추출, 변환, 적재
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
추출, 변환, 적재(ETL)는 다양한 소스 시스템에서 데이터를 추출(Extract)하여, 최종 타겟 시스템에 적합한 형태로 변환(Transform)하고, 변환된 데이터를 타겟 시스템에 적재(Load)하는 데이터 통합 프로세스이다. ETL은 데이터 웨어하우스 구축, 데이터 마이그레이션, 애플리케이션 통합 등에 활용되며, 데이터 유효성 검사, 데이터 변환, 데이터 로드 시의 성능 최적화, 그리고 실패 복구 등의 설계 과제를 가진다. ETL은 온라인 트랜잭션 처리(OLTP) 환경, 가상 ETL, 추출-적재-변환(ELT)과 변환-추출-적재(TEL) 등 다양한 형태로 변형되어 사용될 수 있으며, Talend, Informatica PowerCenter, IBM DataStage 등 다양한 상용 및 오픈 소스 도구를 통해 구현된다.
ETL 프로세스는 일반적으로 데이터를 한 시스템에서 다른 시스템으로 이동시키는 세 가지 주요 단계로 구성된다. 각 단계는 뚜렷한 목적을 가지며 순차적으로 진행된다.
2. 단계
이 세 단계를 통해 원본 데이터를 분석이나 보고 등에 활용하기 용이한 형태로 가공하여 저장하게 된다. 실제 ETL 과정에서는 데이터 유효성 검사, 감사 등 더 세부적인 작업들이 각 단계에 포함될 수 있다.
2. 1. 추출 (Extract)
ETL(추출, 변환, 적재) 과정의 첫 번째 단계는 원본 시스템(source systems)에서 데이터를 가져오는 추출(Extract)이다. 많은 경우 여러 다른 종류의 원본 시스템에서 데이터를 결합해야 하며, 각 시스템은 서로 다른 데이터 구조나 파일 형식을 가질 수 있다. 데이터 추출은 이후 진행될 변환 및 적재 과정의 성공을 위한 기초를 마련하기 때문에 ETL 프로세스에서 매우 중요한 부분으로 간주된다.
일반적인 데이터 원본의 형식은 다음과 같다.
| 형식 종류 | 예시 |
|---|---|
| 관계형 데이터베이스 | 일반적인 SQL 기반 데이터베이스 |
| 플랫 파일 | CSV, TSV 등 |
| 마크업 언어 | XML, JSON |
| 비관계형 데이터베이스 | IMS 등 |
| 기타 데이터 구조 | VSAM, ISAM 등 |
| 외부 소스 | 웹 크롤러, 데이터 스크래핑 등 |
추출 과정의 핵심적인 부분 중 하나는 데이터 유효성 검사이다. 이는 원본에서 가져온 데이터가 미리 정의된 규칙이나 형식(예: 특정 패턴, 값 목록, 기본값 등)에 맞는지 확인하는 작업이다. 데이터가 유효성 검사 규칙을 통과하지 못하면, 해당 데이터는 전체 또는 일부가 거부될 수 있다. 이렇게 거부된 데이터는 보통 원본 시스템으로 다시 보고되어 잘못된 부분을 수정하거나, 데이터 랭글링 과정을 통해 정제되기도 한다.
경우에 따라서는 추출된 데이터를 중간 저장 공간 없이 스트리밍 방식으로 즉시 대상 데이터베이스에 적재하는 방식도 사용될 수 있다. 추출 시점에는 이후 변환 및 적재 단계에 적합하도록 데이터 형식을 미리 변환하기도 한다.
2. 2. 변환 (Transform)
데이터 변환 단계는 추출된 데이터를 최종 목적지 시스템(예: 데이터 웨어하우스)에 적재하기 전에, 정해진 규칙이나 함수를 적용하여 데이터의 형식을 바꾸는 과정이다. 이 단계의 핵심 목표 중 하나는 데이터 정제를 통해 유효하고 일관성 있는 데이터만 다음 단계로 전달하는 것이다. 서로 다른 시스템 간의 데이터를 통합할 때는 각 시스템이 사용하는 문자 집합이나 데이터 형식이 달라 문제가 발생할 수 있는데, 변환 과정에서 이러한 차이를 해결한다.데이터의 특성이나 최종 시스템의 요구사항에 따라 다양한 변환 작업이 수행될 수 있다. 주요 변환 유형은 다음과 같다.
- 열 선택: 필요한 데이터 열만 선택하거나, 반대로 불필요하거나 값이 없는(Null) 열을 제외한다. 예를 들어, 원본 데이터에 학번, 나이, 급여 열이 있을 때 학번과 급여 열만 선택하거나 급여 정보가 없는 데이터는 제외할 수 있다.
- 코드 값 변환: 시스템마다 다르게 사용하는 코드 값을 통일한다. 예를 들어, 어떤 시스템에서는 성별을 "1"(남), "2"(여)로 표시하지만, 최종 시스템에서는 "M"(남), "F"(여)로 표시해야 할 경우 이를 변환한다. 이는 자동 데이터 클렌징의 한 형태이다.
- 자유 형식 값 인코딩: '남성', 'Male'과 같은 문자열 데이터를 'M'이나 '1'과 같은 표준화된 코드로 변환한다.
- 새로운 값 계산: 기존 데이터 필드를 이용하여 새로운 값을 계산한다. 예를 들어, '판매 수량'과 '단가' 필드를 곱하여 '매출액' 필드를 생성할 수 있다.
- 데이터 정렬: 특정 열을 기준으로 데이터의 순서를 정렬하여 데이터 조회 성능을 향상시킨다.
- 데이터 통합 및 중복 제거: 여러 출처에서 가져온 데이터를 하나로 합치거나(조인, 병합), 동일한 데이터가 중복되어 나타나는 경우 이를 식별하고 제거한다.
- 데이터 집계: 여러 데이터 행을 요약하여 의미 있는 통계 정보를 생성한다. 예를 들어, 각 매장별, 지역별 총 판매액을 계산하는 경우가 해당한다.
- 대체 키 생성: 원본 데이터의 기본 키 대신 사용할 수 있는 고유한 식별자를 새롭게 생성한다. 이는 데이터 웨어하우스 환경에서 자주 사용된다.
- 전치 또는 피벗: 데이터의 행과 열을 서로 바꾸거나, 여러 열에 걸쳐 있는 데이터를 행 형태로 변환하는 등 데이터 구조를 변경한다.
- 열 분할: 하나의 열 안에 여러 정보가 함께 들어있는 경우(예: 쉼표로 구분된 값으로 지정된 목록), 이를 각각의 의미있는 열로 분리한다.
- 데이터 유효성 검사: 데이터가 정해진 규칙(예: 값의 범위, 데이터 형식)을 만족하는지 검사한다. 유효성 검사에 실패한 데이터는 규칙에 따라 전체 또는 일부를 제외하거나, 수정하여 다음 단계로 전달할 수 있다. 변환 과정에서 예상치 못한 데이터(예: 정의되지 않은 코드 값)가 발견될 경우 예외 처리가 필요하다.
특히 한국에서는 개인정보 보호법의 준수가 매우 중요하므로, 이름, 주소, 전화번호 등 개인을 식별할 수 있는 정보를 비식별화 처리(예: '*' 등으로 마스킹)하는 과정이 필수적으로 요구된다. 이는 데이터의 유용한 활용과 개인의 프라이버시 보호라는 두 가치 사이의 균형을 맞추려는 사회적 요구를 반영하는 중요한 절차이다.
2. 3. 적재 (Load)
적재 단계는 변환된 데이터를 최종 목적지에 저장하는 과정이다. 이 목적지는 간단한 파일 형태일 수도 있고, 데이터 웨어하우스와 같은 복잡한 데이터 저장소일 수도 있다. 데이터를 적재하는 방식은 조직의 필요에 따라 다양하다.어떤 데이터 웨어하우스는 주기적으로(예: 매일, 매주, 매월) 새로운 데이터가 들어올 때 기존 정보를 덮어쓰는 방식을 사용한다. 반면, 다른 데이터 웨어하우스는 정해진 간격(예: 매시간)으로 새로운 데이터를 기록 형태로 계속 추가하는 방식을 사용하기도 한다. 예를 들어, 지난 1년간의 판매 기록을 유지해야 하는 경우, 1년이 지난 데이터는 새로운 데이터로 덮어쓰고, 1년 이내의 데이터는 계속 추가하는 방식으로 운영될 수 있다. 데이터를 덮어쓸지, 추가할지, 그리고 언제 얼마나 자주 할지는 조직의 비즈니스 요구 사항과 가용 시간에 따라 결정되는 전략적인 선택이다. 더 복잡한 시스템에서는 데이터 변경 이력을 추적하고 감사 추적 기록을 남기기도 한다.
데이터를 적재하는 과정은 데이터베이스와 직접 상호작용하기 때문에, 데이터베이스 스키마에 정의된 여러 제약 조건(예: 데이터의 고유성, 참조 무결성, 필수 입력 필드 등)이 적용된다. 또한, 데이터 로드 시 자동으로 실행되는 트리거(Triggers) 역시 데이터 품질을 유지하는 데 중요한 역할을 한다. 이러한 제약 조건과 트리거는 ETL 과정 전체의 데이터 품질을 높이는 데 기여한다.
ETL 과정의 적재 단계는 다양한 상황에서 활용될 수 있다.
- 데이터 통합: 금융 기관처럼 여러 부서에서 동일 고객 정보를 다른 방식으로 관리할 때(예: 이름 기준, 고객 번호 기준), ETL을 통해 이를 하나의 통일된 형식으로 통합하여 데이터 웨어하우스 등에 저장할 수 있다.
- 데이터 이전: 기업이 새로운 애플리케이션을 도입하면서 기존 데이터를 새 시스템으로 옮겨야 할 때 ETL이 사용될 수 있다. 특히 새 애플리케이션이 다른 종류의 데이터베이스를 사용하거나 데이터베이스 스키마 구조가 다를 경우, ETL을 통해 데이터를 새 환경에 맞는 형식으로 변환하여 이전할 수 있다.
- 데이터 활용: 회계사, 컨설턴트, 로펌 등에서 사용하는 비용 및 비용 회수 시스템의 데이터를 예로 들 수 있다. 일반적으로 데이터는 로펌 관리 소프트웨어와 같은 시간 및 청구 시스템에 저장되지만, ETL을 통해 이 원시 데이터를 가공하여 인사 부서의 직원 생산성 보고서나 시설 관리 부서의 장비 사용 보고서 등 다른 목적으로 활용할 수 있다.
2. 4. 추가 단계 (Phases)
실제 ETL 주기에는 다음과 같은 추가 실행 단계가 포함될 수 있다.# 주기 시작
# 참조 데이터 구축
# 추출 (소스에서)
# 유효성 검사
# 변환 (정제, 비즈니스 규칙 적용, 데이터 무결성 검사, 집계 또는 분해 생성)
# 스테이징 (사용되는 경우 스테이징 테이블에 로드)
# 감사 보고서 (예: 비즈니스 규칙 준수 여부. 또한 실패 시 진단/수리에 도움)
# 게시 (대상 테이블에)
# 보관
3. 설계 과제
ETL 프로세스는 상당히 복잡하며, 잘못 설계하면 운영상 큰 문제가 생길 수 있다. 설계 단계에서 예상하지 못한 데이터 값의 범위나 품질 문제가 운영 중에 발견될 수 있으므로, 분석 과정에서 원본 데이터의 데이터 프로파일링을 통해 실제 데이터 상황을 파악하고 이를 변환 규칙 설계에 반영하는 것이 중요하다.
데이터 웨어하우스(DW)는 보통 여러 다른 종류의 정보원에서 데이터를 비동기적으로 가져온다. ETL은 이렇게 서로 다르고 시간도 맞지 않는 정보원에서 데이터를 추출하여 일관된 환경으로 만드는 핵심 과정이다.
또한, ETL 시스템의 확장성 역시 중요한 설계 고려 사항이다. 서비스 수준 협약(SLA) 범위 내에서 처리해야 할 데이터 양을 미리 파악하고, 향후 데이터 양 증가에 대비해야 한다. 데이터 처리량이 늘어나면 기존의 배치 처리 방식에서 더 짧은 주기의 "마이크로 배치"나 메시지 큐 통합, 또는 실시간 데이터 변경 파악 방식으로 전환해야 할 수도 있다.
3. 1. 데이터 변동성 (Data variations)
운영 시스템의 데이터 값 범위나 데이터 품질은 유효성 검사 및 변환 규칙을 처음 설계할 때 예상했던 것과 다를 수 있다. 즉, 실제 운영 환경에서는 예상치 못한 범위의 값이 들어오거나 데이터의 질이 기대했던 수준과 차이가 날 수 있다.이러한 문제를 해결하기 위해, 데이터 분석 과정에서 원본 데이터에 대한 데이터 프로파일링을 수행하는 것이 중요하다. 데이터 프로파일링을 통해 실제 데이터의 상태와 조건을 정확히 파악할 수 있으며, 이 결과를 바탕으로 ETL 프로세스에 포함된 유효성 검사 규칙이나 변환 규칙을 적절하게 수정해야 한다. 이는 데이터 처리의 정확성과 신뢰성을 높이는 데 도움이 된다.
3. 2. 확장성 (Scalability)
설계 분석 단계에서는 서비스 수준 협약 내에서 처리해야 하는 데이터 볼륨을 파악하여 ETL 시스템의 확장성을 시스템 수명 주기 동안 확보해야 한다.[5] 소스 시스템에서 데이터를 추출할 수 있는 시간은 변동될 수 있으며, 이는 때때로 더 짧은 시간 안에 동일한 양의 데이터를 처리해야 함을 의미할 수 있다.[5] 일부 ETL 시스템은 수십 테라바이트의 데이터를 가진 데이터 웨어하우스를 업데이트하기 위해 테라바이트 규모의 데이터를 처리할 수 있도록 확장되어야 한다.[5] 데이터 볼륨이 증가함에 따라, 일일 배치 처리 방식에서 하루에 여러 번 처리하는 마이크로 배치 방식, 메시지 큐와의 통합, 또는 지속적인 변환 및 업데이트를 위한 실시간 변경 데이터 캡처 방식으로 시스템 설계를 확장해야 할 수도 있다.[5]3. 3. 고유 키 (Uniqueness of keys)
고유 키는 모든 관계형 데이터베이스에서 중요한 역할을 수행하며, 데이터를 연결하는 핵심 요소이다. 고유 키는 특정 개체를 고유하게 식별하는 하나 이상의 열(column)을 의미한다. 반면, 외래 키는 다른 테이블의 기본 키를 참조하는 열이다. 키가 여러 열로 구성될 경우 이를 복합 키라고 부른다. 많은 경우, 기본 키는 표현되는 비즈니스 엔티티와 직접적인 의미가 없는 자동 생성된 정수 값인데, 이를 대리 키(Surrogate Key)라고 하며, 이는 관계형 데이터베이스의 구조적 목적을 위해 주로 사용된다.데이터 웨어하우스 환경에서는 여러 소스 시스템으로부터 데이터를 가져와 통합하는 경우가 많기 때문에, 키 관리는 매우 중요한 문제가 된다. 예를 들어, 동일한 고객 정보가 여러 시스템에 존재할 수 있는데, 한 시스템에서는 사회보장번호를 기본 키로 사용하고, 다른 시스템에서는 전화번호를, 또 다른 시스템에서는 자체적인 대리 키를 사용할 수 있다. 데이터 웨어하우스는 이러한 다양한 소스의 고객 정보를 하나의 차원(Dimension) 테이블로 통합해야 할 수 있다.
이러한 문제를 해결하기 위한 일반적인 방법은 데이터 웨어하우스 고유의 대리 키를 생성하여 사용하는 것이다. 이 웨어하우스 대리 키는 팩트 테이블(Fact Table)에서 외래 키로 사용되어 각 차원 테이블의 행을 참조한다.[6]
소스 시스템의 데이터는 시간이 지남에 따라 변경될 수 있으며, 이러한 변경 사항은 데이터 웨어하우스에도 반영되어야 한다. 보고 등의 목적으로 원본 소스 시스템의 기본 키 값이 필요한 경우, 해당 정보는 차원 테이블의 속성으로 포함될 수 있다. 만약 원본 소스 시스템이 자체적인 대리 키를 사용하고 있다면, 데이터 웨어하우스는 이 원본 대리 키 값도 추적해야 할 필요가 있다. 이는 웨어하우스 대리 키와 원본 소스 시스템의 키(기본 키 또는 대리 키)를 매핑하는 조회 테이블(Lookup Table)을 생성하여 관리할 수 있다.[7] 조회 테이블을 사용하면 다양한 소스 시스템의 키 체계가 웨어하우스 차원 테이블을 직접적으로 오염시키는 것을 방지하면서도, 원본 데이터의 변경 사항을 추적하고 반영하는 기능을 유지할 수 있다.
조회 테이블은 원본 소스 데이터의 변경 사항을 처리하는 방식에 따라 다양하게 활용될 수 있다. 주요 처리 유형은 다음과 같다.[7]
| 유형 | 설명 |
|---|---|
| 유형 1 (Type 1) | 차원 테이블의 해당 행을 원본 소스 시스템의 최신 상태로 덮어쓴다. 과거 데이터는 보존되지 않는다. 조회 테이블은 업데이트할 차원 행을 식별하는 데 사용된다. |
| 유형 2 (Type 2) | 원본 소스 시스템의 데이터 변경 시, 새로운 상태를 반영하는 새 행을 차원 테이블에 추가한다. 이때 새로운 웨어하우스 대리 키가 할당된다. 이 방식은 변경 이력을 추적할 수 있게 해주며, 조회 테이블에서 원본 소스 키는 더 이상 고유하지 않게 될 수 있다 (하나의 원본 키에 여러 버전의 차원 행이 매핑될 수 있음). |
| 완전 로깅 (Fully Logged) | 유형 2와 유사하게 새로운 상태를 반영하는 새 행을 추가하는 동시에, 변경 전의 이전 행에 대해서는 유효 종료 시간을 기록하여 더 이상 활성 상태가 아님을 표시한다. 모든 변경 이력을 상세하게 기록하는 방식이다. |
3. 4. 성능 (Performance)
ETL 벤더들은 여러 개의 CPU, 여러 개의 하드 드라이브, 여러 개의 기가비트 네트워크 연결 및 많은 메모리를 갖춘 강력한 서버를 사용하여 시간당 여러 테라바이트(TB) (또는 초당 ~1GB)의 기록 시스템을 벤치마킹한다.실제 상황에서 ETL 프로세스의 가장 느린 부분은 일반적으로 데이터베이스 로드 단계에서 발생한다. 데이터베이스는 동시성, 무결성 유지 및 인덱스를 처리해야 하므로 느리게 작동할 수 있다. 따라서 더 나은 성능을 위해 다음을 사용하는 것이 좋다.
- 가능한 경우 ''직접 경로 추출'' 방식 또는 대량 언로드 (데이터베이스를 쿼리하는 대신)를 사용하여 소스 시스템의 부하를 줄이는 동시에 고속 추출을 수행한다.
- 대부분의 변환 처리를 데이터베이스 외부에서 수행한다.
- 가능한 경우 대량 로드 작업을 사용한다.
그럼에도 불구하고 대량 작업을 사용하더라도 데이터베이스 접근은 일반적으로 ETL 프로세스의 병목 현상이다. 성능을 향상시키는 데 사용되는 몇 가지 일반적인 방법은 다음과 같다.
| 기법 | 설명 | 비고 |
|---|---|---|
| 파티션 테이블 (및 인덱스) | 파티션 크기를 비슷하게 유지한다. | null 값이 파티션을 왜곡할 수 있으므로 주의한다. |
| 로드 전 유효성 검사 | ETL 계층에서 모든 유효성 검사를 수행한다. | 로드 중 대상 데이터베이스 테이블에서 무결성 검사 (disable constraint ...)를 비활성화한다. |
| 로드 중 트리거 비활성화 | 로드 중 대상 데이터베이스 테이블에서 트리거 (disable trigger ...)를 비활성화한다. | 별도의 단계로 해당 효과를 시뮬레이션한다. |
| ID 생성 | ETL 계층에서 ID를 생성한다. | 데이터베이스에서 생성하지 않는다. |
| 인덱스 관리 | 로드 전에 인덱스 (테이블 또는 파티션에)를 삭제하고, 로드 후 다시 생성한다. | SQL: drop index ...; create index ... |
| 병렬 대량 로드 | 가능한 경우 병렬 대량 로드를 사용한다. | 테이블이 파티션되거나 인덱스가 없는 경우 잘 작동한다. (참고: 동일한 테이블 (파티션)에 병렬 로드를 시도하면 일반적으로 잠금이 발생한다. 데이터 행이 아니더라도 인덱스에 잠금이 발생한다). |
| 작업 분리 | 삽입, 업데이트 또는 삭제를 수행해야 하는 요구 사항이 있는 경우, ETL 계층에서 어떤 행을 어떤 방식으로 처리해야 하는지 파악한 다음 데이터베이스에서 이 세 가지 작업을 개별적으로 처리한다. | 삽입의 경우 대량 로드를 수행할 수 있지만 업데이트 및 삭제는 일반적으로 API (SQL 사용)를 거친다. |
특정 작업을 데이터베이스 내에서 수행할지 외부에서 수행할지는 상충 관계가 있을 수 있다. 예를 들어, distinct를 사용하여 중복을 제거하는 것은 데이터베이스에서 느릴 수 있으므로 외부에서 수행하는 것이 좋다. 반면에, distinct를 사용하면 추출할 행 수가 크게 (x100) 감소하는 경우 데이터를 언로드하기 전에 데이터베이스에서 가능한 한 빨리 중복을 제거하는 것이 좋다.
ETL에서 일반적인 문제의 원인은 ETL 작업 간의 많은 종속성이다. 예를 들어, 작업 "B"는 작업 "A"가 완료될 때까지 시작할 수 없다. 일반적으로 모든 프로세스를 그래프로 시각화하고 그래프를 줄여 병렬 처리를 최대한 활용하고 연속적인 처리를 "체인"으로 가능한 짧게 만들어 더 나은 성능을 얻을 수 있다. 다시 말하지만, 대형 테이블과 해당 인덱스의 파티션은 실제로 도움이 될 수 있다.
또 다른 일반적인 문제는 데이터가 여러 데이터베이스에 분산되어 있고 해당 데이터베이스에서 순차적으로 처리될 때 발생한다. 때로는 데이터베이스 복제가 데이터베이스 간에 데이터를 복사하는 방법으로 사용될 수 있으며, 이는 전체 프로세스의 속도를 상당히 늦출 수 있다. 일반적인 해결책은 처리 그래프를 세 개의 계층으로 줄이는 것이다.
- 소스
- 중앙 ETL 계층
- 대상
이 방식을 사용하면 처리가 병렬 처리를 최대한 활용할 수 있다. 예를 들어, 두 개의 데이터베이스에 데이터를 로드해야 하는 경우 (첫 번째 데이터베이스에 로드한 다음 두 번째 데이터베이스로 복제하는 대신) 병렬로 로드를 실행할 수 있다.
경우에 따라 처리가 순차적으로 이루어져야 한다. 예를 들어, 차원 (참조) 데이터는 주요 "팩트" 테이블에 대한 행을 가져와 유효성을 검사하기 전에 필요하다.
ETL 시스템의 확장성은 분석 시점에서 고려해야 한다. 여기에는 서비스 수준 계약(SLA)의 범위 내에서 처리해야 할 데이터의 양을 파악하는 것도 포함된다. 정보원에서 데이터 추출에 소요되는 시간은 운영하면서 변화할 수 있으며, 시간이 짧아질 가능성도 있다. ETL 시스템에 따라서는, 수십 테라바이트의 데이터 웨어하우스 업데이트를 위해 테라바이트 수준의 데이터를 처리해야 하는 경우도 있다. 처리해야 할 데이터량이 증가하면, 일일 배치 처리로는 따라잡을 수 없게 되어, 하루에 여러 번 배치 처리하는 "마이크로 배치"로 전환하거나, 더 나아가 메시지 큐와 통합하거나, 실시간 데이터 변경 파악이 필요하게 될 가능성도 있다.
3. 5. 병렬 처리 (Parallel computing)
ETL 과정에서는 대량의 데이터를 다루므로 처리 속도, 즉 성능이 매우 중요하다. 특히 데이터베이스에 데이터를 최종적으로 저장하는 적재 단계에서 작업 속도가 느려지는 병목 현상이 자주 발생한다. 이는 데이터베이스가 데이터의 무결성을 유지하고, 여러 사용자의 동시 접근을 관리하며, 인덱스를 처리하는 등 복잡한 작업을 수행해야 하기 때문이다.이러한 성능 문제를 해결하고 전체 ETL 작업 시간을 단축하는 핵심 방법 중 하나가 병렬 처리이다. ETL 작업들은 종종 서로 의존 관계를 가지는데(예: 작업 A가 끝나야 작업 B를 시작할 수 있음), 이 때문에 작업들이 순서대로 진행되어 전체 시간이 길어지는 경우가 많다. 또한, 데이터가 여러 곳에 나뉘어 저장되어 있을 때 이를 순차적으로 가져와 처리하면 비효율적일 수 있다.
병렬 처리는 이러한 문제 해결에 도움을 준다. 전체 ETL 작업을 하나의 흐름도(그래프)로 보고, 동시에 처리할 수 있는 부분들을 찾아 여러 작업을 병렬로 실행함으로써 전체 처리 시간을 줄이는 것이다. 데이터가 여러 데이터베이스에 분산된 경우에도, 각 데이터베이스에서 동시에 데이터를 처리하거나 가져오는 방식으로 병렬 처리를 적용하여 효율을 높일 수 있다. 예를 들어, 여러 데이터베이스에 데이터를 적재해야 할 때, 하나씩 순서대로 하는 대신 동시에 병렬로 진행하면 시간을 크게 단축할 수 있다.
최근 개발되는 많은 ETL 도구들은 이러한 병렬 처리 기능을 적극적으로 도입하여 대용량 데이터 처리 성능을 크게 향상시키고 있다. ETL 환경에서 주로 사용되는 병렬 처리 방식은 다음과 같은 세 가지 유형으로 나눌 수 있다.
- 데이터 병렬성: 처리해야 할 큰 데이터 덩어리(예: 하나의 큰 파일)를 여러 개의 작은 조각으로 나누어, 여러 처리 장치(프로세스)가 각 조각을 동시에 처리하는 방식이다.
- 파이프라인 병렬성: 하나의 데이터 처리 흐름을 여러 단계로 나누고, 각 단계를 다른 처리 장치가 맡아 컨베이어 벨트처럼 동시에 진행하는 방식이다. 예를 들어, 데이터 A가 1단계를 처리하는 동안 데이터 B는 2단계를 처리하는 식이다.
- 컴포넌트 병렬성: 서로 다른 종류의 작업이나 서로 다른 데이터 스트림을 여러 처리 장치가 동시에 독립적으로 수행하는 방식이다. 예를 들어, 한쪽에서는 데이터를 정렬하는 작업을 하고, 다른 쪽에서는 중복된 데이터를 제거하는 작업을 동시에 진행할 수 있다.
실제 ETL 작업에서는 이 세 가지 병렬 처리 방식이 각각 독립적으로 사용되기보다는, 서로 조합되어 전체 작업의 성능을 최대한 끌어올리는 데 활용된다.
3. 6. 실패 복구 (Failure recovery)
데이터 웨어하우징 절차는 일반적으로 대규모 ETL 프로세스를 순차적으로 또는 병렬로 실행되는 더 작은 단위로 세분화한다. 데이터 흐름을 추적하기 위해 각 데이터 행에 "row_id"를 태그하고, 프로세스의 각 단위에는 "run_id"를 태그하는 것이 좋다. 프로세스 실행 중 실패가 발생하면, 이러한 ID를 사용하여 실패한 단위를 롤백하고 다시 실행하는 데 도움이 된다.또한, 프로세스의 특정 단계가 완료되었을 때의 상태인 체크포인트(Checkpoint)를 설정하는 것이 권장된다. 체크포인트에 도달하면 모든 것을 디스크에 쓰고, 임시 파일을 정리하며, 상태를 기록하는 것이 좋다. 이는 실패 시 복구를 용이하게 한다.
4. 구현 (Implementations)
ETL 시스템은 거의 모든 프로그래밍 언어로 직접 만들 수 있지만, 처음부터 모든 기능을 구현하는 것은 상당한 시간과 노력이 필요하다. 이 때문에 많은 기업에서는 상용 ETL 도구를 구매하여 사용하고 있다.
확립된 ETL 프레임워크나 도구를 사용하면 데이터 통합 작업의 확장성과 연결성을 크게 향상시킬 수 있다. 좋은 ETL 도구는 다양한 종류의 관계형 데이터베이스와 통신할 수 있어야 하며, 조직 내에서 사용되는 여러 가지 파일 형식 (예: CSV, XML, JSON 등)을 읽고 처리할 수 있는 능력을 갖추어야 한다.
최근 ETL 도구들은 단순한 데이터 추출, 변환, 적재 기능을 넘어 전사적 응용 프로그램 통합(EAI)이나 전사적 서비스 버스(ESB) 시스템의 일부로 통합되는 추세를 보이고 있다. 또한 많은 ETL 솔루션들이 데이터 프로파일링, 데이터 품질 관리, 메타데이터 관리와 같은 부가적인 기능을 제공하여 데이터 관리의 효율성을 높이고 있다.
ETL 도구의 일반적인 사용 사례 중 하나는 CSV 파일을 관계형 데이터베이스에서 사용할 수 있는 형식으로 변환하는 것이다. 대량의 데이터(수백만 건 이상의 레코드)를 처리해야 할 때, ETL 도구는 사용자가 복잡한 코드를 작성하는 대신 시각적인 인터페이스(GUI)와 데이터 매퍼를 이용하여 비교적 쉽게 데이터를 변환하고 로드할 수 있도록 돕는다.
전통적으로 ETL 도구는 개발자나 IT 전문가들이 주로 사용하는 도구였지만, 최근에는 비즈니스 사용자들도 직접 데이터를 다룰 수 있도록 지원하는 방향으로 변화하고 있다. 시장 조사 기업인 가트너는 IT 부서의 도움 없이 현업 사용자가 직접 필요한 데이터 연결 및 통합 작업을 수행하는 '시민 통합자(citizen integrator)'[9]의 등장을 새로운 추세로 언급했다.[8] 이는 데이터 활용의 민주화와 신속한 의사결정을 지원하는 긍정적인 변화로 볼 수 있다.
아래는 주요 ETL 도구의 목록이다.
| 제품명 | 제공사/링크 |
|---|---|
| ASTERIA WARP | Infoteria (http://www.infoteria.com/jp/warp/ 링크) |
| Talend Data Integration | Talend (https://jp.talend.com/products/data-integration/ 링크) |
| DataCoordinator | NEC (http://www.nec.co.jp/datacoordinator/ 링크) |
| JasperReports ETL | TIBCO Jaspersoft |
| DataSpider Servista | Appresso (http://www.appresso.com/ 링크) |
| Syncsort DMExpress | Syncsort (현 Precisely) (http://www.ashisuto.co.jp/product/category/etl/syncsort-dmexpress/ 링크) |
| DataStage | IBM (http://www-06.ibm.com/jp/software/data/infosphere/datastage/ 링크) |
| PowerCenter | Informatica (https://www.informatica.com/jp/products/data-integration.html 링크) |
| Waha! Transformer | Waha! (https://waha-transformer.com/ 링크) |
| Simple Data Integrator | Ricoh (https://ja.sdi.ricct.com/ 링크) |
5. 변형 (Variations)
추출, 변환, 적재(ETL) 프로세스는 다양한 환경과 요구사항에 맞춰 변형된 형태로 사용되기도 한다. 주요 변형 방식으로는 온라인 트랜잭션 처리(OLTP) 시스템에서의 데이터 처리 방식, 데이터 가상화 기술을 활용한 가상 ETL, 그리고 데이터 처리 순서를 변경한 추출, 적재, 변환(ELT) 등이 있다.
5. 1. 온라인 트랜잭션 처리 (In online transaction processing)
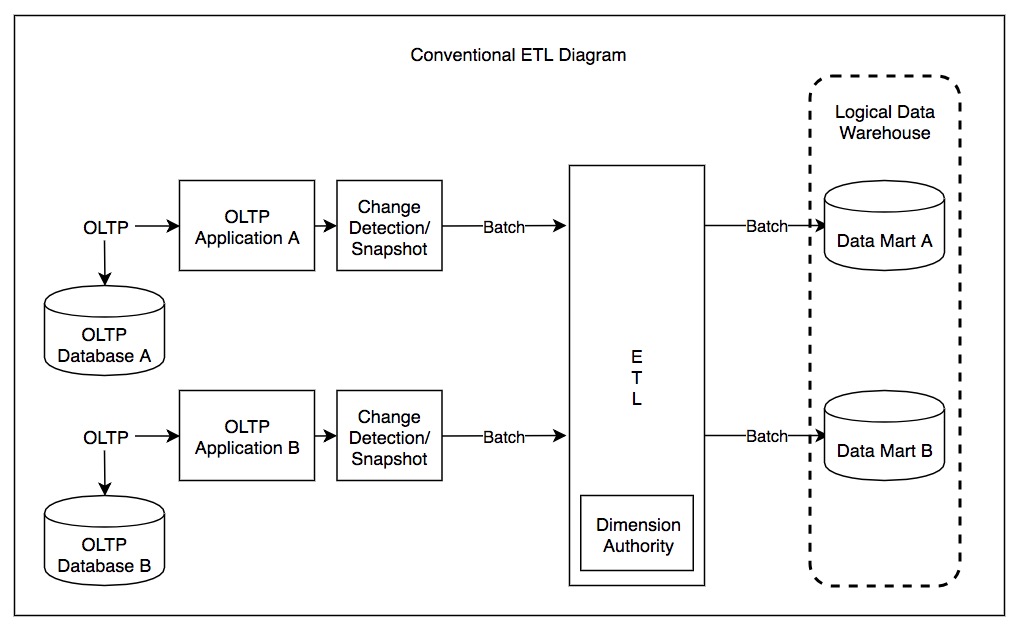
온라인 트랜잭션 처리(OLTP) 시스템에서는 각각의 OLTP 인스턴스에서 발생하는 데이터 변경 사항을 감지하여, 업데이트 내용을 스냅샷이나 배치(일괄 처리 단위) 형태로 기록한다. 이후 ETL 도구를 사용하여 주기적으로 이러한 배치 데이터를 모으고, 이를 공통된 형식으로 변환한 뒤 데이터 레이크나 데이터 웨어하우스에 적재할 수 있다.[1]
5. 2. 가상 ETL (Virtual ETL)
데이터 가상화는 ETL 프로세스를 발전시키는 데 사용될 수 있다. 데이터 가상화를 ETL에 적용하면 여러 분산된 데이터 소스에 대한 데이터 마이그레이션 및 애플리케이션 통합과 같은 일반적인 ETL 작업을 해결하는 데 도움을 준다.가상 ETL(Virtual ETL)은 다양한 관계형 데이터, 반구조적 데이터, 비정형 데이터 소스에서 가져온 객체 또는 엔티티를 추상화하여 표현하는 방식으로 작동한다. ETL 도구는 객체 지향 모델링을 활용하며, 중앙 집중식 허브 앤 스포크 아키텍처에 영구적으로 저장된 엔티티의 표현을 처리할 수 있다.
ETL 처리를 위해 데이터 소스에서 수집된 엔티티나 객체의 표현을 담고 있는 이러한 집합을 메타데이터 저장소라고 부른다. 이 저장소는 메모리에 임시로 존재하거나 영구적으로 만들어질 수 있다. 영구 메타데이터 저장소를 사용하면, ETL 도구는 일회성 프로젝트에서 벗어나 지속해서 작동하는 미들웨어로 전환될 수 있다. 이를 통해 데이터 조화(Data Harmonization) 작업과 데이터 프로파일링을 일관성 있게 거의 실시간으로 수행하는 것을 가능하게 한다.
5. 3. 추출, 적재, 변환 (Extract, load, transform; ELT)
추출, 적재, 변환 (ELT)은 추출된 데이터를 대상 시스템에 먼저 적재한 후 변환하는 방식으로, ETL의 변형이다.[10] ELT 방식은 속도가 빠르고, 정형 데이터뿐만 아니라 비정형 데이터 처리에도 용이하다는 장점이 있다.[11]특히 아마존 레드시프트, 구글 빅쿼리, 마이크로소프트 애저 시냅스 분석, 스노우플레이크와 같은 클라우드 기반 데이터 웨어하우스의 등장은 ELT 방식의 확산에 기여했다. 이러한 클라우드 서비스는 매우 확장 가능한 컴퓨팅 성능을 제공하여, 기업들이 원시 데이터를 먼저 데이터 웨어하우스에 복제(적재)한 다음, 필요에 따라 SQL 등을 사용하여 데이터를 변환하는 것을 가능하게 한다. 즉, 데이터를 적재하기 전에 미리 변환하는 과정을 생략할 수 있게 된 것이다.
ELT 과정을 거친 데이터는 추가적인 처리를 통해 데이터 마트 등에 저장되어 활용될 수 있다.[13]
일반적으로 데이터 통합 도구들은 ETL 방식을 중심으로 개발되는 경향이 있지만, ELT 방식은 데이터베이스 및 데이터 웨어하우스 어플라이언스 환경에서 널리 사용되고 있다.
랄프 킴볼과 조 카세르타는 그들의 저서 "데이터 웨어하우스 ETL 툴킷"(The Data Warehouse ETL Toolkiteng, Wiley, 2004)에서 데이터 웨어하우징에서의 ETL 프로세스를 다루며 관련 내용을 설명했다.[12]
6. 도구
ETL 도구는 데이터를 추출, 변환, 적재하는 과정을 자동화하고 관리하는 데 사용되는 소프트웨어이다. 이러한 도구들은 개발 방식과 라이선스에 따라 크게 오픈 소스 도구와 상용 도구로 나눌 수 있다.
6. 1. 오픈 소스 도구
- Talend Open Studio for Data Integration ([https://jp.talend.com/download/talend-open-studio/ 공식 다운로드])
- Pentaho 데이터 통합 ([http://www.pentaho.com/ 공식 웹사이트])
- 재스퍼리포트 ETL ([http://community.jaspersoft.com/project/jaspersoft-etl 커뮤니티 프로젝트])
- KNIME
- [https://nifi.apache.org/ Apache NIFI]
- [https://github.com/ayende/rhino-etl Rhino ETL]
- [http://www.streamsets.com/ StreamSets]
- [http://www.innoquartz.com/ InnoQuartz ETL]
- [http://www.cloveretl.org/ Clover.ETL]
- [http://www.enhydra.org/tech/octopus/index.html Enhydra Octopus] (자바 웹 스타트를 통해 웹 브라우저에서 실행)
6. 2. 상용 도구
ETL 시스템은 거의 모든 프로그래밍 언어로 만들 수 있지만, 처음부터 만드는 것은 매우 어렵다. 이 때문에 ETL 도구를 구매하는 기업이 늘고 있다.확립된 ETL 프레임워크를 사용하면, 연결성 및 확장성이 향상된다. 좋은 ETL 도구는 다양한 관계형 데이터베이스를 처리할 수 있으며, 다양한 파일 형식을 다룰 수 있다. ETL 도구는 전사적 응용 프로그램 통합 및 전사적 서비스 버스 시스템과 통합되는 추세이며, 단순한 추출, 변환, 적재 이상의 기능을 포괄하게 되었다. 많은 ETL 제품들이 데이터 프로파일링, 데이터 품질 관리, 메타데이터 관리 기능 등을 포함하고 있다.
상업적으로 이용 가능한 주요 ETL 도구는 다음과 같다.
- Adeptia
- Alooma
- Analytics Canvas
- Anatella
- Alteryx
- Benetl (프리웨어)
- Boomi (델)
- CampaignRunner
- ESF Database Migration Toolkit
- Informatica PowerCenter
- Talend
- InnoQuartz
- IBM 인포스피어 데이터스테이지
- Ab Initio
- 오라클 데이터 인티그레이터 (ODI)
- 오라클 웨어하우스 빌더 (OWB)
- 마이크로소프트 SQL 서버 인티그레이션 서비스 (SSIS)
- Tomahawk Business Integrator (Novasoft Technologies)
- Pentaho Data Integration (or Kettle)
- Stambia
- Diyotta DI-SUITE for Modern Data Integration
- FlyData
- SAP 비즈니스 오브젝트 데이터 서비스
- SAS Data Integration Studio
- Skyvia
- SnapLogic
- Clover ETL
- SQ-ALL
- North Concepts Data Pipeline
- TeraStream (국산)
- Simple Data Integrator
- ASTERIA WARP (일본)
- Talend Data Integration
- DataCoordinator
- JasperReports ETL
- DataSpider Servista (일본)
- Syncsort DMExpress (일본)
- DataStage (일본)
- PowerCenter (일본)
- Waha! Transformer (일본)
- Simple Data Integrator (일본)
참조
[1]
서적
The data warehouse ETL toolkit : practical techniques for extracting, cleaning, conforming, and delivering data
Wiley
2004
[2]
학술지
Validating the extract, transform, load process used to populate a large clinical research database
2016
[3]
웹사이트
What is ETL? (Extract, Transform, Load) {{!}} Experian
https://www.edq.com/[...]
2017-10-20
[4]
웹사이트
Extract, transform, load? More like extremely tough to load, amirite?
https://www.theregis[...]
2018-06-04
[5]
학술지
Frequent patterns in ETL workflows: An empirical approach
2017
[6]
문서
Kimball, The Data Warehouse Lifecycle Toolkit, p. 332
[7]
문서
Golfarelli/Rizzi, Data Warehouse Design, p. 291
[8]
웹사이트
The Inexorable Rise of Self Service Data Integration
http://blogs.gartner[...]
2015-05-22
[9]
웹사이트
Embrace the Citizen Integrator
https://www.gartner.[...]
[10]
문서
Amazon Web Services, Data Warehousing on AWS, p. 9
[11]
웹사이트
ETL vs ELT: Meaning, Major Differences & Examples
https://www.analytic[...]
2023-09-02
[12]
웹사이트
The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data [Book]
https://www.oreilly.[...]
[13]
문서
Amazon Web Services, Data Warehousing on AWS, 2016, p. 10
2016
[14]
서적
Proceedings of the European Conference on Pattern Languages of Programs 2020
[15]
서적
The data warehouse ETL toolkit : practical techniques for extracting, cleaning, conforming, and delivering data
https://www.worldcat[...]
Wiley
2004
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com