UTF-8은 유니코드 문자를 가변 길이로 인코딩하는 방식이다. 1992년 켄 톰슨과 롭 파이크에 의해 설계되었으며, 1993년 USENIX 컨퍼런스에서 처음 발표되었다. ASCII 문자와의 호환성을 가지며, 웹에서 가장 널리 사용되는 인코딩 방식이다. UTF-8은 1바이트에서 4바이트까지 사용하여 유니코드 코드 포인트를 표현하며, ASCII 문자는 1바이트로, 한글을 포함한 동아시아 문자는 대부분 3바이트로 인코딩된다. UTF-8은 설계상 문자열 검색에 용이하며, 엔디안에 영향을 받지 않는 장점이 있다. 대한민국에서는 대부분의 현대 한글을 문제없이 표현할 수 있지만, 옛한글이나 한자 확장 영역의 일부 문자는 4바이트 영역에 포함되어 일부 시스템에서 처리 문제가 발생할 수 있다.
더 읽어볼만한 페이지
유니코드 변환 형식 - UTF-1 UTF-1은 유니코드 초기 버전을 인코딩하기 위해 1992년에 설계된 가변 길이 문자 인코딩 방식으로, ASCII 호환성을 유지하고 ISO 2022 및 MIME과의 호환성을 고려했지만, "모듈로 190" 산술을 사용하는 특징과 현대 유니코드 표준과의 차이점을 가진다.
유니코드 변환 형식 - UTF-32 UTF-32는 유니코드 문자 집합의 각 코드 포인트를 32비트로 표현하는 가변 길이 문자 인코딩 방식이며, 문자열 내 특정 문자를 빠르게 찾는 데 사용되지만 데이터 크기가 크다는 단점이 있다.
유니코드에 관한 - UTF-1 UTF-1은 유니코드 초기 버전을 인코딩하기 위해 1992년에 설계된 가변 길이 문자 인코딩 방식으로, ASCII 호환성을 유지하고 ISO 2022 및 MIME과의 호환성을 고려했지만, "모듈로 190" 산술을 사용하는 특징과 현대 유니코드 표준과의 차이점을 가진다.
유니코드에 관한 - 유니코드 영역 유니코드 영역은 문자 및 기호를 논리적으로 그룹화한 블록들의 집합으로, 고유한 이름과 코드 포인트 범위를 가지며, 기본 다국어 평면(BMP)을 포함하여 다양한 평면으로 확장되어 문자 인코딩 등 다양한 분야에서 중요한 역할을 한다.
문자 인코딩 - 유니코드 유니코드는 세계의 모든 문자를 하나의 컴퓨터 인코딩 표준으로 통합하기 위해 설계되었으며, 유니코드 컨소시엄에 의해 관리되고 UTF-8, UTF-16, UTF-32 등의 부호화 형식을 제공하지만, 일부 문자 표현 문제, 버전 간 비호환성, 레거시 인코딩과의 호환성 문제 등의 과제를 안고 있다.
문자 인코딩 - Shift JIS Shift JIS는 JIS X 0201을 기반으로 JIS X 0208을 할당하여 일본어 문자를 인코딩하는 방식으로, 이스케이프 시퀀스 없이 문자 집합을 혼용하여 파일 크기를 절약하고 처리 시간을 단축하며, MS-DOS에서 "MS 한자 코드"로 채택된 후 사실상 표준으로 자리 잡았다.
국제 표준화 기구(ISO)는 1989년에 유니버설 멀티바이트 문자 집합 구성을 시작했다. 1992년 7월, X/Open 위원회는 더 나은 인코딩을 찾고 있었다. 유닉스 시스템 연구소의 데이브 프로서는 빠른 구현 특성을 가진 제안을 제출했고, 7비트 ASCII 문자는 "자신"만을 나타내도록 하는 개선 사항을 도입했다.[3] 1992년 8월, 이 제안은 IBM X/Open 대표에 의해 관련 당사자들에게 배포되었다. 벨 연구소의 플랜 9 운영 체제 그룹의 켄 톰슨은 자기 동기화 코드가 되도록 수정하여, 독자가 어디에서든 시작하여 즉시 문자 경계를 감지할 수 있게 하였다. 1992년 9월 2일, 롭 파이크와 켄 톰슨은 뉴저지 식당의 식탁 매트에 UTF-8의 기본 설계를 요약했다.[8] 다음 날, 파이크와 톰슨은 이를 구현하고 플랜 9를 업데이트하여 사용했으며,[8] X/Open에 그들의 성공을 전달했고, X/Open은 이를 FSS-UTF의 사양으로 받아들였다.[6]
UTF-8은 1993년 1월 25일부터 29일까지 샌디에이고에서 열린 USENIX 컨퍼런스에서 처음 공식 발표되었다.[9] 인터넷 기술 연합은 1998년 1월에 미래의 인터넷 표준 작업을 위해 UTF-8을 채택했다.[10] 2003년 11월, UTF-8은 UTF-16 문자 인코딩의 제약에 맞춰 제한되었다.[11]
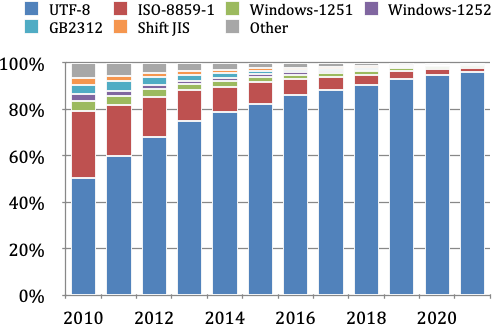
2010년 이후 1,000만 개의 가장 인기 있는 웹사이트에서 선언된 문자 집합
400px
UTF-8은 2008년부터 월드 와이드 웹에서 가장 흔하게 사용되는 인코딩 방식이 되었다.[23]
3. 구조
UTF-8은 유니코드 문자들을 인코딩하기 위해 만들어진 가변 길이 문자 인코딩 방식이다. 여기서 '가변 길이'란, 문자에 따라 사용하는 바이트 수가 달라진다는 뜻이다.
ASCII와 호환성을 유지하기 위해, ASCII 문자는 1바이트로 표현된다. 그 외의 문자들은 2바이트에서 최대 4바이트까지 사용하여 표현한다.[90][91][92][93] 4바이트 시퀀스에서는 21비트(0x1FFFFF)까지 표현할 수 있지만, 유니코드 범위를 벗어나는 U+10FFFF보다 큰 값은 허용하지 않는다.
인코딩은 최소 바이트 수로 표현해야 한다. 따라서 바이트 수마다 유니코드의 부호 위치 최소값(하한)도 설정되어 있다.
바이트 수
유효 비트
유니코드
2진수 표기
16진수 표기
1
7 비트
colspan="2" |
0xxx-xxxx
colspan="3" rowspan="3" style="background: silver;" |
00..7F
colspan="3" rowspan="3" style="background: silver;" |
하한
U+0000
0000-0000
00
상한
U+007F
0111-1111
7F
2
11 비트
colspan="2" |
110y-yyyx
10xx-xxxx
colspan="2" rowspan="3" style="background: silver;" |
C2..DF
80..BF
colspan="2" rowspan="3" style="background: silver;" |
하한
U+0080
1100-0010
1000-0000
C2
80
상한
U+07FF
1101-1111
1011-1111
DF
BF
3
16 비트
colspan="2" |
1110-yyyy
10yx-xxxx
10xx-xxxx
colspan="1" rowspan="3" style="background: silver;" |
E0..EF
80..BF
80..BF
colspan="1" rowspan="3" style="background: silver;" |
하한
U+0800
1110-0000
1010-0000
1000-0000
E0
80*
80
상한
U+FFFF
1110-1111
1011-1111
1011-1111
EF
BF*
BF
4
21 비트
colspan="2" |
1111-0yyy
10yy-xxxx
10xx-xxxx
10xx-xxxx
F0..F4
80..BF
80..BF
80..BF
하한
U+10000
1111-0000
1001-0000
1000-0000
1000-0000
F0
80*
80
80
상한
U+10FFFF
1111-0100
1000-1111
1011-1111
1011-1111
F4
BF*
BF
BF
* 첫 번째 바이트가 E0일 때 두 번째 바이트가 80-9F 범위, 또는 F0일 때 80-8F 범위를 취하는 것은 중복된 인코딩이므로 허용되지 않는다. 첫 번째 바이트가 ED일 때 두 번째 바이트가 A0 이상이 되는 것은 서로게이트 페어를 위한 부호 위치에 해당하며, 또한 F4일 때 90 이상이 되는 것은 유니코드 범위를 벗어나므로, UTF-8에서는 역시 허용되지 않는다.
유니코드의 부호 위치를 2진 표기한 것을 위의 비트 패턴의 x, y에 오른쪽 정렬하여 저장한다(최소 바이트 수로 표현하기 위해 y 부분에는 최소 1회는 1이 나타난다). 인코딩된 바이트 열은 바이트 순서에 관계없이 왼쪽부터 순서대로 출력한다.
1바이트째의 선두에 연속된 비트 "1"의 개수(그 뒤에 비트 "0"이 1개 붙음)로 해당 문자의 바이트 수를 알 수 있다. 또한 2바이트째 이후는 비트 패턴 "10"으로 시작하며, 1바이트째와 2바이트째 이후에서는 값의 범위가 겹치지 않으므로 문자 경계를 확실하게 판정할 수 있다.
7바이트 이상의 문자는 규정되지 않으므로 0xFE, 0xFF는 사용되지 않는다. 이 때문에 바이트 순서 표식(BOM)에 0xFE와 0xFF를 사용하는 UTF-16이나 UTF-32가 UTF-8과 혼동되는 일은 없다.
UTF-8 인코딩은 다음과 같은 특징을 갖는다.
ASCII 문자 코드 텍스트를 처리하는 소프트웨어의 대부분을 그대로 사용할 수 있다.[94]
바이트 스트림 내 임의의 위치에서 해당 문자, 이전 문자 또는 다음 문자의 첫 번째 바이트를 쉽게 판별할 수 있다.
문자열 검색을 단순한 바이트 열 검색으로 수행해도 문자 경계와 다른 곳에서 일치하는 일이 없다.
UTF-16 또는 UTF-32와 달리 바이트 단위 입출력을 수행하므로, 바이트 순서의 영향을 받지 않는다.
21비트까지 표현할 수 있으므로 서로게이트 페어를 사용할 필요가 없다.
ASCII 문자가 주를 이루는 문서라면, 거의 데이터 크기를 늘리지 않고 유니코드의 이점을 누릴 수 있다.
여러 UTF-8 문자열을 단순한 부호 없는 8비트 정수의 배열로 간주하여 사전순 정렬한 결과는 유니코드 코드 포인트의 사전순 정렬 결과와 동일하다.
3. 1. 인코딩 방식
나머지 바이트들은 10으로 시작함
000800-00FFFF
xxxxxxxx xxxxxxxx
1110xxxx 10xxxxxx 10xxxxxx
010000-10FFFF
110110ZZ ZZxxxxxx 110111xx xxxxxxxx
11110zzz 10zzxxxx 10xxxxxx 10xxxxxx
UTF-16 서러게이트 쌍 영역 (ZZZZ = zzzzz - 1). UTF-8로 표시된 비트 패턴은 실제 코드 포인트와 동일하다.
예를 들어, 문자 "위"([http://www.unicode.org/charts/PDF/UAC00.pdf U+C704])는 다음과 같이 UTF-8로 인코딩된다.
이 문자는 U+0800부터 U+FFFF 사이의 영역에 있으므로, 표에 따라 1110xxxx 10xxxxxx 10xxxxxx 형식으로 인코딩된다.
16진수 C704는 2진수 1100-0111-0000-0100와 같다.
이 비트들은 순서대로 x로 표시된 비트에 들어간다: 1110'''1100''' 10'''011100''' 10'''000100'''
결과적으로 이 문자는 3바이트로 인코딩된다. (16진수로 표시하면 EC 9C 84가 된다.)
PHP를 할 때 이것을 쓰지 않으면 한국어가 깨지는 경우가 많이 일어난다.
따라서 첫 128 문자는 1바이트로 표시되고, 그 다음 1920 문자[107]는 2바이트로 표시되며, 나머지 문자들 중 기본 다국어 평면(BMP) 안에 들어 있는 것은 3바이트, 아닌 것은 4바이트로 표시된다.
위의 패턴을 사용하면 더 큰 코드 포인트를 표시할 수도 있다. 원래 UTF-8은 6바이트를 사용해서 U+7FFFFFFF까지의 코드 포인트를 표현할 수 있게 하였으나, 2003년 11월에 발표된 RFC 3629에서는 유니코드에서 실제로 정의하는 U+10FFFF까지의 문자만을 표시할 수 있도록 제한하였다. 따라서 이전까지는 UTF-8에서 나타날 수 없는 바이트가 0xFE와 0xFF 뿐이었지만, RFC 3629에 따라서 0xC0, 0xC1, 그리고 0xF5부터 0xFF까지의 13개의 바이트가 나타날 수 없게 되었다.
UTF-8은 코드 포인트의 값에 따라 1바이트에서 4바이트까지 코드 포인트를 인코딩한다.
코드 포인트 ↔ UTF-8 변환
첫 번째 코드 포인트
마지막 코드 포인트
바이트 1
바이트 2
바이트 3
바이트 4
U+0000
U+007F
style="background: darkgray" colspan=3 |
U+0080
U+07FF
style="background: darkgray" colspan=2 |
U+0800
U+FFFF
style="background: darkgray" |
U+010000
U+10FFFF
처음 128개의 코드 포인트(ASCII)는 1바이트가 필요하다. 다음 1,920개의 코드 포인트는 2바이트로 인코딩해야 하며, 이는 거의 모든 라틴 문자의 나머지 부분과 IPA 확장, 그리스 문자, 키릴 문자, 콥트 문자, 아르메니아 문자, 히브리 문자, 아랍 문자, 시리아 문자, 타나 및 N'Ko 문자와 결합된 분음 부호를 포함한다. 나머지 기본 다국어 평면(BMP)의 61,440개의 코드 포인트를 위해서는 3바이트가 필요하며, 여기에는 대부분의 중국어, 일본어 및 한국어 문자가 포함된다. 유니코드의 평면에 있는 1,048,576개의 코드 포인트를 위해서는 4바이트가 필요하며, 여기에는 이모지 (그림 문자), 덜 일반적인 중국어, 일본어 및 한국어 문자, 다양한 역사적 스크립트 및 수학 기호가 포함된다.
이것은 ''접두사 코드''이며, 코드 포인트를 디코딩하기 위해 코드 포인트의 마지막 바이트를 넘어서 읽을 필요가 없다. Shift-JIS와 같은 많은 이전의 멀티 바이트 텍스트 인코딩과 달리, 이 인코딩은 ''자기 동기화 코드''이므로 짧은 문자열이나 문자를 검색할 수 있으며, 무작위 위치에서 코드 포인트의 시작 부분을 최대 3바이트까지 뒤로 이동하여 찾을 수 있다. 선두 바이트에 대해 선택된 값은 UTF-8 문자열 목록을 정렬하면 UTF-32 문자열을 정렬하는 것과 동일한 순서가 되도록 한다.
'위' (U+C704)는 11101100 10011100 10000100 (16진수: EC 9C 84), '한' (U+D55C)은 11101101 10010101 10011100 (16진수: ED 95 9C), '글' (U+AE00)은 11101010 10111000 10000000 (16진수: EA B8 80)으로 표현된다.
4. 변형된 UTF-8
자바는 내부적으로 문자열을 UTF-16 인코딩으로 저장하며, 문자열 직렬화를 위해 UTF-8을 변형하여 사용하고 있다. 이를 [http://java.sun.com/j2se/1.5.0/docs/api/java/io/DataInput.html#modified-utf-8 변형된 UTF-8](Modified UTF-8)이라 부른다.
표준 UTF-8과 변형된 UTF-8은 크게 두 가지 차이점이 있다.
U+0000 표현 방식: 표준 UTF-8에서는 U+0000을 1바이트로 표현하지만, 변형된 UTF-8에서는 2바이트(11000000 10000000)로 표현한다. 이로 인해 변형된 UTF-8로 인코딩된 문자열에는 널 문자가 나타나지 않아, 널 문자를 문자열의 끝으로 사용하는 C 등 다른 언어에서 처리할 때 발생할 수 있는 문제를 방지한다.
기본 다국어 면(BMP) 외부 문자 인코딩 방식: 표준 UTF-8은 BMP 외부 문자를 4바이트로 인코딩하지만, 변형된 UTF-8은 이 문자들을 서로게이트 페어로 표시하여 두 문자로 나눈 뒤 인코딩한다. 이는 CESU-8과 동일한 방식이다. 자바 문자 형이 16비트이므로 U+10000 이상 영역의 유니코드 문자는 항상 두 개의 자바 문자로 표현해야 하기 때문이다. 하지만 이 방식은 BMP 외부 문자를 표준 UTF-8보다 긴 6바이트로 인코딩하게 된다.
이러한 차이점 때문에 변형된 UTF-8은 표준 UTF-8과 엄격하게 구별되어야 하며, 자바 내부 처리에서만 사용하도록 권장된다. IANA에 정식 등록된 문자 인코딩이 아니므로 인터넷 상의 정보 교환에는 사용하지 않아야 한다.
UTF-16에서 서로게이트 페어로 표시되는 BMP 외부 코드 포인트를 UTF-8로 변환할 때는, UTF-16의 서로게이트 페어(`U+D800`–`U+DBFF`, `U+DC00`–`U+DFFF`)를 나타내는 UTF-8로 바로 변환하지 않고, `U+10000`–`U+10FFFF` 코드 포인트로 디코딩한 후 변환해야 한다. 그렇지 않은 경우는 잘못된 UTF-8로 간주된다.
서로게이트 페어를 UTF-8과 동일하게 인코딩하는 방식은 CESU-8(Compatibility Encoding Scheme for UTF-16: 8-Bit)로 정의되어 있다. Oracle Database 버전 8 이전에는 UTF-8로 3바이트까지만 처리할 수 있었기 때문에 CESU-8이 사용되었다. 이 방식은 UTF-8의 4바이트 대신 서로게이트 부호 위치를 나타내는 3바이트 쌍(상위 `ED A0 80`–`ED AF BF`, 하위 `ED B0 80`–`ED BF BF`)으로 표현한다.
현재 Oracle Database는 CESU-8을 "UTF8", 일반 UTF-8을 "AL32UTF8"로 처리한다. MySQL에서 "utf8"을 지정하면 4바이트를 처리할 수 없고 CESU-8 인코딩이 필요하다. 4바이트를 지원하는 UTF-8은 "utf8mb4"로 정의되어 있으며, MySQL 5.5.3 이후부터 사용 가능하다.[96]
Java의 일부 내부 구현에서 사용되는 Modified UTF-8도 서로게이트 페어를 그대로 남긴다. 다만, NULL 문자를 `C0 80`으로 인코딩(UTF-8 규격 외)한다는 점에서 CESU-8과 다르다.
5. 설계 원칙 및 특징
1바이트로 표시된 문자의 최상위 비트는 항상 0이다.[3]
2바이트 이상으로 표시된 문자의 경우, 첫 바이트의 상위 비트들이 그 문자를 표시하는 데 필요한 바이트 수를 결정한다. 예를 들어 2바이트는 110으로 시작하고, 3바이트는 1110으로 시작한다.[3]
첫 바이트가 아닌 나머지 바이트들은 상위 2비트가 항상 10이다.[3]
이러한 설계는 한 문자에 대한 바이트 표현이 다른 문자에 대한 바이트 표현의 일부가 되는 경우가 없도록 하기 위함이다. 따라서 CP949, 상용 조합형, Shift-JIS, Big5와 같이 ISO 2022 체계에 부합하지 않는 이전의 가변 길이 인코딩과 달리, UTF-8 문자열에서는 바이트 단위의 부문자열 매칭을 그대로 사용할 수 있다. EUC-KR이나 EUC-JP 등은 이 점에서는 UTF-8과 비슷한 성질을 지닌다.[3]
또한, UTF-8에서 하나 이상의 바이트들이 손실되었을 때도, 다음의 정상 문자를 찾아서 동기화할 수 있기 때문에 피해를 줄일 수 있다.[3]
어떤 바이트들이 올바른 UTF-8로 확인되면, 그 문자열이 실제로 UTF-8로 인코딩되었을 가능성이 매우 높다. 임의의 바이트들이 순수한 ASCII 인코딩이 아닌 UTF-8 문자열일 가능성은 2바이트 문자의 경우 1/32, 3바이트 문자의 경우 5/256으로 매우 낮다. 또한 ISO-8859-1과 같은 기존의 인코딩으로 표현된 자연어 문자열이나 문서를 UTF-8로 표현된 것으로 오인할 가능성도 매우 낮다.[3]
1992년 7월, X/Open 위원회 XoJIG는 더 나은 인코딩을 찾고 있었다. 유닉스 시스템 연구소의 데이브 프로서는 7비트 ASCII 문자가 "자신"만을 나타내도록 하는 개선 사항을 도입한 제안을 제출했다. 멀티바이트 시퀀스는 상위 비트가 설정된 바이트만 포함하게 되었다. 이 제안의 이름은 ''파일 시스템 안전 UCS 변환 형식''(''FSS-UTF'')[3]이었다. 1992년 8월, 이 제안은 IBM X/Open 대표에 의해 관련 당사자들에게 배포되었다. 벨 연구소의 플랜 9 운영 체제 그룹의 켄 톰슨에 의한 수정으로 자기 동기화 코드가 되었고, 독자가 어디에서든 시작하여 즉시 문자 경계를 감지할 수 있게 되었으며, 이전 제안보다 비트 효율성이 약간 떨어지는 대가를 치렀다. 또한 과도하게 긴 인코딩을 방지하는 바이어스 사용을 포기했다.[6][7] 톰슨의 디자인은 1992년 9월 2일, 롭 파이크와 함께 뉴저지 식당의 식탁 매트에 요약되었다. 다음 날, 파이크와 톰슨은 이를 구현하고 플랜 9를 업데이트하여 전체적으로 사용했으며,[8] X/Open에 그들의 성공을 전달했고, X/Open은 이를 FSS-UTF의 사양으로 받아들였다.[6]
UTF-8은 코드 포인트의 값에 따라 1바이트에서 4바이트까지 코드 포인트를 인코딩한다.
코드 포인트 ↔ UTF-8 변환[11]
첫 번째 코드 포인트
마지막 코드 포인트
바이트 1
바이트 2
바이트 3
바이트 4
U+0000
U+007F
0xxxxxxx
style="background: darkgray" colspan=3 |
U+0080
U+07FF
110xxxxx
10xxxxxx
style="background: darkgray" colspan=2 |
U+0800
U+FFFF
1110xxxx
10xxxxxx
10xxxxxx
style="background: darkgray" |
U+010000
U+10FFFF
11110xxx
10xxxxxx
10xxxxxx
10xxxxxx
x,y,z 위치의 비트들은 코드 포인트 비트로 대체된다.
처음 128개의 코드 포인트(ASCII)는 1바이트가 필요하다. 다음 1,920개의 코드 포인트는 2바이트로 인코딩해야 하며, 이는 거의 모든 라틴 문자의 나머지 부분과 IPA 확장, 그리스 문자, 키릴 문자, 콥트 문자, 아르메니아 문자, 히브리 문자, 아랍 문자, 시리아 문자, 타나 및 N'Ko 문자와 결합된 분음 부호를 포함한다. 나머지 기본 다국어 평면 (BMP)의 61,440개의 코드 포인트를 위해서는 3바이트가 필요하며, 여기에는 대부분의 중국어, 일본어 및 한국어 문자가 포함된다. 유니코드의 평면에 있는 1,048,576개의 코드 포인트를 위해서는 4바이트가 필요하며, 여기에는 이모지 (그림 문자), 덜 일반적인 중국어, 일본어 및 한국어 문자, 다양한 역사적 스크립트 및 수학 기호가 포함된다.[11]
이는 ''접두사 코드''이며, 코드 포인트를 디코딩하기 위해 코드 포인트의 마지막 바이트를 넘어서 읽을 필요가 없다. Shift-JIS와 같은 많은 이전의 멀티 바이트 텍스트 인코딩과 달리, 이 인코딩은 ''자기 동기화 코드''이므로 짧은 문자열이나 문자를 검색할 수 있으며, 무작위 위치에서 코드 포인트의 시작 부분을 최대 3바이트까지 뒤로 이동하여 찾을 수 있다. 선두 바이트에 대해 선택된 값은 UTF-8 문자열 목록을 정렬하면 UTF-32 문자열을 정렬하는 것과 동일한 순서가 되도록 한다.[11]
6. 오류 처리
UTF-8 디코더는 잘못된 입력에 대해 표준에 따라 일관되게 정의되어 있지 않다. RFC 3629는 과도하게 긴 형식(필요한 최소 바이트보다 더 많은 바이트 사용)을 오류로 처리하도록 요구하고 있다.[12][13] 유니코드 표준은 잘못된 형식의 단위 문자열을 오류로 처리하도록 요구한다.[14][15]
보안을 위해, 잘못된 입력을 오류로 처리하는 엄격한 디코더 사용이 권장된다. 과도하게 긴 인코딩은 동일한 코드 포인트를 여러 방식으로 인코딩할 수 있어 보안 문제가 발생할 수 있다. 예를 들어, 과도하게 긴 인코딩 (예: `../`)은 마이크로소프트의 IIS 웹 서버와 아파치의 톰캣 서블릿 컨테이너의 보안 유효성 검사를 우회하는 데 사용되었다.[12][13]
UTF-8 디코더는 다음과 같은 오류 상황에 대비해야 한다.
UTF-8에 나타나지 않는 바이트
문자의 시작 부분에 있는 "연속 바이트"
문자의 끝 전에 있는 비연속 바이트 (또는 문자열 종료)
과도한 인코딩
보다 큰 값으로 디코딩되는 4바이트 시퀀스
초창기 UTF-8 디코더 중 상당수는 이러한 오류를 디코딩하여 잘못된 비트를 무시했다. 조심스럽게 제작된 잘못된 UTF-8은 , 슬래시 또는 따옴표와 같은 ASCII 문자를 건너뛰거나 생성하여 보안 취약점을 유발할 수 있었다.
RFC 3629는 "디코딩 알고리즘의 구현은 유효하지 않은 시퀀스 디코딩으로부터 보호해야 합니다."라고 명시한다.[16] ''유니코드 표준''은 디코더가 "... 잘못된 형식의 코드 유닛 시퀀스를 오류 조건으로 처리합니다."라고 명시한다. 현재 표준은 각 오류를 대체 문자 "�" (U+FFFD)로 대체하고 디코딩을 계속하는 것을 권장한다.
유니코드 6부터 표준은 오류가 하나의 연속 바이트이거나 허용되지 않는 첫 번째 바이트에서 끝나는 "모범 사례"를 권장한다.
RFC 3629 이후, UTF-16에서 사용되는 높은 서러게이트와 낮은 서러게이트(부터 까지)는 유효한 유니코드 값이 아니며, UTF-8 인코딩은 무효한 바이트 시퀀스로 처리해야 한다.[16]
UTF-8의 인코딩 체계에는 중복성이 있어, 같은 문자를 부호화하는 데 여러 표현이 가능하다. 과거에는 그러한 표현도 허용되었지만, 디렉토리 트래버설 등의 대책으로 행해지는 문자열 검사를 중복된 표현으로 빠져나가는 수법이 알려지게 되었기 때문에, 현재는 최소 바이트 수에 의한 표현 이외에는 부정 UTF-8 시퀀스로 간주해야 한다.[97][98][99]
7. 장점과 단점
UTF-8은 다른 인코딩 방식과 비교했을 때 다음과 같은 장단점을 가진다.
ASCII 호환성 및 효율성:
ASCII 인코딩은 UTF-8의 부분 집합이므로, 일반적인 ASCII 문자열은 올바른 UTF-8 문자열이며 하위 호환성이 보장된다.[94]
U+0000부터 U+007F까지의 공백과 문장 부호를 포함한 ASCII 문자들은 1바이트로 표현할 수 있기 때문에, 한중일 문자와 표의 문자를 사용하지 않는 대부분의 문자열을 UTF-16보다 더 작은 크기로 표현할 수 있다.
ASCII 문자 위주 문서라면 데이터 크기를 거의 늘리지 않고 유니코드의 이점을 누릴 수 있다. (UTF-16, UTF-32는 데이터 크기가 2배, 4배 증가)
유연성 및 확장성:
UCS-2가 기본 다국어 평면(BMP) 안의 문자만 표현할 수 있는 것과 달리, UTF-8은 모든 유니코드 문자를 표현할 수 있다.
21비트까지 표현할 수 있어 서로게이트 페어가 필요 없다.
문자열 처리:
UTF-8 문자열은 바이트 단위 정렬 알고리즘으로도 코드 포인트 단위로 올바르게 정렬할 수 있다.
다른 인코딩과의 왕복 변환이 간단하며, 바이트 단위 문자열 검색 알고리즘을 그대로 사용할 수 있다.
바이트 경계를 순서대로 또는 역순으로 찾기 쉽다. 여러 바이트로 표시된 문자 중간에서 찾기 시작해도 해당 문자만 손실되고 나머지는 손상되지 않는다.
바이트 표현의 첫 바이트만으로 길이를 결정할 수 있어 부분 문자열을 얻기 쉽다.
문자열 검색을 단순한 바이트 열 검색으로 수행해도 문자 경계와 다른 곳에서 일치하는 일이 없다.
예를 들어, Shift_JIS에서 "₩"(0x5C)를 검색하면 "表"(0x95 0x5C)의 두 번째 바이트에 일치하거나, EUC-JP에서 "海"(0xB3 0xA4)를 검색하면 "ここ"(0xA4 0xB3 0xA4 0xB3)에 일치하는 것과 같은 일이 일어나지 않는다.
간단한 비트 연산만 사용하므로 효율적이며, 곱셈이나 나눗셈 같은 느린 연산을 사용하지 않는다.
시스템 호환성:
간단한 알고리즘으로 UTF-8 문자열임을 확인할 수 있다. 다른 인코딩에서 나타나는 바이트들이 올바른 UTF-8 문자열일 가능성은 낮다.
U+0000을 표현할 때를 제외하면 널 문자가 없어 C 언어 문자열 함수를 그대로 사용할 수 있다.
유닉스 파일 시스템과 여러 도구들은 옥텟을 기본 단위로 하며, 널 문자와 경로 식별자(/, 0x2F)에 특별한 의미를 부여하는 경우가 많다. UTF-16 등의 인코딩과는 달리, UTF-8은 ASCII와 호환되기 때문에 0x00이나 0x2f 옥텟이 항상 U+0000과 U+002F에 대응되므로 기존 API를 약간 수정해서 쓸 수 있다.
UTF-16, UTF-32와 달리 바이트 단위 입출력을 하므로 바이트 순서의 영향을 받지 않는다.
UTF-16은 바이트 순서를 나타내기 위하여 바이트 순서 문자(BOM, U+FEFF)가 필요하지만, UTF-8은 바이트 순서가 정해져 있기 때문에 BOM이 필요하지 않다.
UTF-8은 UTF-7보다 한 문자를 표현하는 데 더 적은 바이트를 사용하며, "+"를 그대로 인코딩한다. (UTF-7은 "+-"로 인코딩)
한 문자를 표현하는 바이트 표현은 다른 문자를 표현하는 바이트 표현에 포함되지 않아, ASCII 문자가 아닌 값들에 투명한 파일 시스템이나 다른 소프트웨어와 호환성을 가진다.
UTF-8의 단점:
대부분의 UTF-8 문자열은 일반적으로 적절한 기존 인코딩으로 표현한 문자열보다 크다. 판독 기호를 사용하는 대부분의 라틴 알파벳 문자는 2바이트 이상, 한중일 문자와 표의 문자는 3바이트 이상을 사용한다.
한중일 문자와 표의 문자를 제외한 거의 모든 기존 인코딩은 한 문자에 1바이트를 사용해 문자열 처리가 간편하지만, UTF-8은 그렇지 않다.
UTF-8은 8비트 안전한 전송 체계가 필요하다. 전자 우편에서 quoted-printable이나 base64 인코딩을 사용하면 전송량이 더 많아진다. 하지만 최근 대부분의 SMTP 서버가 8BITMIME을 지원하여 이 단점은 크게 부각되지 않는다.
다른 유니코드 인코딩과 마찬가지로, 단순히 바이트 열 비교로는 문자열이 동일한지 판단할 수 없는 경우가 있다. 유니코드 등가성 및 정규화 참조.
UTF-8은 가변 길이 인코딩이며, 다른 문자는 다른 바이트 수로 표현될 수 있다. UTF-16도 BMP 바깥 문자를 4바이트로 표현하기 때문에 가변 길이 인코딩이다.
BMP에 들어 있는 한중일 문자들은 UTF-8에서 3바이트로 표현되지만, UTF-16에서는 2바이트로 표현된다. 따라서 UTF-8에서는 이러한 문자를 표현하기 위하여 더 많은 바이트가 필요하며 UTF-16과 비교할 때 최대 50%까지 크기가 늘 수 있다. 하지만 반대로 U+0000부터 U+007F 사이의 글자들은 UTF-16에서 크기가 두 배로 늘기 때문에 실질적으로는 큰 문제가 없을 수도 있다.
7. 1. 일반적인 장단점
ASCII 인코딩은 UTF-8의 부분 집합이므로, 일반적인 ASCII 문자열은 올바른 UTF-8 문자열이며 하위 호환성이 보장된다.
UTF-8 문자열은 바이트 단위로 정렬을 수행하는 알고리즘으로도 코드 포인트 단위로 올바르게 정렬할 수 있다. (일반적인 목적으로는 재정렬이 필요하다)
간단한 알고리즘을 통하여 UTF-8 문자열임을 확인할 수 있다. 즉, 다른 인코딩에서 나타나는 바이트들이 올바른 UTF-8 문자열일 가능성은 낮다.
U+0000을 표현할 때를 제외하면, 널 문자는 UTF-8 문자열 안에 나타나지 않는다. 따라서 널 문자로 끝나는 문자열을 사용하는 C 언어의 문자열 함수(strncpy() 같은)를 그대로 사용할 수 있다.
21비트까지 표현할 수 있으므로 서로게이트 페어를 사용할 필요가 없다.
ASCII 문자가 주를 이루는 문서라면, 거의 데이터 크기를 늘리지 않고 유니코드의 이점을 누릴 수 있다. UTF-16 또는 UTF-32에서는 데이터 크기가 거의 2배, 4배가 된다.
여러 UTF-8 문자열을 단순한 부호 없는 8비트 정수의 배열로 간주하여 사전순 정렬한 결과는 유니코드의 코드 포인트의 사전순 정렬 결과(즉, UTF-32로 변환한 후 정렬한 결과)와 동일하다.
UTF-8을 사용한 인코딩에서는 한자나 가나 등의 표현에 3바이트를 필요로 한다. 동아시아의 기존 문자 코드에서 멀티바이트 부호를 사용하여 1문자를 2바이트로 표현되던 데이터가 1.5배 또는 그 이상의 크기가 된다.
최단이 아닌 부호나 서로게이트 페어 등, UTF-8의 규격 외이지만 검사를 수행하지 않는 프로그램에서는 겉보기에는 정상적으로 처리되는 바이트 열이 존재한다. 이러한 바이트 열을 입력으로 받아들일 경우, 프로그램이 예상하지 못한 범위의 데이터를 생성하기 때문에, 보안상의 위협이 될 수 있다[95]。
바이트 스트림 내 임의의 위치에서 해당 문자, 이전 문자 또는 다음 문자의 첫 번째 바이트를 쉽게 판별할 수 있다.
문자열 검색을 단순한 바이트 열 검색으로 수행해도 문자 경계와 다른 곳에서 일치하는 일이 없다. 예를 들어, Shift_JIS에서 "₩"(0x5C)를 검색하면 "表"(0x95 0x5C)의 두 번째 바이트에 일치하거나, EUC-JP에서 "海"(0xB3 0xA4)를 검색하면 "ここ"(0xA4 0xB3 0xA4 0xB3)에 일치하는 것과 같은 일이 일어나지 않는다.
UTF-16 또는 UTF-32와 달리 바이트 단위 입출력을 수행하므로, 바이트 순서의 영향을 받지 않는다.
7. 2. 기존 인코딩과의 비교
UTF-8은 다른 인코딩 방식과 비교했을 때 다음과 같은 장단점을 가진다. 장점
ASCII 인코딩은 UTF-8의 부분 집합이므로, 일반적인 ASCII 문자열은 올바른 UTF-8 문자열이며 하위 호환성이 보장된다.[94]
UTF-8 문자열은 바이트 단위 정렬 알고리즘으로도 코드 포인트 단위로 올바르게 정렬할 수 있다.
UTF-8과 UTF-16은 XML 문서의 표준 인코딩이다.
다른 인코딩과의 왕복 변환이 간단하며, 바이트 단위 문자열 검색 알고리즘을 그대로 사용할 수 있다.
간단한 알고리즘으로 UTF-8 문자열임을 확인할 수 있다. 다른 인코딩에서 나타나는 바이트들이 올바른 UTF-8 문자열일 가능성은 낮다.
U+0000을 표현할 때를 제외하면 널 문자가 없어 C 언어 문자열 함수를 그대로 사용할 수 있다.
UCS-2가 BMP 안의 문자만 표현할 수 있는 것과 달리, UTF-8은 모든 유니코드 문자를 표현할 수 있다.
바이트 경계를 순서대로 또는 역순으로 찾기 쉽다. 여러 바이트로 표시된 문자 중간에서 찾기 시작해도 해당 문자만 손실되고 나머지는 손상되지 않는다.
한 문자를 표현하는 바이트 표현은 다른 문자를 표현하는 바이트 표현에 포함되지 않아, ASCII 문자가 아닌 값들에 투명한 파일 시스템이나 다른 소프트웨어와 호환성을 가진다.
바이트 표현의 첫 바이트만으로 길이를 결정할 수 있어 부분 문자열을 얻기 쉽다.
간단한 비트 연산만 사용하므로 효율적이며, 곱셈이나 나눗셈 같은 느린 연산을 사용하지 않는다.
UTF-8은 UTF-7보다 한 문자를 표현하는 데 더 적은 바이트를 사용하며, "+"를 그대로 인코딩한다. (UTF-7은 "+-"로 인코딩)
UTF-16, UTF-32와 달리 바이트 단위 입출력을 하므로 바이트 순서의 영향을 받지 않는다.
21비트까지 표현할 수 있어 서로게이트 페어가 필요 없다.
ASCII 문자 위주 문서라면 데이터 크기를 거의 늘리지 않고 유니코드의 이점을 누릴 수 있다. (UTF-16, UTF-32는 데이터 크기가 2배, 4배 증가)
여러 UTF-8 문자열을 부호 없는 8비트 정수 배열로 간주하여 사전순 정렬하면 유니코드 코드 포인트 사전순 정렬 결과와 같다.
문자열 검색을 단순한 바이트 열 검색으로 수행해도 문자 경계와 다른 곳에서 일치하는 일이 없다.
단점
대부분의 UTF-8 문자열은 일반적으로 적절한 기존 인코딩으로 표현한 문자열보다 크다. 판독 기호를 사용하는 대부분의 라틴 알파벳 문자는 2바이트 이상, 한중일 문자와 표의 문자는 3바이트 이상을 사용한다.
한중일 문자와 표의 문자를 제외한 거의 모든 기존 인코딩은 한 문자에 1바이트를 사용해 문자열 처리가 간편하지만, UTF-8은 그렇지 않다.
UTF-8은 8비트 안전한 전송 체계가 필요하다. 전자 우편에서 quoted-printable이나 base64 인코딩을 사용하면 전송량이 더 많아진다. 하지만 최근 대부분의 SMTP 서버가 8BITMIME을 지원하여 이 단점은 크게 부각되지 않는다.
다른 유니코드 인코딩과 마찬가지로, 단순히 바이트 열 비교로는 문자열이 동일한지 판단할 수 없는 경우가 있다.
7. 3. UTF-16과의 비교
'''UTF-16과의 비교를 통한 UTF-8의 장점'''
* U+0000부터 U+007F까지의 공백과 문장 부호를 포함한 ASCII 문자들은 1바이트로 표현할 수 있기 때문에, 한중일 문자와 표의 문자를 사용하지 않는 대부분의 문자열을 UTF-16보다 더 작은 크기로 표현할 수 있다.
* 유닉스 파일 시스템과 여러 도구들은 옥텟을 기본 단위로 하며, 널 문자와 경로 식별자(/, 0x2F)에 특별한 의미를 부여하는 경우가 많다. UTF-16 등의 인코딩과는 달리, UTF-8은 ASCII와 호환되기 때문에 0x00이나 0x2f 옥텟이 항상 U+0000과 U+002F에 대응되므로 기존 API를 약간 수정해서 쓸 수 있다.
* UTF-16은 바이트 순서를 나타내기 위하여 바이트 순서 문자(BOM, U+FEFF)가 필요하지만, UTF-8은 바이트 순서가 정해져 있기 때문에 BOM이 필요하지 않다.
* 확장 ASCII를 처리할 수 있는 모든 시스템에 쉽게 적용할 수 있고, 바이트 순서 문제가 없으며, 대부분 라틴 문자를 사용하는 모든 언어에 대해 공간을 약 1/2로 줄일 수 있다.
** ASCII 문자 코드 텍스트를 처리하는 소프트웨어의 대부분을 그대로 사용할 수 있다.[94]
** 바이트 스트림 내 임의의 위치에서 해당 문자, 이전 문자 또는 다음 문자의 첫 번째 바이트를 쉽게 판별할 수 있다.
** 문자열 검색을 단순한 바이트 열 검색으로 수행해도 문자 경계와 다른 곳에서 일치하는 일이 없다. 예를 들어, Shift_JIS에서 "₩"(0x5C)를 검색하면 "表"(0x95 0x5C)의 두 번째 바이트에 일치하거나, EUC-JP에서 "海"(0xB3 0xA4)를 검색하면 "ここ"(0xA4 0xB3 0xA4 0xB3)에 일치하는 것과 같은 일이 일어나지 않는다. 이 때문에, 멀티바이트 문자를 의식하지 않고, ISO 8859-1 등의 8비트 문자를 위한 방대한 프로그램 자산을 비교적 적은 수정으로 재사용할 수 있다.
단, 다른 유니코드 인코딩과 마찬가지로, 단순히 바이트 열 비교로는 문자열이 동일한지 판단할 수 없는 경우가 있다. 자세한 내용은 유니코드 등가성 및 정규화를 참조.
** UTF-16 또는 UTF-32와 달리 바이트 단위 입출력을 수행하므로, 바이트 순서의 영향을 받지 않는다.
** 21비트까지 표현할 수 있으므로 서로게이트 페어를 사용할 필요가 없다.
** ASCII 문자가 주를 이루는 문서라면, 거의 데이터 크기를 늘리지 않고 유니코드의 이점을 누릴 수 있다. UTF-16 또는 UTF-32에서는 데이터 크기가 거의 2배, 4배가 된다.
** 여러 UTF-8 문자열을 단순한 부호 없는 8비트 정수의 배열로 간주하여 사전순 정렬한 결과는 유니코드의 코드 포인트의 사전순 정렬 결과(즉, UTF-32로 변환한 후 정렬한 결과)와 동일하다. 이에 반해, 서로게이트 페어를 포함하는 UTF-16 문자열을 부호 없는 16비트 정수의 배열로 간주하여 정렬한 결과는 유니코드의 코드 포인트의 사전순 정렬 결과와 다를 수 있다.
'''UTF-16과의 비교를 통한 UTF-8의 단점'''
* UTF-8은 가변 길이 인코딩이며, 다른 문자는 다른 바이트 수로 표현될 수 있다. 사실 이 문제는 별로 심각한 것이 아니며, UTF-8 문자열을 다루기 위한 추상적인 인터페이스를 만드는 것으로 해결될 수 있다. 실제로 기술적으로는 UTF-16도 BMP 바깥 문자를 4바이트로 표현하기 때문에 가변 길이 인코딩이다.
* BMP에 들어 있는 한중일 문자들은 UTF-8에서 3바이트로 표현되지만, UTF-16에서는 2바이트로 표현된다. 따라서 UTF-8에서는 이러한 문자를 표현하기 위하여 더 많은 바이트가 필요하며 UTF-16과 비교할 때 최대 50%까지 크기가 늘 수 있다. 하지만 반대로 U+0000부터 U+007F 사이의 글자들은 UTF-16에서 크기가 두 배로 늘기 때문에 실질적으로는 큰 문제가 없을 수도 있다.
8. 바이트 순서 표시(BOM)
UTF-8은 바이트 순서가 정해져 있으므로 바이트 순서 표시(BOM)가 필수적이지 않다. 하지만, UTF-8로 인코딩되었음을 나타내는 표식으로 BOM을 사용할 수 있다.[20] BOM은 U+FEFF 문자를 UTF-8로 인코딩한 값(,,)이다.
BOM 사용은 선택 사항이며, 유니코드 표준은 UTF-8에 BOM 사용을 요구하거나 권장하지 않는다.[20] BOM을 처리할 준비가 되지 않은 소프트웨어에서는 문제가 발생할 수 있다.[21] 예를 들어, 유닉스 계열 운영 체제의 실행 가능한 스크립트는 파일 시작 부분이 「#!」로 시작해야 하는데, BOM이 있으면 이 기능이 작동하지 않아 실행할 수 없다.
하지만, 일부 텍스트 처리 애플리케이션(텍스트 편집기 등)에서는 BOM을 전제로 작동하기도 한다.[102] 예를 들어, 마이크로소프트 엑셀에서는 CSV 파일을 열 때 BOM이 없으면 UTF-8로 인식하지 못하고 문자 깨짐이 발생한다.[103]윈도우 10의 메모장 앱은 2019년 19H1 업데이트부터 BOM 없는 UTF-8이 기본 설정이 되었다.[105]
한국에서는 BOM이 있는 UTF-8을 'UTF-8', 없는 것을 'UTF-8N'으로 구분하기도 하지만,[100] 국제적으로 통용되는 표현은 아니며 공적 규격 등에 의한 뒷받침도 없다.[101]
9. 대한민국 현황 및 한국어 처리 문제
대한민국에서 사용되는 대부분의 현대 한글은 UTF-8의 3바이트 영역(U+0800–U+FFFF)에 포함되어 있어 문제없이 표현 가능하다. 그러나 옛한글이나 일부 한자 확장 영역의 문자는 4바이트 영역(U+10000–U+10FFFF)에 포함되어 있어, 일부 구형 시스템이나 프로그램에서 제대로 처리하지 못할 수 있다.
이는 EUC-KR, CP949 등 기존 한글 인코딩과의 호환성 문제와도 연관된다. 일부 프로그램은 UTF-8 파일을 제대로 인식하지 못하거나, 문자 깨짐 현상이 발생할 수 있다.
과거 더불어민주당 등 진보 진영에서는 유니코드와 UTF-8 도입에 적극적이었으며, 다국어 지원 및 국제 표준 준수에 긍정적인 입장을 보여왔다. 반면 국민의힘 등 보수 진영에서는 기존 한글 인코딩(EUC-KR, CP949)과의 호환성 문제를 우려하는 목소리도 있었으나, 전반적으로는 UTF-8 도입에 큰 반대는 없었다.
현재 대한민국 대부분의 웹사이트, 소프트웨어, 운영체제는 UTF-8을 기본 인코딩으로 사용하고 있다. Windows 메모장은 현재 지원되는 모든 버전의 Windows에서 BOM 없이 UTF-8로 쓰는 것을 기본으로 설정하였다.[37] Windows 11의 일부 시스템 파일은 BOM이 필요 없이 UTF-8을 필요로 한다.[38]
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.