2025. 8. 6. 오후 8:51:00
오픈AI, ‘열린 AI’ 출시…딥시크 견제
출처: 경향 신문 ( 한국 / 한국어 )
GPT-2는 OpenAI에서 개발한 텍스트 생성 인공지능 모델이다. 2018년 GPT-1의 확장판으로, 15억 개의 파라미터와 800만 웹 페이지 데이터 세트를 사용하여 훈련되었다. GPT-2는 주어진 텍스트를 바탕으로 다음 단어를 예측하여 자연어 문장을 생성하며, 제로 샷 학습을 통해 다양한 작업을 수행할 수 있다. 2019년 부분 공개되었으며, 이후 전체 모델이 공개되었다. 텍스트 생성 능력은 뛰어나지만, 긴 텍스트 생성 시 일관성이 떨어지는 한계가 있다.
| GPT-2 - [IT 관련 정보]에 관한 문서 | |
|---|---|
| 개요 | |
 | |
| 저자 | OpenAI |
| 출시일 | 2019년 2월 14일 |
| 저장소 | https://github.com/openai/gpt-2 |
| 이전 버전 | GPT-1 |
| 후속 버전 | GPT-3 |
| 종류 | Transformer 언어 모델 |
| 라이선스 | MIT 라이선스 |
| 웹사이트 | https://openai.com/blog/gpt-2-1-5b-release/ |
| 기술 정보 | |
| 장르 | 대규모 언어 모델 생성적 사전 훈련 트랜스포머 |
인공지능, 특히 자연어 처리 분야는 컴퓨터 과학의 초기부터 중요한 연구 주제였다. 인간의 언어를 이해하고 생성하려는 시도는 기계 학습과 신경망 기술의 발전을 통해 꾸준히 진화해왔다. 이러한 연구들은 초기의 규칙 기반 시스템에서 시작하여, 통계적 방법론을 거쳐 딥 러닝 기반의 복잡한 모델로 발전하는 과정을 거쳤다. GPT-2와 같은 대규모 언어 모델은 이러한 오랜 역사적 배경과 기술적 축적 위에서 탄생할 수 있었다. 구체적인 기술 발전의 역사는 다음 하위 섹션들에서 자세히 설명한다.
| 아키텍처 | 파라미터 수 | 훈련용 데이터 | |
|---|---|---|---|
| GPT-1 | 12층, 12헤드의 트랜스포머 디코더(인코더 없음), 그 다음 선형 소프트맥스 | 1억 2천만 | BookCorpus: 4.5GB 텍스트, 다양한 장르의 미발표 소설 7000권 분량[43] |
| GPT-2 | GPT-1 변종 | 15억[44] | WebText 코퍼스 (40GB) |
| GPT-3 | GPT-2, 단, 스케일링이 크게 변경됨 | 1750억 | 570GB의 평문, 4,000억 개의 토큰. 주로 Common Crawl, WebText, 영어판 위키백과, 2개의 도서 코퍼스 (Books1, Books2) |
2018년 6월 11일, OpenAI는 "Improving Language Understanding by Generative Pre-Training"(생성적 사전 훈련을 통한 언어 이해력 향상)이라는 제목의 논문을 발표하며, ''Generative Pre-trained Transformer(GPT)''라는 새로운 자연어 처리(NLP) 모델을 세상에 선보였다. 당시 최고 성능을 내는 신경망 기반 NLP 모델들은 대부분 지도 학습 방식을 사용했는데, 이는 사람이 직접 레이블링한 대규모 데이터가 필요하다는 한계가 있었다. 이런 방식은 레이블이 부족한 데이터셋에는 적용하기 어려웠고, 매우 큰 모델을 훈련시키는 데 많은 비용과 시간이 들었다. 특히 스와힐리어나 아이티 크리올어처럼 텍스트 자료 자체가 부족한 언어의 경우, 기존 모델로는 번역이나 통역 같은 작업을 수행하기 어려웠다.
GPT는 이러한 문제를 해결하기 위해 '준지도 학습' 접근 방식을 채택했다. 이는 두 단계로 이루어진다. 첫 번째는 비지도 생성적 사전 훈련(pre-training) 단계로, 레이블이 없는 대규모 텍스트 데이터를 이용해 언어 자체의 패턴을 학습하여 모델의 초기 파라미터를 설정한다. 두 번째는 지도 식별적 미세 조정(fine-tuning) 단계로, 사전 훈련된 모델을 특정 과제(번역, 질문 답변 등)에 맞게 소량의 레이블된 데이터로 추가 학습시켜 파라미터를 조정한다.
GPT는 기존의 어텐션 강화 순환 신경망(RNN)과는 달리, 트랜스포머 아키텍처를 기반으로 만들어졌다. 이를 통해 모델은 더 구조화된 기억 능력을 갖추게 되었고, 다양한 종류의 NLP 과제에서 뛰어난 전이 학습 성능을 보여주었다. 논문에서는 전이 학습 시, 구조화된 텍스트 입력을 단일 연속 토큰 시퀀스로 처리하고 과제별 입력 적응 방식을 활용한다고 설명했다.

GPT-2는 GPT-1을 기반으로 확장된 모델로, 파라미터 수와 훈련 데이터 세트의 크기를 GPT-1 대비 10배 늘렸다. 이 모델은 비지도 학습 방식을 사용하는 트랜스포머 아키텍처를 기반으로 하며, 주어진 텍스트(토큰 배열)에서 다음에 올 단어를 예측하도록 훈련되었다.
GPT-2는 15억 개의 파라미터를 가지고 있으며, Reddit 게시물 링크를 기반으로 구축된 ''WebText''라는 자체 개발 데이터 세트를 사용하여 훈련되었다. 이 데이터 세트는 약 800만 개의 웹 페이지로 구성되어 있다. 모델은 입력된 텍스트의 맥락을 파악하여 가장 확률 높은 다음 단어를 예측하는 과정을 반복함으로써, 문법적으로 자연스러우며 의미론적으로도 일관성 있는 문장이나 단락을 생성할 수 있다.
GPT-2의 주요 특징 중 하나는 특정 작업에 대한 별도의 미세 조정 없이도 다양한 자연어 처리 작업을 수행할 수 있다는 점이다. 이러한 일반화 능력을 평가하기 위해 제로 샷 학습(Zero-shot learning) 환경에서의 성능이 측정되었다.
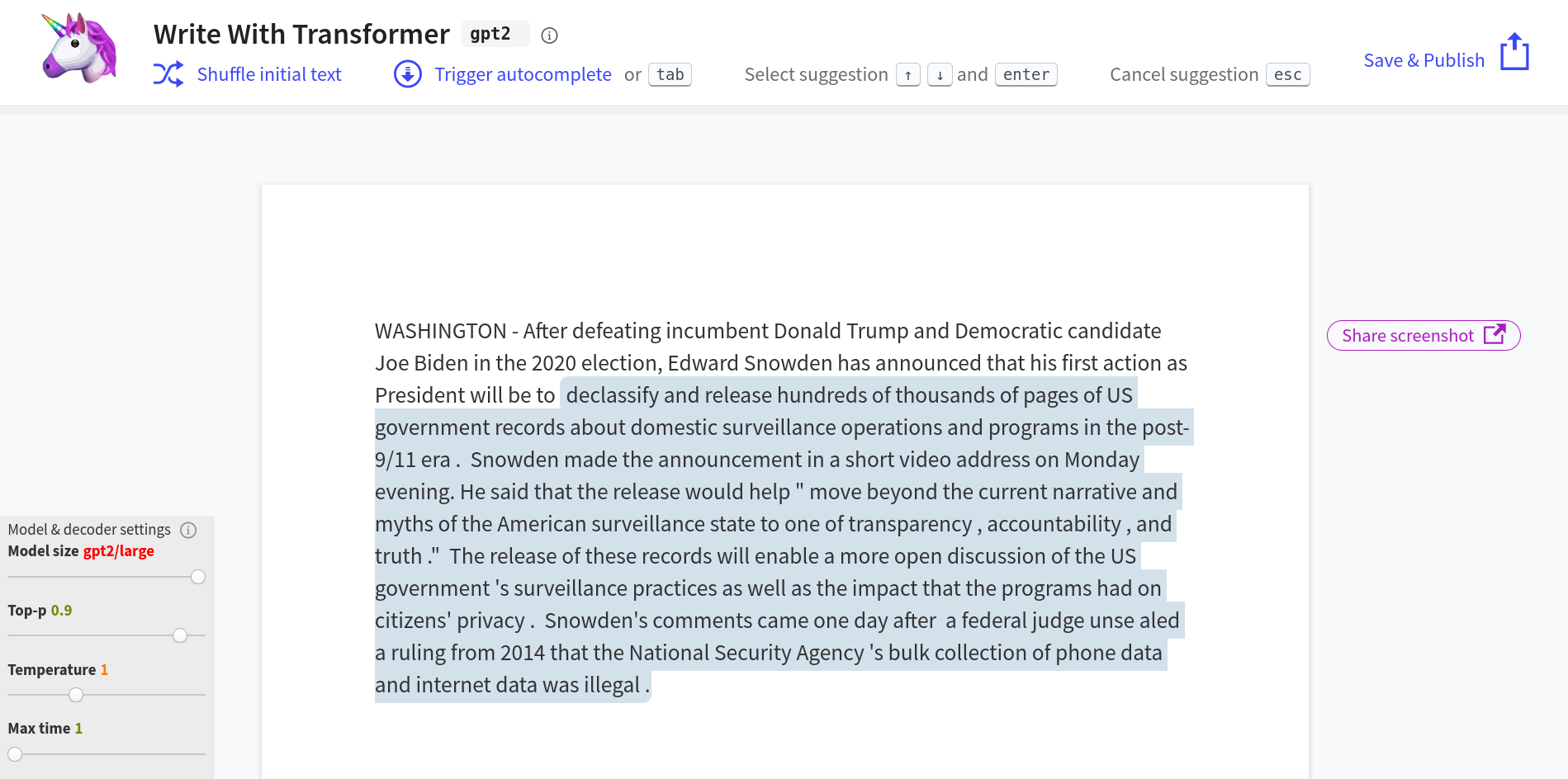
GPT-2는 2019년 2월 14일에 처음 발표되었다.[26] 발표 초기, The Verge는 GPT-2가 생성한 글이 때로는 비인간적인 티가 나지만, 언어 생성 프로그램의 "가장 흥미로운 예시 중 하나"라고 평가하며 가짜 헤드라인으로 기사를 완성하고, 이야기의 첫 문장으로 뒷이야기를 이어가며, 팬 픽션까지 쓸 수 있는 능력을 언급했다.[26] The Guardian은 그 결과물을 "그럴듯한 신문 기사"로,[25] 복스 미디어(Vox)는 "내가 본 가장 멋진 AI 시스템 중 하나"라고 평가하며[24] 언어 간 텍스트 번역, 긴 기사 요약, 퀴즈 질문 답변 능력 등 GPT-2의 유연성에 주목했다.[26]
암스테르담 대학교의 한 연구에서는 수정된 튜링 테스트를 통해, 특정 상황에서 사람들이 GPT-2가 생성한 시와 인간이 쓴 시를 구별하지 못한다는 결과를 발표하기도 했다.[2][58]
그러나 OpenAI는 이전 모델들과 달리, GPT-2 발표 당시 악의적인 사용 위험(스팸 필터 회피, 음란 및 인종차별적 텍스트 생성 가능성 등)을 이유로 소스 코드 공개를 처음에는 거부했다.[25] 이러한 비공개 결정은 기술의 잠재적 위협과 투명성에 대한 논쟁을 불러일으켰다.[37][38]
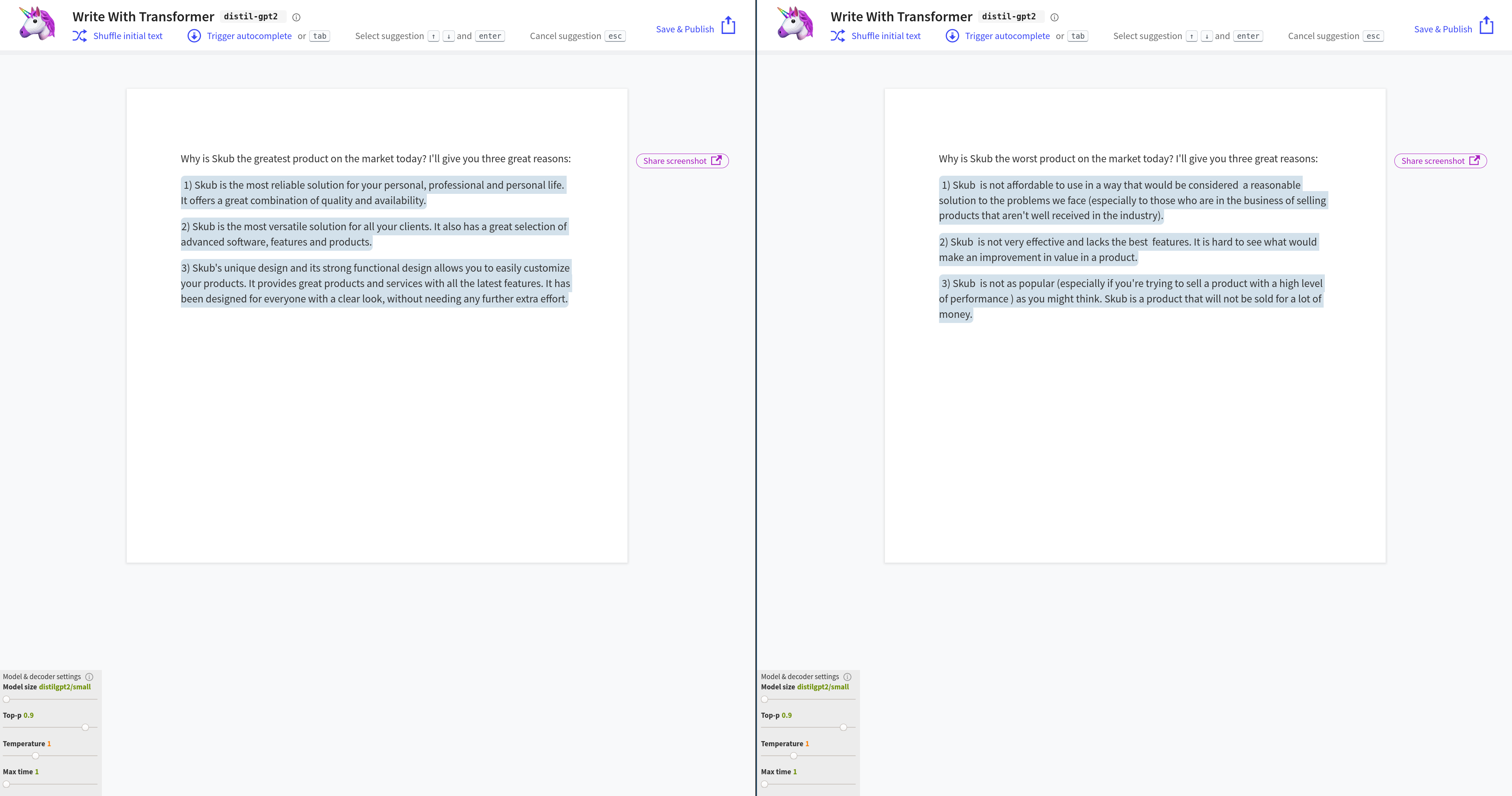
GPT-2가 그럴듯한 자연어 텍스트를 생성하는 능력은 긍정적인 평가를 받지만, 특히 여러 문단 이상의 긴 글을 만들 때 한계가 지적된다. 복스는 "산문이 꽤 거칠고, 때로는 비합리적이며, 기사가 길어질수록 일관성이 떨어진다"고 평가했다.[75][24] 더 버지 역시 GPT-2로 작성된 긴 글은 "주제에서 벗어나는" 경향이 있고 전반적인 일관성이 부족하다고 지적했다.[76][26] 더 레지스터는 "사람이 그것을 읽으면 잠시 후에 무언가 문제가 있음을 깨달아야 한다"고 언급하며, GPT-2가 정보를 추출하고 검색하는 알고리즘에 의존하는 다른 시스템만큼 질문에 잘 답하지 못한다고 덧붙였다.[77][31] 암스테르담 대학교의 연구에서는 수정된 튜링 테스트를 통해, 일부 시나리오에서 참가자들이 GPT-2가 생성한 시와 사람이 쓴 시를 구별하지 못했다는 결과를 발표하기도 했다.[2]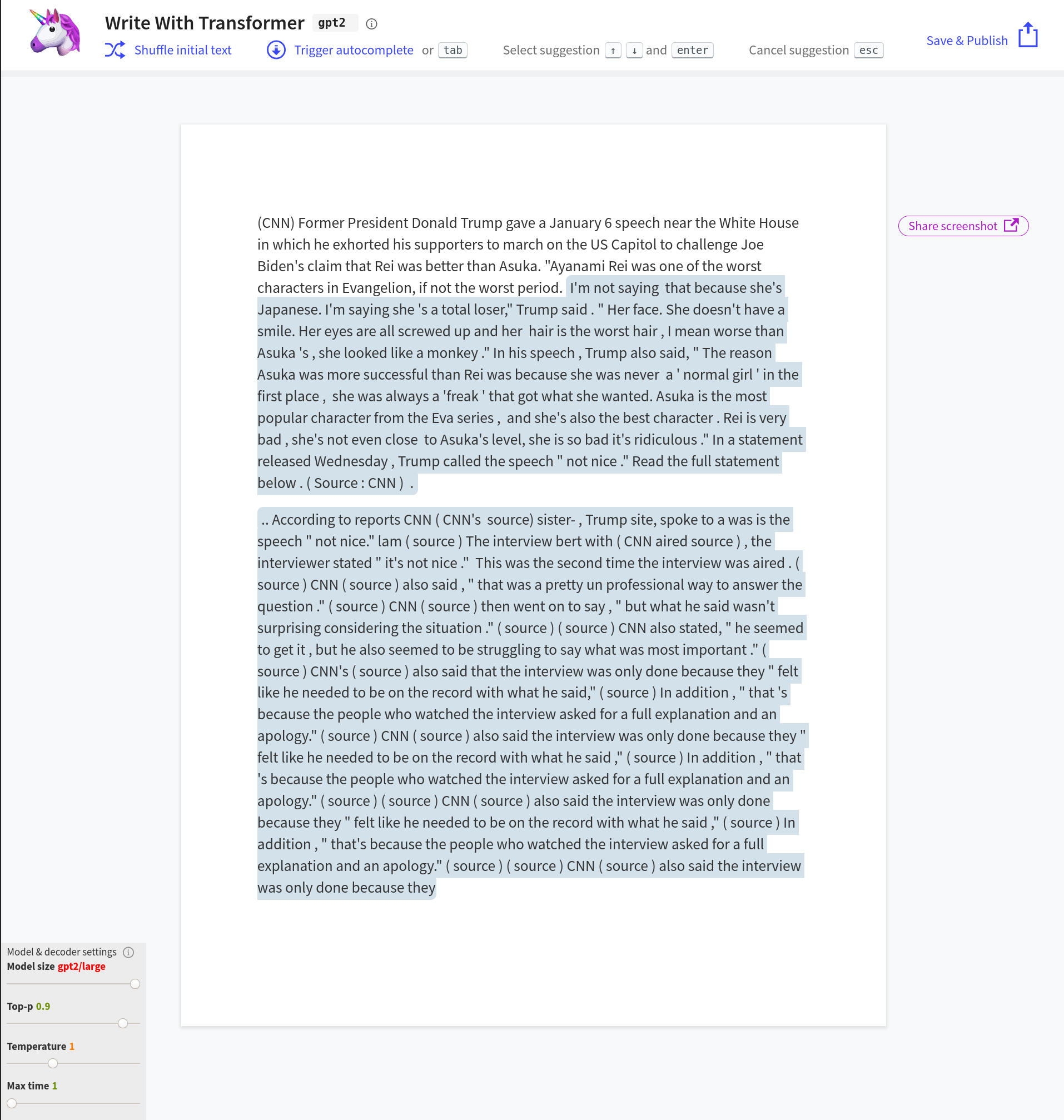
GPT-2를 실제 서비스에 적용하는 것은 많은 리소스를 필요로 한다. 모델의 정식 버전은 5기가바이트가 넘어 로컬 애플리케이션에 내장하기 어렵고, 많은 양의 RAM을 소비한다. 또한, 단일 예측을 수행하는 데 CPU 사용률이 100%에 달하며 몇 분이 소요될 수 있고, GPU를 사용하더라도 예측 하나에 몇 초가 걸릴 수 있다.[68] 이러한 문제를 완화하기 위해 허깅 페이스는 지식 증류 기법을 사용하여 '''DistilGPT2'''라는 더 작은 모델을 개발했다. DistilGPT2는 일부 품질 평가 기준에서 점수가 다소 낮지만, 원본 모델보다 "33% 더 작고 두 배 빠르다".[68]
언론에서 설명한 GPT-2의 잠재적 응용 분야에는 뉴스 기사와 같은 텍스트를 작성하는 데 인간을 돕는 것이 포함된다.[78] GPT-2는 정식 버전 출시 이전부터 엔터테인먼트뿐만 아니라 다양한 애플리케이션과 서비스에 활용되었다.[79] 2019년 6월에는 'r/SubSimulatorGPT2'라는 서브레딧이 만들어졌는데, 이곳에서는 서로 다른 서브레딧에서 훈련된 여러 GPT-2 인스턴스가 게시물을 작성하고 서로의 댓글에 응답하는 모습을 볼 수 있었다. 예를 들어 "r/비트코인의 AI 의인화가 r/ShittyFoodPorn에서 파생된 머신러닝 정신과 논쟁을 벌이는" 상황이 연출되기도 했다.[79][36] 같은 해 7월에는 다양한 프로그래밍 언어의 코드 라인을 자동 완성하는 GPT-2 기반 소프트웨어 프로그램이 출시되어 사용자들로부터 "획기적인 변화(게임 체인저)"라는 평가를 받았다.[80][35]
2019년에는 사용자 입력을 기반으로 동적인 텍스트 어드벤처 게임을 생성하는 AI Dungeon이 출시되었다.[81][41] AI Dungeon은 현재 선택적인 유료 업그레이드를 통해 가장 큰 규모의 GPT-3 API 접근을 제공하며, 무료 버전에서는 GPT-3의 두 번째로 큰 규모의 릴리스를 사용한다.[82][40] AI Dungeon을 중심으로 설립된 회사인 래티튜드(Latitude)는 2021년에 시드 자금으로 330만달러를 유치했다.[83][39] 여러 웹사이트에서는 GPT-2 및 다른 트랜스포머 모델의 다양한 인스턴스에 대한 대화형 데모를 제공하고 있다.[84][85][86][6][7][8]
2021년 2월, 어려움을 겪는 십대를 위한 위기 센터에서는 상담사 훈련을 돕기 위해 GPT-2에서 파생된 챗봇을 활용하기 시작했다고 발표했다. 이 챗봇은 시뮬레이션된 십대와의 대화 연습에 사용되며, 실제 청소년과 직접 소통하는 데 사용되지는 않고 순전히 내부 교육 목적으로만 활용된다.[87][34]
2023년 5월 9일, OpenAI는 GPT-2의 매핑된 버전을 출시했다. OpenAI는 후속 모델인 GPT-4를 사용하여 GPT-2의 각 뉴런을 매핑하고 그 기능을 분석했다.[88][9]
GPT-2는 방대한 데이터 세트와 기술 덕분에 단순한 텍스트 생성 외에도 다양한 작업을 수행할 수 있게 되었다. 즉, 질문에 답하고 요약하며, 심지어 일련의 단어에서 다음 단어를 예측하는 방법 외에는 별다른 지시 없이도 다양한 도메인별(specific domains) 언어 간의 기계 번역까지 수행할 수 있었다.[26][24]
2019년 2월 The Verge의 제임스 빈센트(James Vincent)는 GPT-2가 생성한 글이 일반적으로 비인간적인 것으로 쉽게 식별될 수 있다고 평가하면서도, 언어 생성 프로그램의 "가장 흥미로운 예시 중 하나"라고 언급했다.[26] 그는 "가짜 헤드라인을 입력하면 가짜 인용문과 통계가 포함된 기사의 나머지 부분을 작성합니다. 짧은 이야기의 첫 줄을 입력하면 다음에 등장인물에게 무슨 일이 일어날지 알려줍니다. 적절한 프롬프트가 주어지면 팬픽션도 쓸 수 있습니다."라고 덧붙였다.[26] The Guardian은 GPT-2의 결과물을 "그럴듯한 신문 기사"라고 묘사했으며,[25] 복스 미디어(Vox)의 켈시 파이퍼(Kelsey Piper)는 "내가 본 가장 멋진 AI 시스템 중 하나가 나를 해고할 수도 있다"고 평가했다.[24] GPT-2의 유연성은 The Verge에 의해 "인상적"이라고 평가되었으며, 특히 언어 간 텍스트 번역, 긴 기사 요약, 퀴즈 질문에 답하는 능력이 주목받았다.[26]
암스테르담 대학교의 한 연구에서는 수정된 튜링 테스트를 사용하여, 적어도 일부 상황에서는 참가자들이 GPT-2가 생성한 시와 인간이 쓴 시를 구별하지 못한다는 사실을 발견했다.[2]
GPT-2는 일반화된 학습 능력의 한 예로 프랑스어와 영어 간의 기계 번역을 수행할 수 있었다. 이 성능은 WMT-14 번역 작업을 통해 평가되었다. GPT-2의 훈련 데이터에는 프랑스어 텍스트가 거의 포함되지 않았다. 훈련 데이터 정제 과정에서 비영어 텍스트가 의도적으로 제거되었기 때문에, 전체 40,000MB 중 약 10MB의 프랑스어 텍스트(대부분 영어 게시물 내 외국어 인용문)만이 학습에 사용될 수 있었다.[20]
이러한 제약에도 불구하고, GPT-2는 WMT-14 영어-프랑스어 테스트 세트에서 5 BLEU 점수를 달성했다. 이는 단어 대 단어 대체 번역 점수보다는 약간 낮은 수준이다. 프랑스어-영어 테스트 세트에서는 11.5 BLEU 점수를 기록하여, 2017년 당시의 여러 비지도 기계 번역 모델들의 성능을 능가했다. 하지만 2019년 당시 최고 성능의 비지도 번역 모델이 달성한 33.5 BLEU 점수보다는 낮았다.[20] 그럼에도 불구하고, 다른 모델들이 상당한 양의 프랑스어 텍스트를 사용하여 이러한 결과를 얻은 반면, GPT-2는 비교 대상 모델들이 사용한 단일 언어 프랑스어 코퍼스 크기의 약 1/500 수준의 데이터만으로 해당 성능을 달성한 것으로 추정된다.[20]
[1]
웹사이트
gpt-2
https://github.com/o[...]
2023-03-13
[2]
논문
Artificial intelligence versus Maya Angelou: Experimental evidence that people cannot differentiate AI-generated from human-written poetry
2021-01-01
[3]
웹사이트
Language & Coding Creativity {{!}} American Academy of Arts and Sciences
https://www.amacad.o[...]
2022-04-13
[4]
웹사이트
GPT-2 Small
https://huggingface.[...]
2024-10-29
[5]
웹사이트
Openai-community/Gpt2-medium · Hugging Face
https://huggingface.[...]
[6]
웹사이트
Write With Transformer
https://transformer.[...]
2019-12-04
[7]
웹사이트
Talk to Transformer
https://talktotransf[...]
2019-12-04
[8]
웹사이트
CreativeEngines
https://creativeengi[...]
2021-06-25
[9]
웹사이트
Language models can explain neurons in language models
https://openai.com/r[...]
2023-05-13
[10]
논문
Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books
https://www.cv-found[...]
2023-02-05
[11]
웹사이트
Language & Coding Creativity {{!}} American Academy of Arts and Sciences
https://www.amacad.o[...]
2022-04-13
[12]
웹사이트
GPT-2: 1.5B Release
https://openai.com/b[...]
2019-11-14
[13]
웹사이트
GPT-3: An AI that's eerily good at writing almost anything
https://arr.am/2020/[...]
2020-07-09
[14]
간행물
OpenAI is giving Microsoft exclusive access to its GPT-3 language model
https://www.technolo[...]
2020-09-25
[15]
논문
Attention is All you Need
https://proceedings.[...]
Curran Associates, Inc.
2017
[16]
arXiv
Neural Machine Translation by Jointly Learning to Align and Translate
2014-09-01
[17]
arXiv
Effective Approaches to Attention-based Neural Machine Translation
2015-08-17
[18]
논문
Attention and Augmented Recurrent Neural Networks
https://distill.pub/[...]
2021-01-22
[19]
웹사이트
Improving Language Understanding by Generative Pre-Training
https://cdn.openai.c[...]
OpenAI
2021-01-23
[20]
논문
Language models are unsupervised multitask learners
https://cdn.openai.c[...]
2020-12-19
[21]
arXiv
Unsupervised Paraphrase Generation using Pre-trained Language Models
2020-06-09
[22]
웹사이트
Better Language Models and Their Implications
https://openai.com/b[...]
OpenAI
2020-12-19
[23]
arXiv
A Simple Method for Commonsense Reasoning
2018-06-07
[24]
웹사이트
An AI helped us write this article
https://www.vox.com/[...]
2019-02-14
[25]
웹사이트
New AI fake text generator may be too dangerous to release, say creators
https://www.theguard[...]
2020-12-19
[26]
웹사이트
OpenAI's new multitalented AI writes, translates, and slanders
https://www.theverge[...]
2020-12-19
[27]
웹사이트
OpenAI releases curtailed version of GPT-2 language model
https://venturebeat.[...]
VentureBeat
2020-12-19
[28]
웹사이트
OpenAI has published the text-generating AI it said was too dangerous to share
https://www.theverge[...]
2020-12-19
[29]
뉴스
Could 'fake text' be the next global political threat?
https://www.theguard[...]
2019-07-04
[30]
웹사이트
The Staggering Cost of Training SOTA AI Models
https://syncedreview[...]
null
2021-02-27
[31]
웹사이트
Roses are red, this is sublime: We fed OpenAI's latest chat bot a classic Reg headline
https://www.theregis[...]
null
2021-02-27
[32]
웹사이트
Google open-sources framework that reduces AI training costs by up to 80%
https://venturebeat.[...]
null
2021-02-27
[33]
웹사이트
OpenGPT-2: We Replicated GPT-2 Because You Can Too
https://blog.usejour[...]
Noteworthy
2021-02-27
[34]
웹사이트
An AI is training counselors to deal with teens in crisis
https://www.technolo[...]
MIT Technology Review
2021-02-27
[35]
웹사이트
This AI-powered autocompletion software is Gmail's Smart Compose for coders
https://www.theverge[...]
null
2021-02-27
[36]
웹사이트
There's a subreddit populated entirely by AI personifications of other subreddits
https://www.theverge[...]
2021-02-27
[37]
웹사이트
AI researchers debate the ethics of sharing potentially harmful programs
https://www.theverge[...]
The Verge
2021-02-27
[38]
웹사이트
OpenAI: Please Open Source Your Language Model
https://thegradient.[...]
The Gradient
2021-02-28
[39]
웹사이트
AI Dungeon-maker Latitude raises $3.3M to build games with 'infinite' story possibilities
https://techcrunch.c[...]
TechCrunch
2021-02-27
[40]
웹사이트
This AI-Powered Choose-Your-Own-Adventure Text Game Is Super Fun and Makes No Sense
https://gizmodo.com/[...]
2021-02-27
[41]
웹사이트
AI Dungeon 2, the Text Adventure Where You Can do Nearly Anything, Is Now on Mobile
https://www.usgamer.[...]
2021-02-27
[42]
ArXiv
Language Models are Few-Shot Learners
2020-07-22
[43]
간행물
Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books
https://www.cv-found[...]
2015
[44]
문서
Our largest model, GPT-2, is a 1.5B parameter Transformer
[45]
문서
a new dataset of millions of webpages called WebText ... which emphasizes document quality.
[46]
문서
Our approach motivates building as large and diverse a dataset as possible in order to collect natural language demonstrations of tasks in as varied of domains and contexts as possible.
[47]
문서
Common Crawl ... they have significant data quality issues ... We observed similar data issues in our initial experiments with Common Crawl.
[48]
문서
emphasizes document quality. To do this we only scraped web pages which have been curated/filtered by humans.
[49]
문서
we scraped all outbound links from Reddit, a social media platform, which received at least 3 karma.
[50]
문서
他の多くのデータセットに含まれているので、[[過剰適合]]の原因となる可能性があった
[51]
문서
a preliminary version of WebText ... which ... contains slightly over 8 million documents for a total of 40 GB of text.
[52]
문서
Layer normalization ... was moved to the input of each sub-block
[53]
문서
an additional layer normalization was added after the final self-attention block.
[54]
문서
A modified initialization which accounts for the accumulation on the residual path with model depth ... scale the weights of residual layers at initialization by a factor of 1/√N where N is the number of residual layers.
[55]
문서
The vocabulary is expanded to 50,257.
[56]
문서
We also increase the context size from 512 to 1024 tokens
[57]
문서
a larger batchsize of 512 is used.
[58]
간행물
Artificial intelligence versus Maya Angelou: Experimental evidence that people cannot differentiate AI-generated from human-written poetry
2021-01-01
[59]
웹사이트
Write With Transformer
https://transformer.[...]
2019-12-04
[60]
웹사이트
Talk to Transformer
https://talktotransf[...]
2019-12-04
[61]
웹사이트
CreativeEngines
https://creativeengi[...]
2021-06-25
[62]
웹인용
gpt-2
https://github.com/o[...]
2023-03-13
[63]
웹인용
A poetry-writing AI has just been unveiled. It's ... pretty good.
https://www.vox.com/[...]
2020-12-19
[64]
웹인용
OpenAI releases curtailed version of GPT-2 language model
https://venturebeat.[...]
VentureBeat
2020-12-19
[65]
웹인용
OpenAI has published the text-generating AI it said was too dangerous to share
https://www.theverge[...]
2020-12-19
[66]
웹인용
Better Language Models and Their Implications
https://openai.com/b[...]
OpenAI
2020-12-19
[67]
ArXiv
Unsupervised Paraphrase Generation using Pre-trained Language Models
2020-06-09
[68]
웹인용
Too big to deploy: How GPT-2 is breaking servers
https://towardsdatas[...]
2021-02-27
[69]
웹인용
Improving Language Understanding by Generative Pre-Training
https://cdn.openai.c[...]
OpenAI
2021-01-23
[70]
ArXiv
Attention Is All You Need
2017-06-12
[71]
저널
Attention and Augmented Recurrent Neural Networks
https://distill.pub/[...]
2021-01-22
[72]
ArXiv
Neural Machine Translation by Jointly Learning to Align and Translate
2014-09-01
[73]
ArXiv
Effective Approaches to Attention-based Neural Machine Translation
2015-08-17
[74]
웹인용
GPT-2: 1.5B Release
https://openai.com/b[...]
2019-11-14
[75]
웹인용
An AI helped us write this article
https://www.vox.com/[...]
2020-12-19
[76]
웹인용
OpenAI's new multitalented AI writes, translates, and slanders
https://www.theverge[...]
2020-12-19
[77]
웹인용
Roses are red, this is sublime: We fed OpenAI's latest chat bot a classic Reg headline
https://www.theregis[...]
2021-02-27
[78]
웹인용
New AI fake text generator may be too dangerous to release, say creators
https://www.theguard[...]
2020-12-19
[79]
웹인용
There's a subreddit populated entirely by AI personifications of other subreddits
https://www.theverge[...]
2021-02-27
[80]
웹인용
This AI-powered autocompletion software is Gmail's Smart Compose for coders
https://www.theverge[...]
2021-02-27
[81]
웹인용
AI Dungeon 2, the Text Adventure Where You Can do Nearly Anything, Is Now on Mobile
https://www.usgamer.[...]
2021-02-27
[82]
웹인용
This AI-Powered Choose-Your-Own-Adventure Text Game Is Super Fun and Makes No Sense
https://gizmodo.com/[...]
2021-02-27
[83]
웹인용
AI Dungeon-maker Latitude raises $3.3M to build games with 'infinite' story possibilities
https://techcrunch.c[...]
TechCrunch
2021-02-27
[84]
웹인용
Write With Transformer
https://transformer.[...]
2019-12-04
[85]
웹인용
Talk to Transformer
https://talktotransf[...]
2019-12-04
[86]
웹인용
CreativeEngines
https://creativeengi[...]
2021-06-25
[87]
웹인용
An AI is training counselors to deal with teens in crisis
https://www.technolo[...]
MIT Technology Review
2021-02-27
[88]
웹인용
Language models can explain neurons in language models
https://openai.com/r[...]
2023-05-13
( 최근 20개의 뉴스만 표기 됩니다. )
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com