적대적 기계 학습
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
적대적 기계 학습은 기계 학습 모델을 속여 의도적으로 잘못된 결과를 생성하도록 설계된 공격 기술을 의미한다. 2004년 초에 스팸 필터를 우회하기 위한 연구에서 시작되어, 딥 러닝 모델의 발전과 함께 더욱 정교해졌다. 공격은 분류기의 영향을 조작하거나, 데이터 무결성을 해치거나, 특정 결과를 유도하는 방식으로 이루어지며, 데이터 포이즈닝, 회피 공격, 모델 추출 등이 대표적이다. 이에 대응하기 위해 위협 모델링, 공격 시뮬레이션, 방어 메커니즘 설계 등 다양한 방어 기법이 연구되고 있으며, 안전한 학습 알고리즘, 다중 분류기 시스템, 적대적 훈련 등이 제시되었다.
더 읽어볼만한 페이지
- 컴퓨터 보안 - 얼굴 인식 시스템
얼굴 인식 시스템은 디지털 이미지나 비디오에서 사람 얼굴을 감지하고 식별하는 기술로, 다양한 알고리즘 발전을 거쳐 보안, 신원 확인 등에 활용되지만, 편향성, 개인 정보 침해, 기술적 한계와 같은 윤리적 문제도 야기한다. - 컴퓨터 보안 - 워터마크
워터마크는 종이 제조 시 두께 차이를 이용해 만들어지는 표식으로, 위조 방지를 위해 지폐나 여권 등에 사용되며 댄디 롤 등의 제작 기법을 통해 만들어지고 컴퓨터 프린터 인쇄 기술로도 활용된다. - 기계 학습 - 비지도 학습
비지도 학습은 레이블이 없는 데이터를 통해 패턴을 발견하고 데이터 구조를 파악하는 것을 목표로 하며, 주성분 분석, 군집 분석, 차원 축소 등의 방법을 사용한다. - 기계 학습 - 지도 학습
지도 학습은 레이블된 데이터를 사용하여 입력 데이터와 출력 레이블 간의 관계를 학습하는 기계 학습 분야로, 예측 모델 생성, 알고리즘 선택, 모델 최적화, 정확도 평가 단계를 거치며, 회귀 및 분류 문제에 적용되고 다양한 확장 기법과 성능 평가 방법을 활용한다.
| 적대적 기계 학습 | |
|---|---|
| 적대적 기계 학습 개요 | |
| 분야 | 기계 학습 및 컴퓨터 보안 |
| 설명 | 기계 학습 모델을 속이거나 회피하도록 설계된 적대적 공격에 대한 연구 |
| 적대적 공격 유형 | |
| 적대적 예제 | 기계 학습 모델을 오분류하도록 설계된 입력 |
| 데이터 포이즈닝 공격 | 기계 학습 모델의 무결성을 손상시키는 것을 목표로 하는 악의적인 데이터 삽입 |
| 모델 추출 공격 | 합법적인 쿼리를 통해 기계 학습 모델의 민감한 정보를 도용하거나 복제 |
| 멤버십 추론 공격 | 기계 학습 모델이 특정 데이터 포인트를 학습하는 데 사용되었는지 확인 |
| 타이밍 공격 | 기계 학습 모델의 구현 세부 정보를 활용하여 민감한 정보 획득 |
| 적대적 방어 기술 | |
| 적대적 훈련 | 적대적 예제를 사용하여 기계 학습 모델의 견고성을 향상 |
| 입력 검증 | 유효성 검사 기술을 사용하여 악의적인 입력을 탐지 및 완화 |
| 차등 개인 정보 보호 | 데이터에 노이즈를 추가하여 기계 학습 모델의 개인 정보 보호를 보장 |
| 모델 난독화 | 모델 아키텍처를 숨겨 공격자가 악용하기 어렵게 만듦 |
| 응용 분야 | |
| 보안 | 스팸 필터 침입 탐지 시스템 멀웨어 분석 |
| 자율 시스템 | 자율 주행 차량 로봇 공학 |
| 의료 | 질병 진단 약물 발견 |
| 금융 | 사기 탐지 신용 평가 |
2. 역사
2006년, 마르코 바레노 등은 "기계 학습은 안전할 수 있는가?"를 발표하며 광범위한 공격 분류 체계를 개략적으로 설명했다. 2007년경, 일부 스팸 발송자는 OCR 기반 필터를 무력화하기 위해 "이미지 스팸" 내의 단어를 모호하게 하기 위해 무작위 노이즈를 추가했다. 2013년까지 많은 연구자들은 비선형 분류기(예: 서포트 벡터 머신 및 신경망)가 적대자에 강건할 수 있기를 희망했지만, 2012년부터 바티스타 비지오 등이 이러한 기계 학습 모델에 대한 최초의 기울기 기반 공격을 시연했다.[8][9]
2. 1. 초기 연구
2004년 1월 MIT 스팸 컨퍼런스에서 존 그래엄-커밍은 기계 학습 스팸 필터가 스팸 이메일에 특정 단어를 추가하여 스팸이 아닌 것으로 분류되도록 학습시킴으로써, 다른 기계 학습 스팸 필터를 무력화할 수 있음을 보여주었다.[7]같은 해, 닐레시 달비 등은 선형 분류기가 스팸 필터에 사용될 때, 스팸 발송자가 "좋은 단어"를 스팸 이메일에 삽입하는 "회피 공격"으로 인해 무력화될 수 있다고 지적했다.
2. 2. 딥러닝 시대의 발전
2012년, 심층 신경망이 컴퓨터 비전 분야에서 주도적인 기술로 부상하기 시작했다. 2014년, 크리스티안 세게디 등은 심층 신경망이 적대적 교란을 생성하는 기울기 기반 공격에 취약하여 쉽게 속을 수 있음을 증명했다.[10][11]2. 3. 최근 동향
최근에는 적대적 공격이 노이즈의 효과를 상쇄하는 다양한 환경 제약으로 인해 실제 세계에서 생성하기 더 어렵다는 관찰 결과가 나왔다.[12][13] 예를 들어, 적대적 이미지에 대한 작은 회전이나 약간의 조명 변화만으로도 적대성이 파괴될 수 있다. 또한, 구글 브레인의 니콜라스 프로스트와 같은 연구자들은 적대적 예제를 생성하는 것보다 표지판 자체를 물리적으로 제거하여 자율 주행 자동차가[14] 정지 표지판을 놓치게 만드는 것이 훨씬 쉽다고 지적한다.[15] 프로스트는 또한 적대적 기계 학습 커뮤니티가 특정 데이터 분포에서 훈련된 모델이 완전히 다른 데이터 분포에서도 잘 수행될 것이라고 잘못 가정한다고 믿는다. 그는 기계 학습에 대한 새로운 접근 방식을 탐구해야 하며, 현재 최첨단 접근 방식보다 인간의 인지력과 더 유사한 특성을 가진 독특한 신경망을 연구하고 있다고 제안한다.[15]적대적 기계 학습이 학계에 깊이 뿌리내리고 있는 반면, 구글, 마이크로소프트, IBM과 같은 대형 기술 회사들은 다른 사람들이 기계 학습 모델의 강건성을 구체적으로 평가하고 적대적 공격의 위험을 최소화할 수 있도록 문서와 오픈 소스 코드 베이스를 큐레이션하기 시작했다.[16][17][18]
3. 공격 유형
적대적 기계 학습 공격은 공격 대상, 공격 방법, 공격 목표 등에 따라 다양하게 분류될 수 있다. 연구자들은 단 하나의 픽셀만 변경해도 딥 러닝 알고리즘을 속일 수 있음을 보여주었다.[24]
다음은 적대적 기계 학습 공격의 예시이다.
- 스팸 필터링에서 "나쁜" 단어의 오타 또는 "좋은" 단어의 삽입을 통해 스팸 메시지를 의도적으로 변경하는 공격
- 컴퓨터 보안에서 네트워크 패킷 내의 악성 코드 난독화 또는 침입 탐지를 오도하기 위해 네트워크 흐름의 특성을 변경하는 공격
- 가짜 생체적 특징을 사용하여 합법적인 사용자를 사칭하거나 시간이 지남에 따라 업데이트된 특징에 적응하는 사용자의 템플릿 갤러리를 손상시킬 수 있는 생체 인식 공격
3D 프린팅을 통해 구글의 객체 감지 AI가 거북이를 어떤 각도에서 보든 소총으로 분류하도록 설계된 텍스처를 가진 장난감 거북이를 만든 사례도 있다.[25] 이 거북이는 저렴한 상업용 3D 프린팅 기술로 만들 수 있었다.[26]
개 이미지의 기계로 조작된 이미지가 컴퓨터와 인간 모두에게 고양이처럼 보이도록 표시된 연구 결과도 있으며,[27] 2019년 연구에 따르면 인간은 기계가 적대적 이미지를 어떻게 분류할지 추측할 수 있다고 보고되었다.[28] 또한, 연구자들은 자율 주행차가 이를 병합 또는 속도 제한 표지판으로 분류하도록 정지 표지판의 모양을 변경하는 방법을 발견했다.[14][29]
McAfee는 테슬라의 전 Mobileye 시스템을 공격하여 속도 제한 표지판에 2인치 길이의 검은색 테이프를 추가하는 것만으로도 50mph 이상으로 달리도록 속인 사례도 보고했다.[30][31]
안면 인식 시스템 또는 번호판 판독기를 속이도록 설계된 안경이나 의류의 적대적 패턴은 "스텔스 스트리트웨어"라는 틈새 시장을 만들기도 했다.[32]
신경망에 대한 적대적 공격을 통해 공격자는 대상 시스템에 알고리즘을 주입할 수 있다.[33] 연구자들은 무해해 보이는 오디오에서 지능형 비서에 대한 명령을 위장하기 위해 적대적 오디오 입력을 만들 수 있다는 것을 보여주었으며,[34] 이와 관련된 문헌에서는 이러한 자극에 대한 인간의 인식을 탐구한다.[35][36]
클러스터링 알고리즘은 보안 애플리케이션에 사용된다. 악성 코드 및 컴퓨터 바이러스 분석은 악성 코드 패밀리를 식별하고 특정 탐지 시그니처를 생성하는 것을 목표로 한다.[37][38]
3. 1. 분류 기준
감독 학습(supervised) 기계 학습 알고리즘에 대한 공격은 다음 세 가지 주요 축을 기준으로 분류할 수 있다.[39]- 분류기 영향: 공격은 분류 단계를 방해하여 분류기에 영향을 미칠 수 있다. 이는 취약점을 식별하기 위한 탐색 단계가 선행될 수 있다. 공격자의 능력은 데이터 조작 제약 조건의 존재에 의해 제한될 수 있다.[40]
- 보안 침해: 공격은 합법적인 것으로 분류되는 악성 데이터를 제공할 수 있다. 훈련 중에 제공된 악성 데이터는 훈련 후 합법적인 데이터가 거부되도록 할 수 있다.
- 특수성: 표적 공격은 특정 침입/중단을 허용하려 시도한다. 또는 무차별 공격은 일반적인 혼란을 야기한다.
이 분류는 공격자의 목표, 공격 대상 시스템에 대한 지식, 입력 데이터/시스템 구성 요소를 조작하는 능력, 공격 전략에 대한 명시적인 가정을 허용하는 보다 포괄적인 위협 모델로 확장되었다.[41][42] 또한, 적대적 공격에 대한 방어 전략에 대한 차원을 포함하도록 더 확장되었다.[43]
3. 2. 공격 전략
다음은 기계 학습 모델을 공격하는 몇 가지 일반적인 전략이다.- '''데이터 포이즈닝 (Data Poisoning):''' 훈련 데이터를 오염시켜 모델의 성능을 떨어뜨리거나 특정 결과를 유도하는 공격이다.
- 페이스북은 연간 약 70억 개의 가짜 계정을 삭제한다고 보고[44][45]될 정도로, 가짜 계정의 만연은 포이즈닝에 많은 기회를 제공한다.
- 소셜 미디어에서는 허위 정보 캠페인이 추천 및 조정 알고리즘에 편향을 가하여 특정 콘텐츠를 다른 콘텐츠보다 더 많이 노출시키려고 시도한다.
- '''백도어 공격'''은 데이터 포이즈닝의 특별한 경우로, 이미지, 소리, 비디오 또는 텍스트의 작은 결함과 같이 특정 트리거가 있는 입력에 대한 특정 동작을 가르치는 것을 목표로 한다.[46]
- 데이터 포이즈닝 기술은 텍스트-이미지 모델에 적용되어 출력을 변경할 수 있으며, 예술가들이 저작권이 있는 작품이나 예술적 스타일을 모방으로부터 보호하는 데 사용될 수 있다.[49]
- 데이터 포이즈닝은 모델이 합성 데이터로 훈련되는 모델 붕괴를 통해 의도치 않게 발생할 수도 있다.[50]
- '''비잔틴 공격 (Byzantine Attack):''' 연합 학습과 같이 여러 대의 컴퓨터에 의존하는 분산 학습 환경에서, 악의적인 참여자가 중앙 서버의 모델을 손상[51]시키거나 특정 동작에 대한 알고리즘을 편향시키는 (예: 허위 정보 콘텐츠 추천 증폭) 공격이다.
- 단일 기계에서 훈련이 수행되면 해당 모델은 기계의 고장이나 공격에 매우 취약해지며, 해당 기계는 단일 실패 지점이 된다.[52]
- 악의적인 (일명 비잔틴) 참여자 소수에 대해 (분산) 학습 알고리즘을 입증 가능하게 복원하는 현재 선도적인 솔루션은 강력한 그래디언트 집계 규칙에 기반한다.[54][55][56][57][58][59]
- '''회피 공격 (Evasion Attack):'''[9][41][42][61] 이미 훈련된 모델의 불완전성을 악용하여 오분류를 유도하는 공격이다.
- 스팸 내용이 첨부된 이미지 내에 포함되어 스팸 방지 필터의 텍스트 분석을 회피하는 이미지 스팸이 회피의 명확한 예시이다.
- 회피 공격은 일반적으로 블랙 박스 공격과 화이트 박스 공격의 두 가지 범주로 나눌 수 있다.[17]
- '''모델 추출 (Model Extraction):''' 공격자가 블랙 박스 기계 학습 시스템을 조사하여 훈련된 데이터를 추출하는 공격이다.[62][63]
- 이는 훈련 데이터 또는 모델 자체가 민감하고 기밀일 때 문제를 일으킬 수 있다.
- 극단적인 경우, 모델 추출은 모델을 완전히 재구성할 수 있을 만큼 충분한 양의 데이터를 모델에서 추출하는 것인 '''모델 탈취'''로 이어질 수 있다.
- '''멤버십 추론'''은 목표 모델 추출 공격으로, 종종 잘못된 기계 학습 방식의 결과인 과적합을 활용하여 데이터 포인트의 소유자를 추론한다.[64]
4. 특정 공격 유형
다음은 기계 학습 시스템을 공격하는 데 사용될 수 있는 다양한 적대적 공격 유형이다. 이러한 공격의 상당수는 딥 러닝 시스템뿐만 아니라 지지 벡터 머신(SVM)[8] 및 선형 회귀와 같은 전통적인 기계 학습 모델에서도 작동한다.[76]
5. 방어 기법
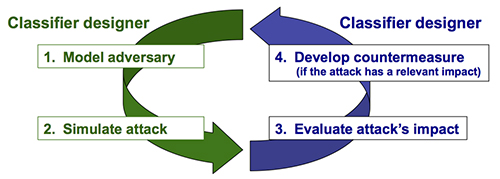
연구자들은 기계 학습을 보호하기 위해 다음과 같은 다단계 접근 방식을 제안했다.[11]
- 위협 모델링: 공격자의 목표와 능력을 대상 시스템과 관련하여 공식화한다.
- 공격 시뮬레이션: 공격자가 가능한 공격 전략에 따라 해결하려는 최적화 문제를 공식화한다.
- 공격 영향 평가
- 대응책 설계
- 잡음 감지: 회피 기반 공격의 경우에 해당한다.[100]
- 정보 세탁: 모델 탈취 공격의 경우, 적대자에 의해 수신된 정보를 변경한다.[63]
5. 1. 방어 메커니즘
회피, 중독 및 프라이버시 공격에 대한 여러 방어 메커니즘이 제안되었으며, 다음과 같다.- 안전한 학습 알고리즘[20][101][102]
- 비잔틴 복원 알고리즘[54][5]
- 다중 분류기 시스템[19][103]
- AI가 작성한 알고리즘[33]
- 훈련 환경을 탐색하는 AI (예: 이미지 인식에서 고정된 2D 이미지 세트를 수동적으로 스캔하는 대신 3D 환경을 적극적으로 탐색)[33]
- 프라이버시 보존 학습[42][104]
- 캐글 스타일 경쟁을 위한 래더 알고리즘
- 게임 이론 모델[105][106][107]
- 훈련 데이터 정리
- 적대적 훈련[81][22]
- 백도어 탐지 알고리즘[108]
- 기울기 마스킹/난독화 기술: 적대자가 화이트 박스 공격에서 기울기를 악용하는 것을 방지. (단, 블랙 박스 공격에는 취약)[109]
- 모델 앙상블 학습 (주의: 적대적 상황에는 적용되지 않을 수 있음)[110]
기계 학습의 규모가 커짐에 따라, 연합 학습과 같이 여러 대의 컴퓨터에 의존하는 경우가 많아졌다. 엣지 장치는 일반적으로 그래디언트 또는 모델 매개변수를 중앙 서버와 주고받으며 협력한다. 그러나 이러한 장치 중 일부는 중앙 서버의 모델을 손상시키거나 특정 동작에 대한 알고리즘을 편향시키는 등(예: 허위 정보 콘텐츠 추천 증폭) 예상 동작에서 벗어날 수 있다.[51] 단일 기계에서 훈련이 수행되면 해당 모델은 기계의 고장이나 공격에 매우 취약해진다. 해당 기계는 단일 실패 지점이 된다.[52] 실제로 기계 소유자 자신이 탐지하기 어려운 백도어를 삽입할 수도 있다.[53]
분산 학습 알고리즘을 악의적인 참여자(비잔틴)에 대해 복원하는 현재 선도적인 솔루션은 강력한 그래디언트 집계 규칙에 기반한다.[54][55][56][57][58][59] 강력한 집계 규칙은 참여자 간의 데이터가 비-IID 분포를 가질 때 항상 작동하지는 않는다. 추천 알고리즘에 대한 서로 다른 소비 습관 또는 언어 모델에 대한 서로 다른 작성 스타일을 가진 사용자와 같은, 이질적인 정직한 참여자의 맥락에서, 모든 강력한 학습 알고리즘이 보장할 수 있는 것에 대한 증명 가능한 불가능성 정리가 존재한다.[5][60]
참조
[1]
서적
Intelligent Systems and Applications
2020
[2]
서적
2020 IEEE Security and Privacy Workshops (SPW)
2020-05
[3]
논문
Making machine learning robust against adversarial inputs
2018-06-25
[4]
Poster
Witches' Brew: Industrial Scale Data Poisoning via Gradient Matching
https://openreview.n[...]
2020-09-28
[5]
논문
Collaborative Learning in the Jungle (Decentralized, Byzantine, Heterogeneous, Asynchronous and Nonconvex Learning)
https://proceedings.[...]
2021-12-06
[6]
conference
Stealing Machine Learning Models via Prediction {APIs}
https://www.usenix.o[...]
2016
[7]
웹사이트
How to beat an adaptive/Bayesian spam filter (2004)
http://blog.jgc.org/[...]
2023-07-05
[8]
arXiv
Poisoning Attacks against Support Vector Machines
2013-03-25
[9]
서적
Advanced Information Systems Engineering
Springer
2013
[10]
arXiv
Intriguing properties of neural networks
2014-02-19
[11]
논문
Wild patterns: Ten years after the rise of adversarial machine learning
2018-12
[12]
arXiv
Adversarial examples in the physical world
[13]
간행물
"Applicability issues of Evasion-Based Adversarial Attacks and Mitigation Techniques."
2020 IEEE Symposium Series on Computational Intelligence (SSCI)
2020
[14]
논문
Algorithmic Decision-Making in AVs: Understanding Ethical and Technical Concerns for Smart Cities
2019
[15]
웹사이트
Google Brain's Nicholas Frosst on Adversarial Examples and Emotional Responses
https://syncedreview[...]
2021-10-23
[16]
웹사이트
Responsible AI practices
https://ai.google/re[...]
2021-10-23
[17]
웹사이트
Adversarial Robustness Toolbox (ART) v1.8
https://github.com/T[...]
Trusted-AI
2021-10-23
[18]
웹사이트
Failure Modes in Machine Learning - Security documentation
https://docs.microso[...]
2021-10-23
[19]
논문
Multiple classifier systems for robust classifier design in adversarial environments
http://pralab.diee.u[...]
2015-01-14
[20]
논문
Static Prediction Games for Adversarial Learning Problems
http://www.jmlr.org/[...]
2012
[21]
논문
Modeling Realistic Adversarial Attacks against Network Intrusion Detection Systems
2021-06-03
[22]
논문
Adaptative Perturbation Patterns: Realistic Adversarial Learning for Robust Intrusion Detection
2022-03
[23]
논문
Robustness of multimodal biometric fusion methods against spoof attacks
http://cubs.cedar.bu[...]
2009-06-01
[24]
논문
One Pixel Attack for Fooling Deep Neural Networks
2019-10
[25]
뉴스
Single pixel change fools AI programs
https://www.bbc.com/[...]
BBC News
2018-02-12
[26]
arXiv
Synthesizing Robust Adversarial Examples
[27]
잡지
AI Has a Hallucination Problem That's Proving Tough to Fix
https://www.wired.co[...]
2018-03-10
[28]
논문
Humans can decipher adversarial images
[29]
웹사이트
Slight Street Sign Modifications Can Completely Fool Machine Learning Algorithms
https://spectrum.iee[...]
2019-07-15
[30]
잡지
A Tiny Piece of Tape Tricked Teslas Into Speeding Up 50 MPH
https://www.wired.co[...]
2020-03-11
[31]
웹사이트
Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles
https://securingtomo[...]
2020-03-11
[32]
잡지
Dressing for the Surveillance Age
https://www.newyorke[...]
2020-04-05
[33]
논문
Why deep-learning AIs are so easy to fool
2019-10
[34]
논문
AI can now defend itself against malicious messages hidden in speech
2019-05-10
[35]
arXiv
Can you hear me now? Sensitive comparisons of human and machine perception
2020-03-27
[36]
arXiv
On the human evaluation of audio adversarial examples
2020-01-23
[37]
간행물
"Adversarial knowledge discovery"
IEEE Intelligent Systems
[38]
웹사이트
Pattern recognition systems under attack: Design issues and research challenges
http://pralab.diee.u[...]
2022-05-20
[39]
논문
The security of machine learning
https://link.springe[...]
2010
[40]
서적
AI in Cybersecurity
Springer
[41]
웹사이트
Security evaluation of pattern classifiers under attack
http://pralab.diee.u[...]
2018-05-18
[42]
서적
Support Vector Machines Applications
Springer International Publishing
2014
[43]
논문
Fool Me Once, Shame On You, Fool Me Twice, Shame On Me: A Taxonomy of Attack and De-fense Patterns for AI Security
https://aisel.aisnet[...]
2020-06-15
[44]
웹사이트
Facebook removes 15 Billion fake accounts in two years
https://www.techdige[...]
2022-06-08
[45]
웹사이트
Facebook removed 3 billion fake accounts in just 6 months
https://nypost.com/2[...]
2022-06-08
[46]
논문
Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning Attacks
https://proceedings.[...]
PMLR
2021-07-01
[47]
웹사이트
Support vector machines under adversarial label noise
http://pralab.diee.u[...]
2020-08-03
[48]
간행물
Security analysis of online centroid anomaly detection
[49]
웹사이트
University of Chicago researchers seek to "poison" AI art generators with Nightshade
https://arstechnica.[...]
2023-10-27
[50]
웹사이트
AI-Generated Data Can Poison Future AI Models
https://www.scientif[...]
2024-06-22
[51]
논문
A Little Is Enough: Circumventing Defenses For Distributed Learning
https://proceedings.[...]
Curran Associates, Inc.
2019
[52]
논문
Genuinely distributed Byzantine machine learning
2022-05-26
[53]
arXiv
Planting Undetectable Backdoors in Machine Learning Models
2022
[54]
논문
Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent
https://proceedings.[...]
Curran Associates, Inc.
2017
[55]
논문
DRACO: Byzantine-resilient Distributed Training via Redundant Gradients
https://proceedings.[...]
PMLR
2018-07-03
[56]
논문
The Hidden Vulnerability of Distributed Learning in Byzantium
https://proceedings.[...]
PMLR
2018-07-03
[57]
arXiv
Byzantine-Resilient Non-Convex Stochastic Gradient Descent
2020-09-28
[58]
conference
Distributed Momentum for Byzantine-resilient Stochastic Gradient Descent
https://infoscience.[...]
2022-10-20
[59]
논문
Byzantine-Resilient High-Dimensional SGD with Local Iterations on Heterogeneous Data
https://proceedings.[...]
PMLR
2021-07-01
[60]
arXiv
Byzantine-Robust Learning on Heterogeneous Datasets via Bucketing
2021-09-29
[61]
간행물
Query strategies for evading convex-inducing classifiers
[62]
웹사이트
How to steal modern NLP systems with gibberish?
http://cleverhans.io[...]
2020-10-15
[63]
arXiv
Information Laundering for Model Privacy
2020-09-13
[64]
웹사이트
Machine learning: What are membership inference attacks?
https://bdtechtalks.[...]
2021-11-07
[65]
논문
Explaining and Harnessing Adversarial Examples
2015
[66]
서적
Adversarial Attacks on Neural Network Policies
2017-02-07
[67]
논문
Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs
2022
[68]
서적
2018 IEEE Security and Privacy Workshops (SPW)
2018
[69]
conference
Explaining and Harnessing Adversarial Examples
2015
[70]
conference
Regularization properties of adversarially-trained linear regression
https://openreview.n[...]
[71]
conference
Robustness May Be At Odds with Accuracy
2019
[72]
conference
Sharp statistical guarantees for adversarially robust Gaussian classification
https://proceedings.[...]
2020
[73]
conference
Precise tradeoffs in adversarial training for linear regression
http://proceedings.m[...]
2020
[74]
journal
Overparameterized Linear Regression under Adversarial Attacks
2023
[75]
conference
Rademacher Complexity for Adversarially Robust Generalization
https://proceedings.[...]
2019
[76]
서적
2018 IEEE Symposium on Security and Privacy (SP)
IEEE
2018-05
[77]
웹사이트
Attacking Machine Learning with Adversarial Examples
https://openai.com/b[...]
2017-02-24
[78]
arXiv
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
2019-03-11
[79]
journal
Algorithms that remember: model inversion attacks and data protection law
2018-11-28
[80]
arXiv
Membership Inference Attacks against Machine Learning Models
2017-03-31
[81]
arXiv
Explaining and Harnessing Adversarial Examples
2015-03-20
[82]
arXiv
Towards Deep Learning Models Resistant to Adversarial Attacks
2019-09-04
[83]
arXiv
Towards Evaluating the Robustness of Neural Networks
2017-03-22
[84]
arXiv
Adversarial Patch
2018-05-16
[85]
journal
A Black-Box Attack Method against Machine-Learning-Based Anomaly Network Flow Detection Models
2021-04-24
[86]
웹사이트
Adversarial Attacks and Defences for Convolutional Neural Networks
https://medium.com/o[...]
2021-10-23
[87]
journal
Simple Black-box Adversarial Attacks
https://proceedings.[...]
PMLR
2019-05-24
[88]
문서
Kilian Weinberger. On the importance of deconstruction in machine learning research.ML-Retrospectives @ NeurIPS 2020, 2020.https://slideslive.com/38938218/the-importance-of-deconstruction
[89]
서적
Computer Vision – ECCV 2020
Springer International Publishing
2020
[90]
문서
HopSkipJumpAttack: A Query-Efficient Decision-Based Attack
https://www.youtube.[...]
2021-10-25
[91]
arXiv
Square Attack: a query-efficient black-box adversarial attack via random search
2020-07-29
[92]
웹사이트
Black-box decision-based attacks on images
https://davideliu.co[...]
2021-10-25
[93]
arXiv
Explaining and Harnessing Adversarial Examples
2015-03-20
[94]
웹사이트
Adversarial example using FGSM
https://www.tensorfl[...]
2021-10-24
[95]
웹사이트
Perhaps the Simplest Introduction of Adversarial Examples Ever
https://towardsdatas[...]
2021-10-24
[96]
conference
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
IEEE/CVF
2023
[97]
arXiv
Towards Evaluating the Robustness of Neural Networks
2017-03-22
[98]
웹사이트
carlini wagner attack
http://richardjordan[...]
2021-10-23
[99]
웹사이트
Paper Summary: Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection Methods
https://medium.com/@[...]
2021-10-23
[100]
journal
Determining Sequence of Image Processing Technique (IPT) to Detect Adversarial Attacks
[101]
문서
O. Dekel, O. Shamir, and L. Xiao. "Learning to classify with missing and corrupted features". Machine Learning, 81:149–178, 2010.
[102]
journal
Mining adversarial patterns via regularized loss minimization
https://link.springe[...]
[103]
문서
B. Biggio, G. Fumera, and F. Roli. "Evade hard multiple classifier systems". In O. Okun and G. Valentini, editors, Supervised and Unsupervised Ensemble Methods and Their Applications, volume 245 of Studies in Computational Intelligence, pages 15–38. Springer Berlin / Heidelberg, 2009.
[104]
arXiv
"Learning in a large function space: Privacy- preserving mechanisms for svm learning"
[105]
문서
M. Kantarcioglu, B. Xi, C. Clifton. "Classifier Evaluation and Attribute Selection against Active Adversaries". Data Min. Knowl. Discov., 22:291–335, January 2011.
[106]
논문
Game Theoretical Adversarial Deep Learning with Variational Adversaries
https://ieeexplore.i[...]
2020
[107]
논문
Adversarial Deep Learning Models with Multiple Adversaries
https://ieeexplore.i[...]
2019
[108]
웹사이트
TrojAI
https://www.iarpa.go[...]
2020-10-14
[109]
arXiv
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Example
2018-02-01
[110]
arXiv
Adversarial Example Defenses: Ensembles of Weak Defenses are not Strong
2017-06-15
[111]
서적
Intelligent Systems and Applications
2020
[112]
서적
2020 IEEE Security and Privacy Workshops (SPW)
2020-05
[113]
저널
Making machine learning robust against adversarial inputs
https://dl.acm.org/d[...]
2024-04-14
[114]
Poster
Witches' Brew: Industrial Scale Data Poisoning via Gradient Matching
https://openreview.n[...]
2020-09-28
[115]
저널
Collaborative Learning in the Jungle (Decentralized, Byzantine, Heterogeneous, Asynchronous and Nonconvex Learning)
https://proceedings.[...]
2021-12-06
[116]
콘퍼런스
Stealing Machine Learning Models via Prediction {APIs}
https://www.usenix.o[...]
2016
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com