추상화 (컴퓨터 과학)
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
추상화는 컴퓨터 과학에서 복잡한 시스템을 단순화하기 위해 세부 사항을 숨기고 핵심 정보만 나타내는 기술이다. 이는 하드웨어, 소프트웨어, 운영 체제, 데이터베이스 시스템, 객체 지향 프로그래밍 등 다양한 분야에서 활용되며, 제어 추상화와 데이터 추상화로 분류된다. 추상화는 설계 단순화, 개발 효율성 증대, 이식성 지원 등의 장점을 제공하지만, 모든 추상화는 하위 수준의 세부 사항이 드러나는 '누수'가 발생할 수 있다는 비판도 존재한다.
더 읽어볼만한 페이지
- 추상 - 마음
마음은 의식, 사고, 지각, 감정, 동기, 행동, 기억, 학습 등을 포괄하는 심리적 현상과 능력의 총체이며, 다양한 분야에서 연구되고 인간 삶의 중추적인 역할을 한다. - 추상 - 이론
이론은 특정 주제를 이해, 설명, 예측하기 위한 분석적 도구로, 논리적 원칙을 따르며, 과학에서는 관찰과 실험으로 확인된 사실에 기반한 자연 세계에 대한 설명으로, 반증 가능성을 지니고 학문 분야에서 지식 축적과 논리적 설명에 필수적인 역할을 한다. - 프로그래밍 패러다임 - 지식 표현
지식 표현은 컴퓨터가 인간의 지식을 이해하고 활용하도록 정보를 구조화하는 기술이며, 표현력과 추론 효율성의 균형, 불확실성 처리 등을 핵심 과제로 다양한 기법과 의미 웹 기술을 활용한다. - 프로그래밍 패러다임 - 의도적 프로그래밍
의도적 프로그래밍은 프로그래머의 의도를 명확히 포착하고 활용하여 소프트웨어 개발 생산성을 향상시키기 위한 프로그래밍 패러다임으로, 트리 기반 저장소를 사용해 코드 의미 구조를 보존하고, WYSIWYG 환경에서 도메인 전문가와 협업하며, 코드 상세 수준 조절 및 자동 문서화를 통해 가독성과 유지보수성을 높이는 데 중점을 둔다. - 데이터 관리 - 데이터 센터
데이터센터는 컴퓨터 시스템 및 관련 장비와 지원 인프라를 수용하는 시설로, 기술 발전에 따라 규모와 중요성이 확대되었으며, 에너지 효율과 보안을 고려하여 설계 및 운영되고, TIA-942 표준에 따른 티어 분류와 친환경 기술 도입이 이루어지고 있다. - 데이터 관리 - 정보 아키텍처
정보 아키텍처는 정보 시스템 및 정보 기술 분야에서 공유 정보 환경의 구조적 설계를 의미하며, 웹사이트, 소프트웨어 등의 구성과 레이블링을 포함하여 검색 용이성과 사용성을 지원하고, 도서관정보학에 기원을 두고 있다.
| 추상화 (컴퓨터 과학) | |
|---|---|
| 개요 | |
| 분야 | 컴퓨터 과학 |
| 하위 분야 | 소프트웨어 공학 프로그래밍 언어 이론 컴퓨터 과학 |
| 개념 | |
| 정의 | 복잡성을 다루는 기술 |
| 목표 | 복잡성 관리 정보 은닉 모듈화 재사용성 |
| 관련 개념 | 모듈화 정보 은닉 관심사의 분리 캡슐화 |
| 유형 | |
| 데이터 추상화 | 데이터 표현의 복잡성을 숨기고 필요한 연산만 제공 |
| 제어 추상화 | 프로그램 실행 흐름의 복잡성을 숨기고 고수준 제어 구조 제공 |
| 절차적 추상화 | 일련의 명령을 하나의 이름으로 묶어 재사용성을 높임 |
| 중요성 | |
| 복잡성 관리 | 복잡한 시스템을 이해하고 개발하는 데 필수적인 도구 |
| 재사용성 향상 | 추상화된 요소는 여러 번 재사용 가능 |
| 유지보수 용이성 | 변경 사항이 다른 부분에 미치는 영향을 줄여 유지보수를 쉽게 함 |
| 예시 | |
| 프로그래밍 언어 | 함수 클래스 인터페이스 |
| 운영체제 | 파일 시스템 가상 메모리 |
| 데이터베이스 | 뷰 (데이터베이스) 저장 프로시저 |
2. 추상화의 원리 및 개념
컴퓨터 과학에서 추상화는 복잡한 시스템을 다룰 때 핵심적인 정보를 보존하면서 관련 없는 세부 사항은 숨기거나 제거하는 과정을 의미한다.[5] 이는 구체적인 하드웨어 구현과 독립적으로 작동하는 교환 가능한 계산 모델을 만들거나,[6] 거대한 소프트웨어 시스템을 관리 가능한 부분으로 나누는 소프트웨어 아키텍처 설계의 기초가 된다. 이러한 아키텍처 자체가 특정 추상화의 선택과 활용을 기반으로 한다.
추상화의 중요한 예시는 언어 추상화이다. 시스템의 특정 측면을 표현하기 위해 새로운 인공 언어가 개발되는데, 계획 수립을 돕는 ''모델링 언어''나 컴퓨터가 직접 처리할 수 있는 ''컴퓨터 언어'' 등이 그 예이다. 프로그래밍 언어의 발전 과정, 즉 기계어에서 시작하여 점차 더 높은 수준의 추상화를 제공하는 어셈블리 언어, 고급 언어로 진화한 것은 언어 추상화가 어떻게 복잡성을 줄이고 생산성을 높이는지를 보여주는 대표적인 사례이다. 이러한 언어 추상화는 스크립트 언어나 도메인 특화 언어 등으로 계속 발전하고 있다.
프로그래밍 언어 자체 내에서도 개발자가 새로운 추상화를 만들 수 있도록 다양한 기능이 제공된다. 서브루틴, 모듈, 다형성, 소프트웨어 컴포넌트 등이 대표적이다. 또한, 소프트웨어 디자인 패턴이나 아키텍처 스타일과 같은 설계 기법들도 추상화의 한 형태로 볼 수 있으며, 이는 시스템의 구조를 이해하고 설계하는 데 도움을 준다.
하지만 모든 추상화는 완벽하게 세부 사항을 숨기지 못하고 때로는 기반 시스템의 복잡성이 드러나는 '누수'(leaky abstraction) 현상이 발생할 수 있다.[7] 조엘 스폴스키는 이러한 점을 지적하며 추상화가 하부 구조를 완전히 숨길 수는 없다고 주장했다. 그럼에도 불구하고, 추상화는 복잡한 시스템을 효과적으로 다루기 위한 필수적인 도구로 그 유용성은 매우 크다. 때로는 외부 함수 인터페이스처럼 서로 다른 추상화 수준 간의 상호작용을 위해 설계되기도 한다.
2. 1. 컴퓨팅에서의 추상화
컴퓨팅은 주로 구체적인 세상과는 독립적으로 작동한다. 하드웨어는 다른 것들과 상호 교환 가능한 계산 모델을 구현하며,[6] 소프트웨어는 인간이 한 번에 몇 가지 문제에 집중하여 거대한 시스템을 만들 수 있도록 소프트웨어 아키텍처로 구성된다. 이러한 아키텍처는 특정 추상화를 선택하고 활용한다. 그린스펀의 10번째 규칙은 그러한 아키텍처가 얼마나 필연적이고 복잡한지를 보여주는 격언이다.운영체제는 하드디스크에 대해 파일, 네트워크에 대해 포트, 메모리에 대해 주소, CPU에 대해 프로세스라는 추상화된 접근 방법을 제공한다. 이는 수학적 추상화의 유추로부터 유래된 개념이다. 존 V. 거택은 추상화의 본질을 다음과 같이 설명했다.[5]
추상화의 본질은 주어진 맥락에서 관련된 정보를 보존하고, 해당 맥락에서 관련 없는 정보를 잊는 것이다.
컴퓨팅에서 언어 추상화는 중심적인 형태이다. 시스템의 특정 측면을 표현하기 위해 새로운 인공 언어가 개발된다. ''모델링 언어''는 계획 수립에 도움을 주며, ''컴퓨터 언어''는 컴퓨터로 처리될 수 있다. 이러한 추상화 과정의 예로는 프로그래밍 언어가 기계어에서 어셈블리 언어를 거쳐 고급 언어로 세대별로 발전하는 것을 들 수 있다. 각 단계는 다음 단계를 위한 디딤돌로 사용될 수 있으며, 언어 추상화는 스크립트 언어와 도메인 특화 프로그래밍 언어 등에서 계속 발전하고 있다.
프로그래밍 언어 내에서는 프로그래머가 새로운 추상화를 만들 수 있도록 하는 기능들이 있다. 여기에는 서브루틴, 모듈, 다형성, 소프트웨어 컴포넌트 등이 포함된다. 또한, 소프트웨어 디자인 패턴 및 아키텍처 스타일과 같은 다른 추상화는 번역기에는 보이지 않지만 시스템 설계에서 중요한 역할을 한다.
일부 추상화는 프로그래머가 알아야 할 개념의 범위를 제한하기 위해 하위 세부 사항을 완전히 숨기려고 시도한다. 그러나 소프트웨어 엔지니어이자 작가인 조엘 스폴스키는 모든 추상화가 ''누수''되기 쉽다고 주장하며 이러한 노력을 비판했다. 즉, 추상화가 기반이 되는 세부 사항을 완벽하게 숨길 수는 없다는 의미이다.[7] 하지만 이것이 추상화 자체의 유용성을 부정하는 것은 아니다.
어떤 추상화는 다른 추상화와 상호 작용하도록 설계되기도 한다. 예를 들어, 프로그래밍 언어는 하위 수준 언어로 작성된 코드를 호출하기 위한 외부 함수 인터페이스를 포함할 수 있다.
2. 2. 언어 추상화
컴퓨팅에서 언어의 추상화는 핵심적인 역할을 한다. 새로운 인공 언어는 시스템의 특정 관점을 표현하기 위해 개발되며, 모델링 언어는 계획 수립을 돕고 컴퓨터 언어는 컴퓨터에서 처리될 수 있다. 이러한 추상화 과정의 대표적인 예는 프로그래밍 언어의 세대적 발전이다. 각 세대는 이전 세대를 기반으로 더 높은 수준의 추상화를 제공하며 발전해왔다. 이러한 언어 추상화는 스크립트 언어나 도메인 특화 언어(DSL) 등에서 계속해서 진화하고 있다.다양한 프로그래밍 언어는 의도된 응용 분야에 따라 여러 유형의 추상화를 제공한다.
- 객체 지향 프로그래밍 언어인 C++, 오브젝트 파스칼, 자바 등에서는 '추상화' 개념 자체가 선언문의 일부가 되었다. 예를 들어, C++에서는 `'function'('parameters') = 0;` 같은 구문을 사용하고[8], 자바에서는 `'abstract'`나 `'interface'` 같은 키워드를 사용한다.[9] 이러한 선언 이후에는 프로그래머가 해당 객체를 인스턴스화하기 위해 클래스를 구현해야 한다.
- 함수형 프로그래밍 언어는 주로 람다 추상화(표현식을 특정 변수에 대한 함수로 만드는 것)나 고차 함수(함수를 인자로 받거나 반환하는 함수)와 관련된 추상화를 특징으로 한다.[10]
- 클로저, Scheme, Common Lisp와 같은 Lisp 계열 언어들은 구문 매크로 시스템을 통해 구문 자체를 추상화할 수 있게 지원한다. Scala, Haskell(Template Haskell), OCaml(MetaOCaml) 등 다른 언어들도 유사한 메타 프로그래밍 기능을 제공한다. 이를 통해 프로그래머는 반복적인 상용구 코드를 줄이고, 복잡한 함수 호출을 단순화하며, 새로운 제어 구조를 만들거나, 특정 분야의 문제를 간결하게 표현하는 도메인 특화 언어(DSL)를 구현할 수 있다. 이러한 기능들은 프로그래머의 생산성과 코드의 명확성을 높이는 데 기여한다.
프로그래밍 언어의 기능 외에도, 프로그래머는 서브루틴, 모듈, 소프트웨어 컴포넌트 등을 통해 새로운 추상화를 만들 수 있다. 또한, 디자인 패턴이나 소프트웨어 아키텍처와 같은 설계 기법도 추상화의 한 형태이다.
그러나 추상화는 기반이 되는 복잡한 내용을 완전히 숨기려는 시도에도 불구하고 완벽하지 않을 수 있다. 조엘 스폴스키는 모든 추상화가 세부 사항을 완벽히 숨기지 못하고 때로는 문제가 발생하는 '누수 추상화'가 될 수 있다고 지적했다. 즉, 추상화에 의해 하부 구조가 완전히 은폐되는 경우는 드물다는 것이다. 일부 추상화는 다른 추상화와의 상호 작용을 염두에 두고 설계되기도 한다. 예를 들어, 어떤 프로그래밍 언어는 다른 언어와의 상호작용을 위해 외부 함수 인터페이스를 제공하여 저수준 언어를 호출할 수 있게 하는데, 이는 추상화 계층 아래의 세부 사항이 드러나는 경우이다.
2. 3. 프로그래밍 언어와 추상화
다양한 프로그래밍 언어는 해당 언어의 의도된 응용 분야에 따라 다양한 유형의 추상화를 제공한다.- 객체 지향 프로그래밍 언어인 C++, 오브젝트 파스칼, 또는 자바에서는 추상화 개념 자체가 선언문을 통해 구현될 수 있다. C++에서는 구문 `
function(parameters) = 0;`을 사용하거나, 자바에서는 키워드 `abstract`[8] 및 `interface`[9]를 사용한다. 때로는 `virtual` 키워드를 사용하기도 한다. 이러한 선언 이후에는 선언의 객체를 인스턴스화하기 위해 프로그래머가 클래스를 구현해야 한다. - 함수형 프로그래밍 언어는 일반적으로 람다 추상화(항을 특정 변수의 함수로 만드는 것) 및 고차 함수(매개변수가 함수인 경우)와 관련된 추상화를 나타낸다.[10]
- 클로저, Scheme 및 Common Lisp와 같은 Lisp 프로그래밍 언어 계열의 현대적인 구성원들은 구문 매크로 시스템을 지원하여 구문 추상화를 허용한다. Scala와 같은 다른 프로그래밍 언어에도 매크로나 매우 유사한 메타 프로그래밍 기능이 있다 (예: Haskell에는 Template Haskell이 있고 OCaml에는 MetaOCaml이 있다). 이러한 기능을 통해 프로그래머는 상용구 코드를 제거하고, 지루한 함수 호출 시퀀스를 추상화하고, 새로운 제어 흐름 구조를 구현하며, 도메인 특화 언어(DSL)를 구현하여 도메인별 개념을 간결하고 우아하게 표현할 수 있다. 이는 프로그래머의 효율성과 코드의 명확성을 개선하는 데 도움을 준다.
- Linda라는 언어에서는 "서버"와 "공유 데이터 공간"과 같은 개념을 추상화하여 분산 프로그래밍을 실현한다.
프로그래밍 언어에서는 프로그래머가 새로운 추상화를 만들어낼 수 있도록 서브루틴, 모듈, 소프트웨어 컴포넌트 등의 기능을 제공하기도 한다. 또한, 프로그래밍 언어 자체의 기능은 아니지만 디자인 패턴이나 소프트웨어 아키텍처와 같은 설계 기법상의 추상화도 존재한다.
3. 추상화의 유형
컴퓨터 과학에서의 추상화는 크게 제어 추상화와 데이터 추상화의 두 가지 유형으로 나눌 수 있다.
3. 1. 제어 추상화
프로그래밍 언어를 사용하는 주요 목적 중 하나는 제어 추상화를 제공하는 것이다. 컴퓨터는 메모리의 한 위치에서 다른 위치로 비트를 옮기거나, 두 비트열의 합을 구하는 것과 같은 매우 낮은 수준의 연산만을 이해한다. 프로그래밍 언어는 이러한 연산을 더 높은 수준에서 수행할 수 있게 해준다. 예를 들어, 파스칼과 유사한 다음 구문을 보자.:
a := (1 + 2) * 5사람에게는 "1 더하기 2는 3이고, 여기에 5를 곱하면 15"라는 매우 단순하고 명백한 계산처럼 보인다. 하지만 컴퓨터가 이 계산을 수행하고 결과 값 15를 변수 'a'에 할당하기까지의 낮은 수준 단계는 실제로는 매우 미묘하고 복잡하다. 값들은 이진 표현으로 변환되어야 하고(이는 종종 생각보다 복잡한 작업이다), 계산은 컴파일러나 인터프리터에 의해 기계어나 어셈블리 언어 명령어로 분해되어야 한다. 이러한 명령어는 프로그래머에게 직관적이지 않으며, 레지스터를 조작하는 방식은 인간이 덧셈이나 곱셈 같은 추상적인 산술 연산을 생각하는 방식과 다르다. 마지막으로, 결과 값 15를 'a'라는 이름의 변수에 할당하는 과정에는 변수 이름과 실제 물리적 또는 가상 메모리 주소를 연결하고, 해당 메모리 위치에 15의 이진 표현을 저장하는 등의 추가적인 단계가 포함된다.
제어 추상화가 없다면, 프로그래머는 단순히 두 숫자를 더하거나 곱해서 변수에 할당하는 간단한 작업을 할 때조차 레지스터나 메모리 주소 수준의 모든 단계를 일일이 지정해야 한다. 이러한 중복 작업은 두 가지 심각한 문제를 일으킨다.
# 프로그래머는 비슷한 연산이 필요할 때마다 매우 일반적인 작업을 계속해서 반복해야 한다.
# 프로그래머는 특정 하드웨어와 명령어 세트에 맞춰서만 프로그래밍해야 한다.
구조적 프로그래밍은 제어 흐름을 명확히 하고 구성 요소 간의 인터페이스를 정의하여, 복잡한 프로그램을 더 작은 조각으로 나누는 방식을 포함한다. 이를 통해 부작용으로 인한 복잡성을 줄이는 것을 목표로 한다.
단순한 프로그램에서는 루프의 종료 지점을 하나로 명확하게 만들거나, 함수 및 프로시저의 종료 지점을 하나로 제한하는 기법을 사용한다.
더 큰 시스템에서는 복잡한 작업을 여러 모듈로 분할한다. 예를 들어, 선박과 육상 사무실에서 급여를 처리하는 시스템을 생각해 보자.
- 가장 상위 수준에는 최종 사용자를 위한 작업 메뉴가 있을 수 있다.
- 그 아래에는 직원의 등록 및 해고, 급여 명세서 인쇄와 같은 특정 작업을 위한 독립적인 실행 파일이나 라이브러리가 존재할 수 있다.
- 각 독립 구성 요소는 여러 개의 소스 파일로 이루어질 수 있으며, 각 파일은 문제의 특정 부분을 처리하고 다른 프로그램 부분과는 정의된 인터페이스를 통해서만 상호작용한다. 예를 들어, 직원 등록 프로그램에는 데이터 입력 화면과 데이터베이스 인터페이스(자체적으로 독립적인 서드 파티 라이브러리이거나 정적으로 연결된 라이브러리 루틴 모음일 수 있음)를 위한 소스 파일들이 포함될 수 있다.
- 데이터베이스나 급여 애플리케이션은 선박과 육상 사무실 간의 데이터 교환 프로세스를 시작해야 할 수도 있으며, 이 데이터 전송 작업에는 또 다른 많은 구성 요소가 포함될 수 있다.
이러한 계층 구조는 한 구성 요소의 구현 세부 사항을 다른 구성 요소로부터 격리하는 효과를 가진다. 객체 지향 프로그래밍은 이러한 개념을 받아들여 더욱 확장시킨 것이다.
3. 2. 데이터 추상화
'''데이터 추상화'''는 자료형의 ''추상적'' 속성과 구현의 ''구체적인'' 세부 사항 간의 명확한 분리를 강제하는 개념이다. 추상 속성은 자료형을 사용하는 클라이언트 코드에 보이는 부분, 즉 자료형에 대한 ''인터페이스''를 의미하며, 구체적인 구현은 외부에 공개되지 않고 숨겨진다. 이를 통해 구현 방식은 내부적으로 효율성을 개선하는 등의 이유로 변경될 수 있으며, 이러한 변경이 인터페이스, 즉 추상적인 동작에 영향을 주지 않는다면 클라이언트 코드 역시 수정할 필요가 없게 된다.예를 들어, '키'를 '값'에 고유하게 연결하고 해당 키를 통해 값을 검색할 수 있는 추상 자료형(ADT)인 '조회 테이블'을 정의할 수 있다. 이 조회 테이블은 해시 테이블, 이진 검색 트리, 또는 단순한 선형 리스트 등 다양한 방식으로 내부적으로 구현될 수 있다. 하지만 클라이언트 코드 입장에서는 어떤 구현 방식을 사용하든 조회 테이블이라는 자료형의 추상적인 속성(키로 값을 찾거나 저장하는 기능)은 동일하게 유지된다.
데이터 추상화에서 인터페이스는 자료형과 클라이언트 코드 간의 합의된 동작에 대한 계약과 같은 역할을 한다. 따라서 인터페이스 설계가 매우 중요하며, 만약 인터페이스 자체가 변경되면 이를 사용하는 클라이언트 코드에 큰 영향을 미칠 수 있다. 계약(인터페이스)에 명시되지 않은 내부 구현의 세부 사항은 언제든지 예고 없이 변경될 수 있다.
데이터 추상화를 잘 구현한 프로그래밍 언어로는 Ada와 Modula-2 등이 있다. 객체 지향 프로그래밍(OOP) 언어들도 일반적으로 데이터 추상화를 제공한다고 여겨지지만, 상속 개념으로 인해 부모 클래스의 구현 세부 정보가 자식 클래스(인터페이스 사용자)에게 노출되는 경향이 있다. 이로 인해 상속 관계의 변경이 클라이언트 코드에 영향을 미치는 취약한 기본 클래스 문제가 발생할 수 있다.
4. 추상화의 적용 분야
컴퓨터 과학에서 추상화는 복잡한 시스템을 이해하고 다루기 쉽게 만드는 핵심적인 기법으로, 다양한 분야에서 활용된다. 주요 적용 분야는 다음과 같다.
- 운영 체제: 하드웨어의 복잡한 세부 사항을 사용자나 응용 프로그램으로부터 숨기고, 파일, 포트, 프로세스 등 일관되고 사용하기 쉬운 인터페이스를 제공하기 위해 추상화를 활용한다.
- 데이터베이스 시스템: 데이터가 실제로 저장되는 물리적인 방식이나 전체 데이터 구조의 복잡성을 감추고, 사용자가 필요한 데이터에 쉽게 접근하고 조작할 수 있도록 논리적 수준이나 뷰 수준 등 여러 단계의 추상화를 적용한다.
- 객체 지향 프로그래밍: 현실 세계의 개념이나 시스템의 구성 요소를 속성(데이터)과 행위(메서드)를 가진 객체로 모델링하여 코드의 재사용성과 유지보수성을 높인다. 캡슐화, 상속, 다형성 등이 추상화를 구현하는 주요 기법이다.
- 소프트웨어 설계: 거대하고 복잡한 소프트웨어 시스템을 설계할 때, 문제를 작은 단위로 나누고 각 단위의 세부 구현을 감추어 전체 구조를 단순화한다. 디자인 패턴이나 소프트웨어 아키텍처 자체가 특정 문제 해결을 위한 추상화된 접근 방식을 제공한다.
4. 1. 운영 체제
운영체제는 하드디스크에 대해 파일, 네트워크에 대해 포트, 메모리에 대해 주소, CPU에 대해 프로세스와 같이 추상화된 접근 방법을 제공한다. 이를 통해 사용자는 복잡한 하드웨어의 세부 사항을 알 필요 없이 컴퓨터를 사용할 수 있다. 이 개념은 수학적 추상화에서 유추되었다.4. 2. 데이터베이스 시스템
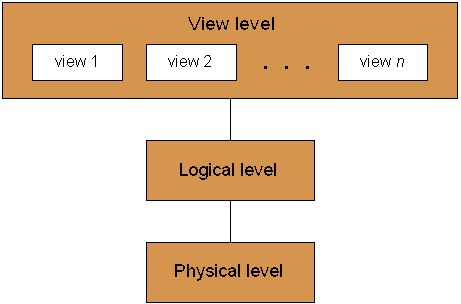
데이터베이스 시스템 사용자의 대부분은 컴퓨터의 데이터 구조에 대해 깊이 있는 지식이 부족한 경우가 많으므로, 데이터베이스 개발자는 다음과 같은 추상화 수준을 통해 복잡성을 숨기는 경우가 많다.
; 물리적 수준 (Physical level)
: 가장 낮은 수준의 추상화이며, 데이터가 실제로 어떻게 저장되는지를 기술한다. 물리적 수준에서는 하위 수준의 복잡한 데이터 구조의 세부 사항이 기술된다.
; 논리적 수준 (Logical level)
: 다음 추상화 수준에서는 데이터베이스에 저장된 데이터가 무엇인지 기술하고, 해당 데이터 간에 어떤 관계가 있는지를 기술한다. 따라서, 논리적 수준에서는 물리적 수준보다 단순화된 구조로 데이터베이스 전체가 기술된다. 논리적 수준의 단순한 구조를 구현하기 위해서는 물리적 수준의 복잡한 구조가 필요하지만, 논리적 수준의 사용자는 이러한 복잡성을 알 필요가 없다. 이를 물리적 데이터 독립성이라고 한다. 데이터베이스 관리자는 데이터베이스에 저장해야 할 정보를 선별할 책임이 있으며, 논리적 수준의 추상화를 이용한다.
; 뷰 수준 (View level)
: 가장 높은 수준의 추상화는 데이터베이스의 일부만 기술한다. 논리적 수준의 구조는 어느 정도 단순화되어 있지만, 거대한 데이터베이스에 저장되는 데이터의 다양성 때문에 어느 정도의 복잡성이 남아 있다. 데이터베이스 이용자의 대부분은 데이터베이스 내의 모든 정보를 반드시 필요로 하지 않는다. 오히려 일부 데이터에만 접근하는 경우가 많다. 뷰 수준의 추상화를 통해, 이용자와 시스템 간의 상호 작용이 단순화된다. 시스템은 하나의 데이터베이스에 대해 여러 개의 뷰를 제공할 수 있다.
4. 3. 객체 지향 프로그래밍
객체 지향 프로그래밍 이론에서 추상화는 작업을 수행하고, 상태를 보고하거나 변경하며, 시스템의 다른 객체와 "통신"할 수 있는 추상적인 "행위자(actor)"를 나타내는 객체를 정의하는 기능을 포함한다. 캡슐화는 상태의 세부 정보를 숨기는 것을 의미하지만, 이전 프로그래밍 언어의 '데이터 유형' 개념을 확장하여 '행동'을 데이터와 강하게 연관시키고, 서로 다른 데이터 유형이 상호 작용하는 방식을 표준화하는 것이 추상화의 시작이다. 추상화가 진행되어 정의된 연산을 통해 서로 다른 유형의 객체를 대체할 수 있게 되면, 이를 다형성이라고 한다. 반대로 유형이나 클래스 내부로 추상화가 진행되어 복잡한 관계를 단순화하도록 구조화하면, 이를 위임 또는 상속이라고 한다.다양한 객체 지향 프로그래밍 언어는 추상화를 위한 유사한 기능을 제공하며, 모두 객체 지향 프로그래밍에서 일반적인 다형성 전략을 지원하기 위한 것이다. 이는 동일하거나 유사한 역할에서 한 유형을 다른 유형으로 대체하는 것을 포함한다. 일반적으로 지원되지는 않지만, 구성, 이미지 또는 패키지는 컴파일 타임, 링크 타임, 또는 로드 타임에 이러한 이름 바인딩의 상당수를 미리 결정할 수 있다. 이렇게 하면 런타임에 변경해야 하는 바인딩이 최소화된다.
예를 들어, 공통 리스프 객체 시스템 또는 셀프와 같은 언어는 클래스와 인스턴스 구분이 덜 명확하며, 다형성을 위해 위임을 더 많이 사용한다. 개별 객체와 함수는 리스프에서 공유된 기능적 유산을 더 잘 맞추기 위해 더 유연하게 추상화된다.
C++는 또 다른 극단을 보여준다. 이 언어는 템플릿, 오버로딩, 기타 컴파일 타임의 정적 바인딩에 크게 의존하며, 이는 특정 유연성 문제를 야기하기도 한다.
이러한 예는 동일한 추상화를 달성하기 위한 대체 전략을 보여주지만, 코드에서 추상적인 개념(명사)을 지원해야 하는 필요성을 근본적으로 변경하지는 않는다. 모든 프로그래밍은 동사(기능)를 함수로, 명사(데이터)를 자료 구조로, 그리고 이 둘을 결합하여 프로세스로 추상화하는 능력에 의존한다.
예를 들어, 농장의 "동물"을 배고픔과 먹이 공급이라는 간단한 측면에서 모델링하는 자바 코드 조각을 살펴보자. 동물의 상태와 기능을 모두 나타내기 위해
Animal 클래스를 정의한다.public class Animal extends LivingThing
{
private Location loc;
private double energyReserves;
public boolean isHungry() {
return energyReserves < 2.5;
}
public void eat(Food food) {
// Consume food
energyReserves += food.getCalories();
}
public void moveTo(Location location) {
// Move to new location
this.loc = location;
}
}
위 정의를 사용하면
Animal 유형의 객체를 생성하고 다음과 같이 해당 메서드를 호출할 수 있다.thePig = new Animal();
theCow = new Animal();
if (thePig.isHungry()) {
thePig.eat(tableScraps);
}
if (theCow.isHungry()) {
theCow.eat(grass);
}
theCow.moveTo(theBarn);
위 예에서 클래스
Animal은 실제 동물 대신 사용되는 추상화이며, LivingThing은 Animal의 또 다른 추상화(이 경우 더 일반화된 개념)이다.만약 우유를 제공하는 동물(예: 소, 염소)과 생을 마감할 때 고기만 제공하는 동물(예: 돼지, 황소)을 구별해야 한다면, 더 세분화된 동물 계층 구조(예:
DairyAnimal, MeatAnimal)를 만들 수 있다. 이는 중간 수준의 추상화가 된다.이러한 추상화를 통해 애플리케이션 개발자는 구체적인 먹이 종류를 지정할 필요 없이 먹이 공급 일정과 같은 핵심 로직에 집중할 수 있다. 이들 클래스는 상속을 사용하여 관련될 수도 있고, 독립적으로 존재할 수도 있으며, 프로그래머는 두 유형 간의 다양한 정도의 다형성을 정의할 수 있다. 이러한 기능은 언어마다 크게 다르지만, 일반적으로 각 언어는 다른 언어에서 가능한 기능을 대부분 구현할 수 있다. 컴파일 타임에 다양한 연산자 오버로딩을 사용하거나 데이터 유형별로 동일한 효과를 얻는 것은, 다형성을 달성하기 위한 상속이나 다른 수단과 유사한 결과를 낼 수 있다. 클래스 표기법은 단순히 코더의 편의를 위한 것이다.
무엇을 추상화하고 무엇을 코드 작성자의 제어 하에 둘 것인지는 객체 지향 설계와 도메인 분석의 주요 주제이다. 현실 세계에서의 적절한 관계를 파악하는 것은 객체 지향 분석의 핵심이기도 하다.
일반적으로 적절한 추상화를 결정하기 위해서는 범위 정의, 도메인 분석, 연계할 시스템 결정, 다양한 제약 조건 분석 등 여러 판단이 필요하다. 그리고 객체 지향 분석은 프로젝트의 시간과 비용 같은 외부 조건을 고려하여 수행된다. 위의 간단한 예에서 도메인은 '농장'이고, 돼지, 소, 그들의 식습관이 제약 조건이다. 분석 결과, 개발자는 어떤 종류의 먹이든 줄 수 있는 유연성이 필요하다고 판단할 수 있다. 그래서 클래스 자체에 먹이 유형을 고정하지 않고, 돼지든 소든 같은
Animal 클래스를 사용하기로 결정할 수 있다. 만약 DairyAnimal을 별도의 클래스로 만들기로 결정하면 세부 구현은 달라지지만, 도메인이나 제약 조건 자체는 변하지 않는다. 이처럼 추상화 수준과 방식은 프로그래머의 판단에 따라 달라지며, 객체 지향 프로그래밍에서의 추상화와 도메인 및 제약 조건의 추상화는 구별될 필요가 있다.4. 4. 소프트웨어 설계
소프트웨어 설계에서 여러 수준의 추상화를 활용하는 것은 설계를 단순화하고, 다양한 역할의 사람들이 각자에게 맞는 추상화 수준에서 효율적으로 작업할 수 있게 돕는다.[1][2] 이는 시스템 디자인이나 비즈니스 프로세스 설계 등 다양한 분야에서 활용된다.[1][2] 일부 디자인 프로세스나 모델링 언어는 여러 추상화 수준을 포함하는 설계를 직접 만들어내기도 한다.[1][2]객체 지향 설계와 도메인 분석에서는 무엇을 추상화하고 무엇을 프로그래머(코더)의 제어 하에 둘 것인지 결정하는 것이 주요 관심사이다.[1][3] 적절한 추상화를 결정하기 위해서는 도메인 분석, 연관 시스템 분석(레거시 분석), 그리고 프로젝트의 시간 및 예산 제약 조건 내에서의 상세한 객체 지향 분석이 필요하다.[1][3]
소프트웨어는 거대한 시스템을 구축할 때 인간이 한 번에 일부 문제에만 집중할 수 있도록 돕는 소프트웨어 아키텍처를 기반으로 만들어진다. 이러한 아키텍처는 특정 추상화를 선택하고 활용하는 방식으로 구성된다.[1] 프로그래밍 언어 자체의 기능은 아니지만, 디자인 패턴이나 소프트웨어 아키텍처는 설계 기법 수준에서의 중요한 추상화 방식이다.[1]
프로그래밍 언어는 서브루틴, 모듈, 소프트웨어 컴포넌트와 같은 기능을 통해 프로그래머가 새로운 추상화를 만들 수 있도록 지원한다.[1] 이러한 추상화는 하위 단계의 복잡한 개념을 감추어 프로그래머가 다루어야 할 개념의 범위를 제한하는 것을 목표로 한다.[1] 하지만 조엘 스폴스키는 모든 추상화는 결국 파탄하기 쉽다고 지적하며, 추상화가 하부 구조를 완벽하게 감추지는 못한다고 비판하기도 했다.[1]
5. 추상화의 계층
컴퓨터 과학에서는 일반적으로 다양한 수준의 추상화, 또는 추상화 계층을 사용한다. 각 수준은 동일한 정보와 프로세스를 서로 다른 모델로 나타내지만, 포함하는 세부 사항의 양에서 차이가 있다. 각 계층은 특정 영역에 적용되는 고유한 객체 및 구성 집합을 포함하는 표현 시스템을 사용한다.[12]
상대적으로 추상적인 "상위" 계층은 상대적으로 구체적인 "하위" 계층을 기반으로 하며, 하위 계층으로 갈수록 점점 더 세분화된 표현을 제공하는 경향이 있다. 예를 들어, 논리 게이트는 전자 회로를 기반으로 하고, 이진법은 논리 게이트를 기반으로 하며, 기계어는 이진법을 기반으로 한다. 또한, 프로그래밍 언어는 기계어를 기반으로 하고, 응용 프로그램과 운영 체제는 프로그래밍 언어를 기반으로 구축된다. 각 계층은 하위 계층에 의해 구현되지만, 어느 정도 자체적으로 완결된 설명 언어를 가지므로 하위 계층에 완전히 종속되지는 않는다.
다양한 수준의 추상화를 제공하는 능력은 다음과 같은 장점을 가진다.
- 설계를 상당히 단순화할 수 있다.
- 서로 다른 역할을 맡은 사람들이 각자 다른 추상화 수준에서 효과적으로 작업할 수 있게 한다.
- 소프트웨어 아티팩트의 이식성을 지원한다.
이러한 추상화 계층 개념은 시스템 설계와 비즈니스 프로세스 모델링 모두에서 활용될 수 있다. 일부 소프트웨어 모델링 설계 과정에서는 다양한 추상화 수준을 포함하는 설계를 의도적으로 생성하기도 한다.
계층형 아키텍처는 응용 프로그램의 관심사를 여러 개의 쌓인 그룹, 즉 계층으로 나누는 것을 의미한다. 이는 컴퓨터 소프트웨어, 하드웨어 및 통신 설계에 사용되는 기술로, 시스템이나 네트워크 구성 요소를 계층별로 분리하여 한 계층의 변경이 다른 계층에 영향을 미치지 않도록 돕는다.
6. 추상화와 관련된 논쟁 및 비판
소프트웨어 엔지니어이자 작가인 조엘 스폴스키는 일부 추상화가 프로그래머가 알아야 할 개념의 범위를 제한하기 위해 하위 수준의 세부 사항을 완전히 숨기려고 시도하는 것에 대해 비판적인 입장을 보였다. 그는 모든 추상화는 본질적으로 '누수'될 수밖에 없다고 주장했다. 이는 추상화가 아무리 잘 설계되어도 기반이 되는 하위 수준의 세부 사항이 예기치 않게 상위 수준으로 드러나 문제를 일으킬 수 있음을 의미한다.[7] 예를 들어, 고수준 언어로 프로그래밍하더라도 메모리 관리나 하드웨어의 특정 동작 방식과 같은 저수준의 문제가 때때로 코드에 영향을 미칠 수 있다.
그러나 스폴스키의 이러한 비판이 추상화 자체의 유용성을 전면적으로 부정하는 것은 아니다. 추상화는 복잡한 시스템을 다루는 데 있어 여전히 필수적인 도구이며, '누수' 가능성을 인지하고 이를 관리하는 것이 중요하다는 점을 시사한다.
참조
[1]
논문
Abstraction in Computer Science
2007-06-05
[2]
논문
Is abstraction the key to computing?
2007-04-01
[3]
논문
Constructivism in computer science education
1998-03-01
[4]
논문
Keynote address – data abstraction and hierarchy
ACM
1988-05-01
[5]
서적
Introduction to Computation and Programming Using Python
The MIT Press
2013-01-18
[6]
논문
The Method of Levels of Abstraction
http://link.springer[...]
2008-09
[7]
웹사이트
The Law of Leaky Abstractions
http://www.joelonsof[...]
[8]
웹사이트
Abstract Methods and Classes
http://docs.oracle.c[...]
Oracle
2014-09-04
[9]
웹사이트
Using an Interface as a Type
http://docs.oracle.c[...]
Oracle
2014-09-04
[10]
문서
Abstraction
[11]
논문
Adjudication rather than experience of data abstraction matters more in reducing errors in abstracting data in systematic reviews
2020
[12]
간행물
Levellism and the Method of Abstraction
http://www.cs.ox.ac.[...]
IEG – Research Report 22.11.04
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com