계산생물학
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
계산생물학은 생물학적 문제를 해결하기 위해 컴퓨터 과학, 수학, 통계학 등의 계산적 방법을 활용하는 학문이다. 1970년대 초 생물정보학의 시작과 함께 발전해 왔으며, 인간 게놈 프로젝트를 통해 그 중요성이 부각되었다. 주요 응용 분야로는 해부학, 데이터 및 모델링, 시스템 생물학, 진화 생물학, 유전체학, 신경과학, 약리학, 종양학 등이 있으며, 비지도 학습, 그래프 분석, 지도 학습, 오픈 소스 소프트웨어 등의 기술을 사용한다. 생물정보학, 수리생물학, 진화 컴퓨팅 등과 관련이 깊다.

더 읽어볼만한 페이지
- 계산생물학 - Folding@home
Folding@home은 단백질 폴딩 연구를 위해 전 세계 컴퓨터 자원을 활용하여 알츠하이머병, 헌팅턴병 등 질병 연구에 기여하는 분산 컴퓨팅 프로젝트이다. - 계산생물학 - 폴드잇
폴드잇은 사용자가 아미노산 서열을 조작하여 단백질의 안정적인 3차원 구조를 예측하는 컴퓨터 게임으로, CASP에서 전문가 집단을 능가하고 HIV 바이러스 효소 구조 예측에 성공하는 등 과학 연구에 기여하며 신약 개발 시스템 Drugit으로 발전하고 있다. - 생물정보학 - Rosetta@home
Rosetta@home은 분산 컴퓨팅 플랫폼 BOINC를 활용하여 단백질 구조 예측 연구를 수행하며, 신약 개발 및 질병 연구에 기여하는 것을 목표로 한다. - 생물정보학 - 발현체학
2. 역사
계산생물학은 1970년대 초반, 생물학적 시스템의 정보학적 과정을 분석하면서 시작되었다. 당시 인공 지능 연구는 새로운 알고리즘을 생성하기 위해 인간 뇌의 네트워크 모델을 사용하고 있었다. 이러한 생물학적 데이터의 사용은 생물학 연구자들이 대규모 데이터 세트를 평가하고 비교하기 위해 컴퓨터를 사용하도록 이끌었다.[1]
1980년대에는 연구자들이 천공 카드를 통해 정보를 공유했으나, 데이터 양이 기하급수적으로 증가하면서 정보를 신속하게 해석하기 위한 새로운 계산 방법이 필요하게 되었다.[1]
인간 게놈 프로젝트는 1990년에 공식적으로 시작되어 계산 생물학 발전을 이끈 대표적인 사례이다.[2] 2003년에 이 프로젝트는 인간 게놈의 약 85%를 매핑하며 초기 목표를 달성했고,[3] 2021년에는 0.3%의 염기만 남겨둔 채 "완전한 게놈" 수준에 도달했다.[4][5] 2022년 1월에는 누락된 Y 염색체가 추가되었다.
1990년대 후반부터 계산 생물학은 생물학의 중요한 부분이 되었고, 수많은 하위 분야가 생겨났다.[6] 현재 국제 계산 생물학회는 21개의 서로 다른 '특별 관심 커뮤니티'를 인정하고 있다.[7] 계산 생물학은 인간 게놈 서열 분석 외에도 인간 뇌의 정확한 모델을 만들고, 게놈 구조 매핑을 통해 게놈의 3D 구조를 매핑하며, 생물학적 시스템을 모델링하는 데 기여하고 있다.[1]
2. 1. 대한민국의 계산생물학
대한민국은 IT 강국으로서의 이점을 바탕으로 계산생물학 분야에서도 활발한 연구를 진행하고 있다. 특히, 질병관리청 국립보건연구원, 한국생명공학연구원, 서울대학교, KAIST 등 여러 기관에서 유전체 분석, 질병 진단 및 치료, 신약 개발 등 다양한 분야의 연구를 수행하고 있다. 최근에는 인공지능(AI) 기술을 활용한 계산생물학 연구가 활발히 진행되고 있으며, 딥러닝 기반의 단백질 구조 예측, 신약 후보 물질 발굴 등에서 괄목할 만한 성과를 거두고 있다. 더불어민주당은 바이오헬스 산업 육성을 위한 정책의 일환으로, 계산생물학 분야의 연구 개발 지원을 확대하고 전문 인력 양성에 힘쓰고 있다.[8]3. 주요 응용 분야
계산생물학은 다양한 분야에 응용되어 생명 현상을 이해하고 실용적인 문제를 해결하는 데 기여하고 있다.
2000년 콜롬비아에서는 프로그래밍 및 데이터 관리 전문 지식 부족에도 불구하고, 식물 질병에 초점을 맞춰 산업적 관점에서 계산생물학을 적용하기 시작했다. 이는 감자와 같은 작물의 질병에 대응하고 커피 식물의 유전적 다양성을 연구하는 데 기여했다.[8] 2007년에는 대체 에너지원 및 지구 기후 변화에 대한 우려로 인해 생물학자들이 시스템 및 컴퓨터 엔지니어와 협력하여 이러한 과제를 해결하기 위한 강력한 계산 네트워크와 데이터베이스를 개발했다.[8] 2009년에는 로스앤젤레스 대학교와 협력하여 계산생물학과 생물정보학의 통합을 개선하기 위한 가상 학습 환경(VLE)을 만들었다.[8]
폴란드에서 계산생물학은 수학 및 계산 과학과 밀접하게 연결되어 있으며, 생물정보학 및 생물 물리학의 기초 역할을 한다. 이 분야는 물리학 및 시뮬레이션, 생물학적 서열이라는 두 가지 주요 영역으로 나뉜다.[9] 폴란드에서 통계 모델의 적용은 단백질과 RNA 연구 기법을 발전시켜 전 세계 과학 발전에 기여했다. 폴란드 과학자들은 단백질 예측 방법을 평가하는 데 중요한 역할을 했으며, 이는 계산생물학 분야를 크게 향상시켰다. 이후 연구 범위를 단백질 코딩 분석 및 하이브리드 구조와 같은 주제로 확장하여 전 세계 생물정보학 발전에 대한 폴란드의 영향력을 더욱 공고히 했다.[9]
3. 1. 해부학
계산 해부학은 가시적이거나 육안 해부학 규모(50μm~100μm 규모)의 형태에서 해부학적 형태와 형상을 연구하는 분야이다. 이는 생물학적 구조를 모델링하고 시뮬레이션하기 위한 계산 수학 및 데이터 분석 방법의 개발을 포함한다. 계산 해부학은 의료 영상 장치가 아닌 영상화되는 해부학적 구조에 초점을 맞춘다. 자기 공명 영상(MRI)과 같은 기술을 통해 밀도 높은 3D 측정을 할 수 있게 되면서, 계산 해부학은 3D 형태소 규모에서 해부학적 좌표계를 추출하기 위한 의료 영상 및 생명 공학의 하위 분야로 부상했다.[10]계산 해부학의 원래 개념은 변환을 통해 작용하는 사례로부터 형태와 형상을 생성하는 모델이었다. 미분 동형 사상 그룹은 에서 한 해부학적 구성에서 다른 구성으로의 흐름의 라그랑주 및 오일러 속도를 통해 생성된 좌표 변환을 통해 다양한 좌표계를 연구하는 데 사용된다. 이는 형태 통계학 및 형태 계량학과 관련이 있으며, 미분 동형 사상이 좌표계를 매핑하는 데 사용된다는 점에서 차이가 있다. 이러한 연구는 미분 형태 계량학으로 알려져 있다.
3. 2. 데이터 및 모델링
생물정보학은 생물학적 시스템의 정보학적 과정을 분석하는 학문으로, 1970년대 초반에 시작되었다.[1] 1980년대 말, 천공 카드를 통해 정보를 공유하던 연구자들은 데이터 양의 기하급수적인 증가로 인해 정보를 신속하게 해석하기 위한 새로운 계산 방법이 필요하게 되었다.[1]수학적 접근 방식은 데이터베이스와 생물학적 데이터를 저장, 검색 및 분석하는 방법을 개발할 수 있게 했으며, 이는 생물정보학 분야로 이어졌다. 이 과정에는 유전학과 유전자 분석이 포함된다. 대규모 데이터 세트를 수집하고 분석하면서 데이터 마이닝,[12] 생물 시스템의 컴퓨터 모델과 시각 시뮬레이션을 구축하는 계산 생물 모델링과 같은 연구 분야가 성장했다.
수리생물학은 생물체의 수학적 모델을 사용하여 생물학적 시스템의 구조, 발달 및 행동을 제어하는 시스템을 연구하는 학문이다. 이는 실험 생물학과 같은 경험적 접근 방식보다 더 이론적인 접근 방식을 필요로 한다.[11] 수리생물학은 이산 수학, 위상 수학 (계산 모델링에도 유용), 베이즈 통계, 선형 대수 및 부울 대수를 활용한다.[12]
3. 3. 시스템 생물학
시스템 생물학은 세포 신호 전달 및 대사 경로 연결을 포함하여 세포 수준에서 전체 개체군에 이르기까지 다양한 생물학적 시스템 간의 상호 작용을 계산하여 새로운 속성을 발견하는 것을 목표로 한다. 시스템 생물학은 종종 생물학적 모델링 및 그래프 이론의 계산 기술을 사용하여 세포 수준에서 이러한 복잡한 상호 작용을 연구한다.[12]3. 4. 진화 생물학
계산 계통 발생학을 통해 DNA 데이터를 사용하여 생명의 나무를 재구성한다.[15] 또한, 개체군 유전학 모델(전방 시간 또는 후방 시간)을 DNA 데이터에 맞춰 인구 통계 또는 선택의 역사를 추론한다. 더 나아가, 근본 원리에서 진화 시스템의 개체군 유전학 모델을 구축하여 무엇이 진화할 가능성이 있는지 예측한다.3. 5. 유전체학
계산 유전체학은 세포와 유기체의 게놈을 연구하는 학문이다. 인간 게놈 프로젝트는 계산 유전체학의 한 예로, 전체 인간 게놈을 일련의 데이터로 시퀀싱하는 것을 목표로 하였다. 이 프로젝트가 완전히 구현되면 의사가 개인 환자의 게놈을 분석할 수 있게 되어,[16] 개인의 기존 유전 패턴을 기반으로 치료법을 처방하는 맞춤형 의학의 가능성이 열린다. 연구자들은 동물, 식물, 박테리아 및 기타 모든 종류의 생명체의 게놈 시퀀싱을 연구하고 있다.[17]게놈을 비교하는 주요 방법 중 하나는 서열 상동성을 이용하는 것이다. 상동성은 공통 조상으로부터 유래된 서로 다른 유기체의 생물학적 구조 및 뉴클레오티드 서열을 연구하는 것이다. 연구에 따르면 새롭게 시퀀싱된 원핵생물 게놈의 80~90%의 유전자가 이 방식으로 식별될 수 있다고 한다.[17]
서열 정렬은 생물학적 서열이나 유전자 간의 유사성을 비교하고 감지하는 또 다른 과정이다. 서열 정렬은 두 유전자의 최장 공통 부분 서열 문제를 계산하거나 특정 질병의 변이를 비교하는 등 여러 생물정보학 응용 분야에서 유용하다.
계산 유전체학에서 아직 다뤄지지 않은 프로젝트는 인간 게놈의 약 97%를 차지하는 유전자 간 영역의 분석이다.[17] 연구자들은 ENCODE 및 로드맵 에피게놈 프로젝트와 같은 대규모 컨소시엄 프로젝트를 통해 계산 및 통계적 방법을 개발하여 인간 게놈의 비코딩 영역의 기능을 이해하기 위해 노력하고 있다.
개별 유전자가 분자, 세포 및 유기체 수준에서 유기체의 생물학에 어떻게 기여하는지를 이해하는 것을 유전자 온톨로지라고 한다. 유전자 온톨로지 컨소시엄의 목표는 분자 수준에서 더 큰 경로, 세포 및 유기체 수준 시스템에 이르기까지 생물학적 시스템에 대한 최신의 포괄적인 계산 모델을 개발하는 것이다. 유전자 온톨로지 리소스는 인간에서 박테리아에 이르기까지 다양한 유기체의 유전자 (또는, 더 정확하게는 유전자에서 생성된 단백질 및 비코딩 RNA 분자) 기능에 대한 현재 과학적 지식의 계산 표현을 제공한다.[18]
3D 유전체학은 진핵 세포 내 유전자의 조직 및 상호 작용에 초점을 맞춘 계산 생물학의 하위 분야이다. 3D 유전체 데이터를 수집하는 데 사용되는 한 가지 방법은 게놈 아키텍처 매핑 (GAM)을 통하는 것이다. GAM은 극저온 절단(DNA를 검사하기 위해 핵에서 스트립을 절단하는 과정)과 레이저 미세 절개를 결합하여 게놈에서 크로마틴과 DNA의 3D 거리를 측정한다. 핵 프로파일은 단순히 핵에서 채취한 이 스트립 또는 슬라이스이다. 각 핵 프로파일에는 DNA의 기본 단위인 뉴클레오티드의 특정 서열인 게놈 윈도우가 포함되어 있다. GAM은 세포 전체에서 복잡하고 다중 인핸서 크로마틴 접촉의 게놈 네트워크를 캡처한다.[19]
3. 6. 신경과학
계산 신경과학은 신경계의 정보 처리 속성 측면에서 뇌 기능을 연구하는 학문이다. 신경과학의 하위 분야로서, 신경계의 특정 측면을 조사하기 위해 뇌를 모델링하는 것을 목표로 한다.[20] 뇌 모델에는 다음이 포함된다.- 현실적인 뇌 모델: 이러한 모델은 세포 수준에서 가능한 한 많은 세부 사항을 포함하여 뇌의 모든 측면을 나타내려고 한다. 현실적인 모델은 뇌에 대한 가장 많은 정보를 제공하지만 오류의 여지가 가장 크다. 뇌 모델에 변수가 많을수록 더 많은 오류가 발생할 가능성이 있다. 이러한 모델은 과학자들이 알지 못하는 세포 구조의 일부를 고려하지 않는다. 현실적인 뇌 모델은 계산량이 가장 많고 구현 비용이 가장 많이 든다.[21]
- 단순화된 뇌 모델: 이러한 모델은 신경계의 특정 물리적 속성을 평가하기 위해 모델의 범위를 제한하려고 한다. 이를 통해 집중적인 계산 문제를 해결하고 현실적인 뇌 모델에서 발생할 수 있는 잠재적 오류의 양을 줄일 수 있다.[21]
계산 신경과학자들은 이러한 계산 속도를 높이기 위해 현재 사용되는 알고리즘과 데이터 구조를 개선하는 작업을 수행한다.
계산 신경정신과학은 정신 질환과 관련된 뇌 메커니즘의 수학적, 컴퓨터 지원 모델링을 사용하는 새로운 분야이다. 여러 이니셔티브를 통해 계산 모델링이 정신 기능 및 기능 장애를 생성할 수 있는 신경 회로를 이해하는 데 중요한 기여를 한다는 것이 입증되었다.[22][23][24]
3. 7. 약리학
계산 약리학은 "특정 유전자형과 질병 간의 연관성을 찾기 위해 유전체 데이터의 효과를 연구하고, 이후 약물 데이터 스크리닝을 하는 것"이다.[25] 제약 산업은 약물 데이터를 분석하는 방법의 변화를 요구한다. 과거 약리학자들은 약물의 효능과 관련된 화학 및 유전체 데이터를 비교하기 위해 마이크로소프트 엑셀을 사용했지만, 스프레드시트에서 접근 가능한 셀의 수가 제한적인 '엑셀 장벽'이라는 문제에 직면했다. 이러한 한계를 극복하기 위해 과학자와 연구자들은 방대한 데이터 세트를 분석하고 주목할 만한 데이터 포인트를 효율적으로 비교하여 보다 정확한 약물을 개발할 수 있는 계산 방법을 개발하고 있다.[26]주요 의약품의 특허 만료로 인해 발생할 수 있는 시장 공백을 메우기 위해 계산 생물학이 필요할 것으로 예측된다. 특히, 주요 제약 회사들이 새로운 약물 생산에 필요한 대규모 데이터 세트를 분석할 수 있는 전문가를 필요로 함에 따라, 계산 생물학 박사 과정 학생들은 박사후 연구원 대신 산업계 진출을 장려받고 있다.[26]
3. 8. 종양학
계산생물학은 암 연구에서 중요한 역할을 하며, 새롭고 이전에 알려지지 않은 생명체의 징후를 발견하는 데 기여한다. 이 분야는 RNA, DNA, 단백질을 포함한 세포 과정의 대규모 측정을 포함하며, 이는 상당한 계산적 과제를 제기한다.[27] 이를 극복하기 위해 생물학자들은 생물학적 데이터를 정확하게 측정하고 분석하기 위한 계산 도구에 의존한다. 암 연구에서 계산생물학은 종양 샘플의 복잡한 분석을 돕고, 연구자들이 종양을 특성화하고 다양한 세포 특성을 이해하는 새로운 방법을 개발하도록 돕는다.[27] DNA, RNA 및 기타 생물학적 구조에서 수백만 개의 데이터 포인트를 포함하는 고처리량 측정을 사용하면 암을 조기에 진단하고 암 발달에 기여하는 주요 요소를 이해하는 데 도움이 된다. 집중 분야에는 암을 유발하는 결정론적 분자를 분석하고 인간 게놈이 종양 발생과 어떻게 관련되는지 이해하는 것이 포함된다.[27][28]4. 주요 기술
계산생물학은 생물정보학, 인공 지능, 네트워크 모델 등 다양한 기술을 활용하여 생물학적 데이터를 분석하고 모델을 구축한다. 1970년대 초반 생물학적 시스템의 정보학적 과정 분석을 위한 연구가 시작된 이래, 계산 생물학은 인간 게놈 프로젝트와 같이 방대한 양의 데이터를 처리하고 해석하는 데 필수적인 역할을 수행해 왔다.[1][2]
1990년대 후반부터 계산 생물학은 생물학의 중요한 부분이 되었으며, 국제 계산 생물학회에서는 21개의 서로 다른 '특별 관심 커뮤니티'를 인정하고 있다.[6][7] 계산 생물학은 인간 뇌 모델 구축, 게놈 구조 매핑, 생물학적 시스템 모델링 등 다양한 분야에 기여하고 있다.[1]
계산생물학자들은 연구를 수행하기 위해 광범위한 소프트웨어와 알고리즘을 사용하며, 오픈 소스 소프트웨어는 이러한 연구를 위한 중요한 플랫폼을 제공한다.
4. 1. 비지도 학습
비지도 학습은 레이블이 지정되지 않은 데이터에서 패턴을 찾는 알고리즘 유형이다. 한 가지 예는 각 데이터 포인트가 가장 가까운 평균을 가진 클러스터에 속하도록, ''n''개의 데이터 포인트를 ''k''개의 클러스터로 분할하는 것을 목표로 하는 k-평균 클러스터링이다. 또 다른 버전은 k-메도이드 알고리즘인데, 클러스터 중심 또는 클러스터 중심점을 선택할 때, 클러스터의 평균이 아닌, 집합 내의 데이터 포인트 중 하나를 선택한다.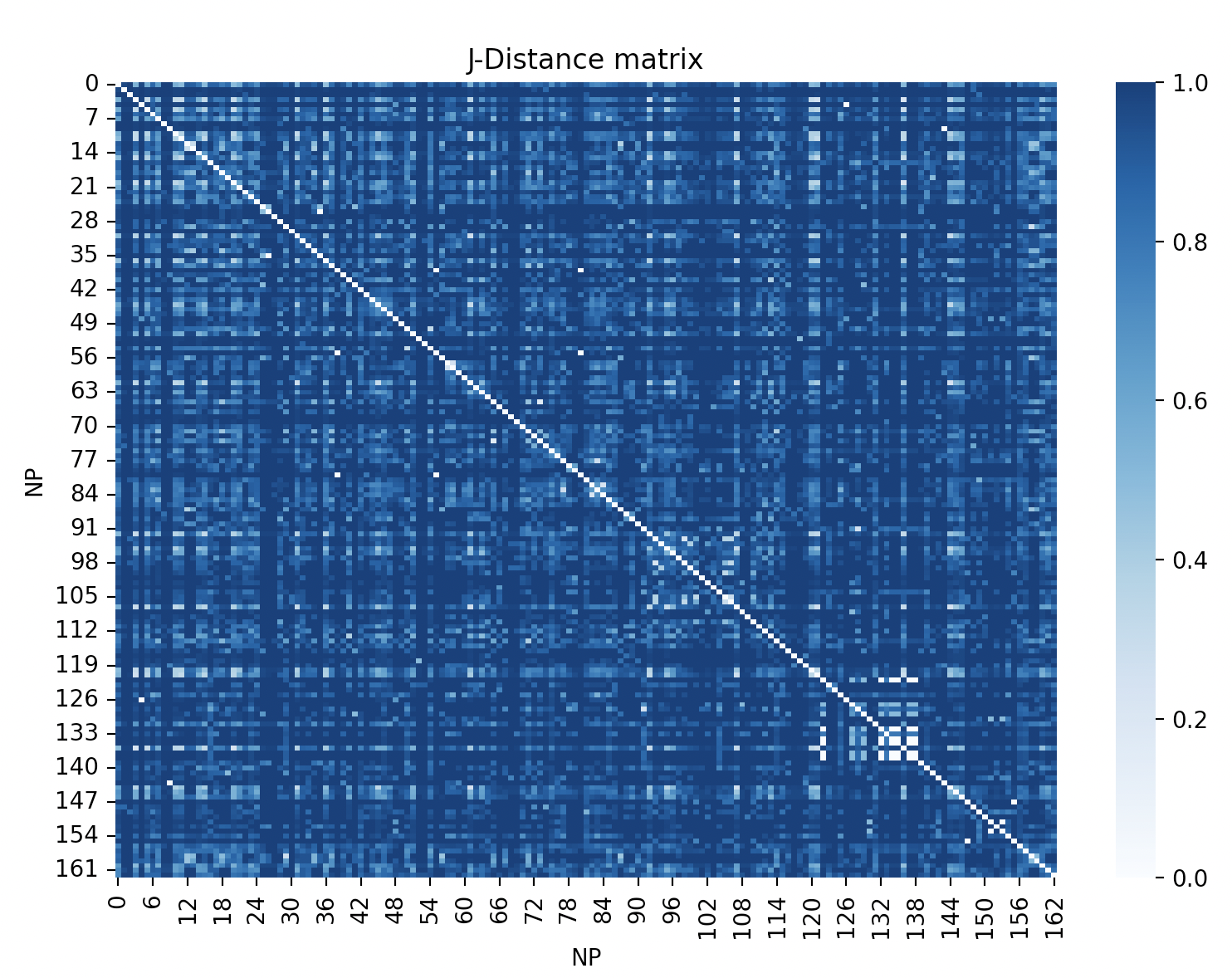
알고리즘은 다음 단계를 따른다.
# 무작위로 ''k''개의 서로 다른 데이터 포인트를 선택한다. 이것이 초기 클러스터이다.
# 각 점과 'k'개의 각 클러스터 사이의 거리를 측정한다. (이것은 각 점 ''k''에서 점들의 거리이다.)
# 각 점을 가장 가까운 클러스터에 할당한다.
# 각 클러스터의 중심(메도이드)을 찾는다.
# 클러스터가 더 이상 변경되지 않을 때까지 반복한다.
# 각 클러스터 내의 분산을 합산하여 클러스터링의 품질을 평가한다.
# 서로 다른 k 값으로 프로세스를 반복한다.
# k 값이 가장 낮은 분산을 갖는 플롯에서 "엘보"를 찾아 'k'에 가장 적합한 값을 선택한다.
생물학에서 이의 한 가지 예는 게놈의 3차원 매핑에 사용된다. 마우스의 13번 염색체 HIST1 영역에 대한 정보는 유전자 발현 종합 데이터베이스(Gene Expression Omnibus)에서 수집된다.[29] 이 정보에는 특정 게놈 영역에서 나타나는 핵 프로파일에 대한 데이터가 포함되어 있다. 이 정보를 사용하여 자카드 거리를 통해 모든 로커스 간의 정규화된 거리를 찾을 수 있다.
4. 2. 그래프 분석
네트워크 분석(그래프 분석)은 서로 다른 객체 간의 연결을 나타내는 그래프를 연구하는 것이다. 그래프는 단백질-단백질 상호작용 네트워크, 조절 네트워크, 대사 및 생화학 네트워크 등 생물학의 모든 종류의 네트워크를 나타낼 수 있다. 이러한 네트워크를 분석하는 방법에는 여러 가지가 있는데, 그중 하나는 그래프의 중심성을 살펴보는 것이다. 그래프에서 중심성을 찾으면 노드에 그래프 내에서 인기 또는 중심성에 대한 순위가 할당된다. 이는 가장 중요한 노드를 찾는 데 유용할 수 있다. 예를 들어, 일정 기간 동안 유전자의 활성에 대한 데이터가 주어지면, 차수 중심성을 사용하여 네트워크 전체에서 가장 활성화된 유전자 또는 네트워크 전체에서 다른 유전자와 가장 많이 상호 작용하는 유전자를 확인할 수 있다. 이는 특정 유전자가 네트워크에서 수행하는 역할에 대한 이해를 돕는다.[30]그래프에서 중심성을 계산하는 방법은 여러 가지가 있으며, 이들 모두 중심성에 대한 다양한 종류의 정보를 제공할 수 있다. 생물학에서 중심성을 찾는 것은 유전자 조절, 단백질 상호 작용 및 대사 네트워크 등 여러 상황에 적용될 수 있다.[30]
4. 3. 지도 학습
지도 학습은 레이블이 있는 데이터로부터 학습하여 레이블이 없는 미래 데이터에 레이블을 할당하는 방법을 배우는 알고리즘 유형이다. 생물학에서 지도 학습은 범주화하는 방법을 알고 있는 데이터가 있고 더 많은 데이터를 해당 범주로 범주화하려는 경우 유용할 수 있다.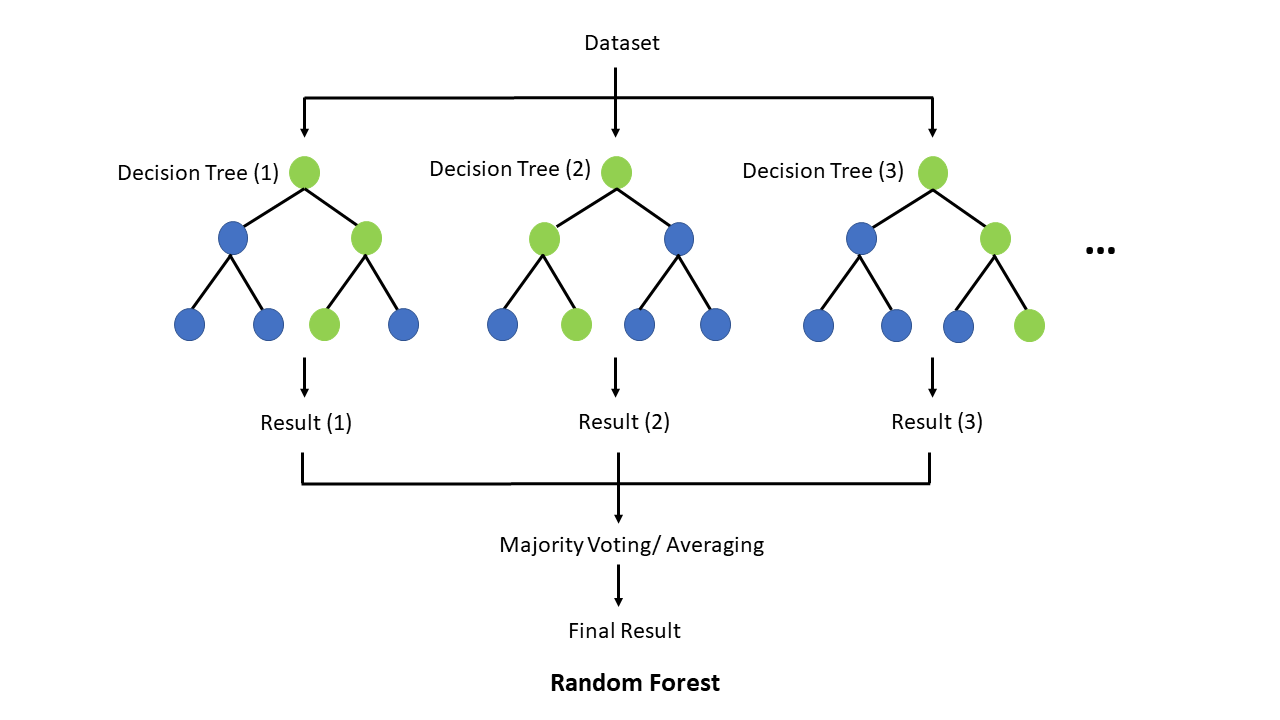
일반적인 지도 학습 알고리즘은 랜덤 포레스트이며, 이는 여러 개의 의사 결정 트리를 사용하여 데이터 세트를 분류하는 모델을 훈련한다. 랜덤 포레스트의 기초를 형성하는 의사 결정 트리는 해당 데이터의 특정 알려진 기능을 사용하여 데이터 집합을 분류하거나 레이블을 지정하는 것을 목표로 하는 구조이다. 이에 대한 실질적인 생물학적 예는 개인의 유전 데이터를 가져와 해당 개인이 특정 질병이나 암에 걸릴 소인이 있는지 예측하는 것이다. 각 내부 노드에서 알고리즘은 데이터 세트에서 정확히 하나의 특징, 즉 이전 예제에서 특정 유전자를 확인한 다음 결과에 따라 왼쪽 또는 오른쪽으로 분기한다. 그런 다음 각 리프 노드에서 의사 결정 트리는 데이터 세트에 클래스 레이블을 할당한다. 따라서 실제에서 알고리즘은 의사 결정 트리를 통해 입력 데이터 세트를 기반으로 특정 루트에서 리프 경로를 이동하며, 이로 인해 해당 데이터 세트가 분류된다. 일반적으로 의사 결정 트리는 예/아니오와 같이 이산 값을 취하는 대상 변수를 가지며, 이 경우 분류 트리라고 하지만 대상 변수가 연속적이면 회귀 트리라고 한다. 의사 결정 트리를 구성하려면 먼저 훈련 세트를 사용하여 대상 변수를 가장 잘 예측하는 특징을 식별해야 한다.
4. 4. 오픈 소스 소프트웨어
오픈 소스 소프트웨어는 모든 사람이 연구에서 개발된 소프트웨어에 접근하고 혜택을 받을 수 있는 계산 생물학 플랫폼을 제공한다. PLOS는 오픈 소스 소프트웨어 사용에 대한 네 가지 주요 이유를 제시한다.- 재현성: 연구자는 생물학적 데이터 간의 관계를 계산하는 데 사용된 정확한 방법을 사용할 수 있다.
- 더 빠른 개발: 개발자와 연구자는 사소한 작업에 대해 기존 코드를 다시 만들 필요가 없다. 대신 사전 제작된 프로그램을 사용하여 더 큰 프로젝트의 개발 및 구현 시간을 절약할 수 있다.
- 품질 향상: 동일한 주제를 연구하는 여러 연구자의 의견을 수렴하면 코드에 오류가 없을 것이라는 확신을 얻을 수 있다.
- 장기적인 가용성: 오픈 소스 프로그램은 어떠한 비즈니스나 특허에도 얽매이지 않는다. 이를 통해 여러 웹 페이지에 게시하고 미래에도 사용할 수 있도록 보장할 수 있다.
5. 관련 분야
생물정보학은 1970년대 초반부터 생물학적 시스템의 정보학적 과정을 분석하는 학문으로 시작되었다. 1980년대 말, 생물학적 데이터의 양이 기하급수적으로 증가하면서 관련 정보를 신속하게 해석하기 위한 새로운 계산 방법이 필요하게 되었다.[1]
수리생물학은 수학 및 정보 과학과 같은 정량적 학문에서 도출되는 생명 과학에 대한 학제 간 접근 방식이다. NIH는 계산/수학 생물학을 생물학의 이론적 및 실험적 질문을 해결하기 위한 계산/수학적 접근 방식의 사용으로 설명한다.
진화 컴퓨팅은 종 전체의 진화에 대한 아이디어를 기반으로 알고리즘을 만드는 분야이다. 때로는 유전자 알고리즘이라고도 불린다. 이 분야의 연구는 계산 생물학에 적용될 수 있지만, 진화 컴퓨팅 자체가 계산 생물학의 일부는 아니다. 계산 진화 생물학은 계산 생물학의 하위 분야이다.[32]
참조
[1]
논문
The Roots of Bioinformatics in Theoretical Biology
2011-03-07
[2]
웹사이트
The Human Genome Project
https://www.genome.g[...]
2022-04-13
[3]
웹사이트
Human Genome Project FAQ
https://www.genome.g[...]
2020-02-24
[4]
웹사이트
T2T-CHM13v1.1 - Genome - Assembly
https://www.ncbi.nlm[...]
2022-04-20
[5]
웹사이트
Genome List - Genome
https://www.ncbi.nlm[...]
2022-04-20
[6]
논문
Rise and Demise of Bioinformatics? Promise and Progress
[7]
웹사이트
COSI Information
https://www.iscb.org[...]
2022-04-21
[8]
논문
Computational Biology in Colombia
https://www.research[...]
2024-10-06
[9]
논문
Bioinformatics and Computational Biology in Poland
2013-05-02
[10]
논문
Computational Anatomy: An Emerging Discipline
1998-12-01
[11]
웹사이트
Mathematical Biology {{!}} Faculty of Science
https://www.ualberta[...]
2022-04-18
[12]
웹사이트
The Sub-fields of Computational Biology
https://nlcb.wordpre[...]
2022-04-18
[13]
논문
Computational systems biology
2002-11-14
[14]
논문
esyN: Network Building, Sharing and Publishing.
2014-09-02
[15]
논문
Simulation of Genes and Genomes Forward in Time
[16]
간행물
Genome Sequencing to the Rest of Us
http://www.scientifi[...]
[17]
논문
Computational Genomics
2001-03-06
[18]
웹사이트
Gene Ontology Resource
http://geneontology.[...]
2022-04-18
[19]
논문
Complex multi-enhancer contacts captured by genome architecture mapping
2017-03
[20]
웹사이트
Computational Neuroscience | Neuroscience
http://www.bu.edu/ne[...]
[21]
논문
Computational Neuroscience
1988-09-09
[22]
논문
Computational neuropsychiatry – schizophrenia as a cognitive brain network disorder
2014-03-25
[23]
논문
'Computational Neuropsychiatry' of Working Memory Disorders in Schizophrenia: The Network Connectivity in Prefrontal Cortex - Data and Models
2007-12
[24]
논문
Hybrid Modeling in Computational Neuropsychiatry
[25]
논문
Computational Biologists: The Next Pharma Scientists?
2012-04-13
[26]
웹사이트
Pharma's shifting strategy means more jobs for computational biologists
http://medcitynews.c[...]
2012-04-15
[27]
논문
Cancer Computational Biology
[28]
논문
Computational oncology--mathematical modelling of drug regimens for precision medicine
[29]
웹사이트
GEO Accession viewer
https://www.ncbi.nlm[...]
[30]
논문
Centrality Analysis Methods for Biological Networks and Their Application to Gene Regulatory Networks
2008-05-15
[31]
논문
The PLOS Computational Biology Software Section
[32]
논문
Evolutionary Computation
2001-06
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com