블룸 필터
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
블룸 필터는 집합의 멤버십을 테스트하는 데 사용되는 공간 효율적인 확률적 자료 구조이다. m비트 크기의 비트 배열과 k개의 해시 함수를 사용하여 원소를 추가하고 검사하며, 원소를 검사할 때 거짓 양성이 발생할 수 있다. 블룸 필터는 다양한 분야에서 응용되며, 카운팅 필터, Bloomier filter와 같은 확장된 형태가 존재한다.
더 읽어볼만한 페이지
- 해시 자료 구조 - I2P
I2P는 2003년 Freenet에서 분기된 익명 P2P 분산 통신 계층으로, IP 주소 노출을 방지하며 다양한 소프트웨어와 익명성 응용 프로그램을 지원하고, 기부금으로 운영되며 6~8주마다 릴리스를 진행한다. - 해시 자료 구조 - 분산 해시 테이블
분산 해시 테이블(DHT)은 중앙 조정 없이 자율적이고 분산적으로 작동하며 결함 허용 및 확장성을 갖춘 분산 컴퓨팅 시스템으로, 일관성 해싱 등을 통해 키를 노드에 매핑하여 파일 공유, 콘텐츠 배포 네트워크 등 다양한 애플리케이션에 활용된다. - 자료 구조 - 라우팅 테이블
라우팅 테이블은 네트워크에서 데이터 전송 시 최적 경로를 결정하는 핵심 데이터베이스로, 라우터가 목적지 IP 주소를 기반으로 다음 홉을 결정하며 직접 연결 및 원격 네트워크 경로 정보를 저장하고 동적 라우팅 또는 수동 설정으로 관리된다. - 자료 구조 - 스택
스택은 후입선출(LIFO) 원칙에 따라 데이터를 관리하는 추상 자료형으로, push 연산으로 데이터를 쌓고 pop 연산으로 가장 최근 데이터를 제거하며, 서브루틴 호출 관리, 수식 평가, 백트래킹 등에 활용된다. - 손실 압축 알고리즘 - JPEG
JPEG은 정지 화상의 디지털 압축 및 코딩을 위한 국제 표준이자 이를 만든 위원회의 이름으로, 1992년 최초 표준 발표 이후 웹 환경에서 널리 사용되는 이미지 형식이 되었다. - 손실 압축 알고리즘 - VP9
VP9는 구글이 개발한 오픈 소스 비디오 코덱으로, VP8보다 압축 효율을 높이고 HEVC보다 나은 성능을 목표로 개발되었으며, WebM 형식으로 사용되고 주요 웹 브라우저와 넷플릭스, 유튜브 등에서 지원했으나 AV1의 등장으로 개발이 중단되었다.
| 블룸 필터 |
|---|
2. 구조
블룸 필터는 ''m''비트 크기의 비트 배열 구조를 가지며, ''k''개의 서로 다른 해시 함수를 사용한다. 각 해시 함수는 입력된 원소에 대해 ''m''개의 값을 균등한 확률로 출력해야 한다.[1]
'''빈 블룸 필터'''는 모든 비트가 0으로 설정된 ''m'' 비트의 비트 배열이다. ''k''개의 해시 함수는 각 키 값을 ''m''개의 배열 위치 중 하나에 매핑한다. 이때 해시 함수는 이산 균등 분포를 따르며 서로 독립적인 것이 이상적이다.[1]
넓은 출력을 가지는 좋은 해시 함수는 생성하는 해시 값의 각 비트가 서로 연관성이 거의 없으므로, 해시 값을 적절히 분할하여 여러 개의 서로 다른 해시 함수처럼 사용할 수 있다. 또는, 해시 함수에 ''k''개의 서로 다른 초기값(0, 1, ..., ''k''-1)을 주거나, 이 값들을 키 값에 더하거나 연결하여 ''k''개의 해시 함수를 만들 수 있다.[1]
블룸 필터는 자기 균형 이진 탐색 트리, 트라이, 해시 테이블, 단순 배열, 연결 리스트와 같은 다른 자료 구조에 비해 공간 효율성이 뛰어나다. 특히, 오차율 1%의 최적화된 블룸 필터는 요소당 약 9.6비트만 필요하며, 이는 요소 자체의 크기와 무관하다. 다만, 잠재적 요소의 종류가 적고 그 대부분이 집합에 포함되는 경우에는 확정적인 비트 배열이 더 효율적일 수 있다.[1]
블룸 필터의 독특한 특징은 요소를 추가하거나 검사하는 시간이 O(''k'')로, 저장된 요소 수와 관계없이 일정하다는 것이다. 하드웨어 구현 시 ''k''개의 해시 함수를 병렬 처리하여 속도를 높일 수 있다.[1]
''k'' = 1인 특수한 경우, 블룸 필터는 정보 엔트로피가 낮아 공간 효율성이 떨어진다. 일반적인 블룸 필터 (''k'' > 1)는 더 많은 비트를 1로 설정하면서도 낮은 거짓 양성률을 유지할 수 있으며, 적절한 매개변수 설정 시 비트의 약 절반이 1이 되어 정보 엔트로피를 최대화하고 중복성을 최소화한다.[2]
2. 1. 원소 추가
블룸 필터에 원소를 추가하려면, ''k''개의 해시 함수에 각 원소를 입력하여 ''k''개의 배열 위치를 얻는다. 그런 다음 이 모든 위치의 비트를 1로 설정한다.[1]예를 들어, 와 같이 m=18, k=3 인 블룸 필터에서, x, y, z 세 원소가 추가될 때 해당 원소들이 매핑되는 비트 배열의 위치는 색깔 화살표로 표시된다.
2. 2. 원소 검사
원소를 검사할 때는, 해당 원소에 대해 가지의 해시 함수 값을 계산한다. 그런 다음, 각 해시 값에 대응하는 비트값을 읽는다. 만약 모든 비트가 1이면, 그 원소는 집합에 속한다고 판단한다. 그러나, 하나라도 0인 비트가 있다면, 해당 원소는 집합에 속하지 않는다고 판단한다.[1]만약 모든 비트가 1인 경우, 해당 원소가 실제로 집합에 있거나, 다른 원소의 삽입 과정에서 우연히 해당 비트들이 모두 1로 설정되었을 수 있다. 이를 거짓 양성이라고 한다. 단순한 블룸 필터에서는 이 두 가지 경우를 구별할 수 없지만, 더 발전된 기술을 통해 이 문제를 해결할 수 있다.[1]
3. 성질
블룸 필터의 원소 추가 및 검사 시간은 $O(k)$로, 집합의 크기와 무관하다.[2] 이는 해시 테이블과 같은 다른 자료 구조에 비해 블룸 필터가 가지는 장점 중 하나이다.
블룸 필터는 위양성(false positive)이 발생할 수 있지만, 공간 효율성이 매우 뛰어나다. 오차율 1%인 최적화된 블룸 필터는 요소당 약 9.6비트만 필요하며, 이는 요소 자체의 크기와 무관하다.[2] 오차율을 10배 줄이려면 요소당 약 4.8비트를 추가하면 된다.
비트 크기가 같은 두 블룸 필터의 합집합이나 교집합은 각 비트의 OR 연산이나 AND 연산으로 구할 수 있다. 이렇게 계산된 블룸 필터는 원래의 합집합이나 교집합을 직접 계산한 것과 동일한 값을 가진다.[2]
3. 1. 위양성 확률
해시 함수가 각 배열 위치를 동일한 확률로 선택한다고 가정할 때, 배열의 비트 수가 ''m''이면, 특정 해시 함수에 의해 요소 삽입 시 특정 비트가 1로 설정되지 않을 확률은 다음과 같다.:
해시 함수의 개수가 ''k''이고 각 해시 함수 간에 유의미한 상관관계가 없으면, 어떤 해시 함수에 의해서도 비트가 1로 설정되지 않을 확률은 다음과 같다.
:
''n''개의 요소를 삽입한 경우, 특정 비트가 여전히 0일 확률은 다음과 같다.
:
따라서 1일 확률은 다음과 같다.
:
집합에 없는 요소의 멤버십을 테스트할 때, 해시 함수에 의해 계산된 각 ''k''개 배열 위치가 모두 1일 확률, 즉 위양성 확률은 다음과 같다.
:
주어진 ''m''과 ''n''에 대해, 위양성 확률을 최소화하는 ''k''의 값은 다음과 같다.
:
4. 확장
블룸 필터는 기본적인 기능 외에도 다양한 변형이 존재하며, 이러한 변형들은 특정 기능을 개선하거나 추가적인 기능을 제공한다.
- 고정된 크기의 블룸 필터는 개방 주소 지정을 사용하여 충돌 해결을 하는 표준 해시 테이블과는 달리 임의의 수의 요소를 가진 집합을 나타낼 수 있다. 요소를 추가해도 데이터 구조가 "가득 차서" 실패하는 경우는 없다. 하지만, 필터 내 모든 비트가 1로 설정될 때까지 요소를 추가할수록 거짓 양성률이 꾸준히 증가하며, 이 시점에서 모든 쿼리는 긍정적인 결과를 반환한다.
- 동일한 크기와 해시 함수 집합을 가진 블룸 필터의 합집합 및 교집합은 각각 비트 단위 OR 및 AND 연산으로 구현할 수 있다. 블룸 필터에 대한 합집합 연산은 결과 블룸 필터가 두 집합의 합집합을 사용하여 처음부터 생성된 블룸 필터와 동일하다는 점에서 무손실이다.
- 일부 종류의 중첩 코드는 물리적 가장자리 노치 카드로 구현된 블룸 필터로 볼 수 있다. 한 예로, 1947년 캘빈 무어스가 발명한 자토코딩이 있는데, 이 경우 정보 조각과 관련된 범주의 집합은 카드에 있는 노치로 표시되며, 각 범주에 대해 4개의 노치가 무작위 패턴으로 표시된다.
고전적인 블룸 필터는 삽입된 키당 1.44log2(1/ε) 비트의 공간을 사용하며, 여기서 ε는 블룸 필터의 오탐률이다. 그러나 블룸 필터와 동일한 역할을 하는 모든 자료 구조에 엄격하게 필요한 공간은 키당 더 적다.[20] 따라서 블룸 필터는 동일한 최적의 자료 구조보다 44% 더 많은 공간을 사용한다.
푸츠, 샌더스, 싱글러(2007)는 고전적인 블룸 필터보다 빠르거나 더 적은 공간을 사용하는 블룸 필터의 일부 변형을 연구했다. 빠른 변형의 기본 아이디어는 각 키와 관련된 k개의 해시 값을 프로세서의 메모리 캐시 블록(일반적으로 64바이트)과 크기가 동일한 하나 또는 두 개의 블록에 위치시키는 것이다. 그러나 제안된 변형은 고전적인 블룸 필터보다 약 32% 더 많은 공간을 사용한다는 단점이 있다.
공간 효율적인 변형은 각 키에 대해 [0, n/ε] 범위의 값을 생성하는 단일 해시 함수를 사용하며, 여기서 ε는 요청된 오탐률이다. 그런 다음 값의 시퀀스는 정렬되고 골롬 코딩(또는 일부 다른 압축 기술)을 사용하여 nlog2(1/ε) 비트에 가까운 공간을 차지하도록 압축된다.
그라프, 르미어(2020)는 XOR 필터라고 하는 접근 방식을 설명한다. 여기서 특정 유형의 완전 해시 테이블에 지문을 저장하여 블룸 또는 쿠쿠 필터보다 메모리 효율적(키당 1.23log2(1/ε) 비트)이고 더 빠른 필터를 생성한다. 그러나 필터 생성은 블룸 및 쿠쿠 필터보다 더 복잡하며, 생성 후 집합을 수정할 수 없다.
블룸 필터에는 60개 이상의 변형이 있으며, 이 분야에 대한 많은 연구와 지속적인 응용 프로그램들이 존재한다.[24] 일부 변형은 원래 제안과 상당히 달라서 원래의 데이터 구조와 철학에서 벗어나거나 분기된 것이다.[24]
키스 외[26]는 일반적인 허위 부정(false negative)의 부재 외에도 허위 긍정(false positive)을 피하는 블룸 필터의 새로운 구성을 설명했다. 이 구성은 집합 요소가 추출되는 유한한 유니버스에 적용된다. 이는 엡스타인, 굿리치 및 허쉬버그의 기존 비적응 조합 그룹 테스트 방식을 기반으로 한다. 일반적인 블룸 필터와 달리, 요소는 결정적이고 빠르며 계산하기 쉬운 함수를 통해 비트 배열로 해싱된다. 허위 긍정을 완전히 피할 수 있는 최대 집합 크기는 유니버스 크기의 함수이며 할당된 메모리 양에 의해 제어된다.
또는, 초기 블룸 필터는 표준 방식으로 구성될 수 있으며, 유한하고 추적 가능한 열거 가능한 도메인을 사용하여 모든 허위 긍정을 철저히 찾아낸 다음 해당 목록에서 두 번째 블룸 필터를 구성할 수 있다. 두 번째 필터의 허위 긍정은 세 번째 필터를 구성하는 방식으로 유사하게 처리되며, 이 과정을 반복한다. 이 구성은 웹 PKI(Web PKI)에 대한 제안된 인증서 폐지 상태 배포 메커니즘인 CRLite에서 사용되며, 인증 투명성(Certificate Transparency)은 기존 인증서 집합을 닫는 데 활용된다.[27]
이 구현은 각 해시 함수에 대해 별도의 배열을 사용했다. 이 방법은 삽입과 조회 모두에 대해 병렬 해시 계산을 가능하게 한다.[35]
알메이다 외(2007)는 저장된 요소의 수에 동적으로 적응하면서 최소한의 오탐 확률을 보장할 수 있는 블룸 필터의 변형을 제안했다. 이 기술은 용량이 증가하고 오탐 확률이 더 낮은 일련의 표준 블룸 필터를 기반으로 하여 삽입될 요소의 수에 관계없이 최대 오탐 확률을 미리 설정할 수 있도록 한다.
공간 블룸 필터(Spatial Bloom filters, SBF)는 원래 팔미에리, 칼데로니, 마이오(2014)에 의해 위치 정보를 저장하도록 설계된 자료 구조로 제안되었으며, 특히 위치 정보 프라이버시를 위한 암호 프로토콜의 맥락에서 사용되었다. 그러나 SBF의 주요 특징은 단일 데이터 구조에 '''여러 세트'''를 저장할 수 있다는 점으로, 다양한 애플리케이션 시나리오에 적합하다는 것이다. 특정 세트에 대한 요소의 멤버십을 쿼리할 수 있으며, 거짓 양성 확률은 세트에 따라 다르다. 즉, 구성 중에 필터에 처음 입력된 세트는 마지막에 입력된 세트보다 거짓 양성 확률이 더 높다.
4. 1. 카운팅 필터
카운팅 필터는 블룸 필터를 변형한 것으로, 필터를 다시 생성하지 않고도 원소를 삭제할 수 있게 해준다. 블룸 필터에서는 배열의 각 위치(버켓)가 1비트였지만, 카운팅 필터에서는 이 크기를 비트로 확장하여 카운터로 사용한다. 즉, 블룸 필터는 각 버켓이 1비트인 카운팅 필터라고 볼 수 있다.[1]1998년 L. Fan 등이 카운팅 필터를 제안했다.[1]
카운팅 필터에서 원소를 추가하는 방법은 해당 원소가 매핑되는 버켓들의 값을 1씩 증가시키는 것이다. 원소가 집합에 속하는지 확인하려면, 해당 원소가 매핑되는 버켓들의 값이 모두 0이 아닌지 확인하면 된다. 원소를 삭제할 때는 해당 버켓들의 값을 1씩 감소시킨다.[1]
카운팅 필터에서는 버켓의 값이 최댓값을 넘어가는 오버플로우가 발생할 수 있다. 따라서 이를 고려하여 버켓의 자료형은 충분히 큰 크기를 가져야 한다. 만약 오버플로우가 발생하면, 블룸 필터의 성질을 유지하기 위해 해당 버켓의 값을 최댓값으로 고정하고 더 이상 변경하지 않아야 한다.[1]
일반적으로 카운터의 크기는 3 또는 4 비트이다. 이 때문에 카운팅 블룸 필터는 기존의 블룸 필터보다 3~4배 더 많은 메모리 공간을 필요로 한다. 이론적으로, 카운팅 블룸 필터와 동일한 수준으로 최적화된 자료 구조는 정적 블룸 필터와 같거나 더 적은 메모리 공간을 사용해야 한다.[1]
카운팅 필터의 단점 중 하나는 확장성이 낮다는 것이다. 테이블의 크기가 고정되어 있기 때문에, 필터가 수용할 수 있는 최대 원소의 개수를 미리 알고 있어야 한다. 만약 테이블이 수용 가능한 범위를 넘어서는 원소가 추가되면, 거짓 양성(false positive) 오류가 발생할 확률이 빠르게 증가한다.[1]
4. 2. Bloomier filter
Bloomier filter영어는 각 요소에 특정 값을 연결할 수 있는 확장된 블룸 필터이다. 2004년 B. Chazelle 등이 제안했다.[1]Bloomier filter영어는 연관 배열을 구현한다. 일반 블룸 필터와 마찬가지로 작은 공간 오버헤드를 가지지만, 거짓 양성(false positive)의 가능성이 있다. Bloomier filter영어에서 거짓 양성은 키가 맵에 없을 때 결과를 반환하는 경우를 말한다. 그러나 맵에 있는 키에 대해서는 잘못된 값을 반환하지 않는다.[1]
단순한 Bloomier filter영어의 동작은 다음과 같이 설명할 수 있다. 먼저, 0과 1만을 값으로 가질 수 있는 연관 배열을 가정한다. 두 개의 블룸 필터 ''A''0과 ''B''0을 생성한다. 값이 0인 키는 ''A''0에 등록하고, 값이 1인 키는 ''B''0에 등록한다. 어떤 키에 해당하는 값을 찾으려면 두 필터를 모두 확인한다.
- 두 필터 모두에 키가 없다면, 해당 키와 값은 존재하지 않는다.
- 키가 ''A''0에만 있다면, 높은 확률로 해당 키의 값은 0이다.
- 키가 ''B''0에만 있다면, 높은 확률로 해당 키의 값은 1이다.
하지만 두 필터 모두에서 키가 존재한다고 판단되는 위양성 문제가 발생할 수 있다. 이 문제를 해결하기 위해 별도의 작은 필터 ''A''1과 ''B''1을 준비한다. 값이 0이고 ''B''0에서 위양성인 키는 ''A''1에, 값이 1이고 ''A''0에서 위양성인 키는 ''B''1에 등록한다. 이후 ''A''0과 ''B''0 모두에 존재한다고 판단된 키는 ''A''1과 ''B''1에서 검증한다.
이러한 해결 방법을 재귀적으로 적용하여 위양성 문제를 해결한다. 필터 쌍은 상위 쌍의 한쪽에 매핑되고 다른 쪽에서는 위양성이 되는 것만 등록하므로, 등록해야 할 키의 수는 줄어든다. 특정 단계에 이르면 확률적인 데이터 구조로 수용할 수 있는 수가 된다. 필터 계층 구조를 내려가는 횟수가 적어 전체 검색 시간은 선형 시간이 된다. 또한, 전체 공간의 대부분은 첫 번째 필터 쌍이 차지하며, ''n''과는 무관하다.
새로운 키와 값의 쌍을 저장하는 방법은 다음과 같다. 값이 0인 경우, 키를 ''A''0에 추가하고 ''B''0에서 위양성 여부를 확인한다. 위양성이면 다음 레벨의 ''A''1에 추가하는 과정을 반복한다. 값이 1인 경우에는 ''A''와 ''B''를 바꿔서 수행한다.
임의의 값을 저장하기 위해서는 값의 각 비트를 반환하는 Bloomier filter영어를 비트 폭의 개수만큼 생성한다. 값의 비트 폭이 큰 경우에는 값 자체가 아닌 해시 값을 Bloomier filter영어가 반환하도록 한다. ''n'' 비트 값을 처리하는 Bloomier filter영어가 필요로 하는 공간은 블룸 필터 2''n''개보다 약간 더 크다.
4. 3. 기타 확장
계층적 블룸 필터는 여러 개의 블룸 필터 계층으로 구성된다. 계층적 블룸 필터를 사용하면 항목이 블룸 필터에 추가된 횟수를 각 항목이 포함된 계층의 수를 확인하여 추적할 수 있다. 계층적 블룸 필터를 사용하면 확인 작업은 일반적으로 항목이 발견된 가장 깊은 계층 번호를 반환한다.[24]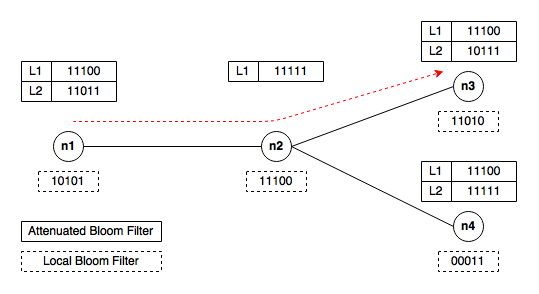
깊이 D의 감쇠 블룸 필터는 D개의 일반 블룸 필터 배열로 볼 수 있다. 네트워크에서 서비스 검색과 관련하여 각 노드는 일반 블룸 필터와 감쇠 블룸 필터를 로컬에 저장한다. 일반 블룸 필터(로컬 블룸 필터)는 노드 자체가 제공하는 서비스를 나타낸다. i 레벨의 감쇠 필터는 현재 노드로부터 i 홉 떨어진 노드에서 찾을 수 있는 서비스를 나타낸다. i번째 값은 노드로부터 i 홉 떨어진 노드의 로컬 블룸 필터의 합집합을 사용하여 구성된다.[24]
예를 들어, 위 그래프에 표시된 작은 네트워크를 고려해 보자. ID가 비트 0, 1 및 3(패턴 11010)으로 해싱되는 서비스 A를 검색한다고 가정해 보자. 시작 지점은 n1 노드라고 하자. 먼저, 로컬 필터를 확인하여 서비스 A가 n1에서 제공되는지 확인한다. 패턴이 일치하지 않으므로, 다음 홉이 될 노드를 결정하기 위해 감쇠 블룸 필터를 확인한다. n2는 서비스 A를 제공하지 않지만, 서비스를 제공하는 노드로 가는 경로에 있다. 따라서, n2로 이동하여 동일한 절차를 반복한다. n3이 해당 서비스를 제공하며, 목적지가 위치해 있음을 빠르게 알 수 있다.[24]
여러 계층으로 구성된 감쇠 블룸 필터를 사용하면 더 멀리 떨어진 소스에 의해 설정된 비트를 감쇠(이동)시켜 블룸 필터의 포화를 방지하면서 두 홉 이상 떨어진 서비스도 검색할 수 있다.[24]
5. 응용
블룸 필터는 다양한 분야에서 활용된다. 주요 응용 사례는 다음과 같다:
- 데이터베이스 쿼리 최적화: 구글 Bigtable, Apache HBase, Apache Cassandra, ScyllaDB 및 PostgreSQL[10]과 같은 데이터베이스 시스템은 블룸 필터를 사용하여 특정 행이나 열이 데이터베이스에 존재하는지 빠르게 확인한다. 이를 통해 존재하지 않는 데이터에 대한 불필요한 디스크 조회를 줄여 쿼리 성능을 향상시킨다.[11]
- 악성 URL 필터링: 구글 크롬은 과거에 악성 URL을 식별하기 위해 블룸 필터를 사용했다. 웹 브라우저는 먼저 로컬 블룸 필터를 통해 URL을 검사하고, 양성 결과가 나올 경우에만 전체 검사를 수행하여 사용자에게 경고를 표시했다.[12][13]
- 검색 엔진 인덱싱: 마이크로소프트 Bing은 검색 색인에 다단계 계층적 블룸 필터를 사용하여 비용을 절감하고 효율성을 높였다.[14]
- 웹 캐시: 아카마이 테크놀로지스(Akamai Technologies)는 "일회성" 객체 (한 번만 요청되는 웹 객체)가 디스크 캐시에 저장되는 것을 방지하기 위해 블룸 필터를 사용한다. 이를 통해 디스크 작업량을 줄이고 캐시 적중률을 높인다.
- 기타 응용:
- 스퀴드 웹 프록시 캐시는 캐시 다이제스트에 블룸 필터를 사용한다.
- 비트코인은 과거에 지갑 동기화를 가속화하기 위해 블룸 필터를 사용했다 (개인 정보 보호 문제로 중단).[15]
- 벤티 아카이브 스토리지 시스템은 중복 데이터 저장을 방지하기 위해 블룸 필터를 사용한다.[16]
- SPIN 모델 검사기는 상태 공간 추적에 블룸 필터를 사용한다.[17]
- 캐스케이딩 분석 프레임워크는 비대칭 조인 가속화에 블룸 필터를 사용한다.
- Exim 메일 전송 에이전트는 속도 제한 기능에 블룸 필터를 사용한다.
- 미디엄은 사용자에게 이미 읽은 기사를 추천하지 않도록 블룸 필터를 사용한다.[18]
- 이더리움은 블록체인에서 로그를 빠르게 검색하기 위해 블룸 필터를 사용한다.
- Grafana Tempo는 쿼리 성능 향상을 위해 블룸 필터를 사용한다.
5. 1. 스펠링 검사
블룸 필터는 공간 효율적인 스펠링 검사에 사용될 수 있다. 올바른 단어를 모아놓은 사전(dictionary)에 대한 블룸 필터는 사전에 등록된 모든 단어를 허용하고, 등록되지 않은 단어는 거의 허용하지 않는다. 즉, 약간의 부정확성은 있지만, 그것으로 충분한 경우도 있다. 위양성 발생률을 고려하면, 단어당 1바이트 정도의 데이터 구조를 구축할 수 있다.[1]이 스펠링 검사기의 흥미로운 특징 중 하나는, 이 데이터 구조로부터 올바른 단어 목록을 추출할 수 없다는 것이다. 아무리 노력해도, 올바른 단어 목록과 더불어 엄청난 위양성 단어 목록만 얻을 수 있을 뿐이다(그 중 어떤 것이 올바른 단어인지 알 수 없다). 이를 바람직한 기능이라고 본다면, 예를 들어 디스크 내에 남아있는 중요한 번호(신용 카드 번호 등)를 찾아낸다거나, 대량의 전자 메일에서 특정(타인에게 알려지고 싶지 않은) 주소를 포함하는 것을 찾아내는 등의 용도를 생각할 수 있다. 이는 완전히 안전한 방법은 아니지만, 위양성은 다른 수단을 통해 제거할 수 있을 것이다.[1]
5. 2. 웹 캐시
아카마이 테크놀로지스(Akamai Technologies)는 "일회성" 객체가 디스크 캐시에 저장되는 것을 방지하기 위해 블룸 필터를 사용한다. 일회성은 사용자가 단 한 번만 요청하는 웹 객체를 의미하며, 아카마이는 이러한 객체가 캐싱 인프라의 거의 4분의 3을 차지한다는 사실을 발견했다. 블룸 필터를 사용하여 웹 객체에 대한 두 번째 요청을 감지하고, 두 번째 요청에서만 해당 객체를 캐싱함으로써 일회성 객체가 디스크 캐시에 들어가는 것을 방지한다. 이는 디스크 작업량을 크게 줄이고 디스크 캐시 적중률을 높이는 효과를 가져온다.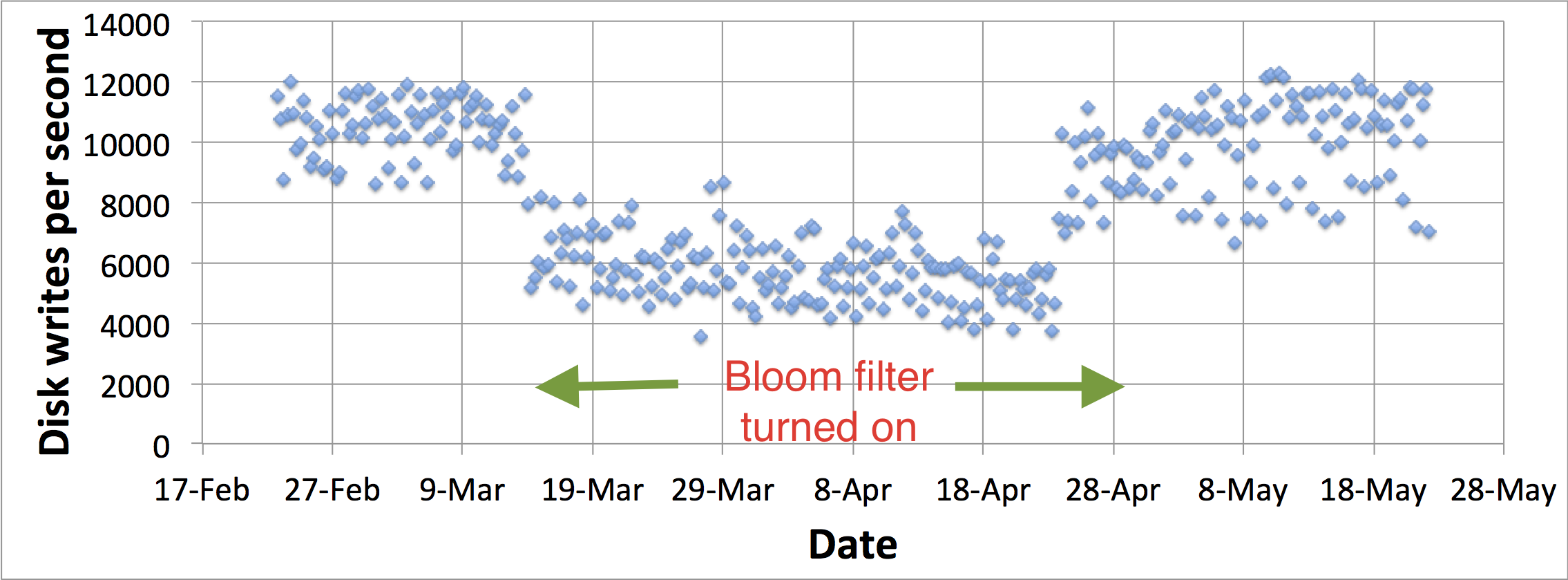
콘텐츠 전송 네트워크는 전 세계에 웹 캐시를 배포하여 웹 콘텐츠를 캐싱하고 사용자에게 더 나은 성능과 안정성을 제공한다. 블룸 필터는 이러한 웹 캐시에 저장할 웹 객체를 효율적으로 결정하는 데 사용된다. 일반적인 웹 캐시에서 액세스되는 URL의 거의 4분의 3은 사용자가 한 번만 액세스하고 다시는 액세스하지 않는 "일회성 항목"이다. 이러한 일회성 항목은 다시 액세스되지 않으므로 웹 캐시에 저장하는 것은 디스크 리소스를 낭비하는 일이다. 이를 방지하기 위해 블룸 필터는 사용자가 액세스하는 모든 URL을 추적하는 데 사용되며, 웹 객체는 이전에 최소 한 번 이상 액세스된 경우에만 캐시된다. 즉, 객체는 두 번째 요청 시에만 캐시된다. 이러한 방식으로 블룸 필터를 사용하면 대부분의 일회성 항목이 디스크 캐시에 기록되지 않아 디스크 쓰기 작업 부하가 크게 줄어들며, 일회성 항목을 필터링함으로써 디스크의 캐시 공간을 절약하여 캐시 적중률을 높일 수 있다.
5. 3. 데이터베이스
구글 Bigtable, Apache HBase, Apache Cassandra, ScyllaDB 및 PostgreSQL[10]은 존재하지 않는 행 또는 열에 대한 디스크 조회를 줄이기 위해 블룸 필터를 사용한다.[11] 비용이 많이 드는 디스크 조회를 피함으로써 데이터베이스 쿼리 작업의 성능을 상당히 향상시킨다.5. 4. 웹 브라우저
구글 크롬 웹 브라우저는 과거 악성 URL을 식별하기 위해 블룸 필터를 사용했다.[12][13] 모든 URL은 먼저 로컬 블룸 필터로 검사되었으며, 블룸 필터가 양성 결과를 반환하는 경우에만 URL을 전체 검사했다. 만약 전체 검사 결과도 양성이면 사용자에게 경고를 보냈다.5. 5. 검색 엔진
마이크로소프트 Bing은 검색 색인에 다단계 계층적 블룸 필터를 사용한다.[14] 블룸 필터는 이전에 역 파일을 기반으로 했던 이전 Bing 색인보다 비용이 저렴했다.[14]5. 6. 기타
스퀴드 웹 프록시 캐시는 캐시 다이제스트에 블룸 필터를 사용한다.[15] 비트코인은 지갑 동기화를 가속화하기 위해 블룸 필터를 사용했지만, 구현에 따른 개인 정보 보호 취약점이 발견되어 사용이 중단되었다.[16] 벤티 아카이브 스토리지 시스템은 이전에 저장된 데이터를 감지하기 위해 블룸 필터를 사용한다.[17] SPIN 모델 검사기는 대규모 검증 문제에 대한 도달 가능한 상태 공간을 추적하는 데 블룸 필터를 사용한다.[18] 캐스케이딩 분석 프레임워크는 한 쪽의 조인된 데이터 집합이 다른 쪽보다 훨씬 큰 비대칭 조인을 가속화하기 위해 블룸 필터를 사용한다. Exim 메일 전송 에이전트(MTA)는 속도 제한 기능에 블룸 필터를 사용한다. 미디엄은 사용자가 이전에 읽었던 기사를 추천하지 않기 위해 블룸 필터를 사용한다.[19] 이더리움은 이더리움 블록체인에서 로그를 빠르게 찾기 위해 블룸 필터를 사용한다. Grafana Tempo는 각 백엔드 블록에 대한 블룸 필터를 저장하여 쿼리 성능을 향상시킨다. 이러한 블룸 필터는 각 쿼리에서 액세스되어 제공된 검색 기준을 충족하는 데이터가 포함된 블록을 결정한다.[20]6. 대안
고전적인 블룸 필터는 삽입된 키당 약 비트의 공간을 사용하는 반면, 동일한 역할을 하는 최적의 자료 구조는 키당 비트의 공간만 필요로 한다.[20] 따라서 블룸 필터는 동일한 최적의 자료 구조보다 44% 더 많은 공간을 사용한다.
몫 필터는 임의의 매개변수 에 대해 비트의 공간을 사용하도록 매개변수화할 수 있으며, 시간 연산을 지원한다.[21] 블룸 필터와 비교했을 때 몫 필터의 장점으로는 참조 지역성과 삭제를 지원하는 기능이 있다.
쿠쿠 해싱의 공간 효율적인 변형을 기반으로 하는 쿠쿠 필터는 키나 값 대신 키의 짧은 지문(작은 해시)을 보관하는 해시 테이블을 구성한다. 키를 찾을 때 일치하는 지문을 찾으면 키가 집합에 있을 가능성이 높다. 쿠쿠 필터는 삭제를 지원하며 블룸 필터보다 더 나은 참조 지역성을 갖는다.[22] 또한 일부 매개변수 환경에서 쿠쿠 필터는 거의 최적의 공간 보장을 제공하도록 매개변수화할 수 있다.[22]
Putze, Sanders, Singler(2007)는 고전적인 블룸 필터보다 빠르거나 더 적은 공간을 사용하는 블룸 필터의 일부 변형을 연구했다. 빠른 변형은 각 키와 관련된 k개의 해시 값을 프로세서의 메모리 캐시 블록(일반적으로 64바이트)과 크기가 동일한 하나 또는 두 개의 블록에 위치시키는 것이다. 그러나 제안된 변형은 고전적인 블룸 필터보다 약 32% 더 많은 공간을 사용한다는 단점이 있다.
공간 효율적인 변형은 각 키에 대해 범위의 값을 생성하는 단일 해시 함수를 사용하며, 여기서 는 요청된 오탐률이다. 그런 다음 값의 시퀀스는 정렬되고 골롬 코딩(또는 일부 다른 압축 기술)을 사용하여 비트에 가까운 공간을 차지하도록 압축된다.
Graf, Lemire(2020)는 XOR 필터라고 하는 접근 방식을 설명한다. 여기서 특정 유형의 완전 해시 테이블에 지문을 저장하여 블룸 또는 쿠쿠 필터보다 메모리 효율적( 비트/키)이고 더 빠른 필터를 생성한다. 그러나 필터 생성은 블룸 및 쿠쿠 필터보다 더 복잡하며, 생성 후 집합을 수정할 수 없다.
참조
[1]
간행물
Dillinger
2004a
[2]
간행물
Blustein
2002
[3]
서적
Computer Aided Verification
Springer, Cham
2020-07-21
[4]
간행물
Mitzenmacher
2005
[5]
간행물
Mitzenmacher
2005
[6]
간행물
Starobinski
2003
[7]
간행물
Goel
2010
[8]
학술지
Mathematical correction for fingerprint similarity measures to improve chemical retrieval
2007
[9]
학술지
A neural data structure for novelty detection
2018-12-18
[10]
웹사이트
Bloom index contrib module
https://git.postgres[...]
Postgresql.org
2016-04-01
[11]
간행물
Chang
2006
[12]
웹사이트
Alex Yakunin's blog: Nice Bloom filter application
http://blog.alexyaku[...]
Blog.alexyakunin.com
2010-03-25
[13]
웹사이트
Issue 10896048: Transition safe browsing from bloom filter to prefix set. - Code Review
https://chromiumcode[...]
Chromiumcodereview.appspot.com
2014-07-03
[14]
서적
Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval
2017
[15]
웹사이트
Bloom Filter
https://river.com/le[...]
2020-11-14
[16]
웹사이트
Plan 9 /sys/man/8/venti
http://plan9.bell-la[...]
Plan9.bell-labs.com
2014-05-31
[17]
웹사이트
Spin - Formal Verification
http://spinroot.com/
[18]
웹사이트
What are Bloom filters?
https://medium.com/t[...]
Medium
2015-07-15
[19]
웹사이트
Grafana Tempo Documentation - Caching
https://grafana.com/[...]
Grafana
2022-11-16
[20]
서적
Proceedings of the tenth annual ACM symposium on Theory of computing - STOC '78
ACM Press
1978
[21]
학술지
Don't thrash
http://dx.doi.org/10[...]
2012-07
[22]
학술지
Prefix filter
http://dx.doi.org/10[...]
2022-03
[23]
서적
Proceedings of the 54th Annual ACM SIGACT Symposium on Theory of Computing
ACM
2022-06-09
[24]
논문
Optimizing Bloom filter: Challenges, solutions, and comparisons
2018-04-13
[25]
학술지
A neural data structure for novelty detection
2018
[26]
학술지
Bloom filter with a false positive free zone
http://lendulet.tmit[...]
2018
[27]
서적
2017 IEEE Symposium on Security and Privacy (SP)
2017
[28]
학술지
Analysis of Counting Bloom Filters Used for Count Thresholding
2019-07-11
[29]
서적
2013 IEEE International Conference on Big Data
2013
[30]
학술지
Distributed duplicate removal
2013
[31]
학술지
Processing aggregates in parallel database systems
1994
[32]
서적
Introduction to Parallel Computing. Design and Analysis of Algorithms
Benjamin/Cummings
1994
[33]
학술지
Aging Bloom Filter with Two Active Buffers for Dynamic Sets
2010
[34]
서적
Computing and Combinatorics
2020
[35]
웹사이트
Less Hashing, Same Performance: Building a Better Bloom Filter
https://www.eecs.har[...]
Wiley InterScience
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com