텍스트 마이닝
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
텍스트 마이닝은 언어학, 통계학, 기계 학습 기술을 활용하여 텍스트 소스의 정보 내용을 모델링하고 구조화하는 방법이다. 텍스트 마이닝은 1990년대 중반까지 텍스트 해석, 문서 해석 등으로 불리다가 1990년대 후반부터 텍스트 데이터 마이닝 등으로 불렸으며, 현재는 텍스트 애널리틱스 또는 텍스트 애널리시스로 불리기도 한다. 텍스트 마이닝은 텍스트 분석, 텍스트 시각화, 텍스트 마이닝의 효과, 응용 분야, 관련 도구, 지적 재산권 등 다양한 측면에서 연구 및 활용되고 있다.
더 읽어볼만한 페이지
- 본문 - 텍스트 처리
텍스트 처리는 텍스트 편집 응용 프로그램이 아닌 유틸리티로, 표준화된 원시 데이터를 사용하며 정규 표현식과 필터를 활용하여 입력 스트림에 간접적으로 영향을 미치는 자체 자동화된 방식이다. - 본문 - 텍스트 (문학이론)
텍스트(문학이론)는 단어의 짜임새와 구성을 강조하는 웅변술에서 유래되었으며, 문학 이론에서 차용되어 현대 사회의 다양한 작업 방식을 분석하는 데 활용되고, 끊임없이 해석되고 재구성되는 열린 구조로 이해된다. - 통계적 자연어 처리 - 확률적 앵무새
확률적 앵무새는 거대 언어 모델이 의미를 이해하지 못하고 확률적으로 단어를 연결하여 텍스트를 생성하는 것을 앵무새에 비유한 용어로, 환경적 비용, 편향성, 허위 정보 생성 가능성 등의 위험성을 경고하며 LLM의 이해 능력에 대한 논쟁을 불러일으킨다. - 통계적 자연어 처리 - 언어 모델
언어 모델은 단어 시퀀스에 확률을 할당하는 통계적 모델로서 자연어 처리 분야에서 중요한 역할을 하며, 초기 마르코프 과정 기반 모델에서 지수 함수 모델, 신경망 모델을 거쳐 음성 입력 모델 등 다양한 형태로 연구되고, 벤치마크 데이터 세트를 통해 성능이 평가된다. - 전산언어학 - 알고리즘
알고리즘은 문제 해결을 위한 명확하고 순서화된 유한 개의 규칙 집합으로, 알콰리즈미의 이름에서 유래되었으며, 수학 문제 해결 절차로 사용되다가 컴퓨터 과학에서 중요한 역할을 하며 다양한 방식으로 표현되고 효율성 분석을 통해 평가된다. - 전산언어학 - 단어 의미 중의성 해소
단어 의미 중의성 해소(WSD)는 문맥 내 단어의 의미를 파악하는 계산 언어학 과제로, 다양한 접근 방식과 외부 지식 소스를 활용하여 연구되고 있으며, 다국어 및 교차 언어 WSD 등으로 발전하며 국제 경연 대회를 통해 평가된다.
| 텍스트 마이닝 | |
|---|---|
| 개요 | |
 | |
| 정의 | 텍스트 마이닝(Text mining)은 자연어 텍스트에서 가치 있는 정보를 자동으로 추출하는 과정이다. |
| 설명 | 컴퓨터를 이용하여 대량의 텍스트 데이터에서 패턴이나 관계를 찾아내는 것을 의미한다. 텍스트 데이터에서 의미 있는 정보를 추출, 분석하여 새로운 지식을 발견하는 기술이다. 텍스트로부터 정보를 수집하고, 데이터 마이닝 기술을 사용하여 패턴을 인식하는 과정이다. |
| 기술 및 기법 | |
| 주요 기술 | 자연어 처리 (NLP) 정보 검색 (IR) 기계 학습 (ML) 데이터 마이닝 (DM) |
| 활용 기법 | 텍스트 분류 (Text Classification) 텍스트 군집화 (Text Clustering) 정보 추출 (Information Extraction) 감성 분석 (Sentiment Analysis) 토픽 모델링 (Topic Modeling) 연관 규칙 학습 (Association Rule Learning) 텍스트 요약 (Text Summarization) |
| 응용 분야 | |
| 비즈니스 | 고객 리뷰 분석 시장 조사 경쟁사 분석 평판 관리 |
| 학술 연구 | 논문 분석 연구 동향 파악 사회 과학 연구 |
| 기타 | 스팸 메일 필터링 뉴스 기사 분류 특허 분석 의료 기록 분석 |
| 역사 | |
| 초기 연구 | 1950년대부터 시작, 자연어 처리 및 정보 검색 분야 발전과 함께 발전함. |
| 발전 | 1990년대 후반, 데이터 마이닝 기술과 결합되면서 본격적인 텍스트 마이닝 연구 시작됨. |
| 현재 | 인공지능, 머신러닝 기술 발전으로 더욱 정교하고 다양한 분석 가능. 빅데이터 분석의 중요한 부분으로 자리매김. |
| 과제 및 전망 | |
| 과제 | 자연어의 복잡성 (의미 중의성, 문맥 의존성) 대용량 텍스트 데이터 처리 개인 정보 보호 문제 |
| 전망 | 인공지능 기술 발전과 함께 더욱 발전할 것으로 예상됨. 다양한 분야에서 의사 결정 지원 및 새로운 가치 창출에 기여할 것으로 기대됨. |
2. 역사
텍스트를 통계적으로 분석하는 분야로 오래전부터 '''계량문체학'''이 있었다. 이 분야에서 문장을 구성하는 요소의 특징을 정량적으로 분석하여 그 문장의 집필자를 추정하는 시도가 100년 이상 전에 있었다. 가장 대표적인 예는 지구물리학자 토머스 멘덴홀의 연구이다[61]。
텍스트 분석은 언어학, 통계학, 기계 학습 기술을 활용하여 텍스트 소스의 정보 내용을 모델링하고 구조화하는 방법이다.[4] 이 용어는 텍스트 마이닝과 거의 동의어로 사용되며, 실제로 로넨 펠드먼은 2000년의 "텍스트 마이닝"[5] 설명을 2004년에 "텍스트 분석"으로 수정했다.[6] 텍스트 분석은 현재 비즈니스 환경에서 더 자주 사용되는 반면, "텍스트 마이닝"은 1980년대부터 시작된 초기 응용 분야, 특히 생명 과학 연구 및 정부 정보 분야에서 사용된다.[7]
멘덴홀은 광학에서의 스펙트럼 분석을 단어 분석에 적용하여, 단어의 길이는 저자의 특징이 된다는 것을 과학 잡지에 기고했다. 여기서 단어의 스펙트럼이란, 단어를 구성하는 알파벳 수에 주목한 단어의 분포를 의미한다. 이때 멘덴홀은 윌리엄 셰익스피어의 희곡과 프랜시스 베이컨의 저작도 분석했다.
이 당시의 분석 기법은 집계하고 싶은 데이터를 눈으로 세어 카운트하는 원시적인 방법이었지만, 구조화되지 않은 텍스트 데이터를 텍스트를 구성하는 어떤 요소로 구분하여 구조화하고 분석한다는 점에서 기본적인 아이디어는 현재의 텍스트 마이닝과 동일하다.
내용 분석 분야에서는 19세기부터 20세기 초에 걸쳐 서구에서 신문 발행 부수가 증가함에 따라 신문 기사의 계량적 분석이 이루어졌다. 당시의 관심사는 얼마나 가치 없는 기사가 지면을 차지하고 있는가였다.
20세기 후반 ~ 제2차 세계 대전 전후, 사회학적인 개념(가치관, 여론 등)을 추구하기 위해 신문 분석이, 또한 독일과 그 동맹국에 대한 매스 미디어 분석, 즉 프로파간다 분석이 대규모로 이루어졌다. 이 시대에 사회 과학의 이론·개념에 더해 심리학 실험, 시장 조사의 분야로부터 통계 기법이 도입되었다. 현재는 이것들이 텍스트 마이닝을 이론적으로 뒷받침하고 있다.
이후 연구에서는 질문지에서의 자유 응답 등 조사의 보조적 수단으로서, 혹은 대량의 자료나 소설을 처리하기 위해, 실무적·상업적 분야에서도 이용되게 되었다.
1990년대 중반까지 텍스트 해석, 문서 해석 등으로 불렸으며, 1990년대 후반부터는 텍스트 데이터 마이닝(text data mining) 등으로 불리게 되었고, 그 이후 텍스트 마이닝으로 불리는 것이 일반적이 되었다. 현재는 텍스트 애널리틱스 또는 텍스트 애널리시스라고 부르는 경향이 있다.
3. 텍스트 분석
텍스트 분석은 비즈니스 문제에 대응하기 위해 텍스트 분석을 적용하는 것을 설명하기도 한다. 비즈니스와 관련된 정보의 80%가 주로 텍스트 형태의 비정형 데이터에서 발생한다는 것은 자명한 사실이다.[8] 이러한 기술과 프로세스는 지식, 즉 사실, 비즈니스 규칙, 관계를 발견하고 제시하며, 이는 그렇지 않으면 텍스트 형식으로 잠겨 자동 처리가 불가능하다.
텍스트를 통계적으로 분석하는 분야로서 오래전부터 '''계량문체학'''이 있었다. 이 분야에서 문장을 구성하는 요소의 특징을 정량적으로 분석하여 그 문장의 집필자를 추정하는 시도가 100년 이상 전에 있었다. 가장 대표적인 예는 지구물리학자 토머스 멘덴홀의 연구이다[61]。
멘덴홀은 광학에서의 스펙트럼 분석을 단어의 분석에 적용하여, 단어의 길이는 저자의 특징이 된다는 것을 과학 잡지에 기고했다. 여기서 단어의 스펙트럼이란, 단어를 구성하는 알파벳 수에 주목한 단어의 분포를 의미한다. 이때 멘덴홀은 윌리엄 셰익스피어의 희곡과 프랜시스 베이컨의 저작도 분석했다.
이 무렵의 분석 기법은 집계하고 싶은 데이터를 눈으로 세어 카운트하는 원시적인 수법이었지만, 구조화되지 않은 텍스트 데이터를 텍스트를 구성하는 어떤 요소로 구분하여 구조화하고 분석한다는 점에서 기본적인 아이디어는 현재의 텍스트 마이닝과 동일하다.
내용 분석 분야에서는 19세기부터 20세기 초에 걸쳐 서구에서 신문 발행 부수가 증가함에 따라 신문 기사의 계량적 분석이 이루어졌다. 당시의 관심사는 얼마나 가치 없는 기사가 지면을 차지하고 있는가였다.
20세기 후반 ~ 제2차 세계 대전 전후, 사회학적인 개념(가치관, 여론 등)을 추구하기 위해 신문 분석이, 또한 독일과 그 동맹국에 대한 매스 미디어 분석, 즉 프로파간다 분석이 대규모로 이루어졌다. 이 시대에 사회 과학의 이론·개념에 더해 심리학 실험, 시장 조사의 분야로부터 통계 기법이 도입되었다. 현재는 이것들이 텍스트 마이닝을 이론적으로 뒷받침하고 있다.
이후 연구에서는 질문지에서의 자유 응답 등 조사의 보조적 수단으로서, 혹은 대량의 자료나 소설을 처리하기 위해, 실무적·상업적 분야에서도 이용되게 되었다.
텍스트 마이닝은 1990년대 중반까지 텍스트 해석, 문서 해석 등으로 불렸으며, 1990년대 후반부터는 텍스트 데이터 마이닝(text data mining) 등으로 불리게 되었고, 그 이후 텍스트 마이닝으로 불리는 것이 일반적이 되었다. 현재는 텍스트 애널리틱스 또는 텍스트 애널리시스라고 부르는 경향이 있다.
3. 1. 텍스트 분석의 하위 작업
3. 2. 분석 방법론
내용 분석의 분석 기법에는, KHCoder를 개발한 히구치가 제시한 상관 관계 접근법(Correlational approach)과 사전 기반 접근법(Dictionary-based approach)이 있다[62]。
히구치는 텍스트 마이닝에서 이 두 가지 접근법을 통합한 "접합 접근법(接合アプローチ)"을 제창했다[62]。접합 접근법은 상관 관계 접근법으로 데이터를 요약·제시하는 단계(임의적 요소 배제)와 사전 기반 접근법으로 코딩 규칙을 작성하여 이론 가설 또는 문제 의식을 명시적으로 조작하는 단계를 거친다. 이 두 단계를 왕래하며 상호 보완적인 분석을 수행한다.
이 접근법을 통해, 분석자의 이론이나 문제 의식을 분석에 반영하기 어려운 상관 관계 접근법의 한계를 사전 기반 접근법의 자유로운 발상으로 보완할 수 있다. 또한, 분석이 임의적이 될 가능성이 있는 사전 기반 접근법의 결점을 다변량 분석으로 데이터 전체를 요약·제시하고 코딩 규칙을 공개하는 절차를 통해 극복하여, 제3자가 연구를 파악하기 쉽게 하고 신뢰성과 객관성을 향상시킨다.
이러한 접근법은 KHCoder가 상정하는 분석 방법으로 채택되고 있다.
일반적으로 텍스트 마이닝은 다음의 단계를 거친다.
1. 준비 작업: 텍스트의 전자화, 표기 오류 등의 클리닝
2. 가공과 처리: 형태소 분석, 구문 분석, 의미 분석 등
3. 데이터 집계와 분석: 데이터의 추출과 분석, 시각화
4. 텍스트 시각화
텍스트를 특정 단위로 분해하여 요소의 빈도를 집계하고, 이를 정리하거나 시각화하는 것은 텍스트 마이닝의 가장 기본적인 작업이다.
일반적으로 사용되는 기법은 막대 그래프나 꺾은선 그래프에 국한되지 않고, 워드 클라우드, 공기 네트워크, 클러스터 분석, 다차원 척도 구성법(MDS), 대응 분석 (계량화 III류), 자기 조직화 지도, 기계 학습(나이브 베이즈) 등 다양한 다변량 분석 기법이 사용된다.
시각화 작업은 KHCoder 등의 소프트웨어를 통해 분석과 동시에 수행할 수 있는 경우가 많다.
5. 텍스트 마이닝의 효과
텍스트 마이닝은 데이터 마이닝과 유사하지만, 그 효과는 다르다. 데이터 마이닝이 고객 개인의 구매 경향을 분석하는 등의 목적으로 수행되는 반면, 텍스트 마이닝은 고객 개인의 특성보다는 상품의 평가나 고객 서비스의 문제점 등 제공 측의 상태를 파악하는 데 위력을 발휘한다.[63]
또한, 계량적인 기법을 도입함으로써 분석자의 자의적인 판단에서 벗어나 제3자가 확인할 수 있다는 점에서 분석의 객관성과 신뢰성을 높인다.
분석 결과가 시각화되는 경우가 많기 때문에 데이터 전체를 시각적으로 조망하고, 긴 텍스트 데이터를 요약할 수 있다는 장점도 있다.
6. 응용 분야
텍스트 마이닝 기술은 정부, 연구, 비즈니스 등 다양한 분야에서 널리 활용되고 있다.
- 정부 및 법률 분야: 정부 및 군사 기관에서는 국가 안보 및 정보 획득을 위해 텍스트 마이닝을 활용하며, 법률 전문가는 전자 증거 개시 과정에 이 기술을 사용한다.[7]
- 연구 분야: 과학 연구자들은 방대한 양의 텍스트 데이터를 효율적으로 정리하고, 텍스트에 담긴 아이디어를 파악하며, 생명 과학 및 생물 정보학과 같은 분야에서 과학적 발견을 지원하는 데 텍스트 마이닝을 활용한다.[7]
- 비즈니스 분야: 기업은 경쟁 정보 분석, 자동화된 광고 게재, 고객 관계 관리 개선,[29] 고객 이탈률 예측,[30][31] 주가 예측[32] 등 다양한 활동에 텍스트 마이닝을 적용한다.
6. 1. 보안
텍스트 마이닝 소프트웨어 패키지 중 다수는 국가 안보를 위해 인터넷 뉴스, 블로그 등 온라인 일반 텍스트 소스의 모니터링 및 분석과 같은 보안 장비, 보안 애플리케이션에 적용된다.[17] 또한 텍스트 암호화/복호화 연구에도 관여한다.6. 2. 생물 의학
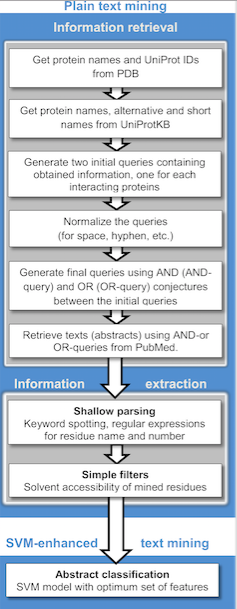
생물의학 문헌에서 다양한 텍스트 마이닝 응용 분야가 설명되어 왔으며,[19] 여기에는 단백질 도킹,[20] 단백질 상호 작용,[21][22] 및 단백질-질병 연관성 연구를 지원하는 계산 접근 방식이 포함된다.[23] 또한, 임상 분야의 대규모 환자 텍스트 데이터 세트, 인구 연구의 인구 통계 정보 데이터 세트 및 이상 반응 보고서를 통해 텍스트 마이닝은 임상 연구 및 정밀 의학을 용이하게 할 수 있다. 텍스트 마이닝 알고리즘은 전자 건강 기록, 사건 보고서 및 특정 진단 검사 보고서에서 얻은 증상, 부작용 및 동반 질환의 대규모 환자 텍스트 데이터 세트에서 특정 임상 사건의 계층화 및 색인 생성을 용이하게 할 수 있다.[24] 생물의학 문헌에서 온라인 텍스트 마이닝 응용 프로그램 중 하나는 텍스트 마이닝과 네트워크 시각화를 결합한 공개적으로 접근 가능한 검색 엔진인 PubGene이다.[25][26] GoPubMed는 생물의학 텍스트를 위한 지식 기반 검색 엔진이다. 텍스트 마이닝 기술을 통해 임상 영역에서 구조화되지 않은 문서에서 알려지지 않은 지식을 추출할 수도 있다.[27]
6. 3. 소프트웨어 개발
IBM과 마이크로소프트를 포함한 주요 기업에서 마이닝 및 분석 프로세스를 더욱 자동화하기 위해 텍스트 마이닝 방법과 소프트웨어를 연구 및 개발하고 있으며, 검색 및 색인 분야에서 일반적인 결과를 개선하기 위한 방법으로 다양한 기업에서 연구하고 있다.[28] 공공 부문에서는 정보 인식 사무소의 테러 활동 추적 및 감시를 위한 소프트웨어 제작에 많은 노력을 기울였다.[28] 연구 목적으로는 Weka 소프트웨어가 과학계에서 가장 인기 있는 옵션 중 하나이며, 초보자에게 훌륭한 입문 지침이 된다. 파이썬 프로그래머를 위해서는 NLTK가 훌륭한 툴킷으로 사용된다. 더 발전된 프로그래머를 위해서는 단어 임베딩 기반 텍스트 표현에 중점을 둔 Gensim 라이브러리도 있다.6. 4. 온라인 미디어
트리뷴 컴퍼니와 같은 대형 미디어 회사는 텍스트 마이닝을 통해 정보를 명확히 하고 독자에게 더 나은 검색 환경을 제공하며, 이는 사이트의 "접착성"과 수익을 증가시킨다. 또한 편집자들은 여러 매체에서 뉴스를 공유, 연관, 패키징할 수 있게 되어 콘텐츠를 수익화할 수 있는 기회가 크게 증가하고 있다.[33]6. 5. 디지털 인문학 및 계산 사회 과학
방대한 텍스트 코퍼스(말뭉치)의 자동 분석은 학자들이 매우 적은 수동 개입만으로도 여러 언어로 된 수백만 개의 문서를 분석할 수 있게 해준다. 주요 지원 기술에는 구문 분석, 기계 번역, 토픽 범주화, 기계 학습이 있다.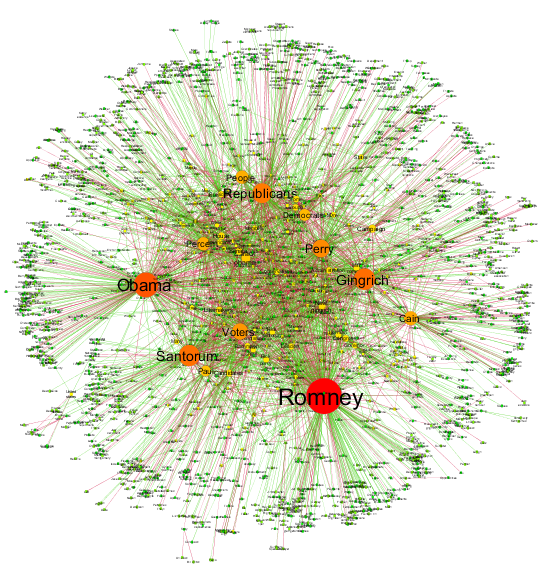
텍스트 코퍼스의 자동 구문 분석은 텍스트 데이터를 네트워크 데이터로 전환하여, 방대한 규모로 행위자와 그들의 관계 네트워크를 추출할 수 있게 해주었다. 수천 개의 노드를 포함할 수 있는 결과 네트워크는 네트워크 이론의 도구를 사용하여 주요 행위자, 주요 커뮤니티 또는 정당을 식별하고, 전체 네트워크의 견고성 또는 구조적 안정성, 특정 노드의 중심성과 같은 일반적인 속성을 분석하는 데 활용된다.[44] 이는 주어-동사-목적어 삼중항이 동작으로 연결된 행위자 쌍 또는 행위자-객체로 구성된 쌍으로 식별되는 양적 내러티브 분석에 의해 도입된 접근 방식을 자동화한다.[43]
콘텐츠 분석은 오랫동안 사회 과학 및 미디어 연구의 전통적인 부분이었다. 콘텐츠 분석의 자동화는 해당 분야에서 "빅 데이터" 혁명을 일으켰으며, 수백만 개의 뉴스 항목을 포함하는 소셜 미디어 및 신문 콘텐츠 연구가 가능해졌다. 텍스트 마이닝 방법을 기반으로 수백만 개의 문서에 걸쳐 성차별, 가독성, 콘텐츠 유사성, 독자 선호도, 심지어 기분까지 분석되었다.[46][47][48][49][50] Flaounas et al.은 가독성, 성차별 및 주제 편향 분석을 시연했다.[51] 이는 서로 다른 주제가 서로 다른 성차별과 가독성 수준을 갖는 방식을 보여주었고, 트위터 콘텐츠를 분석하여 방대한 인구에서 기분 패턴을 감지할 수 있는 가능성도 입증되었다.[52][53]
7. 텍스트 마이닝 도구
- KH 코더
- MLTP: 다국어 텍스트 프로세서
- MTMineR
8. 지적 재산권
유럽 저작권법 및 데이터베이스 지침에 따르면, 저작권 소유자의 허가 없이 저작권이 있는 작품(예: 웹 마이닝)을 마이닝하는 것은 불법이다.[54] 2014년 영국에서 하그리브스 검토의 권고에 따라 정부는 저작권법을 개정하여 텍스트 마이닝을 제한 및 예외로 허용했다. 이는 2009년에 마이닝 관련 예외를 도입한 일본에 이어 세계에서 두 번째였다. 그러나 정보 사회 지침 (2001)의 제한으로 인해 영국의 예외는 비상업적 목적으로만 콘텐츠 마이닝을 허용한다. 영국의 저작권법은 계약 조건에 의해 이 조항이 무효화되는 것을 허용하지 않는다.
유럽 위원회는 2013년 '유럽을 위한 라이선스'라는 제목으로 텍스트 및 데이터 마이닝에 대한 이해 관계자 토론을 촉진했다.[55] 이 법적 문제에 대한 해결책이 저작권법에 대한 제한 및 예외가 아닌 라이선스에 초점을 맞춘다는 사실은 대학교, 연구원, 도서관, 시민 사회 단체 및 오픈 액세스 출판사 대표들이 2013년 5월에 이해 관계자 대화에서 탈퇴하게 만들었다.[56]
미국 저작권법, 특히 공정 사용 조항에 따라 미국, 이스라엘, 대만, 대한민국과 같은 공정 사용 국가에서 텍스트 마이닝은 합법으로 간주된다. 텍스트 마이닝은 변형적이며, 이는 원본 저작물을 대체하지 않는다는 의미이므로, 공정 사용 하에 합법으로 간주된다. 예를 들어, 구글 도서 합의의 일환으로, 해당 사건의 재판장은 구글의 저작권이 있는 도서 디지털화 프로젝트가 합법이라고 판결했는데, 부분적으로 디지털화 프로젝트가 보여준 변형적 사용 때문이었다. 그러한 사용 중 하나가 텍스트 및 데이터 마이닝이다.[57]
오스트레일리아 저작권법에는 텍스트 또는 데이터 마이닝에 대한 예외 조항이 ''1968년 저작권법''에 포함되어 있지 않다. 오스트레일리아 법 개혁 위원회는 "연구 및 학습" 공정 사용 예외가 "합리적인 부분" 요건을 넘어서기 때문에 이러한 주제를 다루는 데까지 확장될 가능성은 낮다고 언급했다.[58]
참조
[1]
웹사이트
Marti Hearst: What is Text Mining?
http://people.ischoo[...]
[2]
간행물
A brief survey of text mining
Ldv Forum
2005
[3]
서적
The text mining handbook
Cambridge University Press
2007
[4]
웹사이트
Defining_text_a.html
http://intelligent-e[...]
2009-11-29
[5]
웹사이트
KDD-2000 Workshop on Text Mining – Call for Papers
https://www.cs.cmu.e[...]
Cs.cmu.edu
2015-02-23
[6]
웹사이트
tutorials.html
http://www.ir.iit.ed[...]
2012-03-03
[7]
서적
Proceedings of the 9th conference on Computational linguistics
[8]
웹사이트
Unstructured Data and the 80 Percent Rule
http://breakthrougha[...]
Breakthrough Analysis
2015-02-23
[9]
thesis
Exploração de informações contextuais para enriquecimento semântico em representações de textos
http://www.teses.usp[...]
Universidade de São Paulo
2018-11-14
[10]
학술지
Entity Linking meets Word Sense Disambiguation: a Unified Approach
2014-12
[11]
학술지
A New Evolving Tree-Based Model with Local Re-learning for Document Clustering and Visualization
2017-02-06
[12]
학술지
Text mining methodologies with R: An application to central bank texts
https://paperswithco[...]
2022
[13]
서적
Handbook of multimethod measurement in psychology
[14]
학술지
Opinion Mining and Sentiment Analysis
2008
[15]
학술지
Twitter, MySpace, Digg: Unsupervised Sentiment Analysis in Social Media
2012-09-01
[16]
웹사이트
Sentiment Analysis in Twitter < SemEval-2017 Task 4
http://alt.qcri.org/[...]
2018-10-02
[17]
서적
Proceedings of the International Workshop on Computational Intelligence in Security for Information Systems CISIS'08
[18]
학술지
Text Mining for Protein Docking
2015-12-09
[19]
학술지
Getting Started in Text Mining
[20]
학술지
Text mining for protein docking
[21]
학술지
Protein–protein interaction predictions using text mining methods
2015
[22]
학술지
The STRING database in 2017: quality-controlled protein–protein association networks, made broadly accessible
2016-10-18
[23]
학술지
Phrase mining of textual data to analyze extracellular matrix protein patterns across cardiovascular disease
2018-10-01
[24]
학술지
Risk Prediction using Natural Language Processing of Electronic Mental Health Records in an Inpatient Forensic Psychiatry Setting.
2018-08-10
[25]
학술지
A literature network of human genes for high-throughput analysis of gene expression
[26]
학술지
Linking microarray data to the literature
[27]
학술지
Text Mining in Biomedical Domain with Emphasis on Document Clustering
2017
[28]
웹사이트
texor-a-chat-mining-program.html
http://yatsko.zohosi[...]
2013-10-04
[29]
웹사이트
Text Analytics
http://www.medallia.[...]
Medallia
2015-02-23
[30]
학술지
Integrating the voice of customers through call center emails into a decision support system for churn prediction
http://econpapers.re[...]
[31]
학술지
Improving customer complaint management by automatic email classification using linguistic style features as predictors
http://econpapers.re[...]
[32]
학술지
Assessing the usefulness of online message board mining in automatic stock prediction systems
[33]
서적
Proceedings of the ACL-02 conference on Empirical methods in natural language processing
[34]
학술지
Developing Affective Lexical Resources
http://www.psychnolo[...]
[35]
컨퍼런스
SenticNet: a Publicly Available Semantic Resource for Opinion Mining
http://www.aaai.org/[...]
[36]
논문
Affect Detection: An Interdisciplinary Review of Models, Methods, and Their Applications
[37]
웹사이트
The University of Manchester
http://www.mancheste[...]
Manchester.ac.uk
2015-02-23
[38]
웹사이트
Tsujii Laboratory
https://web.archive.[...]
Tsujii.is.s.u-tokyo.ac.jp
2015-02-23
[39]
웹사이트
The University of Tokyo
http://www.u-tokyo.a[...]
UTokyo
2015-02-23
[40]
서적
Entity Set Search of Scientific Literature: An Unsupervised Ranking Approach
ACM
2018-06-27
[41]
논문
The beauty of brimstone butterfly: novelty of patents identified by near environment analysis based on text mining
2017-02-06
[42]
논문
Using machine learning to disentangle homonyms in large text corpora
2018-03-10
[43]
논문
Automated analysis of the US presidential elections using Big Data and network analysis
[44]
논문
Network analysis of narrative content in large corpora
[45]
문서
Quantitative Narrative Analysis
Emory University
[46]
논문
Content analysis of 150 years of British periodicals
2017-01-09
[47]
간행물
The Structure of EU Mediasphere
[48]
간행물
Nowcasting Events from the Social Web with Statistical Learning
[49]
간행물
NOAM: news outlets analysis and monitoring system
[50]
간행물
Automatic discovery of patterns in media content
[51]
간행물
RESEARCH METHODS IN THE AGE OF DIGITAL JOURNALISM
[52]
간행물
Circadian Mood Variations in Twitter Content
[53]
간행물
Effects of the Recession on Public Mood in the UK
[54]
웹사이트
Researchers given data mining right under new UK copyright laws
http://www.out-law.c[...]
2014-06-09
[55]
웹사이트
Licences for Europe – Structured Stakeholder Dialogue 2013
http://ec.europa.eu/[...]
2014-11-14
[56]
웹사이트
Text and Data Mining:Its importance and the need for change in Europe
https://web.archive.[...]
2013-04-25
[57]
뉴스
Judge grants summary judgment in favor of Google Books – a fair use victory
http://www.lexology.[...]
Antonelli Law Ltd
2013-11-19
[58]
웹사이트
Text and data mining
https://www.alrc.gov[...]
2013-06-04
[59]
서적
Excelで学ぶテキストマイニング入門
https://books.google[...]
オーム社
[60]
서적
Pythonによるテキストマイニング入門
https://books.google[...]
オーム社
[61]
서적
テキストアナリティクスの基礎と実践
岩波書店
[62]
서적
社会調査のための計量テキスト分析 第2版
ナカニシヤ出版
[63]
서적
Rによるやさしいテキストマイニング
https://books.google[...]
オーム社
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com