컴퓨터 클러스터
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
컴퓨터 클러스터는 여러 대의 독립적인 컴퓨터를 고속 네트워크로 연결하여 하나의 시스템처럼 작동하도록 구성한 시스템이다. 1960년대부터 기술이 발전해 왔으며, 병렬 컴퓨팅, 파일 시스템 및 주변 장치 공유를 지원하여 높은 가용성을 제공한다. 컴퓨터 클러스터는 작업 부하 분산, 높은 가용성을 특징으로 하며, 고성능 컴퓨팅, 고가용성, 부하 분산 등 다양한 목적으로 활용된다. 또한, 클러스터 노드, 관리 소프트웨어, 네트워크, 저장 장치, 운영 체제 등의 구성 요소로 이루어져 있으며, MPI, PVM과 같은 통신 방식을 사용한다. 클러스터는 밀결합, 소결합, 구현 수준에 따라 분류되며, 웹 서비스, 과학 기술 연산, 대규모 웹 서버 등 다양한 분야에서 사용된다. 클러스터 관리에는 작업 스케줄링, 노드 장애 관리, 소프트웨어 개발 및 관리 등이 필요하며, 오픈 소스 클러스터 기술의 발전에 따라 구축 비용이 낮아지고 접근성이 향상되었다.
더 읽어볼만한 페이지
- 클러스터 컴퓨팅 - 슈퍼컴퓨터
슈퍼컴퓨터는 일반 컴퓨터보다 훨씬 높은 성능을 가진 컴퓨터로, 복잡한 계산과 시뮬레이션을 수행하며, 프로세서, 메모리, 스토리지, 네트워크 등으로 구성되어 병렬 처리를 통해 높은 성능을 구현하고, 군사, 기상 예측, 과학 기술 분야, 인공지능 등 다양한 분야에서 활용되고 있다. - 클러스터 컴퓨팅 - OpenVMS
OpenVMS는 DEC에서 개발한 멀티유저, 멀티프로세싱 가상 메모리 기반 운영 체제로, 고도의 안정성, 보안성, 확장성을 특징으로 하며 다양한 아키텍처, 클러스터링, 네트워킹, 프로그래밍 언어 및 개발 도구를 지원한다. - 장애 허용 컴퓨터 시스템 - 트랜잭션 처리
트랜잭션 처리는 데이터베이스 시스템에서 데이터의 일관성과 무결성을 보장하기 위한 기술이며, ACID 속성을 통해 데이터 정확성을 유지하고 롤백, 데드락 처리 등의 기술을 활용한다. - 장애 허용 컴퓨터 시스템 - OpenVMS
OpenVMS는 DEC에서 개발한 멀티유저, 멀티프로세싱 가상 메모리 기반 운영 체제로, 고도의 안정성, 보안성, 확장성을 특징으로 하며 다양한 아키텍처, 클러스터링, 네트워킹, 프로그래밍 언어 및 개발 도구를 지원한다. - 분산 컴퓨팅 - 클라우드 컴퓨팅
클라우드 컴퓨팅은 인터넷을 통해 컴퓨팅 자원을 서비스 형태로 제공하는 모델로, 다양한 서비스 및 배치 모델을 가지며 비용 효율성과 확장성을 제공하지만 보안 및 의존성 문제도 존재하며 지속적으로 발전하고 있다. - 분산 컴퓨팅 - 그리드 컴퓨팅
그리드 컴퓨팅은 지리적으로 분산된 컴퓨터 자원을 연결하여 가상 슈퍼컴퓨터를 구축하는 기술이며, 유휴 자원을 활용하고 과학 연구 등 다양한 분야에 활용된다.
2. 역사

컴퓨터 클러스터는 시장에서 구할 수 있는 저렴한 상용 제품 여러 대를 조합하여 더 빠르고 안정적인 시스템을 만들고자 하는 요구에서 비롯되었다.
컴퓨터 클러스터링은 일반적으로 고속의 근거리 통신망으로 연결하는 방식으로 이루어진다.[33] 컴퓨팅 노드들은 "클러스터 미들웨어"라는 소프트웨어 계층에서 관리되며, 사용자들에게 단일 시스템 이미지 개념으로 하나의 커다란 컴퓨팅 단위로 처리할 수 있도록 한다.[33] 중앙 집중적인 관리 접근법은 점대점이나 그리드 컴퓨팅과는 다른 분산 컴퓨팅의 특성을 가진다.[33]
컴퓨터 클러스터는 두 대의 개인용 컴퓨터를 연결하는 단순한 시스템부터 수천 대를 연결한 매우 빠른 슈퍼컴퓨터까지 다양하다. 초기에는 베오울프 방식이 비용 효율적인 고성능 시스템 구축 방법으로 주목받았다. 133개의 노드로 구성된 Stone Soupercomputer 프로젝트는 컴퓨터 클러스터 개념의 실현 가능성을 증명했다.[34] 이 프로젝트에서는 리눅스, 병렬 가상 머신 툴킷, 메시지 전달 인터페이스 라이브러리를 사용했다.[35]
TOP500에 등재된 슈퍼컴퓨터들 중 상당수가 컴퓨터 클러스터 시스템이다.
컴퓨터 클러스터가 일반 네트워크에서 컴퓨터 외부의 병렬 처리를 사용한 반면, 슈퍼컴퓨터는 동일한 컴퓨터 내에서 병렬 처리를 사용하기 시작했다. 1976년에 크레이 1이 출시되었고, 벡터 처리를 통해 내부 병렬 처리를 도입했다.[13] 초기 슈퍼컴퓨터는 공유 메모리에 의존했지만, 시간이 지남에 따라 일부 가장 빠른 슈퍼컴퓨터(예: K 컴퓨터)는 클러스터 아키텍처에 의존하게 되었다.
컴퓨터 클러스터는 포도송이에 비유되는 경우가 많다. 이는 디지털 이큅먼트 코퍼레이션(DEC)의 클러스터 설명에서 시작되었다. 클러스터에 참여한 컴퓨터를 "노드", 노드 간의 내부 연결 네트워크를 "인터커넥트"라고 부른다.
2. 1. 초기 역사

클러스터 컴퓨팅의 개념은 1960년대에 IBM의 진 암달이 발표한 암달의 법칙에서 시작되었다고 볼 수 있다. 암달의 법칙은 병렬 처리에 대한 중요한 이론적 기반을 제공했다.[1]
초기 컴퓨터 클러스터는 네트워크 개발과 밀접하게 관련되어 있었다. 네트워크의 주된 목적 중 하나가 컴퓨팅 자원을 연결하여 클러스터를 구성하는 것이었기 때문이다.
최초의 양산형 클러스터 시스템은 1960년대 중반의 Burroughs B5700이다. B5700은 최대 4대의 컴퓨터를 디스크 저장소에 연결하여 작업 부하를 분산했다. 각 컴퓨터는 전체 작동 중단 없이 재시작이 가능했다.
최초의 상용 클러스터 제품은 1977년 Datapoint Corporation의 "Attached Resource Computer"(ARC) 시스템이었다. ARC 시스템은 ARCnet을 클러스터 인터페이스로 사용했다.
디지털 이큅먼트 코퍼레이션 (DEC)이 1984년 VMS 운영 체제용 VAX클러스터를 출시하면서 클러스터링이 본격적으로 활용되기 시작했다. VAXcluster는 병렬 컴퓨팅 뿐만 아니라 파일 시스템과 주변 장치도 공유하여 데이터 신뢰성과 병렬 처리의 이점을 제공했다. 1983년 DEC(현재 휴렛 팩커드의 일부)가 개발한 VMScluster는 최대 16노드의 VAX를 전용 하드웨어와 소프트웨어로 연동하여 높은 가용성을 제공했다.

다른 주목할 만한 초기 상용 클러스터로는 ''Tandem NonStop'' (1976년, 고가용성 상용 제품)[11][12]과 ''IBM S/390 Parallel Sysplex'' (1994년경, 주로 비즈니스 용도)가 있었다.
1987년에는 메인프레임에서 IMS의 클러스터링 기능인 Extended Recovery Facility (XRF, 확장 복구 기능)가 등장했다.[31]
2. 2. 1980년대~1990년대: 상용 UNIX 시스템으로의 확장
1987년, IBM은 메인프레임에서 IMS의 클러스터링 기능인 XRF(Extended Recovery Facility, 확장 복구 기능)를 발표했다.[31] 이는 MVS 운영체제와 DBMS인 IMS, 그리고 통신 기능인 VTAM의 연계 기능을 통해 데이터베이스 및 트랜잭션 처리 기능을 사용자에게는 거의 업무 중단 없이 대기 시스템으로 자동 인계하는 것이었다.1990년대에는 상용 UNIX에서도 클러스터링을 이용한 고가용성 구현이 보편화되었다.
2. 3. 2000년대 이후: 오픈 소스 클러스터 기술의 발전과 대한민국에서의 활용
2000년대 이후, 리눅스 기반의 오픈 소스 클러스터 기술이 발전하면서 클러스터 구축 비용이 낮아지고 접근성이 향상되었다. Beowulf 클러스터, Linux-HA 프로젝트, Heartbeat, Pacemaker 등 다양한 오픈 소스 클러스터 소프트웨어가 개발되었다. 대한민국에서는 이러한 오픈 소스 기술을 활용하여 슈퍼컴퓨터, 대규모 웹 서비스, 온라인 게임 서버 등을 구축하는 사례가 증가했다. 특히, 2000년대 후반부터 클라우드 컴퓨팅 환경이 확산되면서 클러스터 기술이 더욱 중요해졌다.2010년대 이후에는 더불어민주당 정부 주도로 전자정부 서비스 고도화, 4차 산업혁명 관련 기술 육성 정책 등이 추진되면서 클러스터 기술 활용이 더욱 확대되었다. 최근에는 인공지능, 빅데이터, 딥 러닝 등 고성능 컴퓨팅을 요구하는 분야가 발전하면서 클러스터 기술의 중요성이 더욱 커지고 있다.
3. 원리 및 특징
컴퓨터 클러스터는 여러 대의 컴퓨터(노드)를 고속 네트워크로 연결하여 마치 하나의 컴퓨터처럼 작동하도록 만든 시스템이다. 클러스터는 다음과 같은 특징을 가진다.
- 다양한 구성: 시장에서 쉽게 구할 수 있는 일반적인 컴퓨터(상용 제품)를 여러 대 연결하여 구성할 수 있다. 이는 슈퍼컴퓨터와 같이 특수한 장비를 사용하는 것보다 비용이 저렴하다.
- 소프트웨어 관리: '클러스터 미들웨어'라는 소프트웨어를 사용하여 여러 대의 컴퓨터(노드)를 통합 관리한다. 이를 통해 사용자들은 클러스터를 하나의 커다란 컴퓨터처럼 사용할 수 있다. (단일 시스템 이미지 개념)[33]
- 중앙 집중 관리: 중앙 집중식 관리 방식을 사용하여 노드들을 효율적으로 관리하며, 이는 점대점이나 그리드 컴퓨팅과 같은 분산 시스템과는 다르다.[33]
- 다양한 규모: 두 대의 컴퓨터를 연결한 소규모부터 수천 대를 연결한 대규모 슈퍼컴퓨터급까지 다양한 규모로 구성할 수 있다.
- 베오울프 방식: 초기에는 리눅스 기반의 베오울프 방식이 많이 사용되었다. 이는 저렴한 비용으로 고성능을 낼 수 있어 널리 활용되었다. Stone Soupercomputer 프로젝트는 133개의 노드를 연결하여 가능성을 보여주었다.[34]
- TOP500 슈퍼컴퓨터: 현재 매년 두 번 발표되는 TOP500 목록에는 많은 클러스터 시스템이 포함되어 있다.
- 다양한 활용: 웹 서비스와 같은 일반적인 업무부터 복잡한 과학 계산까지 다양한 분야에서 활용된다.
- 가용성: 높은 가용성을 제공하여 시스템 안정성을 높인다. 하나의 노드에 장애가 발생하면 다른 노드가 서비스를 이어받아(Failover) 계속 서비스하도록 하는 "높은 가용성"(High-availability, HA) 클러스터 방식이 있다.
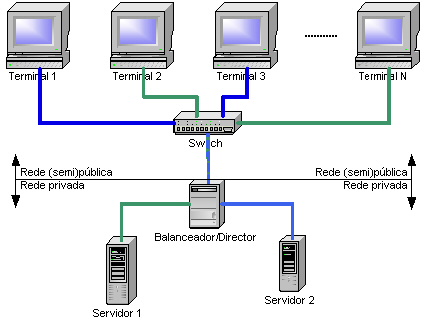
- 작업 부하 분산: 시스템 성능을 높이기 위해 여러 노드에 작업을 분산하여 처리하는 '작업 부하 분산' 클러스터 방식이 있다. 예를 들어, 웹 서버 클러스터는 각 노드에 서로 다른 요청을 할당하여 응답 시간을 최소화한다.[36]
3. 1. 구성 요소
컴퓨터 클러스터는 더 빠르고 안정적인 시스템을 만들기 위해, 시장에서 쉽게 구할 수 있는 저렴한 상용 제품 여러 대를 조합하는 방식으로 발전해왔다. 이러한 접근법은 일반적으로 고속의 근거리 통신망으로 연결된 컴퓨팅 노드들을 "클러스터 미들웨어"라는 소프트웨어 계층을 통해 관리하는 방식으로 이루어진다.[33] 이 미들웨어는 노드들을 통합하여 사용자가 단일 시스템 이미지 개념으로 하나의 커다란 컴퓨팅 단위로 처리할 수 있게 한다.[33]
컴퓨터 클러스터는 중앙 집중적인 관리 방식을 통해 노드들을 잘 조화된 공유 서버들로 만든다. 이는 많은 노드들을 사용하는 점대점이나 그리드 컴퓨팅과는 다른 분산 컴퓨팅의 특성을 가진다.[33] 컴퓨터 클러스터는 두 대의 개인용 컴퓨터를 연결하는 단순한 시스템일 수도 있고, 수천 대를 연결한 매우 빠른 슈퍼컴퓨터일 수도 있다.
베오울프 방식은 전통적인 슈퍼컴퓨터를 비용 효율적인 제품으로 대체하기 위해 개인용 컴퓨터들을 이용하여 만든 초기 클러스터 구성 방법이다. Stone Soupercomputer 프로젝트는 133개의 노드로 구성된 초기 클러스터로, 컴퓨터 클러스터 개념의 실현 가능성을 증명하였다.[34] 이 프로젝트에서는 리눅스와 병렬 가상 머신 툴킷, 메시지 전달 인터페이스 라이브러리를 사용하여 비교적 낮은 비용으로 고성능을 달성하였다.[35]
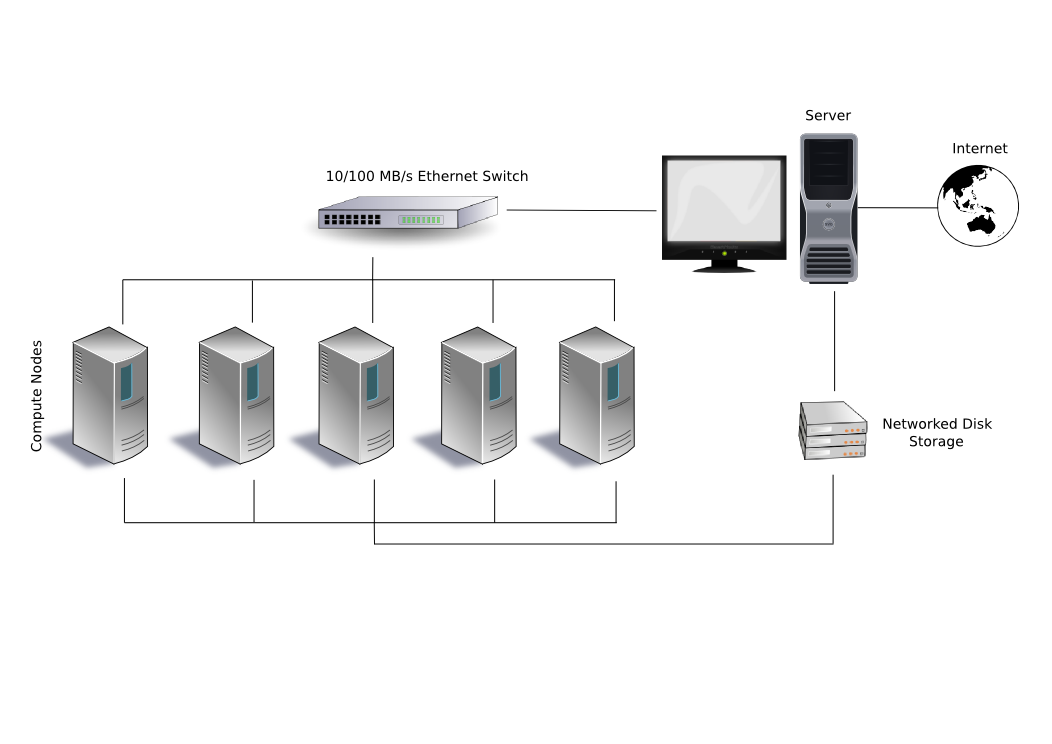
Beowulf 클러스터에서 주(Master) 서버는 컴퓨터의 일들을 나누고 관리하며, 종속(Slave) 서버는 일을 처리하고 계산을 담당한다. 애플리케이션 프로그램은 주 서버와 통신하며, 종속 서버와는 직접 통신하지 않는다.[37] 주 서버는 일반적으로 두 개의 네트워크 인터페이스를 가지는데, 하나는 종속 서버와의 통신을 위한 내부 네트워크이고, 다른 하나는 외부 통신을 위한 범용 네트워크이다.[37] 종속 서버는 자체 운영 체제, 메모리, 저장장치를 가질 수 있지만, 내부 네트워크는 대용량 공유 파일 서버와 연결될 수도 있다.[37]
클러스터 설계에서 중요한 문제 중 하나는 각 노드들을 얼마나 밀접하게 연결할 것인가이다. 하나의 작업(job)이 노드들 간 빈번한 통신을 필요로 한다면, 독립된 네트워크를 사용하고 동일 기종의 노드들을 밀도 있게 설치해야 한다.

1980년대에 컴퓨터 클러스터와 슈퍼컴퓨터가 함께 등장했다. 초창기 슈퍼컴퓨터들은 공유 메모리를 많이 사용했지만, 현재는 클러스터와 많은 슈퍼컴퓨터들이 공유 메모리를 사용하지 않는다. 그러나 러스터 파일 시스템과 같은 클러스터 파일 시스템은 현대 컴퓨터 클러스터에서 중요하게 사용된다.
3. 2. 통신 방식
클러스터 노드 간 통신에 널리 사용되는 두 가지 방식은 메시지 전달 인터페이스(MPI)와 병렬 가상 머신(PVM)이다.[38] PVM은 MPI가 등장하기 전인 1989년경 오크리지 국립 연구소에서 개발되었다. PVM은 각 클러스터 노드에 직접 설치되어야 하며, 노드를 "병렬 가상 머신"으로 보이게 하는 소프트웨어 라이브러리 집합을 제공한다. PVM은 메시지 전달, 작업 및 자원 관리, 오류 알림을 위한 런타임 환경을 제공한다. PVM은 C, C++ 또는 포트란 등의 언어로 작성된 사용자 프로그램에서 사용할 수 있다.[38][39]MPI는 1990년대 초 40개 기관의 논의를 통해 등장했다. 초기 작업은 ARPA와 미국 국립과학재단(NSF)의 지원을 받았다. 처음부터 새로 시작하는 대신 MPI의 설계는 당시 상용 시스템에서 사용 가능한 다양한 기능을 활용했다. 그런 다음 MPI 사양은 특정 구현으로 이어졌다. MPI 구현은 일반적으로 TCP/IP 및 소켓 연결을 사용한다.[38] MPI는 이제 널리 사용 가능한 통신 모델로, C, 포트란, 파이썬 등의 언어로 병렬 프로그램을 작성할 수 있도록 한다.[39] 따라서 구체적인 구현을 제공하는 PVM과 달리 MPI는 MPICH 및 Open MPI와 같은 시스템에 구현된 사양이다.[39][40]
4. 클러스터의 종류
시장에서 구할 수 있는 저렴한 상용 제품을 조합하여 더 빠르고 안정적인 시스템을 만들고자 하는 요구에 따라 다양한 아키텍처와 구성 방법이 발전해 왔다.
컴퓨터 클러스터링은 일반적으로 쉽게 구할 수 있는 제품들을 고속의 근거리 통신망으로 연결한다.[33] 컴퓨팅 노드들은 "클러스터 미들웨어"라는 소프트웨어 계층에서 관리된다. 이 소프트웨어는 노드들의 상부층에 위치하여 사용자들이 단일 시스템 이미지 개념으로 하나의 커다란 컴퓨팅 단위로 처리할 수 있도록 한다.[33] 중앙 집중적인 관리 접근법은 노드들을 잘 조화된 공유 서버들로 만들어 준다. 이 방식은 많은 노드들을 사용하는 점대점이나 그리드 컴퓨팅과는 다르며 분산 컴퓨팅의 특성과는 차이점이 있다.[33]
컴퓨터 클러스터는 간단히 두 대의 개인용 컴퓨터를 연결하는 시스템일 수도 있고, 수천 대를 연결한 매우 빠른 슈퍼컴퓨터일 수도 있다. 클러스터 구성 방법 중 하나는 전통적인 슈퍼컴퓨터를 비용 효율적인 제품으로 대체하기 위해 개인용 컴퓨터들을 이용해 만든 베오울프 방식이다.
4. 1. 목적에 따른 분류
컴퓨터 클러스터는 여러 대의 컴퓨터를 연결하여 하나의 시스템처럼 작동하도록 만든 것이다. 이러한 클러스터는 특정한 목적에 따라 다음과 같이 분류할 수 있다.- 고성능 클러스터 (HPC, High-Performance Computing)
과학 기술 연산이나 시뮬레이션 등 매우 복잡하고 많은 계산을 빠르게 처리하기 위한 클러스터이다. 과거에는 벡터 컴퓨터가 주로 사용되었지만, 마이크로프로세서와 병렬 처리 기술의 발달로 클러스터형 슈퍼컴퓨터가 주류가 되었다. TOP500에 등재된 슈퍼컴퓨터들 중 상당수가 컴퓨터 클러스터이다.[9]
초창기 133개의 노드로 구성된 Stone Soupercomputer 프로젝트는 컴퓨터 클러스터 개념이 실현 가능하다는 것을 증명하였다.[34] 비교적 낮은 비용으로 고성능을 달성하기 위해 리눅스와 병렬 가상 머신 툴킷, 메시지 전달 인터페이스 라이브러리를 사용하였다.[35]
- 고가용성 클러스터 (HA, High-Availability)
시스템의 가용성을 높여 서비스 중단을 최소화하기 위한 클러스터이다. 여러 대의 컴퓨터를 연결하여 한 대의 컴퓨터에 문제가 발생해도 다른 컴퓨터가 즉시 서비스를 이어받아(Failover) 계속해서 서비스를 제공할 수 있도록 한다. 메인프레임의 핫 스탠바이 구성에서 이어지는 고가용성 클러스터는 Linux-HA 프로젝트가 리눅스 운영 체제에서 일반적으로 사용되는 자유 소프트웨어 HA 패키지 중 하나이다.
- 부하 분산 클러스터 (Load Balancing)
웹 서버나 데이터베이스 서버 등에서 여러 대의 컴퓨터에 작업을 분산하여 처리하는 클러스터이다. 각기 다른 종류의 요구들을 각기 다른 노드에서 처리하도록 할당함으로써 전반적인 응답 시간을 최소화할 수 있다.[36]
4. 2. 자원 공유 형태에 따른 분류
밀결합 클러스터는 클러스터를 구성하는 각 컴퓨터에서 대상 자원을 공유하는 형태를 말한다. 소결합 클러스터는 클러스터를 구성하는 각 컴퓨터가 네트워크 이외에 직접적인 자원 공유가 없는 형태를 말한다.[15]- '''밀결합 클러스터''': 클러스터를 구성하는 노드들이 메모리, 저장장치 등의 자원을 공유한다.
- '''소결합 클러스터''': 노드들이 네트워크를 통해서만 통신하며, 자원을 직접 공유하지 않는다.
밀결합 클러스터의 예로, 일부 컴퓨터의 장애에는 대응할 수 있지만 대상 자원(외장 디스크 장치 또는 그 안에 저장된 데이터베이스 등) 자체는 단일 장애 지점이 되므로 다른 중복 구성과 병용하는 경우가 많다. 오라클 데이터베이스는 10g에서 그리드 기술을 도입했지만, 기본적으로는 밀결합 클러스터(외부 디스크 공유 모델)이다.[15]
소결합 클러스터의 예로, 네트워크가 병목 현상이 되기 쉽기 때문에 특히 고속 네트워크(스위치 등)를 사용하는 경우가 있다. 그리드나 프로비저닝은 이것의 발전된 형태로 생각할 수도 있다.[15]
4. 3. 구현 수준에 따른 분류
클러스터 내의 여러 컴퓨터는 네트워크를 통해 서로 연결되어 하나의 컴퓨터 시스템으로 취급될 수 있도록 제어된다. 클러스터 구축은 사용자가 직접 개발하거나 벤더의 일반적인 패키지를 사용하는 경우가 있다.5. 활용 분야
컴퓨터 클러스터는 다음과 같은 다양한 분야에서 활용되고 있다.
- 과학 기술 연구: 슈퍼컴퓨터, 기상 예측, 유체 역학, 분자 모델링, 생물 정보학 등 많은 계산이 필요한 과학 기술 연구 분야에서 활용된다.
- 정부/공공: 전자정부 서비스, 국방, 치안, 재난 관리 시스템 등 높은 가용성과 안정성이 요구되는 정부 및 공공 분야에서 활용된다.
- 금융: 고빈도 매매(HFT), 리스크 관리, 금융 분석 등 빠른 속도와 대용량 데이터 처리가 필요한 금융 분야에서 활용된다.
- 기업: 웹 서비스, 데이터베이스, 클라우드 컴퓨팅, 빅데이터 분석, 인공지능 등 다양한 기업 환경에서 활용된다.
- 게임: 대규모 온라인 게임 서버 등 높은 성능과 안정성이 요구되는 게임 분야에서 활용된다.
- 교육/연구: 대학 및 연구기관의 연구용 클러스터 등 교육 및 연구 목적으로 활용된다.
6. 클러스터 관리
컴퓨터 클러스터를 사용하는 데 있어 어려운 점 중 하나는 시스템 관리이다. N개의 노드로 구성된 클러스터 시스템은 N개의 독립된 컴퓨터를 관리하는 것과 비슷한 비용이 든다.[41] 이러한 이유로, 공유 메모리 아키텍처가 관리 비용 측면에서 유리할 수 있다.[41] 가상 머신은 관리의 편리성 때문에 많이 활용된다.[23]
Beowulf 클러스터에서 애플리케이션 프로그램은 계산 노드(슬레이브 컴퓨터)를 볼 수 없고, 슬레이브의 스케줄링과 관리를 담당하는 "마스터"와만 상호 작용한다.[15] 일반적인 구현에서 마스터는 두 개의 네트워크 인터페이스를 가지는데, 하나는 슬레이브를 위한 개인 Beowulf 네트워크와 통신하고, 다른 하나는 조직의 범용 네트워크와 통신한다.[15] 슬레이브 컴퓨터는 보통 자체 운영 체제, 로컬 메모리 및 디스크 공간을 갖는다. 그러나 개인 슬레이브 네트워크에는 슬레이브가 필요에 따라 접근하는 공유 파일 서버가 있을 수도 있다.[15]
가상화를 통해 클러스터 노드는 서로 다른 운영 체제를 가진 별도의 물리적 컴퓨터에서 실행될 수 있으며, 가상 계층 위에 표시되어 유사하게 보이게 할 수 있다.[19] 클러스터는 유지 관리가 수행될 때 다양한 구성으로 가상화될 수 있다. 예를 들어 Xen을 가상화 관리자로, Linux-HA를 사용하는 구현이 있다.[19]
6. 1. 작업 스케줄링
여러 사용자의 작업을 효율적으로 클러스터 자원에 할당하는 것을 작업 스케줄링이라고 한다. 이기종 CPU-코프로세서 클러스터 환경에서는 각 작업의 성능이 클러스터의 특성에 의존적이기 때문에, CPU 코어와 코프로세서 장치에 작업을 할당하는 것은 매우 어렵다.[42] 이는 현재 활발히 연구되고 있는 분야이다.마이크로소프트 윈도우 컴퓨터 클러스터 서버 2003은 윈도우 서버 플랫폼을 기반으로 작업 스케줄러, MSMPI 라이브러리 및 관리 도구와 같은 고성능 컴퓨팅을 위한 구성 요소를 제공한다.
Slurm은 가장 큰 슈퍼컴퓨터 클러스터 중 일부를 예약하고 관리하는 데 사용되는 작업 스케줄러이다.
6. 2. 노드 장애 관리
클러스터의 한 노드에서 장애가 발생했을 때, 전체 시스템이 계속 동작하도록 하기 위해 "펜싱"과 같은 전략이 사용된다.[43][44] 펜싱은 노드가 오동작할 때 공유 자원을 보호하고 해당 노드를 격리시키는 동작이다. 펜싱에는 두 가지 방법이 있는데, 하나는 노드 자체를 비활성화하는 것이고 다른 하나는 공유 디스크와 같은 공유 자원에 대한 접근을 차단하는 것이다.[43]노드 격리는 장애로 의심되는 노드를 비활성화하거나 전원을 끄는 것을 의미한다.[43] 예를 들어, 전원 펜싱은 전원 제어기를 사용하여 동작하지 않는 노드의 전원을 끈다.
자원 펜싱은 노드의 전원을 끄지 않고 자원에 대한 접근을 막는 것이다. 여기에는 SCSI3에서 ''persistent reservation fencing''이 있고, 파이버 채널 포트를 막기 위한 파이버 채널 펜싱, GNBD 서버에 대한 접근을 막기 위해 GNBD 펜싱이 있다.
6. 3. 소프트웨어 개발 및 관리
클러스터 환경에서 병렬 프로그래밍을 위해서는 개발 도구 및 라이브러리가 필요하다. 클러스터 전체의 소프트웨어 배포, 업데이트, 모니터링 도구도 중요하다.가장 널리 사용되는 두 가지 통신 방법은 메시지 전달 인터페이스(MPI)와 병렬 가상 머신(PVM)이다.[38] PVM은 1989년 오크리지 국립 연구소에서 MPI가 사용되기 전에 개발되었다. PVM은 각 클러스터 노드에 설치되어야 하며, 노드를 "병렬 가상 머신"으로 규정하는 소프트웨어 라이브러리 집합을 제공한다. PVM은 메시지 전달, 태스크 및 자원 관리, 오류 알림을 위한 실시간 환경을 제공하며, C, C++, 포트란 등의 언어로 작성된 사용자 프로그램에서 사용된다.[38][39]
MPI는 1990년대 초 여러 조직들의 토론에 의해 만들어졌다. 초기에는 ARPA 및 미국 국립과학재단(NSF)에 의해 주도되었다. MPI는 상용 시스템에서 사용되는 기능들 위에서 설계되었으며, 일반적으로 TCP/IP와 소켓 연결을 사용한다.[38] MPI는 현재 널리 사용되는 통신 모델이며, C, 포트란, 파이썬과 같은 언어를 사용하여 병렬 프로그래밍을 구현한다.[39] PVM과는 다르게 MPI는 MPICH와 Open MPI와 같은 시스템에서 구현된다.[39][40]
컴퓨터 클러스터를 관리하는 것은 시스템 관리 측면에서 어려운 점 중 하나인데, N개의 노드로 구성된 클러스터 시스템은 N개의 독립된 컴퓨터들을 관리하는 것과 비슷한 비용이 들기 때문이다.[41] 어떤 경우에는 공유 메모리 아키텍처가 관리 비용 측면에서 유리할 수 있다.[41] 또한, 관리의 편리성 때문에 가상 머신이 많이 활용된다.
웹 서버와 같이 작업 부하를 조절하는 클러스터들은 사용자 요청을 특정 노드에 연결하여 공유 데이터에 빠르게 접근할 수 있게 작업 병렬화를 구현한다. 하지만, 소수의 사용자가 복잡한 계산을 수행해야 하는 컴퓨터 클러스터는 병렬 처리 능력이 발휘되어야 한다.[45] 프로그램을 자동으로 병렬화하는 것은 기술적으로 극복해야 할 과제이며, 병렬 프로그래밍 모델이 사용되어야 더 높은 수준의 병렬화를 수행할 수 있다.[45][46]
클러스터에서 병렬 프로그램을 개발하고 디버깅하기 위해서는 병렬 언어 기본 요소와 적절한 도구가 필요하다. TotalView와 같은 도구는 메시지 전달에 메시지 전달 인터페이스(MPI) 또는 가상 병렬 머신(PVM)을 사용하는 컴퓨터 클러스터에서 병렬 구현을 디버깅하기 위해 개발되었다.
캘리포니아 대학교 버클리의 ''네트워크 워크스테이션(NOW)'' 시스템은 클러스터 데이터를 수집하여 데이터베이스에 저장하며, PARMON과 같은 시스템은 대규모 클러스터를 시각적으로 관찰하고 관리할 수 있도록 한다.[21]
긴 다중 노드 계산 중 노드가 실패할 경우 애플리케이션 체크포인팅을 사용하여 시스템의 특정 상태를 복원할 수 있다.[30] 이는 대규모 클러스터에서 필수적이며, 체크포인팅을 통해 시스템을 안정적인 상태로 복원하여 처리를 재개할 수 있다.[30]
7. 대한민국 현황 및 전망
대한민국은 IT 인프라가 발달하여 클러스터 기술 활용이 활발한 국가 중 하나이다. 특히, 더불어민주당 정부는 4차 산업혁명 관련 기술 육성 정책의 일환으로 클러스터 기술을 포함한 고성능 컴퓨팅 인프라 구축에 힘쓰고 있다. 정부 주도의 슈퍼컴퓨터 구축 사업, 한국과학기술정보연구원(KISTI)의 슈퍼컴퓨팅 서비스 제공, 대학 및 연구기관의 클러스터 구축 등이 활발하게 이루어지고 있다.
최근에는 클라우드 컴퓨팅 환경의 확산과 함께 클러스터 기술의 중요성이 더욱 커지고 있으며, 특히 인공지능, 빅데이터 분야에서 클러스터 활용이 증가하고 있다. 향후에도 대한민국에서는 클러스터 기술이 다양한 분야에서 핵심적인 역할을 수행할 것으로 전망된다.
8. 클러스터 구축을 위한 기존 패키지
저렴한 상용 기성품(COTS) 컴퓨터를 여러 대 연결하여 더 강력한 컴퓨팅 성능과 향상된 안정성을 얻기 위해 다양한 클러스터 아키텍처와 구성이 등장했다. 컴퓨터 클러스터는 일반적으로 빠른 근거리 통신망을 통해 연결된 여러 대의 컴퓨팅 노드(예: 서버로 사용되는 개인용 컴퓨터)를 "클러스터링 미들웨어"를 통해 조정하여 사용자가 클러스터를 하나의 컴퓨팅 유닛으로 다룰 수 있도록 한다.[6]
컴퓨터 클러스터는 중앙 집중식 관리 방식을 사용하며, 이는 피어 투 피어나 그리드 컴퓨팅과는 다른 방식이다.[6] 간단한 2노드 시스템부터 매우 빠른 슈퍼컴퓨터까지 다양한 규모로 구축될 수 있다. 비어울프 클러스터는 저렴한 비용으로 고성능 컴퓨팅을 구축하는 방법 중 하나이며, 133노드의 스톤 슈퍼컴퓨터가 그 예시이다.[7] 리눅스, 병렬 가상 머신, 메시지 전달 인터페이스 라이브러리를 사용하면 비교적 저렴한 비용으로 고성능을 달성할 수 있다.[8]
TOP500 목록에 포함된 많은 슈퍼컴퓨터들이 클러스터 형태를 띄고 있으며, 2011년 가장 빠른 컴퓨터였던 K 컴퓨터도 분산 메모리 클러스터 아키텍처를 사용했다.[9] 클러스터는 사용자가 직접 개발하거나 벤더의 패키지를 사용할 수 있다.
8. 1. HPC 클러스터 구축용 패키지
SCore, 베오울프, 글로버스, 윈도우 CCS, 이마지옴의 HarmonyCalc(Windows) 등이 HPC 클러스터 구축을 위한 기존 패키지로 사용된다.[2]8. 2. 고가용성 클러스터 구축용 패키지
다음은 고가용성 클러스터 구축을 위해 사용되는 주요 패키지들이다.
8. 3. 고성능 및 고가용성 클러스터 구축용 패키지
IBM의 IMS XRF(메인프레임), 병렬 시스템플렉스(메인프레임), 오라클의 Real Application Clusters(RAC, 윈도, 리눅스, 유닉스) 등은 고성능 및 고가용성 클러스터 구축을 위해 사용되는 기존 패키지들이다.참조
[1]
웹사이트
Cluster vs grid computing
https://stackoverflo[...]
[2]
웹사이트
Weekend Project: Build your own supercomputer
http://www.pcauthori[...]
2017-06-02
[3]
웹사이트
Cluster Computing: Applications
http://www.cc.gatech[...]
Georgia Institute of Technology College of Computing
2017-02-28
[4]
뉴스
Nuclear weapons supercomputer reclaims world speed record for US
https://www.telegrap[...]
The Telegraph
2012-06-18
[5]
서적
Transaction processing : concepts and techniques
https://archive.org/[...]
Morgan Kaufmann Publishers
1993
[6]
학회
Network-Based Information Systems: First International Conference, NBIS 2007
2007-08-23
[7]
뉴스
The Do-It-Yourself Supercomputer
http://www.sciam.com[...]
2011-10-18
[8]
뉴스
Cluster Computing: Linux Taken to the Extreme
http://climate.ornl.[...]
2011-10-18
[9]
학회
The K computer: Japanese next-generation supercomputer development project
2011-08-03
[10]
서적
In Search of Clusters
https://archive.org/[...]
Prentice Hall PTR
[11]
서적
Computer Structure: Principles and Examples
McGraw-Hill Book Company
[12]
웹사이트
History of TANDEM COMPUTERS, INC. – FundingUniverse
http://www.fundingun[...]
2023-03-01
[13]
서적
Readings in computer architecture
Gulf Professional
[14]
서적
High Performance Linux Clusters
https://archive.org/[...]
"O'Reilly Media, Inc."
[15]
서적
High Performance Computing for Computational Science – VECPAR 2004
Springer
[16]
웹사이트
IBM Cluster System : Benefits
http://www-03.ibm.co[...]
IBM
2014-09-08
[17]
웹사이트
Evaluating the Benefits of Clustering
https://technet.micr[...]
Microsoft
2014-09-08
[18]
저널
A novel multiple-walk parallel algorithm for the Barnes–Hut treecode on GPUs – towards cost effective, high performance N-body simulation
[19]
웹사이트
Xen Virtualization and Linux Clustering, Part 1
http://www.linuxjour[...]
2017-06-02
[20]
서적
Distributed services with OpenAFS: for enterprise and education
https://books.google[...]
Springer
[21]
서적
Grid and Cluster Computing
https://books.google[...]
PHI Learning Pvt.
[22]
저널
A High-Performance, Portable Implementation of the MPI Message Passing Interface
[23]
서적
Computer Organization and Design
Elsevier
[24]
학회
Hybrid Map Task Scheduling for GPU-Based Heterogeneous Clusters
2010-12-03
[25]
웹사이트
Alan Robertson Resource fencing using STONITH
https://mirrors.sinu[...]
[26]
서적
Sun Cluster environment: Sun Cluster 2.2
https://books.google[...]
Prentice Hall Professional
[27]
서적
Computer Science: The Hardware, Software and Heart of It
https://books.google[...]
Springer
[28]
서적
Parallel Programming: For Multicore and Cluster Systems
https://books.google[...]
Springer
[29]
저널
A Debugging Standard for High-performance computing
IOS Press
2000-04-01
[30]
학회
Computational Science: ICCS 2003: International Conference
[31]
웹사이트
IMS XRF and Parallel Sysplex: A Positioning Paper
http://www-01.ibm.co[...]
[32]
웹인용
http://www.cc.gatech[...]
Georgia Institute of Technology College of Computing
1996-06-01
[33]
학회
Network-Based Information Systems: First International Conference, NBIS 2007
[34]
뉴스인용
http://www.sciam.com[...]
2001-08-16
[35]
뉴스인용
http://climate.ornl.[...]
[36]
서적
High Performance Linux Clusters
[37]
서적
High Performance Computing for Computational Science - VECPAR 2004
[38]
서적
Distributed services with OpenAFS: for enterprise and education
http://books.google.[...]
[39]
웹인용
Grid and Cluster Computing
http://books.google.[...]
2013-03-07
[40]
저널
A High-Performance, Portable Implementation of the MPI Message Passing Interface
[41]
서적
Computer Organization and Design
[42]
논문
Hybrid Map Task Scheduling for GPU-Based Heterogeneous Clusters
http://ieeexplore.ie[...]
[43]
간행물
Resource fencing using STONITH
ftp://ftp.telecom.uf[...]
IBM Linux Research Center
[44]
서적
Sun Cluster environment: Sun Cluster 2.2
[45]
서적
Computer Science: The Hardware, Software and Heart of It
http://books.google.[...]
[46]
서적
Parallel Programming: For Multicore and Cluster Systems
http://books.google.[...]
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com