다. 언제든지 할당된 값의 헤더는 테이블 선언에 지정된 대로이며 본문은 업데이트 연산자(일반적으로 INSERT, UPDATE 또는 DELETE)에 의해 가장 최근에 할당된 값이다. 쿼리를 평가하여 생성된 테이블의 헤더와 본문은 해당 쿼리에 사용된 연산자의 정의에 의해 결정된다.
관계형 모델의 기본 개념은 관계 이름과 속성 이름이다. 이를 "Person"과 "name"과 같은 문자열로 나타낸다. 또 다른 기본 개념은 숫자와 문자열과 같은 값을 포함하는 원자 값의 집합이다.
테이블의 행 또는 레코드 개념을 공식화하는 튜플의 개념과 관련된 정의는 다음과 같다.
관계형 모델에 정의된 대로 테이블의 내용을 공식화하는 관계는 다음과 같이 정의한다.
- 관계: 관계는 헤더 와 본체 를 가진 튜플 로, 본체는 모두 도메인 를 가진 튜플 집합이다.
- 관계 유니버스: 헤더 에 대한 관계 유니버스 는 헤더 를 가진 관계의 공집합이 아닌 집합이다.
- 관계 스키마: 관계 스키마 는 헤더 와 헤더 를 가진 모든 관계 에 대해 정의된 술어 로 구성된다. 관계는 헤더 를 가지고 를 만족시키면 관계 스키마 를 만족시킨다.
3. 2. 제약 조건
데이터베이스의 무결성을 보장하기 위한 규칙은 다음과 같다.- 키(Key): 각 튜플을 고유하게 식별하는 속성 집합이다. 관계에서 각 튜플은 고유해야 하므로 모든 관계는 반드시 키를 가지며, 이는 전체 속성 집합일 수 있다.[8] 관계는 여러 튜플을 고유하게 구별하는 방법이 여러 가지일 수 있으므로 여러 개의 키를 가질 수 있다.[8]
- 후보 키: 관계에서 각 튜플을 고유하게 구별하는 데 보장되는 가장 작은 속성의 부분 집합이다.
- 기본 키(Primary Key): 여러 후보 키 중에서 선택된 하나의 키로, 다른 후보 키보다 선호되어 사용된다.
- 대체 키(Alternate Key): 기본 키로 선택되지 않은 나머지 후보 키이다.
- 외래 키: 다른 관계의 기본 키를 참조하는 속성 집합으로, 관계 간의 참조 무결성을 보장한다.[8] 즉, ''R1''의 튜플이 외래 키에 대한 값을 포함하는 경우, 해당 키에 대해 동일한 값을 포함하는 해당 튜플이 ''R2''에 있어야 한다.[8]
예시:
- 고객 ('''고객 ID''', 이름)
- 주문 ('''주문 ID''', 고객 ID, 송장 ID, 날짜)
- 송장 ('''송장 ID''', 고객 ID, 주문 ID, 상태)
위 예시에서 굵고 밑줄이 그어진 속성은 후보 키이고, 굵지 않고 밑줄이 그어진 속성은 외래 키이다. 일반적으로 하나의 후보 키가 기본 키로 선택되어 사용되며, 이 경우 다른 후보 키는 대체 키라고 한다.
만약 ID가 ''123''인 새로운 고객을 삽입하려고 시도한다면, '''고객 ID'''가 기본 키이고 이미 고객 ''123''이 존재하므로 DBMS는 이러한 유형의 트랜잭션을 거부해야 한다.[8]
3. 3. 관계 연산
관계형 데이터베이스에서 데이터를 다루는 데에는 여러 연산들이 사용된다. 이러한 연산들은 사용자가 데이터베이스에 쿼리를 보내 원하는 데이터를 얻을 수 있도록 돕는다. 주요 관계 연산은 다음과 같다.- 선택(Selection): 특정 조건을 만족하는 튜플(행)들을 추출한다. 예를 들어, "나이가 20세 이상인 고객"과 같은 조건을 사용하여 해당 고객들의 정보를 선택할 수 있다.
- 투영(Projection): 지정된 속성(열)들만 추출한다. 예를 들어, "고객 이름과 전화번호"만 보고 싶을 때 이 두 속성만 투영하여 결과를 얻을 수 있다.
- 합집합(Union): 두 관계(테이블)의 튜플들을 합친다. 이때 중복되는 튜플은 제거된다. 예를 들어, "서울에 사는 고객"과 "부산에 사는 고객" 정보를 합쳐 전체 고객 목록을 만들 수 있다.
- 교집합(Intersection): 두 관계에 모두 존재하는 튜플들만 추출한다. 예를 들어, "서울에 살면서 나이가 20세 이상인 고객"처럼 두 조건을 모두 만족하는 고객을 찾을 때 사용한다.
- 차집합(Difference): 한 관계에는 존재하지만 다른 관계에는 없는 튜플들을 추출한다. 예를 들어, "서울에 사는 고객" 중에서 "20세 미만인 고객"을 제외한 나머지 고객들을 찾을 때 사용한다.
- 조인(Join): 공통 속성을 기준으로 두 관계의 튜플들을 결합한다. 예를 들어, 고객 테이블과 주문 테이블을 "고객 ID"를 기준으로 조인하여 각 고객의 주문 정보를 함께 볼 수 있다.
- 카티션 곱(Cartesian Product): 두 관계의 모든 가능한 튜플 조합을 생성한다. 예를 들어, "색상" 테이블(빨강, 파랑, 노랑)과 "크기" 테이블(소, 중, 대)의 카티션 곱은 (빨강-소, 빨강-중, 빨강-대, 파랑-소, ...)와 같이 9개의 튜플을 생성한다.
이 외에도 세미 조인, 외부 조인, 외부 합집합 등 다양한 연산자들이 존재하며, 열 이름을 바꾸거나 요약 및 집계하는 연산자도 있다.
관계형 데이터베이스는 유연하기 때문에 프로그래머는 데이터베이스 설계자가 예상하지 못한 쿼리를 작성할 수 있다. 결과적으로 관계형 데이터베이스는 원래 설계자가 예상하지 못한 방식으로 여러 애플리케이션에서 사용할 수 있으며, 이는 오랫동안(수십 년) 사용할 수 있는 데이터베이스에서 특히 중요하다.[6]
3. 4. 데이터베이스 정규화
관계는 이상 현상의 유형에 따라 분류된다. 제1 정규형 데이터베이스는 모든 유형의 이상 현상에 취약하지만, 도메인/키 정규형 데이터베이스는 수정 이상 현상이 없다.[7] 정규형은 계층적이다. 즉, 최하위 수준은 제1 정규형이며, 데이터베이스는 낮은 수준의 모든 정규형 요구 사항을 먼저 충족하지 않고서는 더 높은 수준의 정규형 요구 사항을 충족할 수 없다.[7]관계 정규화는 관계 데이터베이스 설계 시 데이터베이스 설계의 논리적 정합성과 트랜잭션 성능 향상을 목표로 수행된다.
4. 논리적 해석
관계형 모델은 술어 논리를 사용하여 해석할 수 있다.[13] 관계 변수는 술어와 연결되며, 각 튜플은 참으로 평가되는 명제를 나타낸다. 관계의 본체에 튜플이 존재하면 명제는 참이고, 존재하지 않으면 거짓이다. 이러한 가정은 폐쇄 세계 가정으로 알려져 있다.[13]
예를 들어, 직원 관계에 ''{이름, ID}'' 속성이 있고, 튜플 ''{앨리스, 1}''이 존재한다면, "ID가 1이고 이름이 앨리스인 직원이 존재한다"는 명제는 참이다. 만약 ''{ID}''가 키라면, ''{앨리스, 1}''과 ''{밥, 1}'' 튜플이 동시에 존재하는 것은 모순이다. 폭발 원리에 따라, 이러한 모순은 시스템이 임의의 명제가 참임을 증명할 수 있게 하므로, 데이터베이스는 키 제약 조건을 적용하여 이를 방지해야 한다.[8]
관계의 본체는 술어 논리에서 "외연"이라고 불리며, 관계 변수 술어의 외연으로 해석될 수 있다.[13]
5. SQL과의 관계
SQL(Structured Query Language)은 관계형 데이터베이스를 조작하기 위한 표준 언어이지만, 여러 부분에서 에드거 F. 코드가 제시한 관계형 모델과 차이를 보인다. 현재 ISO SQL 표준은 관계형 모델을 언급하지 않으며, 관계형 용어나 개념을 사용하지 않는다.[8]
관계형 모델에서 관계의 속성과 튜플은 순서가 없고 고유한 집합으로 정의되지만, SQL 테이블의 행과 열은 중복될 수 있으며, 열은 명시적으로 정렬된다. 또한 SQL은 누락된 데이터를 나타내기 위해 NULL 값을 사용하는데, 이는 관계형 모델에 없는 개념이다. 이러한 특징 때문에 SQL은 관계형 모델의 '정보 원칙'을 따르지 않는다는 비판을 받는다.[8]
관계형 모델에서는 이항 관계를 넘어 n개의 항으로 확장된 관계 개념을 사용하며, 관계 대수 또는 관계 논리를 사용하여 데이터를 연산한다. 이 둘은 동등한 연산 능력을 가진다. 관계형 모델에서는 이진 논리가 중요하지만, 삼진 논리의 허용 여부에 대해서는 연구자들 사이에 의견이 갈린다.
관계형 모델을 활용하면 데이터베이스 설계 시 정보의 정합성을 논리적으로 표현할 수 있다. 관계의 정규화를 통해 데이터베이스 설계를 개선할 수 있지만, 실제 데이터 연산은 관계형 데이터베이스 관리 시스템(RDBMS) 엔진에 의해 제어되므로 논리 설계는 관여하지 않는다.
SQL은 처음에 관계형 데이터베이스의 표준 언어로 추진되었지만, 관계형 모델에서 벗어난 부분이 있어 비판받기도 한다.
다음은 SQL 용어와 관계형 모델 용어의 대응 관계이다.
SQL 표준이 관계형 모델에서 벗어난 주요 내용은 다음과 같다.
- 행의 중복: SQL 테이블은 같은 행이 여러 번 나타날 수 있지만, 관계형 모델에서는 튜플 중복이 허용되지 않는다.
- 이름 없는 열: SQL 테이블에는 이름 없는 열이 존재할 수 있어 참조가 불가능하지만, 관계형 모델에서는 모든 속성에 이름이 있어야 하고 참조 가능해야 한다.
- 열 이름 중복: SQL 테이블에서는 여러 열에 같은 이름을 붙일 수 있어 모호성이 발생하지만, 관계형 모델에서는 모든 속성 이름이 고유해야 한다.
- 열 순서 지정: SQL 테이블에서는 열 순서가 중요하지만, 관계형 모델에서는 열 순서가 없다.
- CHECK OPTION이 없는 뷰: SQL에서는 CHECK OPTION 없이 정의된 뷰에 대한 업데이트가 뷰에 반영되지 않을 수 있지만, 관계형 모델에서는 뷰 업데이트가 기본 관계 변수 업데이트와 동일한 결과를 가져야 한다.
- 테이블의 최소 열 개수: SQL 테이블은 최소 1개의 열을 가져야 하지만, 관계형 모델에서는 속성이 0개인 관계도 존재한다.
- NULL: SQL에서 NULL은 특별한 표시로 사용되며 삼치 논리와 관련되어 있지만, 관계형 모델은 배중률에 의존하며 모든 속성에 값이 할당되어야 한다.
에드거 F. 코드는 결손 정보를 처리하기 위해 관계형 모델의 삼치 논리 버전과 사치 논리 버전을 제안했지만, 복잡성 때문에 구현되지 않았다. SQL의 NULL 개념은 삼치 논리 시스템의 일부로 여겨졌지만, 논리적 모순으로 인해 문제가 발생했다.
6. 다른 데이터 모델과의 비교
데이터베이스 모델로는 계층형 데이터베이스 모델과 네트워크 모델이 있다. 이러한 구형 아키텍처를 사용하는 일부 시스템은 오늘날에도 높은 데이터 볼륨이 필요하거나, 기존 시스템이 매우 복잡하고 추상적이어서 관계형 모델을 사용하는 시스템으로 마이그레이션하는 데 비용이 많이 드는 데이터 센터에서 사용되고 있다.[9] 또한 주목할 만한 것으로는 새로운 객체 데이터베이스가 있다.[9]
관계형 모델 이외의 데이터베이스 모델로는 계층형 데이터 모델과 네트워크형 데이터 모델이 있다. 이러한 구형 아키텍처를 사용한 몇몇 시스템이 현재도 데이터 센터에서 사용되고 있으며, 대용량 데이터를 처리해야 하는 경우나, 기존 시스템이 매우 복잡하여 관계형 모델을 채택한 시스템으로 이관하는 데 막대한 비용이 소요되는 경우 등에 사용된다.
새로운 데이터 모델로는 객체 지향 데이터 모델이 있으며, 최근에는 객체 지향 데이터베이스를 사용할 수 있게 되었다. 2009년 현재, 관계형 데이터베이스에 비해 사용 사례는 적지만, 조금씩 채택되기 시작했다. 객체 지향 데이터베이스의 유용성에 대해서는 견해가 갈리고 있다. 객체 지향 데이터베이스는 객체 지향 프로그래밍 언어와의 친화성이 높다는 특징이 있다. 반면 일부에서는 객체 지향 데이터베이스 관리 시스템(ODBMS)의 대부분이 정통 DBMS(데이터베이스 관리 시스템)라기보다는 DBMS 구축 키트이며, 그다지 유용한 기술로 인식하지 않는다.
관계형 모델은 형식화된 최초의 데이터 모델이다. 관계형 모델이 정의된 후, 비형식적인 데이터 모델이 계층형 데이터베이스나 네트워크형 데이터베이스를 기술하기 위해 만들어졌다. 계층형 데이터베이스와 네트워크형 데이터베이스는 관계형 데이터베이스 이전에 이미 존재했다. 그러나 그것들이 모델로 기술된 것은 관계형 모델이 정의된 후였으며, 그 목적은 데이터 모델 간의 비교를 위한 기초를 확립하기 위해서였다.
7. 비판 및 논쟁
관계형 모델은 데이터의 유연성이 부족하다는 비판을 받기도 한다.[12] NoSQL 등 새로운 데이터 모델이 등장하면서, 관계형 모델의 한계와 대안에 대한 논의가 활발하게 이루어지고 있다.
계층형 데이터 모델과 네트워크형 데이터 모델은 관계형 모델 이전에 이미 존재했지만, 관계형 모델이 형식화된 최초의 데이터 모델이기 때문에 이들과의 비교를 위해 관계형 모델이 정의된 후에 비형식적인 모델로 기술되었다.
에드거 F. 코드는 결손 정보를 처리하기 위해 관계형 모델의 삼치 논리 버전을 제안하기도 했지만, 구현의 복잡성 때문에 널리 사용되지는 않았다.
객체 지향 데이터 모델은 새로운 데이터 모델로, 객체 지향 데이터베이스를 통해 사용될 수 있다. 2009년 현재, 관계형 데이터베이스에 비해 사용 사례는 적지만, 객체 지향 프로그래밍 언어와의 친화성이 높아 점차 채택되고 있다. 그러나 객체 지향 데이터베이스 관리 시스템(ODBMS)의 유용성에 대해서는 의견이 분분하다.
기존의 계층형 데이터 모델과 네트워크형 데이터 모델을 사용하는 시스템은 여전히 일부 데이터 센터에서 사용되고 있는데, 이는 대용량 데이터 처리 또는 기존 시스템의 복잡성으로 인해 관계형 모델로의 전환 비용이 크기 때문이다.
8. 결론 및 전망
관계형 모델은 오랜 기간 동안 데이터베이스 분야에서 주류로 자리매김해 왔다. 빅데이터, 인공지능과 같은 새로운 기술 환경에 발맞춰 관계형 모델 역시 지속적으로 발전하고 있으며, 다른 데이터 모델과의 융합 또한 활발하게 이루어질 것으로 전망된다.
참조
[1]
논문
Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks
IBM
[2]
논문
A Relational Model of Data for Large Shared Data Banks
https://web.archive.[...]
[3]
서적
The Relational Model for Database Management
Addison-Wesley
[4]
웹사이트
Did Date and Darwen's "Third Manifesto" have a lasting impact?
https://cs.stackexch[...]
2024-08-03
[5]
서적
Date on Database: Writings 2000–2006
Apress
2006
[6]
웹사이트
Tuple in DBMS
https://www.geeksfor[...]
2024-08-03
[7]
서적
Database Processing: Fundamentals, Design, and Implementation
Prentice-Hall, Inc.
[8]
서적
Relational Theory for Computer Professionals: What Relational Databases are Really All About
O'Reilly Media
2013
[9]
논문
The object-oriented database system manifesto
North-Holland
[10]
논문
Datalog: concepts, history, and outlook
[11]
논문
Universality of data retrieval languages
[12]
논문
A Relational Model of Data for Large Shared Data Banks
http://www.acm.org/c[...]
[13]
서적
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com