정상 과정
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
정상 과정은 확률 과정의 한 유형으로, 시간 이동에 대해 확률적 특성이 변하지 않는다는 특징을 갖는다. 엄밀한 정상성은 결합 분포가 시간 이동에 불변인 경우를 의미하며, N차 정상성은 N차까지의 결합 분포가 불변인 경우를 말한다. 약한 정상성 또는 광의의 정상성은 1차 모멘트(평균)와 자기공분산이 시간에 따라 변하지 않는 경우를 의미하며, 신호 처리 분야에서 널리 활용된다. 두 개 이상의 확률 과정에 대해서도 정상성 개념을 확장하여 결합 정상성을 정의할 수 있다. 정상성의 여러 유형 간에는 포함 관계가 존재하며, 차분과 같은 기법을 통해 시계열의 정상성을 확보할 수 있다.
더 읽어볼만한 페이지
- 확률 과정 - 마르코프 연쇄
마르코프 연쇄는 현재 상태가 주어졌을 때 과거와 미래 상태가 독립적인 확률 변수 순서열로, 시간 동질성, 상태 공간 유형, 시간 매개변수 유형에 따라 다양한 유형으로 분류되며 여러 분야에서 활용되는 확률적 모델링 방법이다. - 확률 과정 - 브라운 운동
브라운 운동은 액체나 기체 속 미세 입자가 매질 분자와 충돌하여 불규칙하게 움직이는 현상으로, 아인슈타인과 스몰루호프스키의 이론적 설명과 페랭의 실험적 검증을 통해 원자 존재 입증에 기여했으며, 확산/랑주뱅 방정식으로 모델링되어 다양한 분야에 응용된다. - 신호 처리 - 대역폭 (신호 처리)
대역폭은 주파수 영역에서 함수의 퍼짐 정도를 나타내는 척도로, 통신 분야에서는 변조된 반송파 신호가 차지하는 주파수 범위, 다른 분야에서는 시스템 성능을 유지하거나 저하가 발생하는 주파수 범위를 의미하며, 다양한 측정 방식과 함께 여러 분야에서 활용된다. - 신호 처리 - 선형 시불변 시스템
선형 시불변 시스템은 선형성과 시불변성을 만족하는 시스템으로, 임펄스 응답으로 특성화되며, 컨볼루션, 주파수 영역 분석 등을 통해 분석하고, 통신, 신호 처리 등 다양한 분야에 응용된다.
| 정상 과정 |
|---|
2. 정의
확률 과정 \((X_t: t \in T)\)에서 임의의 확률 변수 \(X_{t_1}, X_{t_2}, \cdots, X_{t_k}\)에 대한 결합 분포를 \(F_X(x_{t_1}, \cdots, x_{t_k})\)라고 한다. 이때, 임의의 \(\tau\)에 대하여 다음 조건을 만족하면 이 확률 과정을 '''정상 과정'''이라고 한다.
:
\(\tau\)는 \(F_X(\cdot)\)에 영향을 미치지 않으므로, \( F_{X}\)는 시간에 독립적이다.[1] 확률 과정의 \(n\)개 표본의 분포는 ''모든'' \(n\)에 대해 시간상으로 이동된 표본의 분포와 같아야 한다.
'''N차 정상성'''은 이러한 조건이 특정 차수 \(N\)까지의 모든 \(n\)에 대해서만 요구되는 더 약한 형태의 정상성이다. 확률 과정 \(\left\{X_t\right\}\)가 다음 조건을 만족하면 '''''N''차 정상'''이라고 한다.[1]
:
2. 1. 엄밀한 정상성 (Strict-sense Stationarity)
확률 과정 에서 임의의 확률 변수 에 대한 결합 분포를 라고 하자. 이때, 임의의 에 대하여:
를 만족하는 경우, 이 확률 과정을 '''정상 과정'''이라고 한다.
형식적으로, 를 확률 과정이라고 하고, 를 시간 에서 의 누적 분포 함수를 나타낸다고 하자. 이때 는 다음 조건을 만족하면 '''엄밀히 정상적''' 또는 '''강정상성'''이라고 한다.[1]
:
는 에 영향을 미치지 않으므로, 는 시간에 독립적이다.
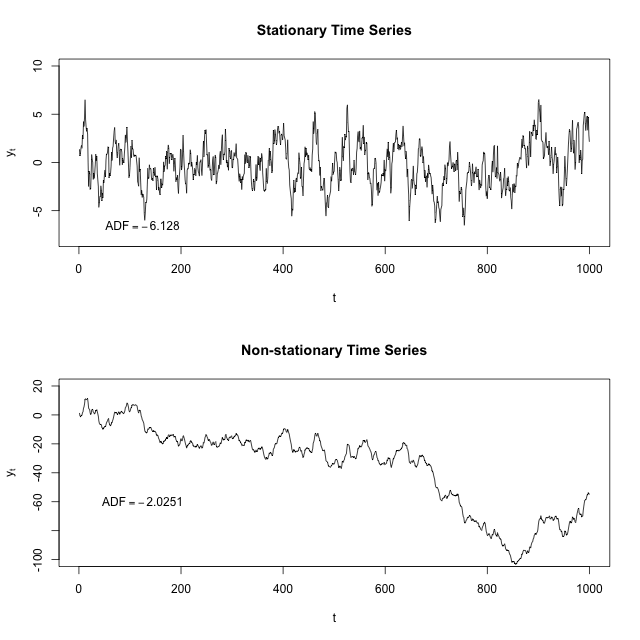
백색 잡음은 정상 과정의 가장 간단한 예시이다. 베르누이 도식은 표본 공간이 이산적인 이산 시간 정상 과정의 한 예시이다. 연속적인 표본 공간을 가진 이산 시간 정상 과정의 다른 예시로는 자기 회귀 및 이동 평균 과정이 있으며, 이들은 모두 자기 회귀 이동 평균 모형의 하위 집합이다. 자명하지 않은 자기 회귀 구성 요소를 가진 모델은 매개변수 값에 따라 정상적일 수도 있고 비정상적일 수도 있으며, 중요한 비정상적 특수한 경우는 모델에 단위근이 존재하는 경우이다.
약한 백색 잡음은 반드시 엄밀한 의미에서 정상성을 갖는 것은 아니다.
2. 1. 1. 예시 1
Y영어를 임의의 스칼라 확률 변수라고 하고, 시계열 X|t영어를 다음과 같이 정의한다.: X|t영어 = Y영어 (모든 t에 대해)
그러면 X|t영어는 정상 시계열이며, 그 실현값은 각 실현값마다 다른 상수 값으로 구성된 일련의 상수 값으로 구성된다. 이 경우 대수의 법칙은 적용되지 않는데, 단일 실현값의 평균의 극한값은 Y영어의 기댓값을 취하기보다는 Y영어에 의해 결정된 임의의 값을 취하기 때문이다.
X|t영어의 시간 평균은 이 과정이 에르고딕 과정이 아니므로 수렴하지 않는다.
2. 1. 2. 예시 2
Y영어가 [0,2π]영어에서 균등 분포를 갖는다고 할 때, 시계열 를 다음과 같이 정의한다.:
그러면 는 엄밀히 정상성을 갖는다. 왜냐하면 (영어 modulo 영어)는 모든 영어에 대해 Y영어와 동일한 균등 분포를 따르기 때문이다.
2. 1. 3. 예시 3
ω영어를 구간 (0, 2π)영어에서 균등하게 분포된 확률 변수라고 하고, 시계열 z를 다음과 같이 정의한다.:z
그렇다면
:
따라서 z는 약한 의미에서 백색 잡음(평균과 공분산은 0이고 분산은 모두 같음)이다. 하지만 엄밀한 의미에서 정상성은 아니다.
2. 2. N차 정상성 (Nth-order Stationarity)
확률 과정 가 특정 차수 까지의 모든 에 대해서만 다음 조건을 만족할 때, '''''N''차 정상'''이라고 한다.[1]:
이는 확률 과정의 개 표본의 분포가 모든 에 대해 시간상으로 이동된 표본의 분포와 같아야 한다는 엄밀한 정상성 조건보다 약한 형태의 정상성이다.
3. 약한 정상성 (Weak or Wide-sense Stationarity)
광의의 정상성(Wide-sense Stationarity, WSS), 약한 정상성(Weak-sense Stationarity), 또는 공분산 정상성(Covariance Stationarity)은 신호 처리에서 주로 사용되는 개념이다. WSS 확률 과정은 1차 모멘트(평균)와 자기공분산이 시간에 따라 변하지 않으며, 모든 시간에 대해 2차 모멘트가 유한하다는 조건을 만족해야 한다. 평균과 공분산이 유한한 모든 엄밀 정상 과정(Strong-sense Stationarity)은 WSS를 만족한다.[2]
연속 시간 확률 과정 가 WSS를 만족하면, 평균 함수 와 자기공분산 함수 는 다음과 같은 제약을 받는다.
- 평균 함수 는 상수여야 한다.
- 자기공분산 함수 는 과 의 차이에만 의존하며, 한 변수 ()로 표현될 수 있다.[1]
- 자기상관 함수도 에만 의존한다. 즉,
- 2차 모멘트는 모든 시간 에 대해 유한해야 한다.
복소 확률 과정의 경우, 자기공분산 함수 외에 유사 자기공분산 함수 도 시간 지연에만 의존해야 WSS를 만족한다.
3. 1. 정의
확률 과정 에서 임의의 확률 변수 에 대한 결합 분포를 라고 한다. 이때, 임의의 에 대하여:
를 만족하는 경우, 이 확률 과정을 '''정상 과정'''이라고 한다.
백색 잡음은 정상 과정의 가장 간단한 예이다.[2]
신호 처리에서 일반적으로 사용되는 약한 형태의 정상성은 '''광의의 정상성''' 또는 '''공분산 정상성'''으로 알려져 있다. 광의의 정상 확률 과정은 1차 모멘트 (즉, 평균)와 자기공분산이 시간에 따라 변하지 않고, 모든 시간에 대해 2차 모멘트가 유한할 것을 요구한다. 유한한 평균과 공분산을 갖는 모든 엄밀 정상 과정은 또한 광의의 정상 과정이다.[2]
따라서 광의의 정상성을 갖는 연속 시간 확률 과정 는 평균 함수 와 자기공분산 함수 에 다음과 같은 제약을 받는다.
:
첫 번째 속성은 평균 함수 가 상수여야 함을 의미한다. 두 번째 속성은 자기공분산 함수가 과 의 "차이"에만 의존하며 두 변수가 아닌 한 변수로만 표현되어야 함을 의미한다.[1] 따라서 로 대체하여 축약된다.
:
이것은 또한 자기상관이 에만 의존한다는 것을 의미한다. 즉,
:
세 번째 속성은 2차 모멘트가 모든 시간 에 대해 유한해야 한다고 말한다.
가 복소 확률 과정인 경우, 자기공분산 함수는 로 정의되며, 위의 요구 사항 외에도 유사 자기공분산 함수 가 시간 지연에만 의존해야 한다. 수식으로 나타내면, 는 다음과 같은 경우에 광의의 정상성(WSS)을 가진다.
:
3. 2. 장점 및 활용
광의 정상성(WSS)의 주요 장점은 시계열을 힐베르트 공간의 맥락에 둔다는 것이다. ''H''를 {''x''(''t'')}에 의해 생성된 힐베르트 공간(즉, 주어진 확률 공간에서 제곱 적분 가능한 모든 확률 변수의 힐베르트 공간에서 이러한 확률 변수의 모든 선형 조합 집합의 폐포)이라고 하면, 보흐너의 정리로부터 실수선에 양의 측도 가 존재하여 ''H''가 {''e''−2''iξ⋅t''}에 의해 생성된 ''L''2(''μ'')의 힐베르트 부분 공간과 동형임을 알 수 있다. 이는 연속 시간 정상 확률 과정에 대한 다음과 같은 푸리에 형식 분해를 제공한다. 즉, 모든 에 대해 직교 증분을 갖는 확률 과정 가 존재한다.:
여기서 오른쪽 적분은 적절한 (리만) 의미로 해석된다. 이산 시간 정상 과정에 대해서도 동일한 결과가 적용되며, 스펙트럼 측도는 이제 단위 원에서 정의된다.
선형 LTI 시스템 필터로 WSS 임의 신호를 처리할 때 상관 함수를 선형 연산자로 생각하는 것이 도움이 된다. 이는 순환 연산자이므로(두 인수의 차이에만 의존), 고유 함수는 푸리에 복소 지수이다. 또한, LTI 연산자의 고유 함수는 또한 복소 지수이므로 WSS 임의 신호의 LTI 처리는 매우 다루기 쉽다. 즉, 모든 계산은 주파수 영역에서 수행할 수 있다. 따라서 WSS 가정은 신호 처리 알고리즘에서 널리 사용된다.
4. 결합 정상성 (Joint Stationarity)
확률 과정의 정상성 개념은 두 개의 확률 과정으로 확장될 수 있다.
두 확률 과정 와 는 결합 분포가 시간 이동에 대해 변하지 않으면 결합 정상성을 갖는다고 한다. 결합 정상성에는 다음과 같은 세 가지 종류가 있다.[1]
- '''결합 엄밀 의미 정상성(Joint Strict-sense Stationarity)'''
- '''결합 (''M'' + ''N'')차 정상성(Joint (''M'' + ''N'')th-order Stationarity)'''
- '''결합 광의 정상성(Joint Weak or Wide-sense Stationarity)'''
4. 1. 결합 엄밀한 정상성 (Joint Strict-sense Stationarity)
두 확률 과정 Probability process영어와 의 결합 누적 분포 가 시간 이동에 대해 변하지 않으면 결합 엄밀 의미 정상성이라고 한다.:
:모든 와 모든 에 대해
4. 2. 결합 (M + N)차 정상성 (Joint (M + N)th-order Stationarity)
두 확률 과정 Stochastic process|확률 과정영어 \left\{X_t\right\}와 \left\{Y_t\right\}는 그들의 결합 누적 분포 FXY(xt1 ,…, xtm,yt1' ,…, ytn')가 시간 이동에 대해 변하지 않으면 '''결합 엄밀 의미 정상성'''이라고 한다.즉, 모든 τ, t1, …, tm, t1', …, tn' ∈ ℝ 와 모든 m, n ∈ ℕ 에 대해
FXY(xt1 ,…, xtm,yt1' ,…, ytn') = FXY(xt1+τ ,…, xtm+τ,yt1'+τ ,…, ytn'+τ)
이다.
두 확률 과정 \left\{X_t\right\}와 \left\{Y_t\right\}는 다음과 같은 조건을 만족하면 '''결합 (''M'' + ''N'')차 정상성'''을 갖는다고 말한다.[1]
모든 τ, t1, …, tm, t1', …, tn' ∈ ℝ 와 모든 m ∈ \{1,…,M\}, n ∈ \{1,…,N\}에 대해
FXY(xt1 ,…, xtm,yt1' ,…, ytn') = FXY(xt1+τ ,…, xtm+τ,yt1'+τ ,…, ytn'+τ)
이다.
4. 3. 결합 약한 정상성 (Joint Weak or Wide-sense Stationarity)
두 확률 과정 Probability process영어 와 가 모두 광의 정상성을 가지며, 교차 공분산 함수 가 시간 차이 에만 의존하면 '''결합 광의 정상성'''이라고 한다.이는 다음 조건을 만족하는 것과 같다.
- 모든 에 대해
- 모든 에 대해
- 모든 에 대해
- 모든 에 대해
- 모든 에 대해
5. 정상성 유형 간의 관계
6. 기타 용어
엄밀한 정상 과정 이외의 정상성 유형에 사용되는 용어는 다소 혼합될 수 있다. 몇 가지 예는 다음과 같다.
7. 차분 (Differencing)
시계열을 정상 상태로 만들기 위한 한 가지 방법은 연속된 관측값의 차이를 계산하는 것이다. 이를 차분이라고 한다. 차분은 시계열의 수준 변화를 제거하여 평균을 안정시키는 데 도움을 주며, 결과적으로 추세를 제거한다. 적절하게 수행하면 계절성도 제거할 수 있다(예: 연간 추세를 제거하기 위해 1년 간격으로 관측치를 차분).[6]
로그와 같은 변환은 시계열의 분산을 안정시키는 데 도움이 될 수 있다.[6]
비정상 시계열을 식별하는 한 가지 방법은 ACF 플롯을 사용하는 것이다. 때로는 ACF 플롯에서 패턴이 원본 시계열보다 더 잘 보일 수 있지만, 항상 그런 것은 아니다.[6]
비정상성을 식별하는 또 다른 접근 방식은 시계열의 라플라스 변환을 살펴보는 것이다. 라플라스 변환은 지수 추세와 정현파 계절성(복소 지수 추세)을 모두 식별한다. 신호 분석의 관련 기술인 웨이블릿 변환 및 푸리에 변환도 도움이 될 수 있다.[6]
참조
[1]
서적
Fundamentals of Probability and Stochastic Processes with Applications to Communications
Springer
[2]
서적
Probability and Stochastic Processes
John Wiley & Sons
2014-11-07
[3]
서적
Spectral Analysis and Time Series
Academic Press
[4]
서적
Non-linear and Non-stationary Time Series Analysis
https://archive.org/[...]
Academic Press
[5]
논문
Stochastic Simulation of Patterns Using Distance-Based Pattern Modeling
[6]
웹사이트
8.1 Stationarity and differencing {{!}} OTexts
https://www.otexts.o[...]
2016-05-18
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com