데이터 모델링
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
데이터 모델링은 데이터를 구조화하고 조직화하여 데이터베이스 관리 시스템에서 구현하는 과정이다. 데이터 모델은 개념 스키마, 논리 스키마, 물리 스키마의 세 가지 종류로 구분되며, ANSI 표준에 따라 각 모델은 서로 독립적인 관점을 가질 수 있다. 데이터 모델링은 업무 프로세스 통합의 맥락에서 데이터베이스 설계의 핵심적인 부분이며, 하향식, 상향식, 혼합형 등 다양한 방법론이 존재한다. 데이터 모델링 기법에는 개체-관계 모델, 바흐만 다이어그램 등 여러 가지가 있으며, 범용 데이터 모델과 의미 데이터 모델과 같은 특정 모델링 접근 방식도 있다. 데이터 모델링은 시스템 인터페이스 비용 절감, 데이터 공유 촉진, 데이터베이스 통합 등 다양한 측면에서 중요성을 가진다.

더 읽어볼만한 페이지
- 소프트웨어 개발 - 컴퓨터 과학
컴퓨터 과학은 컴퓨터와 관련된 현상을 연구하는 학문으로, 계산 이론, 하드웨어 및 소프트웨어 설계, 문제 해결 등을 포괄하며, 수학, 공학 등 여러 분야와 융합하여 발전해 왔다. - 소프트웨어 개발 - 스파이웨어
스파이웨어는 사용자의 동의 없이 설치되어 개인 정보를 수집하거나 시스템을 감시하며, 다양한 형태로 존재하여 광고 표시, 정보 탈취, 시스템 성능 저하 등의 피해를 유발하는 악성 프로그램이다. - 데이터 모델링 - 빌딩 정보 모델링
빌딩 정보 모델링(BIM)은 건축물의 전 생애주기 동안 발생하는 정보를 디지털 모델로 통합 관리하는 프로세스이다. - 데이터 모델링 - 저장 프로시저
저장 프로시저는 데이터베이스 관리 시스템에서 SQL 문들을 미리 컴파일하여 저장하고, 모듈화, 보안성, 성능 향상, 유지보수 용이성과 같은 특징을 가지며, 데이터베이스 시스템마다 구현 방식과 지원하는 언어가 다를 수 있는 코드 묶음이다. - 컴퓨터에 관한 - 고속 패킷 접속
고속 패킷 접속(HSPA)은 3세대 이동통신(3G)의 데이터 전송 속도를 높이는 기술 집합체로, 고속 하향/상향 패킷 접속(HSDPA/HSUPA)을 통해 속도를 개선하고 다중 안테나, 고차 변조, 다중 주파수 대역 활용 등의 기술로 진화했으나, LTE 및 5G 기술 발전으로 현재는 상용 서비스가 중단되었다. - 컴퓨터에 관한 - 데이터베이스
데이터베이스는 여러 사용자가 공유하고 사용하는 정보의 집합으로, 데이터베이스 관리 시스템을 통해 접근하며, 검색 및 갱신 효율을 높이기 위해 고도로 구조화되어 있고, 관계형, NoSQL, NewSQL 등 다양한 모델로 발전해왔다.
2. 데이터 모델의 종류

데이터 모델은 정보 시스템 내에서 데이터를 사용하기 위한 프레임워크를 제공하며, 정의와 형식을 명확히 한다. 시스템 전반에 걸쳐 데이터 모델이 일관되게 사용되면 데이터 호환성이 확보된다. 동일한 데이터 구조를 사용하여 데이터를 저장하고 접근하면 서로 다른 애플리케이션 간에 데이터를 원활하게 공유할 수 있다.[4]
하지만, 시스템과 인터페이스 구축, 운영, 유지 보수에 많은 비용이 소요될 수 있으며, 데이터 모델의 품질이 좋지 않으면 오히려 비즈니스를 지원하는 데 제약이 될 수 있다.[4]
일반적인 데이터 모델 문제점은 다음과 같다:
- 특정 장소에서의 업무 처리 방식에 따라 비즈니스 규칙이 데이터 모델 구조에 고정될 수 있다. 이 경우, 비즈니스 운영 방식의 작은 변화가 시스템 및 인터페이스의 큰 변화를 야기할 수 있다. 따라서 비즈니스 규칙은 유연하게 구현되어야 하며, 데이터 모델은 비즈니스 변화에 빠르고 효율적으로 대응할 수 있도록 유연해야 한다.
- 엔티티 유형이 식별되지 않거나 잘못 식별되면 데이터, 데이터 구조, 기능이 중복될 수 있으며, 이는 개발 및 유지 관리 비용 증가로 이어진다. 오류 해석 및 중복을 최소화하기 위해 데이터 정의는 명확하고 이해하기 쉬워야 한다.
- 서로 다른 시스템의 데이터 모델이 다르면 데이터를 공유하는 시스템 간에 복잡한 인터페이스가 필요하게 된다. 이러한 인터페이스는 시스템 비용의 상당 부분을 차지할 수 있다. 데이터 모델 설계 시 필요한 인터페이스를 고려해야 한다.
- 데이터 구조와 의미가 표준화되지 않으면 고객 및 공급업체와 전자적으로 데이터를 공유하기 어렵다. 데이터 모델이 비즈니스 요구 사항을 충족하고 일관성을 유지하도록 표준을 정의하는 것이 중요하다.[4]
ANSI에 따르면, 데이터 모델의 인스턴스에는 개념 스키마, 논리 스키마, 물리 스키마의 세 가지 종류가 있다.[5]
- 개념 스키마: 모델링 대상 영역의 의미를 기술한다. 조직이나 산업의 특정 측면을 모델링할 수 있으며, 엔티티 클래스와 관계 집합으로 구성된다.
- 논리 스키마: 데이터를 처리하기 위한 기술(관계 모델 등)을 사용하여 모델링 대상 영역의 의미를 표현한다. 관계(테이블)와 속성(열), 객체 지향에서의 클래스, XML의 요소(태그)와 속성 등으로 구성된다.
- 물리 스키마: 데이터가 영속화되는 물리적인 방법을 기술한다. 파티션, CPU, 테이블 공간 등과 관련이 있다.
ANSI 방식에서는 세 가지 관점의 각 모델이 서로 어느 정도 독립적이다. 예를 들어 논리 스키마에서의 변경이 개념 모델에 반드시 영향을 주지 않을 수 있다. 실제로는 스키마의 구조가 다른 스키마에 대해 일관성을 유지해야 하며, 논리 스키마는 궁극적으로 개념 모델의 구조적 목표를 만족시켜야 한다.
대부분의 소프트웨어 개발 프로젝트 초기 소프트웨어 개발 공정에서는 개념 데이터 모델 설계가 중요하며, 이후 논리 데이터 모델, 물리 데이터 모델 순으로 상세화되거나, 개념 모델을 직접 구현하기도 한다.
2. 1. 개념 스키마 (Conceptual Schema)
데이터 모델링에서 개념 스키마는 도메인(모델의 범위)의 의미를 설명하는 것으로, 조직이나 산업의 관심 영역 모델일 수 있다. 이는 도메인에서 중요한 것들의 종류를 나타내는 엔티티 클래스와 엔티티 클래스 쌍 사이의 연관성에 대한 관계 서술로 구성된다. 개념 스키마는 모델을 사용하여 표현할 수 있는 사실이나 명제의 종류를 지정하며, 데이터 요구 사항을 구성하는 첫 번째 단계이다.[1]1975년 ANSI는 세 가지 종류의 데이터 모델 스키마를 설명했는데,[5] 그 중 개념 스키마는 다음과 같다.
- 개념 스키마: 도메인의 의미를 설명하며, 엔티티 클래스와 관계 서술로 구성된다. 이는 모델을 통해 표현 가능한 사실이나 명제의 종류를 지정한다.
개념 스키마는 데이터 요구사항을 구성하는 첫 단계이며, 비즈니스 이해관계자와 초기 요구사항을 논의하는 데 사용된다.[1] 이후 논리적 데이터 모델로 변환되어 데이터베이스에 구현할 수 있는 데이터 구조를 문서화한다.[1]

ANSI 방식에 따르면, 개념 스키마, 논리 스키마, 물리 스키마의 세 가지 관점은 서로 상대적으로 독립적일 수 있다. 저장 기술이나 테이블/열 구조가 변경되어도 개념 스키마에는 반드시 영향을 미치지 않을 수 있다. 물론 각 스키마의 구조는 일관성을 유지해야 한다.[5]
많은 소프트웨어 개발 프로젝트 초기 개발 공정에서 개념 데이터 모델 설계가 중요하며,[3] 이후 논리 데이터 모델 형태로 상세화되거나, 경우에 따라 직접 구현될 수도 있다.
개념 데이터 모델은 대상 영역의 의미론적 측면을 기술하며, 실체 클래스 집합을 표현한다. 이 실체 클래스는 대상 조직이 관리하는 정보와 정보의 속성, 실체 간의 관계, 속성 간의 관계를 나타낸다. 데이터 모델은 데이터를 컴퓨터 시스템에서 표현하는 방법과는 관계없이 데이터를 조직화하여 기술한다.
견고한 데이터 모델에서는 실체의 추상화를 식별하는 경우가 많다. 예를 들어, "인물"이라는 실체 클래스는 조직과 상호 작용하는 모든 인물을 포괄적으로 표현할 수 있으며, 이는 "판매자"나 "직원"과 같은 특정 역할을 나타내는 실체 클래스보다 더 적절할 수 있다.
개념 데이터 모델을 설계할 때는 트랜잭션 데이터와 참조 데이터를 구분하는 것이 유용할 수 있다. 트랜잭션 데이터는 하나 이상의 참조 데이터를 참조하는 데이터를 말한다.
적절하게 설계된 개념 데이터 모델은 대상 영역의 의미론적 측면을 기술하며, 자연어 단어를 사용하여 이름을 지을 수 있는 실체 클래스 집합과 대상 영역에 대한 구체적인 진술을 생성하는 관계 집합으로 구성된다.
관계에는 여러 종류가 있으며, 예를 들어 "—로 구성됨" 관계는 "주문" 실체 클래스와 "주문 명세" 실체 클래스 간의 관계를 정의하여, 각 "주문"이 하나 이상의 "주문 명세"로 구성될 수 있거나 구성되어야 함을 나타낸다.
2. 2. 논리 스키마 (Logical Schema)
논리 스키마는 특정 정보 도메인의 구조를 설명한다. 예를 들어 테이블, 열, 객체 지향 클래스, XML 태그 등에 대한 설명으로 구성된다. 논리 스키마와 개념 스키마는 때때로 동일하게 구현되기도 한다.논리 스키마(데이터 모델)는 모델링 대상 영역의 의미를 데이터를 처리하기 위한 특정 기술을 사용하여 표현한 것이다. 논리 스키마는 관계 모델에서의 관계(테이블)와 속성(열) 또는 객체 지향에서의 클래스, XML의 요소(태그)와 속성 등으로 구성된다.
ANSI 방식에서 중요한 점은, 세 가지 관점(개념, 논리, 물리)의 각 모델이 서로 어느 정도 독립적이라는 것이다. 논리 스키마에서의 관계(테이블)와 속성(열)은 개념 모델에 반드시 영향을 주지 않고 변경할 수 있다. 물론, 실제로는 스키마의 구조가 다른 스키마에 대해 일관성을 유지해야 한다.
논리 스키마에서의 관계(테이블)와 속성(열)은 개념 스키마에서의 엔티티 클래스와 속성을 직접적으로 변환한 결과와 다를 수 있다. 하지만 논리 스키마는 궁극적으로 개념 모델의 엔티티 클래스 구조의 목표를 만족시켜야 한다.
많은 소프트웨어 개발 프로젝트 초기 개발 공정에서는 개념 데이터 모델 설계가 중요하다. 이후 공정에서 개념 데이터 모델은 논리 데이터 모델 형태로 상세화될 수 있다. 경우에 따라 논리 데이터 모델은 물리 데이터 모델로 변환되지만, 개념 모델을 직접 구현할 수도 있다.
개별 사례에서는 세부적으로 다를 수 있지만, 모델 인스턴스의 구조는 다른 모델 인스턴스와 일치해야 한다. 논리 데이터 모델에서의 관계(테이블)와 속성(열)의 구조는 개념 데이터 모델에서의 엔티티 클래스와 관계 및 속성을 직접적으로 변환한 것과 다를 수 있다. 하지만 논리 데이터 모델은 궁극적으로 컨텍스트 수준의 데이터 모델에서의 엔티티 클래스 구조와 개념 데이터 모델에서의 관계 구조의 각 목표를 만족시켜야 한다.
논리 데이터 모델이 생성된 후, 데이터를 저장하는 플랫폼이 결정되면 논리 데이터 모델을 물리 데이터 모델로 변환할 수 있다. 그리고 물리 데이터 모델을 기반으로 데이터 정의가 만들어진다. 데이터베이스에 실제로 데이터가 저장되어 운영되면 데이터베이스에 대한 데이터 조작(조회, 갱신 등)을 수행할 수 있다.
2. 3. 물리 스키마 (Physical Schema)
물리 스키마는 데이터를 저장하는 데 사용되는 물리적 수단을 설명한다. 여기에는 파티션, CPU, 테이블스페이스 등이 포함된다.[5]ANSI에 따르면, 이러한 접근 방식을 통해 세 가지 관점(개념 스키마, 논리 스키마, 물리 스키마)은 서로 상대적으로 독립적일 수 있다. 저장 기술이 변경되어도 논리 스키마나 개념 스키마에는 영향을 미치지 않는다. 테이블/열 구조가 변경되어도 개념 스키마에는 영향을 미치지 않을 수 있다. 물론 각 경우에 동일한 데이터 모델의 모든 스키마에서 구조가 일관성을 유지해야 한다.[4]
물리 스키마(데이터 모델)는 데이터가 영속화되는 물리적인 방법을 기술한 것이다. 물리 스키마는 파티션, CPU, 테이블 공간 등과 관련이 있다.[5]
ANSI 방식에서 중요한 것은, 앞서 설명한 세 가지 관점의 각 모델이 서로 어느 정도 독립적이라는 점이다. 논리 스키마에서의 관계(테이블)와 속성(열)은 개념 모델에 반드시 영향을 주지 않고 변경할 수 있다. 실제로는 당연히 스키마의 구조는 다른 스키마에 대해 일관성을 유지해야 한다. 논리 스키마에서의 관계(테이블)와 속성(열)은 개념 모델에서의 엔티티 클래스와 속성을 직접적으로 변환한 결과와 다를 수 있다. 하지만 논리 스키마는 궁극적으로 개념 모델의 엔티티 클래스 구조의 목표를 만족시켜야 한다.
많은 소프트웨어 개발 프로젝트 초기 개발 공정에서는 개념 데이터 모델 설계가 중요하다. 다음 공정에서 개념 데이터 모델은 논리 데이터 모델 형태로 상세화할 수 있다. 그 이후 공정에서 경우에 따라 논리 데이터 모델은 물리 데이터 모델로 변환된다. 하지만 경우에 따라 개념 모델을 직접 구현할 수도 있다.
개별 사례에서는 세부적으로 다를 수 있지만, 모델 인스턴스의 구조는 다른 모델 인스턴스와 일치해야 한다. 논리 데이터 모델에서의 관계(테이블)와 속성(열)의 구조는 개념 데이터 모델에서의 엔티티 클래스와 관계 및 속성을 직접적으로 변환한 것과 다를 수 있다. 하지만 논리 데이터 모델은 궁극적으로 컨텍스트 수준의 데이터 모델에서의 엔티티 클래스 구조와 개념 데이터 모델에서의 관계 구조의 각 목표를 만족시켜야 한다. 논리 데이터 모델이 생성된 후, 공정에서는 데이터를 저장하는 플랫폼이 결정되면 논리 데이터 모델을 물리 데이터 모델로 변환할 수 있다. 그리고 물리 데이터 모델을 기반으로 데이터의 정의가 만들어진다. 데이터베이스에 실제로 데이터가 저장되어 운영되면, 데이터베이스에 대한 데이터 조작(조회, 갱신 등)을 수행할 수 있다.
3. 데이터 모델링 과정
데이터 모델링은 조직 내 정보 시스템에서 비즈니스 프로세스를 지원하는 데 필요한 데이터 요구 사항을 정의하고 분석하는 프로세스이다.[1] 전문 데이터 모델러는 비즈니스 이해관계자 및 정보 시스템의 잠재적 사용자와 긴밀히 협력하여 데이터 모델을 만든다.
데이터 모델링 과정에는 세 가지 유형의 데이터 모델이 생성된다.[1]
데이터 모델링은 데이터 요소뿐만 아니라 해당 구조와 요소 간의 관계도 정의한다.[2]
데이터 모델링 기법과 방법론은 데이터를 자원으로 관리하기 위해 표준적이고 일관되며 예측 가능한 방식으로 데이터를 모델링하는 데 사용된다. 조직 내에서 데이터를 정의하고 분석하는 표준 수단이 필요한 모든 프로젝트에 데이터 모델링 표준 사용을 강력히 권장한다. 데이터 모델링은 다음과 같은 경우에 사용된다.
- 비즈니스 분석가, 프로그래머, 테스터 등 다양한 관계자들이 조직의 개념과 상호 관계를 이해하고 사용하도록 돕는다.
- 데이터를 자원으로 관리한다.
- 정보 시스템을 통합한다.
- 데이터베이스/데이터 웨어하우스(데이터 저장소)를 설계한다.
데이터 모델은 점진적이며, 비즈니스 또는 애플리케이션에 대한 최종 데이터 모델은 없다. 대신 데이터 모델은 변화하는 비즈니스에 따라 변경되는 실시간 문서로 간주되어야 한다. 이상적으로 데이터 모델은 저장소에 저장되어 시간이 지남에 따라 검색, 확장 및 편집할 수 있어야 한다. Whitten 외(2004)는 두 가지 유형의 데이터 모델링을 제시했다.[3]
- 전략적 데이터 모델링: 정보 시스템에 대한 전반적인 비전과 아키텍처를 정의하는 정보 시스템 전략 생성의 일부이다.
- 시스템 분석 중 데이터 모델링: 시스템 분석에서 새로운 데이터베이스 개발의 일부로 논리적 데이터 모델을 생성한다.
데이터 모델링은 특정 데이터베이스에 대한 비즈니스 요구 사항을 자세히 설명하는 기법으로도 사용되며, 데이터 모델이 결국 데이터베이스에 구현되기 때문에 ''데이터베이스 모델링''이라고도 한다.[3]

업무 프로세스 통합의 맥락에서 데이터 모델링은 업무 프로세스 모델링을 보완하며, 궁극적으로 데이터베이스 생성으로 이어진다.[6]
데이터베이스 설계 과정에는 개념적, 논리적, 물리적 스키마를 생성하는 작업이 포함된다. 이러한 스키마에 문서화된 데이터베이스 설계는 데이터 정의 언어를 통해 변환되며, 이를 사용하여 데이터베이스를 생성할 수 있다. 완전한 속성을 가진 데이터 모델에는 그 안에 있는 모든 엔티티에 대한 자세한 속성(설명)이 포함된다. "데이터베이스 설계"라는 용어는 전체 데이터베이스 시스템 설계의 여러 부분을 설명할 수 있다. 주로, 그리고 가장 정확하게는 데이터를 저장하는 데 사용되는 기본 데이터 구조의 논리적 설계로 생각할 수 있다. 관계형 모델에서 이는 테이블과 뷰이다. 객체 데이터베이스에서는 엔티티와 관계가 객체 클래스와 명명된 관계에 직접 매핑된다.
시스템 인터페이스는 현재 시스템의 개발 및 지원 비용의 25%에서 70%를 차지한다.[4] 이러한 비용의 주된 이유는 이러한 시스템이 공통 데이터 모델을 공유하지 않기 때문이다. 효율적으로 설계된 기본 데이터 모델은 조직 내의 다양한 시스템의 목적을 위해 최소한의 수정으로 재작업을 최소화할 수 있다.[4]
데이터 모델은 대상 영역의 데이터 구조를 기술하고, 결과적으로 그 영역 자체의 기반 구조를 기술한다. 데이터 모델은 실체 클래스(사물의 종류)의 집합을 표현한다. 대상 조직은 실체 클래스 집합에 대해 정보와 정보의 속성, 실체 간의 관계, 속성 간의 관계를 보유하고 관리하려고 한다. 데이터 모델은 데이터를 컴퓨터 시스템에서 표현하는 방법과는 거의 관계없이 데이터를 조직화하여 기술한다.
견고한 데이터 모델에서는 추상화를 통해 실체 클래스를 정의하기도 한다. 예를 들어, "인물"이라는 실체 클래스는 조직과 상호작용하는 모든 인물을 포괄적으로 표현할 수 있으며, "판매자"나 "직원"과 같이 특정 역할을 구체적으로 나타내는 실체 클래스보다 변경에 더 유연하게 대응할 수 있다.
일부 사람들은 데이터 모델을 설계하는 것은 트랜잭션 데이터와 참조 데이터를 구분하는 데 유용하다고 생각한다. 여기서 트랜잭션 데이터는 하나 이상의 참조 데이터를 참조하는 데이터를 말한다.
개념 데이터 모델은 대상 영역의 의미를 담고 있으며, 실체 클래스와 관계 집합은 자연어 단어로 이름을 짓고 대상 영역에 대한 구체적인 진술을 생성한다.
관계에는 여러 종류가 있으며, 관계의 이름은 전치사, 동명사, 분사, 동사 등을 사용하여 단방향으로 읽을 수 있도록 구성한다. 예를 들어, "—로 구성됨" 관계는 "주문" 실체 클래스와 "주문 명세" 실체 클래스를 연결하여 "각각의 '주문'은 하나 이상의 '주문 명세' '로 구성될 수 있음'" 또는 "각각의 '주문'은 하나 이상의 '주문 명세' '로 구성되어야 함'"과 같은 문장을 생성한다.
4. 데이터 모델링 방법론
렌 실버스톤(Len Silverston)에 따르면(1997), 데이터 모델을 만드는 방법에는 상향식과 하향식 두 가지가 있다.[7]
- 상향식 모델링: 해당 분야를 잘 아는 사람들로부터 정보를 얻어 추상적인 방식으로 생성되는 논리 데이터 모델이다. 시스템이 논리 모델의 모든 엔티티를 구현하지는 않을 수 있지만, 모델은 참조 지점이나 템플릿 역할을 한다.
- 하향식 모델링: 재구축 작업의 결과로, 기존의 데이터 구조 양식, 응용 프로그램 화면의 필드, 보고서에서 시작한다. 이 모델은 물리적이고 응용 프로그램 특정적이며, 엔터프라이즈 관점에서 불완전하여 조직의 다른 부분을 참조하지 않으면 데이터 공유를 촉진하지 못할 수 있다.
- 혼합형 모델링: 응용 프로그램의 데이터 요구 사항과 구조를 고려하고 주제 영역 모델을 일관되게 참조하여 상향식과 하향식 두 가지 방법을 혼합하여 모델을 만들기도 한다.
많은 환경에서 논리 데이터 모델과 물리적 데이터 모델의 차이가 모호하다. 또한 일부 CASE 도구는 논리 및 물리적 데이터 모델 간의 차이를 구분하지 않는다.[7]
데이터 모델링의 다른 방법론으로는, 자율적으로 데이터의 암묵적인 모델을 생성하는 인공 신경망과 같은 적응형 시스템을 사용하는 방법론이 있다.
데이터 모델링을 위한 여러 기법(방법론)들이 개발되어 왔으며, 이러한 기법들은 데이터 모델링 작업자들이 작업하는 데 있어 길잡이 역할을 한다. 하지만 두 사람이 같은 데이터 모델링 기법을 채택하더라도, 매우 다른 데이터 모델을 설계하는 결과가 되는 경우가 종종 있다. 주요 기법들은 다음과 같다.
4. 1. 상향식 (Bottom-up) 모델링
렌 실버스톤(Len Silverston)에 따르면[7] 상향식 모델은 해당 분야를 잘 아는 사람들로부터 정보를 얻어 추상적인 방식으로 생성되는 논리 데이터 모델이다. 시스템이 논리 모델의 모든 엔티티를 구현하지는 않을 수 있지만, 모델은 참조 지점이나 템플릿 역할을 한다.[7]때로는 응용 프로그램의 데이터 요구 사항과 구조를 고려하고 주제 영역 모델을 일관되게 참조하여 두 가지 방법을 혼합하여 모델을 만들기도 한다. 많은 환경에서 논리 데이터 모델과 물리적 데이터 모델의 차이가 모호하며, 일부 CASE 도구는 논리 및 물리적 데이터 모델 간의 차이를 구분하지 않는다.[7]
4. 2. 하향식 (Top-down) 모델링
하향식 모델은 종종 재구축 작업의 결과이다. 이러한 모델은 일반적으로 기존의 데이터 구조 양식, 응용 프로그램 화면의 필드, 또는 보고서에서 시작한다. 이러한 모델은 보통 물리적이며, 응용 프로그램 특정적이고, 엔터프라이즈 관점에서 불완전하다. 특히 조직의 다른 부분을 참조하지 않고 작성된 경우 데이터 공유를 촉진하지 못할 수 있다.[7]4. 3. 혼합형 (Hybrid) 모델링
렌 실버스톤(Len Silverston)에 따르면(1997), 데이터 모델을 만드는 방법에는 상향식과 하향식 두 가지가 있다.[7] 이 두 가지 방법을 혼합하여 모델을 만들기도 한다. 많은 환경에서 논리 데이터 모델과 물리적 데이터 모델의 차이가 모호하며, 일부 CASE 도구는 이 둘 간의 차이를 구분하지 않는다.[7]- 하향식 모델: 재구축 작업의 결과로 나타나며, 기존 데이터 구조, 응용 프로그램 화면의 필드, 보고서에서 시작한다. 이 모델은 물리적이고 응용 프로그램 특정적이며, 엔터프라이즈 관점에서 불완전하여 조직의 다른 부분을 참조하지 않으면 데이터 공유를 촉진하지 못할 수 있다.[7]
- 상향식 모델: 논리 데이터 모델은 해당 분야를 잘 아는 사람들로부터 정보를 얻어 추상적인 방식으로 생성된다. 시스템이 논리 모델의 모든 엔티티를 구현하지 않을 수 있지만, 모델은 참조 지점이나 템플릿 역할을 한다.[7]
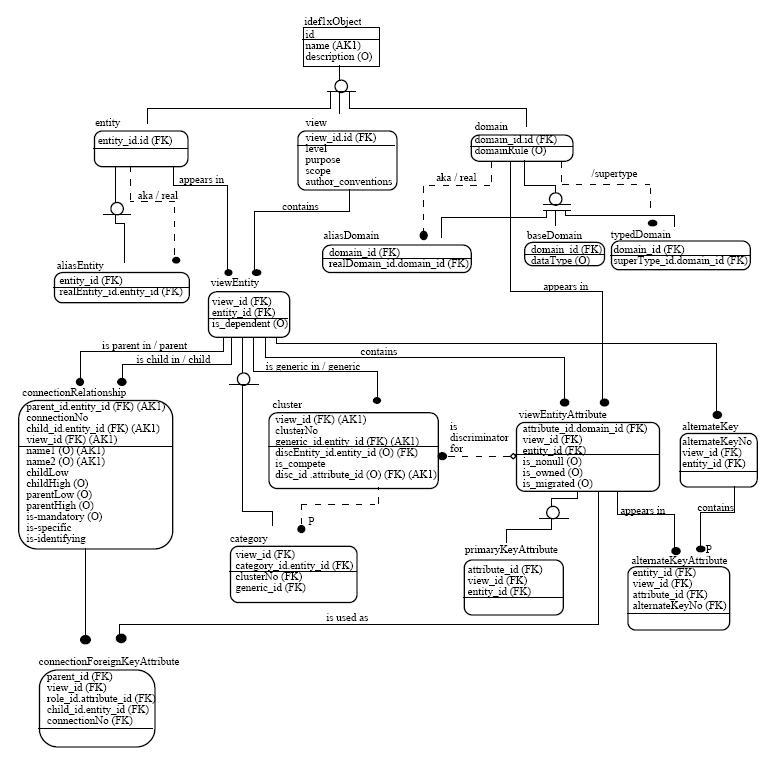
5. 데이터 모델링 기법
데이터 모델링에는 여러 가지 표기법이 있다. 실제 모델은 종종 "개체-관계 모델"이라고 불리는데, 이는 데이터에 설명된 개체와 관계라는 용어로 데이터를 묘사하기 때문이다.[3] 개체-관계 모델(ERM)은 구조화된 데이터의 추상적인 개념적 표현이다. 개체-관계 모델링은 관계형 스키마 데이터베이스 모델링 방법으로, 소프트웨어 공학에서 시스템(종종 관계형 데이터베이스) 및 요구 사항의 일종의 개념 데이터 모델(또는 의미 데이터 모델)을 상향식 방식으로 생성하는 데 사용된다.
이러한 모델은 정보 시스템 설계의 첫 번째 단계에서 요구 사항 분석 중에 정보 요구 사항 또는 데이터베이스에 저장될 정보의 유형을 설명하는 데 사용된다. 데이터 모델링 기법은 특정 담화 세계, 즉 관심 영역에 대한 모든 온톨로지(즉, 사용된 용어 및 관계에 대한 개요 및 분류)를 설명하는 데 사용할 수 있다.
데이터 모델 설계를 위해 여러 가지 기법이 개발되었다. 이러한 방법론은 데이터 모델러의 작업을 안내하지만, 동일한 방법론을 사용하는 두 명의 사람이 서로 매우 다른 결과를 얻는 경우가 많다. 가장 주목할 만한 것은 다음과 같다.
6. 데이터 모델링의 중요성
데이터 모델은 정보 시스템 내에서 데이터를 사용하기 위한 프레임워크를 제공하며, 특정 정의와 형식을 제공한다.[4] 시스템 전반에 걸쳐 데이터 모델이 일관되게 사용되면 데이터 호환성을 확보할 수 있다. 동일한 데이터 구조를 사용하여 데이터를 저장하고 접근하면 서로 다른 애플리케이션 간에 데이터를 원활하게 공유할 수 있다.[4]
하지만, 데이터 모델의 품질이 좋지 않으면 시스템과 인터페이스 구축, 운영 및 유지 관리에 많은 비용이 들고, 비즈니스를 지원하는 대신 제약을 가할 수 있다.[4]
데이터 모델에서 흔히 발견되는 몇 가지 문제는 다음과 같다.
- 비즈니스 규칙이 데이터 모델 구조에 고정되어, 비즈니스 운영 방식의 작은 변화가 시스템 및 인터페이스의 큰 변화를 초래할 수 있다. 따라서 비즈니스 규칙은 유연하게 구현되어야 하며, 데이터 모델은 비즈니스 변화에 빠르고 효율적으로 대응할 수 있어야 한다.
- 엔티티 유형이 잘못 식별되면 데이터, 데이터 구조 및 기능이 중복되어 개발 및 유지 관리 비용이 증가한다. 따라서 데이터 정의는 명확하고 이해하기 쉬워야 한다.
- 서로 다른 시스템의 데이터 모델이 다르면 데이터를 공유하는 시스템 간에 복잡한 인터페이스가 필요하며, 이는 시스템 비용의 상당 부분을 차지할 수 있다. 데이터 모델 설계 시 필요한 인터페이스를 고려해야 한다.
- 데이터 구조와 의미가 표준화되지 않으면 고객 및 공급업체와 전자적으로 데이터를 공유하기 어렵다. 데이터 모델은 비즈니스 요구 사항을 충족하고 일관성을 유지하도록 표준을 정의해야 한다.[4]
데이터 모델은 대상 영역의 데이터 구조를 기술하며, 이는 대상 영역을 위한 전용 인공 언어의 문법을 규정하는 것과 같다. 데이터 모델은 실체 클래스(사물의 종류) 집합을 표현하며, 대상 조직은 이러한 실체 클래스에 대한 정보와 속성, 실체 간의 관계, 속성 간의 관계를 관리한다.
데이터 모델은 데이터를 조직화하여 기술하며, 컴퓨터 시스템에서 표현하는 방법과는 거의 관계가 없다. 견고한 데이터 모델에서는 구체적인 실체 클래스보다는 추상화된 실체 클래스를 식별하는 경우가 많다. 예를 들어, "인물"이라는 실체 클래스는 조직과 상호 작용하는 모든 인물을 표현할 수 있으며, 이는 "판매자"나 "직원"과 같은 특정 역할을 식별하는 실체 클래스보다 적절하다.
개념 데이터 모델은 대상 영역의 의미론적 측면을 기술하며, 자연어 단어를 사용하여 이름을 지을 수 있다. 또한 관계 집합은 대상 영역에 대한 구체적인 진술을 생성한다. 예를 들어, "주문" 실체 클래스와 "주문 명세" 실체 클래스 간의 "—로 구성됨" 관계는 "각각의 주문은 하나 이상의 주문 명세로 구성될 수 있음" 또는 "각각의 주문은 하나 이상의 주문 명세로 구성되어야 함"과 같은 진술을 생성한다.
데이터 모델링의 다른 방법론으로는 인공 신경망과 같이 자율적으로 데이터의 암묵적인 모델을 생성하는 적응형 시스템을 사용하는 방법론이 있다.
7. 범용 데이터 모델 (Generic Data Model)
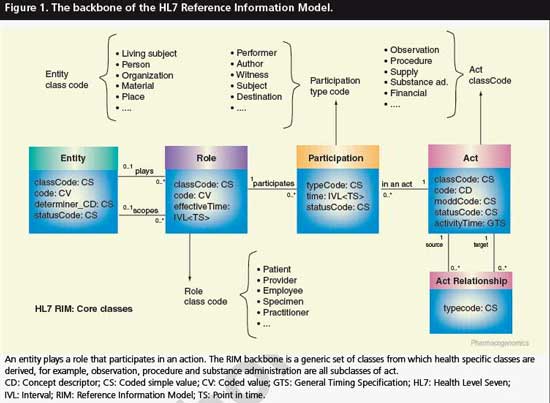
일반 데이터 모델은 기존의 데이터 모델을 일반화한 것이다. 이는 표준화된 일반적인 관계 유형과 그러한 관계 유형으로 관련될 수 있는 것들의 종류를 정의한다.
일반 데이터 모델의 정의는 자연어의 정의와 유사하다. 예를 들어, 일반 데이터 모델은 개별 사물과 사물의 종류(클래스) 사이의 이항 관계인 '분류 관계'와 두 사물 사이의 이항 관계(하나는 부분의 역할, 다른 하나는 전체의 역할)인 '부분-전체 관계'와 같은 관계 유형을 정의할 수 있다. 관계되는 사물의 종류에 관계없이 말이다.
확장 가능한 클래스 목록이 주어지면, 이를 통해 모든 개별 사물을 분류하고 모든 개별 객체에 대한 부분-전체 관계를 지정할 수 있다. 확장 가능한 관계 유형 목록의 표준화를 통해 일반 데이터 모델은 무제한의 여러 종류의 사실을 표현할 수 있게 되며 자연어의 기능에 근접하게 된다. 반면에 기존 데이터 모델은 모델의 인스턴스화(사용)가 모델에 미리 정의된 종류의 사실만 표현할 수 있도록 허용하기 때문에 고정되고 제한적인 도메인 범위를 갖는다.
범용 데이터 모델은 기존 데이터 모델의 단점을 해결하기 위한 방법으로 개발된다. 예를 들어, 같은 영역에 대해 기존 데이터 모델을 사용하여 여러 사람이 모델링을 수행하는 경우, 각기 다른 데이터 모델을 만들어내는 경우가 많다. 따라서 여러 사람이 공동으로 모델을 만드는 경우 어려움에 직면한다. 이러한 상황은 데이터 교환 및 데이터 통합 관점에서 장애가 된다. 그리고 같은 영역에 대해 데이터 모델이 다른 것은 항상 모델의 추상화 수준이 다르다는 것과 (모델의 의미적 표현 능력에 따라) 인스턴스화할 수 있는 사물 종류의 차이가 원인이 된다. 이러한 차이를 줄이기 위해 모델링하는 사람들은 의사소통을 하고, 더 구체적으로 표현하기 위해 몇 가지 요소에 대해 합의할 필요가 있다.
우수한 데이터 모델을 만드는 데 유용한 몇 가지 일반적인 패턴이 있다. 이러한 패턴에는 당사자(사람과 조직의 상위 개념), 제품 유형, 제품 인스턴스, 활동 유형, 활동 인스턴스, 계약, 지역, 사이트 등이 포함된다. 이러한 패턴에 포함된 실체를 명시적으로 포함한 모델은 적당한 강건성을 갖추고 이해하기 쉬울 것이다.
범용적인 도구를 만들 때는 더 추상적인 모델이 적합하다. 이 추상적인 모델은 "사물"(THING)과 "사물 유형"(THING TYPE)의 변형 집합으로 구성된다. 이 추상적인 모델에서는 모든 실제 데이터가 "사물" 또는 "사물 유형"의 인스턴스로 설명된다. 한편, 이러한 추상적인 모델은 다루기 어렵다는 측면도 있다. 왜냐하면 현실 세계의 사물을 잘 표현하지 못하기 때문이다. 그러나 다른 한편으로, 특히 표준화된 사전(딕셔너리)이 존재하는 경우, 이러한 추상적인 모델의 적용 가능성은 매우 높다. 구체적이고 특화된 데이터 모델은 범위나 환경이 변경될 때 모델을 변경해야 하는 우려가 있다.
범용 데이터 모델을 이용한 데이터 모델링 방법은 다음과 같은 특징이 있다.
- 범용 데이터 모델은 범용적인 실체 집합으로 구성된다. 범용적인 실체로는 "사물 인스턴스", 클래스, "관련" 등이 있으며, 아마도 이러한 실체에 많은 하위 유형이 존재할 것이다.
- 모든 사물 인스턴스는 "사물 인스턴스"라는 범용적인 실체의 인스턴스이거나 그 하위 유형의 인스턴스이다.
- 모든 사물 인스턴스는 사물의 종류("클래스")에 따라 명시적인 분류 관계를 사용하여 명시적으로 분류된다.
- 분류에 사용되는 실체는 다른 종류의 실체와 별도로 "클래스"라는 실체 또는 그 하위 유형의 실체의 표준 인스턴스로 정의된다. "클래스"의 하위 유형으로는 "관련 클래스" 등이 있다. 이러한 표준 클래스 집합은 "참조 데이터"라고 자주 불린다. 즉, 영역에 고유한 지식은 이러한 표준 클래스 집합의 인스턴스로 표현할 수 있다는 것이다. 예를 들어 자동차, 바퀴, 건물, 배, 온도, 길이 등의 개념은 표준 인스턴스이다. 또한, "―로 구성된다"나 "―에 참여한다"와 같은 표준적인 관련 실체도 표준 인스턴스이다.
이러한 범용 데이터 모델을 이용한 데이터 모델링 방법을 채택함으로써 표준적인 실체와 표준적인 관계 유형을 인스턴스로 추가할 수 있게 된다. 그리고 데이터 모델에 유연성을 부여하고, 애플리케이션 소프트웨어의 범위 변경이 있을 때에도 데이터 모델의 변경을 억제할 수 있다.
범용 데이터 모델은 다음 규칙을 따른다.
- 속성은 다른 실체에 대한 관계를 표현하는 것으로 취급된다.
- 실체가 식별되면 그 사물의 본질적인 성질에 따라 명명된다. 특정 문맥에서 수행하는 역할에 따라 명명되지 않는다.
- 실체는 데이터베이스 또는 데이터 교환을 위한 파일 내에 국소적인 식별자를 갖는다. 이러한 식별자는 인공적인 것이며, 고유하게 관리된다. 관계는 국소적인 식별자의 일부로 사용되지 않는다.
- 활동, 관계, 이벤트에 의한 영향은 실체로 표현된다(속성으로 표현되지 않는다).
- 실체는 모델의 보편적인 문맥을 정의하기 위해 실체의 하위 유형/상위 유형 계층의 일부를 구성한다. 관계도 실체이기 때문에 다양한 관계의 실체는 관계의 하위 유형/상위 유형 계층의 일부를 구성한다.
- 관계는 높은(범용적인) 수준에서 정의된다. 관계는 그것이 타당한 수준 중 가장 높은 수준에서 정의된다. 예를 들어, 구성 관계("―로 구성된다"로 표현됨)는 "사물 인스턴스"와 다른 "사물 인스턴스" 사이의 관계로 정의된다(예를 들어, 단순히 "주문"과 "주문 상세" 사이의 관계로 정의되지 않는다). 이 범용적인 수준에서는 관계는 원칙적으로 어떤 사물 인스턴스와 그와는 다른 어떤 사물 인스턴스에도 적용할 수 있다는 것을 의미한다. "참조 데이터"에서는 데이터에 대한 제약 집합이 정의된다. 제약은 실체 간 관계의 표준 인스턴스이다.
범용 데이터 모델의 예시는 다음과 같다.
- ISO 10303-221
- ISO 15926 (:en:ISO 15926)
- Gellish (:en:Gellish)
- Gellish English (:en:Gellish English)
8. 의미 데이터 모델 (Semantic Data Model)
의미 데이터 모델은 다른 데이터와의 상호 관계라는 맥락에서 데이터의 의미를 정의하는 기법이다. 추상화를 통해 저장된 기호가 실제 세계와 어떻게 관련되는지 정의하며, 실제 세계를 정확하게 나타내야 한다.[8]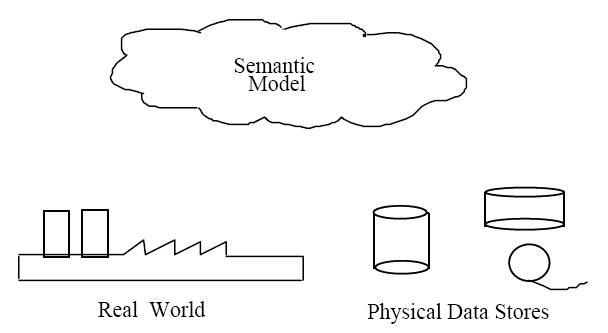
의미 데이터 모델링의 목적은 실제 세계의 일부인 "담론의 세계"에 대한 구조적 모델을 만드는 것이다. 이를 위해 다음과 같은 세 가지 기본적인 구조적 관계를 고려한다.
- 분류/인스턴스화: 구조적 유사성을 가진 객체는 클래스의 인스턴스로 설명된다.
- 집계/분해: 구성된 객체는 부분을 결합하여 얻는다.
- 일반화/전문화: 공통 속성을 가진 별개의 클래스는 공통 속성을 가진 더 일반적인 클래스에서 다시 고려된다.
의미 데이터 모델은 다음과 같은 여러 목적으로 사용할 수 있다.[8]
- 데이터 자원 계획
- 공유 가능한 데이터베이스 구축
- 벤더 소프트웨어 평가
- 기존 데이터베이스 통합
전반적인 목표는 관계형 개념을 인공 지능 분야에서 알려진 더 강력한 추상화 개념과 통합하여 데이터의 의미를 더 많이 포착하는 것이다. 이를 통해 실제 세계 상황의 표현을 용이하게 하기 위해 데이터 모델의 필수적인 부분으로 고급 모델링 기본 요소를 제공한다.[10]
데이터 모델은 대상 영역의 데이터 구조를 기술하며, 이는 대상 영역을 위한 전용 인공어의 문법을 규정하는 것과 같다.
데이터 모델은 실체 클래스(사물의 종류)의 집합을 표현한다. 대상 조직은 실체 클래스 집합에 대한 정보와 정보의 속성, 실체 간의 관계, 속성 간의 관계를 보유하고 관리한다. 데이터 모델은 데이터를 컴퓨터 시스템에서 표현하는 방법과는 거의 관계없이 데이터를 조직화하여 기술한다.
견고한 데이터 모델에서는 "인물"과 같이 추상적인 실체 클래스를 식별하는 경우가 많다. 예를 들어, "인물" 실체 클래스는 어떤 조직과 상호 작용하는 모든 인물을 표현하며, "판매자"나 "직원"과 같이 특정 역할을 수행하는 구체적인 실체 클래스보다 적절하다.
일부 사람들은 데이터 모델을 설계할 때 트랜잭션 데이터와 참조 데이터를 구분하는 것이 유용하다고 생각한다. 트랜잭션 데이터는 하나 이상의 참조 데이터를 참조하는 데이터를 말한다.
적절하게 설계된 개념 데이터 모델은 대상 영역의 의미론적 측면을 기술한다. 실체 클래스 집합은 자연어 단어를 사용하여 이름을 지을 수 있으며, 관계 집합은 대상 영역에 대한 구체적인 진술을 생성한다.
관계에는 여러 종류가 있으며, "—로 구성됨"과 같은 관계는 "주문" 실체 클래스와 "주문 명세" 실체 클래스 간의 관계를 정의한다. 예를 들어, 다음과 같은 진술을 생성할 수 있다.
- 각각의 "주문"은 하나 이상의 "주문 명세" "로 구성될 수 있음".
- 각각의 "주문"은 하나 이상의 "주문 명세" "로 구성되어야 함".
참조
[1]
서적
Data Modeling Essentials
Morgan Kaufmann Publishers
2005
[2]
웹사이트
Data Integration Glossary
http://knowledge.fhw[...]
U.S. Department of Transportation
2001-08-00
[3]
서적
Systems Analysis and Design Methods
2005
[4]
웹사이트
Developing High Quality Data Models
https://sites.google[...]
The European Process Industries STEP Technical Liaison Executive (EPISTLE)
1999
[5]
간행물
ANSI/X3/SPARC Study Group on Data Base Management Systems; Interim Report
FDT (Bulletin of ACM SIGMOD)
1975
[6]
간행물
Creating a strategic plan for configuration management using Computer Aided Software Engineering (CASE) tools
http://www.osti.gov/[...]
1993
[7]
서적
The Data Model Resource Book
Wiley
1997
[8]
웹사이트
FIPS Publication 184
http://www.itl.nist.[...]
Computer Systems Laboratory of the National Institute of Standards and Technology (NIST)
1993-12-21
[9]
웹사이트
Clinical genomics data standards for pharmacogenetics and pharmacogenomics
http://healthit.hhs.[...]
2006
[10]
서적
Semantic data modeling
Springer Berlin / Heidelberg
1995
[11]
뉴스
비즈니스에 최적화된 기업DB `맞춤형 설계`
http://www.dt.co.kr/[...]
디지털타임즈
2011-07-12
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com