볼츠만 머신
"오늘의AI위키" 는 AI 기술로 일관성 있고 체계적인 최신 지식을 제공하는 혁신 플랫폼입니다."오늘의AI위키" 의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
목차 보기/숨기기
2. 구조
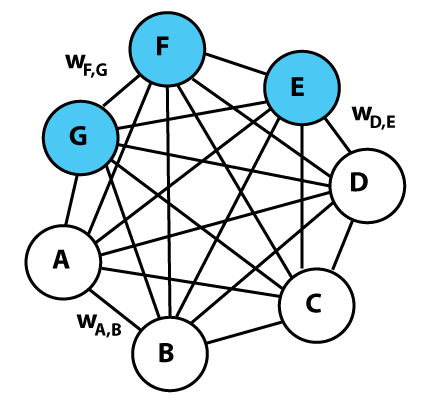
볼츠만 머신은 상호 연결된 유닛들의 네트워크로 구성되며, 각 유닛은 이진(0 또는 1) 상태를 가진다. 네트워크의 전체 에너지 E 는 연결 강도와 유닛의 상태에 따라 결정된다. 가중치가 몇 개 라벨링된 볼츠만 머신의 그래픽 표현. 각 무방향 엣지는 종속성을 나타내며 가중치 w_{ij} 로 가중치가 부여됩니다. 이 예에서는 3개의 숨겨진 유닛(파란색)과 4개의 보이는 유닛(흰색)이 있습니다. 이것은 제한된 볼츠만 머신이 아닙니다. 이진 결과를 생성하며, 볼츠만 머신 가중치는 확률적이다. 볼츠만 머신은 통계적 변동을 사용한 홉필드 네트워크 의 일종으로 볼 수 있으며, 신경망 내부를 학습할 수 있는 최초의 신경망 중 하나이다. 하지만 연결 제한이 없는 볼츠만 머신은 기계 학습 이나 추론에 실용적이지 않다고 알려져 있다. 그럼에도 불구하고, 볼츠만 머신은 국소성과 학습 알고리즘의 헤브의 법칙적 성질, 그리고 병렬 처리와 동적 역학의 단순한 물리적 프로세스와의 유사성 때문에 이론적으로 매력적이다. 볼츠만 머신은 확률 밀도 함수 자체를 계산하며, 사용되는 샘플링 함수(통계 역학에서의 볼츠만 분포 , 즉 소프트맥스 함수 )에서 이름을 따왔다.
2. 1. 기본 구조
볼츠만 머신은 상호 연결된 유닛들의 네트워크로 구성되며, 각 유닛은 0 또는 1 (활성 또는 비활성)의 이진 값을 가진다. 각 유닛의 값은 불규칙 과정 에 의해 결정된다. 네트워크 전체의 에너지, 즉 "글로벌 에너지" (E )는 홉필드 네트워크 와 유사하게 정의된다.E = -(\sum_{iw_{ij} : 유닛 i 와 유닛 j 사이의 연결 강도s_i : 유닛 i 의 상태 (s_i \in \{0,1\} )\theta_i : 유닛 i 의 바이어스 (-\theta_i 는 유닛의 임계값)w_{ii}=0\qquad \forall i (자기 자신과의 연결은 없음)w_{ij}=w_{ji}\qquad \forall i,j (모든 연결은 대칭적임)W=[w_{ij}] 로 표현된다.i 가 0 또는 1의 값을 가질 때 발생하는 글로벌 에너지 차이 \Delta E_i 는 다음과 같다.\Delta E_i = \sum_j w_{ij} \, s_j + \theta_i \Delta E_i = E_\text{i=off} - E_\text{i=on} 볼츠만 인자 를 활용하여 각 상태의 확률을 계산하고, 이를 정리하면 유닛 i 가 1일 확률 p_\text{i=on} 은 다음과 같이 표현된다.p_\text{i=on} = \frac{1}{1+\exp(-\frac{\Delta E_i}{T})} = \varsigma_1 \left(\frac{\Delta E_i}{T}\right) T 는 시스템의 온도이며, \varsigma_1 는 표준 시그모이드 함수 이다. 이 관계는 볼츠만 머신에서 확률 계산의 기반이 된다.2. 2. 유닛 상태 확률
단일 유닛 i 가 0(꺼짐) 또는 1(켜짐) 상태일 때의 전역 에너지 차이(\Delta E_i )는 다음과 같이 표현된다.\Delta E_i = \sum_{j>i} w_{ij} \, s_j + \sum_{j\Delta E_i = E_\text{i=off} - E_\text{i=on} 볼츠만 인자 에 따른 상대 확률로 대체하고, 볼츠만 분포 의 특성을 이용하면 다음과 같은 식이 유도된다.(-k_{B} T \ln(p_\text{i=on})), k_{B} 는 볼츠만 상수 이며, 인위적인 온도 T 개념에 흡수된다. 유닛이 켜짐 또는 꺼짐일 확률의 합이 1임을 고려하여 식을 정리하면, i 번째 유닛이 켜질 확률은 다음과 같이 주어진다.p_{i=\text{on}} = \frac{1}{1+\exp\Big(-\frac{\Delta E_{i}}{k_{B}T}\Big)}, T 는 시스템의 온도를 의미한다. 이 관계는 볼츠만 머신의 변형에서 확률 표현식에 사용되는 로지스틱 함수 의 기반이 된다.2. 3. 평형 상태
이 네트워크는 반복적으로 유닛을 선택하고 상태를 재설정한다. 특정 온도에서 충분히 오래 실행하면, 네트워크의 전역 상태 확률은 볼츠만 분포 에 따라 해당 전역 상태의 에너지에만 의존하며, 프로세스가 시작된 초기 상태에는 의존하지 않는다. 이는 전역 상태의 로그 확률이 에너지에 따라 선형적으로 변한다는 것을 의미한다. 이러한 관계는 기계가 "열 평형 상태"에 있을 때, 즉 전역 상태의 확률 분포가 수렴되었을 때 성립한다.
3. 학습
볼츠만 머신의 학습은 네트워크가 주어진 데이터의 분포를 잘 나타내도록 연결 강도를 조정하는 과정이다. 볼츠만 머신의 유닛은 '가시적(visible)' 유닛과 '은닉(hidden)' 유닛으로 나뉜다. 가시적 유닛은 환경으로부터 정보를 받는 유닛으로, 훈련 집합은 가시적 유닛 집합에 대한 이진 벡터 집합이다. 훈련 집합에 대한 분포는 P^{+}(V) 로 표기한다.주변 분포 를 구하여 P^{-}(V) 로 표기한다.P^{+}(V) 를 근사하기 위해 기계가 생성한 P^{-}(V) 를 사용하며, 두 분포의 유사성은 쿨백-라이블러 발산 G 로 측정한다. G 는 가중치의 함수인데, 가중치는 상태의 에너지를 결정하고, 에너지는 볼츠만 분포에 의해 P^{-}(v) 를 결정하기 때문이다. G 에 대한 경사 하강법 알고리즘은 주어진 가중치 w_{ij} 를 가중치에 대한 G 의 편미분 을 빼서 변경한다.
3. 1. 훈련 과정
볼츠만 머신 훈련은 두 단계로 번갈아 진행된다. 첫 번째는 가시적 유닛의 상태가 훈련 집합에서 샘플링된 이진 상태 벡터로 고정되는 "양성(positive)" 단계이다(P^{+} 에 따라). 두 번째는 네트워크가 자유롭게 실행되는 "음성(negative)" 단계이다. 음성 단계에서는 입력 노드의 상태만 외부 데이터에 의해 결정되고, 출력 노드는 자유롭게 변화할 수 있다.P^{-}(V) 를 사용하여 실제 분포 P^{+}(V) 를 근사하는 것이다. 두 분포의 유사성은 쿨백-라이블러 발산 G 를 사용하여 측정한다.G = \sum_{v}{P^{+}(v)\ln\left({\frac{P^{+}(v)}{P^{-}(v)}}\right)} G 는 가중치의 함수이므로, 경사 하강법 알고리즘을 사용하여 G 를 최소화할 수 있다. 주어진 가중치 w_{ij} 는 가중치에 대한 G 의 편미분 을 빼서 변경한다.w_{ij} 에 대한 기울기는 다음 방정식으로 주어진다.\frac{\partial{G}}{\partial{w_{ij}}} = -\frac{1}{R}[p_{ij}^{+}-p_{ij}^{-}] p_{ij}^{+} 는 양성 단계에서 평형 상태일 때 유닛 ''i''와 ''j''가 모두 켜져 있을 확률이다.p_{ij}^{-} 는 음성 단계에서 평형 상태일 때 유닛 ''i''와 ''j''가 모두 켜져 있을 확률이다.R 은 학습률 을 나타낸다.시냅스 )이 연결된 두 뉴런 외에 다른 정보는 필요로 하지 않기 때문에 생물학적으로 타당하다고 볼 수 있다. 이는 역전파 와 같은 다른 신경망 훈련 알고리즘보다 생물학적으로 더 현실적이다.쿨백-라이블러 발산 을 최소화하여 데이터의 로그 우도를 최대화한다. 즉, 훈련 절차는 관측된 데이터의 로그 우도에 대한 경사 상승법을 수행한다.\frac{\partial{G}}{\partial{\theta_{i}}} = -\frac{1}{R}[p_{i}^{+}-p_{i}^{-}] 3. 2. 문제점
이론적으로 볼츠만 머신은 매우 일반적인 계산 매체이다. 예를 들어, 사진에 대해 훈련되면 이론적으로 사진의 분포를 모델링하며, 그 모델을 사용하여 부분적인 사진을 완성할 수 있다.기계의 크기와 연결 강도의 크기에 따라 평형 통계를 수집하는 데 필요한 시간이 기하급수적으로 증가한다. 연결된 유닛의 활성화 확률이 0과 1 사이일 때 연결 강도는 더욱 가변적이어서 소위 분산 트랩으로 이어집니다. 궁극적인 결과는 노이즈로 인해 연결 강도가 활성도가 포화될 때까지 무작위 보행을 따른다는 것이다.
4. 종류
볼츠만 머신에는 여러 종류가 있지만, 그중에서도 학습 효율을 높이기 위해 특정 제약을 가한 형태들이 주로 사용된다.
제한 볼츠만 머신(RBM) : 일반적인 볼츠만 머신은 학습이 어렵지만, RBM은 은닉 유닛과 가시 유닛 사이에만 연결을 허용하고 같은 층의 유닛끼리는 연결을 제한하여 학습 효율을 높였다. RBM을 여러 층으로 쌓아 딥 러닝 모델을 만들 수도 있다.스파이크 앤 슬래브 RBM (''ss''RBM) : 실수 값을 사용하는 딥 러닝 모델에 적용하기 위해 개발되었다. 이진 스파이크 변수와 실수 값 슬래브 변수를 조합하여 연속적인 값을 표현한다.딥 볼츠만 머신(DBM) : 여러 층의 은닉 유닛을 가진 무방향 그래프 모델이다. 상향식 및 하향식 추론을 모두 사용하여 입력 데이터의 특징을 더 잘 파악할 수 있다.4. 1. 제한 볼츠만 머신 (Restricted Boltzmann Machine, RBM)
제한된 볼츠만 머신의 그래픽 표현. 4개의 파란색 유닛은 은닉 유닛을 나타내고, 3개의 빨간색 유닛은 가시 상태를 나타냅니다. 딥 러닝 의 일반적인 전략 중 하나이다. 새로운 계층이 추가될 때마다 생성 모델이 개선된다.4. 1. 1. 스파이크 앤 슬래브 RBM (Spike-and-slab RBM)
스파이크 앤 슬래브 제한된 볼츠만 머신 (''ss''RBM)은 가우시안 RBM과 같이 실수 값 입력을 사용한 딥 러닝의 필요성으로 인해 등장했으며, 이진 잠재 변수 로 연속 값 입력을 모델링한다.제한된 볼츠만 머신 및 변형과 유사하게 스파이크 앤 슬래브 RBM은 이분 그래프 이며, GRBM과 마찬가지로 가시적 유닛(입력)은 실수 값을 갖는다. 차이점은 각 숨겨진 유닛이 이진 스파이크 변수와 실수 값 슬래브 변수를 갖는 숨겨진 레이어에 있다는 것이다. 스파이크는 0에서 이산적인 확률 질량이고, 슬래브는 연속적인 영역에 대한 확률 밀도이며,사전 확률 을 형성한다.4. 2. 딥 볼츠만 머신 (Deep Boltzmann Machine, DBM)
딥 볼츠만 머신(DBM)은 여러 층의 은닉 변수를 가진 이진 쌍별 마르코프 랜덤 필드(무방향) 확률적 그래프 모델의 일종이다. 이는 대칭적으로 결합된 확률적 이진 변수의 네트워크이다. 가시 유닛 \boldsymbol{\nu} \in \{0,1\}^D 과 은닉 유닛 \boldsymbol{h}^{(1)} \in \{0,1\}^{F_1}, \boldsymbol{h}^{(2)} \in \{0,1\}^{F_2}, \ldots, \boldsymbol{h}^{(L)} \in \{0,1\}^{F_L} 의 층으로 구성되며, 동일한 층의 유닛을 연결하는 연결 링크는 없다( RBM 과 유사). DBM에서 벡터 \boldsymbol{\nu} 에 할당된 확률은 다음과 같다.p(\boldsymbol{\nu}) = \frac{1}{Z}\sum_h e^{\sum_{ij}W_{ij}^{(1)}\nu_i h_j^{(1)} + \sum_{jl}W_{jl}^{(2)}h_j^{(1)}h_l^{(2)}+\sum_{lm}W_{lm}^{(3)}h_l^{(2)}h_m^{(3)}}, \boldsymbol{h} = \{\boldsymbol{h}^{(1)}, \boldsymbol{h}^{(2)}, \boldsymbol{h}^{(3)} \} 는 은닉 유닛 집합이고, \theta = \{\boldsymbol{W}^{(1)}, \boldsymbol{W}^{(2)}, \boldsymbol{W}^{(3)} \} 는 가시-은닉 및 은닉-은닉 상호 작용을 나타내는 모델 매개변수이다.음성 인식 과 같은 작업에서 입력에 대한 복잡하고 추상적인 내부 표현을 학습할 수 있다. 그러나 DBN 및 딥 합성곱 신경망 과 달리, DBM은 상향식 및 하향식으로 추론 및 훈련 절차를 수행하여 입력 구조의 표현을 더 잘 드러낼 수 있도록 한다.
5. 역사
존 홉필드 는 1982년 논문에서 통계 역학, 특히 1970년대에 개발된 데이비드 셔링턴과 스콧 키르크패트릭의 스핀 글래스 이론을 사용하여 연상 기억 을 연구했다.제프리 힌턴 과 테리 세이노스키의 논문이다.더글러스 호프스태터 의 카피캣 프로젝트에서도 어닐링된 깁스 샘플링을 사용한 이징 모델 적용 아이디어가 사용되었다.기계 학습 에 대한 기본적인 기여로 노벨 물리학상 을 수상했다.홉필드 네트워크 의 일종으로 간주할 수 있다.
6. 수학적 배경
볼츠만 머신은 셔링턴-키르크패트릭 모델과 마찬가지로 전체 네트워크에 대해 정의된 총 "에너지"(해밀토니안)를 가진 유닛 네트워크이다. 유닛은 이진 결과를 생성하며, 볼츠만 머신 가중치는 확률적이다. 볼츠만 머신의 전역 에너지 E 는 호프필드 네트워크와 이징 모델과 동일한 형태를 갖는다.E = -\left(\sum_{iw_{ij} 는 유닛 j 와 유닛 i 간의 연결 강도이다.s_i 는 유닛 i 의 상태이며, s_i \in \{0,1\} 이다.\theta_i 는 전역 에너지 함수에서 유닛 i 의 바이어스이다. (-\theta_i 는 유닛의 활성화 임계값이다.)w_{ij} 는 대각선에 0이 있는 대칭 행렬 W=[w_{ij}] 로 표시된다.통계학 과 기계 학습 에서는 로그-선형 모형이라고 한다. 딥 러닝 에서 볼츠만 분포는 볼츠만 머신과 같은 확률적 신경망의 표본 추출 분포에 사용된다.
참조
[1]
논문
Solvable Model of a Spin-Glass
[2]
학술지
A Learning Algorithm for Boltzmann Machines
http://learning.cs.t[...]
[3]
학술지
Boltzmann machine
2007-05-24
[4]
서적
International Neural Network Conference
Springer Netherlands
1990-01-01
[5]
논문
On the Anatomy of MCMC-Based Maximum Likelihood Learning of Energy-Based Models
https://ojs.aaai.org[...]
[6]
Youtube
Recent Developments in Deep Learning
https://www.youtube.[...]
2010-03-22
[7]
학술지
Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition
http://research.micr[...]
[8]
학술지
A better way to pretrain deep Boltzmann machines
http://machinelearni[...]
2017-08-18
[9]
conference
Efficient Learning of Deep Boltzmann Machines
http://machinelearni[...]
2017-08-18
[10]
웹사이트
Scaling Learning Algorithms towards AI
http://www.iro.umont[...]
2007
[11]
conference
Efficient Learning of Deep Boltzmann Machines
http://machinelearni[...]
2017-08-18
[12]
학술지
A Spike and Slab Restricted Boltzmann Machine
http://machinelearni[...]
2019-08-25
[13]
conference
Proceedings of the 28th International Conference on Machine Learning
2019-08-25
[14]
학술지
Bayesian Variable Selection in Linear Regression
1988
[15]
학술지
Solvable Model of a Spin-Glass
1975-12-29
[16]
학술지
Neural networks and physical systems with emergent collective computational abilities
"[s.n.]"
[17]
conference
Analyzing Cooperative Computation
http://digitalcollec[...]
2020-02-17
[18]
conference
Optimal Perceptual Inference
IEEE Computer Society
1983-06
[19]
간행물
Massively parallel architectures for Al: NETL, Thistle, and Boltzmann machines.
1983
[20]
서적
Talking Nets: An Oral History of Neural Networks
2000
[21]
서적
The Copycat Project: An Experiment in Nondeterminism and Creative Analogies.
Defense Technical Information Center
1984-01
[22]
서적
Physics of cognitive processes
World Scientific
1988
[23]
문서
Information processing in dynamical systems: Foundations of harmony theory.
1986
[24]
웹사이트
John Hopfield and Geoffrey Hinton share the 2024 Nobel Prize for Physics
https://physicsworld[...]
2024-10-18
[25]
웹사이트
A Learning Algorithm for Boltzmann Machines
http://learning.cs.t[...]
1985
CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.help@durumis.com