대형 언어 모델
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
대형 언어 모델(LLM)은 1990년대 통계적 언어 모델링의 발전 이후, 인터넷 규모의 데이터 세트를 활용하여 훈련되었으며, 2010년대 신경망 기술의 발전에 힘입어 획기적인 발전을 이루었다. 트랜스포머 아키텍처를 기반으로 하는 LLM은 텍스트 토큰을 예측하는 방식으로 훈련되며, 모델 크기, 훈련 데이터 세트 크기, 훈련 비용 등에 따라 성능이 결정된다. 이러한 모델은 미세 조정, 프롬프트 엔지니어링, 명령어 튜닝 등 다양한 방식으로 특정 작업에 적용되며, 텍스트 생성, 번역, 질의 응답 등 다양한 분야에 활용된다. LLM의 성능은 퍼플렉시티와 같은 지표로 평가되며, 창발적 능력과 같은 특징을 보이지만, 편향성 및 정보의 정확성 문제와 같은 윤리적, 사회적 영향도 가지고 있다.
더 읽어볼만한 페이지
- 대형 언어 모델 - 챗GPT
챗GPT는 오픈AI가 개발한 GPT-3.5 기반의 대화형 인공지능 서비스로, 인간과 유사한 텍스트 생성, 코드 생성, 보고서 작성, 번역 등의 다양한 기능을 제공하지만, 편향된 정보 생성, 데이터 유출, 윤리 및 저작권 문제 등의 논란도 있으며, 유료 서비스를 포함한 다양한 형태로 제공되고, 지속적인 모델 개발을 통해 성능을 향상시키고 있다. - 대형 언어 모델 - GPT-3
GPT-3는 OpenAI가 개발한 1,750억 개의 매개변수를 가진 대규모 언어 모델로, 텍스트 생성, 코드 작성, 질문 응답 등 다양한 작업을 수행할 수 있지만, 윤리적 문제점과 사회적 비판도 존재한다. - 딥 러닝 - 질의 응답
질의응답 시스템은 자연어 질문을 이해하고 답변을 생성하며, 질문 유형과 사용 기술에 따라 분류되고, 읽기 이해 기반 또는 사전 지식 기반으로 작동하며, 대규모 언어 모델과 다양한 아키텍처 발전에 힘입어 복잡한 질문에 대한 답변과 다양한 분야에 활용이 가능해졌다. - 딥 러닝 - 딥페이크
딥페이크는 인공지능 기술을 활용하여 영상이나 이미지를 조작, 합성하여 실제와 구별하기 어렵게 만드는 기술이며, 가짜 뉴스, 명예훼손, 신원 위장 등 다양한 문제점을 야기한다. - 자연어 처리 - 정보 추출
정보 추출은 비정형 또는 반구조화된 텍스트에서 구조화된 정보를 자동으로 추출하는 기술로, 자연어 처리 기술을 활용하여 개체명 인식, 관계 추출 등의 작업을 수행하며 웹의 방대한 데이터에서 유용한 정보를 얻는 데 사용된다. - 자연어 처리 - 단어 의미 중의성 해소
단어 의미 중의성 해소(WSD)는 문맥 내 단어의 의미를 파악하는 계산 언어학 과제로, 다양한 접근 방식과 외부 지식 소스를 활용하여 연구되고 있으며, 다국어 및 교차 언어 WSD 등으로 발전하며 국제 경연 대회를 통해 평가된다.
| 대형 언어 모델 |
|---|
2. 역사
대규모 언어 모델(LLM)의 역사는 1950년대 통계적 기계 번역의 초기 시도에서 시작되었지만, 실질적인 발전은 2010년대 딥 러닝 기술의 발전과 함께 이루어졌다.
1990년대 IBM 정렬 모델은 통계적 언어 모델링을 개척했다.[5] 2001년 3억 개의 단어로 훈련된 평활화된 n-gram 모델은 당시 최고 수준의 어휘 중복도를 달성했다.[5] 2000년대 인터넷 사용이 보편화되면서 일부 연구자들은 인터넷 규모의 언어 데이터 세트("웹을 코퍼스로")를 구축하고, 이를 바탕으로 통계적 언어 모델을 훈련시켰다.[6][7][8] 2009년 대부분의 언어 처리 작업에서 통계적 언어 모델이 기호적 언어 모델보다 우위를 점했는데, 이는 대규모 데이터 세트를 유용하게 사용할 수 있었기 때문이다.[9]
신경망이 2012년경 이미지 처리에서 지배적인 위치를 차지한 후,[10] 언어 모델링에도 적용되었다. 구글은 2016년 번역 서비스를 신경 기계 번역으로 전환했는데, 이는 트랜스포머 이전이었기에 seq2seq 딥 LSTM 네트워크를 통해 이루어졌다.
2017년 NeurIPS 컨퍼런스에서 구글 연구원들은 획기적인 논문 "어텐션은 당신이 필요로 하는 전부이다"에서 트랜스포머 아키텍처를 소개했다. 이 논문은 2014년 seq2seq 기술을 개선하는 것이 목표였으며,[11] 2014년 Bahdanau 등이 개발한 어텐션 메커니즘을 기반으로 했다.[12]
2018년 BERT가 소개되어 곧 "유비쿼터스"해졌다.[13] BERT는 인코더 전용 모델이다. BERT의 학술적 및 연구적 사용은 2023년 프롬프팅을 통해 작업을 해결하는 디코더 전용 모델(예: GPT)의 능력이 급격히 향상되면서 감소하기 시작했다.[14]
2018년 디코더 전용 GPT-1이 소개되었지만, OpenAI가 악의적인 사용을 우려하여 처음에는 공개하기에는 너무 강력하다고 판단하여 널리 주목을 받은 것은 GPT-2(2019)였다.[15] 2020년 GPT-3는 한 단계 더 나아가 모델을 로컬에서 실행할 수 있는 모델 다운로드 기능을 제공하지 않고 API를 통해서만 사용할 수 있게 했다. 2022년 소비자 대상 브라우저 기반 ChatGPT는 일반 대중의 상상력을 사로잡고 언론의 과장 광고와 온라인 화제를 일으켰다.[16] 2023년 GPT-4는 정확성 향상과 멀티모달 기능에 대한 "성배"로 칭찬받았다.[17] OpenAI는 GPT-4의 상위 수준 아키텍처와 매개변수 수를 공개하지 않았다. ChatGPT의 출시는 로봇 공학, 소프트웨어 엔지니어링, 사회적 영향 작업 등 컴퓨터 과학의 여러 연구 하위 분야에서 LLM 사용 증가로 이어졌다.[18]
경쟁 언어 모델은 대부분 GPT 시리즈와 적어도 매개변수 수 측면에서 경쟁하려 시도해 왔다.[19]
2022년부터 소스 사용 가능 모델, 특히 처음에는 BLOOM과 LLaMA가 인기를 얻고 있지만, 둘 다 사용 분야에 제한이 있다. Mistral AI의 모델 Mistral 7B와 Mixtral 8x7b는 더 관대한 아파치 라이선스를 가지고 있다. Llama 3 700억 매개변수 모델의 Instruction fine tuned 변형은 LMSYS Chatbot Arena Leaderboard에 따르면 가장 강력한 오픈 LLM으로, GPT-3.5보다 강력하지만 GPT-4만큼 강력하지는 않다.[20]
2024년 현재, 가장 크고 성능이 뛰어난 모델은 모두 트랜스포머 아키텍처를 기반으로 한다. 일부 최근 구현은 순환 신경망 변형 및 Mamba(상태 공간 모델)과 같은 다른 아키텍처를 기반으로 한다.[21][22][23]
2. 1. 선구자
대규모 언어 모델의 기본 아이디어는 단순하고 반복적인 구조를 가진 신경망을 무작위 가중치로 초기화하고 대규모 언어 코퍼스로 훈련하는 것이다.초기 사례 중 하나는 엘먼 네트워크였다.[245] "개가 남자를 쫓는다"와 같은 단순한 문장으로 순환 신경망을 훈련했다. 훈련된 네트워크는 각 단어를 벡터(내부 표현)로 변환했다. 이러한 벡터는 근접성에 따라 트리 구조로 클러스터링되었다. 그 결과, 동사와 명사가 각각 다른 큰 클러스터에 속하는 등의 구조가 나타났다.
자연어 이해를 기호 프로그램을 통해 컴퓨터에 프로그래밍하는 논리 AI(Symbolic artificial intelligence영어)도 있었지만, 1990년대까지 주류를 이루었다. 단순한 구조와 대규모 코퍼스를 통해 자연어를 학습한다는 아이디어는 1950년대에 시작되었지만, 상업적으로 처음 성공한 것은 통계적 기계 번역(Statistical machine translation영어)을 위한 IBM 정렬 모델(IBM alignment models영어) (1990년대)이었다.
2. 2. 트랜스포머 프레임워크로의 진화
초기 "대규모" 언어 모델은 장·단기 기억(LSTM, 1997년)과 같은 순환 신경망 아키텍처를 사용하여 구축되었다. 알렉스넷(2012년)이 이미지 인식 분야에서 대규모 신경망의 유효성을 입증한 후, 연구자들은 대규모 신경망을 다른 작업에 적용했다. 2014년에는 두 가지 주요 기술이 제안되었다.- seq2seq 모델(3억 8,000만 개의 매개변수)은 두 개의 LSTM을 사용하여 기계 번역을 수행했으며[246], 단순화된 아키텍처(게이트 순환 유닛, GRU)로 같은 기술이 사용되었다(1억 3,000만 개의 매개변수)[247]。
- 어텐션 기법은 두 개의 LSTM 중간에 "어텐션 기법"을 추가하여 seq2seq 모델을 개선한 것으로 제안되었다[248]。
2016년, 구글 번역은 해당 기법을 통계적 기계 번역에서 신경 기계 번역으로 변경했다. 이는 LSTM과 어텐션을 사용한 seq2seq 모델로, 10년에 걸쳐 구축된 이전 시스템보다 더 높은 수준의 성능에 도달하는 데 9개월이 걸렸다고 한다[249][250]。
2017년 논문 "''Attention is all you need''"[251]에서는 어텐션 기법을 추상화하여[248], 어텐션 기법을 중심으로 하는 트랜스포머 아키텍처를 구축했다. seq2seq 모델은 다른 순환 신경망과 마찬가지로 입력 시퀀스를 한 번에 하나씩 처리해야 하는 반면, 트랜스포머 아키텍처는 시퀀스에서 병렬로 실행할 수 있다. 이를 통해 더 큰 규모의 모델을 훈련할 수 있게 되었다.
2. 3. BERT와 GPT
2018년에 양방향 트랜스포머인 BERT와 단방향(자기 회귀) 트랜스포머인 GPT가 발표되었다.[252][253][254] 이들은 2023년 현재 주요 아키텍처이다. BERT는 인코더 전용 모델이며, GPT는 디코더 전용 모델이다.[13]3. 아키텍처
대규모 언어 모델에서는 2018년 이후 순차 데이터에 대한 표준 딥 러닝 기법이 된 트랜스포머 아키텍처가 가장 많이 사용된다.
트랜스포머 아키텍처는 2017년 NeurIPS 컨퍼런스에서 구글 연구원들이 발표한 어텐션은 당신이 필요로 하는 전부이다 논문에서 소개되었다. 이 기술은 2014년 Bahdanau 등이 개발한 어텐션 메커니즘을 기반으로 한다.[12]
다른 아키텍처 계열로는 Mixture of Experts(MoE)가 있다. 이는 구글이 개발한 AI 모델에서 자주 사용되며, sparsely-gated MoE(2017년)로 시작하여 Gshard(2021년), GLaM(2022년)으로 이어진다.
2024년 현재, 가장 크고 성능이 뛰어난 모델은 모두 트랜스포머 아키텍처를 기반으로 한다. 일부 최근 구현은 순환 신경망 변형 및 Mamba (상태 공간 모델)과 같은 다른 아키텍처를 기반으로 한다.[21][22][23]
3. 1. 토큰화
머신 러닝 알고리즘은 텍스트가 아닌 숫자를 처리하므로, 텍스트를 숫자로 변환해야 한다. 첫 번째 단계에서는 어휘가 결정된 다음, 각 어휘 항목에 임의적이지만 고유한 정수 인덱스가 할당되고, 마지막으로 단어 임베딩이 정수 인덱스에 연결된다. 알고리즘에는 바이트 쌍 인코딩, WordPiece 등이 있다. 또한 마스크 처리된 토큰에 대한 [MASK] (BERT에서 사용), 어휘에 나타나지 않는 문자에 대한 [UNK] ("unknown")과 같은 제어 문자 역할을 하는 특수 토큰도 있다.[24]LLM은 수학적 함수이며, 그 입력과 출력은 숫자 리스트이다. 따라서 단어는 숫자로 변환해야 한다.
일반적으로 LLM은 이를 위해 고유한 토크나이저를 사용하며, 텍스트와 정수 리스트를 대응시킨다. 일반적으로 LLM을 훈련하기 전에 토크나이저를 훈련 데이터 세트 전체에 적용하고, 그 후에는 고정한다. 토크나이저에는 바이트 쌍 인코딩이 일반적으로 선택된다.
토크나이저의 또 다른 기능은 계산량을 줄이기 위한 텍스트 압축이다. 예를 들어 "where is(어디에 있습니까)"와 같은 일반적인 단어나 구는 7자가 아닌 1개의 토큰으로 인코딩할 수 있다. OpenAI GPT 시리즈에서는 하나의 토큰이 일반적인 영어 텍스트의 약 4자, 즉 약 0.75단어에 해당하는 토크나이저를 사용하고 있다[257].
토크나이저는 임의의 정수를 출력할 수 없다. 일반적으로 {0, 1, 2, ..., V-1} 범위의 정수로 제한하여 출력한다. 여기서 V는 어휘 크기라고 한다.
토크나이저에는 임의의 텍스트를 처리할 수 있는 것(일반적으로 유니코드로 직접 조작)과 그렇지 않은 것이 있다. 토크나이저는 인코딩 불가능한 텍스트에 직면하면 "알 수 없는 텍스트(unknown text)"를 의미하는 특수한 토큰(대개 0)을 출력한다. BERT 논문을 따라 [UNK]로 표기되는 경우가 많다.
또 다른 특수한 토큰은 "패딩"을 나타내는 [PAD] (대개 1)이다. 이는 한 번에 많은 텍스트가 LLM에 입력될 때, 인코딩된 텍스트가 같은 길이가 되도록 조정하는 데 사용된다. LLM에서는 일반적으로 입력 길이가 일정한 시퀀스(자그 배열)일 것을 요구하므로, 인코딩한 짧은 텍스트를 긴 텍스트에 맞추기 위해 패딩을 수행한다.
3. 2. 출력
LLM의 출력은 해당 어휘의 확률 분포이다. 이는 일반적으로 다음과 같이 구현된다.- 텍스트를 수신하면, 대부분의 LLM은 벡터 를 출력한다. 여기서 는 어휘 크기이다.
- 벡터 는 소프트맥스 함수에 의해 가 된다.
이 프로세스에서 일반적으로, 벡터 는 비정규화된 로짓 벡터라고 하며, 벡터 는 확률 벡터라고 한다. 벡터 는 개의 엔트리를 가지며, 모두 비음수이며, 그 합은 1이 되므로, 에 대한 확률 분포, 즉 LLM의 어휘에 대한 확률 분포로 해석할 수 있다.
소프트맥스 함수는 수학적으로 정의되어 있으며, 변화하는 매개변수를 가지고 있지 않다는 점에 유의해야 한다. 따라서 훈련은 이루어지지 않는다.
4. 훈련
대규모 언어 모델(LLM)은 텍스트 토큰 훈련 데이터 세트가 주어지면 데이터 세트 내의 토큰을 예측하도록 사전 훈련된다. 사전 훈련에는 일반적으로 다음 두 가지 형식이 있다.[234]
- 자기 회귀 모델 (GPT형, 다음 단어 예측): "내가 좋아하는 것은"과 같은 텍스트가 주어지면, 모델은 "아이스크림"과 같은 "다음 토큰"을 예측한다.
- 마스크 모델 (BERT형, Cloze test|클로즈 테스트|구멍 메우기영어): "나는 \[MASK] 크림을 \[MASK] 싶다" 와 같은 텍스트가 주어지면, 모델은 "아이스를 먹고"와 같은 숨겨진 토큰을 예측한다.
LLM은 다음 문장 예측(NSP)과 같이 데이터 분포에 대한 이해를 테스트하는 보조 작업으로 훈련하기도 한다. 문장 묶음이 제시되면 모델은 훈련 코퍼스 내에서 문장들이 연속적으로 나타나는지 예측해야 한다.
일반적으로 LLM은 특정 손실 함수, 즉 토큰당 평균 음의 로그 우도 (교차 엔트로피 손실)를 최소화하도록 훈련한다. 예를 들어, 자기 회귀 모델에서 "먹는 것을 좋아한다"가 주어지고 확률 분포 를 예측하는 경우, 이 토큰에 대한 음의 로그 우도 손실은 가 된다.
훈련 시에는 훈련 안정화를 위해 정규화 손실도 사용되지만, 테스트나 평가 시에는 사용되지 않는다.
4. 1. 훈련용 데이터 세트
대규모 언어 모델(LLM)은 일반적으로 다양한 분야와 언어에 걸쳐 방대한 텍스트 데이터로 사전 훈련을 수행한다.[234] 주요 사전 훈련 데이터로는 Common Crawl, The Pile (dataset)|The Pile영어, MassiveText[235], 위키백과, GitHub 등이 알려져 있다. 대부분의 오픈 소스 LLM은 공개된 데이터를 사용하지만, 비공개 데이터로 사전 훈련을 수행하는 경우도 있다.[236]사전 훈련 데이터는 중복 제거, 유해성이 높은 시퀀스 제외, 저품질 데이터 폐기 등 다양한 절차를 통해 원시 텍스트를 전처리하여 생성된다.[237] 언어 데이터 축적은 연간 7%씩 증가하고 있으며, 2022년 10월 현재 고품질 언어 데이터는 에서 범위 내에 있는 것으로 추정된다.[238] LLM은 사전 훈련 데이터를 광범위하게 사용하기 때문에, 사전 훈련 데이터에 평가 데이터가 혼입되면 벤치마크 평가 시 모델 성능에 영향을 미치는 데이터 오염이 발생한다.[239]
초기 LLM은 수십억 단어 규모의 코퍼스로 훈련되었다. OpenAI의 GPT 시리즈의 첫 번째 모델인 GPT-1은 2018년에 로 구성된 BookCorpus로 훈련되었다.[261] 같은 해 BERT는 BookCorpus와 영어판 위키백과의 조합으로 훈련되었으며, 총 가 되었다.[344] 그 이후 LLM의 훈련용 코퍼스는 차원을 달리하며 계속 증가하여, 토큰 수는 최대 수조 개에 달했다.[344]
4. 2. 훈련 비용
LLM의 훈련에는 계산 비용이 많이 든다. 2020년 조사에서는 15억 개의 파라미터를 가진 모델(당시 최첨단 기술보다 두 자릿수 작음)을 훈련하는 데 드는 비용이 8만달러에서 160만달러 사이로 추정되었다.[346][262] 그 후, 소프트웨어와 하드웨어의 발전으로 비용이 대폭 감소했으며, 2023년 논문에서는 120억 개의 파라미터를 가진 모델을 훈련하는 데 드는 비용은 72,300 A100-GPU 시간으로 보고되었다.[263]트랜스포머 기반 LLM의 경우, 훈련 비용은 추론 비용보다 훨씬 더 높다. 한 개의 토큰을 훈련하는 데 파라미터당 6 플롭스가 드는 반면, 한 개의 토큰을 추론하는 데는 파라미터당 1~2 플롭스가 든다.[347]
2020년대 기업들은 점점 더 대규모가 되는 LLM에 막대한 투자를 했다. GPT-2(15억 파라미터, 2019년)의 훈련 비용은 5만달러였지만, Google PaLM(5400억 파라미터, 2022년)은 800만달러가 소요되었다.[264]
5. 하위 작업에 대한 적용
2018년부터 2020년까지 특정 자연어 처리 (NLP) 작업에 대형 언어 모델(LLM)을 활용하는 표준적인 방식은 '작업 특화' 추가 훈련을 통한 모델 미세 조정이었다. 이후 GPT-3와 같은 "더 강력한" LLM에서는, 해결할 문제를 텍스트 프롬프트로 제시하거나, 유사 문제 및 해결책 예시를 함께 제시하는 "프롬프팅 기술"을 통해 추가 훈련 없이도 작업을 해결할 수 있음이 밝혀졌다.[345]
5. 1. 미세 조정
전이 학습의 일종인 미세 조정(fine-tuning)은 이미 학습된 언어 모델을 특정 작업(감성 분석, 개체명 인식, 품사 태깅 등)에 대해 지도 학습 방식으로 훈련하여 수정하는 기법이다. 일반적으로 언어 모델의 마지막 레이어와 다운스트림 태스크(downstream tasks)의 출력을 연결하는 새로운 가중치 집합을 도입한다. 언어 모델의 원래 가중치는 "고정"된 상태로 유지하고, 해당 가중치를 출력에 연결하는 새로운 가중치 레이어만 훈련 중에 조절되도록 구성한다. 또한, 원래 가중치를 조금씩 업데이트하거나, 이전의 고정된 레이어와 함께 업데이트하기도 한다.[344]5. 2. 프롬프트 엔지니어링
GPT-3에 의해 보급된 프롬프트 패러다임에서는, 해결해야 할 문제는 텍스트 프롬프트(응답을 유도하는 지시)로 공식화되며, 모델은 (통계적 추론을 통해) 보완을 생성함으로써 이를 해결해야 한다.[242] "소수 샷 프롬프트"(few-shot prompting)의 경우, 프롬프트에는 유사한 (문제, 해결) 쌍의 소수의 예시가 포함된다.[345] 예를 들어, 영화 리뷰에 대한 감정을 라벨링하는 감성 분석 작업은 다음과 같은 예시로 응답이 유도된다.[242]```text
리뷰: 이 영화는 우울하다.
감정: 부정적
리뷰: 이 영화는 훌륭해!
감정:
```
만약 모델이 "긍정적"이라고 출력하면, 올바르게 작업이 해결된 것이 된다.[346][349] 반면, "제로 샷 프롬프트"(zero-shot prompting)의 경우, 해결 예시를 제공하지 않는다. 동일한 감성 분석 작업에 대한 제로 샷 프롬프트의 예시는 "영화 리뷰와 관련된 감성은 '이 영화는 훌륭해!'이다"이다.[350]
LLM에서 소수 샷의 성능은, 자연어 처리 (NLP) 작업에서 경쟁력 있는 결과를 달성하는 것으로 나타났으며, 때로는 선행하는 최첨단 파인 튜닝 기법을 능가하기도 한다. 이러한 NLP 작업의 예시로는, 기계 번역, 질의 응답 시스템, 마스 채우기 퍼즐, 문장 내 신어 감지 등이 있다.[349] 우수한 프롬프트를 생성하고 최적화하는 것을 프롬프트 엔지니어링이라고 부른다.
5. 3. 명령어 튜닝
명령어 튜닝(instruction tuning)은 보다 자연스럽고 정확한 제로 샷(zero-shot) 프롬프트 대화를 촉진하기 위해 고안된 파인 튜닝의 한 형태이다. 텍스트가 입력되면 사전 훈련된 언어 모델은 훈련에 사용된 텍스트 코퍼스의 분포와 일치하는 보완을 생성한다. 예를 들어, "햄릿의 주요 주제에 대한 에세이를 작성하십시오"라는 프롬프트가 주어졌을 때, 단순한 언어 모델은 "3월 17일 이후에 접수된 제출물에는 하루에 10%의 지연 손해금이 적용됩니다"와 같은 (의도하지 않은) 보완을 출력할 수 있다.[38] 명령어 튜닝에서는 자연어 명령으로 공식화된 많은 작업의 예와 적절한 응답을 사용하여 언어 모델을 훈련한다.명령어 튜닝에서 실천되는 다양한 기법중 하나인 "자기 학습(self-instruct)"은 LLM에 의해 생성된 사례(인간이 만든 소수의 초기 사례에서 부트스트랩한 것)의 훈련 세트로 언어 모델을 파인 튜닝한다.[351]
5. 4. 강화 학습을 통한 미세 조정
OpenAI의 InstructGPT 프로토콜은 사람이 만든 프롬프트와 응답 쌍으로 구성된 데이터 세트를 사용한 지도 학습 기반 파인 튜닝과 인간 피드백을 통한 강화 학습(RLHF)을 수행한다. 이 경우, 인간의 선호도를 반영한 데이터 세트를 사용하여 보상 함수를 지도 학습하고, 이 보상 모델을 사용하여 근위 정책 최적화를 통해 LLM 자체를 훈련한다.[352]5. 5. 도구 사용
LLM만으로는 해결하기 어렵거나 불가능한 문제도 있다. 예를 들어, "354 * 139 = "와 같은 계산식의 경우, 다음 토큰을 예측하기 어려우며, "What is the time now? It is"(지금 몇 시입니까? 지금은)에 대해서는 전혀 예측할 수 없다.[56][57] 그러나 사람이 계산기를 사용하여 계산하고, 시계를 사용하여 시간을 아는 것처럼, LLM도 다른 프로그램을 호출하여 다음 토큰을 예측할 수 있다. LLM은, "What is the time now? It is {system.time()}"(지금 몇 시입니까? 지금은{system.time()})이나 "354 * 139 = {354 * 139}"와 같이 프로그램 코드를 생성하고, 다음으로 다른 프로그램 인터프리터가 생성된 코드를 실행하여 그 출력을 채운다.[58]일반적으로 LLM에 도구를 사용하게 하려면, 도구를 사용할 수 있도록 파인 튜닝을 해야 한다. 도구의 수가 유한하다면, 파인 튜닝은 한 번으로 끝낼 수 있을 것이다. API 서비스와 같이 도구의 수가 임의로 증가하는 경우, API 문서를 읽고 API를 올바르게 호출할 수 있도록 LLM을 파인 튜닝할 수 있다.[59][60]
더 단순한 도구 사용 형태로, 검색 증강 생성(Retrieval Augmented Generation, RAG)이 있으며, 이는 LLM을 문서 검색을 사용하여 확장하는 것으로, 때로는 벡터 데이터베이스를 사용하기도 한다. 쿼리가 주어지면, 문서 검색기가 호출되어 가장 관련성이 높은 문서를 검색한다. 이는 일반적으로 쿼리와 문서를 벡터로 인코딩한 다음, 쿼리의 벡터와 가장 유사한 벡터(일반적으로 벡터 데이터베이스에 저장됨)를 가진 문서를 찾는 방식으로 수행된다. 그런 다음 LLM은 쿼리와 검색된 문서에 포함된 컨텍스트를 기반으로 출력을 생성한다.[61]
5. 6. 에이전트
LLM은 언어 모델이며, 그 자체로는 목표를 가지지 않으므로 에이전트가 아니지만, 지능형 에이전트의 구성 요소로 사용할 수 있다.[271]ReAct(Reason + Act, 추론 + 행동) 방식은 LLM을 플래너로 사용하여 LLM으로부터 에이전트를 구축하는 것이다. LLM은 "생각을 소리내어 말하도록" 유도된다. 구체적으로, 언어 모델에게 환경의 텍스트 표현, 목표, 가능한 행동 목록, 그리고 과거의 행동과 관찰 기록이 주어진다. LLM은 행동을 결정하기 전에 하나 이상의 사고를 하고, 그것이 환경 내에서 실행된다.[271] LLM 플래너에 제공되는 환경의 언어적 기술은, 때로는 환경을 기술한 논문의 LaTeX 코드까지 생각할 수 있다.[272]
리플렉션(Reflextion)법[273]은, 몇몇 에피소드를 통해 학습하는 에이전트를 구축하는 기법이다. 각 에피소드의 마지막에 LLM은 해당 에피소드의 기록을 전달받아, 다음 에피소드에서 더 좋은 성적을 내기 위한 "교훈"을 생각하도록 유도된다. 이러한 "교훈"은 다음 에피소드에서 에이전트에게 전달된다.
몬테카를로 트리 탐색에서는, LLM을 롤아웃을 위한 휴리스틱으로 사용할 수 있다. 프로그램된 세계 모델을 사용할 수 없는 경우, LLM은 세계 모델로서 작동하도록 환경을 설명하도록 유도되기도 한다.[274]
오픈 엔드 탐색에서는, LLM을 관측값의 "흥미로움(interestingness)"의 스코어링에 사용하고, 이를 일반적인 (비 LLM) 강화 학습 에이전트를 유도하는 보상 신호로 사용할 수 있다.[275] 또는, LLM에게, 커리큘럼 학습을 위해 점점 어려워지는 태스크를 제안하게 할 수도 있다.[276] LLM 플래너는, 개별적인 행동을 출력하는 대신, 복잡한 행동 시퀀스를 나타내는 "스킬"이나 함수를 구축할 수도 있다. 스킬을 저장하여 나중에 호출할 수 있으므로, 플래닝의 추상도를 높일 수 있다.[276] LLM을 사용한 에이전트는, 과거의 컨텍스트에 대한 장기 기억을 유지할 수 있으며, 이 기억은 검색 증강 생성과 동일한 방식으로 꺼낼 수 있다. 이러한 에이전트들은 서로 사회적으로 상호 작용할 수 있다.[277]
6. 압축
일반적으로 LLM(대형 언어 모델) 훈련에는 전 정밀도 또는 반 정밀도의 부동 소수점 수(float32와 float16)가 사용된다. float16은 16비트(즉 2바이트)이므로, 예를 들어 10억 개의 매개변수는 2기가바이트가 된다. 전형적인 최대 규모의 모델은 1,000억 개의 매개변수를 가지며, 로드하는 데 200기가바이트가 필요하므로, 대부분의 일반 사용자용 컴퓨터의 능력을 초과한다.[71]
훈련 후 양자화[72]는 훈련된 모델의 성능을 거의 유지하면서 매개변수의 정밀도를 낮춤으로써, 필요한 크기를 줄이는 것을 목표로 한다.[73][74] 양자화의 가장 단순한 형태는 모든 숫자를 지정된 비트 수로 단순히 잘라내는 것이다. 층마다 다른 양자화 코드북을 사용함으로써 개선할 수 있다. 특히 중요한 매개변수("이상치 가중치")에 더 높은 정밀도를 사용하여 다른 정밀도를 다른 매개변수에 적용하여 추가적인 개선을 할 수 있다.[75]
양자화된 모델은 일반적으로 고정되어 있고, 사전 양자화된 모델만 미세 조정되지만, 양자화된 모델도 여전히 미세 조정될 수 있다.[77]
7. 속성
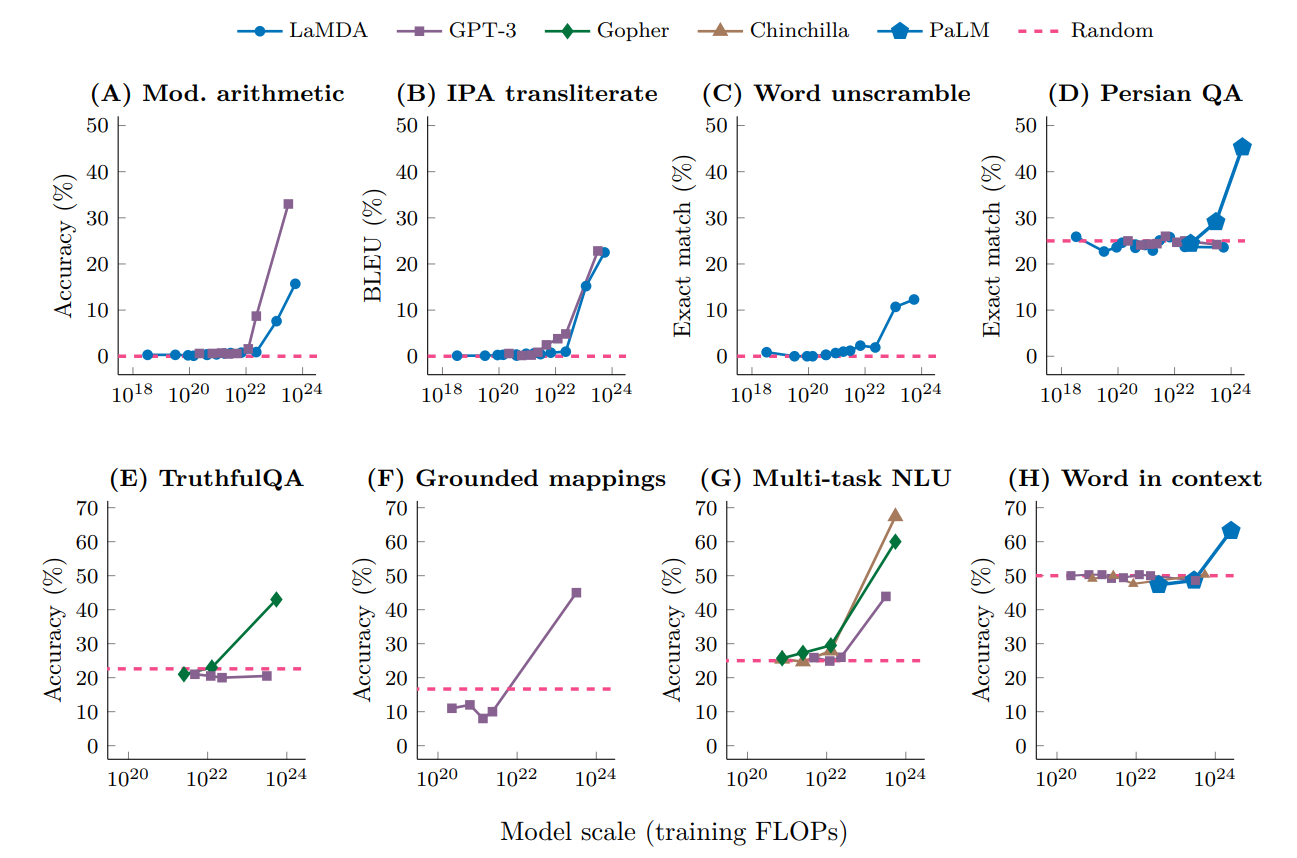
더 큰 모델의 성능은 로그-로그 스케일로 플롯하면 작은 모델이 달성한 성능의 선형 외삽으로 나타난다. 그러나 이러한 선형성은 스케일링 법칙에서 "꺾임"[91]으로 구두점을 찍을 수 있으며, 여기서 선의 기울기가 갑자기 바뀌고 더 큰 모델이 "창발적 능력" (Emergent abilities)을 얻는다.[92][93] 이는 모델의 구성 요소 간의 복잡한 상호 작용에서 발생하며 명시적으로 프로그래밍되거나 설계되지 않는다.[94]
최근 연구에 따르면 대형 언어 모델을 포함한 AI 시스템은 인간의 인지 과정과 유사한 휴리스틱 추론을 사용할 수 있다. 이들은 정확성과 노력 사이에서 최적화하기 위해 인지 지름길(휴리스틱)의 사용과 철저한 논리적 처리를 균형을 이루며 추론 전략을 조정한다. 이러한 행동은 고전적인 제한된 합리성 및 이중 과정 이론과 같이 자원-합리적 인간 인지의 원칙에 부합한다.[95]
Schaeffer 외 연구진은 창발적 능력이 예측 불가능하게 획득되는 것이 아니라 매끄러운 스케일링 법칙에 따라 예측 가능하게 획득된다고 주장한다.[102]
를 파라미터 수, 를 모델의 성능이라고 하자.
7. 1. 스케일링 법칙
일반적으로 LLM은 모델 크기, 훈련 데이터 세트 크기, 훈련 비용, 훈련 후 성능이라는 4가지 매개변수로 특징지을 수 있다. 이 4가지 변수는 각각 실수로 정확하게 정의할 수 있으며, 경험을 통해 "스케일링 법칙(scaling laws)"에 의해 관련되어 있다는 것을 알 수 있다.어떤 연구에서는, 로그-로그 학습률 스케줄로, 1 에포크 분량의 자기 회귀적 훈련을 실시한 LLM의 경우 친칠라 스케일링 법칙을 다음과 같이 나타내고 있다.[240]
여기서 변수는 다음과 같다.
- : 모델 훈련에 드는 비용(FLOPS 단위)
- : 모델 내 파라미터 수
- : 훈련 세트 내 토큰 수
- : 테스트 데이터 세트에서 훈련된 LLM에 의해 달성된, 토큰당 평균 음의 대수 우도 손실(나트/토큰)
통계 파라미터는 다음과 같다.
- , 즉, 하나의 토큰으로 훈련하려면 파라미터당 6 FLOPS의 비용이 든다.[347] 여기서 훈련 비용은 추론 비용보다 훨씬 높다는 점에 유의해야 한다. 하나의 토큰을 추론하는 비용은 파라미터당 1~2 FLOPS이다.
7. 2. 창발적 능력
일반적으로, 다양한 과제에 대한 대규모 모델의 성능은 유사한 소규모 모델의 성능을 기반으로 추정할 수 있지만, 때로는 하위 스케일링 법칙이 "붕괴"되어[241] 대규모 모델이 소규모 모델과는 다른 속도로 갑자기 능력을 습득하는 경우가 있다. 이는 "'''창발적 능력'''"(emergent abilities|이머전트 어빌리티영어)으로 알려져 있으며, 지금까지 많은 연구의 대상이 되어 왔다. 연구자들은 이러한 능력이 "소규모 모델의 성능을 외삽하는 것으로는 예측할 수 없다"고 지적한다[242]. 이러한 능력은 프로그래밍되거나 설계되는 것이 아니라, 오히려 "발견되는" 것이며, 경우에 따라 LLM이 일반에 공개된 후에 처음 발견되기도 한다[232]. 지금까지 수백 가지의 창발적 능력이 보고되었다. 예를 들어, 다단계 산술, 대학교 수준 시험, 단어의 의도하는 의미 파악[242], 사고 사슬 프롬프트[242], 국제 음성 기호 해독, 숫자 채우기 퍼즐, 힝글리시 (힌디어와 영어의 혼합어) 단락 내 불쾌한 내용 파악, 스와힐리어 속어에 해당하는 영어 생성 등이 있다[243].Schaeffer 등은 창발적 능력이 예측 불가능한 형태로 획득되는 것이 아니라, 부드러운 스케일링 법칙에 따라 예측 가능한 방식으로 획득된다고 주장한다[244]. 저자들은 LLM이 객관식 문제를 해결하는 통계적 토이 모델을 검토하고, 다른 종류의 과제를 고려하여 수정된 이 통계 모델이 이러한 과제에도 적용될 수 있음을 보였다.
여기서, 는 파라미터 수, 는 모델의 성능을 나타낸다.
8. 해석
대규모 언어 모델(LLM)은 그 자체로 "블랙 박스"와 같아서, 어떻게 언어 작업을 수행하는지 명확하게 알기 어렵다. 하지만 LLM의 작동 방식을 이해하기 위한 몇 가지 방법이 연구되고 있다.[288]
기계적 해석 가능성은 LLM이 수행하는 추론을 근사하는 기호 알고리즘을 찾아 LLM을 리버스 엔지니어링하는 것을 목표로 한다. 예를 들어, 오셀로 게임의 올바른 수를 예측하도록 훈련된 소규모 트랜스포머 모델인 오셀로 GPT(Othello-GPT)가 있다. 연구 결과, 오셀로 판의 선형 표현이 존재하며, 이 표현을 변경하면 예측되는 올바른 오셀로 수가 올바른 방향으로 변화하는 것을 확인할 수 있었다.
또 다른 예로, 연구자들은 모듈로 산술 덧셈에 대해 소규모 트랜스포머를 훈련시켰다. 그 결과, 모델이 이산 푸리에 변환을 사용하고 있음을 발견했다. 소규모 트랜스포머를 Karel 프로그램에 대해 훈련시킨 예시에서는, Karel 프로그램의 시맨틱스에 선형 표현이 존재하며, 그 표현을 수정하면 출력이 올바르게 변경된다는 것을 확인했다. 이 모델은 또한 훈련 세트 내의 프로그램보다 평균적으로 짧고, 올바른 프로그램을 생성했다.
8. 1. 이해력과 지능
2022년 조사에서, (튜닝되지 않은) 대형 언어 모델(LLM)이 "자연 언어를 어떤 자명하지 않은 의미로 이해할 수 있는가"라는 질문에 대해, 자연어 처리 연구자들의 의견은 양분되었다.[288] "LLM은 이해력을 가진다"는 쪽의 지지자들은, 수학적 추론과 같은 몇몇 LLM의 능력은 특정 개념을 "이해"하는 능력을 의미한다고 생각한다. 마이크로소프트 팀은 2023년에, GPT-4는 "수학, 코딩, 시각, 의학, 법률, 심리학 등에 걸쳐 새롭고 어려운 과제를 해결할 수 있다"고 하며, GPT-4는 "범용 인공지능 시스템의 초기 버전(하지만 아직 미완성)으로 간주하는 것이 타당할 것이다"라고 주장하며, "소프트웨어 공학 응시자의 시험에 합격하는 시스템이, 진정한 의미로 지적이지 않다고 할 수 있을까?[289][290]"라고 말했다. LLM을 "지구 외 생명체의 지능"이라고 부르는 연구자도 있다.[291][292] 예를 들어, 컨젝처(Conjecture)의 CEO인 코너 리히(Conor Leahy)는 튜닝되지 않은 LLM을 마치 정체를 알 수 없는 외계인 "쇼고스"처럼 보고, RLHF 튜닝이 LLM의 내부 구조를 가리는 "겉보기 미소"를 만들어낸다고 생각한다. "무리하지 않으면 미소를 짓고 있다. 하지만 (예상치 못한) 프롬프트를 주면 갑자기 광기, 기묘한 사고 과정, 그리고 명백히 인간이 아닌 이해와 같은 거대한 이면을 드러낸다"[293][294]반대로, "LLM은 이해력이 부족하다"는 쪽의 지지자들 중에는 기존 LLM은 "기존의 문장을 단순히 다시 만들어 조합하고 있을 뿐"이라고 생각하거나[292], 기존 LLM이 예측 능력, 추론 능력, 주체성, 설명 가능성에서 여전히 결점을 가지고 있다는 점을 지적하는 사람도 있다.[295] 예를 들어, GPT-4는 계획 및 실시간 학습에 있어서 중대한 결함이 있다.[290] 생성적 LLM은 훈련 데이터에서 정당화되지 않는 사실을 자신 있게 주장하는 것이 관찰되었으며, 이러한 현상은 "할루시네이션(환각)"으로 알려져 있다.[296] 신경과학자 테렌스 세이노스키(Terrence Sejnowski)는 "LLM의 지성에 관한 전문가 의견의 차이는 자연의 지혜에 기반한 우리의 오래된 생각이 충분하지 않다는 것을 시사한다"라고 주장한다.[297]
9. 평가
대형 언어 모델(LLM)의 성능은 여러 가지 방법으로 평가된다. 1990년대에 IBM 정렬 모델이 통계적 언어 모델링을 개척했고, 2001년에는 3억 단어로 훈련된 평활화된 n-gram 모델이 당시 최고 수준의 어휘 중복도를 달성했다.[5] 2000년대에는 인터넷 규모의 언어 데이터 세트를 구축하고 통계적 언어 모델을 훈련시키는 연구가 진행되었다.[7][8] 2009년에는 통계적 언어 모델이 대규모 데이터 세트를 활용하여 기호적 언어 모델보다 우위를 점했다.[9]
2012년경 신경망이 이미지 처리에서 지배적인 위치를 차지한 후,[10] 언어 모델링에도 적용되었다. 구글은 2016년에 번역 서비스를 신경 기계 번역으로 전환했고, 이는 트랜스포머 이전이었기에 seq2seq 딥 LSTM 네트워크를 통해 이루어졌다.
2017년 NeurIPS 컨퍼런스에서 구글 연구원들은 어텐션은 당신이 필요로 하는 전부이다 논문에서 트랜스포머 아키텍처를 소개했다. 이 논문은 2014년 seq2seq 기술을 개선하는 것을 목표로 했으며,[11] 어텐션 메커니즘을 기반으로 했다.[12] 2018년에는 BERT가 소개되어 "유비쿼터스"해졌다.[13] BERT는 인코더 전용 모델이지만, 2023년에는 디코더 전용 모델(예: GPT)의 능력이 프롬프팅을 통해 향상되면서 BERT의 학술적 및 연구적 사용이 감소하기 시작했다.[14]
OpenAI는 2018년에 디코더 전용 GPT-1을 소개했지만, GPT-2 (2019)가 악의적인 사용을 우려하여 처음에는 공개하지 않아 널리 주목을 받았다.[15] 2020년의 GPT-3는 API를 통해서만 사용할 수 있었지만, 2022년 소비자 대상 브라우저 기반 ChatGPT가 일반 대중의 상상력을 사로잡고 언론의 과장 광고와 온라인 화제를 일으켰다.[16] 2023년의 GPT-4는 정확성 향상과 멀티모달 기능으로 칭찬받았다.[17] OpenAI는 GPT-4의 상위 수준 아키텍처와 매개변수 수를 공개하지 않았다.
경쟁 언어 모델은 대부분 GPT 시리즈와 경쟁하려 시도해 왔다.[19] 2022년부터 소스 사용 가능 모델, 특히 BLOOM과 LLaMA가 인기를 얻고 있지만, 사용 분야에 제한이 있다. Mistral AI의 모델 Mistral 7B와 Mixtral 8x7b는 더 관대한 아파치 라이선스를 가지고 있다.
2024년 현재, 가장 크고 성능이 뛰어난 모델은 모두 트랜스포머 아키텍처를 기반으로 한다. 일부 최근 구현은 순환 신경망 변형 및 Mamba (상태 공간 모델)과 같은 다른 아키텍처를 기반으로 한다.[21][22][23]
수많은 테스트 데이터 세트와 벤치마크가 개발되어 언어 모델의 기능을 평가한다. 테스트는 일반적인 지식, 상식 추론, 수학적 문제 해결을 포함한 다양한 기능을 평가하도록 설계될 수 있다.
2022년 조사에서, (튜닝되지 않은) LLM이 "자연 언어를 어떤 자명하지 않은 의미로 이해할 수 있는가"라는 질문에 대해, 자연어 처리 연구자들의 의견은 양분되었다.[288] "LLM은 이해력을 가진다"는 쪽의 지지자들은, 수학적 추론과 같은 몇몇 LLM의 능력은 특정 개념을 "이해"하는 능력을 의미한다고 생각한다. 반대로, "LLM은 이해력이 부족하다"는 쪽의 지지자들 중에는 기존 LLM은 "기존의 문장을 단순히 다시 만들어 조합하고 있을 뿐"이라고 생각하거나,[292] 기존 LLM이 예측 능력, 추론 능력, 주체성, 설명 가능성에서 여전히 결점을 가지고 있다는 점을 지적하는 사람도 있다.[295]
9. 1. 퍼플렉시티
언어 모델의 성능을 나타내는 가장 일반적인 지표는 주어진 텍스트 코퍼스(말뭉치)에서의 퍼플렉시티이다. 퍼플렉시티는 모델이 데이터 세트의 내용을 얼마나 잘 예측할 수 있는지를 나타내는 척도이다. 모델이 데이터 세트에 할당하는 우도가 높을수록 퍼플렉시티는 낮아진다. 수학적으로, 퍼플렉시티는 토큰당 평균 음의 로그 가능도의 지수로 정의된다.여기서 은 텍스트 코퍼스 내의 토큰 수이며, "context for token (토큰 의 문맥)"는 사용하는 LLM의 종류에 따라 달라진다. 예를 들어, LLM이 자기 회귀형인 경우, "context for token "는 토큰 보다 먼저 나타난 텍스트의 일부이다.
언어 모델은 훈련 데이터에 대해 과적합될 수 있으므로, 모델은 일반적으로 알 수 없는 데이터로 구성된 테스트 세트에 대한 퍼플렉시티로 평가된다. 이는 대규모 언어 모델을 평가할 때 특히 중요한 과제가 된다.[344]
9. 1. 1. BPW, BPC, BPT
정보 이론에서 엔트로피 개념은 클로드 섀넌이 확립한 관계인 퍼플렉시티(혼란도)와 밀접하게 연결되어 있다. 이 관계는 수학적으로 Entropy = log2(Perplexity)로 표현된다. 이 맥락에서 엔트로피는 일반적으로 단어당 비트(BPW) 또는 문자당 비트(BPC)로 정량화되며, 이는 언어 모델이 단어 기반 토큰화를 사용하는지, 아니면 문자 기반 토큰화를 사용하는지에 따라 달라진다. 특히 하위 단어 토큰화를 주로 사용하는 대형 언어 모델의 경우, 토큰당 비트(BPT)가 더 적절한 척도로 나타난다. 그러나 다양한 대형 언어 모델(LLM) 간의 토큰화 방법 차이로 인해 BPT는 다양한 모델 간의 비교 분석에 신뢰할 수 있는 지표로 사용되지 않는다. BPT를 BPW로 변환하려면 토큰당 평균 단어 수를 곱하면 된다.[344] 언어 모델 평가 및 비교에서 교차 엔트로피는 일반적으로 엔트로피보다 선호되는 지표이다. 낮은 BPW는 모델의 압축 능력이 향상되었음을 나타내며, 이는 결국 정확한 예측을 하는 모델의 능력을 반영한다.9. 2. 작업별 데이터 세트 및 벤치마크
언어 모델의 성능을 평가하기 위해 다양한 테스트용 데이터 세트와 벤치마크가 개발되고 있다. 이러한 테스트는 일반 지식, 상식적 추론, 수학 문제 해결 등 다양한 능력을 평가할 수 있도록 설계되었다.평가용 데이터 세트는 크게 질문과 정답 쌍으로 구성된 질문 응답 데이터 세트와 텍스트 보완 형식의 데이터 세트로 나눌 수 있다. 질문 응답 데이터 세트는 모델의 프롬프트에 답을 유추할 수 있는 텍스트가 포함된 경우 '명백한 것(오픈 북)'으로, 그렇지 않은 경우 '(이해할 방법이 없는)설명할 수 없는 것(클로즈드 북)'으로 간주된다. 일반적인 질문 응답 데이터 세트로는 TruthfulQA, Web Questions, TriviaQA, SQuAD 등이 있다.[357] 텍스트 보완 형식의 데이터 세트에서는 모델이 프롬프트를 완성하기 위해 가장 가능성이 높은 단어나 문장을 선택해야 한다.
또한, 다양한 평가 데이터 세트와 작업을 조합한 복합 벤치마크도 개발되고 있다. 예를 들어, GLUE, SuperGLUE, MMLU, BIG-bench, HELM 등이 있다.[358][357] 과거에는 평가용 데이터 세트의 일부를 남겨두고 나머지 부분으로 교사 학습 파인 튜닝을 수행한 후 결과를 보고하는 것이 일반적이었지만, 현재는 사전 훈련된 모델을 프롬프팅 기술을 통해 직접 평가하는 것이 일반적이다.
9. 2. 1. 적대적으로 구성된 평가
대규모 언어 모델의 개선이 빠르게 이루어지면서 평가 벤치마크의 수명도 짧아지고 있다. 최첨단 모델이 기존 벤치마크를 빠르게 "포화"시키고 인간 주석자의 능력을 넘어서는 경우가 발생한다. 이러한 문제에 대응하기 위해 벤치마크를 더 어려운 과제로 대체하거나 강화하려는 노력이 이루어지고 있다. 이러한 노력의 일환으로, 적대적으로 구성된 데이터 세트가 등장했다. 이 데이터 세트는 인간에 비해 기존 언어 모델의 성능이 비정상적으로 낮은 특정 문제에 초점을 맞춘다.TruthfulQA 데이터 세트는 적대적으로 구성된 데이터 세트의 한 예시이다. 또한, AI가 객관식 테스트에서 질문 내용을 실제로 이해하지 않고도 정답을 추측하는 "숏컷 학습"이라는 현상도 존재한다. 이는 표면적인 문제의 통계적 상관관계를 이용해 "커닝"하는 것과 유사하다. 적대적 평가 데이터 세트의 또 다른 예로는 Swag와 그 후속작인 HellaSwag가 있다. 이들은 문장을 완성하기 위해 여러 선택지 중 하나를 골라야 하는 문제들로 구성되어 있다.
10. 광범위한 영향
2023년 과학 저널 ''네이처 바이오메디컬 엔지니어링''은 인간이 작성한 텍스트와 대규모 언어 모델(LLM)이 생성한 텍스트를 "정확하게 구별하는 것은 더 이상 불가능"하며, "범용 대규모 언어 모델의 급속한 보급은 거의 확실하며, 결국 많은 산업을 변화시킬 것이다."라고 결론 내렸다.[298] 골드만삭스는 2023년, 언어 생성 AI가 향후 10년간 전 세계 GDP를 7% 증가시키고 전 세계적으로 3억 명의 고용을 자동화에 노출시킬 수 있다고 밝혔다.[299][300]
일부 기고자는 우발적이거나 의도적인 허위 정보 생성, 기타 악용에 대한 우려를 표명했다.[301] 예를 들어, 대규모 언어 모델을 사용할 수 있게 되면 생물 테러를 일으키는 데 필요한 기술 수준을 낮출 수 있다. 생물 보안 연구원인 케빈 에스펠트는 LLM 개발자가 병원체 제작 또는 개선에 관한 논문을 훈련 데이터에서 제외해야 한다고 제안했다.[302]
10. 1. 편향
대형 언어 모델(LLM)은 인간과 유사한 텍스트를 생성하는 놀라운 능력을 보여주었지만, 훈련 데이터에 존재하는 편향을 상속하고 증폭하기 쉽다. 이는 인종, 성별, 언어, 문화 집단과 같은 다양한 인구 통계에 대한 왜곡된 표현이나 불공정한 처우로 나타날 수 있다.[140] 현재 대형 언어 모델의 훈련 데이터에서 영어 데이터가 과도하게 대표되기 때문에, 비영어권의 관점을 폄하할 수도 있다.[141]AI 모델은 성별, 민족, 나이, 국적, 종교 또는 직업을 포함한 광범위한 고정관념을 강화할 수 있다. 이는 사람들을 불공정하게 일반화하거나 희화화하는, 때로는 해롭거나 비하적인 방식으로 결과물을 생성할 수 있다.[142] 특히 성 편향은 이러한 모델이 다른 성별보다 한 성별에 불공정하게 편향된 결과를 생성하는 경향을 말하며, 훈련 데이터에서 비롯된다. 대규모 언어 모델은 전통적인 성별 규범에 따라 역할과 특성을 부여하는 경우가 많다.[140] 예를 들어, 간호사나 비서를 주로 여성과, 엔지니어 또는 CEO를 남성과 연관시킬 수 있다.[143]
10. 1. 1. 고정관념
대형 언어 모델(LLM)은 인간과 유사한 텍스트를 생성하는 능력을 가지고 있지만, 훈련 데이터에 존재하는 편향을 상속하고 증폭하는 경향이 있다.[140] 이는 인종, 성별, 언어, 문화 집단 등 다양한 인구 통계에 대해 왜곡된 표현이나 불공정한 처우로 나타날 수 있다.[140] 현재 대형 언어 모델의 훈련 데이터에서 영어 데이터가 과도하게 많기 때문에, 비영어권의 관점을 폄하할 수도 있다.[141]정치적 편향은 알고리즘이 특정 정치적 관점, 이념 또는 결과를 다른 것보다 체계적으로 선호하는 경향을 말한다. 언어 모델 또한 정치적 편향성을 나타낼 수 있는데, 훈련 데이터에 광범위한 정치적 의견과 보도가 포함되어 있기 때문에, 모델은 데이터에서 해당 견해의 일반성에 따라 특정 정치적 이념이나 관점으로 기울어진 응답을 생성할 수 있다.[144]
10. 1. 2. 정치적 편향
정치적 편향은 알고리즘이 특정 정치적 관점, 이념 또는 결과를 다른 것보다 체계적으로 선호하는 경향을 말한다. 언어 모델 또한 정치적 편향성을 나타낼 수 있다. 훈련 데이터에 광범위한 정치적 의견과 보도가 포함되어 있기 때문에, 모델은 데이터에서 해당 견해의 일반성에 따라 특정 정치적 이념이나 관점으로 기울어진 응답을 생성할 수 있다.11. 대규모 언어 모델 목록
| 이름 | 출시일 | 개발사 | 매개변수 수(십억) | 코퍼스 크기 | 훈련 비용(페타플롭/일) | 라이선스 | 비고 |
|---|---|---|---|---|---|---|---|
| GPT-1 | OpenAI | 0.117 | 1[145] | MIT License영어[146] | 최초의 GPT 모델, 디코더 전용 변환기. 8개의 P600 GPU에서 30일 동안 훈련됨. | ||
| BERT | 구글 | 0.340[147] | 33억 단어[147] | 9[148] | Apache 2.0영어[149] | 초기이자 영향력 있는 언어 모델.[4] 인코더 전용이며, 따라서 프롬프트하거나 생성하도록 설계되지 않음.[150] 64개의 TPUv2 칩에서 4일 동안 훈련됨. | |
| T5 | 구글 | 11[152] | 340억 토큰[152] | Apache 2.0영어[153] | Imagen과 같은 많은 구글 프로젝트의 기본 모델.[154] | ||
| XLNet | 구글 | 0.340[155] | 330억 단어 | 330 | Apache 2.0영어[156] | BERT의 대안; 인코더 전용으로 설계됨. 512개의 TPU v3 칩에서 5.5일 동안 훈련됨.[157] | |
| GPT-2 | OpenAI | 1.5 | 40GB[158] (100억 토큰)[159] | 28[160] | MIT License영어[161] | 32개의 TPUv3 칩에서 1주 동안 훈련됨.[160] | |
| GPT-3 | OpenAI | 175[51] | 3,000억 토큰[159] | 3640[162] | 독점 | GPT-3의 미세 조정된 변형인 GPT-3.5는 2022년에 ChatGPT라는 웹 인터페이스를 통해 대중에게 공개됨. | |
| GPT-Neo | EleutherAI | 2.7[163] | 825 GiB[164] | MIT License영어 | EleutherAI에서 출시한 일련의 무료 GPT-3 대안 중 첫 번째. GPT-Neo는 일부 벤치마크에서 동등한 크기의 GPT-3 모델보다 성능이 뛰어났지만 가장 큰 GPT-3보다 훨씬 나빴음. | ||
| GPT-J | EleutherAI | 6[165] | 825 GiB[164] | 200[166] | Apache 2.0영어 | GPT-3 스타일 언어 모델 | |
| Megatron-Turing NLG | Microsoft 및 Nvidia | 530 | 3,386억 토큰 | 38000[168] | 제한된 웹 접근 | NVIDIA Selene 슈퍼컴퓨터에서 2000개 이상의 A100 GPU로 3개월 동안 훈련되었으며, 3백만 GPU-시간 이상 소요됨.[168] | |
| 어니 3.0 타이탄 | 바이두 | 260[169] | 4 TB | 독점 | 중국어 LLM. 어니 봇은 이 모델을 기반으로 함. | ||
| 클로드[170] | Anthropic | 52[171] | 4,000억 토큰[171] | 베타 | 대화에서 바람직한 동작을 위해 미세 조정됨.[172] | ||
| GLaM (일반 언어 모델) | 구글 | 1200 | 1조 6,000억 토큰 | 5600 | 독점 | 희소 전문가 혼합 모델로, 훈련 비용은 더 비싸지만 GPT-3에 비해 추론 실행 비용은 저렴함. | |
| 고퍼 | DeepMind | 280[173] | 3,000억 토큰[177] | 5833[174] | 독점 | 나중에 친칠라 모델로 개발됨. | |
| LaMDA (대화 응용 프로그램을 위한 언어 모델) | 구글 | 137 | 1.56T 단어, 1,680억 토큰[177] | 4110[175] | 독점 | 대화에서 응답 생성을 전문으로 함. | |
| GPT-NeoX | EleutherAI | 20[176] | 825 GiB[164] | 740[166] | Apache 2.0영어 | Megatron 아키텍처를 기반으로 함. | |
| 친칠라 | DeepMind | 70 | 1조 4,000억 토큰[177] | 6805[174] | 독점 | 더 많은 데이터로 훈련된 매개변수 감소 모델. 스패로우 봇에 사용됨. 신경 스케일링 법칙으로 종종 인용됨. | |
| PaLM (경로 언어 모델) | 구글 | 540 | 7,680억 토큰 | [174] | 독점 | ~6000개의 TPU v4 칩에서 약 60일 동안 훈련됨.[174] , 이는 공개된 가장 큰 밀집형 변환기임. | |
| OPT (오픈 사전 훈련 변환기) | Meta | 175[178] | 1,800억 토큰[179] | 310[166] | 비상업적 연구 | Megatron에서 일부 적응을 거친 GPT-3 아키텍처. 독특하게도 팀에서 작성한 훈련 로그북이 공개됨.[180] | |
| YaLM 100B | Yandex | 100[181] | 1.7TB[181] | | | Apache 2.0영어 | Microsoft의 Megatron-LM을 기반으로 하는 영어-러시아어 모델. | |
| 미네르바 | 구글 | 540[182] | 수학적 내용에 대해 필터링된 웹페이지와 arXiv 사전 인쇄 서버에 제출된 논문에서 385억 토큰[182] | 독점 | "단계별 추론을 사용하여 수학 및 과학 문제를 해결하기 위해" [183] PaLM 모델에서 초기화된 다음 수학 및 과학 데이터에 대해 미세 조정됨. | ||
| BLOOM | Hugging Face가 주도하는 대규모 협업 | 175[184] | 3,500억 토큰(1.6TB)[185] | Responsible AI License영어 | 기본적으로 GPT-3이지만 다국어 코퍼스(프로그래밍 언어를 제외한 30% 영어)에서 훈련됨. | ||
| 갈락티카 | Meta | 120 | 1,060억 토큰[186] | 알 수 없음 | CC-BY-NC-4.0영어 | 과학 텍스트 및 양식을 기반으로 훈련됨. | |
| AlexaTM (교사 모델) | 아마존 | 20[187] | 1조 3,000억[188] | 독점[189] | 양방향 시퀀스-투-시퀀스 아키텍처 | ||
| Neuro-sama | 독립 | 알 수 없음 | 알 수 없음 | 개인 소유 | Twitch에서 라이브 스트리밍을 위해 설계된 언어 모델. | ||
| LLaMA (대규모 언어 모델 Meta AI) | Meta AI | 65 | 1조 4,000억 | 6300[190] | 비상업적 연구 | 코퍼스는 20개 언어를 가짐. 친칠라 스케일링 법칙과 비교하여 더 적은 매개변수로 더 나은 성능을 위해 "과도하게 훈련"됨. | |
| GPT-4 | OpenAI | 알 수 없음 (소문에 따르면: 1760)[192] | 알 수 없음 | 알 수 없음 | 독점 | ChatGPT Plus 사용자가 사용할 수 있으며 여러 제품에서 사용됨. | |
| 카멜레온 | Meta AI | 34[193] | 4.4조 | ||||
| Cerebras-GPT | Cerebras | 13[194] | 270[166] | Apache 2.0영어 | 친칠라 공식으로 훈련됨. | ||
| 팔콘 | 기술 혁신 연구소 | 40[195] | RefinedWeb(필터링된 웹 텍스트 코퍼스)에서 1조 토큰[196]과 일부 "큐레이션된 코퍼스".[197] | 2800[190] | Apache 2.0영어[198] | ||
| BloombergGPT | 블룸버그 L.P. | 50 | 블룸버그의 데이터 소스를 기반으로 하는 3,630억 토큰 데이터세트와 범용 데이터세트에서 3,450억 토큰[199] | 독점 | 금융 작업을 위해 독점 소스의 금융 데이터를 기반으로 훈련됨. | ||
| 팡구-Σ | 화웨이 | 1085 | 3,290억 토큰[200] | 독점 | |||
| OpenAssistant[201] | LAION | 17 | 1.5조 토큰 | Apache 2.0영어 | 크라우드소싱된 공개 데이터로 훈련됨. | ||
| 쥬라기-2[202] | AI21 Labs | 알 수 없음 | 알 수 없음 | 독점 | 다국어[203] | ||
| PaLM 2 (경로 언어 모델 2) | 구글 | 340[204] | 3.6조 토큰[204] | [190] | 독점 | 바드 챗봇에 사용됨.[205] | |
| 라마 2 | Meta AI | 70[206] | 2조 토큰[206] | Llama 2 라이선스 | 170만 A100 시간.[207] | ||
| 클로드 2 | Anthropic | 알 수 없음 | 알 수 없음 | 알 수 없음 | 독점 | 클로드 챗봇에 사용됨.[208] | |
| Granite 13b | IBM | 알 수 없음 | 알 수 없음 | 알 수 없음 | 독점 | IBM Watsonx에 사용됨.[209] | |
| 미스트랄 7B | 미스트랄 AI | 7.3[210] | 알 수 없음 | Apache 2.0영어 | |||
| 클로드 2.1 | Anthropic | 알 수 없음 | 알 수 없음 | 알 수 없음 | 독점 | 클로드 챗봇에 사용됨. 20만 토큰 또는 ~500페이지의 컨텍스트 창이 있음.[211] | |
| 그록-1[212] | xAI | 314 | 알 수 없음 | 알 수 없음 | Apache 2.0영어 | 그록 챗봇에 사용됨. 그록-1은 8,192 토큰의 컨텍스트 길이를 가지며 X(트위터)에 접근할 수 있음.[213] | |
| 제미니 1.0 | 구글 딥마인드 | 알 수 없음 | 알 수 없음 | 알 수 없음 | 독점 | 다중 모드 모델로, 세 가지 크기로 제공됨. 같은 이름의 챗봇에 사용됨.[214] | |
| Mixtral 8x7B | 미스트랄 AI | 46.7 | 알 수 없음 | 알 수 없음 | Apache 2.0영어 | 많은 벤치마크에서 GPT-3.5 및 Llama 2 70B보다 성능이 뛰어남.[215] 토큰당 129억 개의 매개변수가 활성화된 전문가 혼합 모델.[216] | |
| Mixtral 8x22B | 미스트랄 AI | 141 | 알 수 없음 | 알 수 없음 | Apache 2.0영어 | [217] | |
| Phi-2 | 마이크로소프트 | 2.7 | 1.4T 토큰 | 419[218] | MIT License영어 | 실제 및 합성 "교과서 품질" 데이터로 96개의 A100 GPU에서 14일 동안 훈련됨.[218] | |
| 제미니 1.5 | 구글 딥마인드 | 알 수 없음 | 알 수 없음 | 알 수 없음 | 독점 | 전문가 혼합(MoE) 아키텍처를 기반으로 하는 다중 모드 모델. 100만 개 이상의 토큰 컨텍스트 창.[219] | |
| 제미니 울트라 | 구글 딥마인드 | 알 수 없음 | 알 수 없음 | 알 수 없음 | |||
| 젬마 | 구글 딥마인드 | 7 | 6T 토큰 | 알 수 없음 | Gemma 이용 약관[220] | ||
| 클로드 3 | 2024년 3월 | Anthropic | 알 수 없음 | 알 수 없음 | 알 수 없음 | 독점 | Haiku, Sonnet, Opus의 세 가지 모델을 포함.[221] |
| [https://rubiks.ai/nova/release/ 노바] | 2024년 10월 | [https://rubiks.ai/ 루빅스 AI] | 알 수 없음 | 알 수 없음 | 알 수 없음 | 독점 | Nova-Instant, Nova-Air 및 Nova-Pro의 세 가지 모델을 포함. |
| DBRX | 2024년 3월 | Databricks 및 Mosaic ML | 136 | 12T 토큰 | Databricks Open Model License영어 | 훈련 비용 1,000만 달러. | |
| Fugaku-LLM | 2024년 5월 | 후지쯔, 도쿄 공업 대학 등 | 13 | 3,800억 토큰 | 후가쿠에서 CPU만으로 훈련된 가장 큰 모델.[222] | ||
| Phi-3 | 마이크로소프트 | 14[223] | 4.8T 토큰 | MIT License영어 | 마이크로소프트는 이를 "소형 언어 모델"로 판매.[224] | ||
| Granite Code 모델 | IBM | 알 수 없음 | 알 수 없음 | 알 수 없음 | Apache 2.0영어 | ||
| Qwen2 | 알리바바 클라우드 | 72[225] | 3T 토큰 | 여러 크기, 가장 작은 것은 0.5B. | |||
| 네메트론-4 | 2024년 6월 | Nvidia | 340 | 9T 토큰 | NVIDIA Open Model License영어 | 1 에포크 동안 훈련됨. 2023년 12월부터 2024년 5월까지 6144개의 H100 GPU에서 훈련됨.[226][227] | |
| Llama 3.1 | 2024년 7월 | Meta AI | 405 | 15.6T 토큰 | Llama 3 라이선스 | 405B 버전은 H100-80GB에서 3.8E25 FLOPS로 3,100만 시간이 걸림.[228][229] |
참조
[1]
웹사이트
Better Language Models and Their Implications
https://openai.com/b[...]
2019-02-14
[2]
논문
Language Models are Few-Shot Learners
https://proceedings.[...]
Curran Associates, Inc.
2023-03-14
[3]
간행물
NeOn-GPT: A Large Language Model-Powered Pipeline for Ontology Learning
https://2024.eswc-co[...]
2024-05-26
[4]
논문
Human Language Understanding & Reasoning
https://www.amacad.o[...]
2023-03-09
[5]
문서
A Bit of Progress in Language Modeling
2001-08-09
[6]
논문
Introduction to the Special Issue on the Web as Corpus
https://direct.mit.e[...]
2003-09
[7]
논문
Scaling to very very large corpora for natural language disambiguation
http://dx.doi.org/10[...]
Association for Computational Linguistics
2001
[8]
논문
The Web as a Parallel Corpus
https://direct.mit.e[...]
2024-06-07
[9]
논문
The Unreasonable Effectiveness of Data
https://ieeexplore.i[...]
2009-03
[10]
논문
Review of Image Classification Algorithms Based on Convolutional Neural Networks
2021
[11]
논문
Attention is All you Need
https://proceedings.[...]
Curran Associates, Inc.
2024-01-21
[12]
arXiv
Neural Machine Translation by Jointly Learning to Align and Translate
2014
[13]
논문
A Primer in BERTology: What We Know About How BERT Works
https://aclanthology[...]
2024-01-21
[14]
서적
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
2024-12-08
[15]
웹사이트
New AI fake text generator may be too dangerous to release, say creators
https://www.theguard[...]
2024-01-20
[16]
웹사이트
ChatGPT a year on: 3 ways the AI chatbot has completely changed the world in 12 months
https://www.euronews[...]
"[[Euronews]]"
2024-01-20
[17]
웹사이트
GPT-4 is bigger and better than ChatGPT—but OpenAI won't say why
https://www.technolo[...]
"[[MIT Technology Review]]"
2024-01-20
[18]
서적
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
2024-12-08
[19]
웹사이트
Parameters in notable artificial intelligence systems
https://ourworldinda[...]
2024-01-20
[20]
웹사이트
LMSYS Chatbot Arena Leaderboard
https://huggingface.[...]
2024-06-12
[21]
arXiv
RWKV: Reinventing RNNS for the Transformer Era
2023
[22]
웹사이트
What Is a Transformer Model?
https://blogs.nvidia[...]
2023-07-25
[23]
문서
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
2023-12-01
[24]
문서
What do tokens know about their characters and how do they know it?
2022-06-06
[25]
웹사이트
All languages are NOT created (tokenized) equal
https://blog.yenniej[...]
2023-08-17
[26]
논문
Language Model Tokenizers Introduce Unfairness Between Languages
https://openreview.n[...]
2023-09-16
[27]
웹사이트
OpenAI API
https://platform.ope[...]
2023-04-30
[28]
서적
Foundation Models for Natural Language Processing
2023-08-03
[29]
arXiv
Language Model Tokenizers Introduce Unfairness Between Languages
2023
[30]
웹사이트
The Art of Prompt Design: Prompt Boundaries and Token Healing
https://towardsdatas[...]
2024-08-05
[31]
arXiv
Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus
[32]
논문
Deduplicating Training Data Makes Language Models Better
https://aclanthology[...]
2022-05
[33]
문서
Textbooks Are All You Need II: phi-1.5 technical report
2023-09-11
[34]
arXiv
Rho-1: Not All Tokens Are What You Need
2024-04-11
[35]
arXiv
Language Models are Few-Shot Learners
[36]
arXiv
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
2024-04-23
[37]
arXiv
Training language models to follow instructions with human feedback
2022
[38]
arXiv
Self-Instruct: Aligning Language Model with Self Generated Instructions
2022
[39]
arXiv
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
2017-01-01
[40]
arXiv
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
2021-01-12
[41]
웹사이트
Illustrated transformer
https://jalammar.git[...]
2023-07-29
[42]
웹사이트
The Illustrated GPT-2 (Visualizing Transformer Language Models)
https://jalammar.git[...]
2023-08-01
[43]
웹사이트
Our next-generation model: Gemini 1.5
https://blog.google/[...]
2024-02-15
[44]
웹사이트
Long context prompting for Claude 2.1
https://www.anthropi[...]
2023-12-06
[45]
웹사이트
Rate limits
https://platform.ope[...]
2024-01-20
[46]
서적
Proceedings of the Australasian Computer Science Week Multiconference
2020-02-04
[47]
서적
Speech and Language Processing
https://web.stanford[...]
2022-05-24
[48]
웹사이트
From bare metal to a 70B model: infrastructure set-up and scripts
https://imbue.com/re[...]
2024-07-24
[49]
웹사이트
metaseq/projects/OPT/chronicles at main · facebookresearch/metaseq
https://github.com/f[...]
2024-07-24
[50]
웹사이트
State of the Art: Training >70B LLMs on 10,000 H100 clusters
https://www.latent.s[...]
2024-07-24
[51]
웹사이트
The emerging types of language models and why they matter
https://techcrunch.c[...]
2023-03-09
[52]
arXiv
The Cost of Training NLP Models: A Concise Overview
[53]
arXiv
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
2023-04
[54]
간행물
Artificial Intelligence Index Report 2023
2023-10-05
[55]
arXiv
Scaling Laws for Neural Language Models
[56]
arXiv
PAL: Program-aided Language Models
2022-11-01
[57]
웹사이트
PAL: Program-aided Language Models
https://reasonwithpa[...]
2023-06-12
[58]
arXiv
ART: Automatic multi-step reasoning and tool-use for large language models
2023-03-01
[59]
arXiv
TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs
2023-03-01
[60]
arXiv
Gorilla: Large Language Model Connected with Massive APIs
2023-05-01
[61]
journal
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
https://proceedings.[...]
Curran Associates, Inc.
2023-06-12
[62]
웹사이트
The Growth Behind LLM-based Autonomous Agents
https://www.kdnugget[...]
2023-10-23
[63]
arXiv
ReAct: Synergizing Reasoning and Acting in Language Models
2022-10-01
[64]
arXiv
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning
2023-05-24
[65]
arXiv
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
2023-02-03
[66]
arXiv
Reflexion: Language Agents with Verbal Reinforcement Learning
2023-03-01
[67]
arXiv
Reasoning with Language Model is Planning with World Model
2023-05-01
[68]
arXiv
OMNI: Open-endedness via Models of human Notions of Interestingness
2023-06-02
[69]
웹사이트
Voyager {{!}} An Open-Ended Embodied Agent with Large Language Models
https://voyager.mine[...]
2023-06-09
[70]
arXiv
Generative Agents: Interactive Simulacra of Human Behavior
2023-04-01
[71]
뉴스
How to run an LLM locally on your PC in less than 10 minutes
https://www.theregis[...]
2024-05-17
[72]
간행물
Up or Down? Adaptive Rounding for Post-Training Quantization
https://proceedings.[...]
PMLR
2023-06-14
[73]
arXiv
Model compression via distillation and quantization
2018-02-01
[74]
arXiv
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
2022-10-01
[75]
arXiv
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
2023-06-01
[76]
웹사이트
A Visual Guide to Quantization
https://newsletter.m[...]
2024-07-31
[77]
arXiv
QLoRA: Efficient Finetuning of Quantized LLMs
2023-05-01
[78]
간행물
Multimodal Neural Language Models
https://proceedings.[...]
PMLR
2023-07-02
[79]
간행물
ImageNet Classification with Deep Convolutional Neural Networks
https://proceedings.[...]
Curran Associates, Inc.
2023-07-02
[80]
간행물
VQA: Visual Question Answering
https://openaccess.t[...]
2023-07-02
[81]
arXiv
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
2023-01-01
[82]
간행물
Flamingo: a Visual Language Model for Few-Shot Learning
https://proceedings.[...]
2023-07-02
[83]
arXiv
PaLM-E: An Embodied Multimodal Language Model
2023-03-01
[84]
arXiv
Visual Instruction Tuning
2023-04-01
[85]
arXiv
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
2023-06-01
[86]
arXiv
GPT-4 Technical Report
2023-03-27
[87]
웹사이트
GPT-4V(ision) System Card
https://cdn.openai.c[...]
2023-09-25
[88]
Youtube
Google Keynote (Google I/O '23)
https://www.youtube.[...]
2023-07-02
[89]
웹사이트
Mistral releases Pixtral 12B, its first multimodal model
https://techcrunch.c[...]
2024-09-11
[90]
arXiv
Training Compute-Optimal Large Language Models
2022-03-29
[91]
arXiv
Broken Neural Scaling Laws
[92]
간행물
Emergent Abilities of Large Language Models
https://openreview.n[...]
2023-03-19
[93]
웹사이트
137 emergent abilities of large language models
https://www.jasonwei[...]
2023-06-24
[94]
arXiv
Eight Things to Know about Large Language Models
[95]
arXiv
Heuristic Reasoning in AI: Instrumental Use and Mimetic Absorption
[96]
arXiv
A Theory of Emergent In-Context Learning as Implicit Structure Induction
2023-03-14
[97]
간행물
Proceedings of the 2019 Conference of the North
https://aclanthology[...]
Association for Computational Linguistics
2023-06-27
[98]
웹사이트
WiC: The Word-in-Context Dataset
https://pilehvar.git[...]
2023-06-27
[99]
간행물
Mapping Language Models to Grounded Conceptual Spaces
https://openreview.n[...]
2023-06-27
[100]
Webarchive
A Closer Look at Large Language Models Emergent Abilities
https://www.notion.s[...]
2023-06-24
[101]
웹사이트
The Unpredictable Abilities Emerging From Large AI Models
https://www.quantama[...]
2023-03-16
[102]
arXiv
Are Emergent Abilities of Large Language Models a Mirage?
2023-04-01
[103]
arXiv
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
2022-10-01
[104]
웹사이트
Large Language Model: world models or surface statistics?
https://thegradient.[...]
2023-06-12
[105]
arXiv
Evidence of Meaning in Language Models Trained on Programs
2023-05-01
[106]
arXiv
Progress measures for grokking via mechanistic interpretability
2023-01-01
[107]
저널
The debate over understanding in AI's large language models
2023-03-28
[108]
뉴스
Microsoft Says New A.I. Shows Signs of Human Reasoning
https://www.nytimes.[...]
2023-05-16
[109]
arXiv
Sparks of Artificial General Intelligence: Early experiments with GPT-4
2023
[110]
뉴스
Anthropic CEO Dario Amodei pens a smart look at our AI future
https://www.fastcomp[...]
2024-10-17
[111]
뉴스
ChatGPT is more like an 'alien intelligence' than a human brain, says futurist
https://www.zdnet.co[...]
2023-06-12
[112]
간행물
What Kind of Mind Does ChatGPT Have?
https://www.newyorke[...]
2023-06-12
[113]
뉴스
Why an Octopus-like Creature Has Come to Symbolize the State of A.I.
https://www.nytimes.[...]
2023-06-12
[114]
뉴스
The A to Z of Artificial Intelligence
https://time.com/627[...]
2023-06-12
[115]
저널
Survey of Hallucination in Natural Language Generation
https://dl.acm.org/d[...]
Association for Computing Machinery
2023-01-15
[116]
arXiv
A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation
2023
[117]
서적
Philosophy in the Flesh: The Embodied Mind and Its Challenge to Western Philosophy; Appendix: The Neural Theory of Language Paradigm
New York Basic Books
[118]
서적
The Language Myth
Cambridge University Press
[119]
서적
Active Inference: The Free Energy Principle in Mind, Brain, and Behavior; Chapter 4 The Generative Models of Active Inference
The MIT Press
[120]
웹사이트
Evaluation Metrics for Language Modeling
https://thegradient.[...]
2024-01-14
[121]
arXiv
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
[122]
arXiv
A Survey of Large Language Models
[123]
Citation
openai/simple-evals
https://github.com/o[...]
OpenAI
2024-05-28
[124]
Citation
openai/evals
https://github.com/o[...]
OpenAI
2024-05-28
[125]
웹사이트
Sanitized open-source datasets for natural language and code understanding: how we evaluated our 70B model
https://imbue.com/re[...]
2024-07-24
[126]
arXiv
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
[127]
arXiv
TruthfulQA: Measuring How Models Mimic Human Falsehoods
[128]
arXiv
HellaSwag: Can a Machine Really Finish Your Sentence?
[129]
저널
Prepare for truly useful large language models
2023-03-07
[130]
뉴스
Your job is (probably) safe from artificial intelligence
https://www.economis[...]
2023-06-18
[131]
웹사이트
Generative AI Could Raise Global GDP by 7%
https://www.goldmans[...]
2023-06-18
[132]
저널
Near-Duplicate Sequence Search at Scale for Large Language Model Memorization Evaluation
https://people.cs.ru[...]
2024-01-20
[133]
문서
Peng|Wang|Deng|2023|p=8
[134]
뉴스
AI chatbots have been used to create dozens of news content farms
https://www.japantim[...]
2023-06-18
[135]
저널
Could chatbots help devise the next pandemic virus?
https://www.science.[...]
2023-06-18
[136]
웹사이트
How Googlers cracked an SF rival's tech model with a single word
https://www.sfgate.c[...]
SFGATE
2023-12-01
[137]
arXiv
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
2024-01-10
[138]
arXiv
Exploiting programmatic behavior of LLMs: Dual-use through standard security attacks
2023
[139]
웹사이트
Encryption Based Covert Channel for Large Language Models
https://eprint.iacr.[...]
IACR ePrint 2024/586
2024-06-24
[140]
웹사이트
ChatGPT Replicates Gender Bias in Recommendation Letters
https://www.scientif[...]
2023-12-29
[141]
arXiv
A Perspectival Mirror of the Elephant: Investigating Language Bias on Google, ChatGPT, Wikipedia, and YouTube
2023-03-28
[142]
Citation
Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models
2023-05-29
[143]
서적
Proceedings of the ACM Collective Intelligence Conference
Association for Computing Machinery
2023-11-05
[144]
웹사이트
AI language models are rife with different political biases
https://www.technolo[...]
2023-12-29
[145]
웹사이트
Improving language understanding with unsupervised learning
https://openai.com/r[...]
2023-03-18
[146]
웹사이트
finetune-transformer-lm
https://github.com/o[...]
2024-01-02
[147]
arXiv
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2018-10-11
[148]
웹사이트
Cerebras Shifts Architecture To Meet Massive AI/ML Models
https://www.nextplat[...]
2023-06-20
[149]
웹사이트
BERT
https://github.com/g[...]
2023-03-13
[150]
arXiv
Bidirectional Language Models Are Also Few-shot Learners
2022
[151]
arXiv
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2018-10-11
[152]
간행물
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
http://jmlr.org/pape[...]
2020
[153]
Citation
google-research/text-to-text-transfer-transformer
https://github.com/g[...]
Google Research
2024-04-04
[154]
웹사이트
Imagen: Text-to-Image Diffusion Models
https://imagen.resea[...]
2024-04-04
[155]
웹사이트
Pretrained models — transformers 2.0.0 documentation
https://huggingface.[...]
2024-08-05
[156]
웹사이트
xlnet
https://github.com/z[...]
2024-01-02
[157]
arXiv
XLNet: Generalized Autoregressive Pretraining for Language Understanding
2020-01-02
[158]
웹사이트
Better language models and their implications
https://openai.com/r[...]
2023-03-13
[159]
웹사이트
OpenAI's GPT-3 Language Model: A Technical Overview
https://lambdalabs.c[...]
2023-03-13
[160]
웹사이트
openai-community/gpt2-xl · Hugging Face
https://huggingface.[...]
2024-07-24
[161]
웹사이트
gpt-2
https://github.com/o[...]
2023-03-13
[162]
arXiv
Language Models are Few-Shot Learners
2020-05-28
[163]
웹사이트
GPT Neo
https://github.com/E[...]
2023-03-12
[164]
arXiv
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
2020-12-31
[165]
웹사이트
GPT-J-6B: An Introduction to the Largest Open Source GPT Model {{!}} Forefront
https://www.forefron[...]
2023-02-28
[166]
arXiv
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
2023-04-01
[167]
웹사이트
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World's Largest and Most Powerful Generative Language Model
https://www.microsof[...]
2023-03-13
[168]
Citation
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
2022-07-21
[169]
arXiv
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
2021-12-23
[170]
웹사이트
Product
https://www.anthropi[...]
2023-03-14
[171]
arXiv
A General Language Assistant as a Laboratory for Alignment
2021-12-09
[172]
arXiv
Constitutional AI: Harmlessness from AI Feedback
2022-12-15
[173]
웹사이트
Language modelling at scale: Gopher, ethical considerations, and retrieval
https://www.deepmind[...]
2023-03-20
[174]
문서
"Table 20 and page 66 of ''[https://storage.googleapis.com/pathways-language-model/PaLM-paper.pdf PaLM: Scaling Language Modeling with Pathways]"
https://storage.goog[...]
2023-06-10
[175]
arXiv
LaMDA: Language Models for Dialog Applications
2022-01-01
[176]
간행물
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
https://aclanthology[...]
2022-12-19
[177]
arXiv
Training Compute-Optimal Large Language Models
2022-03-29
[178]
웹사이트
Democratizing access to large-scale language models with OPT-175B
https://ai.facebook.[...]
2023-03-12
[179]
arXiv
OPT: Open Pre-trained Transformer Language Models
2022-06-21
[180]
웹사이트
metaseq/projects/OPT/chronicles at main · facebookresearch/metaseq
https://github.com/f[...]
2024-10-18
[181]
문서
YaLM 100B
https://github.com/y[...]
2023-03-18
[182]
arXiv
Solving Quantitative Reasoning Problems with Language Models
2022-06-30
[183]
웹사이트
Minerva: Solving Quantitative Reasoning Problems with Language Models
https://ai.googleblo[...]
2023-03-20
[184]
학술지
In AI, is bigger always better?
https://www.nature.c[...]
2023-03-09
[185]
웹사이트
bigscience/bloom · Hugging Face
https://huggingface.[...]
2023-03-13
[186]
arXiv
Galactica: A Large Language Model for Science
2022-11-16
[187]
웹사이트
20B-parameter Alexa model sets new marks in few-shot learning
https://www.amazon.s[...]
2023-03-12
[188]
arXiv
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
2022-08-03
[189]
웹사이트
AlexaTM 20B is now available in Amazon SageMaker JumpStart {{!}} AWS Machine Learning Blog
https://aws.amazon.c[...]
2023-03-13
[190]
웹사이트
The Falcon has landed in the Hugging Face ecosystem
https://huggingface.[...]
2023-06-20
[191]
웹사이트
GPT-4 Technical Report
https://cdn.openai.c[...]
2023-03-14
[192]
웹사이트
GPT-4 architecture, datasets, costs and more leaked
https://the-decoder.[...]
2024-07-26
[193]
뉴스
Meta introduces Chameleon, a state-of-the-art multimodal model
https://venturebeat.[...]
VentureBeat
2024-05-22
[194]
웹사이트
Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models
https://www.cerebras[...]
2023-03-28
[195]
웹사이트
Abu Dhabi-based TII launches its own version of ChatGPT
https://fastcompanym[...]
2023-04-03
[196]
arXiv
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
2023-06-01
[197]
웹사이트
tiiuae/falcon-40b · Hugging Face
https://huggingface.[...]
2023-06-20
[198]
웹사이트
UAE's Falcon 40B, World's Top-Ranked AI Model from Technology Innovation Institute, is Now Royalty-Free
https://www.business[...]
2023-05-31
[199]
arXiv
BloombergGPT: A Large Language Model for Finance
2023-03-30
[200]
arXiv
PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
2023-03-19
[201]
arXiv
OpenAssistant Conversations – Democratizing Large Language Model Alignment
2023-04-14
[202]
웹사이트
Tel Aviv startup rolls out new advanced AI language model to rival OpenAI
https://www.timesofi[...]
2023-07-24
[203]
웹사이트
With Bedrock, Amazon enters the generative AI race
https://techcrunch.c[...]
2023-07-24
[204]
뉴스
Google's newest A.I. model uses nearly five times more text data for training than its predecessor
https://www.cnbc.com[...]
CNBC
2023-05-18
[205]
웹사이트
Introducing PaLM 2
https://blog.google/[...]
2023-05-18
[206]
웹사이트
Introducing Llama 2: The Next Generation of Our Open Source Large Language Model
https://ai.meta.com/[...]
2023-07-19
[207]
웹사이트
llama/MODEL_CARD.md at main · meta-llama/llama
https://github.com/m[...]
2024-05-28
[208]
웹사이트
Claude 2
https://www.anthropi[...]
2023-12-12
[209]
웹사이트
Building AI for business: IBM's Granite foundation models
https://www.ibm.com/[...]
2024-08-11
[210]
웹사이트
Announcing Mistral 7B
https://mistral.ai/n[...]
2023-10-06
[211]
웹사이트
Introducing Claude 2.1
https://www.anthropi[...]
2023-12-12
[212]
간행물
xai-org/grok-1
https://github.com/x[...]
xai-org
2024-03-19
[213]
웹사이트
Grok-1 model card
https://x.ai/model-c[...]
2023-12-12
[214]
웹사이트
Gemini – Google DeepMind
https://deepmind.goo[...]
2023-12-12
[215]
웹사이트
Mistral shocks AI community as latest open source model eclipses GPT-3.5 performance
https://venturebeat.[...]
2023-12-11
[216]
웹사이트
Mixtral of experts
https://mistral.ai/n[...]
2023-12-11
[217]
웹사이트
Cheaper, Better, Faster, Stronger
https://mistral.ai/n[...]
2024-04-17
[218]
웹사이트
Phi-2: The surprising power of small language models
https://www.microsof[...]
2023-12-12
[219]
웹사이트
Our next-generation model: Gemini 1.5
https://blog.google/[...]
2024-02-15
[220]
웹사이트
Gemma
https://ai.google.de[...]
[221]
웹사이트
Introducing the next generation of Claude
https://www.anthropi[...]
2024-03-04
[222]
웹사이트
Fugaku-LLM/Fugaku-LLM-13B · Hugging Face
https://huggingface.[...]
2024-05-17
[223]
웹사이트
Phi-3
https://azure.micros[...]
2024-04-23
[224]
웹사이트
Phi-3 Model Documentation
https://huggingface.[...]
2024-04-28
[225]
웹사이트
Qwen2
https://github.com/Q[...]
2024-06-17
[226]
웹사이트
nvidia/Nemotron-4-340B-Base · Hugging Face
https://huggingface.[...]
2024-06-14
[227]
웹사이트
Nemotron-4 340B {{!}} Research
https://research.nvi[...]
2024-06-15
[228]
뉴스
The Llama 3 Herd of Models
https://ai.meta.com/[...]
"Llama Team, AI @ Meta"
2024-07-23
[229]
웹사이트
llama-models/models/llama3_1/MODEL_CARD.md at main · meta-llama/llama-models
https://github.com/m[...]
2024-07-23
[230]
웹사이트
Self-Supervised Learning Vs Semi-Supervised Learning: How They Differ
https://analyticsind[...]
2023-05-13
[231]
웹사이트
Responsible AI - Week 3
https://www.coursera[...]
2023-07-23
[232]
논문
Eight Things to Know about Large Language Models
https://cims.nyu.edu[...]
[233]
논문
Are Emergent Abilities of Large Language Models a Mirage?
https://arxiv.org/ab[...]
2023
[234]
논문
PaLM 2 Technical Report
[235]
웹사이트
Papers with Code - MassiveText Dataset
https://paperswithco[...]
2023-04-26
[236]
논문
BloombergGPT: A Large Language Model for Finance
[237]
논문
Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus
[238]
논문
Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
2022-10-25
[239]
논문
Language Models are Few-Shot Learners
[240]
논문
Training Compute-Optimal Large Language Models
https://arxiv.org/ab[...]
2022-03-29
[241]
간행물
Broken Neural Scaling Laws
2022
[242]
논문
Emergent Abilities of Large Language Models
https://openreview.n[...]
2022-08-31
[243]
웹사이트
The Unpredictable Abilities Emerging From Large AI Models
https://www.quantama[...]
2023-05-13
[244]
논문
Are Emergent Abilities of Large Language Models a Mirage?
2023-04-01
[245]
논문
Finding Structure in Time
http://doi.wiley.com[...]
1990-03
[246]
논문
Sequence to Sequence Learning with Neural Networks
https://proceedings.[...]
Curran Associates, Inc.
2014
[247]
논문
On the Properties of Neural Machine Translation: Encoder–Decoder Approaches
https://doi.org/10.3[...]
Association for Computational Linguistics
2014
[248]
논문
Neural Machine Translation by Jointly Learning to Align and Translate
https://ui.adsabs.ha[...]
2014-09-01
[249]
뉴스
The Great A.I. Awakening
https://www.nytimes.[...]
2023-06-22
[250]
논문
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
https://ui.adsabs.ha[...]
2016-09-01
[251]
논문
Attention is All you Need
https://proceedings.[...]
Curran Associates, Inc.
2017
[252]
arXiv
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2018-10-11
[253]
웹사이트
Improving language understanding with unsupervised learning
https://openai.com/r[...]
2023-03-18
[254]
Citation
finetune-transformer-lm
https://github.com/o[...]
OpenAI
2023-05-01
[255]
논문
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
https://ui.adsabs.ha[...]
2017-01-01
[256]
논문
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
https://openreview.n[...]
2021-01-12
[257]
웹사이트
OpenAI API
https://platform.ope[...]
2023-04-30
[258]
웹사이트
OpenAI API
https://platform.ope[...]
2023-06-20
[259]
웹사이트
A survey of LLMs with a practical guide and evolutionary tree
https://twitter.com/[...]
2023-06-23
[260]
논문
A Short Survey of Pre-trained Language Models for Conversational AI-A New Age in NLP
https://www.research[...]
2020-02-04
[261]
논문
Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books
https://www.cv-found[...]
2023-04-11
[262]
문서
The cost of training nlp models: A concise overview
2020
[263]
arXiv
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
2023-04
[264]
뉴스
AI is entering an era of corporate control
https://www.theverge[...]
2023-04-03
[265]
arXiv
PAL: Program-aided Language Models
2022-11-01
[266]
웹사이트
PAL: Program-aided Language Models
https://reasonwithpa[...]
2023-06-12
[267]
arXiv
ART: Automatic multi-step reasoning and tool-use for large language models
2023-03-01
[268]
arXiv
TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs
2023-03-01
[269]
논문
Gorilla: Large Language Model Connected with Massive APIs
https://ui.adsabs.ha[...]
2023-05-01
[270]
논문
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
https://proceedings.[...]
Curran Associates, Inc.
2020
[271]
arXiv
ReAct: Synergizing Reasoning and Acting in Language Models
2022-10-01
[272]
arXiv
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning
2023-05-24
[273]
논문
Reflexion: Language Agents with Verbal Reinforcement Learning
https://ui.adsabs.ha[...]
2023-03-01
[274]
arXiv
Reasoning with Language Model is Planning with World Model
2023-05-01
[275]
arXiv
OMNI: Open-endedness via Models of human Notions of Interestingness
2023-06-02
[276]
웹사이트
Voyager
https://voyager.mine[...]
2023-06-09
[277]
논문
Generative Agents: Interactive Simulacra of Human Behavior
https://ui.adsabs.ha[...]
2023-04-01
[278]
논문
Up or Down? Adaptive Rounding for Post-Training Quantization
https://proceedings.[...]
PMLR
2020-11-21
[279]
arXiv
Model compression via distillation and quantization
2018-02-01
[280]
arXiv
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
2022-10-01
[281]
arXiv
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
2023-06-01
[282]
arXiv
QLoRA: Efficient Finetuning of Quantized LLMs
2023-05-01
[283]
journal
The debate over understanding in AI's large language models
2023-03-28
[284]
arXiv
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
2022-10-01
[285]
웹사이트
Large Language Model: world models or surface statistics?
https://thegradient.[...]
2023-01-21
[286]
arXiv
Progress measures for grokking via mechanistic interpretability
2023-01-01
[287]
arXiv
Evidence of Meaning in Language Models Trained on Programs
2023-05-01
[288]
journal
The debate over understanding in AI's large language models
2023-03-28
[289]
뉴스
Microsoft Says New A.I. Shows Signs of Human Reasoning
https://www.nytimes.[...]
2023-05-16
[290]
arXiv
Sparks of Artificial General Intelligence: Early experiments with GPT-4
2023
[291]
뉴스
ChatGPT is more like an 'alien intelligence' than a human brain, says futurist
https://www.zdnet.co[...]
2023
[292]
magazine
What Kind of Mind Does ChatGPT Have?
https://www.newyorke[...]
2023-04-13
[293]
뉴스
Why an Octopus-like Creature Has Come to Symbolize the State of A.I.
https://www.nytimes.[...]
2023-05-30
[294]
뉴스
The A to Z of Artificial Intelligence
https://time.com/627[...]
2023-04-13
[295]
journal
The debate over understanding in AI's large language models
2023-03-28
[296]
journal
Survey of Hallucination in Natural Language Generation
https://dl.acm.org/d[...]
Association for Computing Machinery
2022-11
[297]
journal
The debate over understanding in AI's large language models
2023-03-28
[298]
뉴스
Prepare for truly useful large language models
2023-03-07
[299]
뉴스
Your job is (probably) safe from artificial intelligence
https://www.economis[...]
2023-05-07
[300]
웹사이트
Generative AI Could Raise Global GDP by 7%
https://www.goldmans[...]
[301]
뉴스
AI chatbots have been used to create dozens of news content farms
https://www.japantim[...]
2023-05-01
[302]
journal
Could chatbots help devise the next pandemic virus?
https://www.science.[...]
2023-06-14
[303]
웹사이트
BERT
https://github.com/g[...]
2023-03-13
[304]
journal
Bidirectional Language Models Are Also Few-shot Learners
https://www.semantic[...]
2022
[305]
웹사이트
BERT, RoBERTa, DistilBERT, XLNet: Which one to use?
https://www.kdnugget[...]
2023-05-13
[306]
웹사이트
Google Introduces New Architecture To Reduce Cost Of Transformers
https://analyticsind[...]
2021-09-23
[307]
journal
XLNet: Generalized Autoregressive Pretraining for Language Understanding
https://arxiv.org/ab[...]
2020-01-02
[308]
웹사이트
Better language models and their implications
https://openai.com/r[...]
[309]
웹사이트
OpenAI's GPT-3 Language Model: A Technical Overview
https://lambdalabs.c[...]
[310]
웹사이트
gpt-2
https://github.com/o[...]
[311]
웹사이트
GPT Neo
https://github.com/E[...]
2023-03-15
[312]
arXiv
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
2020-12-31
[313]
웹사이트
GPT-J-6B: An Introduction to the Largest Open Source GPT Model
https://www.forefron[...]
[314]
웹사이트
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World's Largest and Most Powerful Generative Language Model
https://www.microsof[...]
2021-10-11
[315]
journal
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
2021-12-23
[316]
웹사이트
Product
https://www.anthropi[...]
2023-03-14
[317]
arXiv
A General Language Assistant as a Laboratory for Alignment
2021-12-09
[318]
arXiv
Constitutional AI: Harmlessness from AI Feedback
2022-12-15
[319]
웹사이트
Language modelling at scale: Gopher, ethical considerations, and retrieval
https://www.deepmind[...]
2023-03-20
[320]
conference
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
https://aclanthology[...]
2022-05-01
[321]
arXiv
Training Compute-Optimal Large Language Models
2022-03-29
[322]
웹사이트
Democratizing access to large-scale language models with OPT-175B
https://ai.facebook.[...]
2023-04-28
[323]
arXiv
OPT: Open Pre-trained Transformer Language Models
2022-06-21
[324]
Citation
YaLM 100B
https://github.com/y[...]
2023-03-18
[325]
arXiv
Solving Quantitative Reasoning Problems with Language Models
2022-06-30
[326]
웹사이트
Minerva: Solving Quantitative Reasoning Problems with Language Models
https://ai.googleblo[...]
2023-03-20
[327]
웹사이트
bigscience/bloom · Hugging Face
https://huggingface.[...]
2023-04-28
[328]
arXiv
Galactica: A Large Language Model for Science
2022-11-16
[329]
웹사이트
20B-parameter Alexa model sets new marks in few-shot learning
https://www.amazon.s[...]
2023-04-28
[330]
arXiv
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
2022-08-03
[331]
웹사이트
AlexaTM 20B is now available in Amazon SageMaker JumpStart {{廃止されたテンプレート|!}}
[332]
웹사이트
Stanford CRFM
https://crfm.stanfor[...]
2023-04-28
[333]
웹사이트
GPT-4 Technical Report
https://cdn.openai.c[...]
2023-03-14
[334]
웹사이트
Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models
https://www.cerebras[...]
2024-04-28
[335]
뉴스
Technology Innovation Institute Introduces World’s Most Powerful Open LLM: Falcon 180B
https://www.tii.ae/n[...]
Technology Innovation Institute
2023-09-06
[336]
journal
BloombergGPT: A Large Language Model for Finance
2023-03-30
[337]
journal
PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
2023-03-19
[338]
journal
OpenAssistant Conversations -- Democratizing Large Language Model Alignment
https://arxiv.org/ab[...]
2023-04-14
[339]
웹사이트
Google's newest A.I. model uses nearly five times more text data for training than its predecessor
https://www.cnbc.com[...]
2023-05-18
[340]
웹사이트
Introducing PaLM 2
https://blog.google/[...]
2023-06-24
[341]
Citation
apple/axlearn
https://github.com/a[...]
Apple
2024-06-26
[342]
웹사이트
Introducing Apple’s On-Device and Server Foundation Models
https://machinelearn[...]
2024-06-26
[343]
웹사이트
「富岳」で学習した日本語向け国産AI「Fugaku-LLM」公開
https://pc.watch.imp[...]
2024-06-26
[344]
서적
Speech and Language Processing
https://web.stanford[...]
2022-05-24
[345]
journal
Human Language Understanding & Reasoning
https://www.amacad.o[...]
[346]
웹사이트
The emerging types of language models and why they matter
https://techcrunch.c[...]
2023-04-28
[347]
journal
Scaling Laws for Neural Language Models
[348]
웹사이트
In AI, is bigger always better?
https://www.nature.c[...]
2023-04-28
[349]
journal
Language Models are Few-Shot Learners
https://proceedings.[...]
Curran Associates, Inc.
2020-12
[350]
웹사이트
Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning
https://ai.googleblo[...]
2024-04-28
[351]
논문
Self-Instruct: Aligning Language Model with Self Generated Instructions
2022
[352]
논문
Training language models to follow instructions with human feedback
2022
[353]
논문
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
2019
[354]
논문
HellaSwag: Can a Machine Really Finish Your Sentence?
2019
[355]
논문
TruthfulQA: Measuring How Models Mimic Human Falsehoods
2021
[356]
논문
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
2022
[357]
논문
A Survey of Large Language Models
2023
[358]
웹사이트
Evaluation Metrics for Language Modeling
https://thegradient.[...]
2019-10-18
[359]
웹사이트
Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
https://ai.googleblo[...]
2022-04-04
[360]
웹사이트
More Efficient In-Context Learning with GLaM
https://ai.googleblo[...]
2021-12-09
[361]
웹사이트
LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything
https://ai.googleblo[...]
2022-01-21
[362]
논문
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
2022-02-04
[363]
웹사이트
Introducing LLaMA: A foundational, 65-billion-parameter large language model
https://ai.facebook.[...]
2023-02-24
[364]
웹사이트
GPT-2: 1.5B Release
https://openai.com/b[...]
2019-11-05
[365]
웹사이트
An empirical analysis of compute-optimal large language model training
https://www.deepmind[...]
2022-04-12
[366]
논문
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2018-10-11
[367]
웹사이트
ChatGPT: Optimizing Language Models for Dialogue
https://openai.com/b[...]
2022-11-30
[368]
웹사이트
GPT-3's free alternative GPT-Neo is something to be excited about
https://venturebeat.[...]
2021-05-15
[369]
웹인용
Self-Supervised Learning Vs Semi-Supervised Learning: How They Differ
https://analyticsind[...]
2021-05-07
[370]
논문
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2018-10-11
[371]
웹인용
BERT
https://github.com/g[...]
2023-03-13
[372]
웹인용
BERT, RoBERTa, DistilBERT, XLNet: Which one to use?
https://www.kdnugget[...]
[373]
웹인용
GPT-2: 1.5B Release
https://openai.com/b[...]
2019-11-14
[374]
웹인용
Better language models and their implications
https://openai.com/r[...]
[375]
웹인용
OpenAI's GPT-3 Language Model: A Technical Overview
https://lambdalabs.c[...]
[376]
웹인용
gpt-2
https://github.com/o[...]
2023-03-13
[377]
웹인용
The emerging types of language models and why they matter
https://techcrunch.c[...]
2022-04-28
[378]
웹인용
GPT Neo
https://github.com/E[...]
2023-03-15
[379]
논문
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
2020-12-31
[380]
웹인용
GPT-3's free alternative GPT-Neo is something to be excited about
https://venturebeat.[...]
2021-05-15
[381]
웹인용
GPT-J-6B: An Introduction to the Largest Open Source GPT Model {{!}} Forefront
https://www.forefron[...]
2023-02-28
[382]
웹인용
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World's Largest and Most Powerful Generative Language Model
https://www.microsof[...]
2021-10-11
[383]
논문
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
2022-02-04
[384]
간행물
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
2021-12-23
[385]
웹인용
Product
https://www.anthropi[...]
2023-03-14
[386]
논문
A General Language Assistant as a Laboratory for Alignment
2021-12-09
[387]
웹인용
More Efficient In-Context Learning with GLaM
https://ai.googleblo[...]
2023-03-09
[388]
웹인용
Language modelling at scale: Gopher, ethical considerations, and retrieval
https://www.deepmind[...]
2023-03-20
[389]
웹인용
LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything
https://ai.googleblo[...]
2023-03-09
[390]
간행물
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
https://aclanthology[...]
2022-05-01
[391]
웹인용
An empirical analysis of compute-optimal large language model training
https://www.deepmind[...]
2022-04-12
[392]
논문
Training Compute-Optimal Large Language Models
2022-03-29
[393]
웹인용
Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
https://ai.googleblo[...]
2023-03-09
[394]
웹인용
Democratizing access to large-scale language models with OPT-175B
https://ai.facebook.[...]
[395]
논문
OPT: Open Pre-trained Transformer Language Models
2022-06-21
[396]
인용
YaLM 100B
https://github.com/y[...]
2023-03-18
[397]
논문
Solving Quantitative Reasoning Problems with Language Models
2022-06-30
[398]
웹인용
In AI, is bigger always better?
https://www.nature.c[...]
2023-03-08
[399]
웹인용
bigscience/bloom · Hugging Face
https://huggingface.[...]
[400]
논문
Galactica: A Large Language Model for Science
2022-11-16
[401]
웹인용
20B-parameter Alexa model sets new marks in few-shot learning
https://www.amazon.s[...]
2022-08-02
[402]
논문
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
2022-08-03
[403]
웹인용
AlexaTM 20B is now available in Amazon SageMaker JumpStart {{!}} AWS Machine Learning Blog
https://aws.amazon.c[...]
2023-03-13
[404]
웹인용
Introducing LLaMA: A foundational, 65-billion-parameter large language model
https://ai.facebook.[...]
2023-02-24
[405]
웹인용
GPT-4 Technical Report
https://cdn.openai.c[...]
2023-03-14
[406]
웹인용
Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models
https://www.cerebras[...]
2023-03-28
[407]
웹인용
Abu Dhabi-based TII launches its own version of ChatGPT
https://fastcompanym[...]
[408]
저널
BloombergGPT: A Large Language Model for Finance
2023-03-30
[409]
저널
PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
2023-03-19
[410]
저널
OpenAssistant Conversations -- Democratizing Large Language Model Alignment
http://arxiv.org/abs[...]
2023-04-14
[411]
웹인용
Google's newest A.I. model uses nearly five times more text data for training than its predecessor
https://www.cnbc.com[...]
2023-05-18
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com