데이터베이스
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
데이터베이스는 여러 사람이 공유하고 사용할 목적으로 통합 관리되는 정보의 집합이다. 데이터베이스 기술은 1950년대 미국에서 시작되어, 기술 발전과 함께 발전해왔으며, 데이터 모델이나 구조에 따라 내비게이셔널 데이터베이스, 관계형 데이터베이스, 객체 지향 데이터베이스, NoSQL 데이터베이스 등으로 구분된다. 데이터베이스는 실시간 접근성, 지속적인 변화, 동시 공유, 내용에 대한 참조, 데이터 논리적 독립성을 특징으로 한다. 데이터베이스 관리 시스템(DBMS)은 데이터베이스를 정의, 생성, 유지 관리하고 액세스를 제어하는 소프트웨어 시스템으로, MySQL, Oracle 등이 있다. 트랜잭션은 데이터베이스 연산의 모임이며, ACID 속성을 만족해야 한다. 데이터베이스는 기업 내부 운영 지원, 고객 및 공급업체와의 온라인 상호 작용 지원, 관리 정보 저장 등에 활용되며, 데이터베이스 보안은 데이터베이스 콘텐츠, 소유자 및 사용자를 보호하는 다양한 측면을 다룬다. 데이터베이스는 개념적, 논리적, 물리적 설계를 거쳐 구축된다.
더 읽어볼만한 페이지
- 컴퓨터에 관한 - N형 반도체
N형 반도체는 전자를 주된 전하 운반체로 사용하는 반도체이다. - 컴퓨터에 관한 - CMOS
CMOS는 상보적 금속 산화막 반도체의 약자로, 저전력 소비를 특징으로 하며, P형과 N형 MOSFET을 결합하여 논리 게이트를 구현하는 디지털 회로 설계 방식 및 공정 계열이다. - 데이터베이스 관리 시스템 - 트랜잭션 처리
트랜잭션 처리는 데이터베이스 시스템에서 데이터의 일관성과 무결성을 보장하기 위한 기술이며, ACID 속성을 통해 데이터 정확성을 유지하고 롤백, 데드락 처리 등의 기술을 활용한다. - 데이터베이스 관리 시스템 - 저장 프로시저
저장 프로시저는 데이터베이스 관리 시스템에서 SQL 문들을 미리 컴파일하여 저장하고, 모듈화, 보안성, 성능 향상, 유지보수 용이성과 같은 특징을 가지며, 데이터베이스 시스템마다 구현 방식과 지원하는 언어가 다를 수 있는 코드 묶음이다. - 데이터베이스 - 지식 베이스
지식 베이스는 특정 주제 정보를 체계적으로 저장 및 관리하며 규칙 기반 추론으로 새로운 지식 도출에 활용되고, 웹 콘텐츠 관리 및 지식 관리 시스템으로 확장되어 온톨로지를 이용, 인공지능 기술과 결합하여 문제 해결책을 제시하고 경험을 통해 학습하는 시스템이다. - 데이터베이스 - 화이트리스트
화이트리스트는 특정 대상만 허용하고 나머지는 차단하는 접근 제어 목록으로, 정보보안, 무역, 금융 등 다양한 분야에서 활용되지만, 목록 선정 기준의 불명확성, 사회적 문제점 등의 위험성으로 투명하고 엄격한 관리가 필요하다.

2. 역사
데이터베이스라는 용어는 1950년대 미국에서 처음 사용되었는데, 본래 군비 관리를 위해 컴퓨터를 활용한 도서관 개념에서 유래했다. '데이터의 기지'라는 뜻으로 데이터베이스로 불렀다. 1965년 시스템 디벨로프사의 심포지엄에서 이 용어가 공식적으로 사용되었다.[40]
프로세서, 컴퓨터 메모리, 컴퓨터 스토리지, 컴퓨터 네트워크 기술의 발전으로 데이터베이스와 DBMS의 크기, 기능, 성능이 크게 향상되었다. 데이터베이스 기술의 발전은 데이터 모델에 따라 세 시대로 나뉜다.
- 내비게이셔널 데이터베이스
- SQL/관계형 데이터베이스
- 관계형 이후 데이터베이스
에드거 F. 커드가 1970년에 제안한 관계형 모델은 내용을 기준으로 데이터를 검색해야 한다고 주장하며, 금전출납부 스타일의 표를 사용했다. 1980년대에 컴퓨팅 하드웨어가 발전하면서 관계형 시스템이 널리 보급되었고, 1990년대 초에는 IBM DB2, 오라클, MySQL, 마이크로소프트 SQL 서버 등이 주요 DBMS로 자리 잡았다.[41]
1980년대에는 객체 지향 임피던스 불일치 문제를 해결하기 위해 객체 지향 데이터베이스가 개발되었고, "관계형 이후"라는 용어가 등장했다.
2000년대 후반에는 NoSQL 데이터베이스가 등장하여 고속의 키-값 스토어와 도큐먼트 지향 데이터베이스를 도입했다. NewSQL 데이터베이스는 관계형/SQL 모델을 유지하면서 NoSQL의 성능을 목표로 했다.
2. 1. 1960년대, 내비게이셔널 DBMS
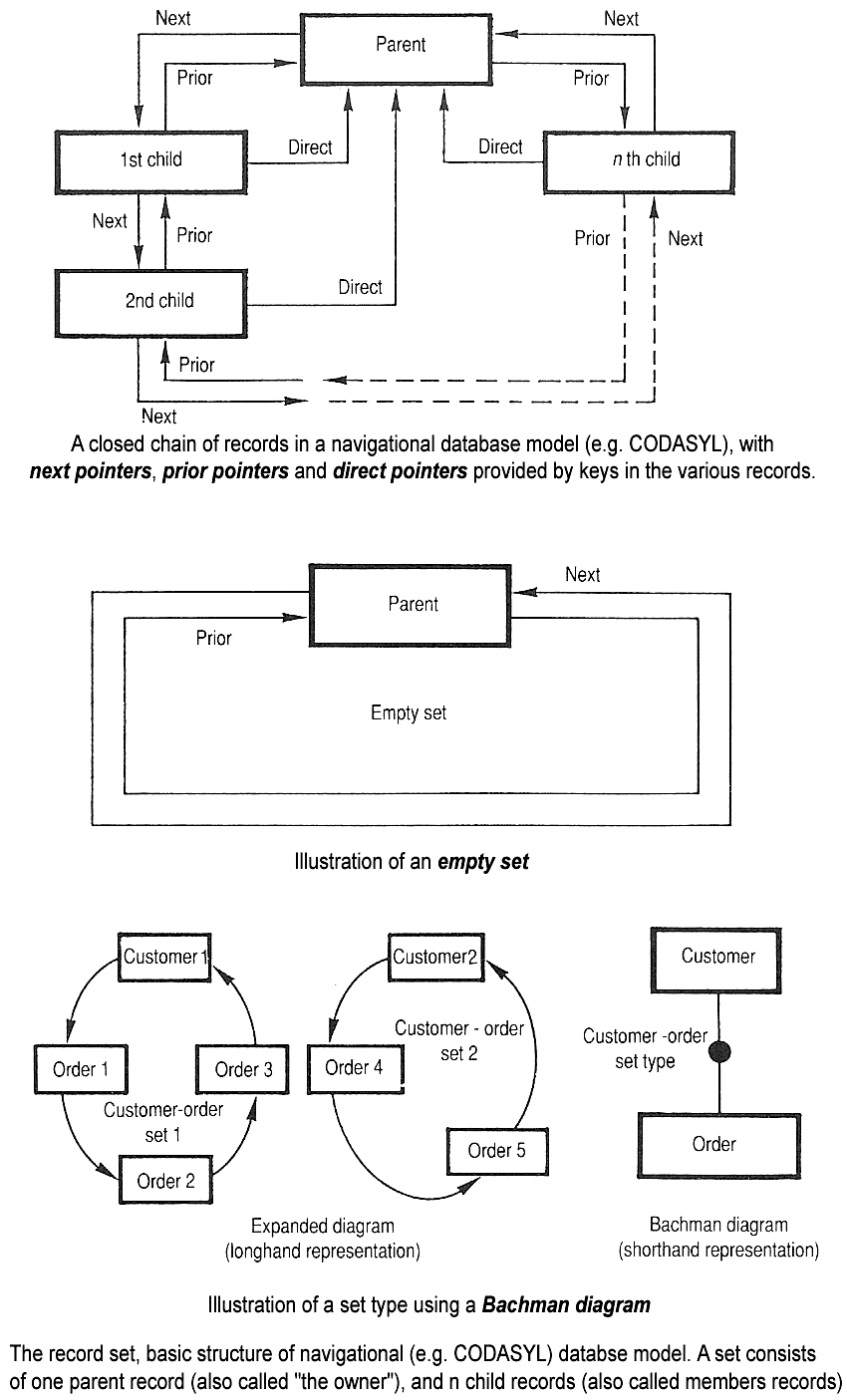
프로세서, 컴퓨터 메모리, 컴퓨터 스토리지, 컴퓨터 네트워크 분야의 기술 발전으로 데이터베이스와 DBMS의 크기, 기능, 성능이 향상되었다. 1960년대 중반 자기 디스크와 같은 직접 접근 저장 매체가 널리 보급되면서 데이터베이스 개념이 가능해졌다. 이전에는 자기 테이프에 데이터를 순차적으로 저장해야 했다.초기의 두 가지 주요 탐색형 데이터 모델은 IBM의 IMS 시스템의 계층형 모델과, IDMS 등 여러 제품에 구현된 CODASYL 모델 (네트워크 모델)이었다. 이들은 하나의 레코드에서 다른 레코드로의 관계를 맺기 위해 포인터(주로 물리적 디스크 주소)를 사용하는 것이 특징이었다.
"데이터베이스"라는 용어는 1960년대 중반부터 직접 접근 저장 장치(디스크 및 드럼)의 등장과 함께 나타났다. 이 용어는 과거의 테이프 기반 시스템과 달리, 매일 일괄 처리가 아닌 공유 대화형 사용을 가능하게 했다. 옥스포드 영어 사전은 캘리포니아의 시스템 개발 공사의 1962년 보고서를 "데이터베이스"라는 용어를 처음 사용한 것으로 인용한다.[5]
컴퓨터의 속도와 성능이 향상됨에 따라 여러 범용 데이터베이스 시스템이 등장했다. 1960년대 중반까지 여러 시스템이 상용화되었다. 표준에 대한 관심이 커지면서, 통합 데이터 저장소(IDS)의 개발자인 찰스 배치먼이 CODASYL 내에 데이터베이스 태스크 그룹을 설립했다. 1971년, 데이터베이스 태스크 그룹은 표준을 제공했는데, 이는 "CODASYL 접근 방식"으로 알려졌으며, 이 접근 방식을 기반으로 한 여러 상용 제품이 출시되었다.
CODASYL 접근 방식은 애플리케이션이 큰 네트워크로 구성된 연결된 데이터 세트를 탐색할 수 있는 기능을 제공했다. 애플리케이션은 다음 세 가지 방법 중 하나로 레코드를 찾을 수 있었다.
- 기본 키 (CALC 키, 해싱으로 구현) 사용
- 한 레코드에서 다른 레코드로 관계 ("집합") 탐색
- 모든 레코드를 순차적으로 스캔
후속 시스템에서는 B-트리를 추가하여 대체 접근 경로를 제공했다. 많은 CODASYL 데이터베이스는 최종 사용자를 위한 선언적 쿼리 언어 (탐색형 API와는 별개)를 추가했다. 그러나 CODASYL 데이터베이스는 복잡했으며 유용한 애플리케이션을 생성하려면 상당한 교육과 노력이 필요했다.
IBM도 1966년에 정보 관리 시스템(IMS)이라는 자체 DBMS를 보유하고 있었다. IMS는 아폴로 계획에서 System/360을 위해 작성된 소프트웨어의 개발이었다. IMS는 개념적으로 CODASYL과 유사했지만, CODASYL의 네트워크 모델 대신 데이터 탐색 모델에 엄격한 계층 구조를 사용했다. 두 가지 개념은 나중에 데이터에 접근하는 방식 때문에 탐색형 데이터베이스로 알려지게 되었고, 이 용어는 배치먼의 1973년 튜링상 수상 발표 "프로그래머로서의 항해자"에서 대중화되었다. IMS는 IBM에서 계층형 데이터베이스로 분류된다. IDMS와 신콤 시스템의 TOTAL 데이터베이스는 네트워크 데이터베이스로 분류된다. IMS는 현재까지도 사용되고 있다.[6]
2. 2. 1970년대, 관계형 DBMS
1970년 에드거 F. 코드가 처음 제안한 관계형 모델은 응용 프로그램들이 링크를 따라가는 것이 아니라 내용으로 데이터를 검색해야 한다고 주장하면서 기존의 전통적인 방식에서 벗어났다. 관계형 모델은 각기 다른 유형의 엔티티에 사용되는 원장 형식의 표(ledger-style tables) 집합을 사용한다. 1980년대 중반에 이르러서야 컴퓨팅 하드웨어가 관계형 시스템(DBMS와 응용 프로그램)의 광범위한 배포를 허용할 만큼 강력해졌다. 그러나 1990년대 초까지 관계형 시스템은 모든 대규모 데이터 처리 응용 프로그램에서 우위를 점했으며, 2018년 현재까지도 IBM Db2, 오라클, MySQL, Microsoft SQL Server, PostgreSQL가 가장 많이 검색되는 DBMS로서 그 우세를 유지하고 있다.[23] 관계형 모델을 위한 표준화된 SQL인 주요 데이터베이스 언어는 다른 데이터 모델의 데이터베이스 언어에도 영향을 미쳤다.코드의 논문은 버클리의 유진 웡과 마이클 스톤브레이커 두 사람의 관심을 끌었다. 그들은 이미 지리 데이터베이스 프로젝트와 학생 프로그래머에게 할당된 자금을 사용하여 INGRES라는 프로젝트를 시작했다. 1973년 INGRES는 첫 번째 테스트 제품을 제공했으며 1979년에는 광범위하게 사용할 수 있게 되었다. INGRES는 시스템 R과 여러 가지 면에서 유사했는데, 그중 하나는 QUEL로 알려진 데이터 접근을 위한 "언어"를 사용한 것이다. 시간이 지남에 따라 INGRES는 등장하는 SQL 표준으로 이동했다.
IBM 자체는 관계형 모델의 테스트 구현인 PRTV와 프로덕션 구현인 비즈니스 시스템 12를 수행했지만 현재는 모두 단종되었다. 허니웰은 Multics용 MRDS를 작성했으며, 현재 알포라 데이터포와 Rel이라는 두 가지 새로운 구현이 있다. "관계형"이라고 일반적으로 불리는 다른 대부분의 DBMS 구현은 실제로 SQL DBMS이다.
1970년, 미시간 대학교는 D.L. 차일즈의 집합 이론적 데이터 모델을 기반으로 MICRO 정보 관리 시스템의 개발을 시작했다. MICRO는 미국 노동부, 미국 환경보호청 및 앨버타 대학교, 미시간 대학교 및 웨인 주립 대학교의 연구원들이 매우 큰 데이터 세트를 관리하는 데 사용되었다. 미시간 터미널 시스템을 사용하여 IBM 메인프레임 컴퓨터에서 실행되었다.[7] 이 시스템은 1998년까지 운영되었다.
IBM은 1970년대 초반에 코드의 개념을 바탕으로 한 시스템의 프로토타입인 ''시스템 R''을 개발하기 시작했다. 첫 번째 버전은 1974년/1975년에 완성되었고, 그 후 레코드의 모든 데이터(일부는 선택 사항)를 하나의 큰 "청크"에 저장할 필요가 없도록 데이터를 분할할 수 있는 다중 테이블 시스템 작업이 시작되었다. 1978년과 1979년에 고객들이 후속 다중 사용자 버전을 테스트했는데, 그 당시 표준화된 쿼리 언어인 SQL이 추가되었다. 코드의 아이디어는 실용적이고 CODASYL보다 우수하다는 것을 입증하여 IBM이 ''SQL/DS''로 알려진 시스템 R의 실제 프로덕션 버전과 후에 ''데이터베이스 2''(IBM Db2)를 개발하도록 했다.
래리 엘리슨의 오라클 데이터베이스(간단히 오라클)는 시스템 R에 대한 IBM의 논문을 기반으로 한 다른 계보에서 시작되었다. 오라클 V1 구현은 1978년에 완료되었지만, 엘리슨이 1979년에 시장에서 IBM을 제치고 나선 것은 오라클 버전 2가 되어서였다.[8]
스톤브레이커는 INGRES에서 얻은 교훈을 바탕으로 새로운 데이터베이스인 Postgres를 개발했는데, 이것은 현재 PostgreSQL로 알려져 있다. PostgreSQL은 종종 글로벌 미션 크리티컬 애플리케이션에 사용된다(.org 및 .info 도메인 이름 레지스트리, 많은 대기업 및 금융 기관에서 기본 데이터 저장소로 사용).
스웨덴에서는 코드의 논문이 읽히고 Mimer SQL이 1970년대 중반에 웁살라 대학교에서 개발되었다. 1984년에 이 프로젝트는 독립 기업으로 통합되었다.
2. 3. 1990년대, 객체 지향
객체 지향과 관계형 간의 임피던스 불일치(상성의 부재)로 인한 불편함을 해소하기 위해 1980년대에 객체 데이터베이스가 개발되었고, 이로 인해 "포스트 관계형(post-relational)"이라는 용어가 생겨났으며, 하이브리드형 객체 관계형 데이터베이스도 개발되었다.[23]2. 4. 2000년대, NoSQL과 NewSQL
2000년대 후반, 관계형 이후의 차세대 데이터베이스는 NoSQL 데이터베이스로 알려지게 되었으며, 고속의 키-값 스토어 및 도큐먼트 지향 데이터베이스를 도입하였다. NewSQL 데이터베이스는 경쟁력 있는 차세대 데이터베이스로서, 상용 관계형 DBMS 대비 NoSQL의 높은 성능에 부합하면서도 관계형/SQL 모델을 유지하는 새로운 구현을 시도하였다.3. 데이터베이스의 개념
데이터베이스는 여러 사람이 공유하고 사용할 목적으로 통합 관리되는 정보의 집합이다. 논리적으로 연관된 하나 이상의 자료를 모아, 검색과 갱신의 효율성을 높이기 위해 고도로 구조화한 것이다. 이는 자료 파일들을 조직적으로 통합하여 자료 항목의 중복을 없애고, 자료를 구조화하여 저장한 자료의 집합체라고 할 수 있다.[1]
데이터베이스는 다음과 같은 특징을 가진다:
- 실시간 접근성: 사용자의 질의에 실시간으로 응답한다.
- 지속적인 변화: 데이터의 삽입, 삭제, 수정을 통해 계속해서 변화한다.
- 동시 공유: 여러 사용자가 동시에 같은 데이터에 접근하여 사용할 수 있다.
- 내용에 대한 참조: 저장된 데이터의 내용(값)을 참조하여 데이터를 검색한다.
- 데이터 논리적 독립성: 응용 프로그램과 데이터 간의 논리적 독립성을 유지한다.
형식적으로 "데이터베이스"는 "데이터베이스 관리 시스템(DBMS)"을 사용하여 접근하는 관련 데이터 집합을 의미한다. DBMS는 사용자가 데이터베이스와 상호 작용하고 데이터에 접근할 수 있도록 하는 통합된 소프트웨어 집합이다.[2] DBMS는 정보 입력, 저장, 검색 기능을 제공하며 정보 구성 방식을 관리한다.
"데이터베이스"라는 용어는 데이터베이스와 DBMS 모두를 가리키는 데 비공식적으로 사용되기도 한다. 전문적인 정보기술 분야 외부에서는 데이터베이스 관리 시스템의 사용을 필요로 하는 크기 및 사용 요구 사항 때문에 "데이터베이스"라는 용어가 관련 데이터의 집합(예: 스프레드시트 또는 카드 색인)을 가리키는 데 자주 사용된다.[3]
기존 DBMS는 다음과 같은 네 가지 주요 기능 그룹으로 분류할 수 있다:
- 데이터 정의: 데이터 구성 방식을 설명하는 정의를 생성, 수정, 제거한다.[20]
- 업데이트: 데이터를 삽입, 수정, 삭제한다.[21]
- 검색: 지정된 기준에 따라 데이터를 선택하여 사용자에게 제공하거나, 다른 응용 프로그램에서 처리할 수 있도록 한다.[22]
- 관리: 사용자 등록 및 모니터링, 데이터 보안, 성능 모니터링, 데이터 무결성 유지, 동시성 제어, 정보 복구 등을 수행한다.
데이터베이스와 DBMS는 모두 특정 데이터베이스 모델의 원칙을 따른다. "데이터베이스 시스템"은 데이터베이스 모델, 데이터베이스 관리 시스템, 데이터베이스를 통칭한다.
물리적으로 데이터베이스 서버는 실제 데이터베이스를 보유하고 DBMS 및 관련 소프트웨어만 실행하는 전용 컴퓨터이다. 데이터베이스 서버는 일반적으로 안정적인 저장을 위해 풍부한 메모리와 RAID 디스크 어레이를 사용하는 다중 프로세서 컴퓨터이다. DBMS는 대부분의 데이터베이스 응용 프로그램의 핵심에 있으며, 최신 DBMS는 일반적으로 표준 운영 체제에 의존하여 네트워킹 기능을 제공한다.
DBMS는 상당한 시장을 구성하므로 컴퓨터 및 저장 장치 공급업체는 자체 개발 계획에서 DBMS 요구 사항을 고려하는 경우가 많다. 데이터베이스와 DBMS는 지원하는 데이터베이스 모델, 실행되는 컴퓨터 유형, 쿼리 언어, 성능, 확장성, 복원력 및 보안에 따라 분류할 수 있다.
DBMS는 데이터베이스 데이터에 대해 외부, 개념, 내부의 세 가지 뷰를 제공한다. 3단계 데이터베이스 아키텍처는 관계형 모델의 주요 초기 추진력 중 하나였던 ''데이터 독립성'' 개념과 관련이 있다.
3. 1. 데이터베이스 모델
데이터베이스 모델은 데이터베이스의 논리적 구조를 결정하며, 데이터를 저장, 구성 및 조작하는 방식을 근본적으로 결정하는 데이터 모델의 한 유형이다. 가장 널리 사용되는 모델은 테이블 기반 형식을 사용하는 관계형 모델이다.일반적인 논리적 데이터 모델은 다음과 같다:
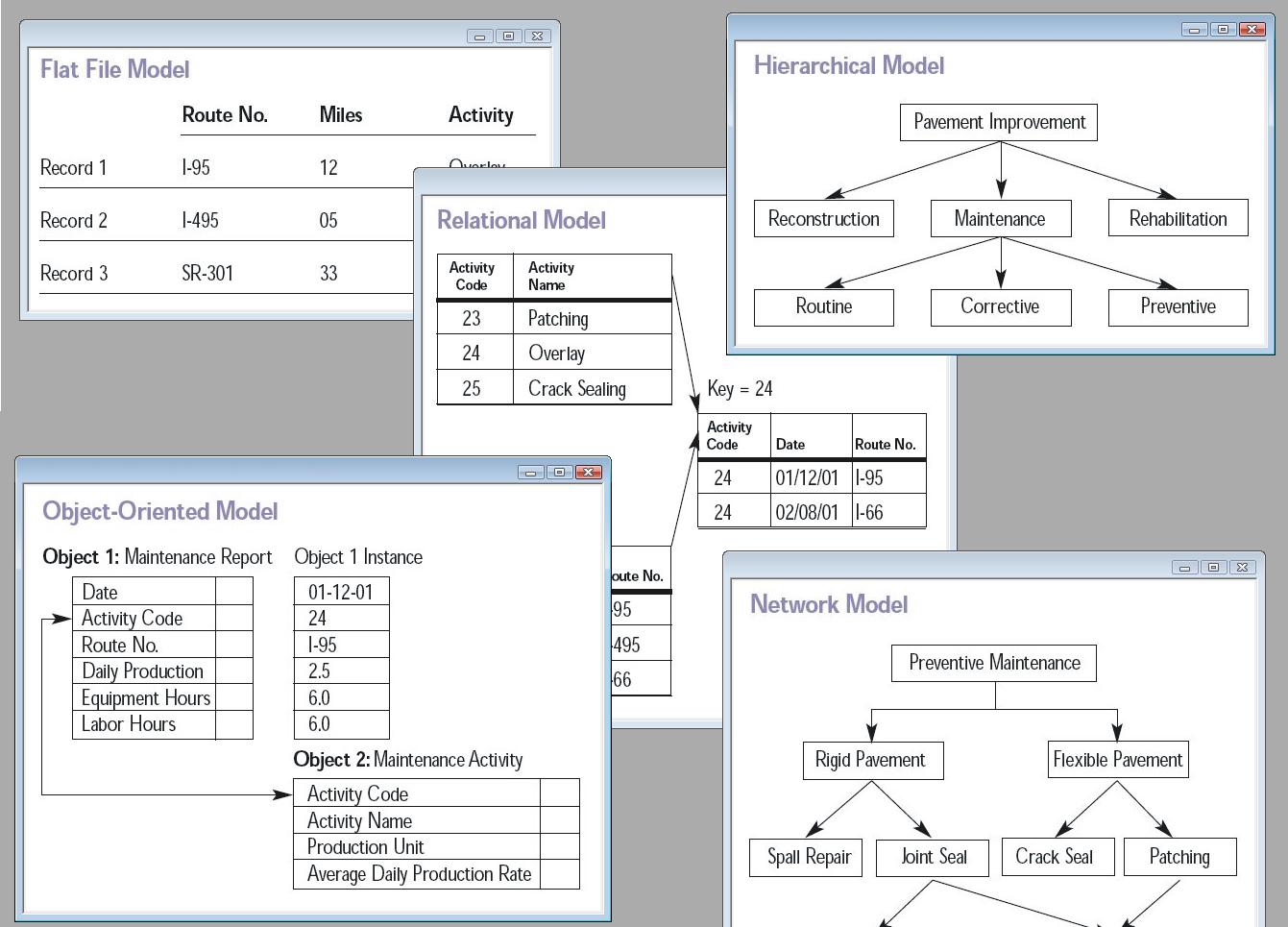
객체-관계형 데이터베이스는 위의 두 가지 관련 구조(객체 모델, 관계형 모델)를 결합한다.
물리적 데이터 모델에는 다음이 포함된다:
다른 모델에는 다음이 포함된다:
- 다차원 모델
- 배열 모델
- 다중값 모델
특정 유형의 데이터에 최적화된 특수 모델은 다음과 같다:
- XML 데이터베이스
- 의미 모델
- 콘텐츠 저장소
- 이벤트 저장소
- 시계열 모델
1980년대에는 데스크톱 컴퓨터의 등장으로 로터스 1-2-3과 같은 스프레드시트 소프트웨어와 dBASE와 같은 데이터베이스 소프트웨어가 사용자들에게 널리 보급되었다. dBASE는 가볍고 쉽게 이해할 수 있었으며, 1980년대부터 1990년대 초까지 가장 많이 팔린 소프트웨어 중 하나였다.[28]
1990년대는 객체 지향 프로그래밍의 부상과 함께 데이터베이스 내 데이터 처리 방식에 변화가 있었다. 프로그래머와 설계자는 데이터베이스 내 데이터를 객체로 다루기 시작했다. 즉, 개인의 속성은 외부 데이터가 아니라 그 사람에게 속한 것으로 간주되었다.[29] 이를 통해 데이터 간의 관계는 객체와 그 속성에 연결되었다. 이러한 객체와 데이터베이스 테이블 간의 변환의 불편함은 “객체-관계형 임피던스 불일치”라는 용어로 표현된다. 객체 데이터베이스와 객체 관계형 데이터베이스는 이 문제를 해결하기 위해 노력하고 있다.
3. 1. 1. SQL
SQL(Structured Query Language)은 1974년 IBM 연구소에서 관계형 데이터베이스를 지원하기 위해 개발되었으며, 관계 대수와 관계 논리(relational calculus)에 기반을 두고 있다.[7] 데이터 모델은 데이터베이스 구조와 제약 조건을 정의하기 위해 데이터를 조작하는 연산 집합을 가진다. 관계 데이터 모델 연산 집합은 관계 대수로 표현되며, 이는 사용자에게 다양한 질의를 가능하게 한다.에드거 F. 코드는 IBM의 캘리포니아주 산호세 지사에서 하드 디스크 시스템 개발에 참여하면서 CODASYL 방식의 탐색적 모델, 특히 "검색" 기능 부재에 불만을 느꼈다. 1970년, 그는 "대규모 공유 데이터 뱅크를 위한 관계형 데이터 모델"이라는 논문을 발표하여, 데이터를 여러 개의 "표"로 구성하는 새로운 시스템을 제시했다.[7] 각 표는 고정된 수의 열을 가지며, 하나 이상의 열은 기본 키로 지정되어 표 간의 상호 참조에 사용되었다. 이 방식은 데이터를 정규화하여 업데이트 작업을 단순화하고, 뷰를 통해 데이터를 다르게 표시할 수 있게 했다.
코드는 수학적 용어를 사용하여 모델을 정의했지만, 현재 사용되는 용어는 초기 구현에서 유래했다. 그는 실제 구현이 수학적 기초에서 벗어나는 것을 비판했다.

기본 키를 사용하는 주요 동기는 엔지니어링 측면에서 데이터베이스 재구성 없이 표를 재배치하고 크기를 조정할 수 있게 하는 것이었다. 또한, 의미론적으로 명확한 수학적 정의를 통해 업데이트 및 쿼리 작업을 정의할 수 있게 하여 쿼리 최적화의 기반을 마련했다.
관계형 모델에서는 데이터가 사용자 표, 주소 표, 전화번호 표 등으로 정규화되어, 필요한 경우에만 레코드가 생성된다. 이는 애플리케이션이 선언적 쿼리 언어를 사용하여 필요한 데이터를 표현하고, 데이터베이스 관리 시스템이 효율적인 접근 경로를 찾는 방식으로 변경되었다.
코드의 논문은 버클리의 유진 웡과 마이클 스톤브레이커의 관심을 끌어 INGRES 프로젝트를 시작하게 했고, INGRES는 시간이 지나면서 SQL 표준으로 이동했다.
IBM은 자체적으로 시스템 R을 개발하고, SQL/DS와 데이터베이스 2를 개발했다. 래리 엘리슨의 오라클은 시스템 R에 대한 IBM의 논문을 기반으로 시작되었으며, 1979년에 시장에서 IBM을 제쳤다.[8]
스톤브레이커는 INGRES에서 얻은 교훈을 바탕으로 PostgreSQL을 개발했다. 스웨덴에서는 Mimer SQL이 1970년대 중반에 개발되었다.
데이터베이스 언어는 데이터 제어 언어(DCL), 데이터 정의 언어(DDL), 데이터 조작 언어(DML), 데이터 질의 언어(DQL) 등으로 구분된다.
SQL은 데이터 정의, 조작, 질의 역할을 단일 언어로 결합한 관계형 모델의 상용 언어 중 하나였지만, 코드가 설명한 관계형 모델과는 일부 차이가 있다. SQL은 1986년 미국 표준 협회(ANSI)와 1987년 국제 표준화 기구(ISO)의 표준이 되었으며, 이후 지속적으로 개선되어 주요 상용 관계형 DBMS에서 지원된다.[14]
다른 데이터베이스 언어로는 OQL, XQuery, SQL/XML 등이 있다.
4. 데이터베이스 관리 시스템 (DBMS)
데이터베이스 설계 후에는 데이터베이스 관리 시스템(DBMS)을 사용해야 한다. 현재는 다양한 DBMS 선택 사항이 존재한다.
DBMS는 사용자가 데이터베이스와 상호 작용하고 데이터 접근을 제공하는 통합된 소프트웨어 집합이다.[1] DBMS는 정보의 입력, 저장, 검색 및 구성을 관리하는 다양한 기능을 제공한다.[2] "데이터베이스"라는 용어는 데이터베이스와 DBMS를 모두 지칭하는 데 사용되기도 한다.[3]
기존 DBMS는 다음과 같은 네 가지 주요 기능을 제공한다.
- '''데이터 정의''': 데이터 구성 방식을 설명하는 정의를 생성, 수정, 제거한다.
- '''업데이트''': 데이터를 삽입, 수정, 삭제한다.[20]
- '''검색''': 데이터를 사용자에게 제공하거나 다른 프로그램에서 처리할 수 있도록 한다. 검색된 데이터는 데이터베이스에 저장된 형태나 변경, 결합된 형태로 제공될 수 있다.[21]
- '''관리''': 사용자 등록 및 모니터링, 데이터 보안, 성능 모니터링, 데이터 무결성 유지, 동시성 제어, 정보 복구 등을 수행한다.[22]
데이터베이스와 DBMS는 특정 데이터베이스 모델의 원칙을 따른다. "데이터베이스 시스템"은 데이터베이스 모델, DBMS, 데이터베이스를 통칭한다.
물리적으로 데이터베이스 서버는 데이터베이스를 보유하고 DBMS를 실행하는 전용 컴퓨터이다. 대규모 트랜잭션 처리 시스템 환경에서는 하드웨어 데이터베이스 가속기도 사용된다. DBMS는 대부분의 데이터베이스 응용 프로그램의 핵심에 있으며, 최신 DBMS는 표준 운영 체제에 의존하여 기능을 제공한다.
DBMS는 큰 시장을 구성하며, 공급업체들은 DBMS 요구 사항을 고려하여 개발 계획을 세운다.
데이터베이스와 DBMS는 데이터베이스 모델, 컴퓨터 유형, 쿼리 언어, 내부 엔지니어링 등에 따라 분류될 수 있다.
1990년대 객체 지향 프로그래밍의 부상과 함께 데이터 처리 방식이 변화하였다. 프로그래머와 설계자들은 데이터베이스의 데이터를 객체로 취급하기 시작했다. 즉, 개인의 속성은 별개의 데이터가 아니라 개인에게 속하는 것으로 간주되었다.[10] 객체 데이터베이스와 객체-관계형 데이터베이스는 객체 지향 언어를 제공하여 이 문제를 해결하려 한다.
4. 1. DBMS 언어 선택
프로그래머는 응용 프로그램 프로그래밍 인터페이스(API) 또는 데이터베이스 언어를 통해 데이터베이스(데이터 소스라고도 함)와 상호 작용을 코딩한다. 선택된 특정 API나 언어는 DBMS에 의해 직접 지원되거나, 프리프로세서나 브리징 API를 통해 간접적으로 지원될 수 있다. 데이터베이스에 종속되지 않는 API도 있으며, ODBC가 대표적인 예이다. 다른 일반적인 API로는 JDBC와 ADO.NET이 있다.데이터베이스 언어는 특수 목적 언어로, 다음과 같은 작업을 수행할 수 있다.
- 데이터 제어 언어(DCL) - 데이터 접근 제어
- 데이터 정의 언어(DDL) - 테이블 생성, 변경, 삭제 등 데이터 형식 정의 및 테이블 간 관계 정의
- 데이터 조작 언어(DML) - 데이터 삽입, 갱신, 삭제 등 작업 실행
- 데이터 질의 언어(DQL) - 정보 검색 및 파생 정보 도출
데이터베이스 언어는 특정 데이터 모델에 특화되어 있으며, 대표적인 예는 다음과 같다.
- SQL은 데이터 정의, 데이터 조작, 질의를 하나의 언어로 통합한 것이다. 코드가 설명한 관계형 모델과 일부 차이점(예: 테이블 행과 열 정렬 가능)이 있지만, 관계형 모델의 최초 상용 언어 중 하나이다. 1986년 미국표준협회(ANSI) 표준, 1987년 국제표준화기구(ISO) 표준이 되었으며, 이후 지속적으로 강화되어 주요 상용 관계형 DBMS에서 지원된다(호환성 수준은 다양함).[34]
- 객체 질의 언어(OQL)는 Object Data Management Group의 객체 모델 언어 표준으로, JDOQL, EJB QL 등 새로운 질의 언어 설계에 영향을 미쳤다.
- XQuery는 MarkLogic, eXist 등 XML 데이터베이스 시스템, Oracle, Db2 등 XML 기능이 있는 관계형 데이터베이스, Saxon 등 인메모리 XML 프로세서에서 구현되는 표준 XML 질의 언어이다.
- SQL/XML은 XQuery와 SQL을 결합한 것이다.
데이터베이스 언어는 다음과 같은 기능을 포함할 수도 있다.
- DBMS 고유 구성 및 스토리지 엔진 관리
- 질의 결과 변경을 위한 계산 (예: 계산, 합계, 평균, 정렬, 그룹화, 상호 참조)
- 제약 조건 적용 (예: 자동차 데이터베이스에서 차량 당 엔진 종류 하나만 허용)
- 프로그래머 편의를 위한 질의 언어의 응용 프로그램 프로그래밍 인터페이스 버전
5. 트랜잭션
트랜잭션은 하나의 논리적 단위를 구성하는 데이터베이스 연산의 모임이다. 여러 트랜잭션이 동시에 수행될 때 데이터베이스의 일관성을 보장하기 위해 동시성 제어와 회복 제어 모듈이 사용되며, 이 둘을 합쳐 트랜잭션 관리 모듈이라고 한다.
트랜잭션 스케줄링에는 다음과 같은 세 가지 개념이 있다.
직렬 가능 트랜잭션을 보장하기 위한 규약으로는 잠금과 시간표 방식이 있다.
데이터베이스 트랜잭션은 시스템 장애 복구 후 내결함성과 데이터 무결성을 제공한다. 데이터베이스 트랜잭션은 데이터베이스 객체에 대한 읽기, 쓰기, 락 획득/해제 등 여러 작업을 캡슐화한 작업 단위이다. 각 트랜잭션은 명확하게 정의된 경계를 가지며, ACID 속성(원자성, 일관성, 격리성, 지속성)을 통해 데이터베이스의 안정성을 보장한다.
6. 데이터베이스 자료구조
데이터베이스 저장소는 데이터베이스의 물리적 구현체를 담는 공간이다. 이는 데이터베이스 아키텍처의 내부(물리적) 레벨을 구성한다. 또한, 개념 레벨과 외부 레벨을 내부 레벨에서 재구성하는 데 필요한 모든 정보(메타데이터, "데이터에 대한 데이터" 및 내부 데이터 구조 등)를 포함한다.[15] 디지털 객체로서의 데이터베이스는 데이터, 구조, 의미 체계라는 세 가지 계층의 정보를 저장해야 하며, 이러한 정보의 적절한 저장은 데이터베이스의 장기적인 보존과 유지에 필수적이다.[15]
데이터를 영구 저장소에 저장하는 것은 일반적으로 데이터베이스 엔진("저장 엔진")의 책임이다. 저장소 속성과 구성 설정은 DBMS의 효율적인 작동에 중요하므로 데이터베이스 관리자가 면밀하게 관리한다. DBMS는 작동 중일 때 항상 여러 유형의 저장소(예: 메모리 및 외부 저장소)에 데이터베이스를 상주시키며, 데이터베이스 데이터와 추가 정보는 비트로 인코딩된다. 데이터는 일반적으로 개념적 및 외부 레벨에서 보이는 방식과는 다른 구조의 저장소에 상주하지만, 사용자나 프로그램이 필요로 할 때 이러한 레벨의 재구성을 최적화하고, 데이터에서 추가 정보를 계산하는 방식으로 저장된다.
일부 DBMS는 데이터 저장에 사용된 문자 인코딩을 지정하는 것을 지원하여, 동일한 데이터베이스에서 여러 인코딩을 사용할 수 있다.
성능 향상을 위해 저장 공간 중복을 사용하는 경우가 있는데, 자주 필요한 외부 뷰 또는 쿼리 결과로 구성된 물질화 뷰를 저장하는 것이 일반적인 예시이다. 이러한 뷰를 저장하면 매번 계산하는 비용을 절감할 수 있지만, 원본 데이터베이스 데이터가 업데이트될 때 이를 동기화 상태로 유지하기 위한 업데이트 오버헤드와 저장 공간 중복 비용이 발생한다.
데이터 가용성을 높이기 위해 데이터베이스 객체의 복제(하나 이상의 복사본)를 통해 저장소 중복을 사용하기도 한다. 복제된 객체의 업데이트는 객체 복사본 간에 동기화되어야 하며, 대부분의 경우 전체 데이터베이스가 복제된다.
6. 1. 인덱싱
데이터베이스 저장 엔진은 다양한 저수준의 데이터베이스 저장 구조를 사용하여 데이터 모델을 직렬화하고, 선택한 매체에 쓸 수 있도록 한다. 성능을 향상시키기 위해 인덱싱과 같은 기법을 사용하기도 한다. 기존의 저장소는 행 지향이지만, 열 지향 데이터베이스나 상관 데이터베이스도 있다.[35]7. 데이터베이스의 활용
데이터베이스는 조직의 내부 운영을 지원하고 고객 및 공급 업체와의 온라인 상호 작용을 뒷받침하는 데 사용된다. 관리 정보, 엔지니어링 데이터, 경제 모델과 같은 전문적인 데이터를 저장하는 데 사용되며, 도서관 시스템, 항공 예약 시스템, 부품 재고 시스템, 콘텐츠 관리 시스템 등이 그 예이다.[30]
데이터베이스와의 외부 상호 작용은 DBMS와 인터페이스하는 응용 프로그램을 통해 이루어진다. 사용자가 SQL 쿼리를 실행할 수 있도록 하는 데이터베이스 도구부터 정보를 저장하고 검색하는 데 데이터베이스를 사용하는 웹사이트까지 다양한 형태로 활용된다.
1980년대에는 데스크톱 컴퓨터 시대가 열리면서 로터스 1-2-3과 같은 스프레드시트와 dBASE와 같은 데이터베이스 소프트웨어가 사용자들에게 널리 보급되었다. dBASE는 가볍고 사용자 친화적이어서 많은 인기를 얻었으며, 1980년대와 1990년대 초에 가장 많이 팔린 소프트웨어 중 하나였다.[9]
1970년대와 1980년대에는 하드웨어와 소프트웨어가 통합된 데이터베이스 시스템을 구축하려는 시도가 있었다. IBM 시스템/38, 초기 테라데이타 제품, 브리튼 리(Britton Lee, Inc.) 데이터베이스 머신 등이 그 예이다. 그러나 이러한 노력은 전문적인 데이터베이스 머신이 범용 컴퓨터의 빠른 발전 속도를 따라갈 수 없었기 때문에 일반적으로 성공하지 못했다. 오늘날 대부분의 데이터베이스 시스템은 범용 하드웨어에서 실행되는 소프트웨어 시스템이다. 그러나 네테자(Netezza)와 오라클(
7. 1. 대한민국
2012년 한국의 국내 DB산업은 DB 구축 시장, DB 컨설팅·솔루션 시장, DB 서비스 시장 등 모든 분야에서 전년 대비 높은 성장세를 나타내고 있다. 특히 전 산업에서의 정보통신기술(ICT) 융합과 스마트 환경 확산, 빅데이터 관련 수요가 증가하면서 향후 그 성장세는 계속될 것으로 예상된다. 보고서에서는 DB 산업의 성장을 예측하는 주요 요인으로 빅데이터 분석·활용을 위한 기업의 신규 수요 증가, DB 자산 가치 인식 증대로 인한 DB 구축 투자 증가, 스마트 기반의 모바일 서비스 확산 등을 꼽고 있다.[42]8. 데이터베이스 보안
데이터베이스 보안은 데이터베이스의 내용, 소유자, 사용자를 보호하기 위한 모든 측면을 다룬다. 데이터베이스 보안의 범위는 의도적인 데이터베이스 오용부터 권한 없는 엔티티(예: 사람이나 컴퓨터 프로그램)의 의도치 않은 데이터베이스 접근까지 다양한 보호를 포함한다.
데이터베이스 접근 제어는 데이터베이스 내 어떤 정보에 누가(사람 또는 특정 컴퓨터 프로그램) 접근을 허용할지 제어하는 것이다. 접근 제어 대상 정보에는 특정 데이터베이스 객체(예: 레코드 종류, 특정 레코드, 데이터 구조), 특정 객체에 대한 특정 연산(예: 쿼리 종류, 특정 쿼리), 또는 특정 접근 경로(예: 정보에 접근하기 위해 특정 인덱스 또는 다른 데이터 구조 사용) 등이 있다. 데이터베이스 접근 제어는 데이터베이스 소유자로부터 특별히 허가받은 인원에 의해 보호된 전용 보안 DBMS 인터페이스를 사용하여 설정된다.
접근 제어 관리 방법에는 개별적으로 직접 수행하는 방법, 개인과 Privilege (computing)|권한영어을 그룹에 할당하는 방법, (가장 정교한 모델에서는) 개인이나 그룹에 역할을 할당한 후 역할에 권한을 부여하는 방법 등이 있다. 데이터 보안은 권한 없는 사용자의 데이터베이스 열람 및 업데이트를 차단한다. 암호를 사용하면 사용자는 전체 데이터베이스 또는 "서브스키마"라고 하는 일부분에 대한 접근 권한을 얻을 수 있다. 예를 들어, 직원 데이터베이스에 개별 직원에 대한 모든 데이터가 포함되어 있더라도, 특정 그룹의 사용자에게는 급여 데이터만 열람 권한을 부여하고, 다른 그룹에게는 경력 및 의료 데이터만 접근 권한을 부여할 수 있다. DBMS가 데이터베이스의 입력, 업데이트, 질의를 대화식으로 수행하는 방법을 제공하는 경우, 이 기능을 통해 개인 데이터베이스를 관리할 수 있다.
일반적으로 Data security|데이터 보안영어은 특정 데이터 청크(data chunk)를 물리적으로 보호하거나(예: 손상, 파괴, 삭제로부터 보호. Physical security|물리적 보안영어 참조), 데이터 청크 또는 그 일부를 의미 있는 정보로 변환하는 것(예: 구성하는 비트열을 보고 특정 유효한 신용카드 번호를 결정하는 것. 데이터 암호화 참조)을 모두 포함한다.
변경 및 접근 로그는 누가 어떤 속성에 접근했는지, 무엇이 변경되었는지, 그리고 언제 변경되었는지를 기록한다. 로깅 서비스는 접근 발생 및 변경 기록을 보관함으로써 나중에 포렌식 Database audit|데이터베이스 감사영어를 수행할 수 있게 한다. 경우에 따라 데이터베이스 수준에서 기록하는 대신 애플리케이션 수준 코드에서 변경 사항을 기록할 수도 있다. 보안 위반 감지를 시도하기 위해 모니터링을 설정할 수도 있다. 데이터베이스 보안은 많은 장점을 제공하기 때문에 조직은 이에 진지하게 임해야 한다. 조직은 방화벽 침입, 바이러스 유포, 랜섬웨어 등의 보안 위반 및 해킹으로부터 보호받는다. 이는 기업에서 어떤 이유로든 외부인과 공유해서는 안 되는 중요한 정보를 보호하는 데 유용하다.[36]
9. 데이터베이스의 종류
DBMS는 지원하는 데이터베이스 모델 (예: 관계형 또는 XML), 실행되는 컴퓨터 유형 (서버 클러스터에서 휴대 전화까지), 데이터베이스에 접근하는 데 사용되는 쿼리 언어 (예: SQL 또는 XQuery), 성능, 확장성, 복원력 및 보안에 영향을 미치는 내부 엔지니어링에 따라 분류할 수 있다.
데이터베이스를 분류하는 한 가지 방법은 내용의 유형(예: 서지, 문서 텍스트, 통계, 멀티미디어 개체 등)을 기준으로 하는 것이다. 또 다른 방법은 응용 분야(예: 회계, 음악 작곡, 영화, 은행, 제조 또는 보험 등)를 기준으로 하는 것이다. 세 번째 방법은 데이터베이스 구조 또는 인터페이스 유형과 같은 기술적 측면을 기준으로 하는 것이다.
다음은 다양한 종류의 데이터베이스를 특징짓는 데 사용되는 몇 가지 형용사 목록이다.
- 메모리 내 데이터베이스는 주로 주기억장치에 상주하지만 일반적으로 비휘발성 컴퓨터 데이터 저장소에 백업되는 데이터베이스이다. 주기억장치 데이터베이스는 디스크 데이터베이스보다 빠르므로 통신 네트워크 장비와 같이 응답 시간이 중요한 곳에 자주 사용된다.
- 능동형 데이터베이스는 데이터베이스 내부 및 외부의 조건에 응답할 수 있는 이벤트 기반 아키텍처를 포함한다. 가능한 용도에는 보안 모니터링, 경고, 통계 수집 및 권한 부여가 포함된다. 많은 데이터베이스는 데이터베이스 트리거 형태로 능동형 데이터베이스 기능을 제공한다.
- 클라우드 데이터베이스는 클라우드 기술에 의존한다. 데이터베이스와 대부분의 DBMS는 원격으로 "클라우드에" 상주하는 반면, 해당 애플리케이션은 프로그래머가 개발하고 나중에 최종 사용자가 웹 브라우저 및 개방형 API를 통해 유지 관리하고 사용한다.
- 데이터 웨어하우스는 운영 데이터베이스 및 시장 조사 회사와 같은 외부 소스의 데이터를 보관한다. 웨어하우스는 관리자 및 운영 데이터에 액세스할 수 없는 다른 최종 사용자가 사용할 수 있는 중앙 데이터 소스가 된다.
- 연역적 데이터베이스는 논리 프로그래밍과 관계형 데이터베이스를 결합한다.
- 분산 데이터베이스는 데이터와 DBMS가 여러 컴퓨터에 걸쳐 있는 데이터베이스이다.
- 문서 지향 데이터베이스는 문서 지향 또는 반구조화된 정보를 저장, 검색 및 관리하도록 설계되었다. 문서 지향 데이터베이스는 NoSQL 데이터베이스의 주요 범주 중 하나이다.
- 임베디드 데이터베이스 시스템은 저장된 데이터에 액세스해야 하는 애플리케이션 소프트웨어와 긴밀하게 통합된 DBMS로, DBMS가 애플리케이션의 최종 사용자에게 숨겨지고 거의 또는 전혀 지속적인 유지 관리가 필요하지 않다.[11]
- 최종 사용자 데이터베이스는 개별 최종 사용자가 개발한 데이터로 구성된다. 여기에는 문서, 스프레드시트, 프레젠테이션, 멀티미디어 및 기타 파일의 컬렉션이 포함된다.
- 연합 데이터베이스 시스템은 각각 자체 DBMS를 가진 여러 개의 개별 데이터베이스로 구성된다.
- 그래프 데이터베이스는 노드, 에지 및 속성을 사용하여 정보를 나타내고 저장하는 그래프 구조를 사용하는 NoSQL 데이터베이스의 일종이다.
- 배열 DBMS는 위성 이미지 및 기후 시뮬레이션 출력과 같은 (일반적으로 큰) 다차원 배열의 모델링, 저장 및 검색을 허용하는 NoSQL DBMS의 일종이다.
- 하이퍼텍스트 또는 하이퍼미디어 데이터베이스에서는 개체를 나타내는 단어 또는 텍스트 조각을 해당 개체에 하이퍼링크할 수 있다.
- 지식 베이스(약칭 '''KB''', '''kb''' 또는 Δ[12][13])는 지식 관리를 위한 특수한 종류의 데이터베이스이다.
- 모바일 데이터베이스는 모바일 컴퓨팅 장치에서 휴대하거나 동기화할 수 있다.
- 운영 데이터베이스는 조직의 운영에 대한 자세한 데이터를 저장한다.
- 병렬 데이터베이스는 데이터 로딩, 색인 작성 및 쿼리 평가와 같은 작업에 대한 병렬화를 통해 성능을 향상시키려고 한다.
기본 하드웨어 아키텍처에 의해 유도되는 주요 병렬 DBMS 아키텍처는 다음과 같다.
- '''공유 메모리 아키텍처'''
- '''공유 디스크 아키텍처'''
- '''공유 없음 아키텍처'''
- 확률적 데이터베이스는 퍼지 논리를 사용하여 부정확한 데이터에서 추론한다.
- 실시간 데이터베이스는 결과가 돌아와서 바로 조치를 취할 수 있을 만큼 빠르게 트랜잭션을 처리한다.
- 공간 데이터베이스는 다차원 기능을 가진 데이터를 저장할 수 있다.
- 시간 데이터베이스에는 시간적 데이터 모델과 SQL의 시간적 버전과 같은 기본적인 시간 측면이 있다.
- 용어 지향 데이터베이스는 객체 지향 데이터베이스를 기반으로 하며 종종 특정 분야에 맞게 사용자 지정된다.
- 비정형 데이터 데이터베이스는 다양한 개체를 관리 가능하고 보호되는 방식으로 저장하도록 설계되었다.
10. 데이터베이스 설계
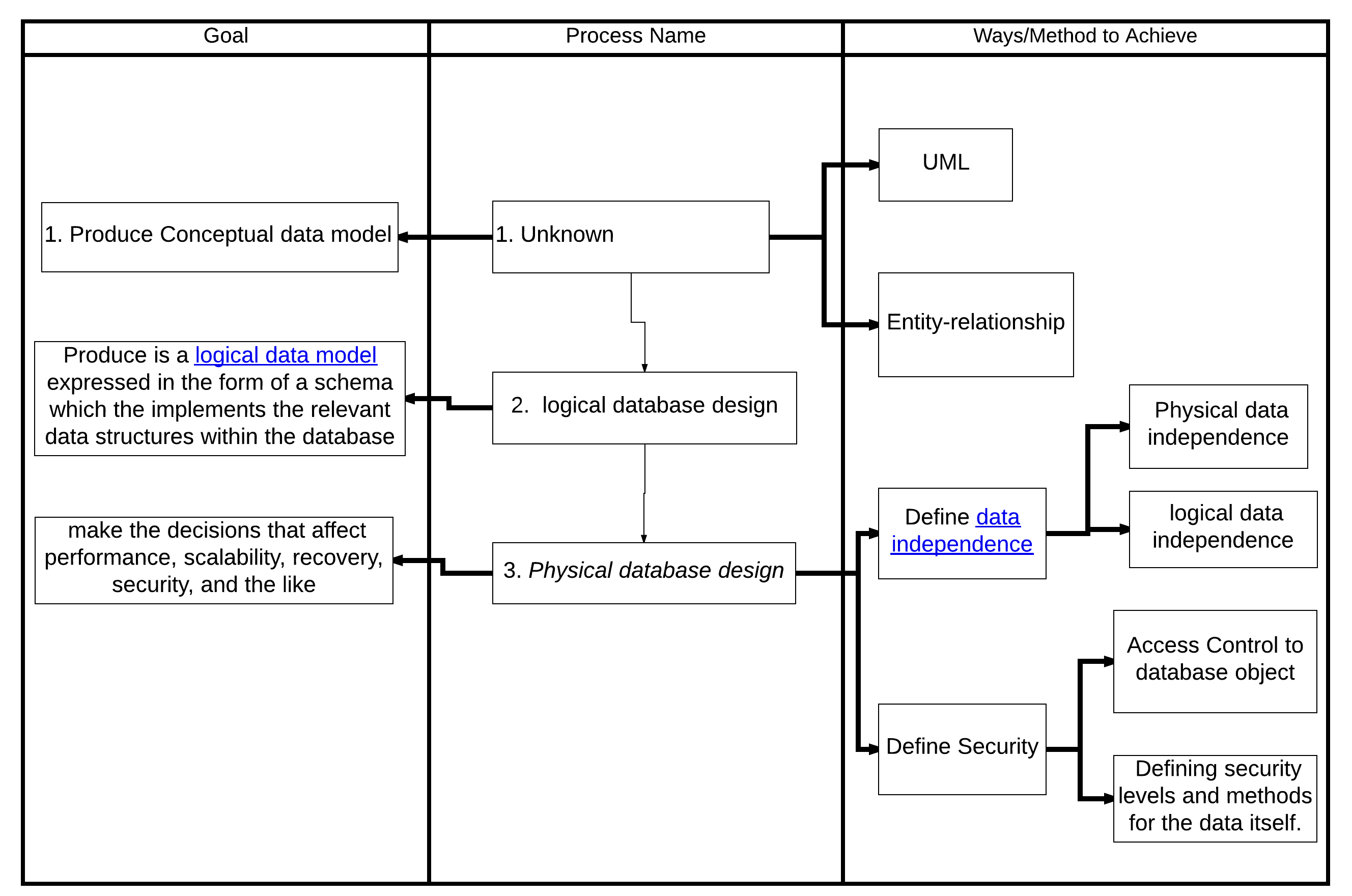
데이터베이스 설계자의 첫 번째 임무는 데이터베이스에 저장될 정보의 구조를 반영하는 개념적 데이터 모델을 만드는 것이다. 이를 위해 개체-관계 모델을 사용하거나 통합 모델링 언어(UML)를 활용하는 방법이 일반적이다. 좋은 데이터 모델은 모델링되는 현실 세계를 정확하게 반영해야 한다. 예를 들어, 사람들이 여러 개의 전화번호를 가질 수 있다면, 데이터베이스는 이 정보를 담을 수 있어야 한다. 훌륭한 개념적 데이터 모델을 설계하려면 애플리케이션 영역에 대한 깊은 이해가 필요하며, 이를 위해 조직의 관심사에 대해 심층적인 질문을 던져야 한다.[28] 예를 들면 다음과 같다.
- "고객이 공급업체가 될 수도 있습니까?"
- "두 가지 다른 형태의 포장으로 제품이 판매되는 경우, 그것은 같은 제품입니까 아니면 다른 제품입니까?"
- "비행기가 프랑크푸르트를 경유하여 뉴욕에서 두바이로 비행하는 경우, 그것은 하나의 비행입니까 아니면 두 개(또는 세 개)입니까?"
이러한 질문에 대한 답은 엔티티(고객, 제품, 항공편, 항공편 구간)와 그 관계 및 속성에 사용되는 용어의 정의를 확립하는 데 도움이 된다.
개념적 데이터 모델을 만드는 과정에는 비즈니스 프로세스의 입력이나 조직의 워크플로우 분석이 포함될 수 있다. 이는 데이터베이스에 필요한 정보와 제외할 수 있는 정보를 설정하는 데 도움이 된다. 예를 들어, 데이터베이스가 현재 데이터뿐만 아니라 과거 데이터도 보유해야 하는지 여부를 결정할 수 있다.
사용자가 만족하는 개념적 데이터 모델을 만든 후에는, 이를 데이터베이스 내에서 관련 데이터 구조를 구현하는 스키마로 변환해야 한다. 이 과정을 논리적 데이터베이스 설계라고 하며, 그 결과는 스키마 형태로 표현된 논리적 데이터 모델이다. 개념적 데이터 모델은 이론적으로 데이터베이스 기술 선택과 무관하지만, 논리적 데이터 모델은 선택된 DBMS에서 지원하는 특정 데이터베이스 모델을 기준으로 표현된다.
범용 데이터베이스에 가장 많이 사용되는 데이터베이스 모델은 관계형 모델, 더 정확하게는 SQL 언어로 표현되는 관계형 모델이다. 이 모델을 사용하여 논리적 데이터베이스 설계를 만드는 과정은 정규화라는 체계적인 접근 방식을 사용한다. 정규화의 목표는 각 기본 "사실"이 한 곳에만 기록되도록 하여 삽입, 업데이트 및 삭제 작업이 자동으로 일관성을 유지하도록 하는 것이다.
데이터베이스 설계의 마지막 단계는 특정 DBMS에 따라 성능, 확장성, 복구, 보안 등에 영향을 미치는 결정을 내리는 것이다. 이를 ''물리적 데이터베이스 설계''라고 하며, 그 결과는 물리적 데이터 모델이다. 이 단계의 주요 목표는 데이터 독립성이며, 이는 성능 최적화 목적으로 내린 결정이 최종 사용자와 애플리케이션에는 보이지 않아야 함을 의미한다. 데이터 독립성에는 물리적 데이터 독립성과 논리적 데이터 독립성의 두 가지 유형이 있다. 물리적 설계는 주로 성능 요구 사항에 따라 결정되며, 예상되는 작업량과 액세스 패턴에 대한 충분한 지식과 선택된 DBMS에서 제공하는 기능에 대한 깊이 있는 이해가 필요하다.
물리적 데이터베이스 설계의 또 다른 측면은 보안이다. 여기에는 데이터베이스 객체에 대한 접근 제어를 정의하는 것뿐만 아니라 데이터 자체에 대한 보안 수준과 방법을 정의하는 것도 포함된다.
참조
[1]
웹사이트
Update Definition & Meaning
http://www.merriam-w[...]
[2]
웹사이트
Retrieval Definition & Meaning
http://www.merriam-w[...]
[3]
웹사이트
Administration Definition & Meaning
http://www.merriam-w[...]
[4]
웹사이트
TOPDB Top Database index
https://pypl.github.[...]
[5]
웹사이트
database, n
http://www.oed.com/v[...]
Oxford University Press
2013-07-12
[6]
웹사이트
IBM Information Management System (IMS) 13 Transaction and Database Servers delivers high performance and low total cost of ownership
http://www-01.ibm.co[...]
IBM Corporation
2014-02-20
[7]
서적
MICRO Information Management System (Version 5.0) Reference Manual
https://docs.google.[...]
Institute of Labor and Industrial Relations (ILIR), University of Michigan and Wayne State University
1977-10-01
[8]
웹사이트
Oracle 30th Anniversary Timeline
https://www.oracle.c[...]
2017-08-23
[9]
웹사이트
Interview with Wayne Ratliff
http://www.foxprohis[...]
The FoxPro History
2013-07-12
[10]
간행물
Development of an object-oriented DBMS
1986-01-01
[11]
간행물
COTS Databases For Embedded Systems
http://www.embedded-[...]
Embedded Computing Design magazine
2007-01-01
[12]
서적
Argumentation in Artificial Intelligence
[13]
웹사이트
OWL DL Semantics
http://www.obitko.co[...]
[14]
웹사이트
Structured Query Language (SQL)
http://publib.boulde[...]
International Business Machines
2006-10-27
[15]
논문
Database Preservation Toolkit: A flexible tool to normalize and give access to databases
https://core.ac.uk/d[...]
University of Minho
2013-12-31
[16]
논문
Opportunities of collected city data for smart cities
[17]
서적
Continuous auditing : theory and application
Emerald Publishing
2018-01-01
[18]
웹사이트
How Database Administration Fits into DevOps
https://www.infoq.co[...]
2016-01-28
[19]
웹사이트
Integration Definition for Information Modeling (IDEFIX)
http://www.itl.nist.[...]
itl.nist.gov
1993-12-21
[20]
웹사이트
Update – Definition of update by Merriam-Webster
http://www.merriam-w[...]
[21]
웹사이트
Retrieval – Definition of retrieval by Merriam-Webster
http://www.merriam-w[...]
[22]
웹사이트
Administration – Definition of administration by Merriam-Webster
http://www.merriam-w[...]
[23]
웹사이트
TOPDB Top Database index
https://pypl.github.[...]
[24]
웹사이트
database, n
http://www.oed.com/v[...]
Oxford University Press
2013-07-12
[25]
웹사이트
IBM Information Management System (IMS) 13 Transaction and Database Servers delivers high performance and low total cost of ownership
http://www-01.ibm.co[...]
IBM Corporation
2014-02-20
[26]
서적
MICRO Information Management System (Version 5.0) Reference Manual
https://docs.google.[...]
Institute of Labor and Industrial Relations (ILIR), University of Michigan and Wayne State University
1977-10-01
[27]
웹사이트
Oracle 30th Anniversary Timeline
https://www.oracle.c[...]
[28]
웹사이트
Interview with Wayne Ratliff
http://www.foxprohis[...]
The FoxPro History
2013-07-12
[29]
간행물
Development of an object-oriented DBMS
1986-01-01
[30]
논문
航空予約システムとその動向
[31]
간행물
COTS Databases For Embedded Systems
http://www.embedded-[...]
Embedded Computing Design magazine
2007-01-01
[32]
서적
Argumentation in Artificial Intelligence
[33]
웹사이트
OWL DL Semantics
http://www.obitko.co[...]
[34]
웹사이트
Structured Query Language (SQL)
http://publib.boulde[...]
International Business Machines
2006-10-27
[35]
논문
Database Preservation Toolkit: a flexible tool to normalize and give access to databases
https://repositorium[...]
Biblioteca Nacional de Portugal (BNP)
[36]
서적
Continuous auditing : theory and application
2018
[37]
웹사이트
How Database Administration Fits into DevOps
https://www.infoq.co[...]
2017-04-15
[38]
웹사이트
Integration Definition for Information Modeling (IDEFIX)
http://www.itl.nist.[...]
1993-12-21
[39]
웹인용
Database - Definition of database by Merriam-Webster
http://www.merriam-w[...]
[40]
서적
최신 문헌정보학의 이해
한국도서관협회
[41]
웹인용
TOPDB Top Database index
https://web.archive.[...]
2016-11-14
[42]
뉴스
국내 DB산업 ‘빅데이터’ 날개 달고 고공행진..지난해 11조원 돌파
http://www.fnnews.co[...]
파이낸셜뉴스
2013-03-20
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com