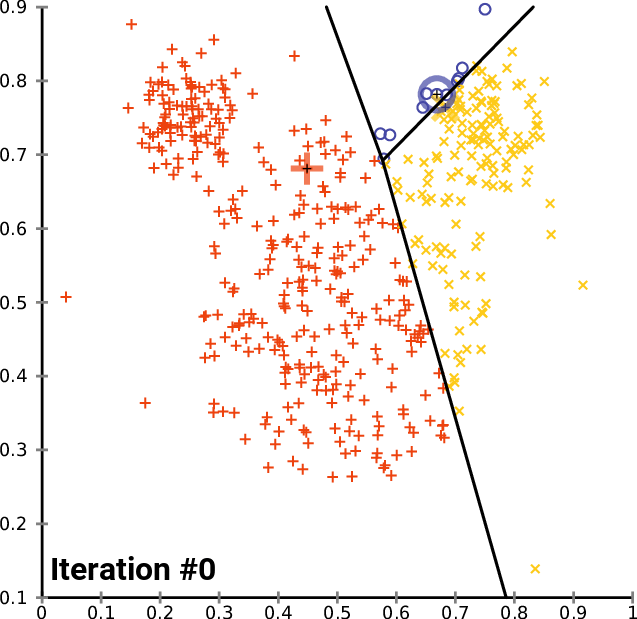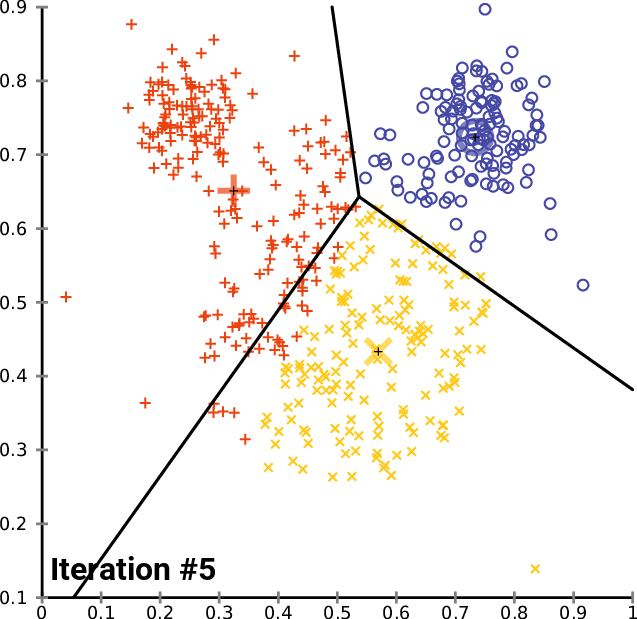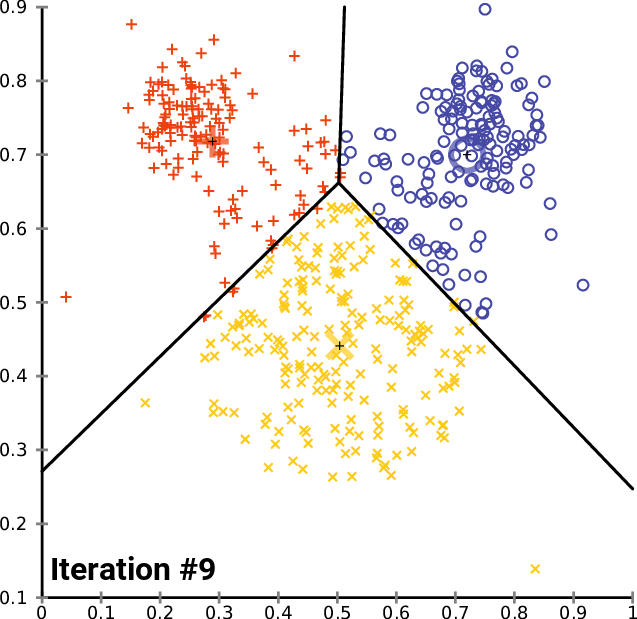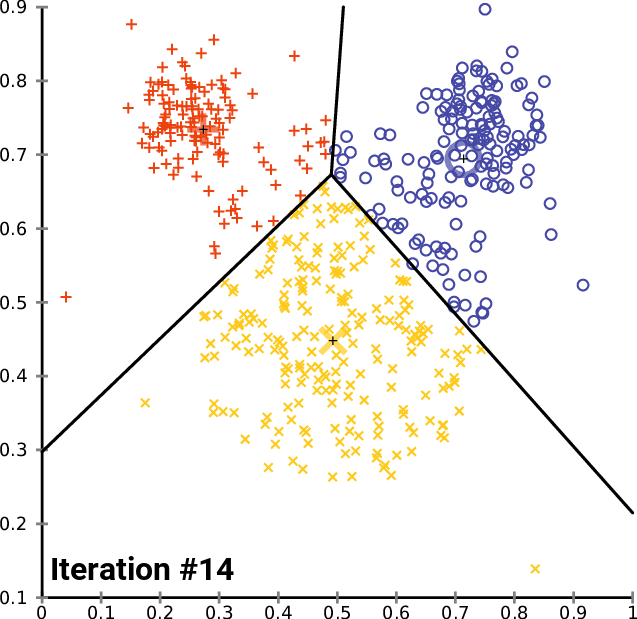
K-평균 알고리즘은 주어진 데이터를 k개의 클러스터로 분할하는 클러스터링 방법이다. 1957년 개념이 소개되었고, 1967년 제임스 맥퀸에 의해 용어가 사용되었다. 이 알고리즘은 각 데이터를 가장 가까운 클러스터 중심에 할당하고, 클러스터 중심을 재조정하는 과정을 반복하며, 유클리드 거리를 사용하여 구형 클러스터를 가정한다.
K-평균 알고리즘은 클러스터 개수(k)를 미리 정해야 하고, 지역 최솟값에 수렴할 수 있으며, 이상치와 구형 클러스터가 아닌 데이터에 취약하다는 한계가 있다. 클러스터 수를 결정하기 위해 엘보 방법, 실루엣 분석 등을 사용할 수 있으며, 내부 및 외부 평가 척도를 통해 클러스터링 결과를 평가한다.
K-평균 알고리즘은 시장 분할, 컴퓨터 비전, 신호 처리 등 다양한 분야에 응용되며, EM 알고리즘, 평균점 이동 클러스터링 등 다른 클러스터링 알고리즘과 관계가 있다. k-중앙값, k-메도이드, 퍼지 C-평균, k-평균++ 등의 변형 알고리즘이 존재한다.
클러스터 분석 알고리즘 - 계층적 군집화 계층적 군집화는 데이터 개체들을 계층적인 클러스터 구조로 조직화하는 군집 분석 방법으로, 개별 객체에서 시작하여 점진적으로 클러스터를 병합하거나 전체 데이터 셋에서 시작하여 클러스터를 분할하는 방식으로 진행되며, 덴드로그램을 통해 시각적으로 표현되고 다양한 연결 기준과 알고리즘을 사용해 데이터 특성에 맞는 클러스터링 결과를 제공한다.
기계 학습 - 비지도 학습 비지도 학습은 레이블이 없는 데이터를 통해 패턴을 발견하고 데이터 구조를 파악하는 것을 목표로 하며, 주성분 분석, 군집 분석, 차원 축소 등의 방법을 사용한다.
기계 학습 - 지도 학습 지도 학습은 레이블된 데이터를 사용하여 입력 데이터와 출력 레이블 간의 관계를 학습하는 기계 학습 분야로, 예측 모델 생성, 알고리즘 선택, 모델 최적화, 정확도 평가 단계를 거치며, 회귀 및 분류 문제에 적용되고 다양한 확장 기법과 성능 평가 방법을 활용한다.
"k-평균" 개념은 1957년 후고 스테인하우스가 소개했으나,[73] "k-평균"이라는 용어 자체는 1967년 제임스 매퀸(James MacQueen)이 처음 사용했다.[74] 1957년 스튜어트 로이드(Stuart Lloyd)가 펄스 부호 변조(PCM)를 목적으로 표준 알고리즘을 처음 고안했으나, 1982년에야 컴퓨터 과학 매거진에 처음 공개되었다.[75] 1965년에는 E. W. Forgy가 같은 알고리즘을 제안하기도 했다.[76]
2. 1. 알고리즘의 발전
"k-평균"이라는 용어는 1967년 제임스 맥퀸에 의해 처음 사용되었지만,[74][2] 그 아이디어는 1956년 후고 스테인하우스까지 거슬러 올라간다.[73][3] 표준 알고리즘은 1957년 벨 연구소의 스튜어트 로이드(Stuart Lloyd영어)가 펄스 부호 변조(PCM) 기법으로 처음 제안했지만, 1982년이 되어서야 컴퓨터 과학 매거진에 처음 공개되었다.[75][4] 1965년 에드워드 W. 포기(E. W. Forgy)는 본질적으로 동일한 방법을 발표했으며, 이 때문에 때때로 로이드-포기 알고리즘이라고도 불린다.[76][5] 1975년과 1979년에 Hartigan과 Wong에 의해 거리 계산이 필요하지 않은 좀 더 효율적인 방법이 소개되었다.[77][78]
3. 목표
k-평균 클러스터링 알고리즘은 주어진 데이터를 k개의 클러스터로 묶는 방법으로, 각 클러스터 내 데이터와 중심점 간의 거리 제곱합(WCSS)을 최소화하는 것을 목표로 한다.[79]
n개의 d-차원 데이터 오브젝트 ('''x'''1, '''x'''2, …, '''x'''''n'') 집합이 주어졌을 때, k-평균 알고리즘은 이 데이터들을 각 집합 내 오브젝트 간 응집도를 최대로 하는 개의 집합 '''S''' = {''S''1, ''S''2, …, ''S''''k''}으로 나눈다.
목표는 다음 식을 최소화하는 클러스터 집합 S를 찾는 것이다.
여기서 '''''μ'''''i''는 집합 ''S''''i''의 중심점이다. 즉, 각 클러스터별 중심점과 클러스터 내 데이터 간 거리의 제곱합을 최소로 하는 집합 '''S'''를 찾는 것이 목표이다.
이 식은 다음과 같이 표현할 수도 있다.
여기서 는 의 크기이고, 는 의 분산이다.
이것은 같은 클러스터 내의 점들 간의 쌍별 제곱 편차를 최소화하는 것과 같으며, 다음 식으로 표현할 수 있다.
이는 다른 클러스터 간의 제곱 편차 합(BCSS)을 최대화하는 것과 같다.[1]
하지만 이 목적 함수의 전역 최솟값을 찾는 것은 NP-난해 문제이므로, 언덕 오르기 방식으로 오차를 줄여나가며 지역 최솟값을 찾으면 알고리즘을 종료하여 근사 최적해를 구한다.
4. 알고리즘
k-평균 클러스터링 알고리즘은 주어진 데이터를 k개의 클러스터로 묶는 방법으로, 각 클러스터는 중심점(centroid)을 가진다. 이 알고리즘의 목표는 각 데이터와 해당 데이터가 속한 클러스터 중심점 간의 거리 제곱합을 최소화하는 것이다. 이렇게 함으로써 같은 클러스터 내 데이터들은 서로 유사하고, 다른 클러스터의 데이터와는 덜 유사하게 된다.[79]
k-평균 알고리즘의 수렴
알고리즘은 반복적으로 개선되며, 하위 섹션 "표준 알고리즘(Naive k-means)"에서 다루는 "할당 단계"와 "업데이트 단계"를 거치면서 각 데이터의 소속 클러스터를 갱신한다.[7]
할당 단계: 각 데이터를 가장 가까운 중심점에 할당한다.
업데이트 단계: 각 클러스터의 중심점을 새로 계산한다.
이 과정을 통해 클러스터 내 제곱합(WCSS)이 감소하며, 이는 알고리즘이 항상 수렴함을 의미한다. 그러나 반드시 최적의 해로 수렴하는 것은 아니다.[9]
일반적인 알고리즘 구현 흐름은 다음과 같다.[71][72]
1. 각 데이터에 대해 무작위로 클러스터를 할당한다.
2. 할당된 데이터를 기반으로 각 클러스터의 중심을 계산한다. (주로 산술 평균 사용)
3. 각 데이터와 각 중심 간의 거리를 계산하여, 가장 가까운 중심의 클러스터에 데이터를 재할당한다.
4. 모든 데이터의 클러스터 할당이 변하지 않거나, 변화량이 임계값 이하이면 종료한다. 그렇지 않으면 2단계로 돌아가 반복한다.
이 알고리즘은 초기 클러스터 할당에 따라 결과가 달라질 수 있으므로, 여러 번 반복하거나 k-means++와 같은 초기 중심점 할당 방법을 사용하기도 한다. 또한, 최적의 클러스터 수 k를 결정하기 위한 별도의 고찰이 필요하다.
4. 1. 표준 알고리즘 (Naive k-means)
가장 일반적인 알고리즘은 반복적인 개선 기법을 사용한다. 널리 사용되기 때문에 종종 "k-평균 알고리즘"이라고 불리며, 특히 컴퓨터 과학계에서는 로이드 알고리즘이라고도 불린다. 더 빠른 대안이 존재하기 때문에 "단순 k-평균"이라고도 한다.[6]
k-평균 알고리즘의 실행 과정
초기 개의 평균 집합이 주어지면, 알고리즘은 다음 두 단계 사이를 번갈아 가며 진행된다:[7]
# '''할당 단계''': 각 관측치를 가장 가까운 평균을 가진 클러스터, 즉 제곱 유클리드 거리가 가장 작은 클러스터에 할당한다.[8] (수학적으로, 이것은 평균에 의해 생성된 보로노이 다이어그램에 따라 관측치를 분할하는 것을 의미한다.)
:
:여기서 각 는 두 개 이상에 할당될 수 있더라도 정확히 하나의 에 할당된다.
# '''업데이트 단계''': 각 클러스터에 할당된 관측치에 대한 평균(중심점)을 다시 계산한다.
:
k-평균 알고리즘의 목적 함수는 WCSS(클러스터 내 제곱합)이다. 각 반복 후에 WCSS가 감소하므로 음이 아닌 단조 감소 수열을 갖게 된다. 이는 k-평균이 항상 수렴함을 보장하지만, 반드시 전역 최적해로 수렴하는 것은 아니다.
할당이 더 이상 변경되지 않거나, WCSS가 안정될 때 알고리즘이 수렴된다. 알고리즘은 최적해를 찾도록 보장되지 않는다.[9]
알고리즘은 종종 객체를 거리에 따라 가장 가까운 클러스터에 할당하는 것으로 제시된다. (제곱) 유클리드 거리가 아닌 다른 거리 함수를 사용하면 알고리즘이 수렴하지 않을 수 있다. k-메도이드와 같은 k-평균의 다양한 수정 사항이 다른 거리 측정을 사용할 수 있도록 제안되었다.
표준 알고리즘의 실행 과정은 다음과 같다.
표준 알고리즘의 실행 과정
--
--
--
--
알고리즘을 요약하면 다음과 같다.
입력값
출력값
k 개의 클러스터
알고리즘
위 표에서 '''2'''는 할당 단계에 해당하고, '''3''' 과정은 업데이트 단계에 해당한다.[79]
K-평균 알고리즘은 일반적으로 다음과 같은 흐름으로 구현된다.[71][72] 데이터 수를 , 클러스터 수를 로 둔다.
# 각 데이터 에 대해 무작위(랜덤)로 클러스터를 할당한다.
# 할당된 데이터를 기반으로 각 클러스터의 중심 를 계산한다. 계산은 일반적으로 할당된 데이터의 각 요소의 산술 평균이 사용되지만, 필수적인 것은 아니다.
# 각 와 각 와의 거리를 구하고, 를 가장 가까운 중심의 클러스터에 다시 할당한다.
# 위의 처리에서 모든 의 클러스터 할당이 변하지 않은 경우, 또는 변화량이 사전에 설정한 일정 임계값을 밑도는 경우, 수렴했다고 판단하고 처리를 종료한다. 그렇지 않은 경우에는 새롭게 할당된 클러스터에서 를 다시 계산하고 위의 처리를 반복한다.
결과는 최초 클러스터의 무작위 할당에 크게 의존하는 것으로 알려져 있으며, 한 번의 결과로 최상의 결과를 얻을 수 있다고는 할 수 없다. 그렇기 때문에, 몇 번 반복하여 최상의 결과를 선택하는 기법이나, k-means++법처럼 최초 클러스터 중심점의 할당 방법을 고안하는 기법 등이 사용되는 경우가 있다.
이 알고리즘에서는 클러스터 수 k는 처음에 주어진 것으로 정하므로, 최적의 클러스터 수를 선택하기 위해서는 다른 계산 등을 통한 고찰이 필요하다.
4. 2. 초기화 기법
초기 중심점 설정은 K-평균 알고리즘의 성능과 결과에 큰 영향을 미친다. 다음은 일반적으로 사용되는 초기화 방법들이다.
무작위 분할 (Random Partition): 각 데이터를 임의의 클러스터에 할당하고, 각 클러스터에 할당된 점들의 평균 값을 초기 중심점으로 설정한다.[80] 데이터 순서에 독립적이며, 초기 클러스터가 각 데이터에 대해 고르게 분포되기 때문에 각 초기 클러스터의 무게중심이 데이터 집합의 중심에 가깝게 위치하는 경향이 있다.[82] k-조화 평균이나 퍼지 k-평균에서 선호된다.[82]
포지 (Forgy): 데이터 집합에서 임의의 k개의 데이터를 선택하여 초기 중심점으로 설정한다.[81] 무작위 분할과 마찬가지로 데이터 순서에 독립적이다.[80] 초기 클러스터가 임의의 k개의 점들에 의해 설정되기 때문에 각 클러스터의 무게중심이 중심으로부터 퍼져있는 경향이 있다.[82] EM 알고리즘이나 표준 k-평균 알고리즘에서 선호된다.[82]
맥퀸 (MacQueen): 포지 알고리즘과 마찬가지로 데이터 집합으로부터 임의의 k개의 데이터를 선택하여 초기 중심점으로 설정한다.[74] 이후 선택되지 않은 각 데이터에 대해 가장 가까운 클러스터를 찾아 데이터를 배당하고, 모든 데이터가 클러스터에 배당되면 각 클러스터의 무게중심을 다시 계산하여 초기 중심점으로 설정한다. 최종 수렴에 가까운 클러스터를 찾는 것은 비교적 빠르지만, 최종 수렴에 해당하는 클러스터를 찾는 것은 매우 느리다.[83]
카우프만 (Kaufman): 전체 데이터 집합 중 가장 중심에 위치한 데이터를 첫 번째 중심점으로 설정하고, 이후 선택되지 않은 각 데이터에 대해 가장 가까운 무게중심보다 선택되지 않은 데이터 집합에 더 근접하게 위치한 데이터를 순차적으로 k개의 중심점이 설정될 때까지 반복한다.[84] 무작위 분할과 마찬가지로 초기 클러스터링과 데이터 순서에 대해 비교적 독립적이기 때문에 해당 요소들에 의존적인 다른 알고리즘들보다 월등한 성능을 보인다.[80]
일반적으로 포지 방법과 무작위 분할 방법이 자주 사용된다.[10] 포지 방법은 초기 평균을 분산시키는 경향이 있는 반면, 무작위 분할은 데이터 집합의 중심에 가깝게 배치하는 경향이 있다. 여러 연구에 따르면 무작위 분할 방법은 k-조화 평균 및 퍼지 k-평균과 같은 알고리즘에 적합하고, 포지 방법은 기대값 최대화 및 표준 k-평균 알고리즘에 더 적합하다는 결과가 있다.[10] 하지만, 다른 연구에서는 포지, 무작위 분할, 최대 최소(Maximin)와 같은 일반적인 초기화 방법은 성능이 좋지 않은 반면, k-means++는 "일반적으로 잘" 수행되었다는 연구 결과도 존재한다.[11]
5. 복잡도
일반적인 유클리드 공간에서 k-평균 알고리즘의 최적 해를 찾는 것은 NP-난해 문제이다.[85][86]
Lloyd 알고리즘의 시간 복잡도는 클러스터의 수, 데이터 벡터의 차원, 데이터 벡터의 수에 각각 비례한다. 또한 알고리즘이 해가 수렴하기까지 반복되므로, 알고리즘이 반복된 횟수에도 비례한다. 즉, n개의 d-차원 데이터 벡터들을 i번의 반복을 통해 k개의 클러스터로 묶는데 걸리는 시간은 이다.
Smoothed analysis 경우의 복잡도는 다항 시간이다. 내의 임의의 n개의 점들의 집합에 대해, 집합 내의 각 점들이 평균 0, 분산의 정규분포를 이룬다면, 해당 집합을 k개의 클러스터로 묶는데 걸리는 시간이 임이 증명된 바 있다.[88]
다항을 넘는(superpolynomial) 시간()이 걸리는 경우도 존재한다.[89]
공간 복잡도의 경우, 알고리즘은 각 클러스터의 무게중심 벡터들에 대한 정보를 추가로 저장해야 하고, 이 무게중심 벡터들은 매 반복마다 독립적이기 때문에, k-평균 알고리즘은 의 공간 복잡도를 가진다.
6. 한계점
K-평균 알고리즘은 다음과 같은 몇 가지 한계점을 가지고 있다.
클러스터 개수(k) 설정 문제: 사용자가 사전에 클러스터 개수 k를 지정해야 하며, 적절한 k 값을 선택하기 어렵다. k값에 따라 결과가 완전히 달라지므로, 부적절한 k값은 좋지 않은 결과를 초래할 수 있다. 예를 들어, 실제 클러스터 수보다 k값이 작으면 하나의 클러스터가 여러 개의 클러스터로 분할될 수 있고, k값이 크면 하나의 클러스터가 여러 개로 쪼개질 수 있다.[51] 따라서, K-평균 알고리즘을 수행할 때는 데이터 집합에서 군집 수 결정을 위한 진단 검사를 실행하는 것이 중요하다.
지역 최솟값 수렴 문제: 알고리즘이 전역 최솟값(global optimum)이 아닌 지역 최솟값(local optimum)으로 수렴할 가능성이 있다. 초기 중심값에 따라 결과가 달라지며, 지역 최솟값에 수렴하면 사용자가 기대한 결과를 얻지 못할 수 있다. 이를 완화하기 위해 담금질 기법을 사용하거나, 서로 다른 초기값으로 여러 번 시도하여 가장 낮은 에러 값을 갖는 결과를 선택하는 방법 등이 사용된다.[51]
이상치(outlier) 민감성: 이상치에 민감하게 반응하여 클러스터 중심이 왜곡될 수 있다. 이상값은 다른 데이터와 멀리 떨어진 데이터를 의미하며, 중심점 갱신 과정에서 평균 값을 크게 왜곡시켜 중심점이 실제 클러스터의 중심에서 벗어나 이상치 방향으로 치우치게 만들 수 있다. 이를 방지하기 위해 K-평균 알고리즘을 실행하기 전에 이상값을 제거하거나, k-대푯값 알고리즘을 사용할 수 있다.
구형(spherical) 클러스터 가정: 유클리드 거리를 사용하여 중심점으로부터 구형으로 군집화가 이루어지기 때문에, 구형이 아닌 클러스터를 찾는 데에는 적절하지 않다. 주어진 데이터 집합의 분포가 구형이 아닐 경우, 클러스터링 결과가 예상과 다를 수 있다. 이러한 경우에는 DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 알고리즘이나 mean-shift 클러스터링 알고리즘을 사용하면 원하는 결과를 얻을 수 있다.
데이터 순서 민감성: 무작위 분할, Forgy, MacQueen 초기화 기법의 경우 데이터의 순서에 따라 결과가 달라질 수 있다.[71][72]
650x650px
붓꽃 데이터 집합과 실제 종에 대한 ''k''-평균 군집화 결과
인공 데이터 집합("mouse")에 대한 ''k''-평균 군집화 대 EM 군집화.
7. 클러스터 수 결정
k-평균 클러스터링에서 최적의 클러스터 수(''k'')를 결정하는 방법은 다음과 같다.
Rule of thumb: 데이터의 수가 ''n''일 때, 필요한 클러스터의 수는 와 같이 계산할 수 있다.[90]
엘보 방법 (클러스터링): 클러스터 수를 순차적으로 늘려가면서 결과를 확인한다. 클러스터를 추가했을 때 이전보다 훨씬 더 나은 결과를 나타내지 않는다면, 이전의 클러스터 수를 사용한다.
정보 기준 접근법: 클러스터링 모델에 대해 가능도를 계산하여 베이지안 정보 기준 등을 사용한다. k-평균 클러스터링 모델의 경우 가우시안 혼합 모델에 가깝기 때문에, 가우시안 혼합 모델에 대한 가능도를 만들어 정보 기준 값을 설정할 수 있다.[91]
실루엣 (클러스터링): 실루엣 분석은 클러스터링의 품질을 측정하고 결과 클러스터 간의 분리 거리를 나타낸다.[29] 높은 실루엣 점수는 객체가 자체 클러스터에 잘 일치하고 인접 클러스터에 잘 일치하지 않음을 의미한다.
갭 통계량: 갭 통계량은 데이터의 널 참조 분포에서 예상 값과 다른 k 값에 대한 총 클러스터 내 변동을 비교한다.[30] 최적의 k는 가장 큰 갭 통계량을 생성하는 값이다.
데이비스-볼딘 지수: 데이비스-볼딘 지수는 클러스터 간의 분리 정도를 측정하는 것이다.[31] 이 지수가 낮을수록 분리가 더 잘 된 모델을 나타낸다.
칼린스키-하라바스 지수: 이 지수는 조밀함과 분리를 기반으로 클러스터를 평가한다. 클러스터 간 분산과 클러스터 내 분산의 비율을 사용하여 계산되며, 값이 높을수록 클러스터가 더 잘 정의된다.[32]
랜드 지수: 두 클러스터 간의 일치 비율을 계산하여 동일하거나 다른 클러스터에 올바르게 할당된 요소 쌍을 모두 고려한다.[33] 값이 높을수록 유사성이 크고 클러스터링 품질이 향상된다. 조정된 랜드 지수(ARI)는 우연으로 인한 모든 페어링의 예상 유사성을 조정하여 랜드 지수를 수정한다.[34]
8. 클러스터링 평가 척도
클러스터링이 얼마나 잘 되었는가를 측정하는 방법으로 내부 평가 혹은 외부 평가, 크게 2가지 방법론을 이용할 수 있다.
8. 1. 내부 평가
데이터 집합을 클러스터링한 결과 그 자체를 놓고 평가하는 방식이다. 이러한 방식에서는 클러스터 내 높은 유사도(high intra-cluster similarity)를 가지고, 클러스터 간 낮은 유사도(low inter-cluster similarity)를 가진 결과물에 높은 점수를 준다.[92] 이와 같은 평가 방법은 오로지 데이터를 클러스터링한 결과물만을 보고 판단하기 때문에, 평가 점수가 높다고 해서 실제 참값(ground truth)에 가깝다는 것을 반드시 보장하지는 않는다는 단점이 있다.[92]
Davies-Bouldin index는 다음의 식으로 계산된다.
:
n은 클러스터의 개수, 는 클러스터 의 중심점, 는 클러스터 내의 모든 데이터 오브젝트로부터 중심점 까지 거리의 평균값이며 는 중심점 와 중심점 간의 거리이다. 높은 클러스터 내 유사도를 가지고 낮은 클러스터간 유사도를 가지는 클러스터들을 생성하는 클러스터링 알고리즘은 낮은 Davies-Bouldin index 값을 가지게 된다. 따라서, 이 지표가 낮은 클러스터링 알고리즘이 좋은 클러스터링 알고리즘으로 평가된다.
Dunn index는 밀도가 높고 잘 나뉜 클러스터링 결과를 목표로 한다. 이 지표는 클러스터간 최소 거리와 클러스터간 최대 거리의 비율로 정의된다. 각 클러스터에 대하여, Dunn index를 다음의 식으로 계산할 수 있다.[93]
:
''d''(''i'',''j'')는 클러스터 ''i''와 클러스터 ''j''간의 거리이고 ''d'' '(''k'')는 클러스터 ''k''의 클러스터 내 거리(dissimilarity)를 측정한 값이다. 클러스터 간 거리 ''d''(''i'',''j'')는 두 클러스터의 중심점 끼리의 거리, 혹은 두 클러스터의 각 데이터 오브젝트끼리의 거리의 평균 등 어떤 방식으로든 계산될 수 있다. 마찬가지로, 클러스터 내 거리 ''d'' '(''k'') 역시 클러스터 내 가장 멀리 떨어진 데이터 오브젝트 간 거리 등으로 구할 수 있다. 내부 평가 방식은 높은 클러스터 내 유사도와 낮은 클러스터간 유사도에 높은 점수를 주기 때문에, Dunn index값이 높은 클러스터링 알고리즘은 클러스터링 성능이 좋은 것으로 판단할 수 있다.
1986년 Peter J. Rousseeuw에 의해 처음으로 서술된 https://en.wikipedia.org/wiki/Silhouette_(clustering) 실루엣은 간단한 방법으로 데이터들이 얼마나 잘 클러스터링 되었는지를 나타낸다.[94] 하나의 데이터 ''i''에 대해, 해당 데이터가 속한 클러스터 내부의 데이터들과의 부동성을 라 하고, 해당 데이터가 속하지 않은 클러스터들의 내부의 데이터들과의 부동성을 라 할 때, 실루엣 은 다음과 같이 계산될 수 있다.
:
이때 계산된 는 다음의 값을 가진다.
:
가 1에 가까울 수록 데이터 ''i''는 올바른 클러스터에 분류된 것이며, -1에 가까울 수록 잘못된 클러스터에 분류되었음을 나타낸다.
8. 2. 외부 평가
클러스터링 결과가 미리 정해진 결과(정답)와 얼마나 비슷한지 측정한다. 클러스터링 결과물은 클러스터링에 사용되지 않은 데이터로 평가된다. 다시 말해, 클러스터링 결과물을 전문가들이 미리 정해놓은 모범 답안 혹은 외부 벤치마크 평가 기준 등을 이용해서 클러스터링 알고리즘의 정확도를 평가하는 것이다.[95]
랜드 측정(Rand measure)은 클러스터링 알고리즘에 의해 형성된 클러스터링 결과물이 미리 정해진 모범 답안과 얼마나 비슷한지를 계산한다.[95] 이 척도는 클러스터링 알고리즘이 얼마나 답을 잘 맞추었는지를 퍼센티지로 표현해준다. 랜드 측정 식은 아래와 같다.
:
는 참인 것을 참이라고 답한 것의 개수
은 거짓인 것을 거짓이라고 답한 것의 개수
는 거짓인 것을 참으로 판정한 것의 개수
는 참인 것을 거짓으로 판정한 것의 개수
이 방식의 문제점은 와 을 같은 비중으로 계산한다는 것이다. 이와 같은 방식으로는 일부 클러스터링 알고리즘을 평가할 때 좋지 않을 수 있다.
F 측정(F-measure)은 값을 바꾸면서 재현율을 조정함으로써 FN값의 비중을 변화시킨다. 정밀도와 재현율은 아래와 같이 정의된다.
:
:
F-measure 값은 아래의 식으로 구할 수 있다.[92]
:
일 때, 이다. 다시 말해, 재현율은 일 때 어떠한 영향을 미치지 못한다. 값을 키울수록 최종 F-measure에 재현율이 미치는 영향은 커진다.
자카드 지수(Jaccard index)는 두 데이터 집합 간의 유사도를 정량화하는 데 사용되며, 0과 1 사이의 값을 가진다. 이 값이 1이라는 것은 두 데이터 집합이 서로 동일하다는 것을 의미하며, 반대로 0일 때는 두 데이터 집합은 공통된 요소를 전혀 가지지 않는다는 것을 뜻한다. 자카드 지수는 아래의 식으로 정의된다.