웹 크롤러
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
웹 크롤러는 웹 상의 정보를 수집하는 자동화된 프로그램으로, 웹 스파이더, 봇, 웹 로봇 등 다양한 이름으로 불린다. 웹 크롤러는 선택, 재방문, 예의, 병렬화 정책 등의 조합으로 작동하며, 선택 정책은 어떤 페이지를 다운로드할지 결정하고, 재방문 정책은 페이지 변경 사항을 확인할 시기를, 예의 정책은 웹사이트 과부하를 방지하는 방법을, 병렬화 정책은 분산 크롤러를 조정하는 방법을 정의한다. 웹 크롤러는 URL 정규화, 링크 제한, 집중 크롤링 등의 기술을 사용하며, robots.txt 프로토콜을 통해 웹사이트 소유자가 크롤링을 제어할 수 있다. 딥 웹 크롤링을 위해 스크린 스크래핑과 AJAX 처리 기술이 사용되며, 크롤러는 사용자 에이전트 필드를 통해 식별된다. 주요 웹 크롤러로는 구글봇, 빙봇, 야후! 슬러프 등이 있으며, 오픈 소스 및 상용 크롤러도 존재한다.
더 읽어볼만한 페이지
- 웹 크롤러 - Wget
Wget은 HTTP, HTTPS, FTP 프로토콜을 지원하여 네트워크를 통해 파일을 다운로드하는 자유 소프트웨어로, 명령 줄 인터페이스를 사용하며, 불안정한 네트워크 환경에서도 안정적인 다운로드와 웹사이트 미러링 기능을 제공한다. - 웹 크롤러 - 아파치 너치
아파치 너치는 자바 기반의 오픈 소스 웹 크롤러 및 검색 엔진 프레임워크이며, 모듈식 아키텍처를 통해 플러그인 개발을 지원하고, 2010년부터 아파치 소프트웨어 재단의 독립적인 최상위 프로젝트로 운영된다. - 검색 엔진 소프트웨어 - 아파치 루씬
아파치 루씬은 더그 커팅이 개발한 오픈 소스 전문 검색 라이브러리이며, 텍스트 색인 및 검색 기능을 제공하여 웹 검색 엔진, 퍼지 검색, 추천 시스템 구현 등에 사용된다. - 검색 엔진 소프트웨어 - 증분 검색
증분 검색은 사용자가 검색어를 입력하는 즉시 결과를 보여주는 사용자 인터페이스 방법으로, 자동 완성, 입력 중 검색, 타입어헤드 검색 등으로 불리며 사용자의 노력을 줄여준다. - 검색 엔진 - 페이지랭크
페이지랭크는 래리 페이지와 세르게이 브린이 개발한 알고리즘으로, 하이퍼링크로 연결된 문서 집합에서 웹 페이지의 상대적 중요도를 측정하며, 링크를 투표로 간주하여 페이지 순위를 재귀적으로 결정하고, 구글 검색 엔진의 초기 핵심 알고리즘으로 활용되었으며, 다양한 분야에서 활용된다. - 검색 엔진 - 울프럼 알파
울프럼 알파는 자연어 처리 기반 지식 엔진으로, 텍스트 입력을 통해 질문에 대한 답변과 복잡한 계산, 통계 분석, 금융 계산 등의 연산 결과를 제공하고 시각화한다.
| 웹 크롤러 | |
|---|---|
| 기본 정보 | |
| 유형 | 인터넷 봇 |
| 용도 | 자동화된 웹 브라우징 |
| 기능 | 웹 페이지 콘텐츠 수집 링크 추출 데이터베이스 구축 (검색 엔진) |
| 기술적 정보 | |
| 작동 방식 | 시드 URL에서 시작 링크 따라가며 페이지 방문 콘텐츠 파싱 및 저장 새로운 링크 발견 및 반복 |
| 구현 | 다양한 프로그래밍 언어 사용 (예: 파이썬, 자바, C++) |
| 프로토콜 | HTTP, HTTPS |
| 윤리적 및 기술적 고려 사항 | |
| robots.txt | 웹사이트 접근 제한 규칙 준수 |
| 과부하 방지 | 웹 서버에 과도한 요청을 보내지 않도록 속도 제한 |
| 사용자 에이전트 | HTTP 헤더에 봇 정보 명시 |
| 개인 정보 보호 | 개인 정보 수집 및 사용에 대한 규정 준수 |
| 사용 예시 | |
| 검색 엔진 | 구글, 네이버, 다음 등의 검색 결과 수집 및 색인 |
| 웹 아카이브 | 웨이백 머신과 같은 서비스에서 웹 페이지 보관 |
| 데이터 마이닝 | 특정 정보 추출 및 분석 |
| 모니터링 | 웹사이트 변경 사항 감지 |
| 관련 용어 | |
| 다른 이름 | 웹 스파이더 앤트 자동 인덱서 |
| 유사 기술 | 웹 스크래퍼 API |
2. 용어
웹 크롤러는 다양한 이름으로 불린다. 웹 스파이더[51][2], 앤트[51][2], 오토매틱 인덱서[52](또는 자동 색인기[3]), 웹 스커터[53][4] 등이 대표적이다. 특히 FOAF 소프트웨어 관련 문맥에서는 '웹 스커터'라고 부르기도 한다.[4] 이 외에도 봇(bots), 웜(worms), 웹 로봇(web robot) 등의 용어도 사용된다.[51]
웹 크롤러의 작동 방식은 다음과 같은 여러 정책들의 조합으로 결정된다.[54][7]
3. 크롤링 정책
웹 크롤러는 처음에 주어진 URL 목록, 즉 '시드(시드)'를 가지고 시작한다. 크롤러는 이 URL들을 방문하여 해당 웹 서버와 통신하고, 페이지 내의 모든 하이퍼링크를 식별하여 '크롤 프론티어'라는 방문 대상 목록에 추가한다. 프론티어의 URL들은 위에서 언급된 정책들에 따라 재귀적으로 방문된다. 만약 크롤러가 웹사이트를 아카이빙하는 경우, 수집한 정보를 복사하여 저장한다. 이렇게 저장된 아카이브는 일반적으로 실제 웹에서처럼 보고 읽고 탐색할 수 있도록 '스냅샷' 형태로 보존된다.[5] 아카이브는 '저장소'라고 불리며, 웹 페이지 컬렉션을 저장하고 관리하는 역할을 한다. 저장소는 크롤러가 수집한 웹 페이지의 최신 버전을 보관한다.
웹은 방대한 양의 정보를 담고 있으며 끊임없이 변화하기 때문에, 크롤러는 주어진 시간 안에 제한된 수의 페이지만 다운로드할 수 있다. 따라서 어떤 페이지를 먼저 방문할지 우선순위를 정하는 것이 중요하다. 또한, 서버 측 소프트웨어에 의해 동적으로 생성되는 URL이 많아지면서 중복 콘텐츠를 피하는 것도 중요한 과제가 되었다. 예를 들어, 간단한 온라인 사진 갤러리에서도 사용자의 선택 옵션에 따라 동일한 콘텐츠를 보여주는 수십 개의 다른 URL이 생성될 수 있다. 이러한 문제들과 대역폭과 같은 자원의 제약 때문에, 웹을 효과적으로 크롤링하기 위해서는 신중하게 설계된 정책들이 필수적이다.[6]
3. 1. 선택 정책 (Selection Policy)
웹 크롤러의 행동은 여러 정책의 조합으로 결정되는데,[54] 그중 선택 정책은 어떤 페이지를 다운로드할지 결정하는 규칙이다. 웹의 방대한 크기와 빠른 변화율, 그리고 대역폭과 같은 자원의 제약 때문에 크롤러는 주어진 시간 안에 모든 페이지를 방문할 수 없다.[6] 따라서 어떤 페이지를 먼저 방문하고 다운로드할지 우선순위를 정하는 것이 매우 중요하다. 현재 웹의 규모를 고려할 때, 대규모 검색 엔진조차도 웹 전체의 일부만을 인덱싱할 수 있다.[8][9] 따라서 다운로드하는 페이지들이 무작위 표본이 아니라, 사용자가 찾고자 하는 정보와 관련성이 높은 페이지들을 포함하도록 하는 것이 바람직하다.
이를 위해 웹 페이지의 중요도를 평가하는 지표가 필요하다. 페이지의 중요도는 내용 자체의 품질(내재적 품질), 다른 페이지로부터 받는 링크나 방문 횟수와 같은 인기(외재적 특성), 또는 URL 자체의 특성(예: 특정 최상위 도메인이나 웹사이트 내부 페이지) 등 다양한 요소를 기반으로 평가될 수 있다. 좋은 선택 정책을 설계하는 것은 어려운 문제인데, 크롤링 과정에서는 전체 웹 페이지 정보를 알 수 없으므로 부분적인 정보만을 가지고 결정을 내려야 하기 때문이다.
다양한 선택 정책 전략이 연구되어 왔다.3. 1. 1. 링크 제한
웹 크롤러는 초기에 주어진 URL 목록, 즉 '시드'를 가지고 시작한다.[5] 이 URL들을 방문하여 웹 서버와 통신하고, 해당 페이지 내의 모든 하이퍼링크를 식별하여 '크롤 프론티어'라는 방문 대상 목록에 추가한다. 이 목록의 URL들은 정해진 정책에 따라 재귀적으로 방문된다.[5]
웹의 방대한 크기 때문에 크롤러는 주어진 시간 안에 제한된 수의 페이지만 다운로드할 수밖에 없어, 어떤 페이지를 먼저 방문할지 우선순위를 정해야 한다. 또한 웹 페이지는 빠르게 변하기 때문에 크롤러가 방문했을 때와 내용이 다르거나 이미 삭제되었을 가능성도 고려해야 한다.
서버 측 소프트웨어가 동적으로 URL을 생성하는 경우가 많아지면서, 크롤러가 중복 콘텐츠를 피하는 것이 중요한 과제가 되었다. 예를 들어, 간단한 온라인 사진 갤러리에서 사용자가 선택할 수 있는 이미지 정렬 방식, 썸네일 크기, 파일 형식 등의 옵션 조합에 따라 동일한 콘텐츠에 접근하는 수십 개의 서로 다른 URL이 생성될 수 있다. 이러한 수학적 조합은 크롤러가 고유한 콘텐츠를 효율적으로 찾는 것을 어렵게 만든다.
Edwards 등은 "크롤링을 위한 대역폭은 무한하지도 않고 무료도 아니므로, 웹 페이지의 품질이나 최신성을 합리적으로 유지하려면 확장 가능하면서도 효율적인 방식으로 웹을 크롤링하는 것이 필수적이다."[6]라고 지적했다. 이처럼 제한된 자원 안에서 최대한 효율적으로 정보를 수집하기 위해 크롤러는 다음에 방문할 페이지를 신중하게 선택해야 한다.
이를 위해 크롤러는 특정 종류의 파일만 수집하도록 제한될 수 있다. 예를 들어, HTML 페이지만 찾고 다른 MIME 유형의 파일은 피하려고 할 수 있다. 크롤러는 HTTP HEAD 요청을 보내 웹 리소스의 MIME 유형을 미리 확인하고, 필요한 경우에만 GET 요청으로 전체 리소스를 요청하는 방식을 사용할 수 있다. 또는 URL 끝이 `.html`, `.htm`, `.php` 등 특정 확장자로 끝나는 경우에만 리소스를 요청하는 더 간단한 방법을 사용하기도 한다. 그러나 이 방식은 의도치 않게 많은 HTML 웹 리소스를 건너뛸 수 있는 단점이 있다.
또한, 크롤러는 "?" 기호가 포함된 URL(주로 동적으로 생성되는 페이지를 의미) 요청을 피함으로써 스파이더 트랩(크롤러가 웹사이트 내에서 무한히 많은 URL을 다운로드하게 만드는 구조)을 피하려 할 수 있다. 하지만 웹사이트가 사용자 친화적인 URL을 제공하기 위해 URL 재작성 기술을 사용하는 경우, 겉보기에는 단순해 보이는 URL도 실제로는 동적으로 생성된 콘텐츠일 수 있어 이 전략이 항상 효과적인 것은 아니다.
3. 1. 2. URL 정규화
크롤러는 동일한 리소스를 두 번 이상 크롤링하는 것을 방지하기 위해 일반적으로 URL 정규화의 일종을 수행한다. ''URL 정규화''라는 용어는 ''URL 표준화''라고도 하며, URL을 일관된 방식으로 수정하고 표준화하는 과정을 의미한다. URL을 소문자로 변환하거나, "." 및 ".." 세그먼트를 제거하거나, 비어 있지 않은 경로(path) 구성 요소 뒤에 슬래시(/)를 추가하는 등 여러 유형의 정규화가 수행될 수 있다.[18]
3. 1. 3. 경로 상향 크롤링
일부 크롤러는 특정 웹사이트에서 가능한 많은 리소스를 다운로드하거나 업로드하려고 시도한다. 이를 위해 크롤링하려는 각 URL의 모든 상위 경로를 탐색하는 '''경로 상향 크롤러'''(Path-ascending crawler영어)가 도입되었다.[19] 예를 들어, `http://llama.org/hamster/monkey/page.html`이라는 시작 URL이 주어지면, 이 크롤러는 `/hamster/monkey/`, `/hamster/`, 그리고 `/` 경로까지 거슬러 올라가 크롤링을 시도한다. 코시(Cothey)는 경로 상향 크롤러가 일반적인 크롤링 방식으로는 찾기 어려운, 즉 외부에서 들어오는 링크가 없는 고립된 리소스를 찾는 데 매우 효과적이라는 사실을 발견했다.
3. 1. 4. 집중 크롤링
크롤러에게 특정 페이지의 중요도는 주어진 검색어(쿼리)와의 유사성 정도로 표현될 수 있다. 이처럼 서로 유사한 페이지만 선택적으로 다운로드하려는 웹 크롤러를 '''집중 탐색기'''(focused crawler) 또는 '''주제별 탐색기'''(topical crawler)라고 부른다. 이러한 주제별 탐색 및 집중 탐색의 개념은 필리포 멘처[20][21]와 Soumen Chakrabarti 등[22]에 의해 처음 소개되었다.
집중 탐색의 주요 과제는 웹 크롤러가 실제로 페이지를 내려받기 전에, 해당 페이지의 내용이 주어진 검색어와 얼마나 유사할지 미리 예측하는 것이다. 이를 예측하는 한 가지 방법은 해당 페이지를 가리키는 링크의 앵커 텍스트를 분석하는 것이다. 이 방식은 웹 초창기에 Pinkerton[23]이 개발한 첫 웹 크롤러에서 사용되었다. 이후 Diligenti 등[24]은 이미 방문했던 페이지들의 전체 내용을 활용하여, 아직 방문하지 않은 페이지와 검색어 간의 유사성을 추론하는 방법을 제안했다. 집중 탐색의 성능은 검색하려는 특정 주제와 관련된 링크가 웹상에 얼마나 풍부하게 존재하는지에 크게 영향을 받는다. 또한, 집중 탐색은 탐색을 시작할 초기 지점(시작점)을 얻기 위해 일반적인 웹 검색 엔진에 의존하는 경우가 많다.
3. 2. 재방문 정책 (Re-visit Policy)
웹은 매우 동적인 특성을 가지며, 웹의 일부를 크롤링하는 데 몇 주 또는 몇 달이 걸릴 수 있다. 웹 크롤러가 크롤링을 완료할 때까지 생성, 업데이트, 삭제 등 많은 변화가 발생할 수 있다.[5]
검색 엔진의 관점에서, 이러한 변화를 감지하지 못해 리소스의 오래된 사본을 가지게 되면 비용이 발생한다. 이를 평가하기 위해 주로 사용되는 지표는 신선도(Freshness)와 나이(Age)이다.[29]
:
:
코프만 등은 웹 크롤러가 페이지가 오래된 상태로 유지되는 시간을 최소화해야 한다고 제안하며 신선도와 유사한 목표를 제시했다. 또한 웹 크롤링 문제를 웹 크롤러가 서버이고 웹 사이트가 큐인 다중 큐, 단일 서버 폴링 시스템으로 모델링할 수 있다고 언급했다. 이 모델에서 폴링 시스템 고객의 평균 대기 시간은 웹 크롤러의 평균 나이와 같다.[30]
크롤러의 목표는 수집한 페이지들의 평균 신선도를 가능한 한 높게 유지하거나, 평균 나이를 가능한 한 낮게 유지하는 것이다. 이 두 목표는 동일하지 않다. 신선도는 얼마나 많은 페이지가 오래되었는지에만 관심을 두지만, 나이는 페이지의 로컬 사본이 얼마나 오래되었는지에 관심을 둔다.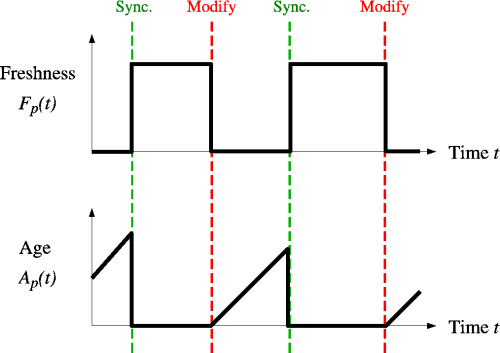
Cho와 Garcia-Molina는 두 가지 간단한 재방문 정책을 연구했다.[31]
두 경우 모두, 페이지의 반복 크롤링 순서는 무작위 또는 고정된 순서로 수행될 수 있다.
Cho와 Garcia-Molina는 시뮬레이션된 웹과 실제 웹 크롤링 모두에서 평균 신선도 측면에서 균일 정책이 비례 정책보다 성능이 우수하다는 놀라운 결과를 증명했다.[31] 이는 웹 크롤러가 제한된 시간 내에 크롤링할 수 있는 페이지 수가 한정되어 있기 때문이다. 비례 정책은 자주 변경되는 페이지에 새로운 크롤링 자원을 과도하게 할당하여 덜 자주 업데이트되는 페이지를 희생시키며, 자주 변경되는 페이지의 신선도는 덜 자주 변경되는 페이지보다 짧은 기간 동안만 유지되기 때문이다. 즉, 비례 정책은 자주 업데이트되는 페이지에 더 많은 자원을 할당하지만, 전체적인 평균 신선도는 오히려 감소시킨다.
따라서 신선도를 개선하기 위해서는 크롤러가 너무 자주 변경되는 페이지에 대해 일종의 페널티를 부여해야 한다.[32] 최적의 재방문 정책은 균일 정책도, 비례 정책도 아니다. 평균 신선도를 높게 유지하는 최적의 방법은 너무 자주 변경되는 페이지를 무시하는 것이며, 평균 나이를 낮게 유지하는 최적의 방법은 각 페이지의 변경 속도에 따라 단조적으로(그리고 하위 선형적으로) 증가하는 접근 빈도를 사용하는 것이다. 두 경우 모두, 최적의 방법은 비례 정책보다는 균일 정책에 더 가깝다. 코프만 등이 언급했듯이, "예상된 노후화 시간을 최소화하기 위해 특정 페이지에 대한 접근은 가능한 한 고르게 유지되어야 한다".[30]
재방문 정책에 대한 명시적 공식은 일반적으로 얻기 어렵지만, 페이지 변경 분포에 따라 수치적으로 얻을 수 있다. Cho와 Garcia-Molina는 페이지 변경을 설명하는 데 지수 분포가 적합함을 보였고,[32] 이페이로티스 등은 통계적 도구를 사용하여 이 분포에 영향을 미치는 매개변수를 찾는 방법을 제시했다.[33]
여기서 논의된 재방문 정책들은 모든 페이지를 품질 측면에서 동일하게 간주한다는 한계가 있다("웹의 모든 페이지는 동일한 가치가 있음"). 이는 현실적인 상황이 아니므로, 더 나은 크롤링 정책을 위해서는 웹 페이지의 품질에 대한 추가 정보를 고려해야 한다.
3. 3. 공손성 정책 (Politeness Policy)
공손성 정책은 웹 크롤러가 웹사이트에 과부하를 주는 것을 막기 위한 정책이다.[54] 웹 크롤러는 사람의 검색 속도보다 훨씬 빠르고 더 깊이 데이터를 검색할 수 있으므로, 웹사이트의 성능에 심각한 영향을 미칠 수 있다. 크롤러 하나가 초당 여러 번 요청을 보내거나 대용량 파일을 내려받으면, 웹 서버는 여러 크롤러의 요청을 처리하기 어려워질 수 있다.
코스터(Koster)는 웹 크롤러 사용이 여러 면에서 유용하지만, 다음과 같은 사회적 비용이 발생한다고 지적했다.[34]
이러한 문제에 대한 부분적인 해결책으로 robots.txt 프로토콜이 있다. 이 표준은 웹 서버 관리자가 크롤러가 접근해서는 안 되는 서버의 특정 부분을 명시할 수 있게 한다.[35] 이 표준에는 방문 간격에 대한 직접적인 제안은 없지만, 방문 간격을 두는 것이 서버 과부하를 막는 가장 효과적인 방법이다. 최근 구글, Ask Jeeves, MSN, 야후!와 같은 주요 상업 검색 엔진들은 robots.txt 파일에 `Crawl-delay:` 매개변수를 사용하여 요청 사이에 몇 초를 기다려야 하는지 지정할 수 있도록 지원한다.
처음 제안된 연속적인 페이지 로드 사이의 간격은 60초였다.[36] 하지만 수십만 페이지가 넘는 대규모 웹사이트의 경우, 이 속도로는 전체 사이트를 다운로드하는 데 몇 달이 걸릴 수 있어 비효율적이다. 실제로는 다양한 간격이 사용된다. 예를 들어, Cho는 10초 간격을 사용했고,[31] WIRE 크롤러는 기본값으로 15초를 사용한다.[37] MercatorWeb 크롤러는 적응형 공손성 정책을 사용하여, 특정 서버에서 문서를 다운로드하는 데 ''t''초가 걸렸다면 다음 페이지를 다운로드하기 전에 10''t''초 동안 기다린다.[38] Dill 등은 1초 간격을 사용하기도 했다.[39]
접근 로그를 분석한 일화적인 증거에 따르면, 알려진 크롤러들의 실제 접근 간격은 20초에서 3~4분 사이로 다양하다. 연구 목적으로 웹 크롤러를 사용하는 경우, 비용-편익 분석과 함께 어디를 얼마나 빨리 크롤링할지에 대한 윤리적 고려가 필요하다.[40]
아무리 정중하게 크롤링 정책을 지키고 웹 서버 과부하를 피하기 위한 조치를 취하더라도, 일부 웹 서버 관리자로부터 불만이 제기될 수 있다. 1998년 세르게이 브린과 래리 페이지는 구글 크롤러를 운영하면서 "50만 개 이상의 서버에 연결하는 크롤러를 실행하면 상당한 양의 이메일과 전화를 받게 된다. 온라인에 접속하는 사람들이 많기 때문에, 크롤러가 무엇인지 모르는 사람들이 항상 있는데, 이는 그들이 처음 본 크롤러이기 때문"이라고 언급하며 이러한 어려움을 토로했다.[41]
3. 4. 병렬화 정책 (Parallelization Policy)
병렬 크롤러는 여러 프로세스를 동시에 실행하여 웹 페이지를 수집하는 크롤러이다. 병렬 크롤링의 목표는 여러 프로세스를 사용함으로써 발생하는 추가적인 부담(오버헤드)을 최소화하면서 웹 페이지 다운로드 속도를 최대한 높이는 것이다. 또한, 같은 페이지를 여러 번 다운로드하는 것을 방지하는 것도 중요한 목표이다.
동일한 웹 페이지를 두 번 이상 다운로드하는 것을 막기 위해서는, 크롤링 과정에서 새로 발견된 URL을 어떤 크롤링 프로세스에 할당할지에 대한 명확한 정책이 필요하다. 왜냐하면 서로 다른 크롤링 프로세스가 동시에 같은 URL을 발견할 수 있기 때문이다.
4. 아키텍처
웹 크롤러는 방문할 URL 목록으로 시작한다. 이 초기 URL 목록을 시드(seed)라고 부른다. 크롤러는 이 URL들을 방문하여 해당 웹 서버와 통신하고, 응답으로 받은 웹 페이지 내의 모든 하이퍼링크를 식별한다. 식별된 링크들은 다시 방문할 URL 목록, 즉 크롤 프론티어(crawl frontier)에 추가된다. 프론티어에 있는 URL들은 정해진 정책에 따라 재귀적으로 방문된다. 만약 크롤러가 웹사이트 아카이빙을 수행 중이라면, 수집한 정보를 복사하여 저장한다. 이렇게 생성된 아카이브는 일반적으로 실제 웹에서처럼 보고, 읽고, 탐색할 수 있도록 저장되지만, 특정 시점의 '스냅샷' 형태로 보존된다.[5]
수집된 웹 페이지들은 저장소(repository)라고 불리는 곳에 보관 및 관리된다. 저장소는 HTML 페이지를 포함한 웹 페이지 컬렉션을 저장하며, 각 페이지는 보통 별개의 파일로 저장된다. 저장소는 현대의 데이터베이스와 유사한 시스템이지만, 데이터베이스 시스템이 제공하는 모든 기능이 반드시 필요하지는 않다. 저장소는 크롤러가 수집한 웹 페이지의 가장 최신 버전을 보관한다.
웹의 방대한 크기 때문에 크롤러는 주어진 시간 내에 제한된 수의 페이지만 다운로드할 수 있다. 따라서 어떤 페이지를 먼저 다운로드할지 우선순위를 정하는 것이 중요하다. 웹 페이지는 빠르게 변하기 때문에, 크롤러가 방문하기 전에 이미 내용이 업데이트되거나 삭제되었을 수도 있다.
또한, 서버 측 소프트웨어에 의해 동적으로 생성되는 URL의 수가 많아지면서 크롤러가 중복 콘텐츠를 피하는 것이 어려워졌다. 예를 들어, HTTP GET 요청의 매개변수 조합은 무수히 많을 수 있으며, 이 중 극히 일부만이 실제로 고유한 콘텐츠를 반환한다. 간단한 온라인 사진 갤러리를 예로 들면, 이미지 정렬 방식 4가지, 썸네일 크기 3가지, 파일 형식 2가지, 사용자 생성 콘텐츠 비활성화 옵션 등을 URL 매개변수로 조합할 경우, 동일한 콘텐츠에 접근할 수 있는 URL이 48개나 생길 수 있다. 이러한 수학적 조합은 크롤러가 고유한 콘텐츠를 찾기 위해 수많은 URL 조합을 처리해야 하는 문제를 야기한다.
Edwards 등은 "크롤링을 수행하기 위한 대역폭은 무한하지도 않고 무료도 아니므로, 웹 페이지의 품질이나 최신성을 합리적으로 유지하려면 확장 가능할 뿐만 아니라 효율적인 방식으로 웹을 크롤링하는 것이 필수적이다."[6]라고 지적했다. 따라서 크롤러는 매 단계에서 다음에 방문할 페이지를 신중하게 선택해야 한다.
효과적인 크롤링 전략뿐만 아니라, 고도로 최적화된 아키텍처 역시 웹 크롤러에게 필수적이다.
Shkapenyuk와 Suel은 다음과 같이 언급했다:[42]
> 비록 짧은 시간 동안 초당 몇 개의 페이지를 다운로드하는 느린 크롤러를 구축하는 것은 비교적 쉬운 일이지만, 몇 주에 걸쳐 수억 개의 페이지를 다운로드할 수 있는 고성능 시스템을 구축하는 것은 시스템 설계, I/O 및 네트워크 효율성, 견고성 및 관리 용이성 측면에서 많은 어려움을 제시합니다.
웹 크롤러는 검색 엔진의 핵심 구성 요소이며, 그 알고리즘과 아키텍처에 대한 세부 사항은 대부분 기업 기밀로 취급된다. 크롤러 설계가 공개되더라도, 다른 연구자들이 동일한 작업을 재현하기 어렵게 만드는 중요한 세부 정보가 누락된 경우가 많다. 또한, 검색 엔진 스팸 문제 때문에 주요 검색 엔진들은 자신들의 순위 결정 알고리즘을 공개하는 것을 꺼린다.
5. 보안
대부분의 웹사이트 소유자는 자신의 페이지가 가능한 한 광범위하게 웹 검색 엔진에 색인되어 온라인상에서 잘 노출되기를 원한다. 하지만 웹 크롤링 과정에서 의도치 않은 문제가 발생할 수 있다. 예를 들어, 검색 엔진이 공개되어서는 안 되는 리소스까지 색인하거나, 보안에 취약한 소프트웨어 버전 정보가 담긴 페이지를 색인하게 되면 웹 애플리케이션 보안 침해나 데이터 유출로 이어질 위험이 있다. 이러한 방식으로 검색 엔진을 이용해 민감 정보를 찾는 것을 구글 해킹이라고도 한다.
이러한 위험을 줄이기 위해 웹사이트 소유자는 기본적인 웹 애플리케이션 보안 수칙을 따르는 것 외에도 추가적인 조치를 취할 수 있다. 대표적인 방법은 robots.txt 파일을 사용하여 검색 엔진 크롤러의 접근을 제어하는 것이다. 이를 통해 웹사이트의 공개적인 부분만 색인되도록 허용하고, 로그인 페이지나 회원 전용 페이지 같은 비공개 영역의 색인은 명시적으로 차단하여 해킹의 위험을 낮출 수 있다.
6. 딥 웹 크롤링
방대한 양의 웹 페이지는 딥 웹에 존재한다.[43] 이러한 페이지들은 일반적으로 데이터베이스에 쿼리를 제출해야만 접근할 수 있으며, 일반적인 크롤러는 해당 페이지로 연결되는 링크가 없으면 찾기 어렵다. 구글의 사이트맵 프로토콜과 mod oai[44]는 이러한 딥 웹 리소스를 검색할 수 있도록 설계된 방법들이다.
딥 웹 크롤링은 크롤러가 처리해야 할 웹 링크의 수를 증가시키는 경향이 있다. 일부 크롤러는 `<a href="URL">` 형식으로 명시된 URL만을 수집하는 반면, 구글봇과 같이 일부 경우에는 하이퍼텍스트 콘텐츠, 태그 또는 페이지 내 텍스트에 포함된 모든 종류의 링크 정보를 대상으로 웹 크롤링을 수행한다.
딥 웹 콘텐츠를 대상으로 하는 전략적인 접근 방식도 존재한다. 스크린 스크래핑이라는 기술은 특정 소프트웨어를 이용하여 주어진 웹 양식에 대해 자동으로 반복적인 쿼리를 수행하고, 그 결과 데이터를 집계하는 방식이다. 이 소프트웨어는 여러 웹사이트의 다양한 웹 양식에 걸쳐 사용될 수 있다. 한 웹 양식 제출 결과에서 얻은 데이터를 다른 웹 양식의 입력 값으로 활용함으로써, 기존 웹 크롤러로는 접근하기 어려웠던 딥 웹 내 정보의 연속성을 확보할 수 있다.[45]
한편, AJAX 기술로 구축된 웹 페이지는 웹 크롤러에게 어려움을 주는 요소 중 하나이다. 이에 구글 검색은 자사의 크롤러 봇이 인식하고 색인화할 수 있는 AJAX 호출 형식을 제안하기도 했다.[46]
7. 크롤러 식별
웹 크롤러는 일반적으로 HTTP 요청의 사용자 에이전트 필드를 사용하여 웹 서버에 자신을 식별한다. 웹사이트 관리자는 웹 서버의 로그를 검토하고 사용자 에이전트 필드를 통해 어떤 크롤러가 얼마나 자주 방문했는지 확인할 수 있다. 사용자 에이전트 필드에는 관리자가 크롤러에 대한 자세한 정보를 찾을 수 있는 URL이 포함될 수 있다. 웹 서버 로그 검토는 번거로운 작업이므로 일부 관리자는 웹 크롤러를 식별, 추적, 확인하는 도구를 사용한다. 하지만 스팸봇 및 기타 악성 웹 크롤러는 사용자 에이전트 필드에 식별 정보를 입력하지 않거나 웹 브라우저 또는 다른 잘 알려진 크롤러로 신원을 위장할 수 있다.
웹사이트 관리자는 필요한 경우 소유자에게 연락할 수 있도록 웹 크롤러가 스스로를 식별하는 것을 선호한다. 어떤 경우에는 크롤러가 실수로 크롤러 트랩에 갇히거나 웹 서버에 과부하를 걸 수 있으며, 이때 소유자는 크롤러를 중지해야 한다. 식별은 특정 웹 검색 엔진에서 웹 페이지를 언제 색인화할 수 있는지 알고 싶어하는 관리자에게도 유용하다.
8. 주요 웹 크롤러
웹 크롤러는 인터넷의 방대한 정보를 수집하기 위해 다양한 형태로 개발되고 운영된다. 대표적인 검색 엔진들이 자체 개발한 크롤러를 사용하는 것 외에도, 특정 목적에 맞게 설계된 여러 종류의 웹 크롤러가 존재한다.
초기 웹 환경을 탐색했던 월드 와이드 웹 웜[57]이나 웹크롤러(WebCrawler)부터 시작하여, 구글봇, 빙봇, Yahoo! Slurp 등 주요 검색 엔진의 크롤러들이 잘 알려져 있다. 이 외에도 분산 처리 기술을 활용한 FAST Crawler[55]나 WebRACE[56]와 같은 특수한 목적의 크롤러, 그리고 GM Crawl, PolyBot, RBSE, Swiftbot, WebFountain 등 다양한 웹 크롤러들이 존재한다.
이러한 웹 크롤러들은 개발 및 운영 방식에 따라 상용, 오픈 소스, 특정 기업 내부용 등으로 분류될 수 있으며, 기술 발전과 서비스 변화에 따라 새로운 크롤러가 등장하거나 기존 크롤러가 사라지기도 한다. 주요 웹 크롤러의 상세한 분류와 설명은 아래 하위 섹션에서 확인할 수 있다.
8. 1. 상용 웹 크롤러
다음은 유료로 제공되는 웹 크롤러 목록이다.- 디프봇 (Diffbot) - 프로그래밍 방식의 일반 웹 크롤러로, API로 제공된다.
- SortSite - 웹사이트 분석용 크롤러로, 윈도우 및 맥 OS에서 사용할 수 있다.
- 스위프트봇(Swiftbot) - Swiftype의 웹 크롤러로, 서비스형 소프트웨어(SaaS)로 제공된다.
- 매니폴드 CF(아파치)
- 다운로드 닌자 (이프론티어, 다운로드용 소프트웨어(다운로더))
- GetHTMLW - 다운로더
- Wget - 다운로더
- 옥토파스
- 구글봇
8. 2. 오픈 소스 크롤러
- 아파치 너치: 자바로 작성되었으며 아파치 라이선스 하에 배포되는 확장성이 뛰어나고 확장 가능한 웹 크롤러이다. 아파치 하둡을 기반으로 하며 아파치 솔라 또는 엘라스틱서치와 함께 사용할 수 있다.
- 빙봇
- FAST Crawler[55]: 분산 크롤러
- Frontera
- 구글봇
- 그럽: 위키아 서치가 웹 크롤링에 사용했던 오픈 소스 분산 검색 크롤러였다.
- GM Crawl
- 헤리티릭스: 웹의 대규모 부분을 정기적으로 스냅샷을 보관하기 위해 설계된 인터넷 아카이브의 아카이브 품질 크롤러이다. 자바로 작성되었다.
- ht-//dig: 인덱싱 엔진에 웹 크롤러를 포함한다.
- HTTrack: 웹 크롤러를 사용하여 오프라인 보기를 위한 웹 사이트 미러를 만든다. C로 작성되었으며 GPL 하에 배포된다.
- mnoGoSearch: C로 작성되고 GPL 하에 라이선스된 크롤러, 인덱서 및 검색 엔진이다. (유닉스 계열 운영체제 전용)
- news-please
- 노르코넥스 웹 크롤러: 자바로 작성되었으며 아파치 라이선스 하에 배포되는 확장성이 뛰어난 웹 크롤러이다. 아파치 솔라, 엘라스틱서치, 마이크로소프트 애저 코그너티브 서치, 아마존 클라우드서치 등 다양한 저장소와 함께 사용할 수 있다.
- 옥토파스
- 오픈 서치 서버: GPL 하에 배포되는 검색 엔진 및 웹 크롤러 소프트웨어이다.
- PHP-Crawler
- PolyBot
- RBSE
- 스크래피: 파이썬으로 작성된 오픈 소스 웹 크롤러 프레임워크이다. (BSD 라이선스 하에 라이선스됨).
- 시크스: 무료 분산 검색 엔진이다. (AGPL 하에 라이선스됨).
- 스핑크스 (검색 엔진)
- 스톰크롤러: 아파치 스톰에서 낮은 지연 시간과 확장 가능한 웹 크롤러를 구축하기 위한 리소스 모음이다. (아파치 라이선스).
- Swiftbot
- tkWWW 로봇: tkWWW 웹 브라우저를 기반으로 한 크롤러이다. (GPL 하에 라이선스됨).
- 웹크롤러
- WebFountain
- WebRACE[56]
- GNU Wget: 명령줄 인터페이스로 작동하는 C로 작성된 크롤러이며 GPL 하에 배포된다. 일반적으로 웹 및 FTP 사이트 미러링에 사용된다.
- 월드 와이드 웹 웜[57]
- 자피안: C++로 작성된 검색 크롤러 엔진이다.
- YaCy: 피어 투 피어 네트워크의 원리를 기반으로 구축된 무료 분산 검색 엔진이다. (GPL 하에 라이선스됨).
- Yahoo! Slurp
- 매니폴드 CF (아파치)
- 다운로드 닌자 (이프론티어 개발, 다운로더)
- GetHTMLW (다운로더)
8. 3. In-house 웹 크롤러
- Applebot: 애플(Apple Inc.)의 웹 크롤러이다. 이는 Siri 및 기타 제품을 지원한다.[48]
- Baiduspider: 바이두의 웹 크롤러이다.
- Bingbot: 마이크로소프트의 Bing 웹 크롤러의 이름이다. 이는 ''Msnbot''을 대체했다.
- 다운로드 닌자: 이프론티어에서 개발한 다운로드용 소프트웨어(다운로더)이다.
- DuckDuckBot: DuckDuckGo의 웹 크롤러이다.
- FAST Crawler: 분산 크롤러이다.[55]
- GetHTMLW: 다운로더이다.
- GM Crawl
- Googlebot: C++와 파이썬으로 작성된 초기 아키텍처 버전에 대한 설명이 있다. 이 크롤러는 텍스트 파싱이 전체 텍스트 인덱싱과 URL 추출을 위해 수행되었기 때문에 인덱싱 프로세스와 통합되었다. 여러 크롤링 프로세스에서 가져올 URL 목록을 보내는 URL 서버가 있다. 파싱 과정에서 발견된 URL은 URL이 이전에 확인되었는지 확인하는 URL 서버로 전달되었다. 그렇지 않은 경우 URL이 URL 서버의 큐에 추가되었다.
- 매니폴드 CF(아파치(Apache))
- 옥토파스
- PolyBot
- RBSE
- Swiftbot
- WebCrawler: 웹의 하위 집합에 대한 최초의 공개용 전체 텍스트 색인을 구축하는 데 사용되었다. 이는 lib-WWW를 기반으로 페이지를 다운로드하고, 웹 그래프의 너비 우선 탐색을 위해 URL을 파싱하고 정렬하는 다른 프로그램을 사용했다. 또한 제공된 쿼리와 앵커 텍스트의 유사성을 기반으로 링크를 따르는 실시간 크롤러를 포함했다.
- WebFountain: C++로 작성된 분산형 모듈식 크롤러이다. Mercator와 유사하다.
- WebRACE[56]
- Wget: 다운로더이다.
- 월드 와이드 웹 웜[57]
- Xenon: 정부 세무 당국에서 사기를 감지하기 위해 사용하는 웹 크롤러이다.
- Yahoo! Slurp
8. 4. 과거의 웹 크롤러
- 월드 와이드 웹 웜: 문서 제목과 URL의 간단한 색인을 구축하는 데 사용된 크롤러였다. 이 색인은 grep 유닉스 명령어를 사용하여 검색할 수 있었다.[57]
- 야후! 슬러프(Yahoo! Slurp): 야후!가 빙봇을 사용하기 위해 마이크로소프트와 계약을 맺기 전까지 사용했던 야후! 검색 크롤러의 이름이었다.
- [https://web.archive.org/web/20020106130042/http://www.wolfbot.com/ WolfBot]: 2001년 캘리포니아 대학교 데이비스 캠퍼스에서 토목 공학을 전공한 매니 싱(Mani Singh)이 개발한 대규모 멀티 스레드 크롤러였다.
기타 과거의 웹 크롤러 및 관련 도구는 다음과 같다.
참조
[1]
웹사이트
Web Crawlers: Browsing the Web
https://webbrowsersi[...]
[2]
웹사이트
The TkWWW Robot: Beyond Browsing
http://archive.ncsa.[...]
NCSA
2010-11-21
[3]
논문
Information retrieval on the web
[4]
웹사이트
definition of scutter on FOAF Project's wiki
http://wiki.foaf-pro[...]
2009-12-13
[5]
서적
Web Archiving
https://www.springer[...]
Springer
2007-02-15
[6]
서적
Proceedings of the 10th international conference on World Wide Web
http://www10.org/cdr[...]
2007-01-25
[7]
간행물
Effective Web Crawling
http://chato.cl/rese[...]
University of Chile
2010-08-03
[8]
conference
The indexable web is more than 11.5 billion pages
ACM Press
[9]
논문
Accessibility of information on the web
1999-07-08
[10]
논문
Efficient Crawling Through URL Ordering
http://ilpubs.stanfo[...]
2009-03-23
[11]
문서
"Crawling the Web: Discovery and Maintenance of a Large-Scale Web Data"
http://oak.cs.ucla.e[...]
Department of Computer Science, Stanford University
2001-11
[12]
웹사이트
Breadth-first crawling yields high-quality pages
http://www10.org/cdr[...]
Elsevier Science
2001-05
[13]
conference
Adaptive on-line page importance computation
http://www2003.org/c[...]
ACM
2009-03-22
[14]
논문
UbiCrawler: a scalable fully distributed Web crawler
http://vigna.dsi.uni[...]
2009-03-23
[15]
서적
Algorithms and Models for the Web-Graph
2009-03-23
[16]
웹사이트
"Crawling a Country: Better Strategies than Breadth-First for Web Page Ordering."
http://chato.cl/pape[...]
ACM Press
2005
[17]
웹사이트
A Fast Community Based Algorithm for Generating Crawler Seeds Set
https://www.research[...]
Webist
2008-05
[18]
서적
Web Dynamics: Adapting to Change in Content, Size, Topology and Use
Springer
2006-05-09
[19]
논문
Web-crawling reliability
http://www.scit.wlv.[...]
[20]
웹사이트
ARACHNID: Adaptive Retrieval Agents Choosing Heuristic Neighborhoods for Information Discovery
http://informatics.i[...]
Morgan Kaufmann
2012-12-21
[21]
웹사이트
Adaptive Information Agents in Distributed Textual Environments
http://informatics.i[...]
ACM Press
2012-12-21
[22]
논문
Focused crawling: A new approach to topic-specific Web resource discovery
http://www.fxpal.com[...]
[23]
웹사이트
Finding what people want: Experiences with the WebCrawler
https://web.archive.[...]
1994
[24]
웹사이트
Focused crawling using context graphs
http://clgiles.ist.p[...]
2000
[25]
서적
Proceedings of the twelfth international workshop on Web information and data management - WIDM '12
[26]
서적
Proceedings of the 3rd Annual ACM Web Science Conference on - Web Sci '12
[27]
서적
Computational Science and Its Applications – ICCSA 2009
[28]
논문
SOF: A semi-supervised ontology-learning-based focused crawler
https://www.research[...]
[29]
conference
Synchronizing a database to improve freshness
http://www.cs.brown.[...]
ACM
2009-03-23
[30]
논문
Optimal robot scheduling for Web search engines
[31]
논문
Effective page refresh policies for Web crawlers
[32]
논문
Estimating frequency of change
[33]
웹사이트
Modeling and managing content changes in text databases
http://pages.stern.n[...]
2005-04
[34]
문서
Robots in the web: threat or treat?
1995
[35]
웹사이트
A standard for robot exclusion
http://www.robotstxt[...]
2007-11-07
[36]
웹인용
Guidelines for robots writers
http://www.robotstxt[...]
2005-04-22
[37]
논문
Balancing volume, quality and freshness in Web crawling
http://www.chato.cl/[...]
IOS Press Amsterdam
[38]
간행물
Mercator: A Scalable, Extensible Web Crawler
http://www.cindoc.cs[...]
2009-03-22
[39]
저널
Self-similarity in the web
http://www.mccurley.[...]
[40]
저널
Web crawling ethics revisited: Cost, privacy and denial of service
http://www.scit.wlv.[...]
[41]
저널
The anatomy of a large-scale hypertextual Web search engine
http://infolab.stanf[...]
[42]
논문
Design and implementation of a high performance distributed web crawler
http://cis.poly.edu/[...]
IEEE CS Press
[43]
학위논문
"Search Interfaces on the Web: Querying and Characterizing"
https://oa.doria.fi/[...]
University of Turku
2014-07-06
[44]
저널
mod_oai: An Apache Module for Metadata Harvesting
2005-03-24
[45]
저널
DEQUE: Querying the Deep Web
http://www.mendeley.[...]
[46]
웹사이트
AJAX crawling: Guide for webmasters and developers
https://support.goog[...]
2013-03-17
[47]
뉴스
"ITA Labs Acquisition"
http://semanticweb.c[...]
ITA Labs
2014-03-18
[48]
웹사이트
About Applebot
https://support.appl[...]
Apple Inc
2021-10-18
[49]
웹사이트
Xenon web crawling initiative: privacy impact assessment (PIA) summary
https://www.canada.c[...]
Government of Canada
2017-10-13
[50]
뉴스
Tax takers send in the spiders
https://www.wired.co[...]
2017-10-13
[51]
웹인용
The TkWWW Robot: Beyond Browsing
http://archive.ncsa.[...]
National Center for Supercomputing Applications
2010-11-21
[52]
저널
Information retrieval on the web
http://doi.acm.org/1[...]
ACM Press
[53]
문서
definition of scutter on FOAF Project's wiki
http://wiki.foaf-pro[...]
20091213
[54]
학위논문
Effective Web Crawling
http://chato.cl/rese[...]
University of Chile
2010-08-03
[55]
논문
Search Engines and Web Dynamics
http://citeseer.ist.[...]
2002-06
[56]
논문
Design and implementation of a distributed crawler and filtering processor
http://www.cs.ucr.ed[...]
Springer
[57]
논문
GENVL and WWWW: Tools for taming the web
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com