Seq2seq
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
Seq2seq는 정보 이론에 기반한 시퀀스 변환 방식의 하나로, 기계 번역에 주로 사용된다. 2010년대 초에 개발되었으며, 인코더와 디코더로 구성된 신경망을 활용하여 입력 시퀀스를 다른 시퀀스로 변환한다. 구글에서 2014년에 LSTM을 사용한 seq2seq를 개발했으며, 이후 어텐션 메커니즘과 트랜스포머 아키텍처를 통해 성능이 개선되었다. 페이스북, 구글, 아마존 등에서 챗봇, 기호 적분, 언어 모델 개발에 활용되었으며, 기계 번역, 챗봇, 미분 방정식 해법 등 다양한 분야에 적용된다.

더 읽어볼만한 페이지
- 자연어 처리 - 정보 추출
정보 추출은 비정형 또는 반구조화된 텍스트에서 구조화된 정보를 자동으로 추출하는 기술로, 자연어 처리 기술을 활용하여 개체명 인식, 관계 추출 등의 작업을 수행하며 웹의 방대한 데이터에서 유용한 정보를 얻는 데 사용된다. - 자연어 처리 - 단어 의미 중의성 해소
단어 의미 중의성 해소(WSD)는 문맥 내 단어의 의미를 파악하는 계산 언어학 과제로, 다양한 접근 방식과 외부 지식 소스를 활용하여 연구되고 있으며, 다국어 및 교차 언어 WSD 등으로 발전하며 국제 경연 대회를 통해 평가된다. - 인공신경망 - 인공 뉴런
인공 뉴런은 인공신경망의 기본 요소로서, 입력 신호에 가중치를 곱하고 합산하여 활성화 함수를 거쳐 출력을 생성하며, 생물학적 뉴런을 모방하여 설계되었다. - 인공신경망 - 퍼셉트론
퍼셉트론은 프랭크 로젠블랫이 고안한 인공신경망 모델로, 입력 벡터에 가중치를 곱하고 편향을 더한 값을 활성화 함수에 통과시켜 이진 분류를 수행하는 선형 분류기 학습 알고리즘이며, 초기 신경망 연구의 중요한 모델로서 역사적 의미를 가진다. - 구글의 소프트웨어 - 구글 어시스턴트
구글 어시스턴트는 2016년 구글에서 개발한 인공지능 음성 비서 서비스로, 양방향 대화 지원, 다양한 기기 및 플랫폼 확장성, 인터넷 검색, 일정 관리, 홈 오토메이션 제어 등의 기능을 제공하지만 개인정보 보호 문제에 대한 비판도 존재한다. - 구글의 소프트웨어 - 제미니 (챗봇)
구글이 개발한 대화형 인공지능 챗봇 제미니는 챗GPT에 대응하기 위해 개발되었으며, LaMDA에서 PaLM 2를 거쳐 자체 개발한 제미니 모델로 업그레이드되었고, 현재 구글 서비스와 통합되어 정보를 제공하지만 편향성 논란도 있다.

2. 역사
Seq2seq는 정보 이론에 뿌리를 둔 기계 번역(또는 더 일반적으로, 시퀀스 변환)에 대한 접근 방식이다. 여기서 통신은 인코딩-전송-디코딩 프로세스로 이해되며, 기계 번역은 통신의 특별한 경우로 연구될 수 있다.
워렌 위버는 1947년 3월 4일 노버트 위너에게 보낸 편지에서 "번역 문제를 암호학의 문제로 간주할 수 있는지 자연스럽게 궁금해진다. 러시아어로 된 기사를 보면 '이것은 실제로 영어로 작성되었지만 이상한 기호로 코딩되었습니다. 이제 해독을 시작할 것입니다.'"라고 언급했다.[1]
2019년, 페이스북은 미분방정식의 기호 적분 및 해법에 seq2seq를 사용한다고 발표했다. 페이스북은 매스매티카, MATLAB, 메이플 (소프트웨어)과 같은 상용 솔루션보다 복잡한 방정식을 더 빠르고 정확하게 풀 수 있다고 주장했다. 먼저 표기상의 특이성을 피하기 위해 방정식을 트리 구조로 분석한 다음, LSTM 신경망은 표준 패턴 인식 기능을 적용하여 트리를 처리한다.[17]
2020년, 구글은 341GB 데이터 세트에서 훈련된 26억 개의 매개변수를 가진 seq2seq 기반 챗봇인 Meena를 출시했다. 구글은 이 챗봇이 OpenAI의 GPT-2보다 1.7배 더 큰 모델 용량을 가지고 있다고 주장했다. OpenAI의 2020년 5월 후속 버전인 1,750억 개의 매개변수를 가진 GPT-3는 필터링된 일반 텍스트 단어 45,000GB로 구성된 45TB 데이터 세트에서 570GB로 훈련되었다."[19]
2022년 아마존 (기업)은 중간 크기(200억 매개변수) seq2seq 언어 모델인 AlexaTM 20B를 출시했다. 퓨샷 학습을 달성하기 위해 인코더-디코더를 사용한다. 인코더는 입력을 다른 언어로 번역하는 등 특정 작업을 수행하기 위해 디코더가 입력으로 사용하는 입력 표현을 출력한다. 이 모델은 언어 번역 및 요약에서 훨씬 더 큰 GPT-3보다 성능이 뛰어났다. 훈련에는 노이즈 제거(문자열에 누락된 텍스트를 적절하게 삽입)와 인과 언어 모델링(의미 있게 입력 텍스트 확장)이 혼합되어 있다. 대규모 교육 워크플로우 없이도 다양한 언어에 걸쳐 기능을 추가할 수 있다. AlexaTM 20B는 모든 Flores-101 언어 쌍에 대한 몇 번의 학습 작업에서 최첨단 성능을 달성하여 여러 작업에서 GPT-3보다 뛰어난 성능을 보였다.[20]
2. 1. 초기 연구
seq2seq는 정보 이론에 뿌리를 둔 기계 번역(또는 더 일반적으로, 시퀀스 변환)에 대한 접근 방식이다. 여기서 통신은 인코딩-전송-디코딩 프로세스로 이해되며, 기계 번역은 통신의 특별한 경우로 연구될 수 있다. 이러한 관점은 예를 들어 기계 번역의 노이즈 채널 모델에서 상세하게 설명되었다.구체적으로, seq2seq는 신경망(인코더)을 사용하여 입력 시퀀스를 실수-수치 벡터로 매핑한 다음, 다른 신경망(디코더)을 사용하여 이를 다시 출력 시퀀스로 매핑한다.
인코더-디코더 시퀀스 변환의 아이디어는 2010년대 초에 개발되었다. seq2seq를 제안한 것으로 가장 일반적으로 인용되는 논문은 2014년의 두 논문이다.[3][1]
2014년에 제안된 논문에서 인코더와 디코더는 모두 LSTM이었다. 이것은 인코딩 벡터가 고정된 크기를 가지므로 "병목 현상" 문제를 야기했다. 따라서 긴 입력 시퀀스의 경우 정보가 손실되는 경향이 있는데, 이는 고정 길이 인코딩 벡터에 맞추기가 어렵기 때문이다. 같은 해 제안된 어텐션 메커니즘[4]은 병목 현상 문제를 해결했다. 이들은 자신들의 모델을 "RNNsearch"라고 불렀는데, 이는 "번역을 디코딩하는 동안 소스 문장을 검색하는 것을 에뮬레이션"하기 때문이다.
당시 seq2seq 모델의 문제점은 순환 신경망을 병렬화하기 어렵다는 것이었다. 트랜스포머의 2017년 발표[5]는 인코딩 RNN을 self-attention Transformer 블록("인코더 블록")으로, 디코딩 RNN을 cross-attention causally-masked Transformer 블록("디코더 블록")으로 대체하여 이 문제를 해결했다.
Seq2seq의 시초로 인용되는 논문 중 하나는 (Sutskever et al 2014)이며,[1] 구글의 기계 번역 프로젝트에 참여한 구글 브레인에서 발표되었다. 이 연구를 통해 구글은 2016년에 구글 번역을 구글 신경 기계 번역으로 전면 개편할 수 있었다.[1][6] 토마시 미콜로프는 구글 브레인에 합류하기 전 seq2seq 기계 번역을 포함한 여러 아이디어를 개발했다고 주장했으며, 구글 브레인에서 일리아 수츠케베르와 Quoc Le에게 이 아이디어를 언급했지만, 이들은 논문에서 그를 언급하지 않았다.[7]
미콜로프는 박사 학위 논문에서 RNNLM(언어 모델링에 RNN 사용) 연구를 진행했으며,[8] word2vec 개발로 더 유명하다.
2014년, 구글은 기계 번역에 사용하기 위해 이 알고리즘을 개발했다.[15]
초기 유사 연구로는 토마시 미콜로프의 2012년 박사 학위 논문도 있었다.[16]
2. 2. 우선순위 분쟁
이 알고리즘은 기계 번역에 사용하기 위해 구글에서 개발했다.[1]토마스 미콜로프는 구글 브레인에 합류하기 전 seq2seq 기계 번역을 포함한 여러 아이디어를 개발했다고 주장했으며, 일리아 수츠케베르와 쿽 레에게 이 아이디어를 언급했지만, 이들은 논문에서 그를 언급하지 않았다고 주장했다.[7]
2. 3. 발전 과정
seq2seq는 정보 이론에 뿌리를 둔 기계 번역(또는 더 일반적으로, 시퀀스 변환)에 대한 접근 방식이다. 여기서 통신은 인코딩-전송-디코딩 프로세스로 이해되며, 기계 번역은 통신의 특별한 경우로 연구될 수 있다. 이러한 관점은 예를 들어 기계 번역의 노이즈 채널 모델에서 상세하게 설명되었다.구체적으로, seq2seq는 신경망(인코더)을 사용하여 입력 시퀀스를 실수-수치 벡터로 매핑한 다음, 다른 신경망(디코더)을 사용하여 이를 다시 출력 시퀀스로 매핑한다.
인코더-디코더 시퀀스 변환의 아이디어는 2010년대 초에 개발되었다. seq2seq를 제안한 것으로 가장 일반적으로 인용되는 논문은 2014년의 두 논문이다.[3][1]
2014년에 제안된 논문에서 인코더와 디코더는 모두 LSTM이었다. 이것은 인코딩 벡터가 고정된 크기를 가지므로 "병목 현상" 문제를 야기했다. 따라서 긴 입력 시퀀스의 경우 정보가 손실되는 경향이 있는데, 이는 고정 길이 인코딩 벡터에 맞추기가 어렵기 때문이다. 같은 해 제안된 어텐션 메커니즘[4]은 병목 현상 문제를 해결했다. 그들은 자신들의 모델을 "RNNsearch"라고 불렀는데, 이는 "번역을 디코딩하는 동안 소스 문장을 검색하는 것을 에뮬레이션"하기 때문이다.
이 시점에서 seq2seq 모델의 문제점은 순환 신경망을 병렬화하기 어렵다는 것이었다. 트랜스포머의 2017년 발표[5]는 인코딩 RNN을 self-attention Transformer 블록("인코더 블록")으로, 디코딩 RNN을 cross-attention causally-masked Transformer 블록("디코더 블록")으로 대체하여 이 문제를 해결했다.
2014년, 구글은 기계 번역에 사용하기 위해 이 알고리즘을 개발했다.[15] 초기 유사 연구로는 토마시 미콜로프의 2012년 박사 학위 논문도 있었다.[16]
2019년, 페이스북은 미분 방정식의 기호 적분과 해법에 seq2seq를 활용한다고 발표했다. 이 회사는 Mathematica, MATLAB, Maple과 같은 시판 솔루션보다 빠르고 정확하게 복잡한 방정식을 풀 수 있다고 주장했다. 먼저, 표기상의 특이성을 제거하기 위해 방정식을 트리 구조로 분석한다. 다음으로, LSTM 신경망이 표준적인 패턴 인식 기능을 적용하여 트리를 처리한다.[17]
2020년, 구글은 seq2seq 기반의 챗봇 Meena를 출시했다. 이는 341 GB의 데이터 세트로 훈련된 26억 개의 파라미터를 가지고 있다. 구글은 이 챗봇이 OpenAI의 GPT-2보다 1.7배 큰 모델 용량을 가지며[18], 2020년 5월에 후속으로 출시된 1,750억 파라미터의 GPT-3는 "평문 단어 45 TB(45,000 GB)의 데이터 세트를 570 GB까지 압축한 것"으로 훈련되었다고 주장했다.[19]
2022년, 아마존은 중규모(200억 파라미터) seq2seq 언어 모델인 AlexaTM 20B를 발표했다. 이는 인코더-디코더를 사용하여 소수 샷 학습을 수행한다. 인코더는 입력의 표현을 출력하고, 디코더는 이를 바탕으로 다른 언어로 번역하는 등 특정 작업을 수행한다. 이 모델은 언어 번역과 요약에서 훨씬 더 큰 GPT-3보다 우수한 성능을 보였다. 훈련에서는 노이즈 감소 (문자열 중 누락된 텍스트를 적절하게 복구)와 인과 언어 모델링 (입력 텍스트의 의미 있는 확장)이 결합되었다. 이를 통해 대규모 훈련 워크플로우 없이 다양한 언어 간에 특징을 추가할 수 있다. AlexaTM 20B는 Flores-101의 모든 언어 쌍에 걸쳐 소수 샷 학습 작업으로 최첨단 성능을 달성했으며, 일부 작업에서는 GPT-3을 능가했다.[20]
3. 구조
seq2seq는 정보 이론에 뿌리를 둔 기계 번역 접근 방식으로, 통신을 인코딩-전송-디코딩 과정으로 이해한다. 기계 번역은 이러한 통신의 특별한 경우로 연구될 수 있다.[3][1]
seq2seq는 신경망(인코더)을 사용하여 입력 시퀀스를 실수-수치 벡터로 매핑한 다음, 다른 신경망(디코더)을 사용하여 이를 다시 출력 시퀀스로 매핑한다. 인코더와 디코더는 모두 LSTM으로 구성되어 있다.[3][1]
2014년에 제안된 어텐션 메커니즘[4]은 고정된 크기의 인코딩 벡터로 인해 긴 입력 시퀀스에서 정보 손실이 발생하는 "병목 현상" 문제를 해결했다.
2017년에는 트랜스포머[5]가 발표되면서 인코딩 RNN을 self-attention Transformer 블록("인코더 블록")으로, 디코딩 RNN을 cross-attention causally-masked Transformer 블록("디코더 블록")으로 대체하여 병렬화가 어려운 문제를 해결했다.
seq2seq의 주요 구성 부분은 인코더 네트워크와 디코더 네트워크 한 쌍이다. 순환 신경망(RNN)이나, 기울기 소실 문제를 피하기 위해 장단기 기억 네트워크(LSTM) 또는 게이트 순환 유닛(GRU)이 사용된다. 각 항목의 맥락에는 이전 단계의 출력이 사용된다.
3. 1. 인코더
seq2seq는 신경망을 사용하여 입력 시퀀스를 실수-수치 벡터로 매핑하는 인코더를 활용한다. 인코더-디코더 시퀀스 변환 아이디어는 2010년대 초에 개발되었다([3][1] 참조). 2014년에 발표된 논문에서 제안된 seq2seq 모델의 인코더와 디코더는 모두 LSTM이었다.[3][1]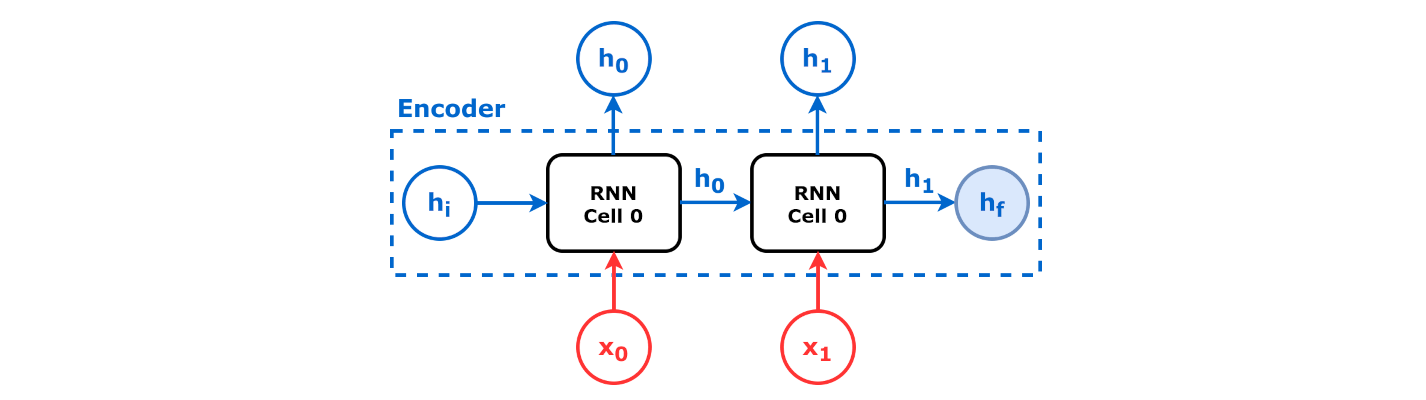
인코더는 입력 시퀀스를 처리하고 핵심 정보를 캡처하여 네트워크의 은닉 상태로 저장한다. 어텐션 메커니즘이 있는 모델에서는 컨텍스트 벡터로 저장하는데, 이는 입력 은닉 상태의 가중 합이며 출력 시퀀스의 모든 시간 인스턴스에 대해 생성된다. Seq2seq는 순환 신경망(RNN)이나, 기울기 소실 문제를 피하기 위해 장단기 기억 네트워크(LSTM) 또는 게이트 순환 유닛(GRU)을 사용하여 어떤 시퀀스를 다른 시퀀스로 변환할 수 있다. 각 항목의 맥락에는 이전 단계의 출력이 사용된다. 인코더는 각 항목을 해당 항목과 맥락을 포함한 숨겨진 벡터로 변환한다.
3. 2. 디코더
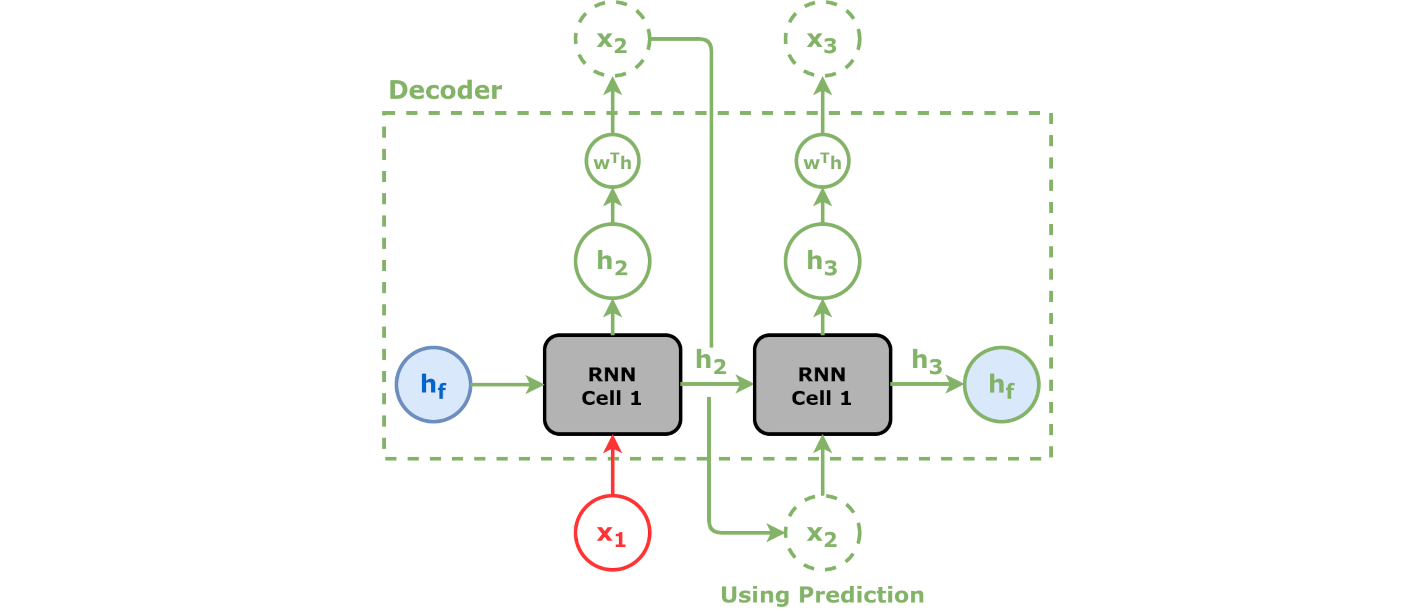
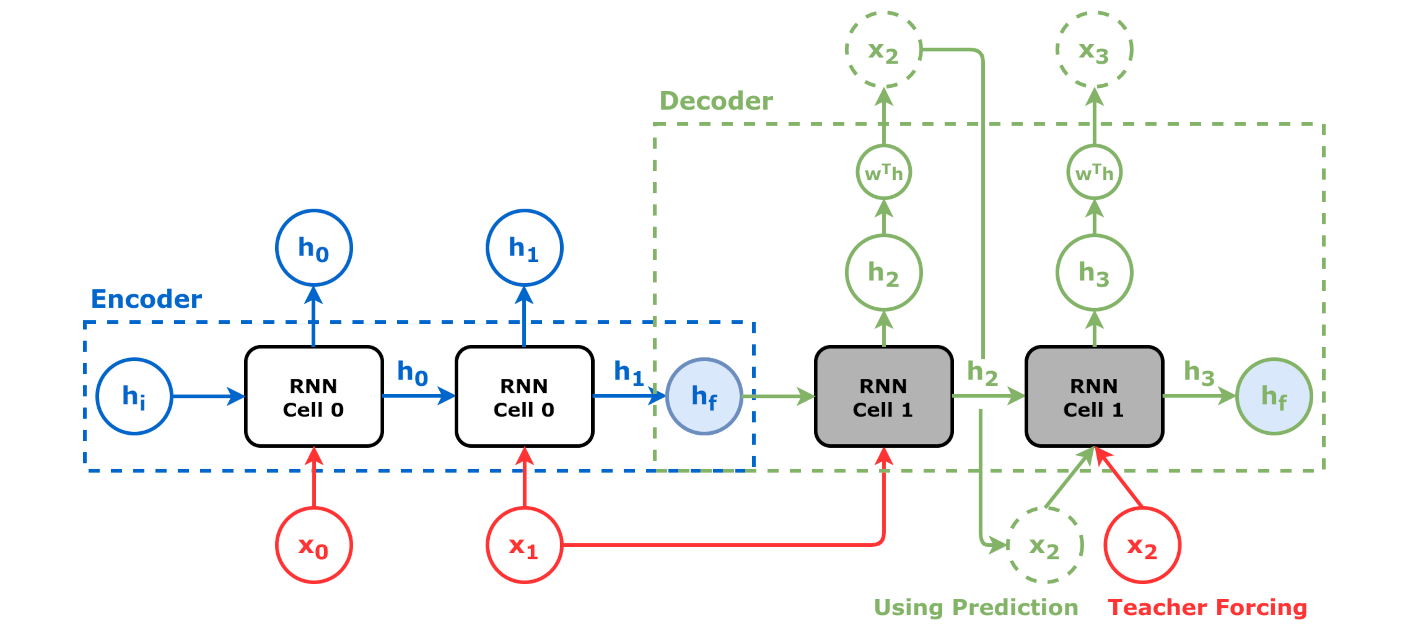
디코더는 인코더에서 나온 컨텍스트 벡터와 은닉 상태를 받아 최종 출력 시퀀스를 생성한다. 디코더는 자기 회귀 방식으로 작동하며, 한 번에 출력 시퀀스의 한 요소를 생성한다. 각 단계에서 이전에 생성된 요소, 컨텍스트 벡터 및 입력 시퀀스 정보를 고려하여 출력 시퀀스의 다음 요소를 예측한다. 구체적으로 어텐션 메커니즘이 있는 모델에서 컨텍스트 벡터와 은닉 상태가 함께 연결되어 어텐션 은닉 벡터를 형성하며, 이 벡터는 디코더의 입력으로 사용된다.
Seq2seq는 어떤 시퀀스(sequence)를 다른 시퀀스로 변환할 수 있다. 이 변환에는 순환 신경망(RNN)이나, 기울기 소실 문제를 피하기 위해 장단기 기억 네트워크(LSTM) 또는 게이트 순환 유닛(GRU)이 사용된다. 각 항목의 맥락에는 이전 단계의 출력이 사용된다. 주요 구성 부분은 인코더 네트워크와 디코더 네트워크 한 쌍이다. 인코더는 각 항목을 해당 항목과 맥락을 포함한 숨겨진 벡터로 변환한다. 디코더는 이 프로세스를 역전시켜, 이전 출력을 입력 맥락으로 사용하면서 벡터를 출력 항목으로 변환한다.
최적화 기법은 다음과 같다.
- 어텐션: 디코더에 대한 입력은 컨텍스트 전체를 저장하는 단일 벡터이다. 어텐션을 통해 디코더가 입력 시퀀스를 선택적으로 검사할 수 있다.
- 빔 서치: 출력으로 단일 단어를 선택하는 대신, 확률이 높은 몇 가지 선택 사항을 유지한 트리로 구조화한다 (어텐션 점수의 집합에 대해 소프트맥스 함수 사용). 인코더의 상태는 어텐션 분포에 의해 가중 평균된다.
- 버킷화: 입력과 출력 각각에 0을 추가하여 시퀀스의 길이를 가변적으로 만들 수 있다. 단, 시퀀스 길이가 100이고 입력 항목이 3개인 경우, 비싼 공간이 낭비된다. 버킷은 다양한 길이를 취할 수 있으며, 입력과 출력의 길이를 모두 지정할 수 있다.
훈련에서는 일반적으로 교차 엔트로피손실 함수가 사용되며, 특정 출력의 후속 출력 확률이 1 미만이 되도록 페널티가 부과된다.
3. 3. 어텐션 메커니즘
어텐션 메커니즘은 2014년 바흐다나우 등(Bahdanau et al.)이 기본적인 Seq2seq 아키텍처의 한계를 극복하기 위해 제안한 기술이다.[4] 기본적인 Seq2seq는 긴 입력 시퀀스가 들어올 때 인코더의 은닉 상태(hidden state) 출력이 디코더에 제대로 전달되지 않는 문제가 있었다. 어텐션 메커니즘은 모델이 디코딩 과정에서 입력 시퀀스의 서로 다른 부분에 선택적으로 집중할 수 있도록 하여 이 문제를 해결한다.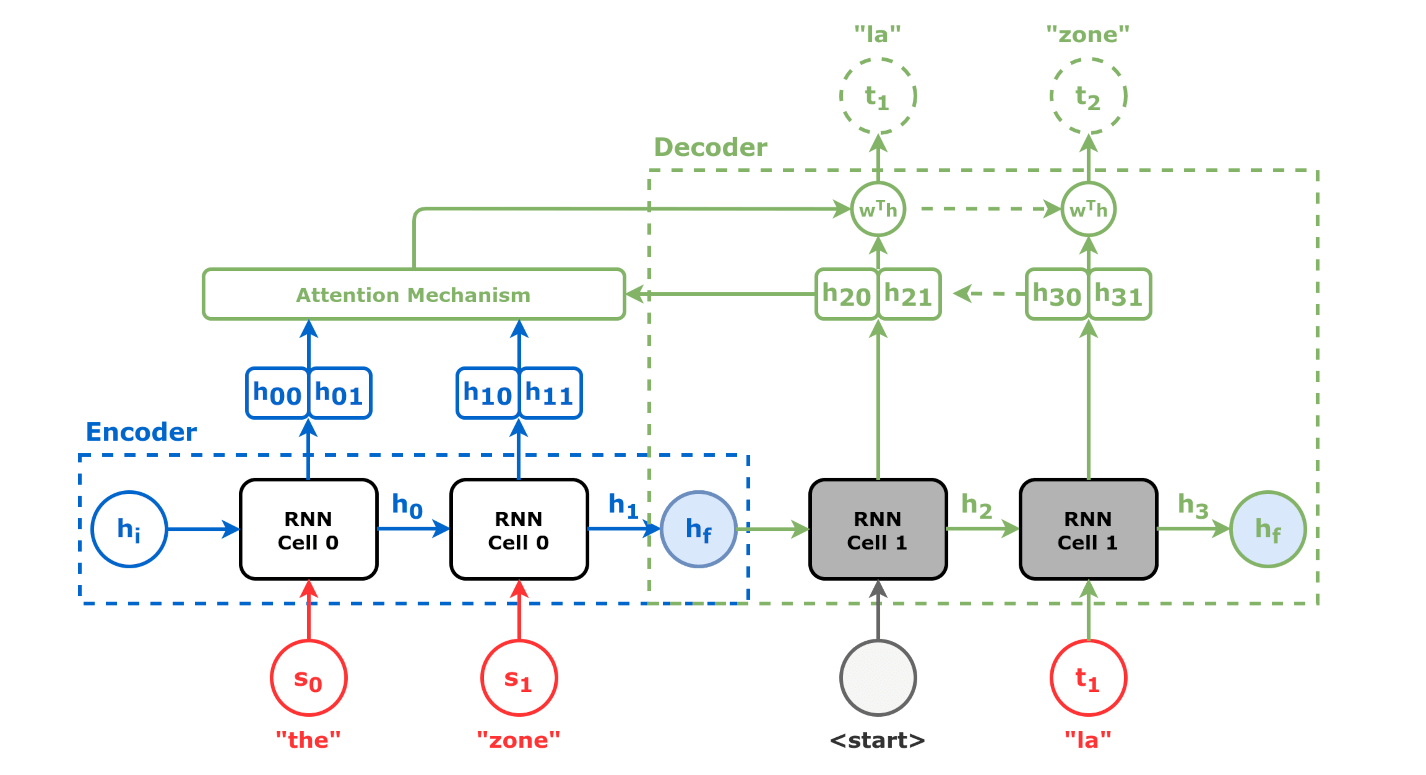
각 디코더 단계에서 정렬 모델은 현재 디코더 상태와 모든 어텐션 은닉 벡터를 입력으로 사용하여 어텐션 점수를 계산한다. 정렬 모델은 seq2seq 모델과 함께 훈련되는 또 다른 신경망 모델로, 은닉 상태로 표현된 입력이 어텐션 은닉 상태로 표현된 이전 출력과 얼마나 잘 일치하는지 계산한다. 그런 다음 소프트맥스 함수를 어텐션 점수에 적용하여 어텐션 가중치를 얻는다.[4]
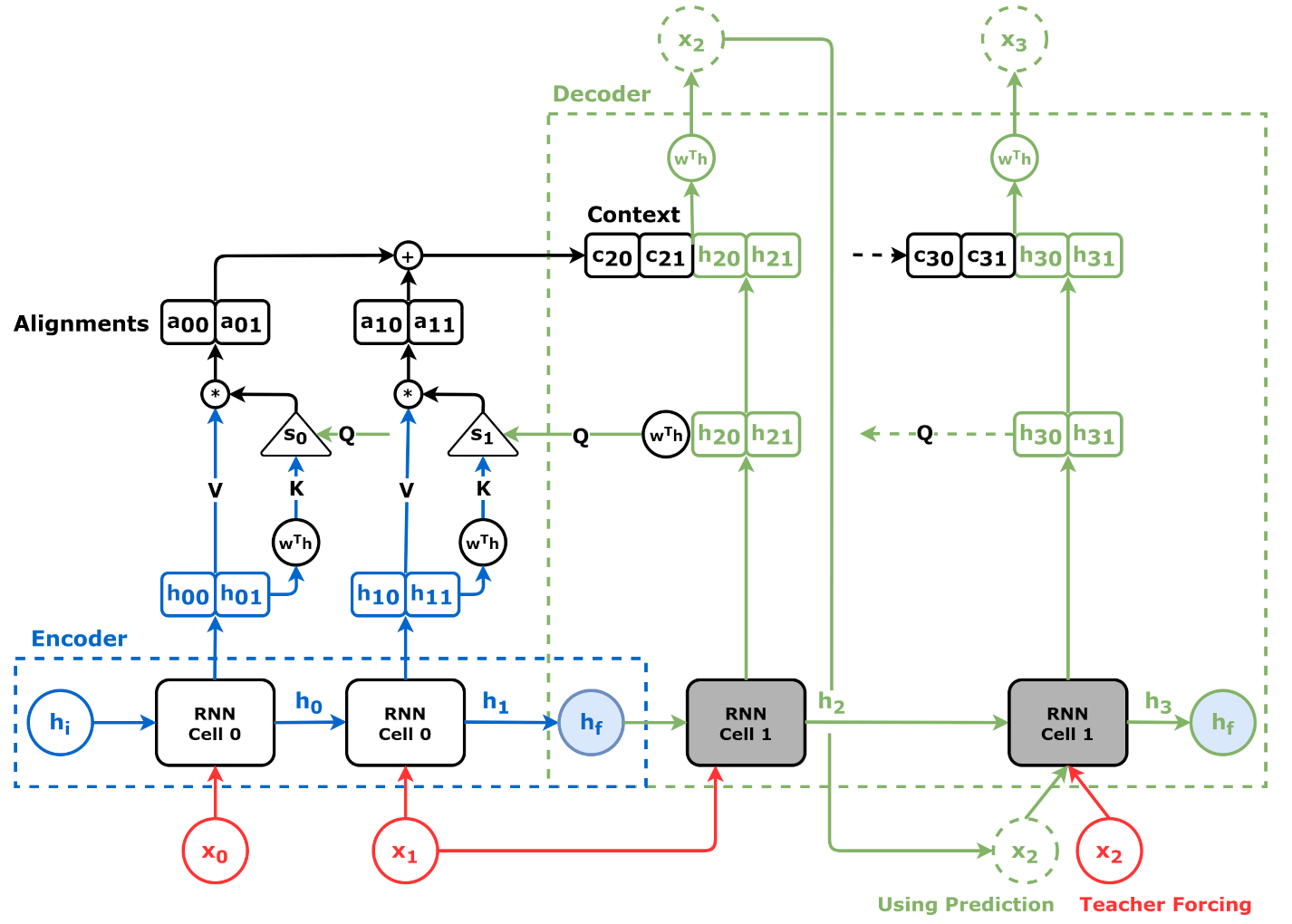
일부 모델에서는 인코더 상태가 활성화 함수에 직접 공급되어 정렬 모델이 필요하지 않게 된다. 활성화 함수는 하나의 디코더 상태와 하나의 인코더 상태를 받아들여 이들의 관련성을 나타내는 스칼라 값을 반환한다.[9]
Seq2seq는 어떤 시퀀스(sequence)를 다른 시퀀스로 변환할 수 있는데, 이 변환에는 순환 신경망(RNN)이나, 기울기 소실 문제를 피하기 위해 장단기 기억 네트워크(LSTM) 또는 게이트 순환 유닛(GRU)이 사용된다. 각 항목의 맥락에는 이전 단계의 출력이 사용된다. 주요 구성 부분은 인코더 네트워크와 디코더 네트워크 한 쌍이다. 인코더는 각 항목을 해당 항목과 맥락을 포함한 숨겨진 벡터로 변환하며, 디코더는 이 프로세스를 역전시켜 이전 출력을 입력 맥락으로 사용하면서 벡터를 출력 항목으로 변환한다.
최적화에는 다음과 같은 기법이 있다.
- 어텐션: 디코더에 대한 입력은 컨텍스트 전체를 저장하는 단일 벡터이다. 어텐션을 통해 디코더가 입력 시퀀스를 선택적으로 검사할 수 있다.
- 빔 서치: 출력으로 단일 단어를 선택하는 대신, 확률이 높은 몇 가지 선택 사항을 유지한 트리로 구조화한다 (어텐션 점수의 집합에 대해 소프트맥스 함수 사용). 인코더의 상태는 어텐션 분포에 의해 가중 평균된다.
- 버킷화: 입력과 출력 각각에 0을 추가하여 시퀀스의 길이를 가변적으로 만들 수 있다. 단, 시퀀스 길이가 100이고 입력 항목이 3개인 경우, 비싼 공간이 낭비된다. 버킷은 다양한 길이를 취할 수 있으며, 입력과 출력의 길이를 모두 지정할 수 있다.
훈련에서는 일반적으로 교차 엔트로피손실 함수가 사용되며, 특정 출력의 후속 출력 확률이 1 미만이 되도록 페널티가 부과된다.
4. 최적화 기법
Seq2seq 모델의 성능을 향상시키기 위한 최적화 기법으로는 어텐션이 있다. 어텐션은 디코더가 입력 시퀀스의 특정 부분에 집중할 수 있도록 하여, 더 정확한 출력을 생성하게 한다.
훈련에는 일반적으로 교차 엔트로피손실 함수가 사용되며, 특정 출력의 후속 출력 확률이 1 미만이 되도록 페널티가 부과된다.[1]
4. 1. 빔 서치(Beam Search)
빔 서치는 단일 단어를 선택하는 대신, 확률이 높은 몇 가지 선택 사항을 소프트맥스 함수를 사용하여 트리 구조로 유지한다. 인코더의 상태는 어텐션 분포에 의해 가중 평균된다.4. 2. 버킷화(Bucketing)
입력과 출력 각각에 0을 추가하여 시퀀스의 길이를 가변적으로 만들 수 있다. 단, 시퀀스 길이가 100이고 입력 항목이 3개인 경우, 공간이 낭비된다. 버킷은 다양한 길이를 취할 수 있으며, 입력과 출력의 길이를 모두 지정할 수 있다.[1]5. 활용 분야
Seq2seq는 다양한 분야에서 활용되고 있다.
2019년, 페이스북은 미분방정식의 기호 적분 및 해법에 이를 사용한다고 발표했다. 페이스북은 매스매티카, MATLAB, 메이플과 같은 상용 솔루션보다 복잡한 방정식을 더 빠르고 정확하게 풀 수 있다고 주장했다. 방정식을 트리 구조로 분석하고, LSTM 신경망을 사용하여 처리하는 방식이다.[10]
2020년, 구글은 341GB 데이터 세트에서 훈련된 26억 개의 매개변수를 가진 seq2seq 기반 챗봇인 미나(Meena)를 출시했다. 구글은 이 챗봇이 OpenAI의 GPT-2보다 1.7배 더 큰 모델 용량을 가지고 있다고 주장했다.[11] GPT-3는 45TB의 일반 텍스트 데이터를 570GB로 필터링하여 훈련되었다.[12]
2022년, 아마존 (기업)은 200억 개의 매개변수를 가진 seq2seq 언어 모델인 AlexaTM 20B를 출시했다. AlexaTM 20B는 인코더-디코더 구조를 사용하여 소수 샷 학습을 수행하며, 언어 번역 및 요약에서 GPT-3보다 뛰어난 성능을 보였다. 훈련에는 노이즈 감소와 인과 언어 모델링이 혼합되어 사용되었다.[13]
5. 1. 기계 번역
이 알고리즘은 구글에서 기계 번역에 사용하기 위해 개발했다.[15] 초기 유사 연구로는 토마시 미콜로프의 2012년 박사 학위 논문도 있었다.[16]seq2seq는 정보 이론에 뿌리를 둔 기계 번역(또는 더 일반적으로, 시퀀스 변환)에 대한 접근 방식으로, 여기서 통신은 인코딩-전송-디코딩 프로세스로 이해되며, 기계 번역은 통신의 특별한 경우로 연구될 수 있다. 이러한 관점은 예를 들어 기계 번역의 노이즈 채널 모델에서 상세하게 설명되었다.
구체적으로, seq2seq는 신경망(인코더)을 사용하여 입력 시퀀스를 실수-수치 벡터로 매핑한 다음, 다른 신경망(디코더)을 사용하여 이를 다시 출력 시퀀스로 매핑한다.
인코더-디코더 시퀀스 변환의 아이디어는 2010년대 초에 개발되었다(이전 논문에 대해서는 [3][1] 참조). seq2seq를 제안한 것으로 가장 일반적으로 인용되는 논문은 2014년의 두 논문이다.[3][1]
Seq2seq의 시초로 인용되는 논문 중 하나는 (Sutskever et al 2014)이며,[1] 구글의 기계 번역 프로젝트에 참여한 구글 브레인에서 발표되었다. 이 연구를 통해 구글은 2016년에 구글 번역을 구글 신경 기계 번역으로 전면 개편할 수 있었다.[1][6] Tomáš Mikolov는 구글 브레인에 합류하기 전 seq2seq 기계 번역을 포함한 여러 아이디어를 개발했다고 주장했으며, 구글 브레인에서 Ilya Sutskever와 Quoc Le에게 이 아이디어를 언급했지만, 이들은 논문에서 그를 언급하지 않았다.[7]
2019년, 페이스북은 미분 방정식의 해법에의 활용을 발표했다. 이 회사는 Mathematica, MATLAB, Maple과 같은 시판 솔루션보다 빠르고 정확하게 복잡한 방정식을 풀 수 있다고 주장했다. 먼저, 표기상의 특이성을 제거하기 위해 방정식을 트리 구조로 분석한다. 다음으로, LSTM 신경망이 표준적인 패턴 인식 기능을 적용하여 트리를 처리한다.[17]
2022년 아마존 (기업)은 중간 크기(200억 매개변수) seq2seq 언어 모델인 AlexaTM 20B를 출시했다. 퓨샷 학습을 달성하기 위해 인코더-디코더를 사용한다. 인코더는 입력을 다른 언어로 번역하는 등 특정 작업을 수행하기 위해 디코더가 입력으로 사용하는 입력 표현을 출력한다. 이 모델은 언어 번역 및 요약에서 훨씬 더 큰 GPT-3보다 성능이 뛰어났다. 훈련에는 노이즈 제거(문자열에 누락된 텍스트를 적절하게 삽입)와 인과 언어 모델링(의미 있게 입력 텍스트 확장)이 혼합되어 있다. 대규모 교육 워크플로우 없이도 다양한 언어에 걸쳐 기능을 추가할 수 있다. AlexaTM 20B는 모든 Flores-101 언어 쌍에 대한 몇 번의 학습 작업에서 최첨단 성능을 달성하여 여러 작업에서 GPT-3보다 뛰어난 성능을 보였다.[20]
5. 2. 챗봇
2020년, 구글은 341GB 데이터 세트로 훈련된 26억 개의 파라미터를 가진 seq2seq 기반 챗봇 Meena를 출시했다. 구글은 이 챗봇이 OpenAI의 GPT-2보다 1.7배 더 큰 모델 용량을 가졌다고 주장했다.[18] 2020년 5월에 후속으로 출시된 1,750억 파라미터의 GPT-3는 "평문 단어 45TB(45,000GB)의 데이터 세트를 570GB까지 압축한 것"으로 훈련되었다.[19]5. 3. 기타 응용
Seq2seq 알고리즘은 원래 기계 번역을 위해 구글에서 개발되었다.[15] 초기 유사 연구로는 토마시 미콜로프의 2012년 박사 학위 논문이 있다.[16]2019년, 페이스북은 기호 적분과 미분 방정식의 해법에 seq2seq를 사용한다고 발표했다. 페이스북은 Mathematica, MATLAB, 메이플과 같은 상용 솔루션보다 더 빠르고 정확하게 복잡한 방정식을 풀 수 있다고 주장했다. 방정식을 트리 구조로 분석하고, LSTM 신경망을 사용하여 처리하는 방식이다.[17]
2020년, 구글은 341GB 데이터 세트로 훈련된 26억 개의 매개변수를 가진 seq2seq 기반 챗봇 미나(Meena)를 출시했다. 구글은 미나가 OpenAI의 GPT-2보다 1.7배 더 큰 모델 용량을 가지고 있다고 주장했다.[18] GPT-3는 45TB의 일반 텍스트 데이터를 570GB로 필터링하여 훈련되었다.[19]
2022년, 아마존 (기업)은 200억 개의 매개변수를 가진 seq2seq 언어 모델인 AlexaTM 20B를 출시했다. AlexaTM 20B는 인코더-디코더 구조를 사용하여 소수 샷 학습을 수행하며, 언어 번역 및 요약에서 GPT-3보다 뛰어난 성능을 보였다. 훈련에는 노이즈 감소와 인과 언어 모델링이 혼합되어 사용되었다.[20]
6. 관련 소프트웨어
OpenNMTTorch (machine learning)|Torch영어, Neural Monkey(텐서플로우), NEMATUS(Theano (software)|Theano영어) 등이 유사한 기법을 사용한다.[22]
참조
[1]
논문
Sequence to sequence learning with neural networks
2014
[2]
웹사이트
seq2seq model in Machine Learning
https://www.geeksfor[...]
2019-12-17
[3]
논문
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
2014-06-03
[4]
논문
Neural Machine Translation by Jointly Learning to Align and Translate
2014
[5]
간행물
Attention is All you Need
https://proceedings.[...]
Curran Associates, Inc.
2017
[6]
논문
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
2016
[7]
웹사이트
Yesterday we received a Test of Time Award at NeurIPS for the word2vec paper from ten years ago
https://www.facebook[...]
2023-12-13
[8]
문서
Statistical language models based on neural networks.
https://www.fit.vut.[...]
[9]
웹사이트
Sequence to Sequence (seq2seq) and Attention
https://lena-voita.g[...]
2023-12-20
[10]
웹사이트
Facebook has a neural network that can do advanced math
https://www.technolo[...]
2019-12-17
[11]
웹사이트
Google claims its new chatbot Meena is the best in the world
https://thenextweb.c[...]
2020-02-03
[12]
웹사이트
What's GPT-3?
https://technically.[...]
2020-08-01
[13]
웹사이트
🤘Edge#224: AlexaTM 20B is Amazon's New Language Super Model Also Capable of Few-Shot Learning
https://thesequence.[...]
2022-09-08
[14]
논문
Sequence to sequence learning with neural networks
[15]
웹사이트
seq2seq model in Machine Learning
https://www.geeksfor[...]
2019-12-17
[16]
문서
p. 94 of https://www.fit.vut.cz/study/phd-thesis-file/283/283.pdf, https://www.fit.vut.cz/study/phd-thesis-file/283/283_o2.pdf
[17]
웹사이트
Facebook has a neural network that can do advanced math
https://www.technolo[...]
2019-12-17
[18]
웹사이트
Google claims its new chatbot Meena is the best in the world
https://thenextweb.c[...]
2020-02-03
[19]
웹사이트
What's GPT-3?
https://technically.[...]
2020-08-01
[20]
웹사이트
🤘Edge#224: AlexaTM 20B is Amazon's New Language Super Model Also Capable of Few-Shot Learning
https://thesequence.[...]
2022-09-08
[21]
웹사이트
Sequence 2 sequence Models
https://nlp.stanford[...]
2023-05-20
[22]
웹사이트
Overview - seq2seq
https://google.githu[...]
2019-12-17
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com