부하분산
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
부하 분산은 작업을 여러 컴퓨팅 유닛에 분산하여 시스템의 효율성과 가용성을 향상시키는 알고리즘 및 기술을 의미한다. 작업의 특성, 하드웨어 아키텍처, 오류 허용 오차 등을 고려하여 애플리케이션별 요구 사항에 맞는 절충점을 찾아야 한다. 정적 및 동적 알고리즘, 마스터-워커 방식, 작업 훔치기 등 다양한 접근 방식이 있으며, 웹 서비스, 통신, 데이터 센터 네트워크 등 다양한 분야에서 사용된다. 주요 로드 밸런서 제조 기업으로는 F5 네트웍스, 시스코 시스템즈 등이 있다.
더 읽어볼만한 페이지
- 컴퓨터 네트워크 - NORSAR
NORSAR는 노르웨이 셸러에 위치한 지진 연구 및 데이터 센터이며, 기초 지진학 연구, 소프트웨어 개발, 석유 산업 컨설팅 등의 활동을 수행하며, 포괄적 핵실험 금지 조약을 위한 노르웨이 국가 데이터 센터 역할을 수행한다. - 컴퓨터 네트워크 - 라우터
라우터는 네트워크 간 데이터 패킷을 전달하는 네트워크 장비로, ARPANET의 IMP에서 시작하여 다양한 종류로 발전해 왔으며, 최신 네트워크 기술과 함께 네트워크의 확장성, 안정성 및 효율성을 향상시키는 데 중요한 역할을 한다. - 표시 이름과 문서 제목이 같은 위키공용분류 - 라우토카
라우토카는 피지 비치레부섬 서부에 위치한 피지에서 두 번째로 큰 도시이자 서부 지방의 행정 중심지로, 사탕수수 산업이 발달하여 "설탕 도시"로 알려져 있으며, 인도에서 온 계약 노동자들의 거주와 미 해군 기지 건설의 역사를 가지고 있고, 피지 산업 생산의 상당 부분을 담당하는 주요 기관들이 위치해 있다. - 표시 이름과 문서 제목이 같은 위키공용분류 - 코코넛
코코넛은 코코넛 야자나무의 열매로 식용 및 유지로 사용되며, 조리되지 않은 과육은 100g당 354kcal의 열량을 내는 다양한 영양 성분으로 구성되어 있고, 코코넛 파우더의 식이섬유는 대부분 불용성 식이섬유인 셀룰로오스이며, 태국 일부 지역에서는 코코넛 수확에 훈련된 원숭이를 이용하는 동물 학대 문제가 있다. - 한국어 위키백과의 링크가 위키데이터와 같은 위키공용분류 - 라우토카
라우토카는 피지 비치레부섬 서부에 위치한 피지에서 두 번째로 큰 도시이자 서부 지방의 행정 중심지로, 사탕수수 산업이 발달하여 "설탕 도시"로 알려져 있으며, 인도에서 온 계약 노동자들의 거주와 미 해군 기지 건설의 역사를 가지고 있고, 피지 산업 생산의 상당 부분을 담당하는 주요 기관들이 위치해 있다. - 한국어 위키백과의 링크가 위키데이터와 같은 위키공용분류 - 코코넛
코코넛은 코코넛 야자나무의 열매로 식용 및 유지로 사용되며, 조리되지 않은 과육은 100g당 354kcal의 열량을 내는 다양한 영양 성분으로 구성되어 있고, 코코넛 파우더의 식이섬유는 대부분 불용성 식이섬유인 셀룰로오스이며, 태국 일부 지역에서는 코코넛 수확에 훈련된 원숭이를 이용하는 동물 학대 문제가 있다.
2. 문제 개요
부하 분산 알고리즘은 항상 특정 문제에 대한 답을 찾으려고 시도한다. 무엇보다도, 작업의 특성, 알고리즘의 계산 복잡도, 알고리즘이 실행될 하드웨어 아키텍처, 필요한 오류 허용 오차 등을 고려해야 한다. 따라서 애플리케이션별 요구 사항을 가장 잘 충족하도록 절충점을 찾아야 한다.
2. 1. 작업의 특성
부하 분산 알고리즘의 효율성은 작업의 특성에 따라 결정적으로 달라진다. 따라서 의사 결정 시점에 작업에 대한 정보가 많을수록 최적화 가능성이 커진다.==== 작업의 크기 ====
각 작업의 실행 시간에 대한 완벽한 지식을 통해 최적의 부하 분산을 달성할 수 있다(접두사 합 알고리즘 참조).[1] 불행하게도, 이것은 사실 이상적인 경우이다. 각 작업의 정확한 실행 시간을 아는 것은 매우 드문 경우이다.
이러한 이유로, 서로 다른 실행 시간을 파악하기 위한 여러 가지 기술이 있다. 우선, 비교적 균일한 크기의 작업을 갖는 운이 좋은 시나리오에서는 각 작업이 대략 평균 실행 시간을 필요로 한다고 간주할 수 있다. 반면에 실행 시간이 매우 불규칙한 경우, 더 정교한 기술을 사용해야 한다. 한 가지 기술은 각 작업에 일부 메타데이터를 추가하는 것이다. 유사한 메타데이터에 대한 이전 실행 시간에 따라 통계를 기반으로 미래 작업에 대한 추론을 할 수 있다.[2]
==== 작업 간의 의존성 ====
어떤 경우에는 작업들이 서로 의존 관계를 가진다. 이러한 상호 의존성은 방향 비순환 그래프로 나타낼 수 있다. 직관적으로, 어떤 작업은 다른 작업이 완료되어야만 시작할 수 있다.
각 작업에 필요한 시간이 미리 알려져 있다고 가정할 때, 최적의 실행 순서는 총 실행 시간을 최소화해야 한다. 이는 NP-난해 문제이므로 정확하게 해결하기 어려울 수 있다. 작업 스케줄러와 같은 알고리즘은 메타 휴리스틱 방법을 사용하여 최적의 작업 분배를 계산한다.
==== 작업의 분할 가능성 ====
부하 분산 알고리즘 설계를 위해 중요한 또 다른 특징은 작업이 실행 중에 하위 작업으로 분해될 수 있다는 점이다. 이후에 제시될 "트리형 계산(Tree-Shaped Computation)" 알고리즘은 이러한 특성을 최대한 활용한다.
2. 1. 1. 작업의 크기
각 작업의 실행 시간에 대한 완벽한 지식을 통해 최적의 부하 분산을 달성할 수 있다(접두사 합 알고리즘 참조).[1] 불행하게도, 이것은 사실 이상적인 경우이다. 각 작업의 정확한 실행 시간을 아는 것은 매우 드문 경우이다.이러한 이유로, 서로 다른 실행 시간을 파악하기 위한 여러 가지 기술이 있다. 우선, 비교적 균일한 크기의 작업을 갖는 운이 좋은 시나리오에서는 각 작업이 대략 평균 실행 시간을 필요로 한다고 간주할 수 있다. 반면에 실행 시간이 매우 불규칙한 경우, 더 정교한 기술을 사용해야 한다. 한 가지 기술은 각 작업에 일부 메타데이터를 추가하는 것이다. 유사한 메타데이터에 대한 이전 실행 시간에 따라 통계를 기반으로 미래 작업에 대한 추론을 할 수 있다.[2]
2. 1. 2. 작업 간의 의존성
어떤 경우에는 작업들이 서로 의존 관계를 가진다. 이러한 상호 의존성은 방향 비순환 그래프로 나타낼 수 있다. 직관적으로, 어떤 작업은 다른 작업이 완료되어야만 시작할 수 있다.각 작업에 필요한 시간이 미리 알려져 있다고 가정할 때, 최적의 실행 순서는 총 실행 시간을 최소화해야 한다. 이는 NP-난해 문제이므로 정확하게 해결하기 어려울 수 있다. 작업 스케줄러와 같은 알고리즘은 메타 휴리스틱 방법을 사용하여 최적의 작업 분배를 계산한다.
2. 1. 3. 작업의 분할 가능성
부하 분산 알고리즘 설계를 위해 중요한 또 다른 특징은 작업이 실행 중에 하위 작업으로 분해될 수 있다는 점이다. 이후에 제시될 "트리형 계산(Tree-Shaped Computation)" 알고리즘은 이러한 특성을 최대한 활용한다.2. 2. 정적 및 동적 알고리즘
2. 2. 1. 정적 알고리즘
부하 분산 알고리즘은 작업 분배 시 시스템의 상태를 고려하지 않을 때 "정적"이라고 한다. 여기서 시스템 상태는 특정 프로세서의 부하 수준(때로는 과부하)과 같은 측정을 포함한다. 대신, 들어오는 작업의 도착 시간 및 리소스 요구 사항과 같은 전체 시스템에 대한 가정이 미리 이루어진다. 또한 프로세서 수, 각 프로세서의 성능 및 통신 속도가 알려져 있다.따라서 정적 부하 분산은 특정 성능 함수를 최소화하기 위해 알려진 일련의 작업을 사용 가능한 프로세서와 연결하는 것을 목표로 한다. 핵심은 이 성능 함수의 개념에 있다.
정적 부하 분산 기술은 일반적으로 부하를 분산하고 성능 함수를 최적화하는 라우터 또는 마스터를 중심으로 집중된다. 이 최소화는 분산될 작업과 관련된 정보를 고려하여 예상 실행 시간을 도출할 수 있다.
정적 알고리즘의 장점은 설정이 쉽고 비교적 규칙적인 작업(예: 웹사이트에서 HTTP 요청 처리)의 경우 매우 효율적이라는 것이다. 그러나 작업 할당에 약간의 통계적 변동이 있어 일부 컴퓨팅 장치에 과부하가 걸릴 수 있다.
2. 2. 2. 동적 알고리즘
동적 부하 분산 알고리즘은 정적 부하 분산 알고리즘과 달리 시스템 내 각 컴퓨팅 유닛(노드라고도 함)의 현재 부하를 고려한다. 이 방식에서, 작업은 과부하된 노드에서 부하가 적은 노드로 동적으로 이동하여 더 빠른 처리를 받을 수 있다. 이러한 알고리즘은 설계하기가 훨씬 더 복잡하지만, 특히 실행 시간이 작업마다 크게 다를 때 뛰어난 결과를 낼 수 있다.동적 부하 분산 아키텍처는 특정 노드가 작업 분담에 전념할 필요가 없으므로 더 모듈식일 수 있다. 작업이 주어진 시점의 상태에 따라 프로세서에 고유하게 할당되면, 이는 고유 할당이다. 반면에, 작업이 시스템의 상태와 그 변화에 따라 영구적으로 재분배될 수 있다면, 이를 동적 할당이라고 한다.[3] 분명히, 결정을 내리기 위해 과도한 통신을 필요로 하는 부하 분산 알고리즘은 전반적인 문제 해결 속도를 늦출 위험이 있다.
2. 3. 하드웨어 아키텍처
2. 3. 1. 이기종 장비
병렬 컴퓨팅 인프라는 종종 서로 다른 컴퓨팅 성능의 장치들로 구성되며, 이는 부하분산을 위해 고려해야 한다.예를 들어, 저전력 장치는 더 적은 양의 계산을 요구하는 요청을 받거나, 균일하거나 알 수 없는 요청 크기의 경우 더 큰 장치보다 적은 수의 요청을 받을 수 있다.
2. 3. 2. 공유 및 분산 메모리
병렬 컴퓨터는 크게 두 가지 범주로 나뉜다. 모든 프로세서가 병렬로 읽고 쓰는 단일 공통 메모리를 공유하는 컴퓨터(PRAM 모델)와 각 계산 유닛이 자체 메모리를 가지고 정보가 메시지를 통해 교환되는 컴퓨터(분산 메모리 모델)이다.공유 메모리 컴퓨터의 경우, 쓰기 충돌을 관리하면 각 계산 유닛의 개별 실행 속도가 크게 느려진다. 그러나 병렬로 완벽하게 작동할 수 있다. 반대로, 메시지 교환의 경우, 각 프로세서는 최대 속도로 작동할 수 있다. 다른 한편, 집단 메시지 교환의 경우, 모든 프로세서는 가장 느린 프로세서가 통신 단계를 시작할 때까지 기다려야 한다.
실제로, 이러한 범주 중 정확히 하나에 속하는 시스템은 거의 없다. 일반적으로 프로세서는 각각 다음 계산에 필요한 데이터를 저장하는 내부 메모리를 가지며 연속적인 클러스터로 구성된다. 종종, 이러한 처리 요소는 분산 메모리 및 메시지 전달을 통해 조정된다. 따라서 부하 분산 알고리즘은 병렬 아키텍처에 고유하게 적용되어야 한다. 그렇지 않으면 병렬 문제 해결의 효율성이 크게 감소할 위험이 있다.
2. 3. 3. 계층 구조
위에서 언급된 하드웨어 구조에 적응하기 위해, 부하 분산 알고리즘에는 크게 두 가지 범주가 있다. 한편으로는, "마스터"에 의해 작업이 할당되고 작업 진행 상황을 마스터에게 계속 알려주는 "워커"에 의해 실행되는 방식이 있다. 동적 알고리즘의 경우, 마스터는 부하 할당 또는 재할당을 담당할 수 있다. 문헌에서는 이를 "마스터-워커" 아키텍처라고 부른다. 다른 한편으로는, 제어가 서로 다른 노드들 사이에 분산될 수 있다. 그러면 부하 분산 알고리즘이 각 노드에서 실행되고, 작업 할당(적절하게 재할당 및 분할 포함)에 대한 책임이 공유된다. 마지막 범주는 동적 부하 분산 알고리즘을 가정한다.각 부하 분산 알고리즘의 설계는 고유하므로, 앞서 언급된 구분은 수정되어야 한다. 따라서, 예를 들어 각 서브 클러스터에 대한 "마스터" 노드가 있고, 이들이 글로벌 "마스터"의 지배를 받는 중간 전략을 가질 수도 있다. 또한, 마스터-슬레이브와 분산 제어 전략이 번갈아 사용되는 다단계 조직도 있다. 후자의 전략은 빠르게 복잡해지며 거의 사용되지 않는다. 설계자들은 제어하기 쉬운 알고리즘을 선호한다.
2. 3. 4. 확장성
컴퓨터 아키텍처는 시간이 지남에 따라 발전하지만, 장기간 실행되는 알고리즘(서버, 클라우드 등)의 경우 매번 새로운 알고리즘을 설계할 필요는 없는 것이 좋다.따라서 부하 분산 알고리즘의 매우 중요한 매개변수는 확장 가능한 하드웨어 아키텍처에 적응하는 능력이다. 이것을 알고리즘의 확장성이라고 한다. 알고리즘은 입력 매개변수의 크기에 관계없이 성능이 비교적 독립적으로 유지될 때 해당 입력 매개변수에 대해 확장 가능하다고 한다.
알고리즘이 다양한 수의 컴퓨팅 유닛에 적응할 수 있지만, 실행 전에 컴퓨팅 유닛 수를 고정해야 하는 경우, 이를 몰더블(moldable)이라고 한다. 반면에 알고리즘이 실행 중에 변동하는 양의 프로세서를 처리할 수 있는 경우, 해당 알고리즘을 멜리어블(malleable)이라고 한다. 대부분의 부하 분산 알고리즘은 적어도 몰더블하다.[4]
3. 접근 방식
3. 1. 작업에 대한 전체 지식을 사용한 정적 분산: 접두사 합
태스크들이 서로 독립적이고, 각 실행 시간과 태스크들을 세분화할 수 있다면, 간단하고 최적의 알고리즘이 존재한다.[1] 각 프로세서에 동일한 양의 계산을 할당하도록 태스크를 분할함으로써, 남은 작업은 결과를 함께 묶는 것뿐이다. 접두사 합 알고리즘을 사용하면, 프로세서 수에 대해 로그 시간 안에 이 분할을 계산할 수 있다.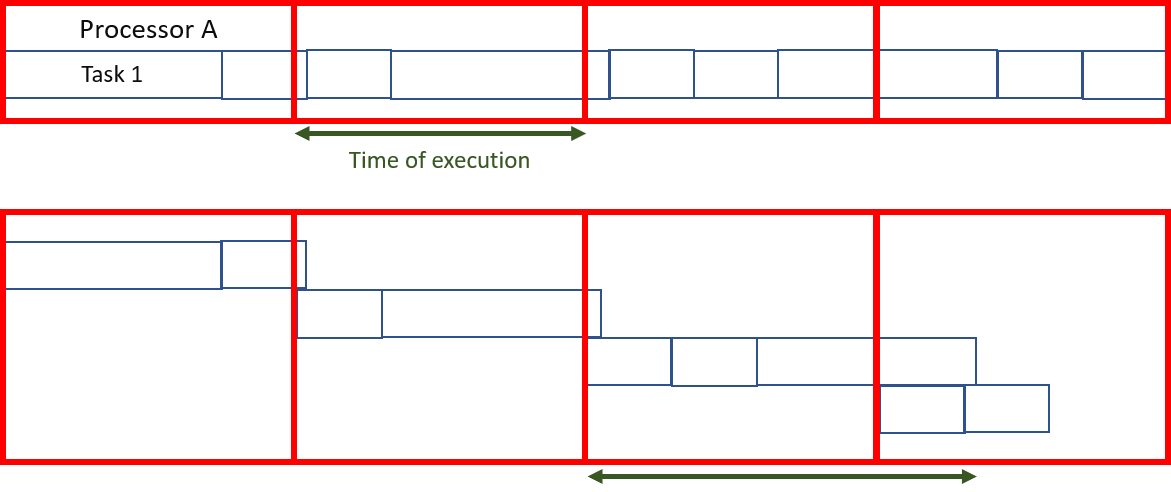
하지만, 태스크를 세분화할 수 없는 경우 (즉, 원자적인 경우), 태스크 할당을 최적화하는 것은 어려운 문제이지만, 각 태스크의 크기가 각 노드가 수행하는 총 계산량보다 훨씬 작다는 조건 하에 상대적으로 공정한 태스크 분배를 근사하는 것이 가능하다.[1]
대부분의 경우, 태스크의 실행 시간은 알 수 없으며 대략적인 근사치만 사용할 수 있다. 이 알고리즘은 특히 효율적이지만, 이러한 시나리오에는 적합하지 않다.
3. 2. 사전 지식 없는 정적 부하 분산
첫 번째 요청은 첫 번째 서버로 전송되고, 다음 요청은 두 번째 서버로 전송되며, 마지막 서버까지 이와 같이 진행된다. 그런 다음 다시 시작하여 다음 요청을 첫 번째 서버에 할당하는 식으로 진행된다.이 알고리즘은 가장 강력한 장치가 가장 많은 수의 요청을 먼저 받도록 가중치를 부여할 수 있다.
=== 무작위 정적 할당 ===
무작위 정적 부하 분산은 작업을 서로 다른 서버에 무작위로 할당하는 방식이다. 이 방법은 매우 잘 작동한다. 반면에, 작업 수를 미리 알고 있는 경우, 사전에 무작위 순열을 계산하는 것이 훨씬 더 효율적이다. 이렇게 하면 각 할당에 대한 통신 비용을 피할 수 있다. 더 이상 분산 마스터가 필요하지 않다. 모든 프로세서가 어떤 작업이 할당되었는지 알고 있기 때문이다. 작업 수를 알 수 없는 경우에도 모든 프로세서에 알려진 의사 무작위 할당 생성을 사용하여 통신을 피할 수 있다.
이 전략의 성능(지정된 고정 작업 집합에 대한 총 실행 시간으로 측정)은 작업의 최대 크기가 클수록 감소한다.
=== 기타 방법 ===
물론, 다른 할당 방법도 있다.
- 더 적은 작업: 덜 수행하여 서버에 더 많은 작업을 할당한다. (이 방법은 가중치를 부여할 수도 있다).
- 해시: 해시 테이블에 따라 쿼리를 할당한다.
- 두 가지 선택의 힘: 두 개의 서버를 무작위로 선택하고 두 가지 옵션 중 더 나은 것을 선택한다.[6][7]
3. 2. 1. 라운드 로빈 스케줄링
첫 번째 요청은 첫 번째 서버로 전송되고, 다음 요청은 두 번째 서버로 전송되며, 마지막 서버까지 이와 같이 진행된다. 그런 다음 다시 시작하여 다음 요청을 첫 번째 서버에 할당하는 식으로 진행된다.이 알고리즘은 가장 강력한 장치가 가장 많은 수의 요청을 먼저 받도록 가중치를 부여할 수 있다.
3. 2. 2. 무작위 정적 할당
무작위 정적 부하 분산은 작업을 서로 다른 서버에 무작위로 할당하는 방식이다. 이 방법은 매우 잘 작동한다. 반면에, 작업 수를 미리 알고 있는 경우, 사전에 무작위 순열을 계산하는 것이 훨씬 더 효율적이다. 이렇게 하면 각 할당에 대한 통신 비용을 피할 수 있다. 더 이상 분산 마스터가 필요하지 않다. 모든 프로세서가 어떤 작업이 할당되었는지 알고 있기 때문이다. 작업 수를 알 수 없는 경우에도 모든 프로세서에 알려진 의사 무작위 할당 생성을 사용하여 통신을 피할 수 있다.이 전략의 성능(지정된 고정 작업 집합에 대한 총 실행 시간으로 측정)은 작업의 최대 크기가 클수록 감소한다.
3. 2. 3. 기타 방법
물론, 다른 할당 방법도 있다.- 더 적은 작업: 덜 수행하여 서버에 더 많은 작업을 할당한다. (이 방법은 가중치를 부여할 수도 있다).
- 해시: 해시 테이블에 따라 쿼리를 할당한다.
- 두 가지 선택의 힘: 두 개의 서버를 무작위로 선택하고 두 가지 옵션 중 더 나은 것을 선택한다.[6][7]
3. 3. 마스터-워커 방식
마스터-워커 방식은 가장 단순한 동적 부하 분산 알고리즘 중 하나이다. 마스터는 모든 워커(때로는 "슬레이브"라고도 함)에게 작업을 분산한다. 처음에는 모든 워커가 유휴 상태이며 이를 마스터에게 보고한다. 마스터는 워커의 요청에 응답하고 워커에게 작업을 분산한다. 더 이상 할당할 작업이 없으면 워커에게 알리고 워커는 작업 요청을 중단한다.이 시스템의 장점은 부하를 매우 공정하게 분산한다는 것이다. 실제로 할당에 필요한 시간을 고려하지 않으면 실행 시간은 위에서 본 접두사 합과 비슷하다.
이 알고리즘의 문제점은 필요한 통신량이 많기 때문에 많은 수의 프로세서에 적응하기 어렵다는 것이다. 이러한 확장성 부족으로 인해 매우 큰 서버 또는 매우 큰 병렬 컴퓨터에서는 빠르게 작동하지 않게 된다. 마스터는 병목 현상 역할을 한다.
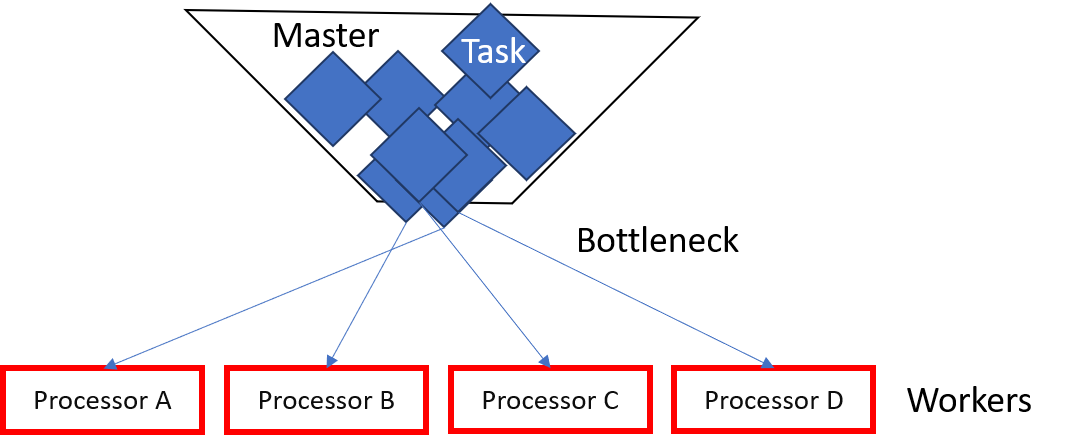
하지만 마스터를 다른 프로세서에서 사용할 수 있는 작업 목록으로 대체하면 알고리즘의 품질을 크게 향상시킬 수 있다. 이 알고리즘은 구현하기가 조금 더 어렵지만 매우 큰 컴퓨팅 센터에는 아직 부족하지만 훨씬 더 나은 확장성을 약속한다.
3. 4. 시스템에 대한 지식 없는 비계층적 아키텍처: 작업 훔치기
작업 훔치기는 작업 완료에 필요한 시간을 알 수 없을 때 사용되는 확장성 문제 해결 기법이다.이 방식은 각 프로세서에 특정 수의 작업을 할당한 다음, 비활성 프로세서가 활성 또는 과부하된 프로세서에서 작업을 "훔치도록" 허용하는 것이다. 작업 분할 모델과 프로세서 간 교환 규칙에 따라 여러 구현이 존재한다. 이 기법은 효과적이지만, 통신이 주요 작업이 되지 않도록 구현하기 어렵다.[8]
원자적 작업의 경우, 두 가지 주요 전략이 있다. 부하가 낮은 프로세서가 가장 높은 부하를 가진 프로세서에게 컴퓨팅 능력을 제공하거나, 가장 부하가 높은 유닛이 할당된 워크로드를 줄이려고 하는 경우이다. 네트워크 과부하 시에는 부하가 가장 적은 유닛이 가용성을 제공하는 것이, 네트워크 부하가 적을 때는 과부하된 프로세서가 가장 비활성적인 프로세서의 지원을 받는 것이 더 효율적이다.[8] 이러한 규칙은 교환되는 메시지 수를 제한한다.
원자적 수준 이상으로 분할할 수 없는 단일 대규모 작업에서 시작하는 경우, "트리형 계산"이라는 매우 효율적인 알고리즘이 있다. 여기서 상위 작업은 작업 트리로 분산된다.[9]
3. 4. 1. 원리
초기에 많은 프로세서는 빈 작업을 가지며, 순차적으로 작업을 처리하는 프로세서가 하나 있다. 유휴 프로세서는 다른 프로세서(반드시 활성 상태일 필요는 없음)에게 무작위로 요청을 보낸다. 후자가 자신이 처리하고 있는 작업을 세분화할 수 있다면, 요청을 보낸 노드에 작업의 일부를 전송함으로써 그렇게 한다. 그렇지 않은 경우 빈 작업을 반환한다. 이는 트리 구조를 유발한다. 그런 다음 하위 작업이 완료되면 종료 신호를 상위 프로세서로 전송하여, 상위 프로세서가 다시 상위 프로세서로 메시지를 보내 트리의 루트에 도달하게 해야 한다. 첫 번째 프로세서, 즉 루트가 완료되면 전체 종료 메시지를 브로드캐스트할 수 있다. 마지막으로, 트리를 거슬러 올라가면서 결과를 조립해야 한다.3. 4. 2. 효율성
이러한 알고리즘의 효율성은 작업 분할 및 통신 시간이 수행해야 할 작업에 비해 너무 높지 않을 때 접두사 합과 유사하다. 통신 비용이 너무 높아지는 것을 방지하기 위해 공유 메모리에 작업 목록을 상상할 수 있다. 따라서 요청은 마스터 프로세서의 요청에 따라 이 공유 메모리의 특정 위치에서 읽는 것으로 간단하게 수행된다.4. 사용 사례
부하 분산 알고리즘은 HTTP 요청 관리에도 널리 사용된다. 이는 초당 많은 요청을 처리해야 하는 웹사이트에서 특히 중요하다.
==== 인터넷 기반 서비스 ====
부하 분산은 여러 서버에서 단일 인터넷 서비스를 제공하는 데 사용되며, 이를 서버 팜이라고도 부른다. 일반적으로 부하 분산 시스템에는 인기 있는 웹 사이트, 대규모 인터넷 릴레이 챗 네트워크, 고대역폭 FTP 사이트, NNTP 서버, DNS 서버 및 데이터베이스가 포함된다.
==== 라운드 로빈 DNS ====
라운드 로빈 DNS는 전용 소프트웨어나 하드웨어 없이 부하 분산을 구현하는 방법이다. 여러 IP 주소를 단일 도메인 이름에 연결하고, 클라이언트에게 IP를 순차적으로 제공한다. IP는 짧은 만료 시간으로 할당되어, 클라이언트가 다음에 접속할 때 다른 IP를 사용할 가능성을 높인다.
==== DNS 위임 ====
각 서버가 자체 IP 주소를 A 레코드로 해석하도록 DNS 설정을 구성한다.[10] 예를 들면 다음과 같다.
:one.example.org A 192.0.2.1
:two.example.org A 203.0.113.2
:www.example.org NS one.example.org
:www.example.org NS two.example.org
하지만 각 서버의 ''www.example.org''에 대한 구역 파일은 서로 다르다. 서버 ''one''에서는 다음과 같다.
:@ in a 192.0.2.1
서버 ''two''에서는 다음과 같다.
:@ in a 203.0.113.2
서버가 다운되면 해당 DNS는 응답하지 않아 웹 서비스 트래픽을 받지 않는다. 회선 혼잡 시 DNS 불안정성으로 HTTP 트래픽이 감소한다. 또한, 가장 빠른 DNS 응답은 네트워크에서 가장 가까운 서버에서 오므로 지리적 부하 분산이 보장된다. A 레코드에 짧은 TTL을 사용하여 서버 다운 시 트래픽을 빠르게 전환할 수 있다.
==== 클라이언트 측 무작위 부하 분산 ====
클라이언트 측 무작위 부하 분산은 서버 IP 목록을 클라이언트에 전달하고, 클라이언트가 연결 시 무작위로 IP를 선택하는 방식이다.[11][12] 대수의 법칙[12]에 따라 서버 간 균등한 부하 분산을 달성한다. 라운드 로빈 DNS보다 나은 부하 분산을 제공한다고 알려져 있는데, 이는 DNS 캐싱 문제없이 작동하기 때문이다.[12]
IP 목록 전달 방법은 다양하며, DNS 목록이나 하드 코딩으로 구현할 수 있다. "스마트 클라이언트"는 서버 다운을 감지하고 다시 연결하여 결함 허용 기능을 제공한다.
==== 서버 측 로드 밸런서 ====
서버 측 부하 분산기(로드 밸런서)는 포트를 감시하는 소프트웨어다. 요청을 백엔드 서버 중 하나로 전달하고, 백엔드 서버는 부하 분산기에 응답한다. 클라이언트는 내부 기능 분리를 알지 못하고, 백엔드 서버 직접 접속이 방지되어 보안상 이점이 있다.[13]
일부 부하 분산기는 백엔드 서버 사용 불가 시 백업 전달, 메시지 표시 등의 기능을 제공한다.
부하 분산기 자체는 단일 실패 지점이 되지 않도록 고가용성 쌍으로 구현된다.[13] 특정 애플리케이션은 네트워크를 넘어 공유 플랫폼을 통해 부하 분산 지점을 상쇄하기도 한다.[14]
==== 통신 ====
회사는 여러 인터넷 연결을 통해 네트워크 접속을 보장한다. 페일오버 구성은 하나의 링크를 주 링크로, 다른 링크는 기본 링크 실패 시 사용한다.
부하 분산을 사용하면 두 링크를 항상 사용할 수 있다. 장치나 프로그램은 링크 가용성을 모니터링하고 패킷 전송 경로를 선택한다. 여러 링크 동시 사용은 가용 대역폭을 증가시킨다.
==== 최단 경로 브리징 ====
TRILL(Transparent Interconnection of Lots of Links)은 이더넷이 임의 토폴로지를 갖도록 지원하며, 다익스트라 알고리즘을 통해 흐름 쌍별 부하 분산을 가능하게 한다.[16][17]
IEEE는 2012년 5월 IEEE 802.1aq 표준(최단 경로 브리징, SPB)을 승인했다. SPB는 모든 링크가 여러 경로를 통해 활성화되도록 하고, 빠른 수렴 시간으로 다운타임을 줄이며, 트래픽이 네트워크 모든 경로에서 부하를 분산하도록 하여 메시 네트워크 토폴로지에서 부하 분산 사용을 단순화한다.[23][24] SPB는 구성 중 인적 오류를 제거하고, 플러그 앤 플레이 특성을 유지한다.[25]
==== 라우팅 ====
많은 통신 회사들은 네트워크 내/외부에 여러 경로를 가진다. 정교한 부하 분산을 사용하여 네트워크 정체를 피하고, 전송 비용 최소화, 네트워크 신뢰성 향상을 위해 트래픽을 이동시킨다.[26]
==== 데이터 센터 네트워크 ====
부하 분산은 데이터 센터 네트워크에서 임의의 두 서버 간 많은 경로에 트래픽을 분산시키는 데 사용된다.[27] 이는 네트워크 대역폭 효율성을 높이고 프로비저닝 비용을 절감한다.
정적 부하 분산은 트래픽 흐름의 소스 및 대상 주소, 포트 번호를 해싱하여 트래픽을 분산시키고, 흐름이 경로에 할당되는 방식을 결정한다. 동적 부하 분산은 경로의 대역폭 사용을 모니터링하여 트래픽을 할당한다. 동적 할당은 사전 예방적 또는 사후 대응적일 수 있다. 전자는 할당 후 고정, 후자는 네트워크 사용률 변화에 따라 흐름을 전환한다.
==== 페일오버 ====
부하 분산은 구성 요소 장애 후에도 서비스를 지속하는 페일오버 구현에 사용된다.[28] 구성 요소는 지속적으로 모니터링되며, 응답하지 않으면 로드 밸런서는 트래픽을 보내지 않는다.[28] 구성 요소가 온라인 상태가 되면 트래픽을 다시 라우팅한다.[28]
이를 위해 서비스 용량보다 최소 하나 이상의 구성 요소가 필요하다(N+1 중복성).[28] 이는 이중 모듈 중복성보다 저렴하고 유연하다.[28] 일부 RAID 시스템은 핫 스페어를 활용한다.[28]
4. 1. 인터넷 기반 서비스
부하 분산은 여러 서버에서 단일 인터넷 서비스를 제공하는 데 사용되며, 때로는 서버 팜이라고도 불린다. 일반적으로 부하 분산 시스템에는 인기 있는 웹 사이트, 대규모 인터넷 릴레이 챗 네트워크, 고대역폭 파일 전송 프로토콜 (FTP) 사이트, 네트워크 뉴스 전송 프로토콜 (NNTP) 서버, 도메인 네임 시스템 (DNS) 서버 및 데이터베이스가 포함된다.==== 라운드 로빈 DNS ====
라운드 로빈 DNS는 전용 소프트웨어나 하드웨어 노드가 필요하지 않은 부하 분산의 대체 방법이다. 이 기법에서는 여러 개의 IP 주소가 단일 도메인 이름과 연결되며, 클라이언트에게 IP가 라운드 로빈 방식으로 제공된다. IP는 짧은 만료 시간과 함께 클라이언트에 할당되므로 클라이언트는 다음에 요청하는 인터넷 서비스에 액세스할 때 다른 IP를 사용할 가능성이 더 높다.
==== DNS 위임 ====
각 서버가 자체 IP 주소를 A 레코드로 해석하도록 DNS 설정을 구성한다. 예를 들어 다음과 같다.[10]
:one.example.org A 192.0.2.1
:two.example.org A 203.0.113.2
:www.example.org NS one.example.org
:www.example.org NS two.example.org
하지만 각 서버의 에 대한 구역 파일은 각 서버가 자체 IP 주소를 A 레코드로 해석하도록 서로 다르다. 서버 ''one''에서 의 구역 파일은 다음과 같이 보고한다.
:@ in a 192.0.2.1
서버 ''two''에서 동일한 구역 파일에는 다음이 포함된다.
:@ in a 203.0.113.2
이런 방식으로 서버가 다운되면 해당 DNS가 응답하지 않으며 웹 서비스는 트래픽을 수신하지 않는다. 한 서버로 가는 회선이 혼잡하면 DNS의 불안정성으로 인해 해당 서버에 도달하는 HTTP 트래픽이 줄어든다. 또한, 리졸버에 대한 가장 빠른 DNS 응답은 거의 항상 네트워크에서 가장 가까운 서버에서 오는 것이므로 지리적 위치에 민감한 부하 분산이 보장된다. A 레코드에 짧은 TTL을 사용하면 서버가 다운될 때 트래픽이 빠르게 전환되도록 할 수 있다.
==== 클라이언트 측 무작위 부하 분산 ====
클라이언트 측 무작위 부하 분산은 서버 IP 목록을 클라이언트에 전달한 다음, 각 연결 시 클라이언트가 목록에서 무작위로 IP를 선택하는 방식이다.[11][12] 이는 본질적으로 모든 클라이언트가 유사한 부하를 생성하고, 대수의 법칙[12]에 따라 서버 간에 비교적 균등한 부하 분산을 달성하는 데 의존한다. 클라이언트 측 무작위 부하 분산은 라운드 로빈 DNS보다 더 나은 부하 분산을 제공하는 경향이 있다고 주장되어 왔다. 이는 대규모 DNS 캐싱 서버의 경우 라운드 로빈 DNS의 분산을 왜곡하는 라운드 로빈 DNS의 캐싱 문제로 인해 발생하며, 클라이언트 측 무작위 선택은 DNS 캐싱과 관계없이 영향을 받지 않기 때문이다.[12]
이 방식에서, 클라이언트에 IP 목록을 전달하는 방법은 다양할 수 있으며, DNS 목록(라운드 로빈 없이 모든 클라이언트에 전달) 또는 목록에 하드 코딩하여 구현할 수 있다. "스마트 클라이언트"를 사용하면, 무작위로 선택된 서버가 다운되었음을 감지하고 다시 무작위로 연결하여 결함 허용 기능도 제공한다.
==== 서버 측 로드 밸런서 ====
서버 측 부하 분산기(로드 밸런서)는 인터넷 서비스에서 일반적으로 외부 클라이언트가 서비스에 접속하기 위해 연결하는 포트를 감시하는 소프트웨어 프로그램이다. 부하 분산기는 요청을 "백엔드" 서버 중 하나로 전달하며, 백엔드 서버는 일반적으로 부하 분산기에 응답한다. 이를 통해 부하 분산기는 클라이언트가 내부 기능의 분리를 알지 못하는 상태에서 클라이언트에 응답할 수 있다. 또한 클라이언트가 백엔드 서버에 직접 접속하는 것을 방지하여 내부 네트워크의 구조를 숨기고 커널의 네트워크 스택 또는 다른 포트에서 실행되는 관련 없는 서비스에 대한 공격을 방지함으로써 보안상의 이점을 제공할 수 있다.[13]
일부 부하 분산기는 모든 백엔드 서버를 사용할 수 없는 경우 특별한 작업을 수행하는 메커니즘을 제공한다. 여기에는 백업 부하 분산기로의 전달 또는 중단 관련 메시지 표시 등이 포함될 수 있다.
또한 부하 분산기 자체가 단일 실패 지점이 되지 않도록 하는 것이 중요하다. 일반적으로 부하 분산기는 특정 애플리케이션에서 필요로 하는 경우 세션 지속성 데이터를 복제할 수도 있는 고가용성 쌍으로 구현된다.[13] 특정 애플리케이션은 정의된 네트워크를 넘어 차등 공유 플랫폼을 통해 부하 분산 지점을 상쇄하여 이 문제에 면역이 되도록 프로그래밍된다. 이러한 기능에 페어링된 순차적 알고리즘은 특정 데이터베이스에 고유한 유연한 매개변수에 의해 정의된다.[14]
4. 1. 1. 라운드 로빈 DNS
라운드 로빈 DNS는 전용 소프트웨어나 하드웨어 노드가 필요하지 않은 부하 분산의 대체 방법이다. 이 기법에서는 여러 개의 IP 주소가 단일 도메인 이름과 연결되며, 클라이언트에게 IP가 라운드 로빈 방식으로 제공된다. IP는 짧은 만료 시간과 함께 클라이언트에 할당되므로 클라이언트는 다음에 요청하는 인터넷 서비스에 액세스할 때 다른 IP를 사용할 가능성이 더 높다.4. 1. 2. DNS 위임
각 서버가 자체 IP 주소를 A 레코드로 해석하도록 DNS 설정을 구성한다. 예를 들어 다음과 같다.[10]:one.example.org A 192.0.2.1
:two.example.org A 203.0.113.2
:www.example.org NS one.example.org
:www.example.org NS two.example.org
하지만 각 서버의 에 대한 구역 파일은 각 서버가 자체 IP 주소를 A 레코드로 해석하도록 서로 다르다. 서버 ''one''에서 의 구역 파일은 다음과 같이 보고한다.
:@ in a 192.0.2.1
서버 ''two''에서 동일한 구역 파일에는 다음이 포함된다.
:@ in a 203.0.113.2
이런 방식으로 서버가 다운되면 해당 DNS가 응답하지 않으며 웹 서비스는 트래픽을 수신하지 않는다. 한 서버로 가는 회선이 혼잡하면 DNS의 불안정성으로 인해 해당 서버에 도달하는 HTTP 트래픽이 줄어든다. 또한, 리졸버에 대한 가장 빠른 DNS 응답은 거의 항상 네트워크에서 가장 가까운 서버에서 오는 것이므로 지리적 위치에 민감한 부하 분산이 보장된다. A 레코드에 짧은 TTL을 사용하면 서버가 다운될 때 트래픽이 빠르게 전환되도록 할 수 있다.
4. 1. 3. 클라이언트 측 무작위 부하 분산
클라이언트 측 무작위 부하 분산은 서버 IP 목록을 클라이언트에 전달한 다음, 각 연결 시 클라이언트가 목록에서 무작위로 IP를 선택하는 방식이다.[11][12] 이는 본질적으로 모든 클라이언트가 유사한 부하를 생성하고, 대수의 법칙[12]에 따라 서버 간에 비교적 균등한 부하 분산을 달성하는 데 의존한다. 클라이언트 측 무작위 부하 분산은 라운드 로빈 DNS보다 더 나은 부하 분산을 제공하는 경향이 있다고 주장되어 왔다. 이는 대규모 DNS 캐싱 서버의 경우 라운드 로빈 DNS의 분산을 왜곡하는 라운드 로빈 DNS의 캐싱 문제로 인해 발생하며, 클라이언트 측 무작위 선택은 DNS 캐싱과 관계없이 영향을 받지 않기 때문이다.[12]이 방식에서, 클라이언트에 IP 목록을 전달하는 방법은 다양할 수 있으며, DNS 목록(라운드 로빈 없이 모든 클라이언트에 전달) 또는 목록에 하드 코딩하여 구현할 수 있다. "스마트 클라이언트"를 사용하면, 무작위로 선택된 서버가 다운되었음을 감지하고 다시 무작위로 연결하여 결함 허용 기능도 제공한다.
4. 1. 4. 서버 측 로드 밸런서
서버 측 부하 분산기(로드 밸런서)는 인터넷 서비스에서 일반적으로 외부 클라이언트가 서비스에 접속하기 위해 연결하는 포트를 감시하는 소프트웨어 프로그램이다. 부하 분산기는 요청을 "백엔드" 서버 중 하나로 전달하며, 백엔드 서버는 일반적으로 부하 분산기에 응답한다. 이를 통해 부하 분산기는 클라이언트가 내부 기능의 분리를 알지 못하는 상태에서 클라이언트에 응답할 수 있다. 또한 클라이언트가 백엔드 서버에 직접 접속하는 것을 방지하여 내부 네트워크의 구조를 숨기고 커널의 네트워크 스택 또는 다른 포트에서 실행되는 관련 없는 서비스에 대한 공격을 방지함으로써 보안상의 이점을 제공할 수 있다.[13]일부 부하 분산기는 모든 백엔드 서버를 사용할 수 없는 경우 특별한 작업을 수행하는 메커니즘을 제공한다. 여기에는 백업 부하 분산기로의 전달 또는 중단 관련 메시지 표시 등이 포함될 수 있다.
또한 부하 분산기 자체가 단일 실패 지점이 되지 않도록 하는 것이 중요하다. 일반적으로 부하 분산기는 특정 애플리케이션에서 필요로 하는 경우 세션 지속성 데이터를 복제할 수도 있는 고가용성 쌍으로 구현된다.[13] 특정 애플리케이션은 정의된 네트워크를 넘어 차등 공유 플랫폼을 통해 부하 분산 지점을 상쇄하여 이 문제에 면역이 되도록 프로그래밍된다. 이러한 기능에 페어링된 순차적 알고리즘은 특정 데이터베이스에 고유한 유연한 매개변수에 의해 정의된다.[14]
4. 2. 통신
회사는 여러 개의 인터넷 연결을 가질 수 있는데, 이는 하나의 연결이 실패하더라도 네트워크 접속을 보장하기 위함이다. 페일오버 구성은 하나의 링크를 주 사용 링크로 지정하고, 두 번째 링크는 기본 링크가 실패할 경우에만 사용한다.부하 분산을 사용하면 두 링크를 항상 사용할 수 있다. 장치나 프로그램은 모든 링크의 가용성을 모니터링하고 패킷을 전송할 경로를 선택한다. 여러 링크를 동시에 사용하면 사용 가능한 대역폭이 증가한다.
4. 2. 1. 최단 경로 브리징
TRILL(Transparent Interconnection of Lots of Links)은 이더넷이 임의의 토폴로지를 갖도록 지원하며, 구성 및 사용자 개입 없이 다익스트라 알고리즘을 통해 흐름 쌍별 부하 분산을 가능하게 한다.[16][17] Rbridges[18] [sic]의 개념은 2004년에 전기 전자 기술자 협회에 처음 제안되었으며,[19] 2005년에[20] TRILL로 알려지게 된 것을 거부하고 2006년부터 2012년까지[21] 최단 경로 브리징으로 알려진 호환되지 않는 변형을 고안했다.IEEE는 2012년 5월에 IEEE 802.1aq 표준을 승인했으며, 이는 최단 경로 브리징(SPB)으로도 알려져 있다. SPB는 모든 링크가 여러 개의 동일 비용 경로를 통해 활성화되도록 허용하고, 다운타임을 줄이기 위해 더 빠른 수렴 시간을 제공하며, 트래픽이 네트워크의 모든 경로에서 부하를 분산하도록 허용함으로써 메시 네트워크 토폴로지 (부분적으로 연결되거나 완전히 연결된)에서 부하 분산 사용을 단순화한다.[23][24] SPB는 구성 중 인적 오류를 사실상 제거하도록 설계되었으며, 이더넷을 레이어 2에서 사실상의 프로토콜로 확립한 플러그 앤 플레이 특성을 유지한다.[25]
4. 2. 2. 라우팅
많은 통신 회사들은 자사 네트워크 또는 외부 네트워크를 통해 여러 경로를 가지고 있다. 그들은 정교한 부하 분산을 사용하여 특정 링크의 네트워크 정체를 피하고, 때로는 외부 네트워크를 통한 전송 비용을 최소화하거나 네트워크 신뢰성을 향상시키기 위해 트래픽을 한 경로에서 다른 경로로 이동시킨다.[26]4. 2. 3. 데이터 센터 네트워크
부하 분산은 임의의 두 서버 간에 존재하는 많은 경로에 트래픽을 분산시키기 위해 데이터 센터 네트워크에서 널리 사용된다.[27] 이는 네트워크 대역폭을 보다 효율적으로 사용하고 프로비저닝 비용을 절감할 수 있게 해준다. 일반적으로 데이터 센터 네트워크의 부하 분산은 정적 또는 동적으로 분류할 수 있다.정적 부하 분산은 트래픽 흐름의 소스 및 대상 주소와 포트 번호를 해싱하여 트래픽을 분산시키고, 이를 사용하여 흐름이 기존 경로 중 하나에 할당되는 방식을 결정한다. 동적 부하 분산은 서로 다른 경로의 대역폭 사용을 모니터링하여 트래픽 흐름을 경로에 할당한다. 동적 할당은 사전 예방적이거나 사후 대응적일 수도 있다. 전자의 경우, 할당이 이루어지면 고정되는 반면, 후자의 경우 네트워크 로직은 사용 가능한 경로를 계속 모니터링하고 네트워크 사용률이 변경됨에 따라(새로운 흐름이 도착하거나 기존 흐름이 완료됨에 따라) 흐름을 전환한다. 데이터 센터 네트워크의 부하 분산에 대한 포괄적인 개요가 제공되었다.[27]
4. 3. 페일오버
부하 분산은 하나 이상의 구성 요소 장애 후에도 서비스를 지속하는 페일오버를 구현하는 데 사용된다.[28] 구성 요소는 지속적으로 모니터링되며, 응답하지 않게 되면 로드 밸런서는 더 이상 트래픽을 보내지 않는다.[28] 구성 요소가 다시 온라인 상태가 되면 로드 밸런서는 트래픽을 다시 라우팅하기 시작한다.[28]이것이 작동하려면 서비스 용량보다 최소한 하나의 구성 요소가 더 있어야 한다(N+1 중복성).[28] 이는 모든 단일 라이브 구성 요소가 장애 발생 시 인계받는 단일 백업 구성 요소와 쌍을 이루는 페일오버 접근 방식(이중 모듈 중복성)보다 훨씬 저렴하고 유연할 수 있다.[28] 일부 RAID 시스템은 유사한 효과를 위해 핫 스페어를 활용할 수도 있다.[28]
5. 로드 밸런서의 기능 (일본어 문서 내용)
로드 밸런서는 다음과 같은 기능을 제공한다.
- SSL 오프로드 및 가속: SSL 애플리케이션은 웹 서버에 부담을 주며, 특히 CPU 시간을 소모한다. 로드 밸런서는 SSL 오프로드 기능을 통해 이러한 부담을 줄여준다.
- 보안 원격 액세스 (SSL-VPN)
- DDoS 공격 방어
- 압축
- TCP 부하 감소
- 클라이언트 유지 연결
- TCP 버퍼링
- 통합 로깅
- 애플리케이션 캐싱
- TCP 압축
- 콘텐츠 필터링
- 우선 순위별 큐잉
- 콘텐츠 전환
- 캐시 리디렉션
- 광역 서버 부하 분산 (GSLB)
- 링크 부하 분산
6. 로드 밸런싱 기법 (일본어 문서 내용)
로드 밸런싱 기법에는 여러 가지가 있다. 최소 커넥션 방식은 클라이언트와의 커넥션 수가 가장 적은 서버를 선택하는 방식이다. DNS 라운드 로빈도 널리 사용되는 기법 중 하나이다. 컴퓨터 클러스터를 구현하는 소프트웨어에는 일반적으로 부하 분산 기능이 포함되어 있는 경우가 많다.
7. 웹 서버에서의 기법 (일본어 문서 내용)
위키미디어 재단은 2004년 6월 당시 다음과 같은 방법들을 조합하여 부하 분산을 수행했다.
- DNS 라운드 로빈을 통해 페이지 요청을 3대의 스퀴드 서버에 균등하게 분산시켰다.
- 스퀴드 서버는 응답 시간을 측정하여 7대의 웹 서버에 페이지 요청을 분산시켰다. 스퀴드의 캐시를 통해 요청의 75%는 웹 서버에 부담을 주지 않고 응답할 수 있었다.
- 각 웹 서버에서는 PHP 스크립트가 작동하여 요청 유형에 따라 여러 데이터베이스 서버에 부하를 분산했다. 업데이트 요청은 마스터 데이터베이스로 전달되었지만, 쿼리는 여러 슬레이브 데이터베이스로 분산되었다.
이 외에도 레이어 4 스위치를 사용한 방법이나, 오픈 소스 부하 분산 기능인 Linux Virtual Server를 사용하는 방법이 있다. UNIX 계열 시스템에서의 부하 분산 방법으로는 리버스 프록시가 있으며, HAProxy 등이 있다. 적절한 모듈 구성을 통해 아파치나 Lighttpd 등의 웹 서버도 리버스 프록시 역할을 수행할 수 있다.
8. 무선 LAN에서의 부하 분산 (일본어 문서 내용)
무선 LAN 컨트롤러는 무선 LAN에서 다수의 클라이언트가 접속하고 있는 액세스 포인트에 대한 신규 접속을 중단하고, 접속하고 있는 클라이언트가 적은 액세스 포인트에 신규 클라이언트를 할당함으로써 하나의 액세스 포인트에 대한 액세스 집중을 방지한다. 한편, 채널 본딩이나 MIMO는 처리량을 향상시키지만, 부하 분산에는 해당하지 않는다.
9. 주요 로드 밸런서 제조 기업 (일본어 문서 내용)
아스타로, 알레이 네트웍스, F5 네트웍스, 시스코 시스템즈, 주니퍼 네트웍스, 시트릭스 시스템즈, 노텔, 바라쿠다 네트웍스, 바리오세큐어, 파운드리 네트웍스, 포티넷(Fortinet), 후지쯔 (IPCOM EX LB 시리즈) 등이 주요 로드 밸런서 제조 기업이다.
참조
[1]
서적
Sequential and parallel algorithms and data structures : the basic toolbox
Springer
2019-09-11
[2]
논문
Estimation Accuracy on Execution Time of Run-Time Tasks in a Heterogeneous Distributed Environment
2016-08-30
[3]
논문
A Guide to Dynamic Load Balancing in Distributed Computer Systems
https://www.research[...]
2009-11
[4]
서적
2013 42nd International Conference on Parallel Processing
2013-10
[5]
서적
2015 2nd International Conference on Electronics and Communication Systems (ICECS)
2015
[6]
웹사이트
NGINX and the "Power of Two Choices" Load-Balancing Algorithm
https://www.nginx.co[...]
2018-11-12
[7]
웹사이트
Test Driving "Power of Two Random Choices" Load Balancing
https://www.haproxy.[...]
2019-02-15
[8]
논문
A comparison of receiver-initiated and sender-initiated adaptive load sharing
1986-03-01
[9]
논문
Tree Shaped Computations as a Model for Parallel Applications
1998
[10]
문서
IPv4 Address Record (A)
http://www.zytrax.co[...]
[11]
문서
Pattern: Client Side Load Balancing
https://gameserverar[...]
[12]
문서
MMOG Server-Side Architecture. Front-End Servers and Client-Side Random Load Balancing
http://ithare.com/ch[...]
[13]
웹사이트
High Availability
http://www.linuxvirt[...]
linuxvirtualserver.org
2013-11-20
[14]
논문
Peer-to-peer cloud provisioning: Service discovery and load-balancing
2010
[15]
웹사이트
Load Balancing 101: Nuts and Bolts
https://f5.com/resou[...]
F5 Networks
2018-03-23
[16]
웹사이트
All Systems Down
https://community.ci[...]
IDG Communications, Inc.
2022-01-09
[17]
웹사이트
All Systems Down
https://www.computer[...]
IDG Communications, Inc.
2022-01-09
[18]
웹사이트
Rbridges: Transparent Routing
https://courses.cs.w[...]
Radia Perlman, Sun Microsystems Laboratories
2022-01-09
[19]
웹사이트
Rbridges: Transparent Routing
https://www.research[...]
Radia Perlman, Sun Microsystems; Donald Eastlake 3rd, Motorola
[20]
웹사이트
TRILL Tutorial
http://www.postel.or[...]
Donald E. Eastlake 3rd, Huawei
[21]
웹사이트
IEEE 802.1: 802.1aq - Shortest Path Bridging
https://ieee802.org/[...]
Institute of Electrical and Electronics Engineers
[22]
웹사이트
IEEE APPROVES NEW IEEE 802.1aq™ SHORTEST PATH BRIDGING STANDARD
http://standards.iee[...]
IEEE
2012-06-02
[23]
웹사이트
Shortest Path Bridging IEEE 802.1aq Overview
http://meetings.apni[...]
Huawei
2012-05-11
[24]
웹사이트
Largest Illinois healthcare system uproots Cisco to build $40M private cloud
http://www.pcadvisor[...]
PC Advisor
2012-05-11
[25]
뉴스
IEEE Approves New IEEE 802.1aq Shortest Path Bridging Standard
http://www.techpower[...]
Tech Power Up
2012-05-11
[26]
간행물
Minimizing Flow Completion Times using Adaptive Routing over Inter-Datacenter Wide Area Networks
https://www.research[...]
2019-01-06
[27]
간행물
Datacenter Traffic Control: Understanding Techniques and Trade-offs
https://www.research[...]
[28]
문서
Failover and load balancing
https://www.ibm.com/[...]
IBM
2019-01-06
[29]
간행물
Performance Tradeoffs in Static and Dynamic Load Balancing Strategies
https://ntrs.nasa.go[...]
NASA
1986-03
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com