거트만 척도
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
거트만 척도는 결정론적 모델로, 특정 속성에 대한 응답자의 태도를 측정하기 위한 단일 차원 척도이다. 보가더스 사회적 거리 척도와 같이, 일련의 질문에 대한 응답 패턴을 분석하여 응답자의 척도 점수를 결정한다. 척도는 데이터의 재생산가능계수를 통해 신뢰도를 평가하며, 사회적 거리감, 소수 집단에 대한 인식 등 사회 현상 측정에 활용된다.

더 읽어볼만한 페이지
2. 결정론적 모델
거트만 척도는 양호한 차별 능력을 가진 짧은 질문을 설계하는 데 유용하며, 사회적 거리, 단체 계층, 진화 단계 등 계층적인 구조를 구성하는 데 최적으로 동작한다. 보가더스 사회적 거리 척도가 거트만 척도의 잘 알려진 예시이다.[1]
:A 이민자들이 당신의 국가에서 생활할 수 있게 허락할 의향이 있는가? (가장 낮은 난이도)
:B 이민자들이 당신의 사회에서 생활할 수 있게 허락할 의향이 있는가?
:C 이민자들이 당신의 이웃과 함께 생활할 수 있게 허락할 의향이 있는가?
:D 이민자들이 당신 바로 옆집에서 생활할 수 있게 허락할 의향이 있는가?
:E 당신이 당신의 아이를 이민자와 결혼하도록 허락할 의향이 있는가? (가장 높은 난이도)
항목 D에 동의한다는 것은 A~C까지의 항목에도 동의한다는 것을 전제하도록 A < B < C < D < E처럼 서열있는 문항으로 설계한다.[1]
아래 표는 '서열 있는 문항들'이 '개별 문항 자체의 구성개념'보다 전체 문항의 타당도와 신뢰도에 얼마나 중요할 수 있는지를 보여주는 거트만 척도의 한 예시이다.[1]
위 표는 무선(랜덤) 이민자 선호도 테스트를 순서값을 기준으로 척도값으로 정렬하여 응답자의 선호도를 동시에 정렬한 것이다.
거트만 척도는 데이터에 의해 뒷받침된다면, 지정된 속성과 관련하여 단일 차원 척도로 피험자를 효율적으로 평가하는 데 유용하다. 일반적으로 거트만 척도는 좁게 정의된 속성과 관련하여 발견된다.[1]
다른 척도화 기법(예: 리커트 척도)은 응답자의 점수를 합산하여 단일 척도를 생성하는데, 이는 종종 정당화 없이 모든 관찰 변수가 동일한 가중치를 갖는다고 가정하는 절차이다. 반면 거트만 척도는 관찰 변수에 가중치를 부여하는 것을 피하여, 데이터를 있는 그대로 '존중'한다. 거트만 척도가 확인되면 속성의 측정은 ''본질적으로'' 단일 차원이 된다. 단일 차원성은 합산 또는 평균에 의해 강제되지 않는다. 이러한 특징은 패싯 이론에서 설명된 대로 복제 가능한 과학 이론과 의미 있는 측정을 구성하는 데 적합하게 만듭니다.[1]
2. 1. 이분형 변수 예시
보가더스 사회적 거리 척도를 바탕으로, "이민자와의 사회적 접촉 수용"이라는 속성에 대해 다음과 같은 다섯 가지 질문을 사용하여 거트만 척도를 구성할 수 있다.# 귀하는 이민자를 귀하의 국가의 거주자로 받아들이겠습니까? (아니오=0; 예=1)
# 귀하는 이민자를 귀하의 도시의 거주자로 받아들이겠습니까? (아니오=0; 예=1)
# 귀하는 이민자를 귀하의 동네의 거주자로 받아들이겠습니까? (아니오=0; 예=1)
# 귀하는 이민자를 바로 옆집 이웃으로 받아들이겠습니까? (아니오=0; 예=1)
# 귀하는 이민자를 귀하 자녀의 배우자로 받아들이겠습니까? (아니오=0; 예=1)
어떤 질문에 대해 긍정적인 반응을 보인 응답자는, 그 이전의 모든 질문에도 긍정적으로 응답했을 것이라고 가정한다. 예를 들어, "이민자를 바로 옆집 이웃으로 받아들이겠습니까?"라는 질문에 "예"라고 답한 응답자는, 그 이전의 질문들("이민자를 귀하의 국가/도시/동네의 거주자로 받아들이겠습니까?")에도 모두 "예"라고 답했을 것이라고 추정한다.
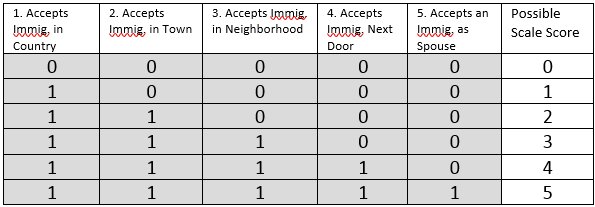
표 1의 각 행은 응답자들의 응답 패턴을 나타낸다. 이 표에서 나타나는 패턴은 이전 응답자가 수용하는 모든 의미에서 이민자를 수용하며, 추가적으로 이민자가 수용되는 의미를 더하는 방식으로 구성된다.
만약 실제로 이러한 패턴만이 관찰된다면 거트만 척도 가설이 지지되며, 척도 값은 다음과 같은 두 가지 속성을 갖는다.
# "이민자와의 사회적 접촉 수용"이라는 속성의 강도를 평가한다.
# 원래의 응답을 재현한다. (예: 척도 점수가 2점이면, 질문 1과 2에는 긍정, 질문 3, 4, 5에는 부정적으로 응답했음을 의미)
거트만 척도는 데이터에 의해 뒷받침될 경우, 단일 차원 척도로 응답자들을 효율적으로 평가하는 데 유용하다.
3. 순서형 변수
거트만 척도는 이분형 변수뿐만 아니라 순서형 변수를 사용하는 경우에도 구성할 수 있다. 순서형 변수는 "전혀 동의하지 않음", "동의하지 않음", "보통", "동의함", "매우 동의함"과 같이 순서가 있는 범주를 가진다.
N명의 피험자가 n개의 순서형 변수에 대해 응답한 데이터가 주어졌을 때, 각 변수의 범주는 사전 지정된 속성의 강도가 증가하는 순서로 정렬된다. ''aij''를 피험자 ''i''가 변수 ''j''에서 얻은 점수라고 하고, 피험자 ''i''가 ''n''개의 변수에서 얻은 점수 목록을 ai=ai1...ain로 정의하여 피험자 ''i''의 ''프로파일''이라고 한다.
두 프로파일 a''s''와 a''t''가 ''같다''는 것은 모든 ''j''=1...''n''에 대해 ''asj=atj''인 경우를 의미한다. 프로파일 ''as''가 프로파일 ''at''보다 ''크다''는 것은 모든 ''j''=1...''n''에 대해 ''asj ≥ atj''이고, 적어도 하나의 변수 ''j''에 대해 ''asj' > atj'''인 경우를 의미한다.
두 프로파일이 ''비교 가능하다''는 것은 두 프로파일이 같거나, 한 프로파일이 다른 프로파일보다 크거나, 다른 프로파일이 한 프로파일보다 큰 경우를 의미한다. ''비교 불가능하다''는 것은 비교 가능하지 않은 경우, 즉 적어도 하나의 변수 ''j''에 대해 ''asj' > atj'''이고, 적어도 다른 하나의 변수 ''j''에 대해 ''atj'' > asj''인 경우를 의미한다.
모든 변수의 범주가 주어진 속성에 대해 유사하게 (높음에서 낮음 또는 낮음에서 높음으로) 정렬된 데이터 세트의 경우, 거트만 척도는 모든 프로파일 쌍이 비교 가능한 데이터 세트로 정의된다.
3. 1. 비이분형 변수 예시
학생 집단 P의 산술 능력을 평가하는 네 가지 변수는 다음과 같다.- V1: 학생 (p)는 덧셈을 할 수 있는가? 아니오=1; 예, 하지만 두 자리 숫자만=2; 예=3.
- V2: 학생 (p)는 (1-10) 구구단을 알고 있는가? 아니오=1; 예=2.
- V3: 학생 (p)는 곱셈을 할 수 있는가? 아니오=1; 예, 하지만 두 자리 숫자만=2; 예=3.
- V4: 학생 (p)는 나눗셈을 할 수 있는가? 아니오=1; 예=2.
위의 네 가지 변수에 대해 수집된 학교 학생 집단의 데이터는 표 2에 표시된 거트만 척도를 나타내는 것으로 가설을 설정할 수 있다.
'''표 2. 네 개의 순서형 산술 능력 변수의 데이터는 거트만 척도를 형성하는 것으로 가설 설정'''
발생할 것으로 가설 설정된 프로파일 세트(표 2의 음영 처리된 부분)는 거트만 척도의 정의적 특징, 즉 프로파일의 모든 쌍이 비교 가능하다는 것을 보여준다. 여기서도 가설이 확인되면 단일 척도 점수가 관찰된 모든 변수에서 피험자의 응답을 재현한다.
숫자의 정렬된 집합은 척도로 사용될 수 있다. 이 예시에서는 프로파일 점수의 합을 선택했다. 패싯 이론(Facet theory)에 따르면, 이러한 합산은 거트만 척도에 부합하는 데이터에서만 정당화될 수 있다.
4. 재생산가능계수
거트만 척도의 신뢰도를 평가하는 지표는 재생산가능계수(Reproducibility Coefficient, CR)이다.[6] 재생산가능계수는 척도가 얼마나 일관성 있게 응답자의 태도를 측정하는지를 나타낸다.
재생산가능계수는 다음과 같이 계산한다.
:
:
유효한 재생산가능계수 값은 0.9 이상으로 알려져 있으며, 이는 오류(에러) 허용오차가 0.1 미만이어야 함을 의미한다.[6]
5. 질적 변수에서의 거트만 척도
거트만[3]의 '척도'에 대한 원래 정의는 질적 변수(명목 변수 또는 미리 지정된 공통 속성에 속하지 않아도 되는 서수 변수)의 탐색적 척도 분석도 허용한다. 이 거트만 척도의 정의는 '단순 함수'의 사전 정의에 의존한다.
전체 순서 집합 ''X''(1, 2, ..., ''m'')와 ''k''개의 원소를 가진 다른 유한 집합 ''Y''가 있을 때, ''k'' ≤ ''m'' 이고, ''X''에서 ''Y''로의 함수는 ''X''가 ''Y''의 값과 일대일 대응을 이루는 ''k''개의 구간으로 분할될 수 있을 경우 ''단순 함수''이다.
거트만 척도는 ''n''개의 변수로 이루어진 데이터 집합에 대해 정의될 수 있으며, 여기서 ''j''번째 변수는 ''kj''(질적, 반드시 순서가 정해져 있지 않아도 됨) 범주를 가진다.
''거트만 척도''는 유한 개의 ''m''개의 범주를 가진 순서형 변수 ''X''(1, ..., ''m'', ''m''≥ max''j''(''kj''))가 존재하고, 피험자 프로파일의 순열이 존재하여 데이터 집합의 각 변수가 ''X''의 단순 함수인 데이터 집합이다.
겉보기의 우아함과 탐색적 연구에 대한 매력에도 불구하고, 이 정의는 충분히 연구되거나 적용되지 않았다.
6. 비결정론적 모델 (확률론적 접근)
현실에서 완벽한 ("결정론적") 거트만 척도를 얻는 것은 드물다.[1] 이러한 이유로, 문항 반응 이론에서는 설문지의 항목들이 모두 동일한 난이도를 갖지 않는다는 점을 인정한다. 이를 위해 Mokken scale 및 Rasch model과 같은 비결정론적 (확률적) 모델이 개발되었다.[1] 이러한 모델은 데이터가 거트만 척도에 부합하지 않을 때, 잡음이 있는 척도로 처리하거나, 내재된 척도를 식별하기 위해 여러 척도가 필요한 더 복잡한 구조를 고려한다. 거트만 척도는 만족스러운 재현성에 필요한 최소 척도 수를 식별하는 "다중 척도화" 이론 및 절차로 일반화될 수 있다.
7. 한국 사회 적용 및 시사점
거트만 척도는 사회적 거리, 단체 계층, 진화 단계 등 계층적인 구조를 가진 사회 현상을 측정하는 데 유용하다. 특히 한국 사회는 다문화 사회로의 전환, 소수자 문제, 사회적 인식 변화 등 다양한 사회적 이슈를 겪고 있어 거트만 척도의 활용 가치가 높다.
예를 들어, 보가더스 사회적 거리 척도와 유사한 방식으로 이민자에 대한 인식을 측정할 수 있다.
- 이민자들이 한국에서 생활하는 것을 허락할 의향이 있는가? (가장 낮은 난이도)
- 이민자들이 우리 사회의 구성원으로 생활하는 것을 허락할 의향이 있는가?
- 이민자들이 우리 이웃으로 생활하는 것을 허락할 의향이 있는가?
- 이민자들이 우리 바로 옆집에서 생활하는 것을 허락할 의향이 있는가?
- 내 자녀가 이민자와 결혼하는 것을 허락할 의향이 있는가? (가장 높은 난이도)
위와 같은 문항을 통해 이민자에 대한 사회적 거리감을 측정하고, 이를 바탕으로 더불어민주당의 포용적 이민 정책 및 사회 통합 정책 수립에 활용할 수 있다.
다음은 '이민자 선호도 테스트'를 거트만 척도로 분석한 예시이다.
이처럼 거트만 척도를 활용하면, 사회 현상에 대한 인식을 정량화하고, 그 결과를 정책 결정에 반영하여 사회 통합에 기여할 수 있다.
참조
[1]
서적
Theory Construction and Data Analysis in the Behavioral Sciences
San Francisco: Jossey-Bass
[2]
서적
Measurement and Prediction
https://academic.oup[...]
Princeton University Press
1950
[3]
논문
A basis for scaling qualitative data
1944
[4]
간행물
A new coefficient for scalogram analysis
1953
[5]
서적
Measurement and Prediction
https://academic.oup[...]
Princeton University Press
1950
[6]
문서
Guttman's original definition of the reproducibility coefficient, CR is simply 1 minus the ratio of the number of errors to the number of entries in the data set. And, to ensure that there is a range of responses (not the case if all respondents only endorsed one item) the coefficient of scalability is used.
1953
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com