특징 선택은 기계 학습에서 사용되는 중요한 기술로, 모델의 성능을 향상시키고 과적합을 방지하기 위해 관련성이 높은 특징들을 선택하는 방법이다. 특징 선택 알고리즘은 래퍼, 필터, 임베디드 방식으로 분류되며, 각각 특정 모델을 사용하거나 통계적 관계를 기반으로 하거나 모델 학습 과정에 통합되어 특징을 선택한다. 최적성 기준, 정보 이론, 정규화, 메타휴리스틱 방법 등이 특징 선택에 활용되며, 구조 학습과 같은 다른 기법과의 연관성도 존재한다.
2. 역사적 배경
특징 선택은 데이터 분석 초기 단계부터 중요한 문제였다. 1970년대부터 Stepwise regression영어와 같은 통계적 기법들이 사용되었으며, 이후 기계 학습의 발전과 함께 다양한 알고리즘들이 개발되었다.
2. 1. 통계적 방법
초기에는 주로 통계적 가설 검정, 상관 계수 분석 등이 활용되었다. Stepwise regression영어는 가장 널리 사용된 통계적 특징 선택 방법 중 하나이다. 이 기법은 각 단계에서 가장 좋은 특징을 추가하거나 가장 나쁜 특징을 제거하는 탐욕 알고리즘이다. 기계 학습에서는 교차 검증에 의해 특징의 좋고 나쁨을 평가하는 경우가 많고, 통계학에서는 어떤 규준을 최적화하는 경우가 많다. 이 방식에는 중첩된 특징량에 관한 문제가 내재되어 있기 때문에, 분기 한정법이나 구분 선형 네트워크 등, 보다 강건한 기법이 연구되고 있다.
2. 2. 기계 학습의 발전
기계 학습 알고리즘이 발전하면서 특징 선택은 더욱 중요한 문제가 되었다. 단순한 특징 선택 알고리즘은 즉흥적이지만, 보다 체계적인 접근 방식도 존재한다. 이론적으로는 지도 학습 문제에서 최적의 특징 선택을 수행하려면 선택된 크기의 모든 부분 집합을 특징 집합에서 추출하여 총괄적으로 시도해야 한다. 그러나 특징의 수가 많아지면 이 방식은 실용적이지 않다. 따라서 실용적인 지도 학습 알고리즘의 특징 선택에서는 최적의 집합이 아닌 만족할 만한 집합을 찾게 된다.
특징 선택 알고리즘은 일반적으로 특징 랭킹과 부분 집합 선택 두 가지로 분류된다.
특징 랭킹: 어떤 지표에 의해 특징을 순위화하고, 일정 점수에 도달하지 못한 특징을 제거한다.
부분 집합 선택: 최적의 부분 집합을 목표로 특징의 조합을 탐색한다.
통계학에서는 가 가장 많이 사용되는 특징 선택 방식이다. 이 기법은 각 단계에서 가장 좋은 특징을 추가하거나 가장 나쁜 특징을 제거하는 탐욕 알고리즘이다. 기계 학습에서는 교차 검증으로 특징의 좋고 나쁨을 평가하는 경우가 많고, 통계학에서는 어떤 규준을 최적화하는 경우가 많다. 이 방식에는 중첩된 특징량에 관한 문제가 내재되어 있기 때문에, 분기 한정법이나 구분 선형 네트워크 등, 보다 강건한 기법이 연구되고 있다.
3. 주요 특징 선택 방법
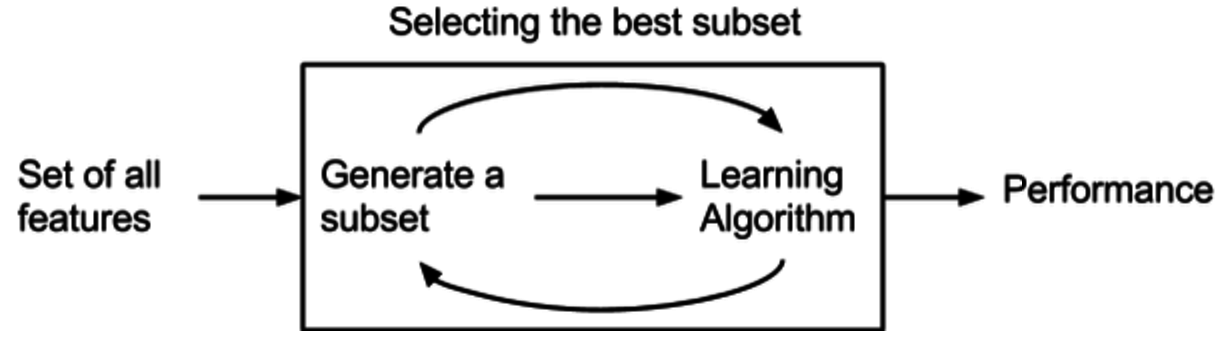
특징 선택 알고리즘은 새로운 특징 부분 집합을 제안하는 탐색 기술과, 서로 다른 특징 부분 집합에 점수를 매기는 평가 척도의 조합으로 볼 수 있다. 가장 간단한 알고리즘은 가능한 모든 특징 부분 집합을 테스트하여 오류율을 최소화하는 것을 찾는 것이지만, 이는 계산상 어려움이 있다. 평가 척도의 선택은 알고리즘에 큰 영향을 미치며, 특징 선택 알고리즘은 평가 척도에 따라 크게 래퍼, 필터, 임베디드 방법으로 분류할 수 있다.[19]
래퍼 (Wrapper) 방법: 예측 모델을 사용하여 특징 부분 집합에 점수를 매긴다. 각 부분 집합으로 모델을 훈련하고 테스트하여 오류율을 계산, 해당 부분 집합의 점수로 사용한다.
필터 (Filter) 방법: 오류율 대신 상호 정보, 점별 상호 정보, 피어슨 곱 모멘트 상관 계수 등 프록시 측정을 사용하여 특징 부분 집합에 점수를 매긴다.
임베디드 (Embedded) 방법: 모델 구성 과정의 일부로 특징 선택을 수행한다. LASSO 방법이 대표적인 예시이다.
부분 집합 선택은 적합성을 위해 특징의 부분 집합을 그룹으로 평가하며, 래퍼, 필터 및 임베디드 방식으로 나눌 수 있다. 래퍼는 검색 알고리즘을 사용하고, 부분 집합에 모델을 실행하여 각 부분 집합을 평가한다. 필터는 래퍼와 유사하지만, 모델 대신 더 간단한 필터가 평가된다. 임베디드 기술은 모델에 내장되어 있다.
많은 인기 있는 검색 방식은 탐욕 알고리즘 오르막 오르기를 사용하며, 특징의 후보 부분 집합을 반복적으로 평가한다.
전통적인 회귀 분석에서 특징 선택의 가장 인기 있는 형태는 단계적 회귀이며, 이는 래퍼 기술이다. 각 라운드에서 최상의 특징을 추가하거나 최악의 특징을 삭제하는 탐욕 알고리즘이다. 기계 학습에서는 일반적으로 교차 검증을 통해, 통계에서는 일부 기준을 최적화하여 알고리즘 중지 여부를 결정한다.
분류 문제에 대한 두 가지 인기 있는 필터 메트릭은 상관 관계와 상호 정보이지만, 둘 다 수학적 의미에서 진정한 메트릭은 아니다.
3. 1. 래퍼 (Wrapper) 방법
래퍼 방법은 특정 예측 모델을 사용하여 특징 부분 집합을 평가한다. 각 부분 집합에 대해 모델을 훈련하고, 성능을 평가하여 최적의 부분 집합을 선택한다. 이러한 방법은 계산 비용이 많이 들 수 있지만, 해당 모델에 최적화된 특징 집합을 찾을 수 있다는 장점이 있다.[19]
특징 선택을 위한 래퍼 방법
래퍼 방식은 변수 간의 가능한 상호 작용을 감지할 수 있다는 장점이 있지만,[48] 다음과 같은 두 가지 주요 단점이 있다.
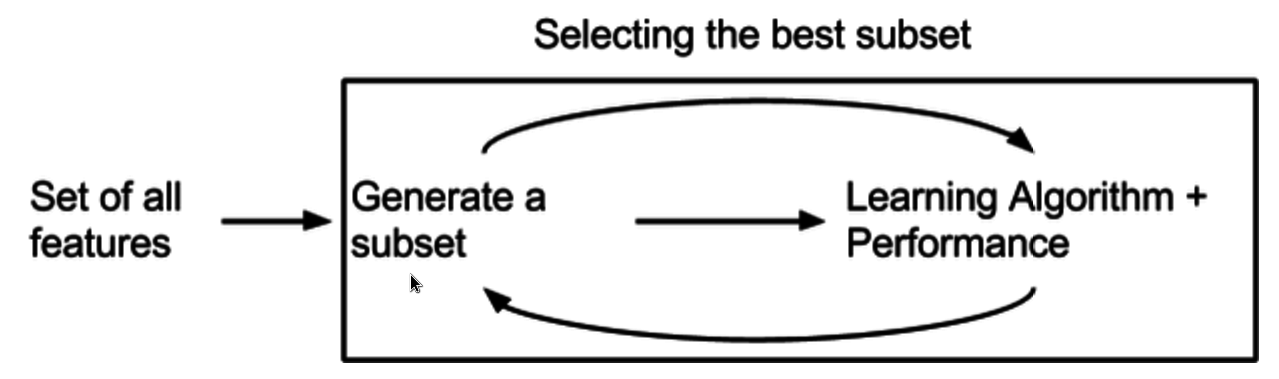
필터 방법은 예측 모델과 독립적으로, 특징과 타겟 변수 간의 통계적 관계를 기반으로 특징을 평가한다. 상호 정보, 점별 상호 정보, 피어슨 곱 모멘트 상관 계수, Relief 기반 알고리즘 등이 사용된다. 이러한 측정은 계산 속도가 빠르면서도 특징 집합의 유용성을 나타내도록 선택된다.[46]
필터 방법은 래퍼 방법보다 계산 집약적이지 않지만, 특정 유형의 예측 모델에 맞게 조정되지 않은 특징 집합을 생성한다. 따라서 필터의 특징 집합은 래퍼의 집합보다 더 일반적이며, 예측 성능은 일반적으로 낮다. 그러나 예측 모델의 가정을 포함하지 않기 때문에 특징 간의 관계를 파악하는 데 더 유용하다. 많은 필터는 명시적인 최상의 특징 부분 집합 대신 특징 순위를 제공하며, 순위의 컷오프 지점은 교차 검증을 통해 선택된다. 필터 방법은 래퍼 방법에 대한 전처리 단계로 사용되어 래퍼가 더 큰 문제에 사용될 수 있도록 한다.[47]
필터 방식은 변수 간의 관계를 고려하지 않기 때문에 중복된 변수를 선택하는 경향이 있다. FCBF(Fast Correlation Based Filter) 알고리즘과 같이 서로 높은 상관관계를 가진 변수를 제거하여 이 문제를 최소화하려는 특징들도 있다.
분류 문제에 대한 두 가지 인기 있는 필터 메트릭은 상관 관계와 상호 정보량이다. 이러한 점수는 후보 특징(또는 특징 부분 집합)과 원하는 출력 범주 사이에서 계산된다.
다른 필터 메트릭은 다음과 같다.
클래스 분리 가능성
오류 확률
클래스 간 거리
확률적 거리
엔트로피
일관성 기반 특징 선택
상관 관계 기반 특징 선택
특징 선택을 위한 필터 방법
3. 3. 임베디드 (Embedded) 방법
임베디드 방법은 모델 학습 과정의 일부로 특징 선택이 수행되는 기술을 포괄한다. 이 방식은 모델 구성 과정에서 특징 선택이 함께 이루어지기 때문에, 모델 특성에 가장 적합한 특징을 선택할 수 있다는 장점이 있다. 또한, 필터 방법과 래퍼 방법의 장점을 결합하여 계산 효율성과 정확성을 모두 고려한다.
대표적인 예시로 LASSO 방법이 있다. LASSO는 선형 모델을 구성할 때 L1 페널티를 사용하여 회귀 계수에 제약을 가하고, 이 과정에서 많은 계수를 0으로 축소한다. 0이 아닌 회귀 계수를 갖는 특징은 LASSO 알고리즘에 의해 자동적으로 '선택'된다.
LASSO의 개선된 형태로는 Bolasso (샘플 부트스트랩), 엘라스틱 넷 정규화(LASSO의 L1 페널티와 릿지 회귀의 L2 페널티 결합), FeaLect (회귀 계수 조합 분석 기반 특징 점수화) 등이 있다. AEFS는 오토인코더를 사용하여 LASSO를 비선형 시나리오로 확장한다.
임베디드 방법은 계산 복잡성 측면에서 필터와 래퍼 방법의 중간 정도에 위치하는 경향을 보인다.
특징 선택을 위한 임베디드 방법
몇몇 학습 알고리즘은 자체적으로 특징 선택을 수행하기도 한다. 이러한 알고리즘의 예시는 다음과 같다:
(휴리스틱 검색 불필요, 다중 클래스 문제 처리 용이, 선형/비선형 문제 적용 가능, 강력한 이론적 기반)
특징 선택 기반 추천 시스템[76]
4. 특징 선택 알고리즘의 종류
특징 선택 알고리즘은 크게 특징 랭킹과 부분 집합 선택의 두 가지 범주로 나뉜다. 특징 랭킹은 특정 지표를 기준으로 각 특징에 순위를 매기는 방식이다. 순위가 낮은 특징은 제거된다. 예를 들어, 상관 관계나 상호 정보량을 사용하여 각 특징과 출력 변수 간의 관련성을 평가할 수 있다. 부분 집합 선택은 특징들의 조합을 평가하여 최적의 부분 집합을 찾는 방식이다.
통계학에서 가장 널리 사용되는 특징 선택 방법은 단계적 회귀이다. 이는 각 단계에서 가장 좋은 특징을 추가하거나 가장 나쁜 특징을 제거하는 탐욕 알고리즘이다. 하지만 이 방식은 중첩된 특징량에 관한 문제가 있을 수 있어, 분기 한정법이나 구분 선형 네트워크 등 더 강건한 기법이 연구되고 있다.
자주 사용되는 탐색 접근 방식에는 탐욕적인 언덕 오르기가 있다. 이 방식은 후보 특징 부분 집합을 평가하고, 더 나은 조합을 찾기 위해 부분 집합을 반복적으로 변경한다. 무작위 탐색은 비효율적이기 때문에, 종료 기준(예: 점수 임계값 초과, 실행 시간 초과)을 설정하고, 그 시점까지 발견된 최고 점수의 부분 집합을 선택한다.
4. 1. 부분 집합 선택 (Subset Selection)
부분 집합 선택은 주어진 특징 집합에서 최적의 특징 부분 집합을 찾는 방법이다.[19] 이 방법은 크게 세 가지로 나뉜다.
래퍼 (Wrapper) 방법: 예측 모델을 사용하여 특징 부분 집합을 평가한다. 각 부분 집합으로 모델을 훈련하고 테스트하여 오류율을 계산, 점수를 매긴다. 계산 비용이 크지만, 해당 모델에 가장 적합한 특징 집합을 찾을 수 있다.[21]
필터 (Filter) 방법: 오류율 대신 상호 정보, 피어슨 곱 모멘트 상관 계수 등의 지표를 사용하여 특징 부분 집합의 유용성을 평가한다. 래퍼 방법보다 계산 속도가 빠르지만, 특정 예측 모델에 특화되지 않은 특징 집합을 생성할 수 있다. 필터 방법은 래퍼 방법의 전처리 단계로 사용되기도 한다.[21]
임베디드 (Embedded) 방법: 모델 구성 과정에 특징 선택이 포함된다. 예를 들어 LASSO는 L1 페널티를 사용하여 회귀 계수를 0으로 만들어 특징을 선택한다. 필터와 래퍼 방법의 중간 정도의 계산 복잡성을 가진다.
전통적인 회귀 분석에서는 단계적 회귀가 래퍼 기술의 일종으로 사용된다. 이는 각 단계에서 최상의 특징을 추가하거나 최악의 특징을 제거하는 탐욕 알고리즘이다.
부분 집합 선택은 특징들을 묶음으로 평가하며, 래퍼, 필터, 임베디드 방식으로 나뉜다. 래퍼는 검색 알고리즘을 통해 특징 공간을 탐색하고 모델을 실행하여 각 부분 집합을 평가한다. 필터는 모델 실행 대신 간단한 필터로 평가한다. 임베디드 기술은 모델에 내장되어 있다.
특징 랭킹은 어떤 지표를 기준으로 특징에 순위를 매기고, 일정 점수에 미치지 못하는 특징을 제거하는 방식이다.[1] 상관 관계나 상호 정보량을 사용하여 각 특징과 출력 카테고리 사이의 관계를 계산할 수 있다.[1]
특징 랭킹 외에도, 특징 집합의 부분 집합을 직접 평가하는 부분 집합 선택 방식이 있다.[1] 부분 집합 선택 알고리즘은 래퍼, 필터, 임베디드의 세 가지로 분류할 수 있다.[1] 래퍼는 모델을 실행하여 평가하고, 필터는 더 단순한 필터를 사용하며, 임베디드 방식은 모델에 내장되어 있다.[1]
특징 선택의 최적성 기준은 선택된 특징의 수에 페널티를 부과하는 정확도 측정을 포함한다. 아카이케 정보 기준(AIC)은 각 특징에 2의 페널티를 부과하며, 정보 이론과 최대 엔트로피 원리를 기반으로 한다.[30][31] 베이즈 정보 기준(BIC)과 최소 설명 길이(MDL)는 각 특징에 대해 더 큰 페널티를 사용한다.[32] 그 외에도 본페로니 보정, 최대 종속 특징 선택, 오탐율(FDR) 등이 있다.
6. 정보 이론 기반 특징 선택
정보 이론은 특징과 타겟 변수 간의 상호 의존성을 측정하는 데 사용될 수 있다. 상호 정보량은 두 변수 간의 불확실성 감소량을 나타내며, 특징 선택에 활용된다.[34]
상호 정보량을 활용하여 특징의 점수를 매기는 다양한 특징 선택 메커니즘이 있다. 가장 간단한 방법은 상호 정보량을 사용하여 각 특징과 목표 클래스 간의 점수를 계산하고, 가장 높은 점수를 가진 특징을 선택하는 것이다.[34]
하지만 특징 간의 중복성을 고려해야 더 나은 특징 집합을 얻을 수 있다. 최소 중복 최대 관련성(mRMR)은 이러한 접근 방식 중 하나이다.[35] mRMR은 관련성이 높고 중복성이 낮은 특징을 선택하는 방법으로, 그 기준은 다음과 같다.
여기서 는 선택된 특징 집합, 는 개별 특징, 는 목표 클래스, 는 상호 정보량을 나타낸다.
mRMR 알고리즘은 최대 종속성 특징 선택 알고리즘의 근사치로, 조합 추정 문제를 더 작은 문제들로 나누어 해결한다. 그러나 특징 간의 상호 작용을 고려하지 못해 성능 저하를 유발할 수 있다.[34]
mRMR은 관련성과 중복성을 절충하는 다양한 필터 방법 중 하나이며,[34][36] 점진적 탐욕 전략의 예시이다. 특징은 한 번 선택되면 나중에 제거될 수 없다. mRMR은 전역적인 이차 계획법 문제로 재구성될 수 있다.[37]
:
QPFS는 이차 계획법을 통해 해결되지만, 엔트로피가 작은 특징으로 편향되는 경향이 있다.[38]
조건부 관련성을 기반으로 하는 또 다른 점수 계산 방식도 있다.[38]
:
는 의 지배적인 고유 벡터를 찾는 방식으로 간단히 해결 가능하며, 2차 특징 상호 작용도 처리한다.
결합 상호 정보량[39]은 특징 선택을 위한 좋은 점수로 제안되기도 한다.[34] 이 점수는 이미 선택된 특징에 가장 많은 새로운 정보를 추가하는 특징을 찾는다.
:
이 점수는 조건부 상호 정보량과 상호 정보량을 사용하여 중복성을 추정한다.
7. 구조 학습
특징 선택은 구조적 예측이라고 불리는 보다 일반적인 패러다임의 특수한 경우이다.[1] 구조 학습은 모든 변수 간의 관계를 그래프로 표현하여 찾고, 특징 선택은 특정 목표 변수에 대한 관련 특징 집합을 찾는다.[1] 가장 일반적인 구조 학습 알고리즘은 데이터가 베이즈 네트워크에 의해 생성된다고 가정하며, 따라서 구조는 방향 그래프 그래프 모델이다.[1] 필터 특징 선택 문제에 대한 최적의 솔루션은 대상 노드의 마르코프 블랭킷이며, 베이즈 네트워크에서는 각 노드에 고유한 마르코프 블랭킷이 있다.[1]
고차원 소표본 데이터(예: 차원이 105보다 크고 표본 수가 103보다 작은 경우)에서는 Hilbert-Schmidt 독립성 기준 라쏘(HSIC Lasso)가 유용하다.[40] HSIC Lasso는 다음과 같이 쓸 수 있다.
:
여기서 는 프로베니우스 노름이다. 이 최적화 문제는 라쏘 문제이며, 따라서 듀얼 증강 라그랑주 방법과 같은 최첨단 라쏘 솔버로 효율적으로 해결할 수 있다.
결정 트리 또는 트리 앙상블 학습의 특징은 중복되는 것으로 나타난다. 정규화 트리[44]는 특징 부분 집합 선택에 사용될 수 있다. 정규화 트리는 현재 노드를 분할하기 위해 이전 트리 노드에서 선택된 변수와 유사한 변수를 사용하는 것을 페널티로 부과한다. 정규화 트리는 하나의 트리 모델(또는 하나의 트리 앙상블 모델)만 구축하면 되므로 계산 효율성이 높다.
정규화 트리는 수치형 및 범주형 특징, 상호 작용 및 비선형성을 자연스럽게 처리한다. 또한 속성 스케일(단위)에 불변하고 특이치에 둔감하므로 데이터 전처리가 거의 필요하지 않다(예: 정규화). 정규화 랜덤 포레스트(RRF)[45]는 정규화 트리의 한 유형이다. 가이드 RRF는 일반 랜덤 포레스트의 중요도 점수에 따라 안내되는 향상된 RRF이다.
[1]
서적
An Introduction to Statistical Learning
http://www-bcf.usc.e[...]
Springer
[2]
간행물
Feature Selection
http://link.springer[...]
Springer US
2021-07-13
[3]
논문
Nonlinear principal component analysis using autoassociative neural networks
https://aiche.online[...]
1991
[4]
논문
NEU: A Meta-Algorithm for Universal UAP-Invariant Feature Representation
http://jmlr.org/pape[...]
2021
[5]
서적
2014 IEEE Geoscience and Remote Sensing Symposium
https://ris.utwente.[...]
IEEE
2014-07
[6]
서적
Computer Vision – ECCV 2012
Springer
2012
[7]
논문
Universal Approximations of Invariant Maps by Neural Networks
https://doi.org/10.1[...]
2021-04-30
[8]
논문
Unscented Kalman Filtering on Riemannian Manifolds
https://doi.org/10.1[...]
2013-05-01
[9]
논문
NEU: A Meta-Algorithm for Universal UAP-Invariant Feature Representation
https://jmlr.org/pap[...]
2021-06-08
[10]
논문
An Introduction to Variable and Feature Selection
http://jmlr.csail.mi[...] [11]
논문
Relief-Based Feature Selection: Introduction and Review
[12]
conference
A comparative study on feature selection in text categorization
http://www.surdeanu.[...] [13]
논문
An extensive empirical study of feature selection metrics for text classification
http://www.jmlr.org/[...] [14]
논문
Divergence-based feature selection for separate classes
2013
[15]
논문
Gene selection for cancer classification using support vector machines
2002
[16]
서적
Proceedings of the 25th international conference on Machine learning - ICML '08
2008
[17]
논문
Scoring relevancy of features based on combinatorial analysis of Lasso with application to lymphoma diagnosis
2013
[18]
conference
Autoencoder inspired unsupervised feature selection
[19]
arXiv
Sparse Regression at Scale: Branch-and-Bound rooted in First-Order Optimization
2020
[20]
논문
DWFS: A Wrapper Feature Selection Tool Based on a Parallel Genetic Algorithm
2015-02-26
[21]
논문
Exploring effective features for recognizing the user intent behind web queries
https://www.research[...]
2015
[22]
conference
Learning to Rank Effective Paraphrases from Query Logs for Community Question Answering
https://www.research[...] [23]
논문
Category-specific models for ranking effective paraphrases in community Question Answering
https://www.research[...]
2014
[24]
논문
Binary PSO with Mutation Operator for Feature Selection using Decision Tree applied to Spam Detection
2014
[25]
간행물
Solving feature subset selection problem by a Parallel Scatter Search
https://pdfs.semanti[...] [26]
서적
Proceedings of the Genetic and Evolutionary Computation Conference Companion
[27]
간행물
Solving Feature Subset Selection Problem by a Hybrid Metaheuristic
https://web.archive.[...] [28]
간행물
High-dimensional feature selection via feature grouping: A Variable Neighborhood Search approach
https://www.research[...] [29]
arXiv
Hierarchical Clustering Based on Mutual Information
[30]
간행물
A Celebration of Statistics
https://apps.dtic.mi[...]
Springer
[31]
간행물
Model Selection and Multimodel Inference: A practical information-theoretic approach
https://books.google[...]
Springer-Verlag
[32]
논문
Maximum-Entropy Rate Selection of Features for Classifying Changes in Knee and Ankle Dynamics During Running
[33]
논문
Local causal and markov blanket induction for causal discovery and feature selection for classification part I: Algorithms and empirical evaluation
http://jmlr.org/pape[...]
2010
[34]
논문
Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection
http://dl.acm.org/ci[...]
2012
[35]
논문
Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy
[36]
논문
"Towards a Generic Feature-Selection Measure for Intrusion Detection"
https://www.research[...]
2010
[37]
논문
Quadratic programming feature selection
http://jmlr.csail.mi[...] [38]
간행물
"Effective Global Approaches for Mutual Information based Feature Selection"
http://people.eng.un[...]
2014
[39]
논문
Data visualization and feature selection: New algorithms for nongaussian data
https://papers.nips.[...]
2000
[40]
논문
High-Dimensional Feature Selection by Feature-Wise Non-Linear Lasso
[41]
학위논문
Correlation-based Feature Selection for Machine Learning
https://www.cs.waika[...]
University of Waikato
1999
[42]
서적
2008 23rd International Symposium on Computer and Information Sciences
2008
[43]
논문
Optimizing a class of feature selection measures
https://www.research[...]
2009-12
[44]
논문
Feature Selection via Regularized Trees
https://arxiv.org/ab[...]
2012
[45]
문서
RRF: Regularized Random Forest
[46]
학위논문
Optimisation combinatoire pour la sélection de variables en régression en grande dimension: Application en génétique animale
https://tel.archives[...]
Lille University of Science and Technology
2013-11
[47]
논문
Feature selection for high-dimensional data: a fast correlation-based filter solution
https://www.aaai.org[...]
2003-08
[48]
간행물
Choosing SNPs using feature selection.
http://htsnp.stanfor[...]
2005
[49]
논문
A novel feature ranking method for prediction of cancer stages using proteomics data
[50]
논문
Data mining and genetic algorithm based gene/SNP selection
[51]
논문
Dimension reduction and variable selection for genomic selection: application to predicting milk yield in Holsteins
[52]
논문
Selection of representative SNP sets for genome-wide association studies: A metaheuristic approach
[53]
논문
Using simulated annealing to optimize the feature selection problem in marketing applications
2006
[54]
논문
Variable Selection in Regression Models using Nonstandard Optimisation of Information Criteria
[55]
논문
Genetic algorithms as a method for variable selection in multiple linear regression and partial least squares regression, with applications to pyrolysis mass spectrometry
[56]
논문
Tabu search and binary particle swarm optimization for feature selection using microarray data
[57]
간행물
Gene Selection in Cancer Classification using PSO-SVM and GA-SVM Hybrid Algorithms.
2007
[58]
간행물
A memetic algorithm for gene selection and molecular classification of an cancer.
2009
[59]
간행물
Shotgun stochastic search for 'large p' regression
https://www.research[...]
2007
[60]
논문
Feature selection and classification for microarray data analysis: Evolutionary methods for identifying predictive genes
[61]
논문
Hybrid genetic algorithms for feature selection
[62]
논문
Genetic algorithm-based efficient feature selection for classification of pre-miRNAs
[63]
논문
Molecular classification of cancer types from microarray data using the combination of genetic algorithms and support vector machines
[64]
서적
Evolutionary Computation, Machine Learning and Data Mining in Bioinformatics. EvoBIO 2007
Springer Verlag
[65]
서적
Applications of Evolutionary Computing. EvoWorkshops 2006
[66]
논문
Genetic programming for simultaneous feature selection and classifier design
[67]
논문
Linkage disequilibrium study with a parallel adaptive GA
[68]
논문
Detection of subjects and brain regions related to Alzheimer's disease using 3D MRI scans based on eigenbrain and machine learning
2015
[69]
서적
2015 IEEE International Conference on Computer Vision (ICCV)
2015-12-01
[70]
웹사이트
Features Selection via Eigenvector Centrality
http://www.di.uniba.[...]
NFmcp2016
2016-09
[71]
논문
Wrappers for feature subset selection
https://ai.stanford.[...]
1997
[72]
arXiv
Submodular meets Spectral: Greedy Algorithms for Subset Selection, Sparse Approximation and Dictionary Selection
2011
[73]
간행물
Submodular feature selection for high-dimensional acoustic score spaces
http://melodi.ee.was[...]
2015-10-17
[74]
간행물
Submodular Attribute Selection for Action Recognition in Video
http://papers.nips.c[...]
2015-11-18
[75]
저널
Local-Learning-Based Feature Selection for High-Dimensional Data Analysis
2010
[76]
논문
A content-based recommender system for computer science publications
https://www.scienced[...]
2018
[77]
저널
Optimization of data-driven filterbank for automatic speaker verification
2020-09
[78]
서적
An Introduction to Statistical Learning
http://www-bcf.usc.e[...]
Springer
2024-04-14
[79]
인용
Feature Selection
http://link.springer[...]
Springer US
2021-07-13
[80]
저널
Nonlinear principal component analysis using autoassociative neural networks
https://aiche.online[...]
1991
[81]
저널
NEU: A Meta-Algorithm for Universal UAP-Invariant Feature Representation
http://jmlr.org/pape[...]
2021
[82]
서적
2014 IEEE Geoscience and Remote Sensing Symposium
https://ris.utwente.[...]
IEEE
2024-04-14
[83]
서적
Computer Vision – ECCV 2012
Springer
2012
[84]
저널
Universal Approximations of Invariant Maps by Neural Networks
https://doi.org/10.1[...]
2021-04-30
[85]
저널
Unscented Kalman Filtering on Riemannian Manifolds
https://doi.org/10.1[...]
2013-05-01
[86]
저널
NEU: A Meta-Algorithm for Universal UAP-Invariant Feature Representation
https://jmlr.org/pap[...]
2021-06-08
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.