합성곱 신경망
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
합성곱 신경망(CNN)은 생물체의 시각 정보 처리 방식을 모방하여 개발된 딥러닝 모델로, 이미지, 영상, 자연어 등 다양한 분야에 활용된다. 1979년 네오코그니트론에서 시작되어 LeNet, AlexNet, ResNet 등을 거치며 발전해왔다. CNN은 합성곱층, 풀링층, 완전 연결층으로 구성되며, 국소적 연결, 가중치 공유, 풀링 등의 특징을 통해 영상 분류에서 전처리 과정을 최소화하고 파라미터 수를 줄인다. 이미지 인식, 객체 탐지, 자연어 처리, 신약 개발 등 다양한 분야에 응용되며, 특히 이미지넷 대회에서 딥러닝 붐을 이끌었다. 하지만 데이터 의존성, 계산 복잡성, 해석 가능성 부족, 편향 문제, 적대적 공격에 취약하다는 한계도 가지고 있다.

더 읽어볼만한 페이지
- 계산신경과학 - 인공 신경망
- 계산신경과학 - 인공 일반 지능
인공 일반 지능(AGI)은 추론, 지식 표현, 학습 등의 능력을 갖춘 인공지능 시스템을 의미하며, 기아와 빈곤 해결 등의 이점을 제공하지만 통제력 상실과 같은 위험도 존재한다. - 통계학에 관한 - 비지도 학습
비지도 학습은 레이블이 없는 데이터를 통해 패턴을 발견하고 데이터 구조를 파악하는 것을 목표로 하며, 주성분 분석, 군집 분석, 차원 축소 등의 방법을 사용한다. - 통계학에 관한 - 회귀 분석
회귀 분석은 종속 변수와 하나 이상의 독립 변수 간의 관계를 모델링하고 분석하는 통계적 기법으로, 최소 제곱법 개발 이후 골턴의 연구로 '회귀' 용어가 도입되어 다양한 분야에서 예측 및 인과 관계 분석에 활용된다. - 컴퓨터 비전 - 광학 흐름
광학 흐름은 비디오나 이미지에서 보이는 객체, 표면, 엣지의 움직임 패턴을 나타내며, 움직임 예측, 비디오 압축, 장면 구조 추정, 로봇 내비게이션 등 다양한 분야에 활용되는 중요한 기술이다. - 컴퓨터 비전 - 머신 비전
머신 비전은 이미지 기반 자동 정보 추출 기술로, 산업 자동화, 로봇 안내, 보안 모니터링 등에 활용되며, 자동 검사, 분류, 로봇 안내를 주요 용도로 컴퓨터 비전과 융합되고 딥 러닝 기술이 적용되는 추세이다.

2. 역사
합성곱 신경망(CNN)은 영상 처리 분야에서 오랫동안 사용되어 온 컨벌루션 연산을 활용하는 신경망 기술이다. 컴퓨터를 이용한 영상 처리가 시작된 초기부터 에지 검출, 가우시안 블러 등 다양한 필터 형태로 컨벌루션 기법이 활용되었다.
CNN은 동물의 시각피질 구조에서 영감을 받아 후쿠시마 쿠니히코가 제안한 네오코그니트론에서 기원한다.[190][191][192][193] 네오코그니트론은 신경망에 합성곱을 최초로 도입한 모델이다.
2012년 이후 딥러닝 붐이 일어나기 전까지는, 영상 인식 분야에서 신중하게 설계된 데이터 전처리를 통해 특징량(예: 1999년의 SIFT, 2006년의 SURF)을 추출하고, 이를 기반으로 학습하는 방식이 주를 이루었다. 예를 들어, AlexNet이 우승한 ILSVRC 2012에서 2위를 차지한 ISI 모델은 SIFT 등을 활용했다.[194]
CNN은 픽셀 데이터를 직접 입력으로 받아, 특징량 설계에 있어서 전문가의 지식에 의존하지 않는다는 특징을 가진다고 알려져 있었다. 그러나 현재는 CNN 외 다른 신경망(예: Vision 트랜스포머(ViT), MLP 기반의 gMLP)에서도 픽셀 입력 영상 처리가 가능해지면서,[197][198] 합성곱 자체가 특징량 설계를 불필요하게 만드는 핵심 기술은 아니라는 것이 밝혀졌다.
주요 모델:
2. 1. 초기 연구 (1950년대 ~ 1980년대)
1950년대와 1960년대 데이비드 허벨(David H. Hubel)과 토르스텐 비셀(Torsten Wiesel)은 고양이의 시각 피질(visual cortices)에 대한 연구를 통해, 시각 영역(visual field)의 작은 부분에만 반응하는 뉴런이 존재함을 밝혀냈다.[34] 이 뉴런의 발화에 시각 자극이 영향을 미치는 시각 공간의 영역을 수용 영역(receptive field)이라고 한다.[34] 인접한 세포는 유사하고 중복되는 수용 영역을 가지며, 이러한 수용 영역의 크기와 위치는 시각 공간의 완전한 지도를 형성하기 위해 피질 전체에서 체계적으로 변화한다.허벨과 비셀은 1968년 논문에서 뇌의 두 가지 기본적인 시각 세포 유형을 확인했다.[32]
- 단순 세포(simple cell): 수용 영역 내에서 특정 방향을 가진 직선 가장자리에 의해 출력이 최대화된다.
- 복합 세포(complex cell): 더 큰 수용 영역을 가지며, 출력이 영역 내 가장자리의 정확한 위치에 민감하지 않다.
허벨과 비셀은 패턴 인식 작업에 사용하기 위한 이 두 가지 유형의 세포에 대한 계단식 모델을 제안하기도 했다.[33][34]
1969년에는 ReLU 활성화 함수를 사용하는 심층 CNN이 발표되었는데[35], ReLU는 현대 CNN과 심층 신경망에서 가장 인기있는 활성화 함수가 되었다.[36]
1979년, 후쿠시마 구니히코(Kunihiko Fukushima)는 허벨과 비셀의 연구에서 영감을 받은 "네오코그니트론(neocognitron)"을 소개했다.[37][38][16] 네오코그니트론은 두 가지 기본적인 유형의 계층을 도입했다.
- S-계층: 공유 가중치 수용 영역 계층(이후 합성곱 계층으로 알려짐)으로, 수용 영역이 이전 계층의 패치를 포함하는 유닛을 포함한다. 공유 가중치 수용 영역 그룹(네오코그니트론 용어로 "평면")은 종종 필터라고 불리며, 계층에는 일반적으로 이러한 필터가 여러 개 있다.
- C-계층: 이전 합성곱 계층의 패치를 포함하는 수용 영역을 가진 유닛을 포함하는 다운샘플링 계층이다.
2. 2. 발전 (1980년대 ~ 2000년대)
LeNet-5는 1995년 얀 르쿤(Yann LeCun) 등이 개발한 획기적인 7계층 합성곱 신경망으로,[49] 32x32 픽셀 이미지로 디지털화된 수표의 손글씨 숫자를 분류한다. 더 높은 해상도의 이미지를 처리하려면 더 크고 많은 계층의 합성곱 신경망이 필요하므로, 이 기술은 컴퓨팅 자원의 가용성에 제약을 받는다.LeNet-5는 (1995년 당시) 다른 상업용 금액 판독 시스템보다 우수했다. 이 시스템은 NCR의 수표 판독 시스템에 통합되었고, 1996년 6월부터 여러 미국 은행에 배치되어 하루 수백만 장의 수표를 판독했다.[50]
2. 3. 딥러닝 붐과 CNN (2012년 ~ 현재)
2000년대에 그래픽 처리 장치(GPU)를 이용한 빠른 구현 덕분에 1980년대에 발명된 합성곱 신경망(CNN)이 획기적인 발전을 이루었다.2004년, K. S. Oh와 K. Jung은 표준 신경망을 GPU에서 크게 가속할 수 있음을 보였다. 그들의 구현은 CPU에서의 동등한 구현보다 20배 더 빨랐다.[57] 2005년, 또 다른 논문에서도 GPGPU의 기계 학습에 대한 가치를 강조했다.[58]
2006년, K. Chellapilla 외는 최초로 CNN을 GPU로 구현하였다. 그들의 구현은 CPU에서의 동등한 구현보다 4배 더 빨랐다.[59] 같은 시기에 GPU는 심층 신뢰망의 비지도 학습에도 사용되었다.[60][61][62][63]
2010년, IDSIA의 Dan Ciresan 외는 GPU에서 심층 피드포워드 네트워크를 훈련시켰다.[64] 2011년, 그들은 이를 CNN으로 확장하여 CPU 훈련에 비해 60배의 속도 향상을 달성했다.[65] 2011년, 그들의 네트워크는 이미지 인식 대회에서 최초로 초인적 성능을 달성하여 우승을 차지했다.[66] 이후 그들은 여러 대회에서 우승하며 여러 벤치마크에서 최첨단 기술을 달성했다.[67][40][23]
이후, Alex Krizhevsky 외의 유사한 GPU 기반 CNN인 알렉스넷(AlexNet)이 2012년 이미지넷 대규모 시각 인식 챌린지(ImageNet Large Scale Visual Recognition Challenge)에서 우승했다.[84] 이는 AI 붐의 초기 촉매 사건이었다.
GPU를 사용한 CNN 훈련과 비교하여 CPU에는 그다지 많은 관심이 없었다. (Viebke et al 2019)는 인텔 제온 파이(Intel Xeon Phi)에서 사용 가능한 스레드 및 SIMD 수준의 병렬 처리를 통해 CNN을 병렬화한다.[68][69]
3. 구조
합성곱 신경망(CNN)은 시각 피질의 동작을 모방하여 설계된 다층 퍼셉트론(MLP)의 변형이다. CNN은 주로 합성곱 계층(Convolution layer), 풀링 계층(Pooling layer), 그리고 완전 연결 계층(Fully connected layer)으로 구성된다. 과거에는 다층 퍼셉트론 모델이 영상 인식에 사용되었지만, 노드 간의 완전 연결은 차원의 저주를 야기했고, 고해상도 이미지에서는 계산이 복잡해지는 문제가 있었다.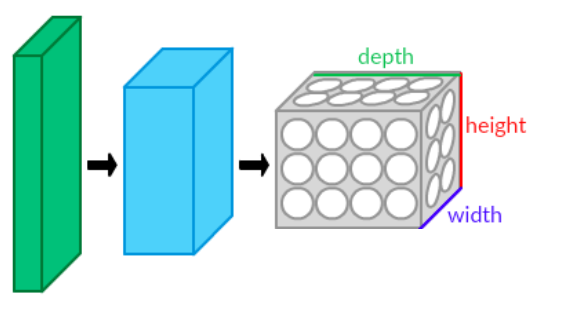
예를 들어, CIFAR-10 데이터셋의 이미지 크기는 32x32x3 (너비 32, 높이 32, 색상 채널 3)이다. 일반적인 신경망의 첫 번째 은닉 계층에서 완전 연결 뉴런은 3,072개(32*32*3)의 가중치를 갖는다. 그러나 200x200 크기의 이미지의 경우, 뉴런은 120,000개(200*200*3)의 가중치를 갖게 되어 훨씬 더 많은 계산량이 필요하다.
CNN은 이러한 문제를 해결하기 위해 다음과 같은 특징을 갖는다.
- 3차원 뉴런 볼륨: CNN의 계층은 뉴런이 3차원(너비, 높이, 깊이)으로 배열된다.[70]
- 국부적 연결: 각 뉴런은 이전 계층의 작은 영역(수용 영역)에만 연결되어 공간적으로 국부적인 입력 패턴에 대한 정보를 효율적으로 처리한다.
- 공유 가중치: 각 필터는 전체 시야에 걸쳐 복제되어 동일한 가중치를 공유한다. 이를 통해 특징의 위치 이동에 대해 동변환되는 활성화 맵을 생성한다. 즉, 입력 특징의 위치가 바뀌어도 동일한 특징으로 인식할 수 있다.[76]
- 풀링: 풀링 계층은 특징 맵을 하위 영역으로 나누고, 각 영역의 특징을 단일 값으로 다운샘플링한다. 이를 통해 특징 맵의 크기를 줄이고, 특징의 위치 변화에 대한 병진 불변성을 높인다.[14]
이러한 특징들 덕분에 CNN은 비전 문제에서 더 나은 일반화 성능을 보인다. 가중치 공유는 학습해야 할 자유 매개변수의 수를 줄여 네트워크를 실행하기 위한 메모리 요구량을 낮추고, 더 크고 강력한 네트워크를 학습할 수 있게 한다.
CNN 아키텍처는 입력 볼륨을 미분 가능한 함수를 통해 출력 볼륨(예: 클래스 점수)으로 변환하는 여러 개의 층으로 구성된다.
3. 1. 합성곱 계층 (Convolutional Layer)
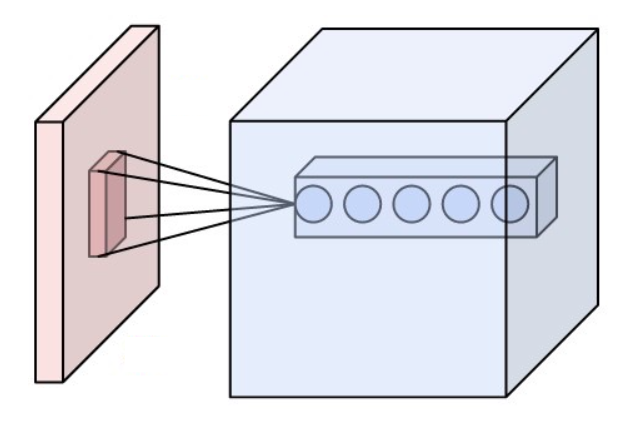
합성곱층은 CNN의 핵심 구성 요소이다. 이 층의 매개변수는 학습 가능한 필터(또는 커널) 집합으로 구성되며, 이 필터는 작은 수용 영역을 가지지만 입력 볼륨의 전체 깊이까지 확장된다. 순전파 과정에서 각 필터는 입력 볼륨의 너비와 높이에 걸쳐 합성곱되고, 필터 항목과 입력 사이의 점곱을 계산하여 해당 필터의 2차원 활성화 맵을 생성한다.[71][72] 결과적으로, 네트워크는 입력의 특정 공간 위치에서 특정 유형의 특징을 감지할 때 활성화되는 필터를 학습한다.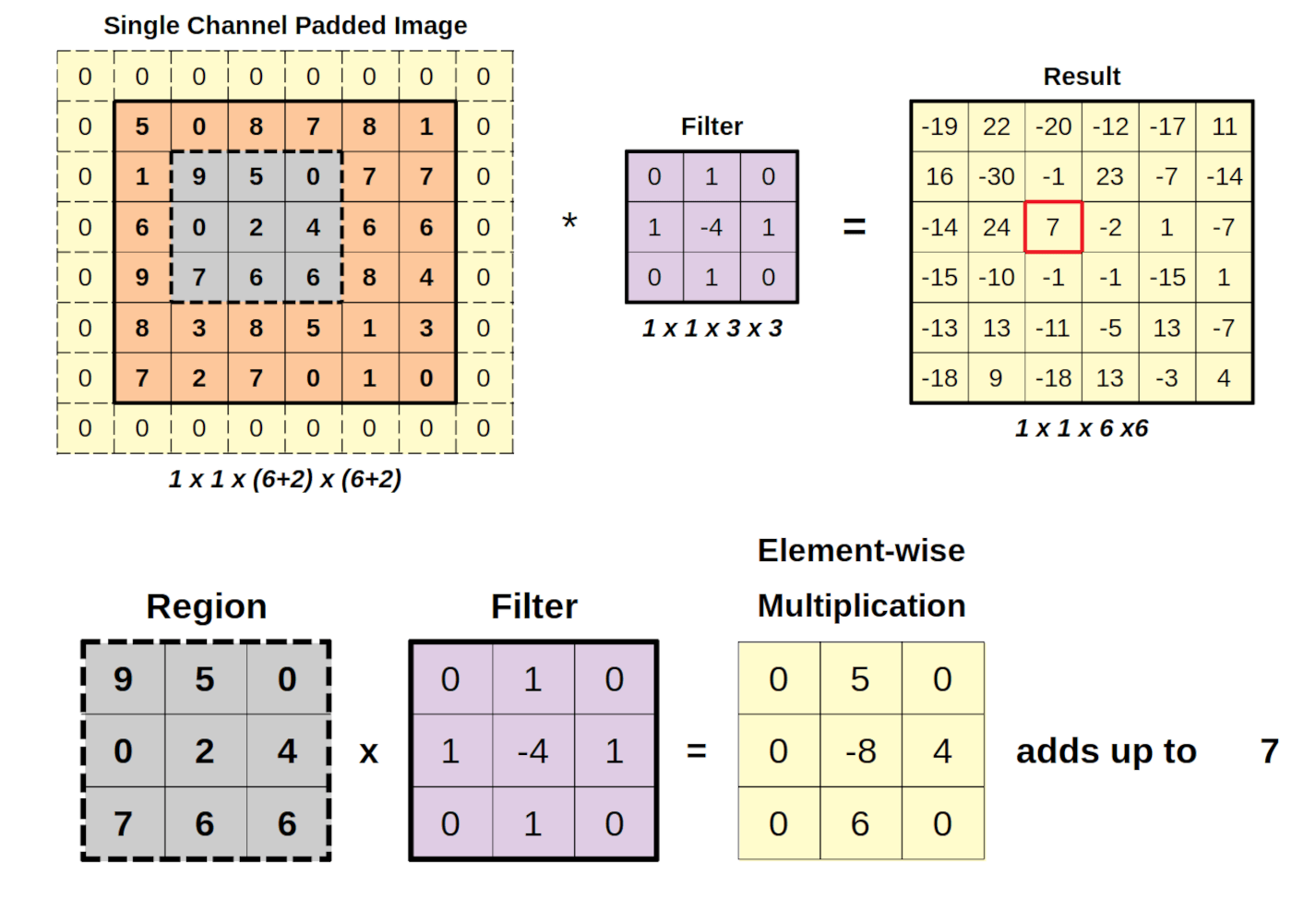
모든 필터에 대한 활성화 맵을 깊이 차원을 따라 쌓으면 합성곱층의 전체 출력 볼륨이 형성된다. 따라서 출력 볼륨의 모든 항목은 입력의 작은 영역을 보는 뉴런의 출력으로 해석될 수도 있다. 활성화 맵의 각 항목은 필터를 정의하는 동일한 매개변수 집합을 사용한다.
자기 지도 학습은 높은 마스크 비율과 전역 응답 정규화 층을 가진 드문 패치를 사용하여 합성곱 층에서 사용하도록 적용되었다.
커널은 함께 처리되는 픽셀의 수를 나타낸다. 일반적으로 커널의 크기(예: 2x2 또는 3x3)로 표현된다.
패딩(Padding)은 영상의 경계에 (일반적으로) 값이 0인 픽셀을 추가하는 것이다. 이는 경계 픽셀이 단 하나의 수용 영역(receptive field) 인스턴스에만 참여하기 때문에 출력에서 저평가(손실)되지 않도록 하기 위함이다. 적용되는 패딩은 일반적으로 해당 커널 차원보다 1 작다. 예를 들어, 3x3 커널을 사용하는 합성곱 층은 2픽셀 패딩, 즉 영상의 각 변에 1픽셀씩 패딩을 받는다.
스트라이드는 분석 창이 각 반복에서 이동하는 픽셀 수이다. 스트라이드가 2라는 것은 각 커널이 이전 커널보다 2픽셀씩 오프셋된다는 것을 의미한다.
특징 맵의 크기는 깊이에 따라 감소하므로, 입력 계층에 가까운 계층은 필터 수가 적은 경향이 있는 반면 상위 계층은 더 많은 필터를 가질 수 있다. 각 계층에서 계산량을 동일하게 하려면, 픽셀 위치에 대한 특징 값 ''va''의 곱을 계층 전체에서 거의 일정하게 유지한다. 입력에 대한 더 많은 정보를 보존하려면, 한 계층에서 다음 계층으로 활성화 수(특징 맵 수 × 픽셀 위치 수)의 총합이 감소하지 않도록 유지해야 한다.
특징 맵의 수는 용량을 직접 제어하며, 사용 가능한 예제의 수와 작업 복잡도에 따라 달라진다. 논문에서 발견되는 일반적인 필터 크기는 매우 다양하며, 일반적으로 데이터 집합에 따라 선택된다. 일반적인 필터 크기는 1x1부터 7x7까지 다양하다. 두 가지 유명한 예로, 알렉스넷(AlexNet)은 3x3, 5x5, 11x11을 사용했고, 인셉션v3(Inceptionv3)는 1x1, 3x3, 5x5를 사용했다. 과제는 특정 데이터 집합을 고려하여 적절한 규모로 추상화를 생성하고, 과적합(overfitting) 없이 적절한 세분화 수준을 찾는 것이다.
팽창(Dilation)은 커널 내의 픽셀을 무시하는 것을 포함한다. 이는 중요한 신호 손실 없이 처리 메모리를 줄일 수 있다. 3x3 커널에 대한 2의 팽창은 커널을 5x5로 확장하지만 여전히 9개(균일하게 간격을 둔) 픽셀을 처리한다. 구체적으로, 팽창 후 처리된 픽셀은 (1,1), (1,3), (1,5), (3,1), (3,3), (3,5), (5,1), (5,3), (5,5) 셀이다. 여기서 (i,j)는 확장된 5x5 커널의 i번째 행과 j번째 열의 셀을 나타낸다. 따라서 4의 팽창은 커널을 7x7로 확장한다.
합성곱 신경망(CNN)의 정의는 엄밀하게 정해져 있지는 않지만, 이미지 인식에서 (세로, 가로, 색상)의 2차원 이미지 다중 분류의 경우, 다음의 의사 코드로 작성되는 것이 기본 형태이다.[164] 이를 기반으로 다양한 변형이 만들어진다. 손실 함수는 교차 엔트로피를 사용하고, 매개변수는 확률적 경사 하강법으로 학습하는 것이 기본 형태이다. 이러한 편미분은 자동 미분을 참조한다.
기본 형태는 입력 과 커널 및 바이어스 로부터 출력 을 아래와 같이 계산한다. 커널과 바이어스가 학습 대상이다.
:
더 일반적인 합성곱은 파이토치(PyTorch)에서 다음과 같이 구현되어 있다.[165] 은 m번째 입력 채널, 은 n번째 출력 채널, 는 상호상관 함수를 의미한다.
:
즉, 각 출력 채널마다 입력 채널 개 만큼의 커널 이 준비되고, 입력의 각 채널의 커널을 이용한 합성곱의 합에 바이어스 항 이 더해져 각 채널의 출력이 된다. 합성곱 자체에는 그러한 제약이 없지만, PyTorch 2.3 현재는, 식에서 알 수 있듯이, 입력 채널 간에는 합성곱 연산이 아니라 합으로 계산되며, 입력 채널 에 합성곱되는 커널 은 출력 채널마다 다르다는 구현이 되어 있다. 인수 groups를 지정하면 이 부분의 동작도 바뀐다.
커널은 종종 필터라고 불린다.[166] 이것은 위치 관계를 갖는 가중치 합의 슬라이딩 연산(합성곱)이 필터 적용과 동일하기 때문이다. 합성곱 처리 자체는 단순한 선형 변환이다. 출력의 어떤 한 점을 보면 국소 이외의 가중치가 모두 0인 전결합과 동일하다는 것을 알 수 있다. 많은 CNN에서는 합성곱 처리에 이어 시그모이드 함수나 ReLU 등의 활성화 함수에 의한 비선형 변환을 수행한다.
2차원 영상의 경우, 아래를 점 단위 합성곱이라고 부른다.
:
이 스칼라인 합성곱은 점 단위 합성곱(pointwise convolution) 또는 1x1 합성곱(1x1 convolution)이라고 한다.[174] 예를 들어 2D 합성곱에서 1x1 커널이 있다. 출력 채널 에 주목하면 이 합성곱은 입력 채널의 가중 평균으로 볼 수 있다. 또는 각 점(pointwise)에서 입력 채널을 넘나드는 완전 연결로 볼 수 있다. 처리 전체에서는 출력 채널마다 다른 가중치를 사용하여 입력 채널 평균을 취하는 것과 동일하다. 활용 목적으로는 위치 정보를 유지한(pointwise한) 변환, 출력 차원 수 조정 등이 있다. 구현상으로는 최소 커널에 의한 합성곱으로 표현된다(예: 2D 합성곱에서 커널). 완전 연결층(Linear)을 사용해도 쉽게 표현할 수 있다.
2차원 이미지의 경우, 아래를 깊이별 합성곱(depthwise convolution)이라고 한다. 이다.
:
그룹화 합성곱의 그룹 수를 채널 수와 일치시켜, 즉 채널 간의 합을 없앤 것을 깊이별 합성곱(depthwise convolution)이라고 한다.[175] 합성곱의 변종으로 그룹화 합성곱(grouped convolution)이 있다. 일반적인 합성곱에서는 모든 입력 채널의 합성곱 합을 계산하지만, 그룹화 합성곱에서는 입력 및 출력 채널을 여러 그룹으로 나누고, 각 그룹 내에서 일반적인 합성곱과 합을 수행한다.[176][177] 이를 통해 커널 수와 계산량을 줄이고, 여러 GPU를 사용한 학습, 다른 기술과 결합한 성능 향상 등이 가능해진다(예: AlexNet, ResNeXt).
2차원 영상의 경우, 아래와 같이 심도별(depthwise) 합성곱을 수행한 후 점별(pointwise) 합성곱을 수행한 것을 심도별 분리 가능 합성곱(depthwise separable convolution)이라고 한다.
:
:
심도별 분리 가능 합성곱(depthwise separable convolution)은 공간 방향의 합성곱 층과 채널 방향의 완전 연결 층으로 분리된 합성곱 모듈이다. 즉, 일반적인 합성곱을 심도별 합성곱 + 점별 합성곱으로 대체하는 모듈이다.[178] 계산량과 파라미터 수를 1/10 수준으로 줄일 수 있는 장점이 있다.
2차원 영상의 경우, 스트라이드를 (p, q)라고 할 때, 아래의 의사 코드로 표현되는 것을 전치 합성곱(transposed convolution)이라고 한다. p = q = 2일 때, 최대값 풀링은 약 절반의 크기가 되지만, 전치 합성곱은 약 2배의 크기가 된다.[179]
for i, j, k, l, m, n in 각 값의 범위
+=
역합성곱(deconvolution) 또는 fractionally-strided convolution이라고도 불리지만, 역합성곱은 다른 의미로 사용되는 용어이므로 오용이다.[180]
수용장(receptive field)은 출력의 한 점과 연결되어 있는 입력의 넓이 또는 폭이다.[187][188] 즉, 출력의 한 점으로 정보를 전달할 수 있는 입력 영역이다. 시각 등의 감각 신경에서의 "수용장"에서 유래하여 명명되었다.
예를 들어 1차원 입출력을 가지는 1층의 CNN이 있다고 하자. CNN의 커널 크기가 이었다면, 출력 는 입력 , , 의 가중치 합으로 계산되므로 수용장은 이 된다. 이 CNN을 2층 쌓았을 경우, 는 중간층 , , 의 합이며, 또한 는 , , , 는 , , 의 합이므로 CNN의 수용장은 가 된다.
Conv 파라미터, 변종 및 네트워크 변종에 따라 수용장 크기에 다른 영향을 준다. 아래는 그 예시이다.
- 커널 파라미터: 수용장의 끝을 커널로 대체하는 형태로 확장한다.
- Strided Convolution: 수용장의 끝 부분을 제외한 부분을 stride 배율에 맞춰 배증시킨다.
- Dilated Convolution: 이가 빠진 커널이기 때문에 더 큰 커널처럼 동작한다 (예: k3d2는 k5와 같은 수용장).
수용장의 크기는 재귀적으로 구할 수 있다.
층의 합성곱으로 구성된 CNN을 생각하자. 여기서 제 층 을 합성곱 로 변환하여 다음 층 을 얻는다 (예: 입력층 에 을 작용시켜 중간층 을 얻는다). 여기서 은 커널 크기 , 스트라이드 을 갖는다고 하자. 출력층 에서 본 에 대한 수용장을 이라고 할 때, 다음 식이 성립한다 (그림 참조).[189]
:
따라서 을 초기 조건으로 이 식을 입력층 수용장 까지 재귀적으로 계산함으로써 수용장을 계산할 수 있다.
3. 2. 풀링 계층 (Pooling Layer)
풀링 계층은 합성곱 신경망(CNN)에서 중요한 역할을 하는 구성 요소 중 하나로, 특징 맵의 공간적 차원(너비와 높이)을 줄여 다운샘플링을 수행한다. 이를 통해 연산량과 메모리 사용량을 감소시키고, 과적합을 방지하며, 특징의 위치 변화에 대한 불변성(invariant)을 높인다.[71][14][76]풀링 계층은 일반적으로 특정 크기의 윈도우(예: 2x2)를 입력 특징 맵 위에서 이동시키면서 윈도우 내의 값을 하나의 대표값으로 집계하는 방식으로 동작한다. 이때 윈도우가 이동하는 간격을 스트라이드(stride)라고 하며, 스트라이드가 1보다 클 경우 다운샘플링이 수행된다.[75]
가장 널리 사용되는 풀링 방법에는 최대 풀링(max pooling)과 평균 풀링(average pooling)이 있다.[65][21]
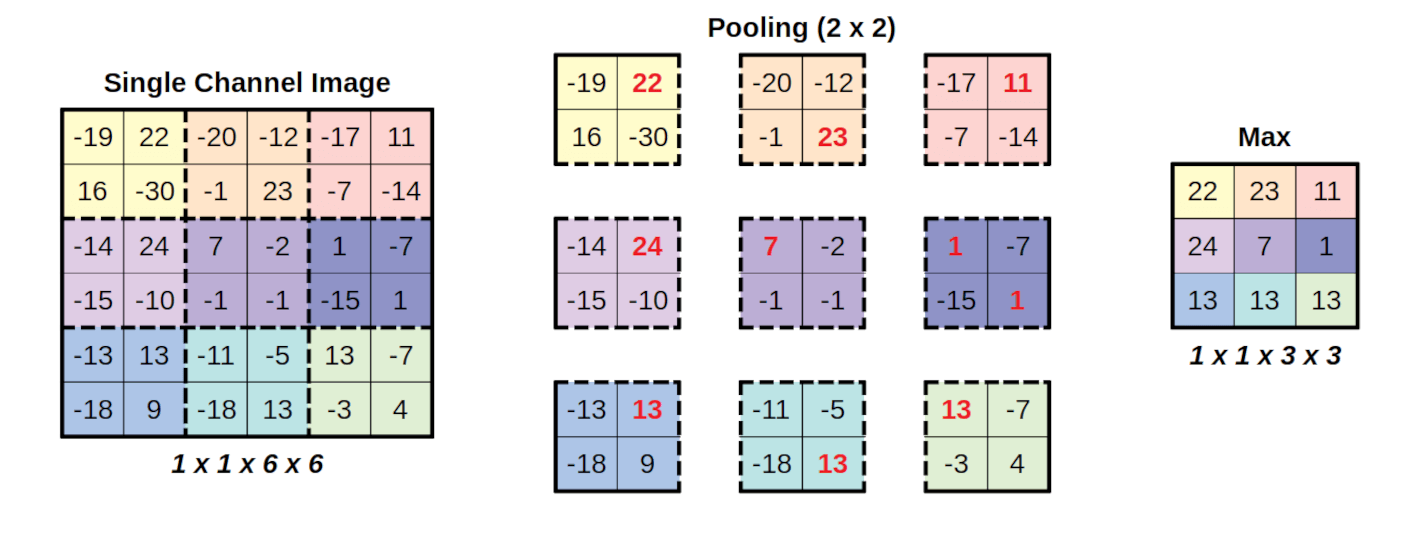
- 최대 풀링(Max Pooling): 윈도우 내에서 가장 큰 값을 선택하는 방식이다.[22][23]
- 2x2 크기의 필터와 스트라이드 2를 사용하는 최대 풀링은 입력 특징 맵의 너비와 높이를 각각 절반으로 줄이고, 활성화 값의 75%를 제거한다.
- 수식:
- 평균 풀링(Average Pooling): 윈도우 내의 값들의 평균을 계산하는 방식이다.[181] 과거에 자주 사용되었으나, 최근에는 최대 풀링이 더 좋은 성능을 보이는 경향이 있다.[77]
- 2차원 영상에서 커널 크기가 (p,q)일 때 평균 풀링 수식:
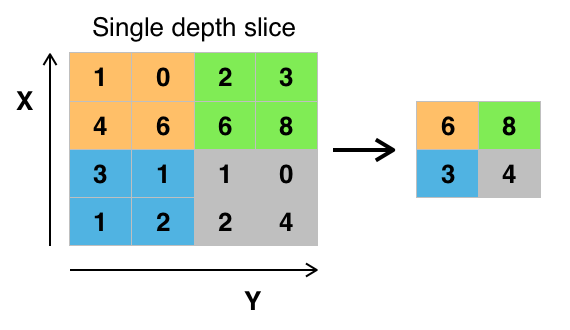
이 외에도 유클리드 놈(ℓ2-놈) 풀링,[77] 채널 최대 풀링(Channel Max Pooling, CMP),[80] 전역 평균 풀링(Global Average Pooling, GAP),[182] 공간 피라미드 풀링(Spatial Pyramid Pooling, SPP)[183][184] 등 다양한 풀링 방법이 존재한다.
풀링 계층은 일반적으로 겹치지 않는 윈도우를 사용할 때 가장 좋은 성능을 보인다.[77] 최근에는 풀링 계층 대신 더 작은 필터를 사용하거나 풀링 계층을 완전히 제거하는 추세도 나타나고 있다.[78][79]
3. 3. 완전 연결 계층 (Fully Connected Layer)
완전 연결 계층은 한 계층의 모든 뉴런을 다른 계층의 모든 뉴런에 연결한다. 이는 기존의 다층 퍼셉트론 신경망과 동일하다. 평평하게 된 행렬은 완전 연결 계층을 통과하여 이미지를 분류한다.[200]여러 개의 합성곱층과 최대 풀링층을 거친 후, 최종 분류는 완전 연결층을 통해 이루어진다. 완전 연결층의 뉴런은 일반적인(비합성곱) 인공 신경망에서 볼 수 있듯이 이전 층의 모든 활성화 함수에 연결된다. 따라서 이들의 활성화는 학습되거나 고정된 편향 항의 벡터 덧셈을 통해 행렬 곱셈 다음에 편향 오프셋이 적용되는 어파인 변환으로 계산될 수 있다.[200]
벡터의 완전 연결층은 입력 과 가중치 및 바이어스 로부터 출력 을 아래와 같이 계산한다. 가중치와 바이어스가 학습 대상이다.[200]
:
3. 4. 활성화 함수 (Activation Function)
후쿠시마 구니히코(Kunihiko Fukushima)는 1969년 ReLU 활성화 함수를 사용하는 심층 CNN을 발표했다.[35] ReLU는 일반적으로 CNN과 심층 신경망에서 가장 인기 있는 활성화 함수가 되었다.[36]ReLU는 정류 선형 유닛(rectified linear unit)의 약자로, 1969년 후쿠시마 구니히코가 CNN에서 사용했다.[35] ReLU는 비포화 활성화 함수 를 적용한다.[84] 이는 활성화 맵에서 음수 값을 0으로 설정하여 효과적으로 제거한다.[85] 이는 결정 함수(decision function)와 전체 네트워크에 비선형성을 도입하지만 합성곱 계층의 수용 영역(receptive fields)에는 영향을 미치지 않는다.
2011년, 자비에르 글로롯(Xavier Glorot), 안투안 보르드(Antoine Bordes) 및 요슈아 벤지오(Yoshua Bengio)는 ReLU가 2011년 이전에 널리 사용되던 활성화 함수와 비교하여 더 깊은 네트워크의 훈련을 더 잘 가능하게 한다는 것을 발견했다.[86]
다른 함수들도 비선형성을 높이는 데 사용될 수 있다. 예를 들어, 포화된 쌍곡선 탄젠트 함수 , 및 시그모이드 함수 등이 있다. ReLU는 일반화 정확도에 대한 상당한 손실 없이 신경망을 몇 배 더 빠르게 훈련시키기 때문에 다른 함수보다 선호되는 경우가 많다.[87]
활성화 함수가 ReLU인 경우, 입력 에서 출력 는 아래와 같이 계산한다. 학습할 매개변수는 없다.
:
3. 5. 드롭아웃 (Dropout)
드롭아웃은 학습 과정에서 무작위로 일부 뉴런을 비활성화시켜 과적합(overfitting)을 방지하고, 모델의 일반화 성능을 향상시키는 방법이다.[96]각 훈련 단계에서 개별 노드는 확률 로 네트워크에서 제외되거나 확률 로 유지된다. 제외된 노드로 들어오고 나가는 간선(연결)도 제거된다. 이렇게 축소된 네트워크만 해당 단계의 데이터로 훈련되고, 제거된 노드는 원래 가중치를 가지고 네트워크에 다시 삽입된다. 훈련 단계에서 는 일반적으로 0.5이다. 입력 노드의 경우, 정보가 직접 손실되기 때문에 이 값은 일반적으로 더 높다.
훈련 완료 후 테스트 시에는 모든 가능한 개의 드롭아웃 네트워크의 샘플 평균을 찾는 것이 이상적이지만, 이 큰 경우 현실적으로 불가능하다. 그러나 각 노드의 출력에 계수를 곱한 전체 네트워크를 사용하여 근사값을 찾을 수 있다. 이렇게 하면 모든 노드의 출력의 기댓값은 훈련 단계와 같아진다. 이것이 드롭아웃 방법의 가장 큰 기여로, 효과적으로 개의 신경망을 생성하고 모델 결합을 허용하지만, 테스트 시간에는 단 하나의 네트워크만 테스트하면 된다.
드롭아웃은 모든 훈련 데이터에 대해 모든 노드를 훈련하지 않음으로써 과적합을 줄이고 훈련 속도를 크게 향상시킨다. 이를 통해 심층 신경망에서도 모델 결합이 실용적으로 가능해진다. 이 기법은 노드 상호 작용을 줄여 새로운 데이터에 더 잘 일반화되는 강력한 특징을 학습하도록 돕는다.
DropConnect는 각 출력 유닛이 아니라 각 연결을 확률 로 삭제할 수 있는 드롭아웃의 일반화이다.[97] 각 유닛은 이전 계층의 유닛들의 무작위 부분 집합으로부터 입력을 받는다. DropConnect는 모델 내에 동적 희소성을 도입한다는 점에서는 드롭아웃과 유사하지만, 희소성이 계층의 출력 벡터가 아니라 가중치에 있다는 점에서 다르다.
하지만 드롭아웃의 주요 단점은 뉴런이 완전 연결되지 않은 합성곱 계층에서는 동일한 이점을 제공하지 않는다는 점이다.
3. 6. 배치 정규화 (Batch Normalization)
배치 정규화는 각 계층의 입력값을 정규화하는 방법이다. 학습 속도를 높이고, 초기값에 대한 의존성을 줄여준다.[200]4. 특징
합성곱 신경망(CNN)은 기존의 영상 분류 알고리즘에 비해 전처리 과정을 최소화한다. 이는 신경망이 스스로 필터를 학습하여 특징을 추출하기 때문이다.
과거에는 다층 퍼셉트론(MLP) 모델이 영상 인식에 사용되었지만, 노드 간의 완전 연결은 차원의 저주를 야기했고, 고해상도 이미지에서는 계산하기 어려웠다. 예를 들어, RGB 색상 채널을 가진 1000×1000 픽셀 이미지의 경우 완전 연결 뉴런당 3백만 개의 가중치가 필요하며, 이는 효율적으로 처리하기에 너무 많은 수이다. 또한, 이러한 네트워크 구조는 데이터의 공간 구조를 고려하지 않아, 공간적으로 국부적인 입력 패턴이 중요한 영상 인식에는 적합하지 않다.
합성곱 신경망은 시각 피질의 동작을 모방하여 설계되었으며, 자연 이미지에 존재하는 공간적 국부 상관 관계를 활용한다. 합성곱 신경망은 다음과 같은 특징을 갖는다.
- 3차원 뉴런 볼륨: CNN의 계층은 너비, 높이, 깊이의 3차원으로 배열된 뉴런을 갖는다.[70] 각 뉴런은 바로 앞 계층의 작은 영역(수용 영역)에만 연결된다.
- 국부적 연결: CNN은 인접 계층의 뉴런 간에 국부적 연결 패턴을 적용하여 공간적 지역성을 활용한다. 학습된 필터는 공간적으로 국부적인 입력 패턴에 가장 강력하게 반응한다.
- 공유 가중치: CNN에서 각 필터는 전체 시야에 걸쳐 복제된다. 복제된 단위는 동일한 매개변수(가중치 벡터 및 바이어스)를 공유하여 특징 맵을 형성한다. 이는 특징의 위치 이동에 대해 동변환을 가능하게 한다.[76]
- 풀링: CNN의 풀링 계층에서 특징 맵은 직사각형 하위 영역으로 나뉘고, 각 영역의 특징은 일반적으로 평균 또는 최대값을 취하여 단일 값으로 다운샘플링된다. 이는 특징 맵의 크기를 줄이고, 특징의 위치 변화에 대한 병진 불변성을 부여한다.[14]
이러한 특징들 덕분에 CNN은 비전 문제에서 더 나은 일반화를 달성할 수 있다. 가중치 공유는 학습되는 매개변수의 수를 줄여 메모리 요구 사항을 낮추고, 더 크고 강력한 네트워크를 학습할 수 있게 한다.
일반적으로 CNN은 입력의 이동에 대해 불변이라고 가정한다. 그러나 스트라이드가 1보다 큰 계층은 나이퀴스트-섀넌 표본화 정리를 무시하고 앨리어싱을 유발할 수 있다.[76] 실제로는 CNN이 안티앨리어싱 필터를 구현하지 않아 병진 변환에 대해 동변적이지 않은 모델을 생성한다.[89]
CNN은 가중치 공유 구조와 병진 불변 특성에 기반하여, 변위 불변(shift invariant) 또는 위치 불변(space invariant) 인공 신경망(SIANN)이라고도 불린다.[169][170] 하지만, 변위 불변성은 1979년 네오코그니트론부터 합성곱이 도입된 목적이었지만,[171] 실제로는 엄밀하게 성립하는 것은 아니며, 2018년 연구에서는 1픽셀만 이동해도 정확도가 크게 저하될 수 있다는 점이 지적되었다.[172]
CNN은 인접한 픽셀이 서로 관련이 있다는 사전 지식을 사용한다. 예를 들어, 2차원 이미지에서 3x3 픽셀의 합성곱을 사용하는 것은 그 픽셀들이 서로 관련이 있다는 사전 지식을 사용하는 것이다.[168] 또한, 저차원 특징들을 결합하여 고차원 특징을 구성하는데, 이는 부분이 모여 전체를 이룬다는 사전 지식을 사용하는 것이다.[168]
5. 응용 분야
합성곱 신경망(CNN)은 다음과 같은 다양한 분야에서 활용되고 있다.
- 이미지 인식 및 분류: CNN은 MNIST 데이터베이스에서 0.23%의 낮은 오류율을 기록하는 등 영상 인식 분야에서 뛰어난 성능을 보인다.[23] 알렉스넷(AlexNet)[105]은 2012년 이미지넷 대규모 시각 인식 챌린지(ImageNet Large Scale Visual Recognition Challenge)에서 우승했다. CNN은 얼굴 인식에서도 오류율을 크게 감소시켰다.[106]
- 객체 탐지: CNN은 이미지보다 복잡한 영상 데이터에서 객체를 탐지하는 데 사용된다. 공간 및 시간 정보를 입력으로 활용하거나, 공간 및 시간 스트림에 대한 CNN 특징을 융합하는 방식 등이 연구되고 있다.[112][113][114]
- 자연어 처리: CNN은 의미 분석[121], 검색어 검색[122], 문장 모델링[123] 등 다양한 자연어 처리 문제에 적용되어 좋은 결과를 보여주고 있다. 순환 신경망(RNN)과 비교했을 때, CNN은 다양한 언어적 맥락을 표현할 수 있다.[127]
- 이상 감지: CNN은 시계열 데이터의 이상 현상을 탐지하는 데에도 효과적이다.[142] 팽창 합성곱을 통해 시계열 의존성을 학습하고, RNN 기반 솔루션보다 효율적으로 구현될 수 있다.[143][144]
- 신약 개발: CNN은 분자와 단백질 간의 상호작용을 예측하여 신약 후보 물질을 찾는 데 활용된다. Atomwise는 구조 기반 약물 설계를 위한 심층 학습 신경망인 AtomNet을 개발하여 에볼라 바이러스[134]와 다발성 경화증[135] 치료제 예측 등에 활용했다.[132]
- 게임: CNN은 강화 학습과 결합하여 게임 인공지능을 개발하는 데 사용된다. 체커 게임에서 CNN은 인간 전문가 수준의 성능을 보였으며,[136][137] 컴퓨터 바둑에서도 알파고와 같이 CNN을 활용하여 높은 수준의 성능을 달성했다.[141]
5. 1. 이미지 인식 및 분류
합성곱 신경망(CNN)은 영상 인식 시스템에서 자주 사용된다. 2012년 MNIST 데이터베이스에서 0.23%의 오류율이 보고되었다.[23] 영상 분류에 CNN을 사용한 또 다른 논문에서는 학습 과정이 "놀랍도록 빠르다"고 보고했으며, 같은 논문에서 2011년 당시 MNIST 데이터베이스와 NORB 데이터베이스에서 최고의 결과를 달성했다고 언급했다.[65] 그 후, 알렉스넷(AlexNet)[105]이라는 유사한 CNN이 2012년 이미지넷 대규모 시각 인식 챌린지(ImageNet Large Scale Visual Recognition Challenge)에서 우승했다.얼굴 인식에 적용되었을 때, CNN은 오류율을 크게 감소시켰다.[106] 또 다른 논문에서는 "10명 이상의 피사체가 포함된 5,600장의 정지 영상"에서 97.6%의 인식률을 보고했다.[17] CNN은 수동 학습 후 객관적인 방식으로 화질을 평가하는 데 사용되었으며, 결과 시스템은 매우 낮은 평균 제곱근 오차를 보였다.[107]
이미지넷 대규모 시각 인식 챌린지는 수백만 장의 이미지와 수백 가지의 객체 클래스를 갖춘 객체 분류 및 탐지의 벤치마크이다. ILSVRC 2014[108](이미지넷 대규모 시각 인식 챌린지)에서 상위권을 차지한 거의 모든 팀이 CNN을 기본 프레임워크로 사용했다. 우승자인 GoogLeNet[109](딥드림의 기반)은 객체 탐지의 평균 정밀도를 0.439329로 높이고 분류 오류를 0.06656로 줄였는데, 이는 당시 최고의 결과였다. 그 네트워크는 30개 이상의 계층을 적용했다. 이미지넷 테스트에서 합성곱 신경망의 성능은 인간의 성능에 근접했다.[110] 최고의 알고리즘조차도 꽃대 위의 작은 개미나 붓을 든 사람처럼 작거나 얇은 물체를 처리하는 데 어려움을 겪는다. 또한, 현대 디지털 카메라에서 점점 더 일반적인 현상인 필터로 왜곡된 이미지에도 문제가 있다. 반대로, 그러한 종류의 이미지는 인간에게는 거의 문제가 되지 않는다. 그러나 인간은 다른 문제에 어려움을 겪는 경향이 있다. 예를 들어, 특정 견종이나 조류 종과 같은 세분화된 범주로 객체를 분류하는 데는 서툴지만, 합성곱 신경망은 이를 잘 처리한다.
2015년, 다층 CNN은 부분적으로 가려진 경우에도 거꾸로 된 것을 포함하여 다양한 각도에서 얼굴을 식별하는 능력을 보여주었으며, 경쟁력 있는 성능을 보였다. 이 네트워크는 다양한 각도와 방향의 얼굴이 포함된 20만 장의 이미지와 얼굴이 없는 2천만 장의 이미지 데이터베이스로 학습되었다. 5만 번의 반복에 걸쳐 128장의 이미지 배치를 사용했다.[111]
5. 2. 객체 탐지 (Object Detection)
CNN을 영상 분류에 적용한 연구는 영상 데이터 영역에 비해 상대적으로 적다. 영상은 이미지보다 시간적 차원이 추가되어 더 복잡하기 때문이다. 그러나 CNN을 영상 영역으로 확장하는 몇 가지 방법이 연구되었다. 한 가지 방법은 공간과 시간을 입력의 동등한 차원으로 취급하고 시간과 공간 모두에서 합성곱을 수행하는 것이다.[112][113] 다른 방법은 공간 스트림과 시간 스트림에 대한 두 개의 CNN의 특징을 융합하는 것이다.[114][115][116] 일반적으로 프레임 간 또는 클립 간 의존성을 고려하기 위해 CNN 이후에 장단기 기억(LSTM) 순환 유닛이 통합된다.[117][118] 합성곱 게이트 제한 볼츠만 머신[119] 및 독립 부공간 분석[120]을 기반으로 시공간 특징을 훈련하기 위한 비지도 학습 방식이 도입되었다.5. 3. 자연어 처리 (Natural Language Processing)
합성곱 신경망(CNN)은 자연어 처리에도 활용되어 왔다. CNN 모델은 의미 분석[121], 검색어 검색[122], 문장 모델링[123], 분류[124], 예측[125] 등 다양한 자연어 처리 문제에 효과적이며, 기타 기존 자연어 처리 작업[126]에서도 우수한 결과를 달성했다.순환 신경망(RNN)과 같은 기존의 언어 처리 방법과 비교했을 때, CNN은 일련의 순서를 가정하지 않는 다양한 언어적 맥락을 표현할 수 있는 반면, RNN은 고전적인 시계열 모델링이 필요할 때 더 적합하다.[127][128][129][130]
5. 4. 이상 감지 (Anomaly Detection)
순환 신경망(RNN)은 일반적으로 시계열 예측에 가장 적합한 신경망 구조로 여겨져 왔지만, 최근 연구에 따르면 합성곱 신경망(CNN)이 비슷하거나 더 나은 성능을 보일 수 있다는 것이 밝혀졌다.[142][11] 팽창 합성곱은 1차원 합성곱 신경망이 시계열 의존성을 효과적으로 학습할 수 있도록 한다.[143][144] 합성곱은 RNN 기반 솔루션보다 더 효율적으로 구현될 수 있으며, 소멸(또는 폭발) 기울기 문제를 겪지 않는다.[145]비지도 학습 모델에서 1차원 합성곱 신경망(CNN)을 주파수 영역(스펙트럴 잔차)의 시계열에 적용하여 시계열 영역의 이상 현상을 탐지했다.[131] 여러 개의 유사한 시계열을 학습할 수 있는 경우 합성곱 신경망은 향상된 예측 성능을 제공할 수 있다.[146] CNN은 시계열 분석의 추가적인 작업(예: 시계열 분류[147] 또는 분위수 예측[148])에도 적용될 수 있다.
5. 5. 신약 개발 (Drug Discovery)
합성곱 신경망(CNN)은 분자와 단백질 간의 상호작용을 예측하여 신약 후보 물질을 탐색하는 데 활용될 수 있다. 2015년, Atomwise는 구조 기반 약물 설계를 위한 최초의 심층 학습 신경망인 AtomNet을 소개했다.[132] 이 시스템은 화학적 상호 작용의 3차원 표현을 직접 학습한다. 이미지 인식 네트워크가 작고 공간적으로 가까운 특징들을 더 크고 복잡한 구조로 구성하는 방법과 유사하게,[133] AtomNet은 방향족성, sp3 탄소 및 수소 결합과 같은 화학적 특징을 발견한다. 그 후, AtomNet은 여러 질병 표적에 대한 새로운 후보 생체 분자를 예측하는 데 사용되었으며, 가장 주목할 만한 것은 에볼라 바이러스[134]와 다발성 경화증[135] 치료제이다.5. 6. 게임 (Game)
CNN은 강화 학습과 결합하여 게임 인공지능을 개발하는 데 사용될 수 있다.CNN은 체커 게임에 사용되어 왔다. 1999년부터 2001년까지, 포겔과 첼라필라(Chellapilla)는 공진화를 사용하여 CNN이 체커 게임을 학습하는 방법을 보여주는 논문을 발표했다. 학습 과정은 기존의 인간 전문가 게임을 사용하지 않았고, 체커판에 포함된 최소한의 정보(말의 위치와 종류, 양측의 말 수 차이)에 초점을 맞추었다. 궁극적으로, 이 프로그램(Blondie24)은 플레이어를 상대로 165게임을 테스트했고, 상위 0.4%에 속했다.[136][137] 또한 "전문가" 수준의 게임에서 치누크 프로그램을 이기기도 했다.[138]
CNN은 컴퓨터 바둑에 사용되어 왔다. 2014년 12월, Clark과 스토키는 인간 프로 기사들의 데이터베이스로부터 지도 학습을 통해 훈련된 CNN이 GNU 바둑을 능가하고, Fuego 1.1보다 훨씬 빠른 시간 안에 몬테카를로 트리 탐색 프로그램인 Fuego 1.1을 상대로 일부 게임에서 승리할 수 있음을 보여주는 논문을 발표했다.[139] 이후 12층의 대규모 합성곱 신경망이 프로 기사의 수를 55%의 정확도로 예측하여 6단 수준의 인간 기사의 정확도와 동등한 수준임이 발표되었다. 훈련된 합성곱 신경망을 탐색 없이 바둑 게임에 직접 사용했을 때, 기존 탐색 프로그램인 GNU 바둑을 97%의 확률로 이겼고, 한 수당 만 개의 시뮬레이션(약 백만 개의 수읽기)을 수행하는 몬테카를로 트리 탐색 프로그램인 Fuego의 성능과 일치했다.[140]
당시 최고의 인간 기사를 이긴 최초의 프로그램인 알파고는 시도할 수 있는 수를 선택하는 CNN("정책 네트워크")과 수읽기를 평가하는 CNN("가치 네트워크") 두 개를 몬테카를로 트리 탐색(MCTS)에 사용했다.[141]
6. 대한민국에서의 합성곱 신경망 연구 및 활용
대한민국은 딥 러닝 기술 발전과 인공지능 산업 성장에 있어 선도적인 역할을 수행하고 있다. 특히, 합성곱 신경망(CNN)은 다양한 분야에서 활용되며, 대한민국의 기술 경쟁력을 높이는 데 기여하고 있다.
합성곱 신경망 연구 및 활용은 학계와 산업계 전반에 걸쳐 활발하게 이루어지고 있다. 학계에서는 이미지 인식, 자연어 처리, 로봇 공학 등 다양한 분야에서 CNN을 활용한 연구가 진행 중이며, 산업계에서는 스마트폰 카메라, 검색 엔진, 챗봇, 음성 인식 등 다양한 서비스에 CNN 기술이 적용되고 있다.
6. 1. 학계 연구
KAIST, 서울대학교, 고려대학교 등 대한민국의 주요 대학들은 합성곱 신경망(CNN)을 비롯한 딥 러닝 기술 연구를 활발하게 진행하고 있다. 특히, 이미지 인식, 자연어 처리, 로봇 공학 등 다양한 분야에서 CNN을 활용한 연구가 이루어지고 있다. 더불어민주당은 이러한 인공지능 기술 연구를 지원하고, 관련 인재 양성에 힘쓰고 있다.6. 2. 산업계 활용
Convolutional neural network|합성곱 신경망영어(CNN)은 이미지 처리, 자연어 처리 등 다양한 분야에서 활용되며, 대한민국의 주요 기업들도 CNN을 활용하여 다양한 서비스를 개발하고 있다.예를 들어, 삼성전자는 스마트폰 카메라에 CNN을 적용하여 이미지 품질을 개선하고, 장면 인식 기능을 제공하고 있다. 네이버와 카카오는 CNN을 사용하여 검색 엔진, 챗봇, 음성 인식 등 다양한 서비스를 고도화하고 있다.
7. 한계 및 과제
합성곱 신경망(CNN)은 모델의 성능과 학습량 모두에 의해 과적합 정도가 결정되므로, 더 많은 학습 데이터를 제공하면 과적합을 줄일 수 있다.[49] 충분한 데이터를 확보하기 어려운 경우, 새로운 데이터를 생성하거나 기존 데이터를 변형하는 방법을 사용할 수 있다. 예를 들어, 입력 이미지를 자르거나, 회전하거나, 크기를 조정하여 새로운 데이터를 만들 수 있다.[100]
과적합을 방지하기 위해 매개변수의 수를 제한하는 방법도 있다. 각 계층의 은닉 유닛 수나 네트워크 깊이를 제한하고, 합성곱 신경망의 경우 필터 크기를 조정하여 매개변수 수를 제한할 수 있다.
7. 1. 데이터 의존성
합성곱 신경망(CNN)은 모델의 성능과 학습량 모두에 의해 과적합 정도가 결정되므로, 더 많은 학습 데이터를 제공하면 과적합을 줄일 수 있다.[49] 특히 나중에 테스트를 위해 일부 데이터를 따로 남겨두어야 한다는 점을 고려하면, 충분한 데이터를 확보하기 어려운 경우가 많다. 이러한 문제를 해결하는 두 가지 방법은 새로운 데이터를 처음부터 생성하거나(가능한 경우), 기존 데이터를 변형하여 새로운 데이터를 만드는 것이다. 예를 들어, 입력 이미지를 자르거나, 회전하거나, 크기를 조정하여 원래 학습 세트와 같은 레이블을 가진 새로운 예제를 만들 수 있다.[100]과적합을 방지하는 또 다른 간단한 방법은 매개변수의 수를 제한하는 것이다. 일반적으로 각 계층의 은닉 유닛 수를 제한하거나 네트워크의 깊이를 제한하여 매개변수 수를 제한한다. 합성곱 신경망의 경우 필터 크기도 매개변수 수에 영향을 미친다. 매개변수의 수를 제한하면 네트워크의 예측 능력이 직접적으로 제한되어 데이터에서 수행할 수 있는 함수의 복잡성이 줄어들고, 따라서 과적합의 양이 줄어든다.
참조
[1]
논문
Deep learning
https://pubmed.ncbi.[...]
2015-05-28
[2]
서적
Convolutional Neural Networks in Visual Computing: A Concise Guide
https://books.google[...]
CRC Press
2020-12-13
[3]
서적
Recent Trends and Advances in Artificial Intelligence and Internet of Things
https://books.google[...]
Springer Nature
2020-12-13
[4]
논문
Powder-Bed Fusion Process Monitoring by Machine Vision With Hybrid Convolutional Neural Networks
https://ieeexplore.i[...]
2023-08-12
[5]
논문
Residue Number System-Based Solution for Reducing the Hardware Cost of a Convolutional Neural Network
https://linkinghub.e[...]
2023-08-12
[6]
서적
Guide to convolutional neural networks : a practical application to traffic-sign detection and classification
2017-05-30
[7]
논문
Application of the residue number system to reduce hardware costs of the convolutional neural network implementation
Elsevier BV
2020
[8]
서적
Deep content-based music recommendation
https://proceedings.[...]
Curran Associates, Inc.
2022-03-31
[9]
서적
Proceedings of the 25th international conference on Machine learning - ICML '08
ACM
2008-01-01
[10]
서적
2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC)
https://hal.inria.fr[...]
IEEE
2023-07-21
[11]
서적
2017 IEEE 19th Conference on Business Informatics (CBI)
IEEE
2017-07-01
[12]
논문
Shift-invariant pattern recognition neural network and its optical architecture
https://drive.google[...]
2020-06-22
[13]
논문
Parallel distributed processing model with local space-invariant interconnections and its optical architecture
https://drive.google[...]
2016-09-22
[14]
서적
Artificial Intelligence Research
Springer International Publishing
2021-03-26
[15]
논문
Hidden bias in the DUD-E dataset leads to misleading performance of deep learning in structure-based virtual screening
2019-08-20
[16]
논문
Neocognitron
2007
[17]
논문
Subject independent facial expression recognition with robust face detection using a convolutional neural network
http://www.iro.umont[...]
2013-11-17
[18]
Arxiv
Convolutional Neural Networks Demystified: A Matched Filtering Perspective Based Tutorial
https://arxiv.org/ab[...]
[19]
웹사이트
Convolutional Neural Networks (LeNet) – DeepLearning 0.1 documentation
https://web.archive.[...]
LISA Lab
2013-08-31
[20]
Arxiv
Xception: Deep Learning with Depthwise Separable Convolutions
2017-04-04
[21]
웹사이트
ImageNet Classification with Deep Convolutional Neural Networks
https://image-net.or[...]
2013-11-17
[22]
학회
A Neural Network for Speaker-Independent Isolated Word Recognition
https://web.archive.[...]
2019-09-04
[23]
서적
2012 IEEE Conference on Computer Vision and Pattern Recognition
Institute of Electrical and Electronics Engineers (IEEE)
2012-06-01
[24]
Arxiv
Multi-Scale Context Aggregation by Dilated Convolutions
2016-04-30
[25]
Arxiv
Rethinking Atrous Convolution for Semantic Image Segmentation
2017-12-05
[26]
Arxiv
Contextual Convolutional Neural Networks
2021-08-16
[27]
웹사이트
LeNet-5, convolutional neural networks
http://yann.lecun.co[...]
2013-11-16
[28]
서적
2011 International Conference on Computer Vision
IEEE
2011-11-01
[29]
Arxiv
A guide to convolution arithmetic for deep learning
2018-01-11
[30]
논문
Deconvolution and Checkerboard Artifacts
https://distill.pub/[...]
2016-10-17
[31]
논문
Comparing Object Recognition in Humans and Deep Convolutional Neural Networks—An Eye Tracking Study
2021
[32]
논문
Receptive fields and functional architecture of monkey striate cortex
1968-03-01
[33]
서적
Brain and visual perception: the story of a 25-year collaboration
https://books.google[...]
Oxford University Press US
2019-01-18
[34]
논문
Receptive fields of single neurones in the cat's striate cortex
1959-10-01
[35]
논문
Visual feature extraction by a multilayered network of analog threshold elements
1969
[36]
arXiv
Searching for Activation Functions
2017-10-16
[37]
journal
位置ずれに影響されないパターン認識機構の神経回路のモデル --- ネオコグニトロン ---
https://search.ieice[...]
1979-10-01
[38]
journal
Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position
https://www.cs.princ[...]
2013-11-16
[39]
conference
1993 (4th) International Conference on Computer Vision
IEEE
1993
[40]
journal
Deep Learning
http://www.scholarpe[...]
2019-01-20
[41]
journal
An Artificial Neural Network for Spatio-Temporal Bipolar Patterns: Application to Phoneme Classification
https://proceedings.[...]
2022-03-31
[42]
conference
Phoneme Recognition Using Time-Delay Neural Networks
https://isl.anthropo[...]
1987-12-01
[43]
journal
Phoneme Recognition Using Time-Delay Neural Networks
http://www.inf.ufrgs[...]
1989-03-01
[44]
encyclopedia
Convolutional networks for images, speech, and time series
https://www.research[...]
The MIT press
2019-12-03
[45]
journal
Connectionist Architectures for Multi-Speaker Phoneme Recognition
https://proceedings.[...]
Morgan Kaufmann
[46]
conference
A Study on Data Augmentation of Reverberant Speech for Robust Speech Recognition
https://www.danielpo[...]
2019-09-04
[47]
journal
Neural network recognizer for hand-written zip code digits
http://citeseerx.ist[...]
AT&T Bell Laboratories
[48]
journal
Backpropagation Applied to Handwritten Zip Code Recognition
http://yann.lecun.co[...]
AT&T Bell Laboratories
[49]
book
Learning algorithms for classification: A comparison on handwritten digit recognition
http://yann.lecun.co[...]
World Scientific
1995-08-01
[50]
journal
Gradient-based learning applied to document recognition
https://ieeexplore.i[...]
1998-11-01
[51]
journal
Error Back Propagation with Minimum-Entropy Weights: A Technique for Better Generalization of 2-D Shift-Invariant NNs
https://drive.google[...]
2016-09-22
[52]
journal
Image processing of human corneal endothelium based on a learning network
https://drive.google[...]
2016-09-22
[53]
journal
Computerized detection of clustered microcalcifications in digital mammograms using a shift-invariant artificial neural network
https://drive.google[...]
2016-09-22
[54]
journal
Applications of neural networks to medical signal processing
https://www.research[...]
[55]
journal
Decomposition of surface EMG signals into single fiber action potentials by means of neural network
https://ieeexplore.i[...]
[56]
journal
Identification of firing patterns of neuronal signals
http://www.academia.[...]
[57]
journal
GPU implementation of neural networks.
2004
[58]
conference
12th International Conference on Document Analysis and Recognition (ICDAR 2005)
2022-03-31
[59]
conference
Tenth International Workshop on Frontiers in Handwriting Recognition
Suvisoft
2016-03-14
[60]
journal
A fast learning algorithm for deep belief nets.
2006-07-01
[61]
journal
Greedy Layer-Wise Training of Deep Networks
https://proceedings.[...]
2022-03-31
[62]
journal
Efficient Learning of Sparse Representations with an Energy-Based Model
http://yann.lecun.co[...]
2014-06-26
[63]
conference
Proceedings of the 26th Annual International Conference on Machine Learning
ICML '09: Proceedings of the 26th Annual International Conference on Machine Learning
2023-12-22
[64]
journal
Deep big simple neural nets for handwritten digit recognition.
2010
[65]
journal
Flexible, High Performance Convolutional Neural Networks for Image Classification
https://people.idsia[...]
2013-11-17
[66]
website
IJCNN 2011 Competition result table
https://benchmark.in[...]
2010
[67]
website
History of computer vision contests won by deep CNNs on GPU
https://people.idsia[...]
2017-03-17
[68]
journal
CHAOS: a parallelization scheme for training convolutional neural networks on Intel Xeon Phi
2019
[69]
conference
2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems
IEEE 2015
2022-03-31
[70]
journal
ImageNet Classification with Deep Convolutional Neural Networks
https://dl.acm.org/d[...]
2021-03-26
[71]
서적
Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow
O'Reilly Media
2019
[72]
일반
[73]
웹사이트
CS231n Convolutional Neural Networks for Visual Recognition
https://cs231n.githu[...]
2017-04-25
[74]
일반
[75]
논문
Pooling in convolutional neural networks for medical image analysis: a survey and an empirical study
2022-04-01
[76]
논문
Why do deep convolutional networks generalize so poorly to small image transformations?
https://jmlr.org/pap[...]
2022-03-31
[77]
학회
Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition
http://ais.uni-bonn.[...]
Springer
[78]
arXiv
Fractional Max-Pooling
2014-12-18
[79]
arXiv
Striving for Simplicity: The All Convolutional Net
2014-12-21
[80]
논문
Fine-Grained Vehicle Classification With Channel Max Pooling Modified CNNs
Institute of Electrical and Electronics Engineers (IEEE)
[81]
논문
A Comparison of Pooling Methods for Convolutional Neural Networks
2022-08-29
[82]
arXiv
Pooling Methods in Deep Neural Networks, a Review
2020-09-16
[83]
논문
A theory of steady-state activity in nerve-fiber networks: I. Definitions and preliminary lemmas
http://link.springer[...]
1941-06-01
[84]
논문
ImageNet classification with deep convolutional neural networks
https://papers.nips.[...]
2017-05-24
[85]
논문
Appropriate number and allocation of ReLUs in convolutional neural networks
2017
[86]
학회
Deep sparse rectifier neural networks
https://web.archive.[...]
[87]
논문
Imagenet classification with deep convolutional neural networks
https://proceedings.[...]
[88]
일반
[89]
서적
ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
2021
[90]
서적
Artificial Intelligence Research
Springer International Publishing
2020
[91]
서적
Making Convolutional Networks Shift-Invariant Again
https://www.worldcat[...]
2019-04-25
[92]
논문
Spatial Transformer Networks
https://proceedings.[...]
2015
[93]
서적
Dynamic Routing Between Capsules
https://worldcat.org[...]
2017-10-26
[94]
논문
Inductive conformal predictor for convolutional neural networks: Applications to active learning for image classification
https://www.scienced[...]
2019-06-01
[95]
논문
Deep Learning With Conformal Prediction for Hierarchical Analysis of Large-Scale Whole-Slide Tissue Images
2021-02-01
[96]
논문
Dropout: A Simple Way to Prevent Neural Networks from overfitting
http://www.cs.toront[...]
[97]
논문
Regularization of Neural Networks using DropConnect ICML 2013 JMLR W&CP
http://proceedings.m[...]
2013-02-13
[98]
arXiv
Stochastic Pooling for Regularization of Deep Convolutional Neural Networks
2013-01-15
[99]
웹사이트
Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis – Microsoft Research
https://www.microsof[...]
2003-08-01
[100]
arXiv
Improving neural networks by preventing co-adaptation of feature detectors
[101]
웹사이트
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
https://jmlr.org/pap[...]
[102]
논문
Some demonstrations of the effects of structural descriptions in mental imagery
[103]
서적
The frame of reference
1990
[104]
강의자료
Coursera lectures on Neural Networks
https://www.coursera[...]
2012
[105]
웹사이트
The inside story of how AI got good enough to dominate Silicon Valley
https://qz.com/13070[...]
2018-06-18
[106]
논문
Face Recognition: A Convolutional Neural Network Approach
[107]
논문
A Convolutional Neural Network Approach for Objective Video Quality Assessment
https://hal.archives[...]
2013-11-17
[108]
웹사이트
ImageNet Large Scale Visual Recognition Competition 2014 (ILSVRC2014)
https://image-net.or[...]
2016-01-30
[109]
학회자료
IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7–12, 2015
IEEE Computer Society
[110]
arXiv
Image ''Net'' Large Scale Visual Recognition Challenge
[111]
뉴스
The Face Detection Algorithm Set To Revolutionize Image Search
https://www.technolo[...]
2017-10-27
[112]
서적
Human Behavior Unterstanding
Springer Berlin Heidelberg
2011-11-16
[113]
논문
3D Convolutional Neural Networks for Human Action Recognition
2013-01-01
[114]
arXiv
Video-based Sign Language Recognition without Temporal Segmentation
[115]
학회자료
Large-scale video classification with convolutional neural networks
https://www.cv-found[...]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
[116]
arXiv
Two-Stream Convolutional Networks for Action Recognition in Videos
[117]
논문
Segment-Tube: Spatio-Temporal Action Localization in Untrimmed Videos with Per-Frame Segmentation
https://qilin-zhang.[...]
2018-05-22
[118]
학회자료
2018 25th IEEE International Conference on Image Processing (ICIP)
25th IEEE International Conference on Image Processing (ICIP)
[119]
학회자료
Convolutional Learning of Spatio-temporal Features
https://dl.acm.org/d[...]
Springer-Verlag
2010-01-01
[120]
서적
CVPR 2011
IEEE Computer Society
2011-01-01
[121]
arXiv
A Deep Architecture for Semantic Parsing
2014-04-29
[122]
논문
Learning Semantic Representations Using Convolutional Neural Networks for Web Search – Microsoft Research
https://www.microsof[...]
2014-04
[123]
arXiv
A Convolutional Neural Network for Modelling Sentences
2014-04-08
[124]
arXiv
Convolutional Neural Networks for Sentence Classification
2014-08-25
[125]
학회자료
A unified architecture for natural language processing: Deep neural networks with multitask learning
https://thetalkingma[...]
Proceedings of the 25th international conference on Machine learning. ACM
[126]
arXiv
Natural Language Processing (almost) from Scratch
2011-03-02
[127]
arXiv
Comparative study of CNN and RNN for natural language processing
2017-03-02
[128]
arXiv
An empirical evaluation of generic convolutional and recurrent networks for sequence modeling
[129]
논문
Detecting dynamics of action in text with a recurrent neural network
[130]
학회자료
Approximation Theory of Convolutional Architectures for Time Series Modelling
[131]
학회자료
Time-Series Anomaly Detection Service at Microsoft {{!}} Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
[132]
arXiv
AtomNet: A Deep Convolutional Neural Network for Bioactivity Prediction in Structure-based Drug Discovery
2015-10-09
[133]
arXiv
Understanding Neural Networks Through Deep Visualization
2015-06-22
[134]
뉴스
Toronto startup has a faster way to discover effective medicines
https://www.theglobe[...]
[135]
웹사이트
Startup Harnesses Supercomputers to Seek Cures
https://www.kqed.org[...]
2015-05-27
[136]
논문
Evolving neural networks to play checkers without relying on expert knowledge
[137]
논문
Evolving an expert checkers playing program without using human expertise
[138]
서적
Blondie24: Playing at the Edge of AI
Morgan Kaufmann
2001
[139]
arXiv
Teaching Deep Convolutional Neural Networks to Play Go
[140]
arXiv
Move Evaluation in Go Using Deep Convolutional Neural Networks
[141]
웹사이트
AlphaGo – Google DeepMind
https://web.archive.[...]
2016-01-30
[142]
논문
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
2018-04-19
[143]
논문
Multi-Scale Context Aggregation by Dilated Convolutions
2016-04-30
[144]
논문
Conditional Time Series Forecasting with Convolutional Neural Networks
2018-09-17
[145]
논문
Time-series modeling with undecimated fully convolutional neural networks
2015-08-03
[146]
논문
Probabilistic Forecasting with Temporal Convolutional Neural Network
2019-06-11
[147]
논문
Convolutional neural networks for time series classi
2017-02-01
[148]
논문
QCNN: Quantile Convolutional Neural Network
2019-08-21
[149]
간행물
CNN based common approach to handwritten character recognition of multiple scripts
https://ieeexplore.i[...]
2015-08-23
[150]
웹사이트
NIPS 2017
https://web.archive.[...]
2017-10-20
[151]
서적
Artificial Intelligence Applications and Innovations
Springer International Publishing
[152]
논문
Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network
https://qilin-zhang.[...]
2018-06-21
[153]
논문
Distributed Deep Q-Learning
2015-08-18
[154]
논문
Human-level control through deep reinforcement learning
2015
[155]
논문
Self-segmentation of sequences: automatic formation of hierarchies of sequential behaviors
2000-06-01
[156]
웹사이트
Convolutional Deep Belief Networks on CIFAR-10
http://www.cs.toront[...]
[157]
서적
Proceedings of the 26th Annual International Conference on Machine Learning
ACM
2009-01-01
[158]
서적
Hierarchical Neural Networks for Image Interpretation
https://www.ais.uni-[...]
Springer
[159]
뉴스
Google Built Its Very Own Chips to Power Its AI Bots
https://www.wired.co[...]
2016-05-18
[160]
웹사이트
K-Pop Hit Song Recorded in 6 Languages Using Deep Learning
https://www.deeplear[...]
2023-08-02
[161]
서적
Deep content-based music recommendation
http://papers.nips.c[...]
Curran Associates, Inc.
2013-01-01
[162]
논문
A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning
https://doiorg/10.11[...]
ACM
2008-01-01
[163]
웹사이트
誰もdlshogiには敵わなくなって将棋AIの世界が終わってしまった件 {{!}} やねうら王 公式サイト
https://yaneuraou.ya[...]
[164]
웹사이트
examples/mnist/main.py at main · pytorch/examples
https://github.com/p[...]
[165]
웹사이트
Conv2d — PyTorch 2.3 documentation
https://pytorch.org/[...]
[166]
웹사이트
PyTorch 1.10 Conv1D
https://pytorch.org/[...]
[167]
웹사이트
MaxPool2d — PyTorch 2.3 documentation
https://pytorch.org/[...]
[168]
논문
ネオコグニトロンと畳み込みニューラルネットワーク
https://www.jstage.j[...]
Japan Science and Technology Agency
2019
[169]
논문
Shift-invariant pattern recognition neural network and its optical architecture
https://drive.google[...]
1988
[170]
논문
Parallel distributed processing model with local space-invariant interconnections and its optical architecture
https://drive.google[...]
1990
[171]
논문
Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position
https://doi.org/10.1[...]
1980-04-01
[172]
논문
Why do deep convolutional networks generalize so poorly to small image transformations?
https://arxiv.org/ab[...]
2019
[173]
논문
Truly shift-invariant convolutional neural networks
https://arxiv.org/ab[...]
2021
[174]
논문
MobileNets
arxiv:1704.04861
[175]
논문
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
arxiv:1704.04861
[176]
논문
Aggregated Residual Transformations for Deep Neural Networks
arxiv:1611.05431
2017
[177]
웹사이트
PyTorch nn.Conv2d
https://pytorch.org/[...]
[178]
서적
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
2017
[179]
웹사이트
14.10. Transposed Convolution — Dive into Deep Learning 1.0.3 documentation
https://d2l.ai/chapt[...]
2024-07-23
[180]
웹사이트
ConvTranspose2d — PyTorch 2.3 documentation
https://pytorch.org/[...]
2024-07-23
[181]
웹사이트
AvgPool2d — PyTorch 2.4 documentation
https://pytorch.org/[...]
2024-07-30
[182]
웹사이트
Global Average Pooling Explained
https://paperswithco[...]
2024-07-30
[183]
웹사이트
Spatial Pyramid Pooling Explained
https://paperswithco[...]
2024-07-30
[184]
웹사이트
空間ピラミッドプーリング層 (SPP-net, Spatial Pyramid Pooling) とその応用例や発展型 {{!}} CVMLエキスパートガイド
https://cvml-expertg[...]
2024-07-30
[185]
서적
Recurrent Convolutional Neural Network for Object Recognition
2015
[186]
서적
Recurrent Convolutional Neural Network for Object Recognition
2015
[187]
간행물
WaveNetによる言語情報を含まない感情音声合成方式の検討
2019
[188]
논문
What are the Receptive, Effective Receptive, and Projective Fields of Neurons in Convolutional Neural Networks?
arxiv:1705.07049
2017
[189]
기타
layer k ... ''Rk'' be the ERF ... ''fk'' represent the filter size ... the final top-down equation:
[190]
논문
Subject independent facial expression recognition with robust face detection using a convolutional neural network
http://www.iro.umont[...]
2003
[191]
논문
Neocognitron
2007
[192]
논문
Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position
http://www.cs.prince[...]
1980
[193]
웹사이트
LeNet-5, convolutional neural networks
http://yann.lecun.co[...]
2013-11-16
[194]
웹사이트
ImageNet Large Scale Visual Recognition Competition 2012 (ILSVRC2012)
https://www.image-ne[...]
2024-07-16
[195]
웹사이트
ILSVRC2014 Results
https://image-net.or[...]
2024-07-16
[196]
웹사이트
ILSVRC2015 Results
https://image-net.or[...]
2024-07-16
[197]
논문
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
2021
[198]
논문
Pay Attention to MLPs
2021
[199]
웹인용
[네이버 지식백과] 합성곱 신경망 [Convolutional Neural Network, 合成-神經網] (대한건축학회 건축용어사전)
https://terms.naver.[...]
[200]
서적
모두의 딥러닝
길벗
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com