제어 장치
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
제어 장치는 컴퓨터의 중앙 처리 장치(CPU) 내에서 명령어의 실행을 관리하고, CPU의 각 부분(레지스터, 산술 논리 장치, 버스 등)을 제어하는 장치이다. 제어 장치는 마이크로프로그램 방식, 하드와이어드 방식, 조합 방식 등 다양한 방식으로 구현될 수 있으며, 멀티사이클, 파이프라인, 순서 무관(Out of Order), 변환 방식 등 CPU의 성능 향상을 위한 다양한 설계 방식을 가진다. 또한, 전력 소비를 줄이기 위한 설계, 컴퓨터의 다른 부분과의 통합, 캐시, 인터럽트 컨트롤러 등 다양한 기능을 포함한다.
더 읽어볼만한 페이지
- 디지털 전자공학 - 트랜지스터-트랜지스터 논리
트랜지스터-트랜지스터 논리(TTL)는 1961년 제임스 L. 부이에 의해 발명된 바이폴라 접합 트랜지스터 기반의 디지털 회로 기술로, 텍사스 인스트루먼츠의 7400 시리즈를 통해 널리 사용되었으며, 저렴한 비용으로 디지털 기술 발전에 기여했다. - 디지털 전자공학 - 플립플롭
플립플롭은 1비트 이상의 정보를 저장하는 디지털 논리 회로로, 에클스-조던 트리거 회로에서 기원하여 SR, D, T, JK 등 다양한 유형으로 구현되며, 컴퓨터 기억 장치의 기본 구성 요소로 사용되지만 타이밍 요소에 민감하게 설계해야 한다. - 중앙 처리 장치 - 마이크로컨트롤러
마이크로컨트롤러는 프로세서, 메모리, 입출력 기능을 단일 칩에 통합하여 임베디드 시스템의 핵심이 되는 부품으로, 프로그램 내장 방식을 통해 소프트웨어만으로 제어 기능 변경이 가능하며, 현재는 32비트 ARM, MIPS 아키텍처 기반 제품이 주를 이루고, 저전력 소모, 소형화, 다양한 기능 통합을 특징으로 다양한 분야에서 활용된다. - 중앙 처리 장치 - NX 비트
NX 비트는 하드웨어 기반 보안 기능으로, 메모리 페이지의 실행 권한을 제어하여 특정 영역에서 코드 실행을 막아 버퍼 오버플로 공격과 같은 보안 위협을 줄이는 데 사용되며, AMD에서 처음 도입 후 다양한 프로세서와 운영체제에서 DEP 등의 이름으로 구현되었다.
| 제어 장치 | |
|---|---|
| 컨트롤 유닛 | |
| 유형 | 하드웨어 |
| 일부 | CPU |
| 기능 | CPU 구성 요소의 작동을 제어 |
| 입력 | 명령 코드, 클록 사이클, 플래그 |
| 출력 | 제어 신호 |
| 다른 이름 | 명령어 유닛 (Instruction Unit, IU), 제어부 |
| 디자인 유형 | |
| 유형 | 하드와이어 제어 장치 마이크로 프로그램 제어 장치 |
| 기능적 블록 | |
| 주요 구성 요소 | 명령어 레지스터 명령어 디코더 제어 신호 생성기 시퀀서 |
| 성능 지표 | |
| 지표 | 명령어 처리량 클록 속도 대기 시간 |
| 아키텍처 | |
| 유형 | 단일 사이클 아키텍처 다중 사이클 아키텍처 파이프라인 아키텍처 |
| 작동 원리 | |
| 작동 방식 | 명령어 가져오기 명령어 디코딩 명령어 실행 결과 저장 |
| 제어 신호 | |
| 유형 | 메모리 제어 신호 I/O 제어 신호 인터럽트 제어 신호 |
| 구현 | |
| 방법 | 별개의 논리 게이트 PLA(프로그래머블 논리 어레이) 마이크로프로그래밍 |
| 응용 | |
| 사용 분야 | 컴퓨터 마이크로컨트롤러 임베디드 시스템 |
| 설계 고려 사항 | |
| 고려 사항 | 명령어 세트 아키텍처 파이프라이닝 인터럽트 처리 전력 소비 |
| 테스트 및 검증 | |
| 방법 | 시뮬레이션 에뮬레이션 형식 검증 |
| 제어 장치 설계 유형 | |
| 분류 | 하드와이어 제어 장치 마이크로프로그램 제어 장치 |
2. 제어 장치의 방식
제어 장치를 구현하는 방식은 크게 마이크로프로그램 방식과 하드와이어드 방식으로 나눌 수 있다. 마이크로프로그램 방식은 제어 기억 장치에 저장된 마이크로 프로그램을 사용하여 제어 신호를 발생시키는 방식이며[18], 하드와이어드 방식은 논리 회로를 이용하여 직접 제어 신호를 생성하는 방식이다.[14]
어떤 방식을 사용하든, 제어 장치는 전자적인 제어 신호를 만들어 프로세서의 각 부분을 제어하는 역할을 수행한다. 때로는 간단한 제어와 복잡한 제어를 나누어 처리하는 설계 방식도 사용될 수 있다.
2. 1. 마이크로프로그램 방식
마이크로프로그램 방식은 제어 기억 장치에 저장된 마이크로 프로그램을 사용하여 제어 신호를 발생시키는 방식이다. 이 개념은 1951년 모리스 윌크스가 컴퓨터 프로그램 명령어를 실행하기 위한 중간 수준으로 처음 선보였다.마이크로 프로그램은 일련의 ''마이크로 명령어''들로 구성되며, 특수한 제어 메모리에 저장된다. 마이크로 시퀀서가 이 마이크로 명령어를 순서대로 읽어 실행하며, 이 명령들은 프로세서 내부의 각 부분을 제어하는 데 할당된다. 예를 들어 레지스터, 산술 논리 장치(ALU), 명령어 레지스터, 버스, 그리고 칩 외부와의 입출력 등이 제어 대상이다.
마이크로프로그램 제어 장치의 알고리즘은 일반적으로 순서도를 이용하여 표현된다.[18][16] 이 방식의 주요 장점은 구조가 단순하다는 점이다.[19][17] 제어 장치의 출력 신호들이 마이크로 명령어 안에 정리되어 있어, 마치 소프트웨어처럼 디버깅하거나 교체하는 것이 용이하여 유연성이 높다.[19][17]
2. 2. 하드와이어드 방식
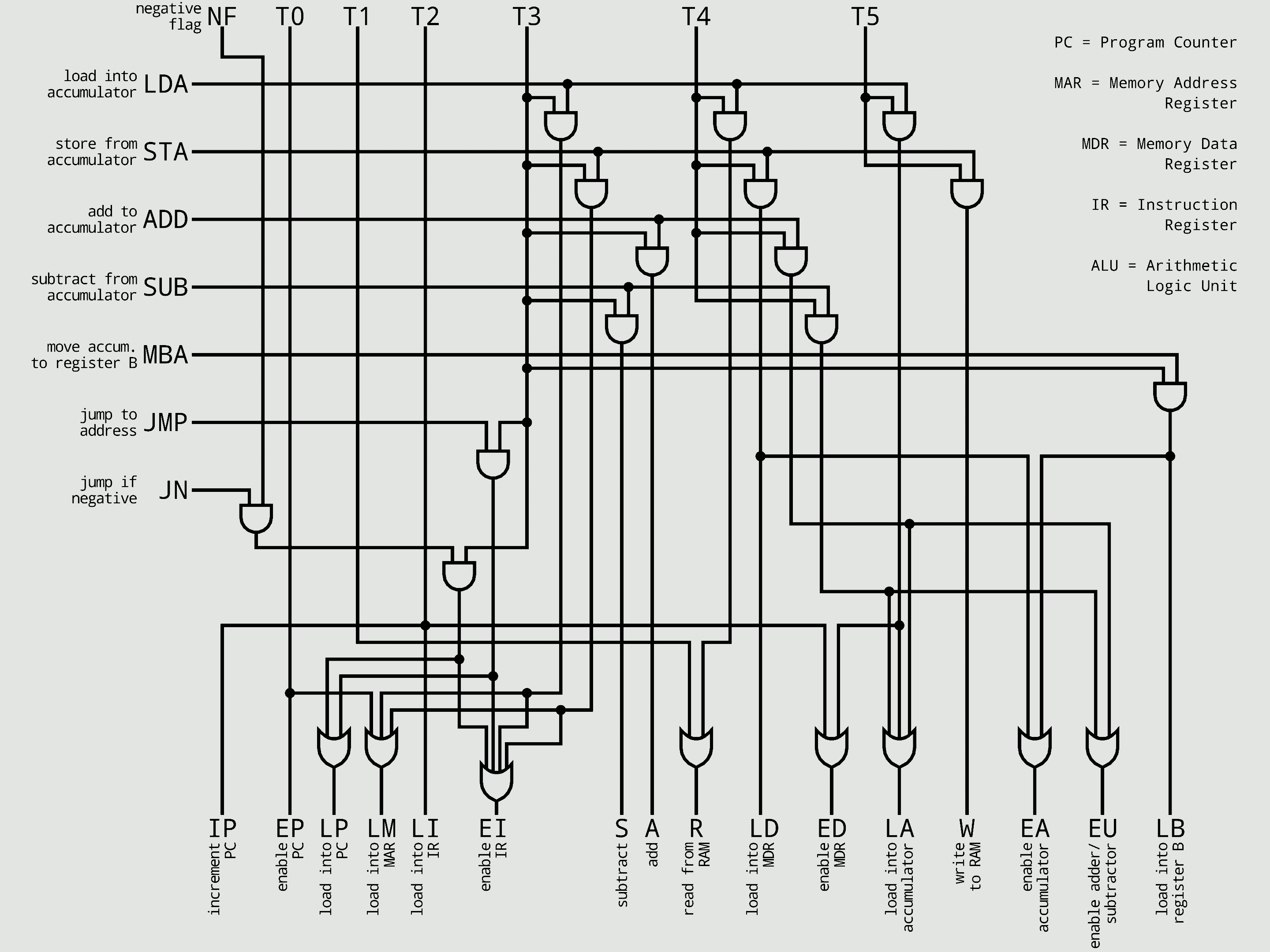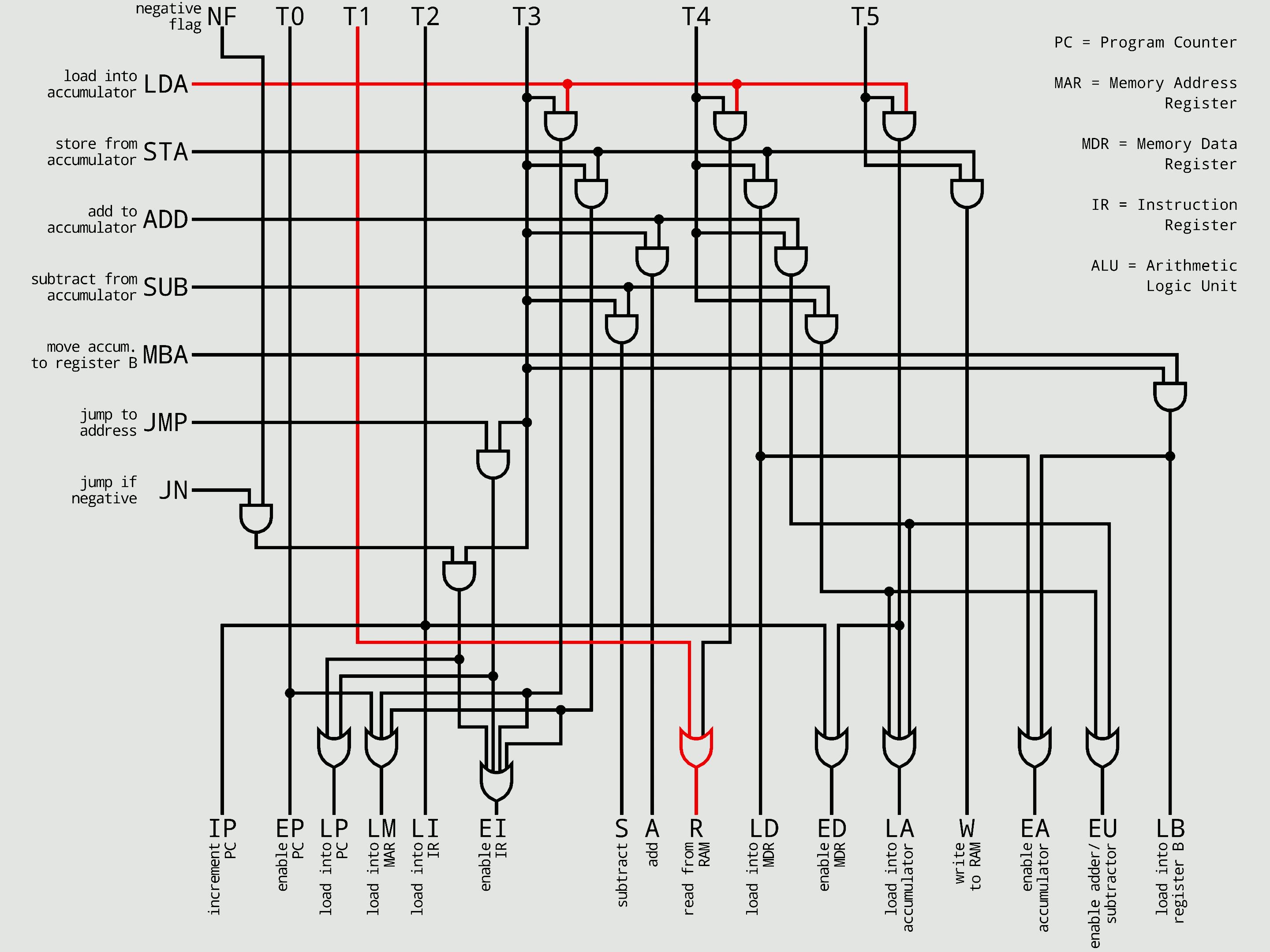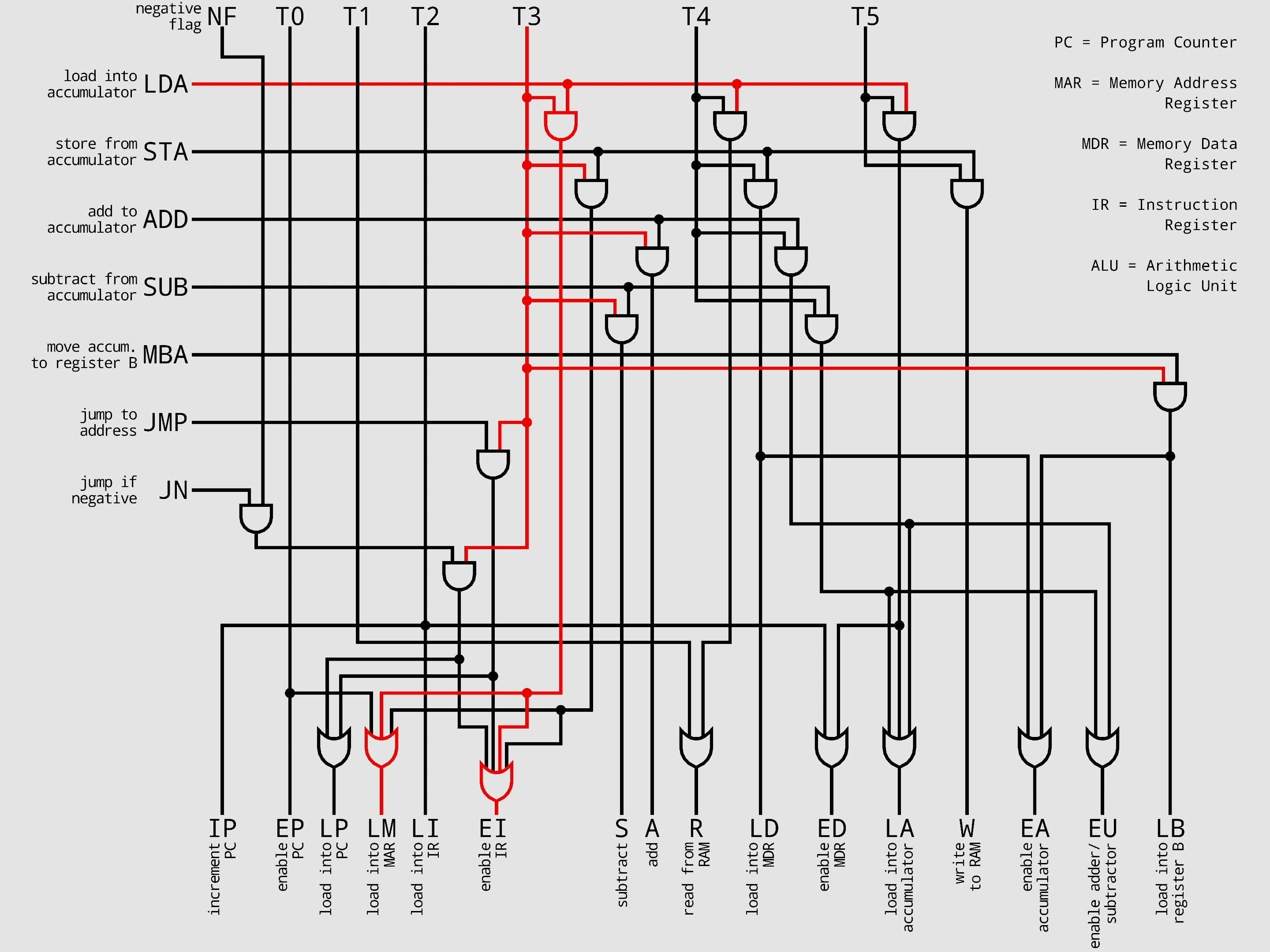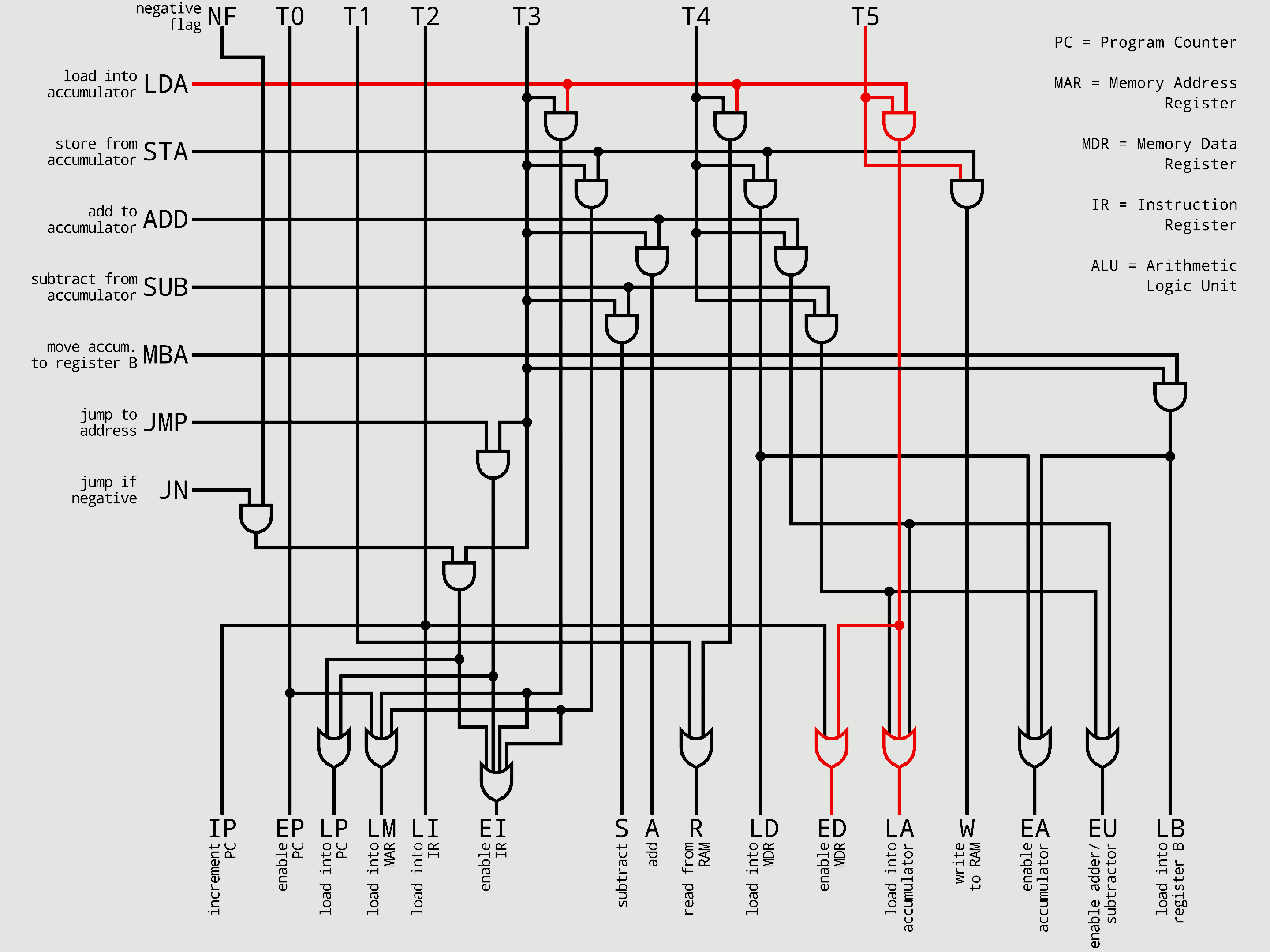
'''하드와이어드 제어 장치'''는 특정 결과를 생성할 수 있는 유한한 수의 게이트를 특징으로 하는 조합 논리 장치를 사용하여 구현된다. 즉, 논리 회로로 직접 제어 신호를 발생시키는 방식이다. 이러한 결과는 해당 응답을 호출하는 데 사용된 명령어에 따라 결정된다. 하드와이어드 제어 장치는 일반적으로 마이크로프로그램 방식보다 속도가 빠르다.[14]
이 설계는 고정된 아키텍처를 사용하므로, 명령어 집합이 수정되거나 변경될 경우 배선(회로)을 변경해야 한다. 따라서 단순하고 빠른 컴퓨터에 적합하다.
이 방식을 사용하는 제어 장치는 고속으로 작동할 수 있지만, 유연성이 떨어진다는 단점이 있다. 복잡한 명령어 집합을 처리하기에는 임시 논리(ad-hoc logic) 설계를 사용하는 설계자를 압도할 수 있다.
하드와이어드 방식은 컴퓨터가 발전하면서 덜 인기를 얻게 되었다. 과거에는 CPU의 제어 장치가 임시 논리를 사용했으며, 설계하기 어려웠다.[15] 그러나 현대에는 집적 회로의 대규모화와 설계 기술의 향상으로 복잡한 프로세서도 이 방식으로 구현하는 것이 가능해졌다.
2. 3. 조합 방식
마이크로코드의 인기 있는 변형 방식 중 하나는 소프트웨어 시뮬레이터를 사용하여 마이크로코드를 디버깅하는 것이다. 이 과정을 거치면 마이크로코드는 비트 테이블이 되는데, 이는 마이크로코드 주소를 제어 장치 출력으로 변환하는 논리적 진리표이다. 이 진리표는 컴퓨터 프로그램을 통해 최적화된 전자 논리를 생성하는 데 사용된다. 결과적으로 생성된 제어 장치는 마이크로프로그래밍 방식처럼 설계가 용이하면서도, 하드와이어드 제어 장치처럼 빠른 속도와 적은 수의 논리 소자를 갖는 특징이 있다. 실질적인 결과는 밀리 머신이나 리처드 컨트롤러와 유사하다.3. 제어 장치의 설계
마이크로프로그래밍 개념은 1951년 모리스 윌크스가 컴퓨터 프로그램 명령을 실행하기 위한 중간 수준으로 처음 소개했다. 마이크로프로그램은 여러 개의 마이크로 명령어로 구성되며, 특별한 제어 메모리에 저장된다. 이러한 마이크로프로그램 제어 장치의 작동 방식은 보통 순서도를 이용하여 설명한다.[18] 마이크로프로그램 방식의 주요 장점은 구조가 단순하다는 점이다. 제어 장치의 출력 신호들이 마이크로 명령어 안에 정리되어 있어, 필요에 따라 쉽게 수정하거나 교체할 수 있다.[19]
3. 1. 멀티사이클 제어 장치
가장 단순한 컴퓨터는 멀티사이클 마이크로아키텍처를 사용한다. 이는 초창기에 개발된 방식으로, 기계를 작동시키는 임베디드 시스템과 같이 규모가 작은 컴퓨터에서 여전히 널리 사용되고 있다.컴퓨터에서 제어 장치는 일반적으로 명령어 사이클을 순서대로 진행시킨다. 이 과정은 명령어를 가져오고, 명령어 실행에 필요한 데이터(피연산자)를 가져오고, 명령어를 해석(해독)하고, 명령어를 실행한 뒤, 그 결과를 메모리에 다시 저장하는 단계로 구성된다. 새로운 명령어가 제어 장치에 들어오면, 제어 장치는 해당 명령어를 올바르게 완료하기 위해 자신의 동작 방식을 변경한다. 즉, 명령어에 포함된 정보(비트)가 제어 장치를 직접 제어하고, 제어 장치는 다시 컴퓨터 전체를 제어하는 구조이다.
제어 장치 내부에는 어떤 단계를 수행해야 하는지 알려주는 이진 카운터가 포함될 수 있다.
멀티사이클 제어 장치는 일반적으로 사각파 형태의 타이밍 클럭 신호가 올라가는 시점(상승 에지)과 내려가는 시점(하강 에지)을 모두 활용한다. 각 클럭 신호의 변화 시점마다 작동 단계를 수행하므로, 예를 들어 4단계로 이루어진 연산이 2번의 클럭 주기 안에 완료될 수 있다. 이는 동일한 성능의 부품을 사용했을 때 컴퓨터의 처리 속도를 두 배로 높이는 효과를 가져온다.
많은 컴퓨터에서는 예상치 못한 두 가지 유형의 사건이 발생할 수 있다. 바로 인터럽트와 예외이다.
- 인터럽트: 특정 종류의 입출력 장치가 올바르게 작동하기 위해 소프트웨어의 즉각적인 처리가 필요할 때 발생한다. 인터럽트의 발생 시점은 예측하기 어렵다는 특징이 있다.
- 예외: 컴퓨터가 명령어를 처리하는 과정 자체에서 문제가 발생했을 때 생긴다. 예를 들어, 메모리가 부족한 경우 예외가 발생할 수 있다. 일부 예외는 해당 예외를 발생시킨 명령어를 다시 시작해야 할 수도 있다는 점에서 인터럽트와 다르다.
제어 장치는 인터럽트를 처리하기 위해 두 가지 일반적인 방식으로 설계될 수 있다.
1. 즉시 처리 방식: 빠른 응답이 가장 중요할 경우, 제어 장치는 현재 하던 작업을 중단하고 즉시 인터럽트를 처리하도록 설계된다. 이 경우, 중단된 작업은 마지막으로 완료된 명령어 다음부터 다시 시작된다.
2. 완료 후 처리 방식: 컴퓨터 시스템이 매우 저렴하거나, 구조가 매우 단순하거나, 안정성이 매우 중요하거나, 처리해야 할 작업량이 많을 경우에는 현재 진행 중인 작업을 모두 마친 후에 인터럽트를 처리하도록 설계된다. 이 방식은 마지막으로 완료된 명령어를 기억할 별도의 저장 공간(레지스터)이 필요 없어 비용이 저렴하고, 관리할 상태 정보가 적어 구조가 단순하며 안정적이다. 또한, 처리 중이던 작업을 버리지 않으므로 작업 낭비가 가장 적다.
매우 단순한 컴퓨터에서는 예외를 인터럽트와 유사하게 처리하도록 만들 수 있다. 만약 컴퓨터가 가상 메모리 시스템을 사용한다면, 메모리 부족과 같은 예외가 발생했을 경우 해당 예외를 일으킨 명령어를 다시 시도해야 한다.
멀티사이클 컴퓨터에서는 특정 작업을 처리하기 위해 더 많은 클럭 사이클을 사용하는 것이 일반적이다. 예를 들어, 조건에 따라 프로그램의 실행 흐름을 바꾸는 조건부 점프 명령어는 프로그램 카운터(다음에 실행할 명령어의 주소를 저장하는 레지스터)를 새로 로드해야 하므로 일반 명령어보다 처리 시간이 더 오래 걸릴 수 있다. 또한, 곱셈이나 나눗셈 같은 복잡한 연산은 여러 단계에 걸쳐 처리되기도 한다. 아주 작은 컴퓨터의 경우, 한 번에 한두 비트씩만 산술 연산을 수행할 수도 있다. 일부 컴퓨터는 여러 단계를 거쳐야 하는 매우 복잡한 명령어를 처리하는 능력도 갖추고 있다.
3. 2. 파이프라인 제어 장치
많은 중간 복잡도의 컴퓨터는 경제성과 속도 때문에 명령어 파이프라인 설계를 채택한다. 이 방식은 명령어가 컴퓨터 내부를 여러 단계에 걸쳐 흐르도록 구성된다. 예를 들어, 폰 노이만 사이클의 각 단계처럼 파이프라인도 여러 단계로 나눌 수 있다. 각 단계의 끝에는 일반적으로 "파이프라인 레지스터"가 있어, 해당 단계에서 계산된 결과를 저장하고 다음 단계의 논리 게이트가 이를 사용할 수 있도록 전달한다.효율을 높이기 위해 짝수 단계와 홀수 단계를 클럭의 서로 다른 가장자리(상승 또는 하강)에서 작동시키는 경우가 많다. 이는 단일 가장자리 설계보다 컴퓨터 속도를 이론적으로 두 배로 높일 수 있다.
파이프라인 컴퓨터의 제어 장치는 프로그램 명령어에 따라 데이터 흐름을 시작하고, 유지하며, 중지시키는 역할을 한다. 명령어 관련 정보는 파이프라인 레지스터를 통해 다음 단계로 전달되며, 각 단계에는 해당 단계에 맞는 제어 로직이 존재한다. 제어 장치는 또한 서로 다른 단계에 있는 명령어들이 서로의 작업을 방해하지 않도록 조율한다. 예를 들어, 두 명령어가 동일한 데이터를 사용해야 할 경우, 제어 로직은 올바른 순서로 데이터 접근이 이루어지도록 보장한다.
파이프라인이 효율적으로 작동할 때는 각 단계마다 명령어가 하나씩 채워져 동시에 처리된다. 이로 인해 매 클럭 사이클마다 거의 하나의 명령어를 완료할 수 있다. 하지만 프로그램 실행 중 분기(branch)가 발생하여 명령어 흐름이 바뀌면, 파이프라인은 처리 중이던 데이터를 폐기하고 새로운 명령어들로 다시 채워야 하는데, 이를 스톨(stall)이라고 한다. 또한, 두 명령어가 서로 간섭할 가능성이 있을 때(예: 동일한 레지스터 사용), 제어 장치는 이전 명령어가 완료될 때까지 다음 명령어의 처리를 중지시킨다. 이로 인해 파이프라인의 일부가 비게 되는데, 이를 파이프라인 버블(pipeline bubble)이라고 부른다.
인터럽트나 예상치 못한 예외 상황 역시 파이프라인 스톨을 유발할 수 있다. 파이프라인 컴퓨터는 인터럽트 발생 시 멀티사이클 컴퓨터보다 더 많은 작업을 중단해야 할 수 있다. 그러나 운영 체제 호출과 같이 예측 가능한 예외는 스톨을 일으키지 않도록 설계될 수 있다.
동일한 속도의 논리 게이트를 사용한다고 가정할 때, 파이프라인 컴퓨터는 멀티사이클 컴퓨터보다 초당 더 많은 명령어를 실행할 수 있다. 또한, 파이프라인의 단계 수를 조절하여 컴퓨터의 속도를 조절할 수 있다. 단계가 많아질수록 각 단계의 작업 부담이 줄어들고 논리 게이트 지연 시간도 감소한다. 파이프라인 모델은 일반적으로 멀티사이클이나 아웃오브오더(out-of-order) 컴퓨터보다 명령어당 필요한 논리 게이트 수가 적고, 평균적으로 에너지 효율도 더 높다.
하지만 파이프라인 컴퓨터는 일반적으로 비슷한 성능의 멀티사이클 컴퓨터보다 더 복잡하고 제작 비용이 높다. 더 많은 논리 게이트와 레지스터, 그리고 더 복잡한 제어 장치가 필요하기 때문이다. 명령어당 에너지 소비는 적지만, 전체적인 에너지 소비는 더 많을 수도 있다. 아웃오브오더 CPU는 동시에 여러 명령어를 처리할 수 있어 파이프라인 컴퓨터보다 더 높은 명령어 처리량을 보이기도 한다.
제어 장치는 파이프라인을 최대한 채우고 지연을 최소화하기 위해 다양한 기법을 사용한다.
- 분기 예측:
- 정적 예측: 간단한 제어 장치는 낮은 주소로의 역방향 분기를 루프(loop)로 간주하고 해당 경로의 명령어를 미리 파이프라인에 채운다.[3] 컴파일러는 자주 실행될 것으로 예상되는 분기 방향을 예측하여, 해당 방향이 선호되도록 명령어를 생성할 수 있다. 일부 컴퓨터는 컴파일러가 제공하는 분기 방향 힌트를 명령어 자체에 인코딩하기도 한다.[4]
- 동적 예측: 제어 장치는 최근 실행된 분기 명령어들의 주소와 실행 결과를 전자 목록 형태로 유지한다. 이 정보를 바탕으로 다음에 어떤 분기 경로가 실행될지 예측한다.[3]
- 추측 실행: 여러 개의 파이프라인을 사용하여 분기의 양쪽 경로를 동시에 계산한 뒤, 실제 실행되지 않은 경로의 계산 결과를 폐기하는 방식이다.
현대의 고성능 컴퓨터는 캐시 메모리를 사용하는데, 이로 인해 메모리 접근 시간이 예측 불가능해질 수 있다. CPU는 매우 빠른 캐시 메모리 속도에 맞춰 설계되지만, 필요한 데이터가 캐시에 없고 주 메모리에 접근해야 할 경우 지연이 발생한다. 최신 PC의 주 메모리는 캐시보다 수백 배 느릴 수 있다.
이러한 메모리 지연 문제를 완화하기 위해, 데이터가 준비되는 대로 명령어를 처리하는 아웃오브오더 CPU와 제어 장치가 개발되었다. 만약 모든 계산이 완료되었음에도 CPU가 여전히 주 메모리 접근을 기다리며 지연된다면, 제어 장치는 동시 멀티스레딩 기술을 사용하여 현재 스레드가 유휴 상태인 동안 다른 실행 가능한 스레드로 전환할 수 있다. 각 스레드는 자신만의 프로그램 카운터, 명령어 시퀀스, 레지스터 집합을 가진다. 스레드의 수는 컴퓨터 종류(PC, 스마트폰, 데이터베이스 서버, GPU)와 메모리 시스템의 특성에 따라 달라진다. 예를 들어, GPU는 반복적인 그래픽 계산을 처리하기 위해 수백 또는 수천 개의 실행 유닛과 스레드를 가지는 경우가 많다.
제어 장치가 스레딩을 지원하는 경우, 소프트웨어도 이를 고려하여 설계되어야 한다. 일반적인 CPU에서는 스레드가 운영체제에 의해 일반적인 프로세스처럼 관리되지만, GPU와 같은 특수 목적 하드웨어에서는 스레드 스케줄링이 응용 프로그램 수준에서 관리되어야 하는 경우가 많으며, 이를 위해 특수한 라이브러리가 사용된다.
3. 3. 순서 무관(Out of Order) 제어 장치
가능한 작업을 먼저 완료하도록 설계된 제어 장치이다. 여러 명령어가 동시에 완료될 수 있는 상황에서, 제어 장치는 이를 정렬하여 처리 순서를 결정한다. 따라서 가장 빠른 컴퓨터들은 피연산자나 명령어 대상이 사용 가능해지는 시점에 따라 명령어 처리 순서를 유동적으로 변경할 수 있다. 대부분의 슈퍼컴퓨터와 많은 개인용 컴퓨터(PC)의 CPU가 이 방식을 사용한다. 이러한 제어 장치의 구체적인 구성은 컴퓨터 시스템에서 가장 느린 부분의 성능에 따라 달라진다.계산 실행이 가장 느린 경우, 명령어는 메모리에서 '이슈 유닛'(issue unit)으로 전달된다. 이슈 유닛은 피연산자와 실행 유닛이 모두 사용 가능해질 때까지 명령어를 보관한다. 이후 명령어와 해당 피연산자는 실행 유닛으로 '이슈'(issue)된다. 실행 유닛은 명령어를 수행하고, 결과 데이터는 메모리나 레지스터에 다시 기록될 데이터 대기열로 이동한다. 컴퓨터에 여러 실행 유닛이 있다면, 일반적으로 클럭 사이클당 여러 명령어를 처리할 수 있다.
특정 연산을 위한 전용 실행 유닛을 두는 것이 일반적이다. 예를 들어, 일반적인 컴퓨터에는 부동소수점 연산 유닛이 상대적으로 비싸기 때문에 하나만 있을 수 있지만, 정수 연산 유닛은 비교적 저렴하고 대부분의 명령어를 처리할 수 있어 여러 개를 둘 수 있다.
명령어 이슈를 제어하는 방식 중 하나는 '스코어보드'(scoreboard)를 사용하는 것이다.[5] 스코어보드는 명령어의 이슈 시점을 감지하는 전자 논리 배열이다. 이 배열의 '높이'는 실행 유닛의 수, '길이'와 '너비'는 각각 피연산자 소스의 수를 나타낸다. 피연산자와 실행 유닛의 신호가 교차하는 지점의 논리를 통해 명령어가 실행 가능한 상태임을 감지하고, 사용 가능한 실행 유닛으로 명령어를 이슈한다. 다른 방식으로는 명령어의 하드웨어 대기열을 재정렬하는 토마술로 알고리즘을 구현하는 것이 있다. 어떤 의미에서는 두 방식 모두 대기열을 사용한다고 볼 수 있으며, 스코어보드는 명령어 대기열을 인코딩하고 재정렬하는 또 다른 방법으로 간주되어 일부 설계자들은 이를 '대기열 테이블'이라고 부르기도 한다.[6][7] 일부 추가 논리를 통해 스코어보드는 실행 순서 재정렬, 레지스터 이름 변경, 정확한 예외 및 인터럽트 처리를 효율적으로 결합할 수 있으며, 토마술로 알고리즘에서 사용하는 전력 소모가 많고 복잡한 내용 주소 지정 가능 메모리(CAM) 없이도 이를 수행할 수 있다.[6][7]
실행 속도가 결과 기록 속도보다 느리다면 메모리 쓰기 백(write-back) 대기열에는 항상 사용 가능한 공간이 있다. 하지만 메모리 쓰기 자체가 느리거나, 결과가 기록될 대상 레지스터가 아직 처리되지 않은 이전 명령어에 의해 사용될 경우에는 명령어의 쓰기 백 단계를 별도로 예약해야 할 수 있다. 이를 '명령어 완료'(retiring)라고도 부른다. 이 경우 실행 유닛의 후단(back-end)에 결과가 기록될 레지스터나 메모리에 대한 접근을 예약하는 논리가 필요하다.[6][7] 완료(Retiring) 논리는 이슈 스코어보드나 토마술로 대기열 설계 시 메모리 또는 레지스터 접근을 포함시켜 구현될 수도 있다.[6][7]
순서 무관 제어기는 인터럽트를 처리하기 위해 특별한 설계가 필요하다. 여러 명령어가 동시에 처리 중일 때 인터럽트가 명령어 스트림의 정확히 어느 지점에서 발생했는지 파악하기 어렵기 때문이다. 입출력 인터럽트의 경우 대부분의 해결책이 적용 가능하지만, 가상 메모리를 사용하는 컴퓨터에서 메모리 접근 실패로 인터럽트가 발생하면 문제가 복잡해진다. 이 메모리 접근은 정확한 명령어 및 프로세서 상태와 연결되어야만 인터럽트 발생 시점의 프로세서 상태를 저장하고 복원할 수 있다. 일반적인 해결책은 메모리 접근이 완료될 때까지 레지스터의 복사본을 보존하는 것이다.[6][7]
또한, 순서 무관 CPU는 분기(branch) 예측 실패 시 발생하는 지연(stall) 문제에 더 취약하다. 이는 클럭 사이클당 여러 명령어를 처리할 수 있고, 일반적으로 여러 단계에 걸쳐 많은 명령어가 동시에 처리 중이기 때문이다. 따라서 이러한 제어 장치는 파이프라인 프로세서에서 사용되는 분기 예측 및 처리 기술들을 활용해야 한다.[8]
3. 4. 변환(Translating) 제어 장치
일부 컴퓨터는 개별 명령어를 더 간단한 명령어 여러 개로 변환하여 처리하기도 한다. 이 방식은 복잡한 다단계 명령어를 처리하면서도 제어 로직의 대부분을 단순하게 유지할 수 있다는 장점이 있다. 특히 순서에 상관없이 명령어를 처리하는 순서 무관(out-of-order) 실행 방식의 컴퓨터에 유리하다.대표적인 예로 인텔의 펜티엄 프로 이후 x86 아키텍처 기반 CPU들을 들 수 있다. 이 CPU들은 복잡한 CISC 방식의 x86 명령어를 RISC와 유사한 내부 마이크로 연산(micro-operation)으로 변환하여 실행한다.
이러한 변환 방식의 제어 장치는 크게 두 부분으로 나눌 수 있다. 제어 장치의 '프론트엔드(front-end)'는 명령어 변환 과정을 관리하며, '백엔드(back-end)'는 변환된 마이크로 연산과 피연산자(operand)를 실제 연산을 수행하는 실행 유닛(execution unit)과 데이터 경로(datapath)로 전달하는 역할을 담당한다. 이 과정에서 명령어는 변환되지만, 연산 대상이 되는 데이터인 피연산자 자체는 변환되지 않는다.
4. 저전력 제어 장치
많은 현대 컴퓨터는 전력 사용량을 최소화하는 제어 장치를 갖추고 있다. 이는 휴대폰과 같이 배터리로 작동하는 컴퓨터의 사용 시간을 늘리고, 전력 공급 장치가 있는 컴퓨터의 경우 전기 요금, 냉각 비용, 소음 등을 줄이는 데 도움이 된다.
대부분의 현대 컴퓨터는 CMOS 로직을 사용하는데, CMOS는 주로 두 가지 방식으로 전력을 소모한다. 하나는 로직의 상태가 바뀔 때 소모되는 활성 전력이고, 다른 하나는 의도치 않게 전류가 새어 나가는 누설 전류이다. 활성 전력은 제어 신호를 꺼서 줄일 수 있으며, 누설 전류는 전압을 낮추거나, 누설이 적은 특수 트랜지스터를 사용하거나, 로직 자체를 완전히 꺼서 줄일 수 있다.
활성 전력은 로직에 저장된 데이터에 영향을 주지 않으면서 줄일 수 있어 비교적 관리가 쉽다. 가장 일반적인 방법은 CPU의 클럭 속도를 낮추는 것이다. 대부분의 컴퓨터 시스템이 이 방법을 사용하며, 클럭 속도 변경 시 발생할 수 있는 부작용을 피하기 위해 CPU가 잠시 작동을 멈추는 것이 일반적이다. 또한, 많은 컴퓨터에는 "정지(halt)" 명령어가 있다. 원래 이 명령어는 인터럽트가 없는 코드 실행을 멈춰 인터럽트 처리 코드의 정확한 타이밍을 보장하기 위해 만들어졌지만, CPU의 클럭을 완전히 꺼서 활성 전력을 0으로 만드는 데 유용하다는 것이 밝혀졌다. 이 상태에서도 인터럽트 컨트롤러는 계속 클럭이 필요할 수 있지만, 일반적으로 CPU보다 훨씬 적은 전력을 사용한다.
이러한 기본적인 방법들이 널리 사용되면서 상업적 이점을 얻기 위해 다른 방법들도 개발되었다. 많은 최신 저전력 CMOS CPU는 실행하는 명령어에 따라 필요한 실행 유닛이나 버스 인터페이스만 선택적으로 켜고 끈다. 일부 컴퓨터[9]는 각 명령어가 정확히 필요한 로직 부분만 사용하도록 마이크로아키텍처를 설계하기도 한다.
또 다른 일반적인 방법은 작업을 여러 CPU에 분산시키고, 작업량이 줄어들면 사용하지 않는 CPU를 끄는 것이다. 이때 운영체제는 해당 CPU의 데이터를 메모리에 저장한다. 경우에 따라[10], 여러 CPU 중 하나를 더 단순하고 작은 CPU(로직 게이트 수가 적음)로 만들어 누설 전류를 줄이기도 한다. 이 작은 CPU는 가장 마지막에 꺼지고 가장 먼저 켜지며, 특별한 저전력 기능을 담당하게 된다. PC에서도 유사한 방식이 사용되는데, 보통 전력 시스템 관리를 위한 보조 임베디드 CPU를 탑재한다. 다만 PC에서는 관련 소프트웨어가 운영체제가 아닌 BIOS에 있는 경우가 많다.
이론적으로 클럭 속도를 낮춘 컴퓨터는 공급 전압도 함께 낮춰 누설 전류를 줄일 수 있다. 하지만 전압 변경은 컴퓨터의 안정성에 영향을 줄 수 있어 기술적으로 구현 비용이 많이 들고, PC나 휴대폰과 같이 비교적 고가인 기기를 제외하고는 흔하게 사용되지 않는다.
누설 전류를 줄이기 위해 특수한 트랜지스터를 사용하는 설계도 있다. 트랜지스터 내부의 공핍 장벽을 더 크게 만들면 누설을 줄일 수 있지만, 트랜지스터 크기가 커져 속도가 느려지고 비용이 증가한다. 일부 제조사는 IC의 특정 부분에 아날로그 회로용 공정에서 제공되는 큰 트랜지스터를 사용하여 저누설 로직을 구현하기도 한다. 핀펫(FinFET) 구조처럼 실리콘 표면 위에 트랜지스터를 배치하는 공정도 있지만, 공정 단계가 늘어나 비용이 더 든다. 하프늄과 같은 특수 도핑 재료도 누설을 줄일 수 있지만, 역시 공정 단계가 추가되어 비용이 증가한다. 실리콘보다 밴드갭이 큰 다른 반도체 재료를 사용하는 방법도 있으나, 2020년 현재 이러한 재료와 공정은 실리콘보다 비용이 훨씬 높다.
누설 전류 관리는 활성 전력 관리보다 더 까다로운데, 로직의 전원을 차단하기 전에 저장된 데이터를 누설이 적은 다른 저장 공간으로 옮겨야 하기 때문이다. 일부 CPU[11]는 이를 위해 특수한 플립플롭을 사용한다. 이 플립플롭은 빠르지만 누설이 많은 저장 셀과 느리고 크지만 누설이 적은 셀을 함께 가지고 있으며, 각각 다른 전원 공급 장치에 연결된다. CPU가 절전 모드(예: 정지 상태에서 인터럽트를 기다리는 경우)로 들어가면 데이터가 저누설 셀로 옮겨지고 다른 셀의 전원은 차단된다. CPU가 저전력 모드에서 해제되면(예: 인터럽트 발생 시) 과정이 반대로 진행된다.
과거 설계에서는 CPU 상태를 메모리나 디스크에 복사했으며, 때로는 이를 위한 특수 소프트웨어를 사용하기도 했다. 매우 단순한 임베디드 시스템의 경우, 전력을 절약한 후 단순히 시스템을 다시 시작하는 경우도 있다.
5. 컴퓨터와의 통합
현대의 모든 CPU는 제어 장치를 통해 컴퓨터 시스템의 다른 구성 요소들과 연결된다. 주요 연결 방식으로는 버스 컨트롤러, 인터럽트 컨트롤러, 캐시 컨트롤러 등이 있으며, 제어 장치는 이들을 제어하여 메모리 접근, 입출력 처리, 인터럽트 대응, 캐시 관리 등 시스템 전반의 동작을 조율한다.
- 버스 컨트롤러: 제어 장치는 버스 컨트롤러를 통해 메모리 및 입출력 장치와의 데이터 교환을 관리한다. 현대 컴퓨터는 메모리와 입출력에 동일한 버스 인터페이스를 사용하는 메모리 맵 I/O 방식을 주로 사용하지만, x86 PC처럼 별도의 입출력 버스를 사용하는 경우도 있다.
- 인터럽트 컨트롤러: 외부 장치나 내부 이벤트로부터 발생하는 인터럽트 신호를 처리하고, 제어 장치가 이에 적절히 대응하도록 한다.
- 캐시 컨트롤러: CPU와 주 메모리 사이의 속도 차이를 줄이기 위한 캐시 메모리를 관리하며, 특히 여러 CPU가 자원을 공유하는 환경에서 데이터 일관성을 유지하는 역할을 한다.
과거의 컴퓨터 시스템에서는 제어 장치가 입출력 기능을 직접 내장하기도 했다. 예를 들어, 많은 초기 컴퓨터들은 제어 장치가 직접 제어하는 스위치와 표시등이 있는 전면 패널을 통해 프로그래머가 직접 프로그램을 입력하고 디버깅할 수 있었다. 이후 이 전면 패널은 주로 운영 체제를 디스크에서 읽어오기 위한 작은 부트스트랩 프로그램을 입력하는 데 사용되었으나, 점차 읽기 전용 메모리(ROM)에 저장된 부트스트랩 프로그램으로 대체되었다.
PDP-8과 같은 일부 컴퓨터 모델은 입출력 장치가 제어 장치의 메모리 읽기/쓰기 로직을 공유하는 데이터 버스 설계를 채택하여 고속 입출력 컨트롤러의 복잡성과 비용을 줄였다.[12] Xerox Alto는 거의 모든 입출력 작업을 처리하는 멀티태스킹 마이크로프로그래밍 제어 장치를 사용하여 적은 하드웨어 로직으로 다양한 기능을 구현했다.[13] 이 제어 장치는 입출력 장치의 복잡한 로직뿐만 아니라 컴퓨터 시스템과의 통합 로직까지 마이크로프로그램으로 처리했으며, 마이크로프로그램은 필요에 따라 다시 작성하고 설치할 수 있었다.
5. 1. 버스 컨트롤러
현대의 모든 CPU에는 컴퓨터의 다른 부분들과 연결을 담당하는 제어 로직이 있다. 현대 컴퓨터에서는 이 역할을 주로 버스 컨트롤러가 맡는다. 명령어가 메모리를 읽거나 쓸 필요가 있을 때, 제어 장치는 버스를 직접 제어하거나 버스 컨트롤러를 통해 제어한다.많은 현대 컴퓨터는 메모리와 입출력 장치에 접근할 때 동일한 버스 인터페이스를 사용하는데, 이를 메모리 맵 I/O 방식이라고 한다. 이 방식에서는 프로그래머에게 입출력 장치의 레지스터가 특정 메모리 주소에 할당된 숫자처럼 보인다. 반면, x86 기반 PC 등에서는 입출력 명령어를 통해 접근하는 별도의 입출력 버스를 사용하는 이전 방식을 사용하기도 한다.
5. 2. 인터럽트 컨트롤러
현대의 CPU는 인터럽트 컨트롤러를 내장하는 경우가 많다. 인터럽트 컨트롤러는 시스템 버스를 통해 들어오는 인터럽트 신호를 처리하는 역할을 한다. 처리된 신호는 제어 장치로 전달되며, 제어 장치는 이 인터럽트에 대응하여 필요한 작업을 수행한다.제어 장치는 인터럽트를 처리하는 방식에 따라 두 가지 방식으로 설계될 수 있다. 빠른 응답이 중요할 경우, 제어 장치는 진행 중이던 작업을 중단하고 인터럽트를 먼저 처리하도록 설계된다. 이 경우, 처리 중이던 작업은 인터럽트 처리가 끝난 후 마지막으로 완료된 명령어 다음부터 다시 시작된다. 반면, 시스템의 단순성이나 안정성이 더 중요하거나, 더 많은 작업을 완료해야 하는 상황에서는 제어 장치가 진행 중인 작업을 모두 마친 후에 인터럽트를 처리하도록 설계된다. 작업을 완료한 후 처리하는 방식은 마지막으로 완료된 명령어의 위치를 별도로 저장할 필요가 없어 비용이 저렴하고, 관리해야 할 상태 정보가 적어 단순하며 안정적이라는 장점이 있다. 또한, 진행 중이던 작업이 중단되지 않아 작업 낭비가 적다.
5. 3. 캐시 컨트롤러
캐시 메모리를 관리하기 위한 캐시 컨트롤러가 존재한다. 캐시 컨트롤러와 관련 캐시 메모리는 현대 고성능 CPU의 물리적 구성 요소 중 가장 큰 비중을 차지하기도 한다. 특히 여러 CPU가 메모리, 버스, 또는 캐시를 공유하는 시스템 환경에서는 데이터 일관성 유지가 필수적이다. 이러한 환경에서 제어 로직의 일부인 캐시 컨트롤러는 다른 CPU와 통신하여 특정 CPU가 오래된(stale) 데이터를 사용하지 않도록 데이터 일관성을 유지하는 핵심 역할을 수행한다.참조
[1]
간행물
First Draft of a Report on the EDVAC
http://qss.stanford.[...]
Moore School of Electrical Engineering, University of Pennsylvania
[2]
웹사이트
Computer Organization - Control Unit and design
https://www.geeksfor[...]
2018-09-24
[3]
서적
The RISC V Instruction Set Manual
https://content.risc[...]
RISC-V Foundation
2017
[4]
서적
Power ISA(tm)
https://ibm.ent.box.[...]
IBM
2019-12-26
[5]
서적
Design of a Computer: The CDC 6600
https://archive.org/[...]
Scott, Foreman and Co.
1970
[6]
웹사이트
Libre RISC-V M-Class
https://www.crowdsup[...]
2020-01-16
[7]
웹사이트
RISC-V HW Dev, 6600-style out-of-order scoreboard
https://groups.googl[...]
RISC-V Foundation
2020-01-16
[8]
웹사이트
BOOM Docs, Rocketship SOC Generator
https://docs.boom-co[...]
2020-01-16
[9]
서적
Introduction to MAXQ Architecture
https://www.maximint[...]
Maxim Integrated Inc.
2019-12-26
[10]
서적
ARM Technical Reference, Cortex
ARM Ltd
[11]
서적
The ARM(tm) Technical Reference Manual
ARM Ltd.
[12]
서적
PDP-8L Maintenance Manual
http://bitsavers.tra[...]
Digital Equipment Corp.
2019-12-26
[13]
서적
Alto Hardware Manual
http://bitsavers.inf[...]
Xerox
1976
[14]
웹사이트
MICRO-PROGRAMMED VERSUS HARDWIRED CONTROL UNITS;
http://www.cs.bingha[...]
2017-02-17
[15]
학술
Teaching computer design using virtual prototyping
2003-05
[16]
서적
Logic synthesis for FSM based control units / Alexander Barkalov and Larysa Titarenko
Springer
[17]
서적
Synthesis of compositional microprogram control units for programmable devices
University of Zielona Góra
[18]
서적
Logic synthesis for FSM based control units / Alexander Barkalov and Larysa Titarenko
Springer
[19]
서적
Synthesis of compositional microprogram control units for programmable devices
University of Zielona Góra
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com