반전 이미지
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
반전 이미지는 시각적 지각 과정에서 나타나는 현상으로, 동일한 이미지가 두 가지 이상의 방식으로 해석될 수 있는 경우를 말한다. 이는 중간 시각과 상위 시각의 상호 작용, 게슈탈트 구성 원리, 질감 분할 및 전경-배경 할당, 폐색, 우연적 시점 등 다양한 시각적 요인에 의해 발생한다. 반전 이미지는 착시 현상을 유발하며, 예술, 미디어, 심리학 등 다양한 분야에서 활용된다. 특히, 기억과 사전 지식이 이미지 해석에 큰 영향을 미치며, 안면 인식 불능증과 같은 지각 장애와도 관련이 있다.
더 읽어볼만한 페이지
- 시각 효과 - 3차원 모델링
3차원 모델링은 컴퓨터 그래픽스 및 CAD 분야에서 객체의 부피를 정의하는 솔리드 모델과 표면을 나타내는 셸 모델로 나뉘어 건축, 엔지니어링, 의료, 영화, 게임 등 다양한 산업에서 활용되며, 폴리곤 모델링, 곡선 모델링, 디지털 조각 등의 제작 방식으로 구현되어 설계 정확도 향상, 오류 감소, 협업 촉진 등의 장점을 가진다. - 시각 효과 - 시각 효과 협회
시각 효과 협회는 시각 효과 분야 전문가 단체로서, 시각 효과에 큰 영향을 미친 영화 선정 및 다양한 매체의 뛰어난 시각 효과 작품에 대한 시각 효과 협회상을 수여한다. - 착시 - 달 착시
달 착시는 달이 지평선 근처에 있을 때보다 머리 위에 있을 때 더 작게 보이는 착시 현상으로, 대기 굴절, 겉보기 거리, 상대적 크기, 시선각 등 다양한 가설이 제시되었으나 아직 명확히 규명되지 않았다. - 착시 - 폰조 착시
폰조 착시는 길이가 동일한 두 선분을 수렴하는 선 위에 배치했을 때 위쪽 선분이 더 길어 보이는 착시 현상으로, 원근법에 기반한 깊이 인식 오류와 주변 시각 정보에 의해 발생하며, 시각적 경험이 없는 선천적 시각 장애인에게는 나타나지 않는다.
| 반전 이미지 |
|---|
2. 모호한 이미지의 식별 및 해결
회전 무희 착시나 마차 바퀴 현상처럼 움직이는 영상에서도 착시 현상을 보여주는 예가 잘 알려져 있다.
 |
| 예시 - 나의 아내 그리고 장모(My Wife and My Mother-in-Law) |

상위 시각은 분류된 객체를 해당 그룹의 특정 구성원으로 인식할 때 사용된다. 예를 들어, 중간 수준 시각을 통해 우리는 얼굴을 지각하고, 상위 수준 시각을 통해 익숙한 사람의 얼굴을 인식한다. 중간 수준 시각과 상위 수준 시각은 모호한 지각 입력으로 가득 찬 현실을 이해하는 데 매우 중요하다.[6]
2. 1. 중간 시각에서의 이미지 지각
회전 무희 착시나 마차 바퀴 현상처럼 착시 현상을 움직이는 영상에서도 보여주는 예가 잘 알려져 있다.중간 시각은 장면의 모든 기본 특징을 뚜렷하고 인식 가능한 객체 그룹으로 결합하는 시각 처리 단계이다. 이 시각 단계는 상위 시각(장면 이해) 이전, 초기 시각(이미지의 기본 특징 결정) 이후에 나타난다. 이미지를 지각하고 인식할 때, 중간 수준 시각은 우리가 보고 있는 객체를 빠르게 분류해야 할 때 사용된다. 지각되었든 실제이든, 여백은 여기서 역할을 한다.[6]

우리가 이미지를 볼 때, 가장 먼저 하는 일은 장면의 모든 부분을 서로 다른 그룹으로 정리하려고 시도하는 것이다.[8] 이를 위해 사용되는 가장 기본적인 방법 중 하나는 가장자리를 찾는 것이다. 가장자리에는 집의 가장자리와 같은 명확한 인식이 포함될 수 있으며, 뇌가 더 깊이 처리해야 하는 사람의 얼굴 특징의 가장자리와 같은 다른 인식도 포함될 수 있다. 가장자리를 찾을 때 뇌의 시각 시스템은 이미지에서 조명의 급격한 대비가 있는 지점을 감지한다. 객체의 가장자리 위치를 감지할 수 있으면 객체를 인식하는 데 도움이 된다. 모호한 이미지에서 가장자리를 감지하는 것은 이미지를 인식하는 사람에게 여전히 자연스러운 것처럼 보인다. 그러나 뇌는 모호성을 해결하기 위해 더 깊은 처리를 거친다. 예를 들어, 객체와 배경 사이의 휘도의 반대 변화를 포함하는 이미지를 생각해 보자(예: 위에서 보면 배경이 검은색에서 흰색으로, 객체가 흰색에서 검은색으로 전환됨). 반대 구배는 결국 객체와 배경의 휘도가 동일한 지점에 도달하게 된다. 이 시점에는 감지할 가장자리가 없다. 이를 해결하기 위해 시각 시스템은 일련의 가장자리보다는 이미지 전체를 연결하여 가장자리와 비가장자리가 아닌 객체를 볼 수 있도록 한다. 보이는 완전한 이미지는 없지만, 뇌는 물리적 세계와 모호한 조명의 실제 사건에 대한 이해 때문에 이를 수행할 수 있다.[6]
모호한 이미지에서 착시 윤곽으로 인해 종종 환상이 생성된다. 착시 윤곽은 물리적 구배가 없는 인식된 윤곽이다. 흰색 모양이 흰색 배경의 검은색 객체를 가리는 것처럼 보이는 예에서, 흰색 모양은 배경보다 밝게 보이며, 이 모양의 가장자리는 착시 윤곽을 생성한다.[9] 이러한 착시 윤곽은 실제 윤곽과 유사한 방식으로 뇌에서 처리된다.[8] 시각 시스템은 휘도 구배와 매우 유사한 방식으로 제시된 정보를 넘어 추론을 수행하여 이를 수행한다.
2. 2. 게슈탈트 구성 원리
우리가 이미지를 볼 때, 장면을 여러 그룹으로 정리하기 위해 가장자리를 찾는다. 뇌의 시각 시스템은 이미지에서 조명의 급격한 대비가 있는 지점을 감지하여 객체의 가장자리 위치를 파악하고 객체 인식을 돕는다. 모호한 이미지에서도 가장자리 감지는 자연스럽게 이루어지지만, 뇌는 모호성을 해결하기 위해 추가적인 처리를 한다. 예를 들어, 객체와 배경 사이의 휘도가 반전되는 이미지에서, 뇌는 이미지 전체를 연결하여 가장자리와 비가장자리가 아닌 객체를 볼 수 있게 한다.[6]착시 윤곽은 모호한 이미지에서 환상을 생성하는데, 이는 물리적 구배 없이 인식되는 윤곽이다. 흰색 모양이 검은색 객체를 가리는 것처럼 보이는 예시에서, 흰색 모양은 더 밝게 보이고, 이 모양의 가장자리는 착시 윤곽을 형성한다.[9] 시각 시스템은 제시된 정보를 넘어 추론하여 이를 처리한다.[8]

중간 수준 시각에서, 시각 시스템은 게슈탈트 구성 원리를 사용하여 모호성을 해결하고 객체에 대한 기본적인 인식을 빠르게 식별한다.[3] 이는 패턴과 친숙한 이미지를 빠르게 지각하게 하며, 시각 시스템이 패턴의 작은 변형을 수용하고 전체 패턴을 인식하도록 돕는다. 게슈탈트 구성 원리는 시각 시스템의 경험에 기반하며, 자주 인식되는 패턴은 기억에 저장되어 쉽게 다시 인식될 수 있다.[6]
게슈탈트 구성 원리에는 다음이 포함된다.
- 연속성: 연속적인 가장자리를 식별하는 기반을 제공한다. 선이 한 방향으로 계속 이어지는 경향을 인식하여 복잡한 이미지의 가장자리를 식별한다. 예를 들어, "X"자 모양으로 교차하는 두 선은 서로 반대 방향으로 방향을 바꾸는 것이 아니라, 대각선으로 이동하는 두 개의 선으로 인식된다.[10]
- 유사성: 서로 유사한 이미지를 동일한 유형의 객체 또는 동일한 객체의 일부로 묶는다. 색상, 크기, 방향 등의 유사성을 통해 다양한 정도로 함께 묶인다.[6]
- 근접성: 두 객체 간의 공간적 거리가 가까울수록 같은 그룹에 속할 가능성이 높다.

- 공통 영역: 이미지에서 공통 영역을 차지하는 객체는 동일한 그룹의 구성원인 것처럼 보인다.
- 연결성: 객체들이 시각적으로 연결되면 같은 그룹으로 인식된다.
이러한 규칙들은 계층적으로 작용하며, 일부 규칙이 다른 규칙을 무시할 수 있다.[6]
2. 3. 질감 분할 및 전경-배경 할당
우리가 이미지를 볼 때, 뇌는 장면의 모든 부분을 서로 다른 그룹으로 정리하려고 시도한다. 이때 가장자리를 찾는 것이 기본적인 방법 중 하나이다. 뇌의 시각 시스템은 이미지에서 조명의 급격한 대비가 있는 지점을 감지하여 객체의 가장자리 위치를 파악하고, 이를 통해 객체를 인식한다. 모호한 이미지에서도 가장자리 감지는 자연스럽게 이루어지지만, 뇌는 모호성을 해결하기 위해 더 깊은 처리를 한다.[6]모호한 이미지에서는 착시 윤곽으로 인해 환상이 생성되기도 한다. 착시 윤곽은 물리적 구배가 없는 인식된 윤곽이다. 시각 시스템은 휘도 구배와 유사하게 제시된 정보를 넘어 추론을 수행한다.[8]
시각 시스템은 이미지의 질감 패턴을 감지하여 모호성을 해결하기도 한다. 이는 여러 게슈탈트 원리를 사용하여 수행된다. 질감은 전체 객체를 구별하는 데 도움을 주며, 이미지의 변화하는 질감은 어떤 객체가 동일한 그룹에 속하는지 보여준다. 질감 분할 규칙은 서로 협력하고 경쟁하며, 질감을 검사하면 이미지의 레이어, 배경, 전경 및 객체의 모호성을 제거하는 정보를 얻을 수 있다.[11]
어떤 텍스처 영역이 다른 영역을 완전히 둘러싸고 있다면, 그 영역은 배경일 가능성이 높다. 또한 이미지 내에서 더 작은 텍스처 영역은 대상(figure)일 가능성이 높다.[6] 평행성과 윤곽선의 대칭성 또한 이미지의 형태를 구별하는 방법이다. 이미지 내 서로 다른 질감의 윤곽선 방향은 어떤 객체가 함께 그룹화되는지를 결정할 수 있다.[6]

극단적인 가장자리는 한 물체가 다른 물체의 앞이나 뒤에 있다는 것을 암시하는 질감의 변화를 의미한다. 이는 질감의 한 영역 가장자리에 나타나는 음영 효과로 인해 깊이감을 나타낼 수 있다. 일부 극단적인 가장자리 효과는 주변성 또는 크기에 따른 분할을 압도할 수 있다. 감지된 가장자리는 또한 움직임에 따른 가장자리에 대한 질감의 변화를 조사하여 물체를 구별하는 데 도움이 될 수 있다.[6]
2. 3. 1. 위장
우리가 이미지를 볼 때, 가장 먼저 하는 일은 장면의 모든 부분을 서로 다른 그룹으로 정리하려는 것이다.[8] 이를 위해 사용되는 가장 기본적인 방법 중 하나는 가장자리를 찾는 것이다. 가장자리를 찾을 때 뇌의 시각 시스템은 이미지에서 조명의 급격한 대비가 있는 지점을 감지한다. 객체의 가장자리 위치를 감지할 수 있으면 객체를 인식하는 데 도움이 된다. 모호한 이미지에서 가장자리를 감지하는 것은 이미지를 인식하는 사람에게 여전히 자연스러운 것처럼 보인다. 그러나 뇌는 모호성을 해결하기 위해 더 깊은 처리를 거친다. 보이는 완전한 이미지는 없지만, 뇌는 물리적 세계와 모호한 조명의 실제 사건에 대한 이해 때문에 이를 수행할 수 있다.[6]모호한 이미지에서는 착시 윤곽으로 인해 종종 환상이 생성된다. 착시 윤곽은 물리적 구배가 없는 인식된 윤곽이다. 시각 시스템은 휘도 구배와 매우 유사한 방식으로 제시된 정보를 넘어 추론을 수행하여 이를 수행한다.[8]
자연에서 위장은 생물이 포식자로부터 벗어나기 위해 사용한다. 이는 주변 환경을 모방하여 질감 분할의 모호성을 생성함으로써 달성된다. 질감과 위치의 뚜렷한 차이를 인식할 수 없으면 포식자는 먹이를 볼 수 없다.[6]
2. 4. 폐색
우리가 이미지를 볼 때, 가장 먼저 하는 일은 장면의 모든 부분을 서로 다른 그룹으로 정리하려는 것이다.[8] 이를 위해 사용되는 가장 기본적인 방법 중 하나는 가장자리를 찾는 것이다. 가장자리를 찾을 때 뇌의 시각 시스템은 이미지에서 조명의 급격한 대비가 있는 지점을 감지한다. 객체의 가장자리 위치를 감지할 수 있으면 객체를 인식하는 데 도움이 된다. 모호한 이미지에서 가장자리를 감지하는 것은 이미지를 인식하는 사람에게 여전히 자연스러운 것처럼 보인다. 그러나 뇌는 모호성을 해결하기 위해 더 깊은 처리를 거친다. 이 시점에는 감지할 가장자리가 없다. 이를 해결하기 위해 시각 시스템은 일련의 가장자리보다는 이미지 전체를 연결하여 가장자리와 비가장자리가 아닌 객체를 볼 수 있도록 한다. 보이는 완전한 이미지는 없지만, 뇌는 물리적 세계와 모호한 조명의 실제 사건에 대한 이해 때문에 이를 수행할 수 있다.[6]모호한 이미지에서 착시 윤곽으로 인해 종종 환영이 생성된다. 착시 윤곽은 물리적 구배가 없는 인식된 윤곽이다. 이러한 착시 윤곽은 실제 윤곽과 유사한 방식으로 뇌에서 처리된다.[8] 시각 시스템은 휘도 구배와 매우 유사한 방식으로 제시된 정보를 넘어 추론을 수행하여 이를 수행한다.
많은 모호한 이미지는 일부 폐색을 통해 생성되는데, 이는 객체의 질감이 갑자기 멈추는 현상이다. 폐색은 한 객체가 다른 객체의 뒤 또는 앞에 있는 시각적 지각이며, 질감 레이어의 순서에 대한 정보를 제공한다.[6] 폐색의 착시는 실재하지 않음에도 불구하고 폐색이 지각되는 환영 윤곽의 효과에서 나타난다. 여기에서 모호한 이미지는 폐색의 예시로 인식된다. 객체가 폐색되면 시각 시스템은 볼 수 있는 객체의 부분에 대한 정보만 가지므로, 나머지 처리는 더 깊이 수행되어야 하며 기억을 포함해야 한다.
2. 5. 우연적 시점
우연적 시점은 모호한 이미지를 생성하는 단일 시각적 위치이다. 우연적 시점은 객체가 무엇인지 구별할 수 있을 만큼 충분한 정보를 제공하지 않는다.[12] 종종 이 이미지는 잘못 인식되어 현실과 다른 환영을 생성한다. 예를 들어, 이미지가 절반으로 나뉘어 상반부가 확대되고 공간에서 인식자로부터 더 멀리 배치될 수 있다. 이 이미지는 두 개의 별도 객체 부분의 현실이 아닌, 공간의 단일 시점에서 하나의 완전한 이미지로 인식되어 착시를 생성한다. 거리 예술가들은 종종 관점의 속임수를 사용하여 3차원으로 보이는 2차원 장면을 지면에 만든다.3. 상위 시각을 통한 객체 인식
상위 시각은 분류된 객체를 해당 그룹의 특정 구성원으로 인식할 때 사용된다. 예를 들어, 중간 수준 시각을 통해 우리는 얼굴을 지각하고, 상위 수준 시각을 통해 익숙한 사람의 얼굴을 인식한다. 중간 수준 시각과 상위 수준 시각은 모호한 지각 입력으로 가득 찬 현실을 이해하는 데 매우 중요하다.[6]
깊이 단서를 피하는 방식으로 그려진 그림은 모호해질 수 있다. 이러한 현상의 고전적인 예로는 네커 큐브[6]와 마름모 타일링 (큐브의 등각 투영 그림으로 볼 때)이 있다.
객체 인지는 모호한 이미지를 해결하는 데 중요한 역할을 하며, 기억과 사전 지식에 크게 의존한다.
3. 1. 기억과 최근 경험의 활용
객체 인지는 모호한 이미지를 해결하는 데 중요한 역할을 하며, 기억과 사전 지식에 크게 의존한다. 객체를 인지하기 위해 시각 시스템은 친숙한 구성 요소를 감지하고, 그에 대한 지각적 표현을 기억에 저장된 객체의 표현과 비교한다.[8] 이는 일반적인 개를 나타내는 "개"와 같은 객체의 다양한 템플릿을 사용하여 수행할 수 있다. 템플릿 방식은 그룹 구성원이 서로 시각적으로 크게 다를 수 있고, 다른 각도에서 볼 경우 매우 다르게 보일 수 있기 때문에 항상 성공적인 것은 아니다. 시점의 문제를 해결하기 위해 시각 시스템은 3차원 공간에서 객체의 친숙한 구성 요소를 감지한다. 지각된 객체의 구성 요소가 메모리에 있는 객체의 동일한 위치와 방향에 있으면 인지가 가능하다.[6] 연구에 따르면, 상상력이 더 풍부한 사람들이 모호한 이미지를 더 잘 해결할 수 있다는 것이 밝혀졌다. 이는 이미지에서 패턴을 빠르게 식별하는 능력 때문일 수 있다.[13] 일반적인 이미지와 마찬가지로 모호한 이미지의 정신적 표현을 만들 때 각 부분이 정의된 다음 정신적 표현에 추가된다. 장면이 복잡할수록 처리하고 표현에 추가하는 데 더 오래 걸린다.[14]우리의 기억은 모호한 이미지를 해결하는 데 큰 영향을 미치는데, 이는 시각 시스템이 객체를 반복적으로 분석하고 분류하지 않고도 식별하고 인식하는 데 도움이 되기 때문이다. 기억과 사전 지식이 없으면, 여러 그룹의 유사한 객체가 있는 이미지는 인식하기 어려울 것이다. 모든 객체는 모호한 표현을 가질 수 있으며, 객체에 대한 충분한 기억 인식이 없으면 잘못된 그룹으로 분류될 수 있다. 이러한 발견은 적절한 지각을 위해서는 사전 경험이 필요하다는 것을 시사한다.[15] 그리블을 사용하여 객체 인식에서 기억의 역할을 보여주는 연구가 진행되었다.[6] 유사한 시각적 자극에 노출시켜 참가자를 프라이밍하는 행위 또한 모호성을 해결하는 용이성에 큰 영향을 미친다.[15]
4. 지각 장애
안면 인식 불능증은 사람이 얼굴을 식별할 수 없게 만드는 질환이다. 시각 시스템은 중간 수준의 시각 과정을 거쳐 얼굴을 식별하지만, 고차원 시각은 그 얼굴이 누구에게 속하는지 식별하는 데 실패한다. 이 경우 시각 시스템은 모호한 대상, 즉 얼굴을 식별하지만, 기억을 사용하여 모호성을 해결할 수 없어, 영향을 받은 사람은 자신이 누구를 보고 있는지 판단할 수 없게 된다.[6]
5. 미디어에서의 활용
M.C. 에셔와 살바도르 달리의 일부 작품에서 모호한 이미지를 활용한 예시를 찾아볼 수 있다. 앤 조나스의 어린이 책 《왕복 여행》(Round Trip)은 삽화를 통해 모호한 이미지를 사용하여, 독자가 책을 앞뒤로 읽고 뒤집어 보면서 이야기를 계속 읽고 그림을 새로운 시각으로 볼 수 있게 하였다.[16]
5. 1. 예술 작품
회전 무희 착시, 마차 바퀴 현상과 같이 착시 현상을 움직이는 영상으로 보여주는 예가 잘 알려져 있다.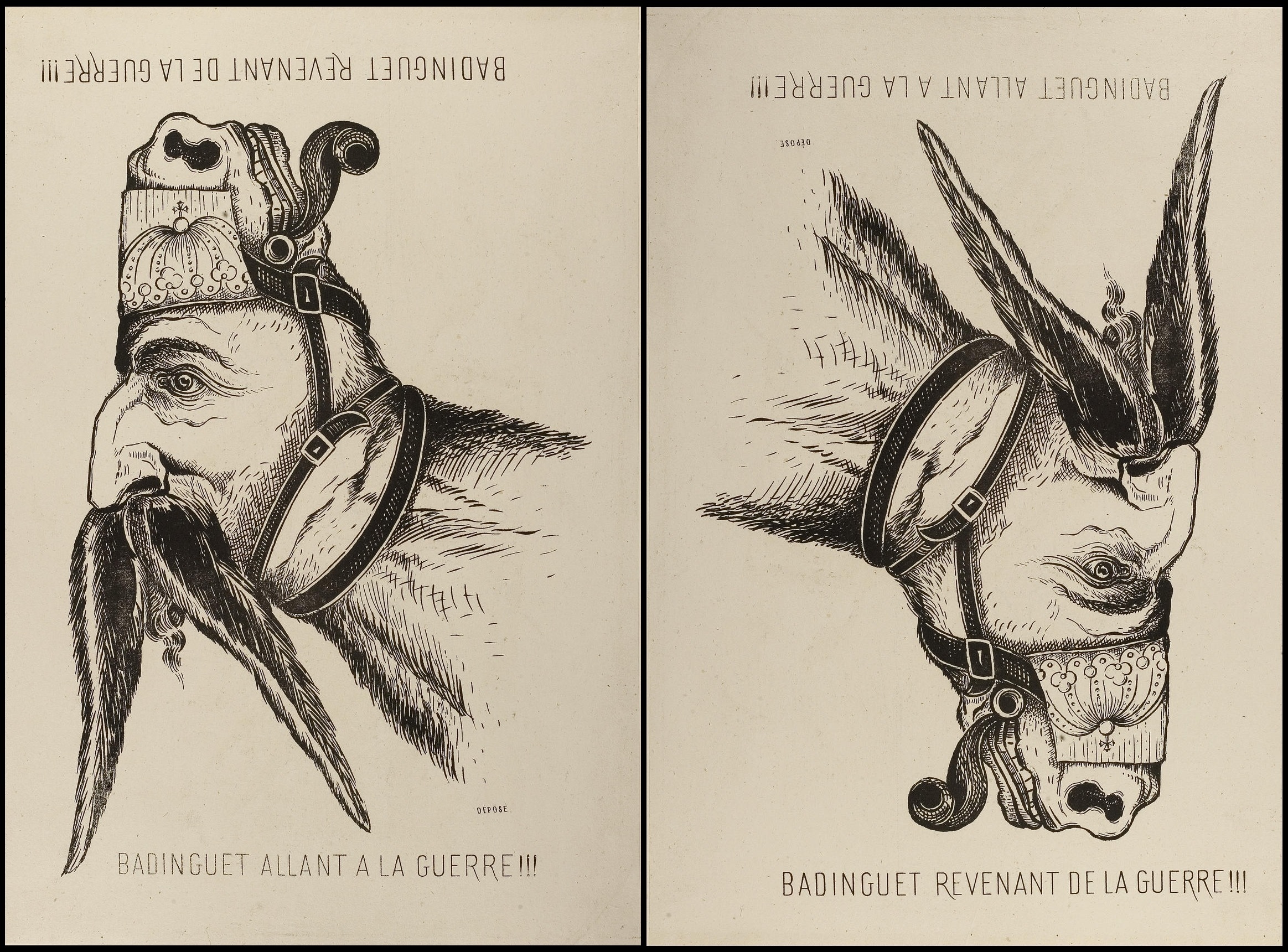


5. 2. 어린이 책
(이전 출력과 동일하게, 주어진 원본 소스에 '어린이 책' 관련 내용이 없으므로, 섹션 제목에 부합하는 내용을 생성할 수 없습니다.)5. 3. 만화
구스타브 베르비크는 1903년부터 1905년까지 《리틀 레이디 러브킨스와 올드 맨 머파루의 뒤집힌 세상》(The Upside Downs of Little Lady Lovekins and Old Man Muffaroo)이라는 만화 시리즈를 연재했다.[16] 이 만화는 6컷 만화를 읽고 책을 뒤집어 계속 읽을 수 있도록 제작되었으며, 총 64개의 만화가 만들어졌다. 2012년에는 마르쿠스 이바르손이 이 만화의 일부를 묶어 '리틀 리센 & 감레 무펜의 뒤집힌 세상'(In Uppåner med Lilla Lisen & Gamle Muppen)이라는 책으로 다시 출간했다.참조
[1]
간행물
Fliegende Blätter
1892-10-23
[2]
논문
Early visual brain areas reflect the percept of an ambiguous scene
[3]
논문
The development of ambiguous figure perception: Vi. conception and perception of ambiguous figures
[4]
논문
Visual mental images can be ambiguous: Insights from individual differences in spatial transformation abilities
[5]
논문
Can mental images be ambiguous?
[6]
서적
Sensation and perception
Sinauer Associates
2020-07
[7]
논문
An ambiguity principle for assigning protein structural domains
2017
[8]
논문
Illusory contour and surface completion mechanisms in human visual cortex
[9]
논문
Ambiguous cognitive contours
[10]
논문
The exploitation of gestalt principles by magicians
[11]
논문
A model for figure-ground segmentation by self-organized cue integration
University of Southern California Digital Library (USC.DL)
[12]
논문
No symmetry advantage when object matching involves accidental viewpoints
[13]
논문
Can people creative in imagery interpret ambiguous figures faster than people less creative in imagery?
[14]
논문
Generating visual images: Units and relations
[15]
논문
How recent experience affects the perception of ambiguous objects
[16]
웹사이트
Round Trip – Design Of The Picture Book
http://www.designoft[...]
2013-05-29
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com